基于多尺度密集连接网络的矿物图像智能识别
2022-11-28杨彪马亦骥倪瑞璞苏森涛曾德明
杨彪,马亦骥,倪瑞璞,苏森涛,曾德明
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500;3.昆明理工大学 非常规冶金教育部重点实验室,云南 昆明 650093)
在矿物的勘探过程中,快速、准确地对矿产资源进行识别,判明其品质和储量,决定开采规模具有重大意义[1-2].矿物肉眼鉴定是地质研究者所必须熟练掌握的基本技能,因为肉眼鉴别可以初步估计出矿物的种或族,由此决定选用什么方法进行精确的鉴定和研究.但这种方法受限于鉴别者主观经验,鉴别准确性不高[3],如果选用方法不当,也会对后续研究会造成困难.
随着机器学习技术的发展,采用模型判定矿物种属的方法逐渐成为多数学者采用的方法.Baykan等[4]采用人工神经网络(Artificial Neural Network,ANN)对5 种显微镜下薄片图像进行分类,证明了RGB 这一颜色空间是矿物识别最佳色彩空间,但由于不同族的矿物其颜色特征可能相似,所以此方法还不能作为判别矿物种属的依据.与此同时,Singh等[5]采用多层感知机(Multi-Layer Perceptron,MLP)进行岩石纹理识别,通过从不同玄武岩提取的数值参数作为输入,以岩体纹理类别作为输出,相比单一颜色特征作为区分不同种矿物,此方法准确率较高,但需要人工从众多矿岩数值中进行筛选,计算预处理过程较为繁琐,不利于实际工程应用.Chauhan等[6]等通过使用7 种机器学习方法对岩心断层图像进行分割,比较了各个方法的优劣性,找到了适用于矿物图像分割的机器学习算法.受此启发,Baklanova等[7]使用K-means 聚类算法对显微镜下拍摄的矿物图像定性评估其组成成分.贺金鑫等[8]使用朴素贝叶斯分类模型对高光谱矿物图像进行识别.但这些方法分析既耗时准确率又不高.之后刘珏先等[9]针对岩石薄片成分分析耗时且准确率不高问题,提出基于协同表示的多特征融合岩石分类法,识别速度得到了极大的提升,但仍未解决需要人工筛矿物特征这一问题.近十年来,围绕着计算机视觉技术开展的研究工作取得了傲人的成绩,尤其是卷积神经网络解决了传统机器学习需要人工筛选特征问题,许多学者开始采用此技术解决矿物识别的问题.程国建等[10]通过搭建浅层卷积神经网络,对3 类岩石薄片进行自动分类取得了98%的准确率;白林等[11]基于VGG19 网络,对6 种常见岩石薄片进行分类取得了82%的准确率;郭艳军等[12]以ResNet 作为框架,对5 种偏光显微镜下矿物进行鉴别取得了89%的准确率;徐述腾等[13]基于U-net 网络对5 种硫化矿物的显微镜下图像进行识别,取得了90%的准确率.采用卷积神经网络彻底解决了人工筛选矿物特征的问题,但是早期卷积神经网络所需训练数据较为庞大,同时对计算机运算能力也有一定要求,而且目前针对实验环境下矿物识别研究较多,而针对野外环境下矿物识别过程研究较少.之后也有学者针对这些问题进行了优化和研究.张野等[14]运用迁移学习的方法对3 类矿岩图像进行分类取,得了85%的准确率,运用迁移学习方法可以很好地弥补由于数据集不足造成卷积神经网络欠拟合问题,但在迁移学习之前网络仍需在样本充足的数据集上进行充分训练,该数据集与矿物关联性的强弱会影响最终的识别准确率.彭伟航等[15]通过改进InceptionV3 网络和损失函数,对16 种矿物直接图像进行识别取得了86%的准确率.采用Inception 结构对矿物图像进行多尺度采样可以充分提取到矿物特征,但由于传统Inception结构每一层都是特别设计的并且伴随着较大的参数量,造成部署较为困难,而且采集到多尺度特征信息并不能充分利用,使得网络性能并不能充分发挥.李明超等[16]利用模型集成的方法,通过耦合颜色和纹理特征的方法,对19 类矿物图像实现自动辨别,但计算复杂度仍然较高.
针对上述问题,本文以直接获取的矿物图像作为研究对象,选用兼具低参数量和特征复用功能的DenseNet[17]为主干网络,同时结合前人所提聚合变换[18]思想,设计了一种多尺度密集连接网络(Multi-Scale Densely connected convolutional Network,MS-DenseNet)作为矿物识别模型,并以分组卷积策略对多尺度结构进行参数优化减少参数量.通过与典型网络在测试集上进行横向对比,实验结果表明本文所提网络在参数量和准确率方面都有较大优势.
1 面向矿物识别的智能算法
1.1 密集连接结构密集连接网络(DenseNet)是Huang等[17]于2017 年提出一种网络模型.相比之前从深度和宽度角度提升网络性能,DenseNet 采用特征复用的方式对网络性能进行提升.通过将上层特征提取器与下层特征提取器进行特征信息交互,将各自提取到的特征在通道维度进行拼接,丰富下层网络输入特征的多样性,同时减少信息损失.密集连接方式让特征信息和梯度信息传递更加高效,对特征信息的挖掘更加充分,非常适用于样本数较少的数据集.故本文选取DenseNet 中的密集连接结构作为矿物识别的主干结构,密集连接结构如图1 所示.

