抗乳腺癌活性化合物的ADMET 性质预测模型
2022-11-28秦雅琴夏玉兰卢梦媛王锦锐谢济铭
秦雅琴,夏玉兰,卢梦媛,王锦锐,谢济铭
(昆明理工大学 交通工程学院,云南 昆明 650500)
在抗乳腺癌药物的研发过程中,由于某些化合物的一些药代动力学性质(ADMET)无法被预见,即药物的吸收(Absorption)、分配(Distribution)、代谢(Metabolism)、排泄(Excretion)、和毒性(Toxicity),可能会降低药物研发效率,造成大量的资源浪费[1-2].而常规的生物试验方法常常代价高昂且耗时长[3-4],随着药物信息学技术及数据挖掘技术的不断发展,利用累积的药物实验数据进行ADMET性质建模可快速对批量化合物进行处理和预测[5].
机器学习因其能有效捕获非线性数据的内在规律,从复杂的ADMET 数据中学习化学结构与药效学的关联,成为药物化学领域用来解决复杂化合物性质预测问题的一个重要方法[6-7].Chi等[5]使用支持向量回归方法(Support Vector Regression,SVR)解决了药物吸收预测时输入和输出之间的非线性问题.李晓等[8]针对人体小肠吸收、血脑屏障透过等多个ADMET 相关的性质,使用支持向量机(Support Vector Machine,SVM)分别建立适用于小分子化合物的预测模型.但SVM 对参数调节和和函数的选择相当敏感,极易影响预测精度.莫贤炜等[9]对苯基哌嗪类5-HT7受体拮抗剂进行三维定量构效关系(Quantitative Structure-Activity Relationship,QSAR)分析及ADMET 相关性质的预测,用于受体拮抗药物的预测与筛选.Tsou等[10]将深度神经网络(Deep Neural Networks,DNN)用于三阴性乳腺癌(Triple-Negative Breast Cancer,TNBC)抑制剂药物的虚拟筛选,由于DNN 结构里下层神经元和所有上层神经元都能够形成连接,若调参不当,易导致参数数量膨胀.Feinberg等[11]利用包含多个图卷积层的图卷积神经网络学习每个化合物分子式的图示化特征向量,并应用于ADMET 性质预测,取得了较好的准确性.Dahl等[12]使用分子描述符和药效团指纹作为分子特征,训练并构建了基于随机森林(Random Forest,RF)和逻辑回归(Logistic Regression,LR)的ADMET 预测模型.Dong等[13]利用多个数据库得到的海量化合物数据,分别构建了基于朴素贝叶斯(Naïve Bayes,NB)和决策树(Decision Tree,DT)的预测模型,结果表明,在面对多分类任务或数据特征缺失时,NB 模型能够表现出良好的鲁棒性.以上研究多使用较为经典的机器学习模型,其模型结构可以继续优化以更加适应化合物的ADMET 属性预测任务.
基于此,本文从数据样本与特征约束条件出发,构建基于LR、NB、GBDT 模型的ADMET 性质预测模型,并挑选出最优模型GBDT.同时考虑上述经典模型中超参数设置对预测精度、调参时间等的影响,提出改进最优模型GBDT*.经对比验证,发现超参数调优算法可有效发挥分类GBDT*模型最优性能,研究成果有助于抗乳腺癌候选药物的ADMET 性质预测.
1 ADMET 性质预测模型的设计
针对抗乳腺癌活性化合物的ADMET 性质预测问题,需收集一系列作用于乳腺癌治疗靶标的化合物数据,然后以化合物的诸多分子结构描述符作为输入变量,选取ADMET 性质中表征人体对化合物渗透吸收能力的Caco-2 性质、表征化合物在人体内的代谢能力的CYP3A4 性质、表征化合物对心脏毒副作用的hERG 性质进行建模,并定义化合物各性质的表现程度为二分类变量,例如‘Caco-2=1’代表小肠上皮细胞对该化合物具有较好的渗透吸收能力,‘Caco-2=0’代表小肠上皮细胞对该化合物渗透吸收能力较差;‘CYP3A4=1’代表人体对该化合物具有代谢能力,‘CYP3A4=0’代表对该化合物无代谢能力;‘hERG=1’代表该化合物具有心脏毒性,‘hERG=0’代表该化合物无心脏毒性.基于此,构建基于逻辑回归和机器学习方法的化合物ADMET 预测模型,筛选出最优模型,并采用超参数调优的方法对优选模型进行优化处理,作为最终的ADMET 性质分类预测模型,进行抗乳腺癌活性化合物的ADMET 性质预测.模型框架如图1 所示.

