VMD特征提取与PSO-GRU神经网络的能耗预测
2022-11-28许晓萍叶泓伟
许晓萍,叶泓伟
(1.福州职业技术学院 机器人学院,福建 福州 350108;2.福州大学 电气工程与自动化学院,福建 福州 350108)
信息时代网络信息传输量和业务应用要求飞速增长,推进云计算中心规模化发展,但随之而来的能源消耗过高问题也日益突出.在“碳达峰、碳中和”节能减排的背景下,云计算中心绿色运行已成为其生存和发展的关键.机柜设备作为云计算中心提供云计算服务载体,机柜设备能耗直接决定云计算中心总体能效.实时监控、准确预测机柜能耗,动态调整机柜投入、减少能源消耗,有助于优化云计算中心能源管理方案与提高能效指标.如何精确预测机柜设备能耗,成为云计算中心能耗管理和能效优化的关键.因云计算中心用户需求差异大,使得云计算中心能耗时间序列具有较强的随机性、非平稳特点,这些因素加大能耗预测难度.
常见的能耗预测方法有基于回归的预测法[1]、时间序列法[2]和基于人工智能的预测方法.随着深度学习技术的发展,人工智能预测方法逐渐成为能耗预测的主流方法.文[3-4]提出基于神经网络的能耗预测模型,具有较强的学习与自适应能力;但单一的神经网络预测模型,无法有效学习非平稳能耗序列中的所有信息,因此难以获得最佳精度.叶瑞丽等[5]采用小波变换与Elman神经网络,基于信号处理技术的能耗组合预测模型,有效实现对能耗序列中不同特征信息的学习,进一步提高预测精度.但小波分解需依靠经验人为选择小波基函数,模型的适用范围有所限制.因此,本文融合信息处理和深度学习方法,开展机柜能耗序列特征提取、能耗预测建模、实验验证等研究,设计一种基于变分模态分解与粒子群优化的门控循环单元的能耗预测模型能耗组合预测模型,旨在实现对非平稳能耗信号的特征提取且有效提高模型的精度与通用性.
1 VMD特征提取
变分模态分解(variational modal decomposition,VMD)是一种自适应、非递归的信号分解算法,相比于经验模态分解(empirical mode decomposition,EMD),鲁棒性更好,能有效提取信号中粗略与精细信息且能避免模态混叠问题.云计算中心进行能耗建模的第一步是对能耗时间序列f进行VMD特征提取,提取到K个本征模态函数(intrinsic mode functions,IMF)uk,满足如下约束关系:
(1)
其中:{uk}代表分解后得到的所有固有模态函数;{ωk}为固有模态函数对应的中心频率;*为卷积运算.为求解{uk}的变分问题,引入二次惩罚因子、拉格朗日乘子将其转变为非约束问题;采用乘法算子交替方向法(alternating direction method of multipliers,ADMM)在频域上迭代更新{uk},直至求得的{uk}满足给定迭代收敛精度.
IMF的个数K在选取时,应遵循包含尽可能多地有效信息且应尽可能避免模态混叠问题的原则,在实际操作时,可通过观察法进行确定.当K取3~7时,对机柜A能耗序列进行特征提取,得到的IMF中心频率值如表1所示.由表1可知:当K<5时,信号中的精细信息将被过滤,VMD算法相当于滤波器的作用;当K>5时,信号中的精细信息虽被保留,但各个IMF中心频率过于接近,容易引起模态混叠;当K=5时,信号既保留了精细信息,中心频率距离也适中.因此,确定云计算中心能耗序列IMF的K值为5,既能解决模态混叠问题,也能为后续机器学习提供充分的信息.对机柜A能耗序列进行VMD算法分解获得的5个IMF分量如图1所示.