图1 密集连接结构示意图Fig.1 Schematic diagram of dense connection structure
1.2 多尺度特征提取结构由于DenseNet 所有下层的网络层与上层输出的有一定关联,上层网络提取到信息量多少对后续网络层有着一定影响.而在卷积神经网络中,浅层网络提取的特征和输入比较接近,如果只使用小卷积将会忽视掉一些全局信息,造成后续可用于分类的信息较少,所以要让靠前的网络层具有不同尺度的特征获取能力.此外,对于非公共数据集而言样本数少是其显著特点,采用多尺度卷积结构在一定程度可以弥补这一不足.因此,本文在DenseNet 基础上引入了Inception[18-19]结构,如图2 所示,并对传统Inception 结构进行了参数优化,解除传统Inception 结构存在针对性设计、参数量大等不足的问题.

图2 传统Inception 结构Fig.2 The structure of classic Inception
首先,为了降低传统结构的计算复杂度同时又不损失其特征获取能力,采用大小为1×1 的分组卷积对特征通道进行减半压缩,一方面可以起到线性修正的作用,方便后续特征融合;另一方面,防止参数量过大造成过拟合.
采用分组卷积,可以以较少的参数获得与传统卷积运算得到一样的特征图.采用传统卷积其参数量计算公式为:

式中,p为参数量,k为卷结核大小,c1为输入特征图维度,c2为输出特征图维度.
而采用分卷卷积其参数量计算公式为:

