基于快速强化学习的无线通信干扰规避策略
2022-11-29赵肖迪赵海涛魏急波
李 芳 熊 俊* 赵肖迪 赵海涛 魏急波 苏 曼
①(国防科技大学电子科学学院 长沙 410073)
②(湖南大学电气与信息工程学院 长沙 410082)
③(北京跟踪与通信技术研究所 北京 100094)
1 引言
无线通信信道的开放性使其更容易受到未知干扰攻击,对正常通信构成威胁,因此抗干扰技术得到了广泛的研究[1,2]。抗干扰技术主要是通过频谱感知方式[3]检测干扰信息,并根据自身通信状态进行干扰规避和对抗的过程,从而改善通信效率。干扰规避常用技术主要包括跳频 (Frequency Hopping,FH)、传输速率自适应 (Rate Adaptive, RA)、功率控制等。如果干扰规律已知且恒定,可以使用监督学习进行训练,得到特定的策略进行规避。但是一般无线环境中干扰规律未知且动态变化,预先制定好的规避策略难以适应环境变化。当干扰变化时原策略可能失效,无法采用监督学习制定策略来优化通信性能,需要探索更加有效的干扰规避算法。
在时域和频域都动态变化的通信环境中,业界通常利用强化学习 (Reinforcement Learning, RL)与环境进行交互获得学习经验来优化干扰规避策略[4],从而达到规避干扰的目的。近年来,许多学者将动态频谱接入 (Dynamic Spectrum Access,DSA) 和Q学习进行结合,提出了多种有效的智能抗干扰方法。文献[5,6]将信道选择问题建模为马尔可夫决策过程 (Markov Decision Process, MDP),提出了一种智能选择最优信道的实时强化学习算法(即Q学习),从而选择条件较好的信道进行数据传输来主动避免信道拥塞。在文献[7]中,应用极小极大-Q原理来确定用于传输数据信道的数目,并确定了如何在不同信道之间进行信道切换的方案以规避干扰。文献[8]在多信道动态抗干扰博弈中,基于强化Q学习技术提出了一种最优的信道接入策略。此外,在认知无线网络(Cognitive wireless Network,CRN)场景中,文献[9]提出的基于策略同步Q学习的信道分配策略主动避免了网络中的信道拥塞问题。然而,以上算法均只采用信道切换进行躲避干扰,显然频繁的信道切换会增大系统开销,并不能带来整体性能的提升,因此需要考虑其他方式来进行躲避干扰,完成正常通信。
随着通信设备的更新换代,越来越多的通信设备开始具有切换通信频率和调节发射功率的能力[10]。文献[11]首次研究了多用户场景下同时进行信道选择和功率分配决策的协作抗干扰问题,并将该问题建模为一个多主一从的Stackelberg博弈过程。文献[12,13]提出的零和博弈研究了跳频和传输速率控制,通过联合优化跳频和传输速率自适应技术来避免干扰。无线通信系统中的发送机通过改变其信道、调整其速率或同时改变这两种方式来避开干扰,以提高系统的平均吞吐量,但该文献仅对反应式扫频干扰这一种干扰模式做出了分析,并不适用于多种干扰环境。而文献[14]则将上述决策问题描述为一个马尔可夫决策过程,提出了一种基于深度强化学习(Deep Reinforcement Learning, DRL)的抗干扰算法,该算法可以同时对通信频率和功率进行决策,但是该算法并没有考虑信道切换的代价,不能从多方面说明算法的优势。基于Q学习的2维抗干扰移动通信方案[15]为每个状态策略保留Q函数,用于选择发射功率和接入信道,但是状态空间维度过大会造成Q学习的学习速度降低,难以适应动态变化的无线通信环境。