表1 K取不同值时IMF中心频率分布

图1 机柜A能耗数据VMD分解结果图
2 基于PSO优化的GRU神经网络模型
2.1 GRU神经网络
GRU(gated recurrent unit)神经网络,在结构上引进“更新门”和“重置门”的门控机制,有效避免循环神经网络中难以克服的梯度消失问题,且比长短时记忆网络(long short-term memory,LSTM)少1个门,模型在训练时的变量少,计算速度更快,甚至在某些场合效果比LSTM还要好.为此,本研究采用GRU神经网络建模,基于TensorFlow框架构建2层隐含层、1层输出层的预测模型.其中,超参数学习率α取0.001,训练批次取32,迭代次数取100.GRU神经网络隐含层节点数则通过PSO算法寻优,建立最优预测模型.
2.2 粒子群算法
粒子群算法(particle swarm optimization,PSO)广泛应用于函数寻优领域.该算法用粒子群模拟鸟群觅食行为,通过在d维空间搜索目标对粒子群的位置进行寻优.首先用一组随机生成的值初始化粒子群的位置和速度;然后通过迭代法根据粒子个体、群体与目标距离,按照一定算法更新粒子群的位置和速度,直到寻找到目标或达到迭代次数.此时,个体最优位置就是个体最优解,群体最优位置既是群体最优解,也是要寻找的最终目标.
粒子个体速度、位置更新满足
(2)
(3)

(4)
其中:ω为惯性权重;ωmax和ωmin分别表示惯性权重的最大值和最小值;k为当前迭代次数,kmax为最大迭代次数.
2.3 改进的PSO-GRU预测模型的建立

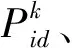
3 VMD-PSO-GRU能耗预测模型
经过上述VMD特征提取、PSO寻优GRU神经网络得到的VMD-PSO-GRU能耗组合预测模型框图如图2所示.首先,VMD-PSO-GRU模型采用VMD算法对机柜设备能耗序列进行特征提取,得到K个不同频率的IMF分量,所得IMF分量中心频率各不相同,有效解决模态混叠问题.其次,构建PSO-GRU预测模型对每一个IMF分量进行学习,自动寻优GRU隐含层节点数求得最优模型,有效解决GRU神经网络依靠人工经验进行反复试验的问题.最后,使用最优模型对每一个IMF分量进行预测并重构,以序列叠加方式得到最终的能耗预测结果.
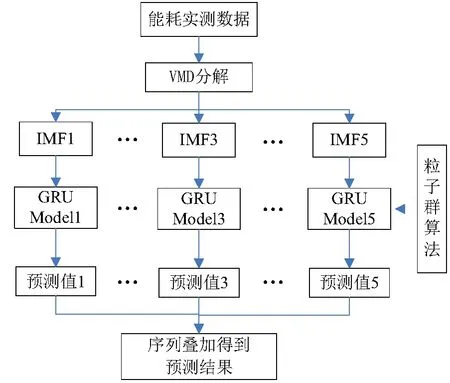
图2 VMD-PSO-GRU能耗组合预测模型框图
4 模型验证与结果分析
本研究在云计算中心机柜设备进行测试,验证VMD-PSO-GRU模型的通用性与精度.能耗序列取自机柜设备连续100 d内每小时的样本点,即每个机柜有2 400个样本点,分别采用GRU、PSO-GRU、VMD-PSO-GRU模型对机柜A、B能耗序列做提前1、2、3、24 h预测,从对比实验中验证模型通用性与预测精度.
4.1 模型误差指标
模型训练性能误差指标选择最小目标损失函数,即预测值与真实值的均方误差(root mean square error,RMSE),模型泛化性能误差指标选择平均绝对百分比误差(mean absolute percentage error,MAPE).RMSE、MAPE的计算公式为
(5)
(6)
两者计算得到的值越小,表明该模型进行能耗序列预测时的训练性能、泛化性能越好,预测精度越高.
4.2 机柜A、B能耗预测实验
对机柜A、B能耗序列分别采用GRU、PSO-GRU、VMD-PSO-GRU模型进行提前1、2、3、24 h预测,其中GRU模型中的节点数n0、n1均取较大值200.PSO-GRU、VMD-PSO-GRU模型的节点数通过PSO算法在1~200内自动寻优确定,计算得到的能耗预测误差指标如表2所示.