图1 ADMET 性质预测模型框架Fig.1 A predictive modelling framework for the nature of ADMET
2 ADMET 性质预测模型
将降维处理后的N个化合物分子描述符数据作为分类器的输入,以实现ADMET 性质判别.

逻辑回归(Logistic Regression,LR)[14]作为一种基于二项分类的回归分析模型,通过在线性回归的基础上增加一个Sigmoid 函数映射,实现对定性变量的有效预测.朴素贝叶斯(Naïve Bayes,NB)[15]通过给定独立的目标值属性之间的相互条件,假定模型的变量遵循某种概率分布,对样本数据集进行分类.两者均具有形式简单、性能稳定、鲁棒性强等优点,广泛应用于文本分类、入侵检测、故障诊断等领域[16].随着深度学习在模式识别中的广泛应用,梯度提升决策树(Gradient Boosting Decision Tree,GBDT)[17]基于梯度提升学习策略,对决策树中的回归树的迭代优化,寻找最佳划分特征,进而学习样本路径实现分类,是近年来一种模型复杂度较高、参数随机性较强的学习器.因此,本文选取LR 模型、NB 模型及GBDT 模型进行ADMET 性质分类预测模型的构建.
此外,由于上述经典模型中人工设置超参数(如学习速率、层数以及每层的神经元数等参数)对预测性能的影响较大,训练时间较长[18].为使算法获得最优性能,采用概率代理模型拟合超参数x与预测精度y之间的关系(即黑箱模型),再通过采集函数扩大数据集D={(x1,y1),(x2,y2),(x3,y3),···,(xn,yn)}的规模,更新代理模型的后验分布,直到后验分布基本贴合于真实分布,从而筛选出优选模型的最优超参数,能有效地搜索可能的超参数空间,提升模型的训练速度.
3 实验及结果分析
3.1 数据处理实验数据来源于公开数据集“2021 年中国研究生数学建模竞赛”.数据集包含:①分子描述符:1 974 个化合物的729 个分子描述符信息,分子描述符是一系列用于描述化合物的结构和性质特征的参数,包括物理化学性质与拓扑结构特征等;② ADMET 性质:1 974 个化合物的ADMET 性质(Caco-2、CYP3A4、hERG)的数据,该性质可表征候选药物在人体内是否具备良好的药代动力学性质.
根据以往的研究可知,该数据集化合物样本量较小(1 974 个化合物),分子描述符(729 个特征变量)特征冗余,具有有效特征不明显、难以直接预测应用等特点[19].首先通过描述性统计分析,剔除原始数据中的“0”值样本,如表1 所示;然后为客观评价模型性能,避免模型忽略不同量纲指标的潜在信息,利用多重共线性诊断[20]、极值归一化处理等方法,对数据做深层次的处理分析;最后从729 个分子描述符中,遴选出对ADMET 性质具有影响的319 个特征变量,为构建化合物的ADMET 性质预测模型提供有效的数据基础.

表1 描述性统计分析结果示例Tab.1 Example of descriptive statistical analysis results
3.2 模型预测结果分析为降低由于数据样本量受限导致的预测偶然性,提高模型泛化能力及数据使用率,采用小型数据集适用的k折交叉验证方法对各预测模型验证.本文通过将数据集划分为5折,即将样本集分为5份,每次选择1 份样本集用于验证,将剩余的4 份样本集用于测试.
3.2.1 Caco-2 性质预测结果 ADMET 性质中Caco-2 性质预测混淆矩阵如图2 所示.结合表2 可以发现,NB 模型对Caco-2 性质的预测效果在准确率(Accuracy,评价总体预测效果)、精准率(Precision,反映预测的精确性)、灵敏度(True Positive Rate,TPR)、误报率(False Positive Rate,FPR)方面表现最差,而GBDT 模型优于LR 和NB 模型.

表2 模型指标对比(Caco-2)Tab.2 Comparison of model indicators (Caco-2)