针对动态变化的干扰环境,干扰规避策略不仅需要考虑通信信道的接入和发射功率控制,还应该考虑算法收敛速度以快速适应环境变化。考虑这一联合优化目标,本文将动态变化环境中的干扰规避问题建模为一个马尔可夫决策过程,提出了一种赢或学习快速策略爬山 (Win or Learn Fast Policy Hill-Climbing, WoLF-PHC)的干扰规避方法,本方法使用“赢或快学习”准则以及可变的学习率,从而更快地实现最优的干扰规避策略。本文主要的研究工作如下:
(1) 首先基于实际无线通信环境,建立2维时频域的经典干扰模型,比如扫频干扰、随机干扰、跟随式干扰、贪婪随机策略干扰,用于后续仿真验证。
(2) 然后将干扰环境下的接入信道和发射功率控制问题建模为一个马尔可夫决策过程,分别给出状态、动作、转移概率和奖励4个元素,并将其定义为一个4元组(S,A,p,R)。
(3) 介绍传统Q学习算法,接着提出一种基于WoLF-PHC学习的快速干扰规避算法。
(4) 将所提的WoLF-PHC算法与传统Q学习和随机策略进行仿真对比,验证了所提WoLF-PHC算法性能最佳。
2 系统模型及问题描述
2.1 干扰模型
为了模拟无线通信环境中的未知干扰,干扰机在每个时隙随机选择干扰信道并发送特定干扰功率的干扰信号,以恶化或中断正在进行的通信链路。本文考虑4种干扰模型[15]场景,分别为扫频干扰、贪婪随机策略干扰、跟随式干扰、随机干扰。具体定义如下:
(1) 扫频干扰:每个时隙干扰m个信道,总信道数M为m的整数倍,扫频周期即为T=M/m。例如,在第1个扫描周期先产生一个随机序列[3,5,1,4,2,6], 即第1个时隙干扰信道[f3,f5],第2个时隙干扰信道[f1,f4], 第3个时隙干扰信道[f2,f6]。当一个扫频周期结束之后,继续重复上一个周期的干扰策略。
(2) 贪婪随机策略干扰:每个时隙随机选择干扰信道,使用P0=1−ε的概率干扰相同信道,P1=ε的概率随机干扰新信道。假设每个时隙生成一个( 0,1) 的 随机数,如果这个随机数小于ε,则随机干扰一个新信道,如果这个随机数大于ε,那么继续干扰原信道。
(3) 跟随式干扰:根据正在进行通信的信道来选择干扰策略。即干扰上一时隙通信所采用的信道,上一时隙通信采用哪个信道,当前时隙就干扰哪个信道。
(4) 随机干扰:每个时隙随机选择信道和干扰功率进行干扰。
2.2 问题分析与建模
如图1所示,考虑无线通信环境中,存在发送机、干扰机、接收机。设信道增益为1,发送信号为x(t),噪声为n(t),干扰信号为z(t),那么接收信号y(t)为
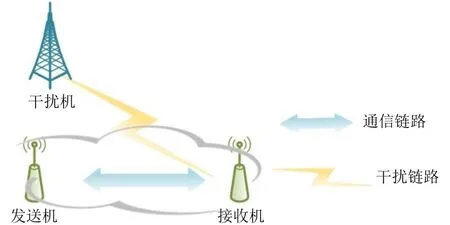
图1 系统模型