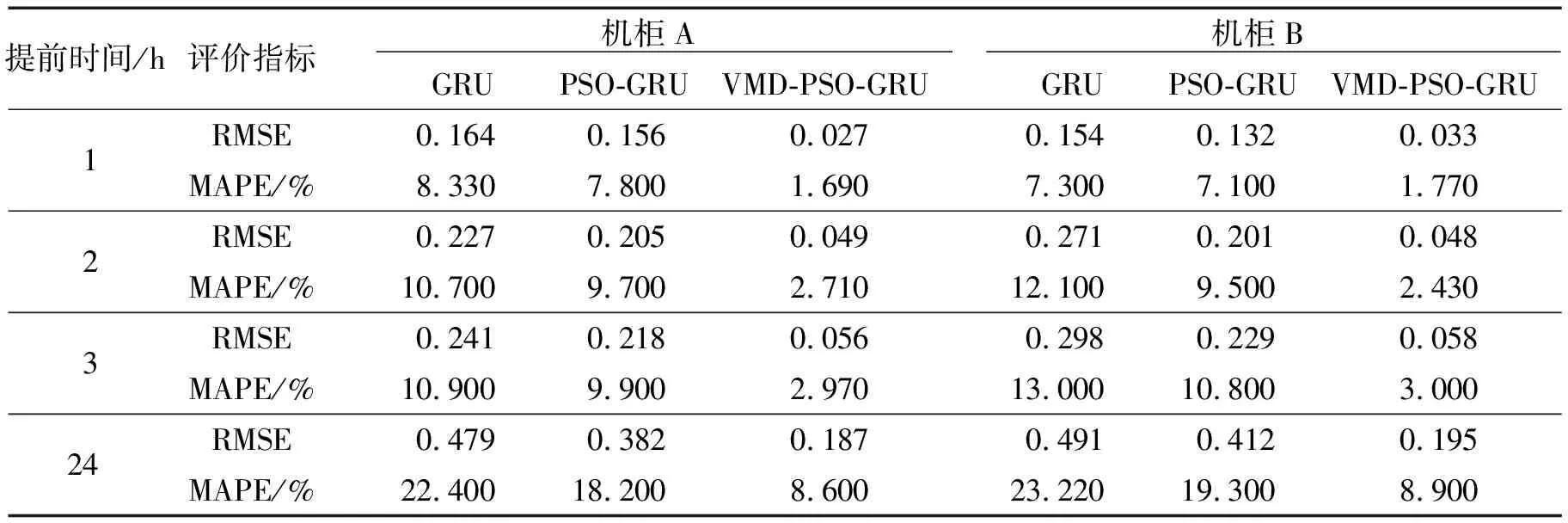
表2 能耗预测误差指标
因篇幅原因,仅列出机柜A的提前1、24 h能耗预测结果,分别如图3、4所示.从图3、4可以看出,相对于GRU、PSO-GRU模型,VMD-PSO-GRU神经网络组合预测模型在对机柜能耗序列进行预测时,能耗预测值曲线更加贴近实际值曲线,拟合度更高,能耗预测精度更好.