式中,g为分组数.
由公式(1)和(2)可知,传统卷积参数量是分组卷积的g倍.使用分组卷积消耗的计算内存更少,计算复杂度也将降低,会使网络的推理速度得到加强.
然后,将分组卷积接入3 分支结构.分支1 是一组3×3 卷积;分支2 是两组3×3 卷积,用两组3×3 卷积替代一组5×5 大尺度卷积;分支3 是直连结构.同时,引入一条最大池化分支,对上层特征图进行局部特征提取,并将该分支与3 卷积分支在通道维度进行拼接,构成一个多尺度特征提取模块.
不同的卷积核所提取到的特征存在差异,其中大尺寸卷积核有助于捕获全局信息,同一点所包含语义信息也较为丰富;小尺寸卷积核有助于获取细节信息,最大池化层则更加关注特征图的局部信息.将不同分支获得的信息进行融合,根据各自所得权重自适应地处理特征信息.使网络在无需构建较深的情况下,也能得到丰富的特征信息,这些信息增强了网络的鲁棒性,提升了网络性能,改进后的多尺度特征提取结构如图3 所示.
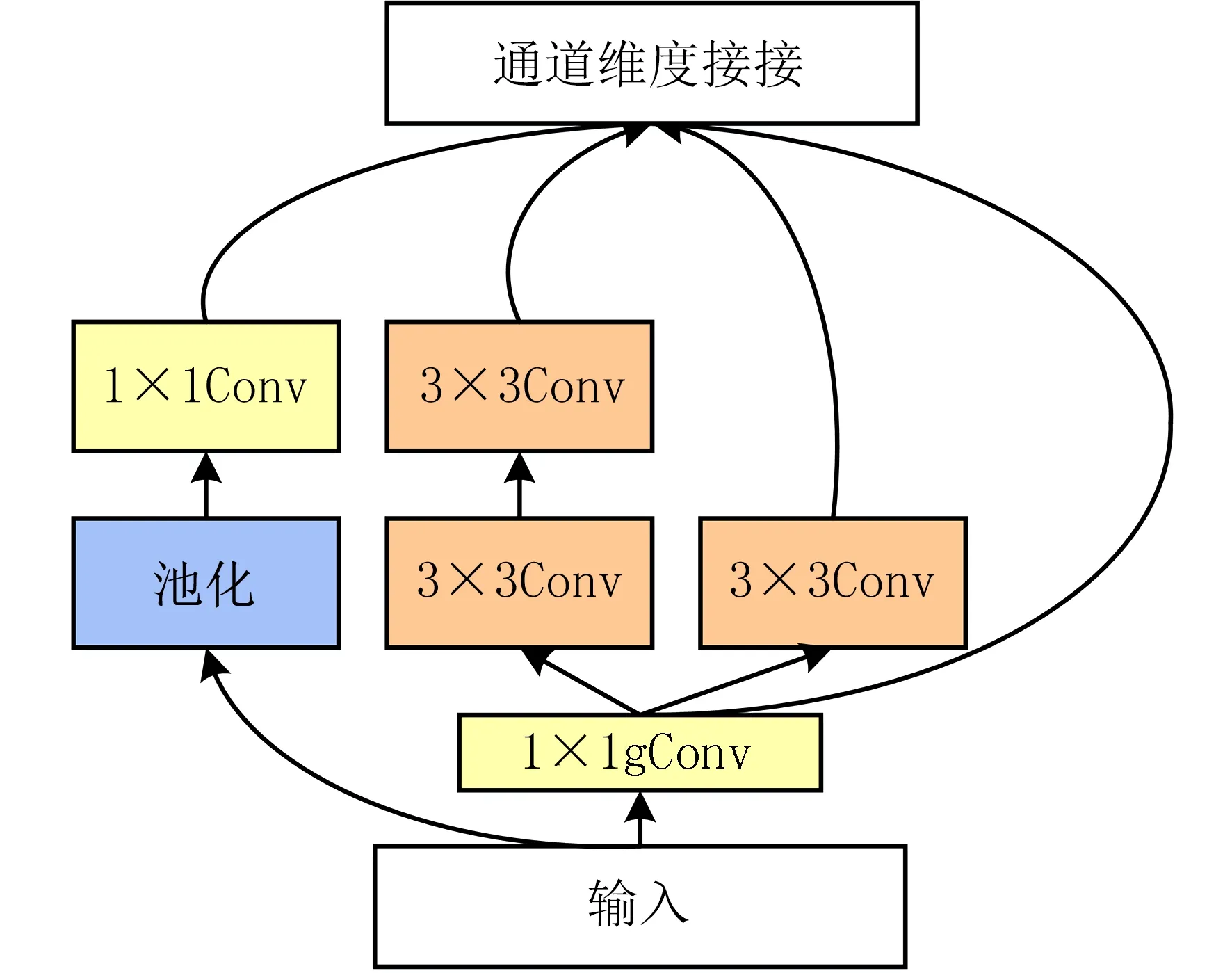
图3 优化后的Inception 结构Fig.3 The structure of improved Inception
融合后的特征计算公式为:

式中,finput为输入特征,c为融合后的特征,wi(i=1,2,3,4)为 特征权重值,gConv1×1为1×1 分组卷积,Conv3×3为3×3 卷积,Conv1×1为1×1 普通卷积,max()为区域最大值函数.
1.3 跳跃结构输入网络经过多次下采样操作后,虽然压缩了特征图的尺寸,便于后续分类,但是在压缩过程中造成一些信息的丢失.对于浅层网络层因为靠近输入图像层,这种影响非常小.而对于深层的网络层这种影响较为严重,可能会影响最终分类效果.所以,为了减少这一损失,本文在密集连接模块后的网络层引入跳跃结构,以减小特征信息损失.
1.4 总体结构本文网络结构如图4 所示,表1给出了每个网络层的具体信息.

