基于Hadoop的网站大数据分析系统设计
2022-11-29林在宁杨文杰陈修洁
林在宁杨文杰陈修洁
(北京印刷学院,北京 102600)
中国经济持续飞速发展,房价是国民生活中最关心的议题,考虑到房价上涨,房地产的投资、居住、置业、小孩上学等与购房相关的问题令人困扰,对于房价进行分析,研究其规律和预测房价成为热点问题。在如今信息爆炸的大数据时代,房地产行业在互联网上的庞大数据资源为本文提供了充分的数据源,因此研究开发一个可从互联网中获取房价信息,进行分布式数据存储、大数据计算、数据展示分析,且高性能、方便操作、易用的大数据分析系统,对网站海量数据进行分析,以及对房子信息进行大数据分析都有参考意义。
本文通过编写网络爬虫在各大房价网站上对上海各区房价进行数据爬取,搭建分布式数据存储系统保存数据,引用高效大数据计算框架对数据进行计算,并将得出的相关数据与国家GDP数据一并展示。
1 相关技术
1.1 Python爬虫
网络爬虫是一种自动抓取网页数据、按照算法规则对网页中的数据进行抽取,形成所需的数据的脚本。可使用第三方库提供的强大功能,对网页中进行正则表达式匹配抓取,不断循环,自动把数据获取到本地。爬虫是从网站爬取大数据不可缺少的一种技术。
1.2 Hadoop
Hadoop是一款开源的分布式大数据处理框架,专为服务器设计,从单一到成千上万服务器集群处理海量数据,实现了本地存储和计算。主要用MapReduce的计算框架实现多服务器并行计算。
1.3 ECharts
ECharts是百度开源的纯 Javascript 图表库,支持多种图表,同时提供可交互组件,支持多图表、组件的联动和混搭展现。可以流畅地运行在 PC 和移动设备上,兼容当前绝大部分浏览器,提供直观、生动、可交互、可高度个性化定制的数据可视化图表。
2 系统功能分析
利用大数据分析平台使用网络爬虫技术对从各大房地产网站爬取的数据进行分布式计算,将结果展现成图表形式。数据来源于链家、安居客等房地产相关网站,编写高可用性网络爬虫抓取大量数据,将分析得到的数据与官方发布的数据进行可视化对比展示。本文的具体实现流程如下:
(1)研究Python爬虫技术如何获取房地产网站价格信息以及攻破反爬技术。
(2)对数据进行清洗,对大量的房地产价格信息数据进行处理,把多余的数据参量剔除,保留有用的价格信息、区域信息等,否则无效的数据将会使计算结果不准确。
(3)实现Hadoop分布式集群搭建,使用多个虚拟机进行模拟大规模计算机集群,对于可行性进行测试、使用MapReduce并行计算框架,Map阶段把任务拆分成多个小份,分别将各部分计算出结果,按默认的方式排序,Reduce阶段将Map阶段得出的结果进行合并运算,基于此思想将海量数据进行高效、准确的计算。将分析结果和相关数据进行展示,可以通过不同数据维度进行不同角度的分析,判断数据产生的趋势,关注偏离趋势的点并进行详细分析。通过Python爬虫将数据存于Hadoop集群分析并处理,将结果通过ECharts展示。图1呈现了本系统的主要工作流程。
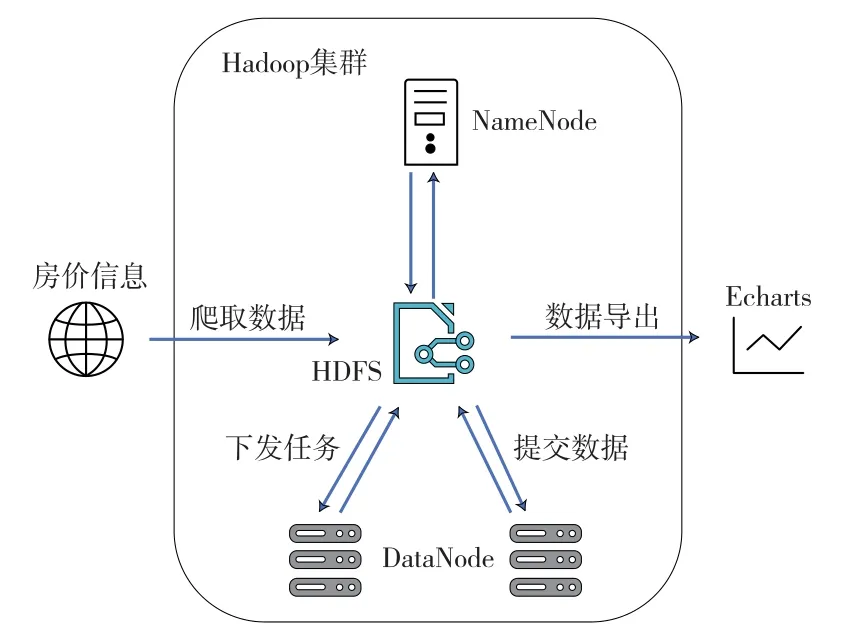
图1 系统工作流程图
3 系统设计
3.1 网络爬虫实现
