基于复杂噪声干扰的英语口语测试系统*
2022-11-28霍小静
霍小静
(西安培华学院,陕西 西安 710125)
1 引言
英语口语测试是英语教学测试的重要组成部分[1]。传统英语口语测试主要由人工完成,由于人工测试具有较强的主观因素影响,且测试效率较差,费用较高,因此英语口语测试从人工测试转变为线上人机交互测试,利用计算机实施自动测试成为信息化社会的迫切需求[2-3]。
当前普遍使用系统主要为基于技术模型的测试系统和基于序列匹配的英语口语发音质量评估系统[4-5],但它们均存在测试结果波动大等缺陷。究其原因主要是由于系统检测过程中,语音信号中存在明显噪声导致[6]。
为了获得更优的结果,针对当前测试过程存在的问题,设计一种针对复杂噪声背景的口语测试系统,主要针对复杂应用环境下,对信号中语音和非语音的准确判断进行研究,以此提升系统的应用性能。
2 复杂噪声干扰的英语口语测试系统
2.1 测试系统整体结构
本文系统整体结构如图1所示。系统包含六个模块,分别是:语音采集模块、预处理模块、语音特征分析模块、测评模块、映射模块与输出模块。其中语音采集模块主要采集被测者的语音信号,并将采集结果输入预处理模块中,预处理模块对含噪信号进行降噪处理;降后信号传输到语音特征分析模块中,得到文本标注信息与特征文件,测评模块根据文本标注信息与特征文件进行机器测评,生成机器打分。映射模块根据机器打分与人工打分实施映射处理,得到最终测试结果,并通过输出模块向用户展示最终测试结果。
2.2 英语口语信号预处理模块
在语音信号采集过程中,受环境噪声以及信号传输过程中电路噪声的影响,语音信号通常存在复杂的噪声背景,对测评结果产生干扰,导致测试结果不够准确[7]。为提升测评准确性,需对语音信号进行降噪处理,提升被测者输入信号的质量,为此通过预处理模块对环境噪声、电路噪声进行处理,去除信号中的复杂噪声背景。
2.2.1 环境噪声处理
针对信号中的环境噪声,选取谱相减降噪技术进行降噪处理[8]。|yi(t)|2(t=1,2,…,k)表示第t帧幅值谱的第i元素的语音功率,和分别表示噪声功率和除噪后语音的功率,谱相减降噪技术的表达式:
式中,α表示权系数。
通常将噪声设为平稳噪声,这样要求整个语音段、噪声功率和α值通常具有一致性[9]。在实际应用中,环境噪声通常具有非平稳性,因此利用一致性的噪声功率值无法得到有效的去噪效果。且权系数α一致的条件下,会概率产生消除过度或消除不足的问题,部分区域中出现噪声消除不完全或消除过度,|si(t)|2会出现失真现象,因此需对谱相减降噪技术进行优化。
对噪声功率进行优化时,利用整体区域语音外输入帧功率|xi(t)|2逐次更新噪声功率,描述如下:
式中,β为噪声谱特征。
为使α同输入语音功率相匹配,根据式(3)使权系数α随输入语音功率的变化而变化:
式中,θ1、θ2和C1、C2分别表示门限阈值和常数。
利用式(3)可防止出现消除过度或消除不完全的问题。
2.2.2 电路噪声处理
针对语音信号中的电路噪声,选取倒谱均值规整降噪技术实施降噪处理[9]。Ci(t)表示第t帧倒谱的第i元素噪声下的语音倒谱,表示除噪后语音的倒谱。由此得到倒谱均值规整降噪技术的表达式:
式中,表示整体输出语音的倒谱平均值。
倒谱均值规整降
噪技术存在两个问题:
(1) 输入信号不利因素的出现频度对值产生直接影响;
(2) 需对整体信号计算完成才可确定值,对降噪过程实时性产生不利影响。
因此,利用最大后验概率优化值计算精度,式(4)可转换为:
式中,γ和Ci0均表示自适应训练系数,两者分别由实验和学习数据确定。
作为渐进自适应方法,最大后验概率算法中样本采用逐个输入方式,从而去除样本数据中的噪声。
2.3 语音特征分析模块