表1 MS-DenseNet 参数信息Tab.1 The parameter information of MS-DenseNet

图4 MS-DenseNet 结构示意图Fig.4 The structure diagram of MS-DenseNet
MS-DenseNet 运算步骤如下:
步骤 1读入图像,使用7×7 卷积对原始图像进行特征预提取,并使用批标准化层进行归一化处理,使用ReLU 激活函数进行激活,使用最大池化层将特征图压缩.
步骤 2将步骤1 得到的特征图输入进分组卷积并在每层第一层使用批标准化层进行归一化处理,使用ReLU 激活函数进行激活,送入三卷积分支和最大池化支路,并行进行特征提取操作.将各支路获取的信息进行融合.在以平均池化操作整合全局空间信息,并进一步缩减特征图尺寸.
步骤 3对步骤2 得到的特征,进行密集卷积运算挖掘粗粒度信息,以平均池化压缩特征图尺寸.
步骤 4将步骤3 得到特征图输入带有跳跃连接的卷积层,进行卷积运算.并将运算后的特征送入全连接层,使用softmax 激活函数计算各类型矿物的概率.
2 实验与结果分析
2.1 实验数据及平台矿物识别图像数据集中所有数据来源于互联网中最大的矿产资源数据库平台Mindat.org,使用爬虫方法收集到的6 类矿物图像,合计5 695张,各类矿物分布如表2 所示.选取数据集的80%作为训练集,10%作为验证集,10%作为测试集.并对训练集进行随机上下翻转、随机左右翻转等数据增强操作扩充训练集,实验电脑配置为:AMD Ryzen 7 4800H 2.90 GHz 处理器,NVIDIA GeForce RTX 1650 显卡,使用Python 语言和Tensorflow2.3 深度学习平台进行网络训练.

表2 各类矿物数据统计Tab.2 Statistics of various minerals
2.2 实验设置在图像输入网络前,将图像统一为224×224.损失函数为交叉熵损失函数,使用Adam优化器.学习率为自然指数衰减,初始学习率设为0.001,衰减率设为0.05,其数学表达式如下:

式中,l′表示初始学习率,r为衰减率,s为迭代次数,s′为衰减次数.
使用自然指数衰减学习率能够加快网络训练速度,而且变化的学习率能够提升网络抗干扰性,使其不易陷入局部最小值.每次迭代选取16 张图像送入网络进行训练,训练次数(epochs)为1 000 次.
2.3 网络评估本文以测试集的准确率(A)评判各个网络的分类性能,使用参数量评价网络模型大小,使用混淆矩阵、精确度(P)、召回率(R) 和FS评价各网络对矿物的识别能力.根据实验中真实情况和预测结果之间的关系,把实际结果和预测结果之间的差异分为4 种类别:实际为正样本预测也为正样本(TP)、实际为负样本预测为正样本(FP)、实际为正样本预测为负样本(FN)、实际为负样本预测为负样本(TN).
准确率、精确度、召回率及FS的计算公式如下:

式中,β是调整精确度和召回率在FS中的权重.根据两者的重要程度进行选择,若认为召回率重要,则增大 β;若认为精确度重要,则减小 β ;当 β=1时认为二者一样重要.对于矿物识别任务,我们更关注识别准确度,所以在FS中设置 β=0.5.
2.4 与典型经典网络对比实验为了验证本文提出方法的有效性,在使用相同数据集和同样的预处理条件下,将本文方法与5 种典型图像分类网络在验证集和测试集上分别进行横向对比.经过1 000次训练后,各个网络在训练集均得到了充分训练,准确率均达到了100%,如图5 所示.