图2 Caco-2 性质各预测模型混淆矩阵Fig.2 Confusion matrix of each prediction model of Caco-2
具体来看,GBDT 模型相比LR 模型在准确率、精准率、灵敏度、误报率方面依次提升了3.9%、5.8%、3.3%、4.2%;GBDT 模型相比NB 模型在准确率、精准率、误报率方面则依次提升了11.7%、20.5%、22.3%,灵敏度虽然下降了5.4%,但也达到了85%以上,同时与精准率保持均衡,表明GBDT模型对ADMET 性质中的Caco-2 性质的预测精度良好,优选模型即基于GBDT 的ADMET 性质预测模型.对其进行超参数优化过后,基于GBDT*的ADMET 性质预测模型的准确率达到91.2%.其相比基准GBDT 模型在准确率、精准率、灵敏度、误报率方面则依次提升了1.3%、2.6%、0.4%、1.9%.GBDT*模型准确率的进一步上升,验证了本文超参数优化方法的有效性.同时也说明GBDT*更适用于ADMET 性质的预测问题.
考虑到ADMET 性质预测问题中样本数据数量不平衡会对模型的预测效果产生影响,而工作特性曲线(Receiver Operating Characteristic curve,ROC)能够综合客观衡量模型本身整体性能,具有避免不同测试集带来的干扰,不受样本不均影响等特点.因此,为客观反映模型的预测性能,选取ROC 作为ADMET 性质预测效果的进一步评价指标.在显著性水平为0.05 的情况下,计算ROC 曲线下面积(Area Under Curve,AUC),研究所构建的预测模型是否适用于ADMET 不同性质的判别.
从图3 可以看出,在对Caco-2 性质进行预测时,基于GBDT 的ADMET 预测模型AUC 最大(AUC=0.96).相比LR 和NB 算法的预测模型,GBDT模型AUC 指标分别提高了0.10 和0.11.再次说明在对分子描述符数据进行统一清洗处理的条件下,基于GBDT 算法构建的ADMET 性质预测模型对Caco-2 性质具有较好的预测能力.同时也说明基于GBDT 的ADMET 预测模型更适合处理低维非线性分析描述符数据,对其进行超参数优化后,GBDT*与GBDT 模型的AUC 指标虽相差不大,但准确率、精准率、灵敏度、误报率均有效提升.总体来看,基于GBDT*算法构建的ADMET 性质预测模型能有效提升预测精度,具有应用于ADMET性质预测的潜力.

图3 Caco-2 性质各预测模型ROC 曲线Fig.3 ROC curves of each prediction model of Caco-2
3.2.2 CYP3A4 性质预测结果 CYP3A4 结果与Caco-2 类似,如表3 所示.具体表现为:与基于LR的ADMET 性质预测模型相比,GBDT 在准确率、精准率、灵敏度、误报率方面分别提升了3.2%、0.4%、4.2%、0.6%;与基于NB 的ADMET 性质预测模型相比,GBDT 模型在精准率和误报率方面较弱,这是因为原始数据集中CYP3A4 样本类别不均衡,无代谢能力的样本(CYP3A4=0)占有代谢能力的样本(CYP3A4=1)的35%,导致模型对无代谢能力的样本(CYP3A4=0)判断不准确;但在模型总体预测效果方面,GBDT 模型的准确率较NB 模型提升了5.8%,AUC 综合评估指标提升了0.07,并且精准率和灵敏度也得到了兼顾.因此,从全局考虑,仍选用GBDT 模型作为优选模型,进行ADMET 性质预测,在对其进行超参数优化过后,GBDT*与GBDT 各评价指标相差不大,但有效缩减了基于GBDT 的ADMET 性质预测模型的训练时间.

表3 模型指标对比(CYP3A4)Tab.3 Comparison of model indicators (CYP3A4)
3.2.3 hERG 性质预测结果 hERG 性质判别结果也与上述类似,如表4 所示.在hERG 性质预测过程中,集成学习方法GBDT 相较于LR 模型与NB 模型在准确率、精准率等方面均取得了最佳的预测结果,成为优选模型.且GBDT*较GBDT 在准确率、精准率、灵敏度、误报率方面提升了0.9%、1%、0.5%、1.4%;在AUC 综合评价指标方面提升了0.01,体现出基于GBDT*的ADMET 预测模型的优越性.

表4 模型指标对比(hERG)Tab.4 Comparison of model indicators (hERG)
3.2.4 ADMET 性质的特征筛选 基于模型精度分析,选择优选模型GBDT 预测模型探究不同特征变量对各ADMET 性质的影响,采用经验阈值法(特征权重大于0.015 的变量)筛选出显著变量.按重要性百分比从大到小依次排序,结果如图4 所示.三类性质的特征变量在权重数值层面较为集中分布于某一种或几种变量上.例如Caco-2 特征重要性指标中,大于0.015 的指标有8项,其中ECCEN 特征对Caco-2 性质起到绝对控制作用,占比50.30%.CYP3A4 各特征重要性指标中,VP-7、Zagreb、SP-6 是对CYP3A4 影响程度较大的变量,分别占比27.00%、13.97%、10.97%.hERG 各特征重要性指标中,ECCEN 是影响hERG 预测的关键特征变量,占比31.40%.