假设该系统中发送机的发射功率集合为PU={pu1,pu2,...,pui,...,puL},pui表示可供选择的发射功率大小,共有L种发射功率。第k个时隙所使用的发射功率记为,∈PU。干扰功率集合设为PJ={pj1,pj2,...,pji,...,pjW},pji表示可供选择的干扰功率大小,共有W种发射功率。第k个时隙干扰功率记为,∈PJ, 噪声功率为σ2。利用频谱感知算法[3],我们可以获得未知环境下的干扰信息(即干扰所占信道和干扰功率)。基于这一干扰信息,发送机需要选择合适的信道和发射功率使接收信号达到一定的信干噪比,完成正常解调达到正常通信的目的。发送机应尽量减少信道的切换和发射功率,以达到较少开销的目的。这里引入信道切换代价和功率来衡量系统开销。所谓信道切换代价,即为后一时隙与前一时隙选择的通信信道不同时,进行信道切换所带来的代价;而功率代价,即为所使用的发射功率越大,成本越大。因此,在未知且动态变化的干扰环境中,发送机应需要尽量减少信道切换和发射功率的代价,同时还要规避干扰,从而完成正常通信。
本文将未知环境下发送机选择信道和功率控制过程建模为一个马尔可夫决策过程 (Markov Decision Process, MDP)[6]。MDP为寻找最优策略提供了数学模型,在描述MDP时,通常采用状态、动作、转移概率和奖励这4个元素,并将其定义为一个4元组(S,A,p,R)。 其中,状态空间S和动作空间A是离散的,由于本文的下一状态由当前动作确定,所以状态转移概率为确定值,记为p:S×S×A →[0,1],表示给定当前状态sk ∈S下选择动作ak ∈A转移到下一状态sk+1∈S的概率。本文的MDP模型具体如下:
(1) 状态:定义第k个时隙的状态为sk=(),其中∈{1,2,...,M},前者表示当前时隙选择的通信信道,后者表示当前时隙干扰所占用的信道,设状态空间为S。
(2) 动作:定义在第k个时隙用户采取的动作为ak=(), 其中∈{1,2,...,M},∈PU。为第k+1个时隙用户选择的通信信道,为第k+1个时隙用户采用的发射功率,动作空间大小为M×L, 记为A。
(3) 奖励函数:当用户在sk状态执行动作ak时,会获得相应的奖励值Rk。这里定义第k个时隙的信干噪比 (Signal to Interference plus Noise Ratio, SINR)为

在学习过程中,用户不断与环境交互,探索干扰的变化规律,从而获得最优的传输策略。本文的系统目标是优化用户的传输策略π,使系统的长期累积收益最大化,因此系统优化问题可以建模为其中,γ (0<γ≤1)为折扣因子,表示未来收益对当前收益的重要程度。
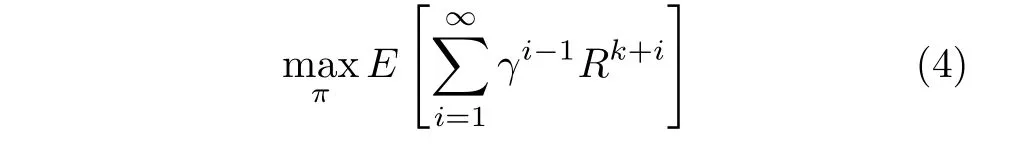
由于问题式(4)被建模为马尔可夫决策问题,可以采用Q学习方法与环境进行实时交互,根据选取动作得到下一时隙的反馈奖励值,并不断更新2维Q矩阵来实现抗干扰策略的优化。下面将介绍传统Q学习算法,并对该算法的现有缺陷进行分析,进而提出一种基于WoLF-PHC的快速强化学习算法。所提算法在未知干扰模型且干扰动态变化的情况下,不仅能保持Q学习的性能,而且能快速学习干扰变化规律并获得最优规避策略,在随机干扰的情况下也能保证收敛。
3 基于快速强化学习的干扰规避算法
3.1 传统Q学习算法
采用Q学习的方法来解决MDP问题的主要思想是将状态和动作构建成一张2维Q表来存储Q值,然后根据Q值来选取能够获得最大收益的动作。Q表中的元素即Q(s,a),表示在某一时隙的s状态下(s∈S),采取动作a(a∈A)后预计能够得到的累计奖励值。在第k个时隙的状态s下采取动作a,更新的Q函数为[6,12]
