无线局域网自动化接入过程安全监测方法
2022-11-28高俊
高俊
(河南省科学技术情报中心,河南 郑州450018)
1 引言
无线局域网(Wireless Local Area Networks,WLAN)可以实现在局部区域内无线媒体或介质进行信息传输,是计算机网络和无线通信技术相结合的结果。经过不断的升级发展,已经被广泛应用于教育行业、医疗行业、金融行业和人们的生活中。然而,在WLAN 快速发展、为人们生活和工作带来极大便利的同时,安全问题也随之产生,并成为影响其继续发展和普及的一个重要因素。
调查研究表明,WLAN 主要存在以下几个方面的安全威胁:通过公共WLAN网络,攻击者伪装成合法用户,接入WLAN非法访问网络资源;一些黑客研制的某种扫描工具使非法接入WLAN变得更加简单;在使用WLAN传输未被加密的信息或文件时,易被攻击者截获或者篡改,甚至造成个人信息被盗取;还有某些无线设备的不适当配置也有可能造成信息的泄露。因此,有必要研究适用于无线网络自动化接入安全监测方法。
近年来,也有许多国内外的学者针对无线网络安全问题提出了一些安全理论、安全方法和安全技术。文献[1]提出了无线网络中信息安全防范方法,通过对机密信息标准化处理建立机密信息融合的超曲面,并在此基础上构建了RBF神经网络,利用RBF神经网络对局域网中机密信息的相关度进行预测实现信息安全防范,但是该方法计算过程较繁杂,耗时长。文献[2]提出了家用无线网络路由器安全防护方法,通过监测HTTP 协议网络攻击行为,将非法行为牵引至影子服务器,从而降低家用无线路由器的安全风险,但是该方法局限性较大,适用于家用无线网络,在大型无线环境内效果并不理想。国外专家通过能效技术找出无线传感器网络中的欺骗攻击并减轻影响,由于分组传输的延迟和分组丢失会不必要地浪费资源,因此通过减少能耗相关算法提高了网络性能从而提升无线网络安全性。
本文总结以往研究经验,提出基于K-means算法的无线局域网自动化接入过程安全监测方法。在大量的网络数据中筛选出有效的正常用户行为数据,利用K-means算法对其进行安全监测,将正常用户行为与异常行为进行归类划分,屏蔽或拉黑异常行为用户,保障正常用户的上网安全,完成无线局域网自动化接入过程安全监测,以图有效保护用户上网安全。
2 WLAN常见攻击分类
针对当前WLAN 环境中用户信息数据量巨大且结构复杂的特点,要实现对不同类型的数据进行准确无误、快速的处理是一件非常困难的事情,这就对WLAN自动化接入安全监测提出了更高的要求[3]。采用高效率的数据处理方法,对数据集中具有代表性的数据进行分析,可以提高网络安全检测的工作效率。聚类算法是一种将数据按照群的形式进行分析的算法。将WLAN 环境中采集到的所有数据分为若干个模式子集,并将相似度较高的数据放在同一个集合内,所以,每个集合之间的差异性都是比较大的。
WLAN环境下实现自动化接入安全监测的主要途径是通过在网络运行过程中,随着运行环境的不断变化,节点会相应的插入新的安全监测代码[4],从而保障整个网络运行的安全性。常见的WLAN网络攻击如图1所示。
K-means 算法是按照数据的相似度进行分类划分,将有着相近相似度的数据归为同一类,并且通过计算各个数据之间相似度的平均值,将其划分为k个聚类。
在本文WLAN安全监测中,所要监测的数据不仅数量多,而且类型不统一,可以采用K-means 算法从网络大数据n个对象中随机选取k个对象作为初始聚类中心,被选取的对象属性特征较明显,且不同于其他对象。以被选取对象到初始聚类中心的距离为划分依据,将符合条件的对象划分在同一个聚类内。通过计算就会有新的聚类产生,并对新产生的聚类计算求平均值,以此类推重复计算,则会有若干个新的聚类产生和若干个新的距离出现,当标准测度函数开始收敛时停止计算,此时得到的数即为最佳准确度的平均值。
K-means算法是根据数据间的相似度进行划分的一种方法,该算法将采集到的网络大数据中的n个对象分为k个簇,这些簇之间具有明显的属性相似度,并且差异性也有明显的不同。对每一个簇中的数据计算求平均值,得到具有最佳准确度的簇。通过此算法将WLAN 环境中所有的数据进行聚簇分类后,可以得到合法信息的簇和入侵信息的簇,将入侵信息筛选出来,以此达到保护WLAN中正常用户的信息安全性和完整性的目的。
