基于特征增维和近邻成分分析的民航发动机故障分类方法
2022-11-28孔祥兴刘凯伟莫李平王奕首卿新林
孔祥兴,刘凯伟,莫李平,王奕首,卿新林
(1.中国航空发动机研究院,北京 101304;2.厦门大学航空航天学院,厦门 361005)
0 引言
航空发动机结构复杂且长时间工作在高温高压等恶劣环境下,其安全性和稳定性问题一直备受关注[1]。数据表明,民用航空发动机的维修费用占航空公司整体运营支出的15%以上[2]。因此,开展航空发动机故障诊断研究对保证飞行安全、降低维护成本起着关键作用。
快速存取记录器(Quick Access Recorder,QAR)作为一种带保护装置的机载飞行数据记录设备,其记录数据可连续完整地反映飞机各系统在整个航程中的实际运行状况[3]。通过分析和挖掘QAR数据的隐含相关关系和知识,可以实现对发动机故障的诊断[4-5]。目前,从QAR等飞行数据中提取特征主要有主成分分析、线性判别分析以及卷积神经网络等方法。徐萌等[6]依据发动机制造商提供的故障报告选择4种关键气路参数,结合Stacking集成学习模型,实现了航空发动机典型气路故障的智能诊断;顾彬等[7]给出基于正交约束闭包球的最大间隔QAR数据特征提取方法,有效解决了QAR数据大样本特征提取问题;戴婧睿等[8]利用深度置信网络算法提取QAR数据中的特征,并与主成分分析法对比验证了其提取的特征对提高分类识别准确率的有效性;张鹏等[9]将卷积神经网络和长短时记忆网络通过注意力机制融合,使模型能同时表达QAR数据在空间维度和时间维度上的特征;Jiang等[10]提出了一种基于主成分分析和深度置信网络相结合的航空发动机气路故障诊断方法,并验证了该方法的有效性;Cui等[11]采用动态主成分分析算法对原始数据进行去噪、降维和消除相关性处理,并输入改进的支持向量机中进行发动机故障诊断;Cao等[12]利用单位向量、比值系数和相关系数对数据进行降维处理,以支持向量机为基本分类器建立了多分类AdaBoost算法。
目前发展的多种常用的特征选择方法均具有一定的局限性。例如基于神经网络方法提取的特征可解释性差,缺乏明确的物理意义;主成分分析算法作为线性的降维方法,其应用具有局限性,部分情况下得到特征并不是最优的。
本文基于常用的5种特征,结合特征增维方法和近邻成分分析算法,提出了一种最合适的特征提取方法,挖掘隐藏信息并剔除冗余特征,并利用朴素贝叶斯和决策树等分类算法验证该方法对提升算法准确度的有效性。
1 近邻成分分析算法
近邻成分分析算法(Neighbor component analysis,NCA)是一种非参数的特征优化方法。其通过构建包含正则项的目标函数,将最优特征组合的选取问题转换为求目标函数最小值的问题[13]。NCA在医疗检测、人脸识别、机械轴承故障诊断等研究方向上应用广泛[14-16]。以n个训练样本的情况进行说明,训练样本空间为

式中:xi∈Rp为特征向量,p为特征向量的维度;yi为特征向量所对应的标签。
NCA的具体实现步骤如下:
步骤1:设wr为特征的距离权重,定义距离函数dw

步骤2:设k为相似函数,定义样本x的参考样本为xj的概率为

这里NCA假设了x与xj的距离较小时,xj较大的概率作为x的参考样本。当xj是x的参考样本时,使用xj的标签yj作为x的标签。
步骤3:去除样本(xi,yi)后,计算xi的参考样本为xj的“去一概率”