图4 ADMET 性质的特征重要性Fig.4 Characteristic importance of ADMET
可见,ADMET 性质受不同特征因素影响差异大,导致其预测效果的随机性.传统的最优权重阈值方法只能筛选出ADMET 性质的明显特征,而难以确定最有效的特征变量.因此,本文采用概率代理模型拟合超参数与预测精度之间的关系(即黑箱模型),及时调整模型最佳超参数,获取有效特征因子,以适应各性质的预测需求.
3.3 GBDT*模型优化效果分析为进一步验证本文GBDT*算法的优势,设置GBDT*模型最大迭代次数为30次,参数调整范围为:树的数量为(0,1 200),学习率为(0,1),最大特征数为(0,100),经超参数自动寻优后,输出结果如表5 所示.同时找到适合Caco-2、CYP3A4、hERG 预测的有效特征数分别为49、14、36 个.调参可视化过程如图5 所示,可以看出,GBDT*对Caco-2 性质和hERG 性质预测模型的优化效果显著,对CYP3A4 性质预测模型的优化效果稍弱,可能是数据样本量太小、有效特征不明显所致.总的来说,GBDT*模型能够针对不同输入及时调整所需超参数,提升模型快速找到不同ADMET 性质的有用特征,有效改善数据特征不明显、维度过高导致特征冗余等情况,提升模型训练的效率.

图5 GBDT*模型超参数优化过程可视化Fig.5 Visualization of hyperparaments optimization process for GBDT* model
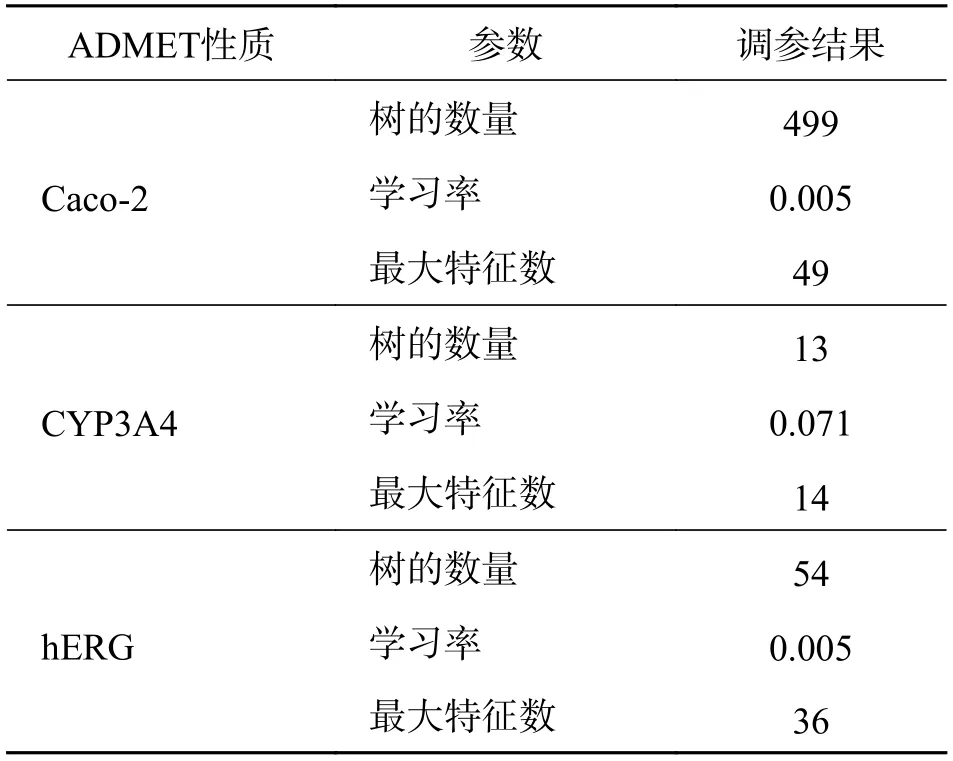
表5 GBDT*调参结果Tab.5 Hyperparameters tuning results of GBDT*
4 结论
本文以抗乳腺癌活性化合物的ADMET 性质中的吸收、代谢、毒性属性的分类预测为研究方向,提出基于GBDT*算法的ADMET 性质预测方法.然后对抗乳腺癌活性化合物的物理化学性质、拓扑结构特征等数据进行清洗处理,获取丰富的状态信息,选取LR、NB、GBDT 作为ADMET 分类预测的候选模型,针对经典算法训练成本较高的问题,对GBDT 模型进行超参数寻优,提出ADMET 性质分类预测模型为最优模型GBDT*,有效改善浅层机器学习调参时间久、局部最小化以及过拟合等缺陷,能更好地根据小样本、多特征条件下分子描述符变量对ADMET 性质进行预测,有助于抗乳腺癌候选药物的虚拟筛选研究.本文在预测时仅以分子描述符特征作为自变量,未来将综合考虑各类因素,建立更加通用且稳定的ADMET 性质预测模型.