在K-means算法计算过程中,采用均方差作为标准测度函数来求平均值,标准测度函数见式(1):
式中,xj表示网络中某一数据点;Ci为聚类中心;mi为聚类的平均值。
K-means 聚类算法的优点很多,但是在计算过程中缺点也很明显。例如,k值需要在进行聚类计算之前就给出,对聚类初始中心的依赖性较大,对于WLAN 环境下数据量巨大的计算,该算法在计算过程中要花费大量的时间。这也在一定程度上阻碍了K-means 聚类算法的应用范围。
K-means聚类算法对数据类型为密集型数据[5]、所有数据之间有明显的类别差异的这类数据进行聚类计算较简便,在网络安全监测中也可以取得很好的效果。但是在实际环境中,安全监测网络数据包的数据通常都是随机选取的,尚无显性的规律可循,就要对其进行聚类划分,此时利用K-means聚类算法来选取聚类中心就比较困难了。因为还没有确定k的值,所以聚类的结果也是不确定的。再加上K-means 聚类算法在处理密集型数据时效果较好,对于离散型数据[6]计算过程较为繁杂,不能很好地处理,大大地限制了其应用范围。
3 WLAN接入安全监测预处理过程优化
为了更好地监测WLAN 中的异常行为,本文对Kmeans算法中的数据预处理、初始中心选取和k值确定这三面做出优化调整。
(1) 数据预处理。
网络中的大数据具有两种属性,一是连续型数据,另一种是如服务协议和服务名称一类的离散型数据。为了适应本文算法,更利于对数据的挖掘,这里将所有离散型数据进行预处理,转换为方便计算的数值型数据,对离散型数据的定义过程如下所示:
定义1:在网络报警数据库D中含有w个警告记录集T={T1,T2,…,Tw}(w≥1),由r个特征属性构成其属性集X,X={X1,X2,…,Xr}并且满足原则X=Xc Xd和XcXd=φ,其中Xd为数值型数据。D中的所有警告记录Ti都是由r维属性构成的,那么则有:Ti=(xi1,xi2,…,xir)。
可以通过计算所有数据之间的距离来计算数据之间的相似度,这里本文采用欧氏距离来计算。
定义2:如果Ti和Tj为分别为警告记录中的任意两条记录,那么就可以通过欧式距离来计算Ti与Tj之间的相似度距离Sim(Ti,Tj)为:
其中,Ti与Tj之间的字符型属性的相似度距离表示为:
其中,q 表示字符型属性个数,1≤q≤r,ij,S(xih,xjh)表示第h个字符属性的相似度距离。Ti与Tj之间的数值型属性的相似度距离为:
式中,p表示数值型属性个数,且有1≤p≤r,i≠1。
定义3:假定聚类集C={Ci}{i=1,2,…,k};Ci={Tf,Tl,…,Tg}为第i个聚类内包含l个警告记录。
定义4:ri可表示为ri+rid+ric,其中,rid表示为数值属性的聚类中心,其值的大小取决于警告记录内所对应的属性平均值,即:
由警告记录内属性频率最高的值来确定字符属性聚类中心的值,即:
定义5:通过计算聚类中心rj的相似度,就可得到Ti和Cj的相似度的值,计算过程如下:
最小距离为:
定义6:任意两个聚类Ci和Cj之间最小相似度距离可以表示为:
包含l 个数据对象的第Ci类内数据对象相似度平均值SWCi可表示为,式中Avg为算数平均值求解函数:
定义7:按照Ti与类别的最大相似度距离为依据,对数据进行划分。按照与聚类中心距离最近为依据,可得到这个最大相似度距离为:
定义8:记录分布密度函数di=,其中zi=,di的值越大,对后期聚类的结果影响就越大。
(2) 初始聚类中心的确定。
由于样本点的密度和聚类中心的相似度会对初始聚类中心的确定产生一定程度的影响,所以这里选择密度较高、相似度较大的聚类来进行计算,从D中随机选取q个数据子集D1,D2,…,Dq,每个子集含有n'条记录,n'=(t,n'n),利用FindM(D,q,n')函数,得到r1、r2、r3三个初始聚类中心。
FindM(D,q,n')函数计算过程如下:对随机选取的q个数据子集Dj(1≤j≤q)进行遍历,根据定义8,可得到Dj各记录的分布密度为di(1≤i≤n'),rj=Max(di),并根据定义4得到{rj}的聚类中心设为r1。根据定义2计算Sim(r1,rj),得到Max(Sim(r1,rj))设为r2。同理,计算,Sim(r2,rj),r3=Max(Sim(r1,rj)+Sim(r2,rj))输出初始聚类中心r1、r2、r3。