语音特征分析模块主要功能是对降噪处理后信号进行分析,特征分析质量对测评结果产生重要影响。正确判断一个单词开始对于语音特征分析尤为关键,即语音端点检测技术[10]。通常情况下端点检测普遍采用短时能量En与短时平均幅度函数Mn两种方法进行,两种方法描述如下:
式中,Sn(m)表示信号频率特征,m=0,1,…,N表示帧数。
短时能量En与短时平均幅度函数Mn均可描述单帧信号的能量,在端点判断过程中,通过设定|En|值或|Mn|值确定语音端点位置。
语音特征向量的构造是以模糊聚类矢量量化特征为主,结合英语口语测试的实时性要求,同时考虑计算量进行选取。在选取信号特征矢量Xi时,参考部分相关资料后决定合成一个特征矢量,该特征矢量由12 阶梅尔频率倒谱系数与各阶差分参数加短时能量En合成。
2.4 语音信号的测评模块
测评模块根据文本标准与特征文件对输入的语音信息进行测评,采用隐马尔可夫模型作为语音识别软件,依照语音特征分析模块中特征矢量对信号进行测评。利用隐马尔可夫模型能够获取指定文本Ti(i=1,2,…,N)的发音数据O的输出概率P[O|T]。在进行测评过程中,利用后验概率P[O|T]作为英语口语质量测评的工具,后验概率是针对孤立字实施的,在连续语音信号条件下需对连续信号实施分割并分段累加。针对连续信号,选取贝叶斯公式计算后验概率P[O|T]:
式中,Q和q分别表示模型集合和Ti可能被误读成的音素,NF(Ti)和P(|Ti)分别表示音素Ti的总帧数和发音矢量的似然度。
3 仿真测试
实验为验证复杂噪声背景的英语口语测试系统的应用效果,在TIMIT语料库中数据作为测试对象,选取NOISEX-92噪声库中的F16噪声和pink噪声为添加的复杂噪声,采样频率和采样精度分别为12.14kHz和18bit。
3.1 复杂噪声背景下端点检测结果
选择基于技术模型的测试系统和基于序列匹配的测试系统作为对比系统。选取1段纯净无噪音信号,具体如图2所示。
在图2中英语口语语音信号中添加噪声,统计不同复杂噪声,不同系统的端点检测结果,具体如图3和4 所示。由图3可知,添加F16 噪声后,对比系统均出现极为不稳定的能量波动,而本文系统的输出较平稳,可以检测到信号有用信息;由图4可知,添加pink 噪声后,基于技术模型的测试系统无法有效去除pink 噪音干扰,检测效果差,基于序列匹配的评估系统虽然去除了一定的噪声干扰,但检测结果不稳定,而本文系统信号检测平稳,良好地去除了噪声的干扰。因此,针对复杂噪声环境下信号,本文系统的去噪效果好,端点检测结果更加准确,利于提升测试结果。
3.2 测试结果显示
将本文系统应用于实际英语口语测试过程中,选取4个被测者从单词发音与对话两方面进行测试,相同测试内容分别进行3次测试,结果如表1所示。分析表1得知,基于技术模型的同一被测者单词发音测试分值差异上限为10分,对话测试分值差异上限为11分。基于序列匹配的评估系统的同一被测者单词发音测试分值差异上限为8分,对话测试分值差异上限为9分。本文系统的同一被测者单词发音测试分值差异上限为2分,对话测试分值差异上限为2分。结果表明本文系统的测试结果更为稳定,提升测试结果的可信度,测试性能更优。
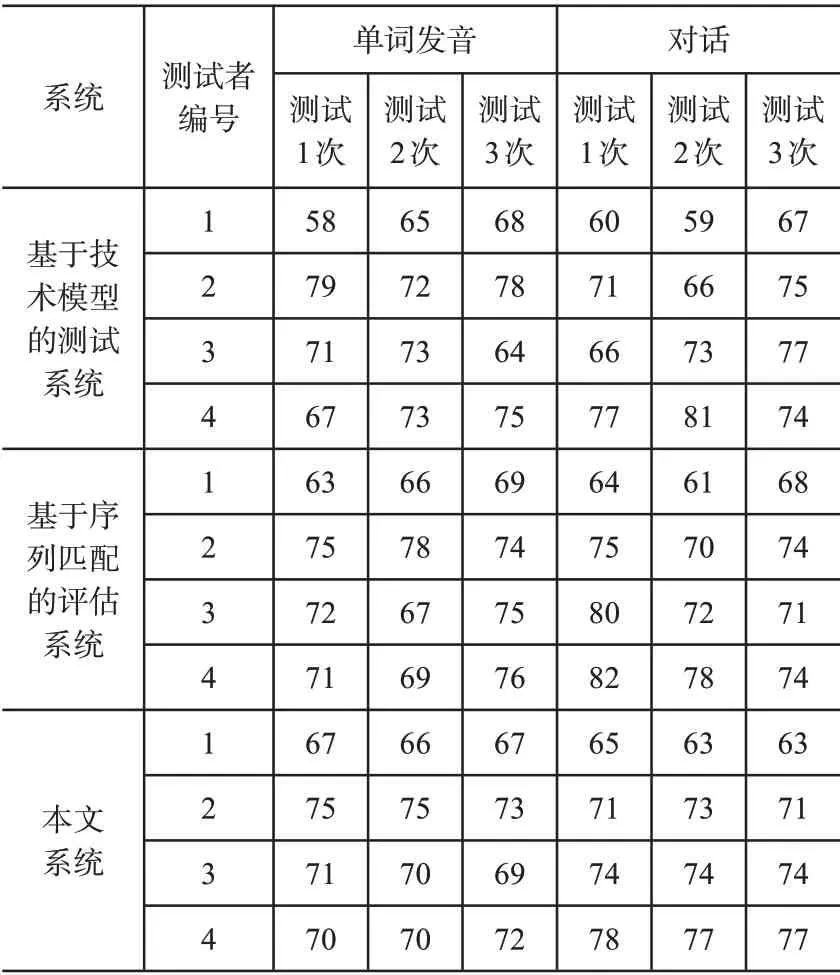
表1 不同系统的测试结果对比
3.3 系统工作效率测试
为了分析不同系统效率,统计不同系统的平均测试时间,具体如图5所示。对图5的时间进行对比和分析可以发现,相对于对比系统,本文系统的测试时间明显减少,获得更优测试速度,测试效率有了显著的改善。
4 结束语
在经济全球化的推动下,英语口语重要性更加凸显,为更加有效准确的获取英语口语测试成绩,针对测试过程中的复杂噪声,设计了复杂噪声背景的英语口语测试系统,通过降噪处理、端点检测以及语音特征分析等过程,利用隐马尔可夫模型的语音识别软件进行测评,测试结果表明,本文系统能够获取更加精确稳定的测试结果,具有更高的实际应用价值。