步骤4:计算参考样本xj的标签与xi标签相同情况下的概率
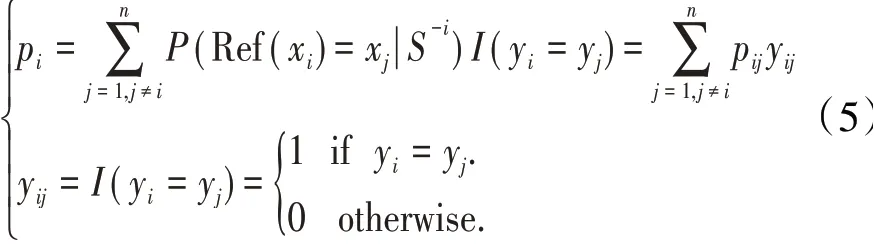
显然当pi的值越大时,说明样本之间的距离越小的情况,有更大的概率作为参考样本,即有更大的概率是同一类。
步骤5:计算所有样本的“去一概率”的平均值
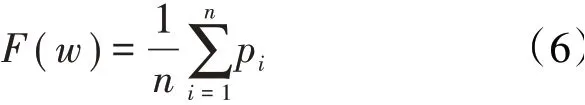
同时通过加入λ组成的正则项构造目标函数
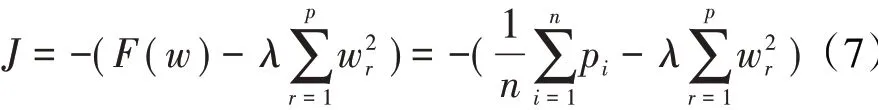
构造目标函数后,将特征选择的问题转换为求最小值问题

根据目标函数选择合适的正则系数得到各特征的权重值,筛选部分权重最大的特征作为最终特征。
2 QAR数据处理及特征提取
对原始QAR的处理过程主要分为数据预处理和特征提取2部分,具体流程如图1所示。

图1 原始QAR数据处理流程
2.1 QAR数据预处理
某航空公司提供的4台CFM56-7B发动机的QAR数据主要包括发动机、飞行控制、液压控制以及环境控制等4个系统的重要参数,如:计算空速CAS、马赫数Ma、飞行高度(Altitude,ALT)、燃油流量FF、低压涡轮转速N1、高 压 涡 轮 转 速N2、排气温度EGT等。
一方面,由于不同传感器采样频率不同导致传感器信号周期性缺失,因此根据发动机QAR数据的缺失值与附近值相似的特性,采用“最近邻填补”方法对所有的缺失值进行填补;另一方面,根据CAS、Ma、FF等参数按初步提取飞机巡航段规则(见表1)初步提取飞机巡航段数据,如图2中步骤1所示。

表1 初步提取飞机巡航段规则
步骤2,设置ALT的偏差不超过10feet提取到的巡航段数据如图2红色线段所示。依次判断所提取到的巡航段数据的跨度,选取跨度超过500cycle的第1个巡航段数据,随机取其中1个点的数据作为巡航点数据(图2中绿点)。

图2 数据预处理
2.2 特征提取
传统的民航飞机通常是使用△EGT、△N2和△FF这3个性能参数偏差作为特征,结合相应的诊断算法来进行发动机的故障诊断。由于实际的发动机故障种类较多,仅仅使用以上3个故障特征无法进行准确的故障诊断。因此,本文通过增加故障特征与故障特征优化的方法提高发动机故障诊断的精度。
根据航空公司提供的维修记录,选取水洗之后的一段时间内的QAR数据用于建立EGT、FF、N2、T3、T25这5个参数的基线模型[17-18]。本文采用多元线性的方法进行基线建模,选取N1,TAT,Ma和ALT作为自变量。在获取基线方程后,通过将测量值减去基线值得到性能参数偏差值。
特征增维是在已有特征的基础上,以提高故障诊断精度为目的增加故障特征的方法。对已有的故障特征做4种类型的特征增维,包括指数特征增维、对数特征增维、组合特征增维以及差分特征增维,具体的故障特征增维方法见表2,共有31个增维特征。