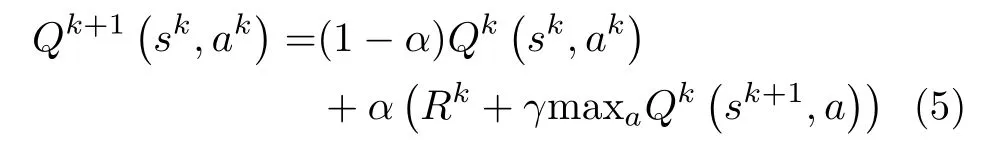
其中,sk,ak分别表示当前的动作和状态,α ∈(0,1]表示学习率,γ ∈(0,1]表 示折扣因子,Rk代表在sk状态执行动作ak时(获得的)奖励值。Qk(sk,ak)为当前的Q值,Qk+1sk,ak则表示更新后的Q值。maxaQk(sk+1,a) 表示下一个状态所有Q值中的最大值。
在基于Q学习的选择策略中,如果用户总是选择Q值对应最大的动作,算法容易陷入局部最优,因此可以采用贪婪策略选择动作。在贪婪选择动作的过程中,产生一个[ 0,1]的随机数,如果该数小于ε,则随机采取一个动作,否则选择Q值最大对应的动作。贪婪策略[16]定义为
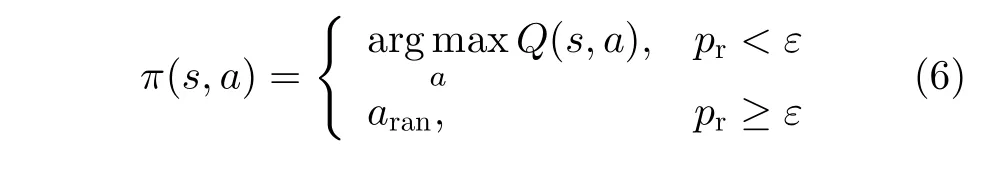
基于Q学习的功率和信道选择策略具体步骤如表1所示。

表1 基于Q学习的功率和信道选择策略
Q学习采用恒定的学习率,收敛速度较慢。根据后面仿真结果图2(d)可知,针对随机策略的干扰该算法不一定达到收敛。在实际无线通信场景中,很难预知干扰的动态变化情况。可见,传统Q学习算法并不适用于所有环境。为此,本文提出了一种新的WoLF-PHC算法,其采用可变的学习率使用户加快学习,并且根据赢或快学习(Win or Learn Fast, WoLF)准则保证了算法的收敛性。

图2 不同干扰环境下的算法性能
3.2 WoLF-PHC算法
赢或学习快速策略爬山(WoLF-PHC)[17]是将“赢或快学习” (WoLF)规则与“策略爬山法”(Policy Hill-Climbing, PHC)相结合的一种学习算法。其中PHC算法是Q学习的简单扩展,通过学习率δ ∈(0,1)逐步增大选择最大行为值(即Q值)的概率来改进策略。当δ= 1时,该算法等效于Q学习算法。该算法中,Q函数的更新规则与Q学习算法中的更新规则相同,即式(5)所示。然而,面对随机策略干扰,PHC算法依然无法收敛。因此,文献[16]进一步引入了WoLF算法以确保算法收敛。当用户当前“赢”时,缓慢调整学习速率,当用户“输”时,加快学习速率,这样使得PHC算法能够收敛到纳什 均 衡。当 前 策 略π(s,a) 和 平 均 策 略π¯ (s,a)之 间 的差异可以作为判断算法输或赢的标准。为了计算平均策略,引入C(s) 表 示当前状态s出现的次数,平均策略的规则为
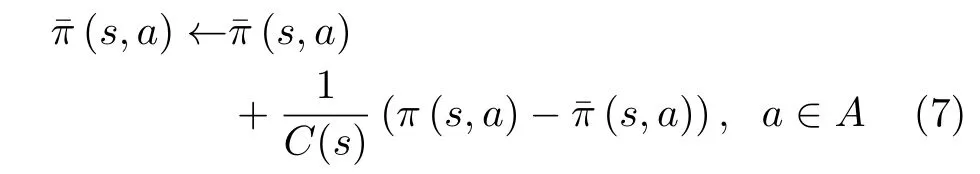
当前策略π(s,a)的 初始值为1 /|A|,|A|为动作空间的长度。如果选择最大Q值的动作,则当前策略增加一个值;而选择其他动作则减去一个值。当前策略的更新规则可表示为
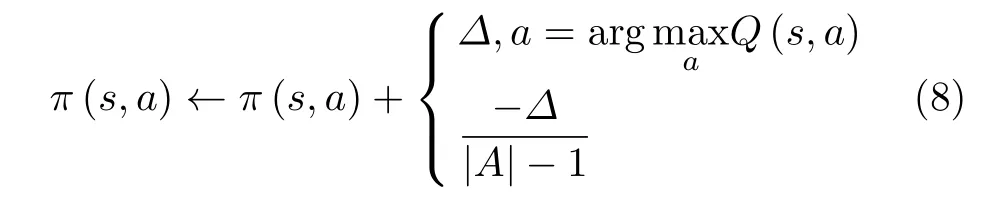
其中

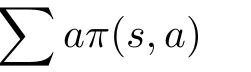
基于WoLF-PHC学习的功率和信道策略具体步骤如表2所示。

表2 基于WoLF-PHC学习的功率和信道选择策略
4 仿真分析