普通的爬虫很难完成大量复杂的爬取工作,容易因网络波动、硬件限制对爬取效率造成影响。为解决Python爬虫对网页数据爬取的稳定性、成功率的问题,采用分治思想,将整个爬取数据的工作分为两个步骤:首先获取房价信息的网页链接,然后根据获取到的链接逐个爬取具体信息。根据网站Html代码找出当前页码的代码,用正则表达式进行匹配,目的是让爬虫脚本精准定位分页、不断自动翻页,进行全自动爬取。
图2中是某二手房网页上Html代码分析,熟悉编写正则表达式是爬取的前置步骤。
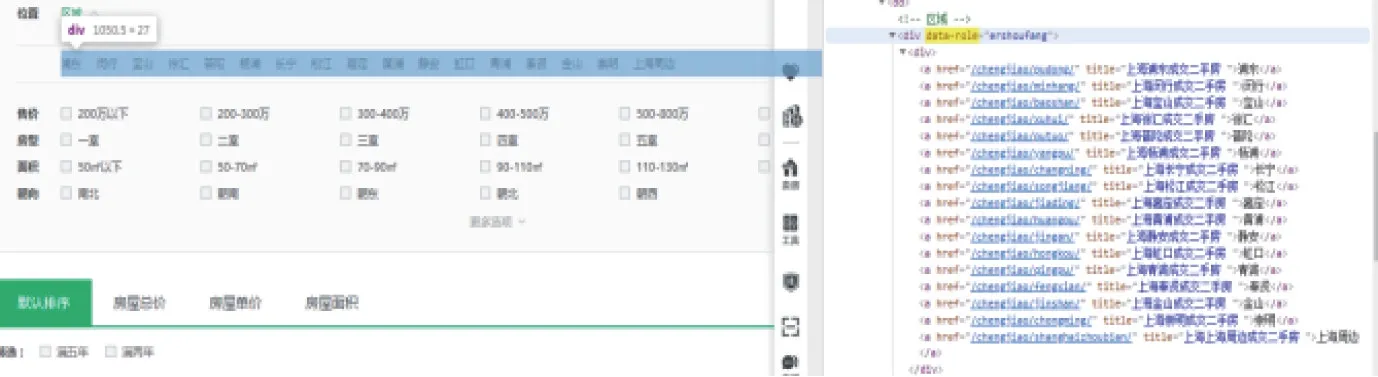
图2 网页Html代码
接下来要获取二手房的信息。对此需要进行粗略的划分,如按照区域划分,在爬取之前做一个简单的分类,为接下来的数据处理做好铺垫,可以减少不必要的麻烦。以下代码通过将Html中二手房的url存入变量中,方便进行url拼接。

最后引入XML包,通过etree.HTML()把Html文本保存到本地。通过拼接url的方式让爬虫获取每一条具体住房的信息。用pandas包将内容以xlsx格式存在本地。代码如下:

由此得到了原始的房价数据。
读取获取的具体房价信息的网页链接,将其首个字段的内容作为数据存入数组。

图3在网站代码中寻找成交价格的代码,仍然用正则表达式来匹配数据。
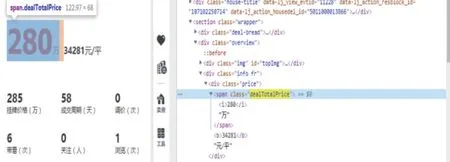
图3 房产成交价格代码
代码如下,将dealTotalPrice的值即成交总价作为对象编译正则表达式。
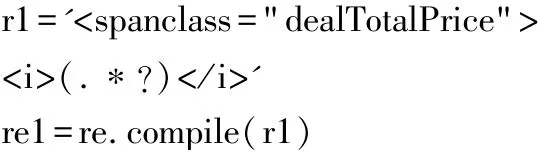
完善数据形式和输出xlsx文件的逻辑。数据爬取的工作流程就基本完成了。
由于本文需要长时间大量且稳定地爬取数据,所以采用了付费的阿布云(https://www.abuyun.com/)的服务,在爬虫中需要配置代理服务器的信息。
3.2 Hadoop平台搭建
Hadoop是一个分布式平台,NameNode作为主节点HDFS文件管理系统建立于此,DataNode在众多机器中存在负责使用各个计算机对数据存储计算。FsImage 文件中保存了某个时刻对HDFS和其文件的快照。editlog顾名思义就是对HDFS进行的所有事务、更改操作的日志文件。SecondaryNamenode节点是一个检查节点。随着运行时间的增长,会将FsImage和editlog文件进行合并生成新的FsImage和editlog。为了防止NameNode发生严重错误导致程序崩溃,此时在SecondaryNamenode中保存一份最近的FsImage和editlog文件,有助于恢复正常状态减少损失,使得Hadoop具有较好的稳定性。Hadoop集群全分布结构由一台主节点为NameNode和多个从节点作DataNode和客户端构成。图4为Hadoop全分布模式数据流图。
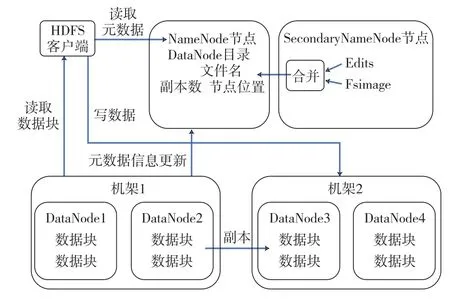
图4 Hadoop全分布模式数据流图
搭建好了Hadoop计算平台,此前爬虫已获取到的房价数据以xlsx的格式存放在表格中,首先将其上传至HDFS服务器中切分成数据块分布式存储,交由NameNode读取数据以进行计算,编写适用于MapReduce计算框架的计算逻辑根对数据进行分析计算。再将结果存入HDFS服务器中。