图3 各模型提前1 h预测机柜A能耗结果
分析表2中各模型能耗预测误差指标的具体值,可以得到如下几点结论:(1)采用单一的GRU神经网络模型对机柜A能耗序列进行预测时,随着预测步数增加,GRU模型预测精度大幅降低,从1 h的8.33%、2 h的10.7%到24 h的22.4%,这是由于GRU神经网络预测精度会随着能耗序列时间关联性减弱而显著降低.(2)采用PSO-GRU神经网络对机柜A进行能耗预测时,预测精度从1 h的7.8%降低到24 h的18.2%;当采用PSO对GRU的隐含层节点数进行寻优后,PSO-GRU模型预测精度相对于GRU有一定程度地改善,但还无法从根本上解决GRU无法学习到具有强随机性的能耗序列信息的问题.(3)采用本文提出的VMD-PSO-GRU模型对机柜A每一个IMF分量进行能耗预测,对应的神经网络节点数根据PSO寻优确定,并叠加得到能耗预测结果,得到的预测精度显著提高,提前1、2、3 h预测的精度在2.97%以内,24 h预测精度为8.96%.(4)对机柜B采用VMD-PSO-GRU模型进行能耗预测时,提前1、2、3 h的精度控制在3%内,24 h的精度也在9%内,表明模型具有良好的通用性能.实验结果表明,VMD-PSO-GRU神经网络组合预测模型,在采用VMD算法提取机柜能耗序列特征值的基础上,采用PSO算法优化GRU模型,能有效实现基于能耗序列特征的机器学习寻优,可显著提高模型预测的精度,且模型对全天24 h能耗预测通用性能好.
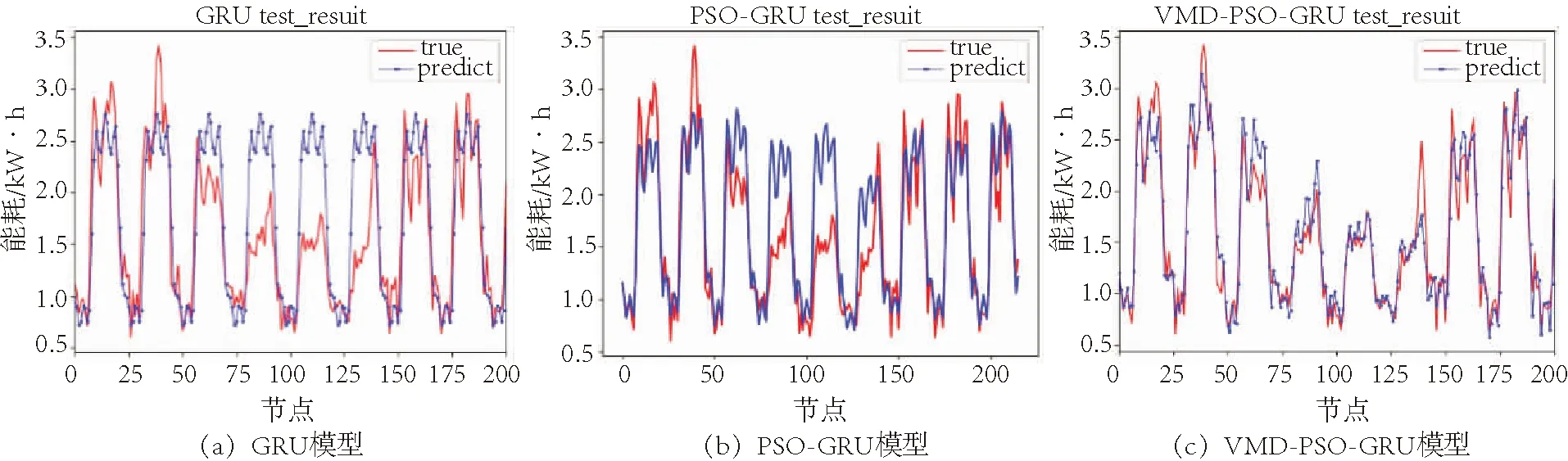
图4 各模型提前24 h预测机柜A能耗结果
5 结论
本研究针对云计算中心机柜设备能耗序列非平稳性、随机性强的特点,研究设计一种VMD-PSO-GRU能耗组合预测模型.在云计算中心进行机柜设备能耗预测实验结果表明,该模型不仅有效地解决了能耗序列非平稳问题、信号分解容易存在的模态混叠问题、GRU神经网络节点数依靠人工经验进行反复试验确定的问题,而且能耗预测精度高且通用性强.