(3) 新聚类的产生和k值的确定。
通过计算得到类间相似度距离最小和类内相似度最大的结果[7]。为了使k值能够按照类内相似度距离最小和类间相似度距离最大为标准进行划分,在计算过程中随时变换k的值,计算过程如图2所示。
4 基于K-means算法的WLAN安全监测模型
在运用K-means算法求解过程中,首先,随机选取k个对象,根据每个对象与聚类中心距离最近的方式进行聚类划分[8];然后,重复计算对象的聚类中心,当准确度函数开始收敛时停止计算。
基于K-means 聚类算法的WLAN 自动化接入安全监测模型如图3所示。
监测模型可分为两个阶段来设计,一是训练阶段,另一个是监测阶段。
在监测模型的训练阶段,首先要抓取WLAN环境中的正常行为数据,将可以反映网络状态安全的特征数据挑选出来,为构建安全监测模型准备所需要的安全行为数据集。其次,将抓取到的所有数据通过Hash函数进行预处理,将特征数据转化为监测模型可以识别和处理的数据形式以适应本文的算法分析,需要最后运用K-means 聚类算法计算预处理后的特征数据,完成聚类划分,构建数据树形结构,完成对所有数据的训练,从而完成安全行为数据基准库的构建。
监测模型到了第二阶段,也就是监测阶段:
首先,要对WLAN环境中采集到的正常行为数据进行监控,以确保所选取的待测特征数据是准确无误的。
其次,利用Hash函数对特征数据完成类别转换。然后,将数据集里的数据按照K-means 聚类算法,选取不同的特征进行聚类划分。利用在训练阶段构建的树形结构寻找与k值邻近的对象。最后,利用直推式异常检测算法计算特征数据,再对比正常行为数据基准库,得到p 值的结果,对比两次计算的结果就可以判断出接入WLAN的用户是否存在异常信息。
利用直推式异常检测算法可以对网络采集到的原始数据通过训练进行随机性检测和置信度计算,将所得的p值与聚类后的数据进行对比分析,如果p值比安全行为数据基准库的空间值大,说明其类属于接入WLAN正常用户的可能性就越大。
5 仿真实验
为了验证本文方法在WLAN 自动化接入过程中的安全监测性能,以WLAN 网络安全评测基准为基础,将文献[1]、文献[2]和本文方法对WLAN自动化接入的安全监测进行仿真实验。
在实验环境中,记录的属性值包括44个,字符属性包括8个。在网络数据库中,随机抽取5个数据子集作为样本数据,其中每个子集中包含100 个信息记录,以此为实验环境进行仿真实验测试。数据样本如表1所示。
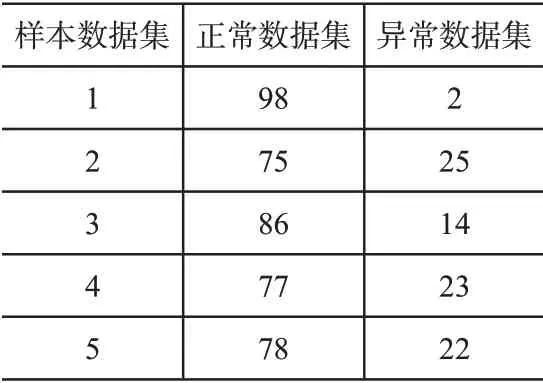
表1 数据样本
将文献[1]、文献[2]方法与本文方法在监测率、误检率、监测时间上进行对比,实验结果如表2-表4所示。
根据表2-表4建立更为直观的图4,可以看出本文方法不管是在监测率、误检率、监测时间方面分别为85.11%、14.89%、126s,结果都优于文献[1]、文献[2]方法。其中,文献[1]方法最差,文献[2]方法次之。主要是因为本文方法在数据处理方面将不易计算的离散型数据考虑在内,使影响监测结果的误差降到最小。

表2 文献[1]方法

表3 文献[2]方法
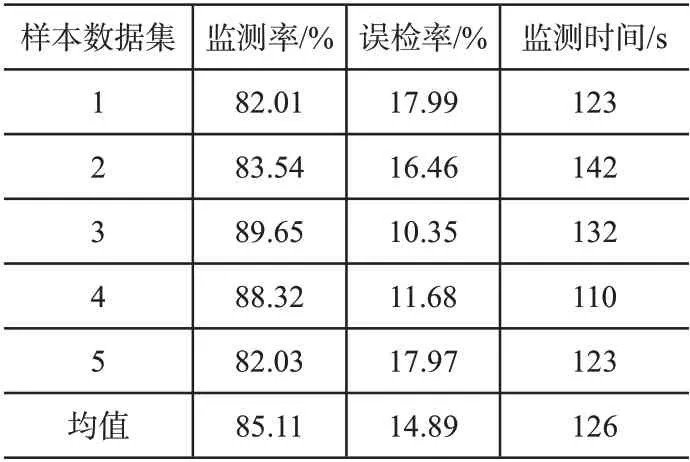
表4 本文方法
6 结束语
由于无线局域网固有的特性使一些不法分子有机可乘,因而存在很多的安全隐患,即使目前已经有很多关于这方面的研究,但是都有其狭隘性。本文在此基础上,提出了基于K-means 算法的无线局域网自动化接入安全监测方法。在K-means算法的基础上对数据预处理、聚类中心的选取和确定k值等方面做了优化改进,使其计算过程更简便,在实际应用中的范围更广,并且可以很好地处理离散型数据。以优化后的K-means 算法为基础构建WLAN自动化接入安全监测模型,将采集到的网络数据分别进行训练和监测,并采用直推式异常检测算法与正常行为数据基准库进行对比,完成WLAN 的安全监测。仿真实验结果表明,本文方法监测效率和准确度较高,在WLAN安全监测方面可以很好地保障正常用户上网安全。在下一步的研究工作中,将会不断完善无线局域网的安全监测方法,不断增加新的安全策略来保障无线局域网用户的安全使用。