表2 故障特征增维方法
按照表中列出的先后顺序对31个特征编号,再采用近邻主成分分析的方法对特征进行特征优化,从中选取出最优的特征组合。构造目标函数与正则系数λ=Lambda关系,正则系数选取如图3所示。

图3 正则系数选取
从图中可见,当选取正则系数λ*=8.0091×10-5时(图中实心点),目标函数值最低,此时各特征的权重值如图4所示。
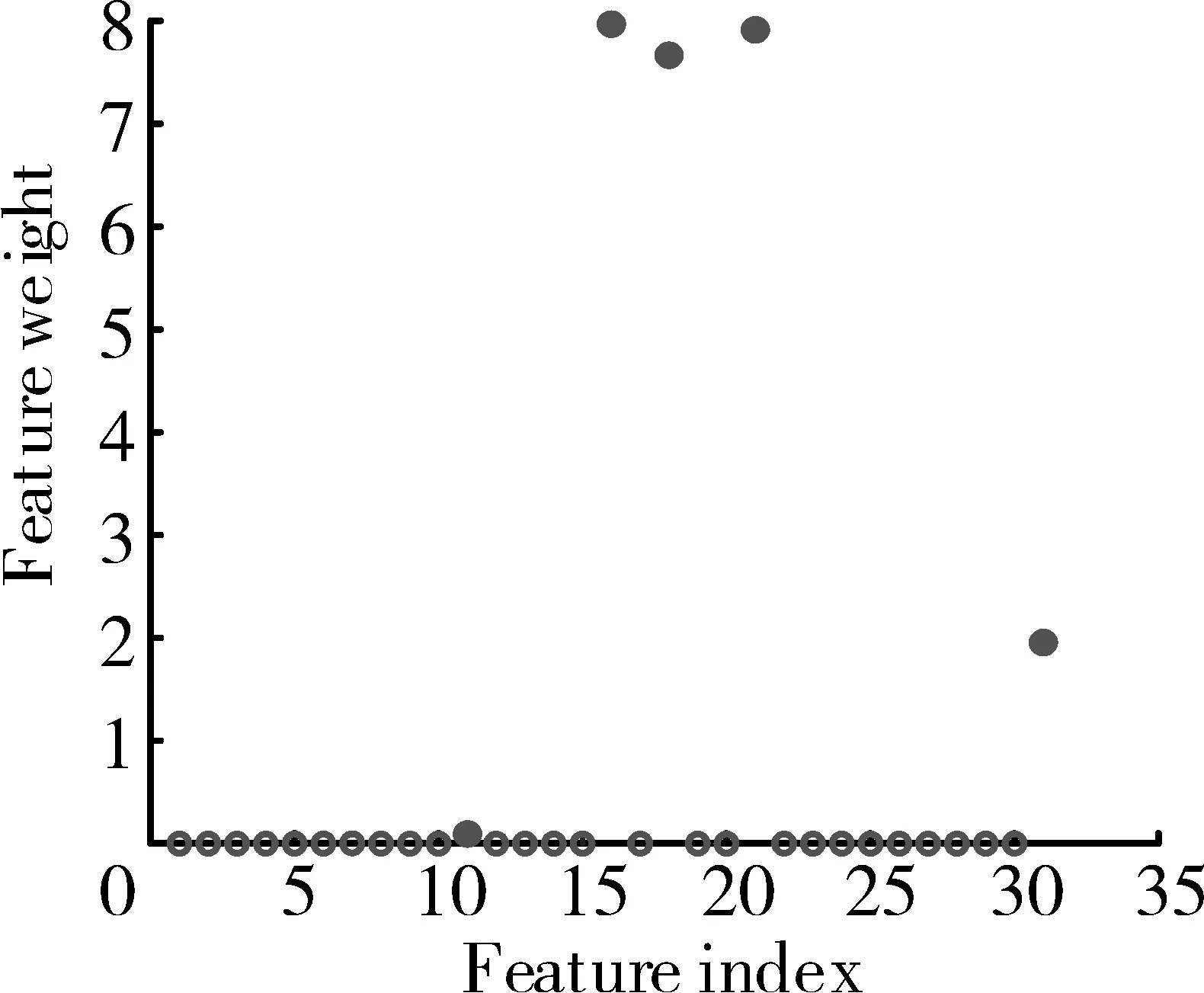
图4 不同特征的特征权重值
从图4中选取权重最大的5个特征(图中实心点),分别为第11个特征△N22、第16个特征log(△N2+C2)、第18个特征log(△EGT+C3)、第21个特征diff(△EGT)和第31个特征△EGT/△T25。结合5个原始性能参数偏差作为最终特征。NCA特征保留结果见表3。