本节主要基于所提WoLF-PHC算法、Q学习算法以及随机策略进行信道和发射功率的选择,并对这3种算法进行仿真分析对比。其中,随机策略是根据上一时隙的感知结果,下一时隙随机选择上一时隙未受干扰的信道和干扰功率。在仿真过程中,首先在频谱感知信息完全正确的情况下,研究了算法的收敛性并对其进行性能评估。其次,在频谱感知结果存在误差的情况下,对算法的鲁棒性能进行分析讨论。仿真参数如表3所示。

表3 仿真参数
如图2所示,本文针对扫频干扰、贪婪随机策略干扰、跟随式干扰、随机干扰4种典型干扰场景进行性能分析。假设一共有M=6个频率不重叠的通信信道,纵坐标表示信道,横坐标代表时隙。实心色块代表当前时隙存在干扰的信道,颜色深浅代表干扰功率的大小,颜色越深代表功率越大,白色代表当前时隙无干扰且不被占用的通信信道,网格块代表当前时隙正在通信的信道。其中,图2(a)表示扫频周期为T=3 ,每个时隙存在m=2个信道的扫频干扰;图2(b)为贪婪概率为ε= 0.2的贪婪随机策略干扰;图2(c)为跟随式干扰,当第1个时隙选取f5信道进行通信时,在第2个时隙就干扰f5信道;图2(d)为随机干扰。
4.1 频谱感知结果完全正确的性能分析
为了对系统一段时间的性能进行统计,仿真过程中在每50个时隙内累积并统计一次奖励值。假设历史干扰检测所占用的信道和干扰功率完全正确,由图3(a)—图3(c)可知,当经历一段时间后,每种干扰模型下所得到的累积奖励值能够趋于稳定,可见算法具有收敛性。此外,还可以观察到WoLFPHC比Q学习能更快地达到收敛,这说明该算法能够快速地学习干扰规律并迅速适应环境,采取最优策略使用户完成通信。在算法收敛后,WoLFPHC和Q学习的性能相近,而随机策略性能相比这两者差很多。而由图3(d)所示,针对随机干扰,Q学习最终不能达到收敛,WoLF-PHC依然可以快速收敛。所以由仿真结果可知,在历史频谱感知结果完全正确的情况下,WoLF-PHC比Q学习可以获得更快的收敛速度,且性能也略优于Q学习,远好于随机策略。
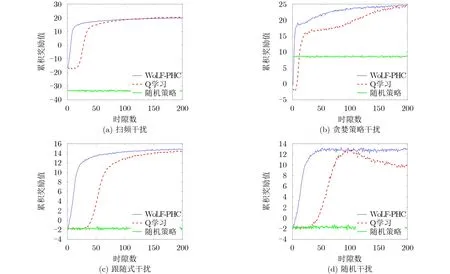
图3 4种典型干扰模型
4.2 频谱感知结果存在误差的性能分析
图4表示在扫频干扰的环境下,WoLF-PHC算法基于不同误检概率下的干扰规避性能,其中p表示感知干扰所占信道错误的概率。由图4可以看出,当频谱感知结果存在误差时会对所提的干扰规避算法产生一定的影响。当频谱感知完全正确的情况下,干扰规避的性能优于频谱感知存在错误的情况,而且误检概率越大,干扰规避性能会越差,但随着时间的推移,不同误检概率的干扰规避性能几乎相近。而且,所提WoLF-PHC算法仍然能够实现收敛,对频谱感知误差具有一定的鲁棒性。
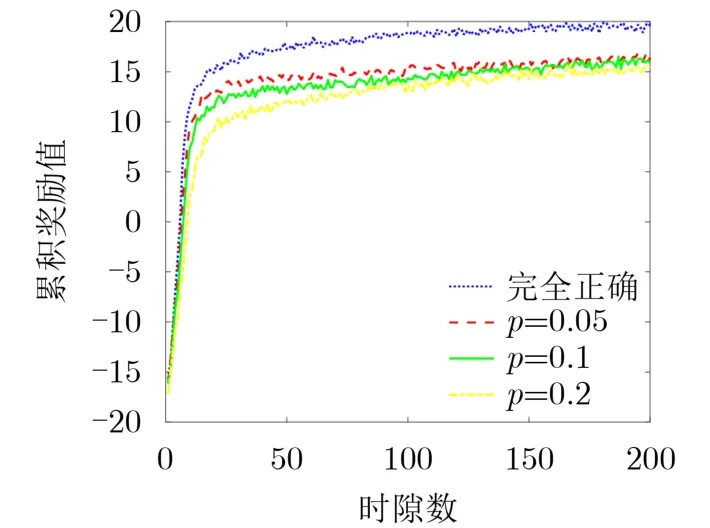
图4 频谱感知误差对所提干扰规避算法的影响
5 结论
本文主要在未知干扰环境下,研究了一种联合发射功率控制和动态信道接入的WoLF-PHC干扰规避方法。在4种典型的干扰环境下,通过对比基于Q学习的干扰规避方法、基于WoLF-PHC的干扰规避方法和随机干扰选择方法,可以看出前两种算法都比随机选择方法性能更优。所提的基于WoLF-PHC干扰规避方法的性能和收敛速度均比Q学习更好。进一步,在频谱感知结果存在误差的情况下对干扰规避性能的影响进行分析可知,频谱感知的误检概率越大,干扰规避性能会略差。在不同频谱感知误差情况下,所提WoLF-PHC算法仍然能够实现收敛,具有一定的鲁棒性。