图5 各模型训练集准确率对比Fig.5 Accuracy comparison of training sets of each model
在验证集上,MS-DenseNet 准确率达到90.54%,DenseNet121[17]准确率达到87.76%;InceptionV3[20]准确率为86.63%,ResNet50[21]准确率为85.67%;MobileNetV2[22]准确率为85.11%,VGG19[23]网络准确率为83.09%.验证集对比结果如图6 所示.

图6 各模型验证集准确率对比Fig.6 Accuracy comparison of validation sets for each model
从各个模型准确率对比结果可知,在矿物数据集上MS-DenseNet 的总体鉴别性能要好于VGG19、ResNet50 和InceptionV3 经典网络,和同量级网络MobileNetV2 和DenseNet121 相比,本文所提方法也取得了较优的成绩.
表3 为各个模型在测试集评价指标对比表,从表3 中最后一列可以看出,本文所提方法的参数量要高于MobileNetV2,但本文方法在其他评价指标上,比MobileNet 高3 到4 个百分点,说明本文方法以牺牲较小的计算复杂性为代价,换取比同量级网络更高的识别性能.在与其他网络评价指标对比中发现,无论是在精确度、召回率和FS还是测试集准确率、参数量,本文所提方法都要好于其他网络,证明本文所提模型可以胜任在普通计算机上的矿物识别任务.

表3 各模型在测试集评价指标Tab.3 Comparison of evaluation indicators of each model
图7 给出了在测试集整体识别准确率较高的网络的混淆矩阵对比图.在测试集准确率排名前3的网络分别为MS-DenseNet、DenseNet 和Inception.从图7 混淆矩阵对比可以看出,3 个网络对赤铁矿易发生误判.MS-DenseNet 对赤铁矿的识别准确率仅为72%,相比InceptionV3 和DenseNet121 表现较差;而InceptionV3 对这类矿物识别效果较好,准确率达到了77%左右.但在硅孔雀石和孔雀石的这两类极为相似的矿物鉴别上,MS-DenseNet 鉴别效果要优于其他两个网络.对于斑铜矿的鉴定,DenseNet121 相比另外两个网络表现较好.虽然各网络对各类矿物表现出不同的判定能力,但是各网络对6 类矿物整体识别准确率都在85%以上,而且本文所提方法整体精准度要优于其他两类网络,尤其在硅孔雀石、孔雀石、黄铁矿和石英判定上,误判发生的概率较低.
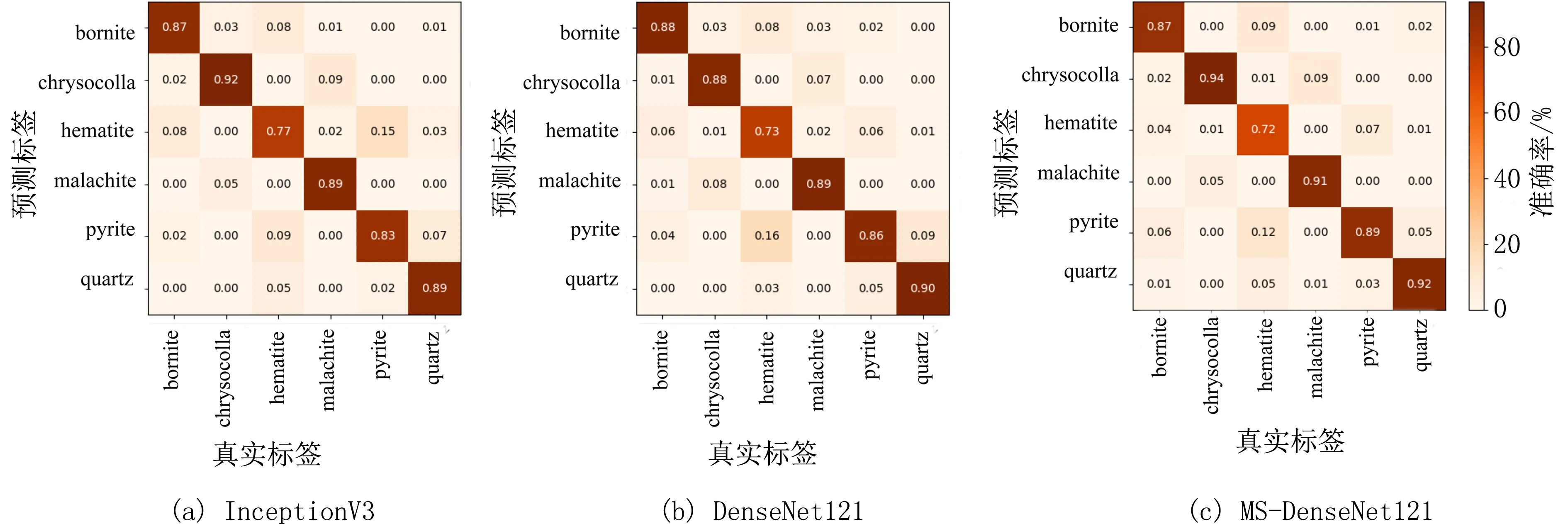
图7 混淆矩阵对比Fig.7 Confusion matrix comparison
2.5 消融实验与识别热力图为了验证MS-DenseNet在网络结构上的改进更能有效地提取矿物特征,本节对原始的DenseNet、结合改进多分支结构的IDenseNet、结合跳跃连接结构的S-DenseNet 以及本文方法进行了对比.并以测试集准确率作为评价指标,各个网络训练设置相同对比结果如表4 所示.