表3 NCA特征保留结果
3 结果与讨论
在特征增维与优化的基础上,利用常见的几种分类算法实现故障诊断,并对比了特征优化前后对分类算法结果的影响。
3.1 样本提取与处理
由于故障样本有限,本文当前涉及3种常见的故障类型,包括发动机叶片积垢、鸟撞、VSV作动筒工作故障。根据维修记录,选择维修当天航段及前20个航段构造故障样本数据集,如图5所示。
图5 故障样本数据集构造
所得样本数量分布见表4。

表4 样本数量分布
从表中可见,故障样本的数量远小于健康样本的数量,由于正负样本数量不均衡的现象会导致算法倾向于诊断出拥有较多样本的状态结果,且影响模型的泛化性与准确性,因此采用重复采样的方法对少数的样本进行扩充,从而达到样本均衡的目的,并采用Zscore方法对均衡后的样本进行归一化处理。
3.2 近邻成分分析算法验证
利用高斯朴素贝叶斯、二次判别、提升树、高斯支持向量机、共4种算法验证该特征提取方法对分类结果的提升程度。为防止模型产生过拟合,采用5折交叉验证的方法对模型进行验证。分别对比仅使用5个原始特征、使用原始特征加所有增维特征共36个特征、使用原始特征加NCA算法提取后的增维特征共10个特征用于训练和构造模型的结果,如图6所示。

图6 选择不同维度的特征分类结果
从图中可见,相比只利用5个维度的特征去训练模型,5个原始特征加31个增维特征对分类算法准确率的提升效果不明显,特别在二次判别算法上算法准确率反而降低,而5个原始特征加上NCA算法提取的5个增维特征总体上对分类算法的准确率有明显提高,在二次判别和提升树算法上尤为明显,特别是在提升树算法准确率的提升达到15.1%。
利用不同维度的特征训练和测试算法的运行时间见表5。从表中可见,采用特征增维方法增加了特征的维度后,算法的训练时间相应延长,在大部分情况下利用36个特征构建算法模型所花费的运行时间最长,而采用NCA算法降低增维特征的维度后,可以显著缩短算法的运行时间。

表5 利用不同维度的特征训练和测试算法的运行 s
通过特征增维方法构建新的特征,再利用近邻成分分析算法从中提取最优特征的方法,一方面,相比仅使用原始特征构建模型,能明显提高模型的准确率;另一方面,相比只使用特征增维的方法,运算量大大减小,大幅缩短了运行时间,且具有更高的准确率。
4 结论
(1)对于数据驱动的诊断方法,不同的算法对于诊断准确率影响较大,诊断准确率最高相差达40%,其中基于高斯核支持向量机算法的诊断准确率达到83%;
(2)采用△EGT、△N2、△FF、△T3、△T25参数偏移量增维特征进行故障诊断能够显著提升诊断准确率,相较于5个特征参数偏移量的诊断精度最高提升了15.1%;
(3)采用近邻成分分析算法通过主元分析实现故障特征参数向量的降维和优化,有利于提高诊断准确
率和计算效率。