3.3 MapReduce计算
(1)Map阶段
Mapper首先从输入的数据块中序列化为Hadoop数据类型Long Writable,相比JAVA 中long类型剔除了与计算无关的信息,使得其转化为二进制时体积更小效率更高。定义两个long变量sum和count 初值为0,用于记录总和和数量。
(2)Combiner阶段
Combiner获取 key的值累加到sum中,从value中迭代,累加count值。
Combiner对map阶段的输出先做一次合并,减少了Map阶段和Reduce阶段之间要传输的数据量。减少了IO的工作量,对于网络数据传输性能有了较大提升。
(3)Reduce阶段
Reducer获取了前面map、combiner阶段得出的数据,在此需要一个平均值,即sum/count,此时需要输出的类型为Double Writable,否则可能会出现精度问题。
(4)Driver阶段
这个阶段是整个MapReduce程序的运行类,其中定义了main类、Job的配置、Map阶段启动的类、Combiner阶段启动的类和Reduce阶段启动的类分别是什么,配置了各阶段<k,v>对的输出类型和最终数据文件输出到什么位置等。
(5)MapReduce计算
Hadoop无法直接运行代码,因此首先将代码打包。将数据文档上传到Driver中设定的Input-Path的路径下,确保输出的文件未存在,如存在就先将文件夹删除,否则无法输出结果。准备完成后将xxx-1.0-SNAPSHOT.jar包上传至NameNode的根目录下,输入命令 hadoop jar xxx-1.0-SNAPSHOT.jar等待系统计算完成。计算成功并输出结果后在Hadoop可视化网页中寻找输出目录。
_SUCCESS文件是告知用户计算成功。part-r-00000、00001是最终得出历年上海房价平均值。
3.4 分析效果对比图示
从互联网上爬取,并通过大数据处理得到的数据,将其可视化以便实现对数据的更好展示。并以国家统计局颁布的GDP数据作为对比,在浏览器中即可展示。
如图5是以上海市的GDP与20年来的房价各年均值为例,用大数据分析效果进行对比。
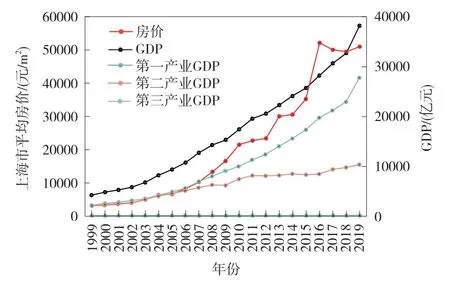
图5 对比效果分析图
图中左侧y方向是上海市的平均房价(元/m2),右侧则为GDP(亿元)。
第一产业GDP几乎贴近于x轴,上海市并非农业主导经济,第二产业GDP在2010年前后与房价增长速度相近,第三产业GDP占经济主导,GDP总值和房价变化幅度类似,符合上海市由第二产业向第三产业转型的经济结构变化规律。
4 结语
为了实现爬虫与大数据计算相结合的网站数据分析系统,使用了Python爬虫技术获取互联网公开数据,对于海量数据结合了Hadoop分布式计算框架,将数据切块分布式存储在可用资源上,整合算力,大大提升了千万、亿级数据处理效率,实现了数据聚合、资源整合,系统高可用,与市场上许多数据处理方案相比避免了资源存储开销高、负载不均、效率过低的问题。
除此以外,还结合了ECharts的前端相关技术,将上海市多年商品房均价与GDP增长的数据清晰地呈现出来,方便普通人、专业人士无门槛快速分析、研究预测。