表4 网络结构评价与指标对比Tab.4 Network structure evaluation and index comparison
从表4 可知,最优网络的预测准确率为88.06%,该网络是在DenseNet 基础上,融入跳跃连接结构和多尺度卷积结构.在网络前期,通过使用多尺度卷积可以耦合不同尺度的矿物特征信息,这些信息能有效帮助网络进行矿物判别;以密集连接方式将前面提取到的多尺度信息与下层网络进行交互,在丰富下层网络输入特征多样性的同时加强信息流通;在网络终端,以跳跃连接方式进行信息增强,减少特征图压缩过程中的信息丢失.从对比结果来看,本文所提改进点是有效的.
除实验外,本文还将MS-DenseNet 在训练过程中学习到的矿物特征以及重要程度做了可视化展示,如图8 所示,输出前三的最大可能类别.从矿物特征图对比中可发现,每条分支所提取到特征是不同的,既有全局特征,也有局部特征,这印证了上文所述的多尺度卷积具有良好的尺度适应性.同时,本文所提多尺度结构兼具低参数量优势,相比传统卷积结构,本文算法所需计算内存低,便于日后在便携式设备上进行应用.类激活热力图是将所提取特征对于网络识别矿物种类的重要性作展示,如果提取到信息对网络最后的判别越重要,那么该位置的激活强度就越大,即反映出的颜色也就越鲜艳.通过类激活热力图和top3 最大可能矿物概率,给出了网络找到了不同种类矿物的不同之处,对于一些重要特征做了明显标记,提升了工作效率.

图8 矿物特征图与类激活热力图Fig.8 Mineral feature map and class activation heatmap
3 结束语
为了避免识别网络结构规模庞大、计算复杂度高问题,同时在有限数据集训练情况下,网络模型具备矿物的识别性能,本文提出MS-DenseNet 矿物智能识别模型.首先通过在密集连接网络中引入多尺度卷积结构并使用分组卷积策略对网络进行优化,使其具有不同尺度特征学习能力,减少特征信息损失同时保证较低网络参数数量;其次在深层网络的尾部采用跳跃连接结构,实现耦合上下层的信息并减少了深层网络的信息丢失.为了验证本文方法有效性,在本文数据集上进行了网络结构对比实验和与5 种典型网络对比实验,结果表明,本文所提方法在测试集预测准确率均高于其他5 种网络,达到88.06%,所提改进点有助于提升网络性能.由于图像质量对网络模型的特征提取能力有着重要影响,未来将采用目标检测网络对图像进行预处理减少图像中的干扰因素,从而进一步提升网络的性能.
