基金项目和论文主题扩散演化路径识别及其可视化研究
2022-11-28刘自强岳丽欣朱承宁刘春江
刘自强 岳丽欣* 朱承宁 刘春江
(1.南京师范大学新闻与传播学院,江苏 南京 210023;2.中国科学院成都文献情报中心,四川 成都 610041;3.中国科学院大学经济与管理学院,北京 100190)
随着计算机和互联网技术的不断进步,全球范围内科学研究和经济社会获得了新的发展契机,大数据、深度学习等新兴技术加速了世界各国(地区)迈向数据科学时代。数据科学时代,知识创新过程必须依赖科学研究与技术研发活动的有效开展,知识创新往往来源于现有学术成果的融合、重组和升华,但是当前学术成果数量爆发式增长,知识创新主体在研发活动中的机会和选择更加复杂。
在此背景下,世界各国(地区)科技创新活动已然呈现出新特征,科技情报分析与研究的问题往往更为综合,涉及要素更为多元的同时也更为细化,导致单一数据不能满足分析的要求。研究前沿识别、热点发现、科技评价等工作都需要在充分搜集多种数据的基础上进行分析,以便为科技创新决策提供更有力的情报支撑。但是,现有研究大都针对论文数据[1-2],部分研究者关注利用多种数据(基金项目、论文等科技文献)[3-4],但缺少对不同数据内在关联的考虑。基金项目、论文等科技文献之间存在着直接或间接关联关系,厘清这些关系对于把握研究主题扩散演化(科学知识流动)规律,促进研究前沿识别、新兴趋势检测等科技情报分析实践工作具有重要意义。
在目前研究的基础上,本文提出一种基金项目和论文主题扩散演化路径识别及可视化方法,旨在定量、可视化识别基金项目和论文研究主题之间的扩散演化路径,辅助探索科学知识在基金项目和论文数据之间的流动规律,以期能够应对不断深化的科技情报分析需求,为科研人员选题、企业科技研发和科研管理部门制定战略规划等提供一定的参考、借鉴。
1 相关研究
1.1 科学发展中的主题演化
无论是波普尔提出“伪证主义”(亦称批判理性主义)的科学发展模式理论,还是库恩提出的基于范式理论的科学发展模式,都是从科学发展的宏观层面上用不同的形式描述了科学研究内容的发展演化过程[5]。从主题演化的角度来看,科学发展是新研究主题不断产生和旧研究主题不断消失的过程,同时包含着研究主题的交叉和融合。波普尔通过《科学发现的逻辑》《猜想与反驳:科学知识的增长》和《客观知识:一个演化论的研究》等著作系统论述了科学哲学论,并且较为全面地阐述了“证伪主义”[6]和“三个世界”[7]学说,他在研究中指出,知识的发展同生物的进化有着惊人的相似[8],客观知识发展、进化是通过非自然的、非自发的或人为的选择进行的,具有遗传、继承、变异等特征[9-10]。库恩在《科学革命的结构》一书中提出科学发展模式理论[11-12],从历史主义方法论出发,以范式为核心概念,采用四段图式(问题—猜想—反驳—新的问题)表示科学发展模式,认为科学发展是一个革命过程并永无止境不断发展,逐渐向真理逼近,并将科学范式定义为“某一学科领域的共同约定”。
科技文献作为科学知识的主要载体,其中蕴含的文本内容(主题词、主题等)会随着科学领域的发展发生动态关联演变:在某一段时期来看,科学知识结构趋于稳定,整体研究处于相对稳定的渐进式发展,伴随着少量新词、新主题的出现、关联和消失等现象;在较长时期来看,科学发展的基本模式就是知识的产生、发展、成熟、消亡的动态过程,也可以认为是研究主题的动态演化过程[13]。通过上述分析可知,某学科领域发展过程中基金项目、论文等科技文献中蕴含的研究主题的发展演化过程同样符合科学发展模式理论,在某一短时期来看,研究主题作为某学科领域中近期产生的、受到研究者关注的科学知识不会凭空产生,而是来源于前期研究内容的交叉、融合和延伸,因此,基金项目和论文主题扩散演化路径识别在理论上来讲是可行、合理的。
1.2 主题演化路径识别与可视化
由于科学技术的发展是连续的、累积式的,作为研究内容概括性描述的研究主题,在时间维度会呈现出一定的隐性脉络和路径,可以通过定量计算、数据挖掘和可视化等技术方法将对这些主题演化路径进行识别、揭示。为有效揭示特定学科领域的主题演化路径并进行可视化,国内外研究者提出了众多卓有成效的方法。
Rosvall M等基于冲积图设计了一种关键词社区演化可视化方法,首先利用关键词聚类识别学科主题,然后以不同颜色的条带表示主题演化路径[14]。微软亚洲研究院网络图形组的Cui W等利用直观的流式图形可视化表示主题演化路径,能够有效揭示主题演变趋势、关键事件和关键词相关性[15]。王晓光等提出了一种新的学科主题演化路径识别与可视化方法,并研发设计了相应的软件工具Neviewer(一款基于共词网络的学科主题演化过程可视化分析软件),能够以冲积图可视化主题演化路径[16],后续部分研究者使用该工具进行了学科领域主题演化路径可视化实证研究[17-19]。刘自强等进行了多维度视角下的学科主题演化路径可视化研究,以人工标注方法对关键词进行语义角色分类,然后通过聚类算法识别主题并设计了3种科学知识图谱进行可视化分析[20]。岳丽欣等提出了领域核心研究主题演化路径可视化方法,利用主题河流图展示主题演化过程,通过对我国医疗健康信息领域的实证验证了方法的可行性和有效性[21]。王康等以时间加权修正后提取的关键词为知识单元,在关键词、关键词关联和主题关联3个阶度进行科学主题演化路径可视化分析,以图书情报领域大数据研究论文为研究对象进行了实证研究,指出该方法框架能够展示各主题之间的融合、扩散、突现、消亡等复杂关系[22]。
概括来说,当前研究主要基于单一论文或专利数据进行学科领域主题演化路径识别与可视化研究,缺乏对基金项目和论文等不同科技文献数据隐含主题关联的考虑,特别是定量、可视化揭示基金项目、论文主题扩散、流动路径问题有待于进一步探索,该问题的解决对于促进研究前沿识别、新兴趋势检测等科技情报分析实践工作具有重要意义。
因此,针对现有研究中的不足,本文提出基金项目和论文主题扩散演化路径识别及其可视化方法,基于LDA主题模型识别基金项目和论文中的研究主题,利用余弦相似度算法构建主题演化路径,并基于Web前端可视化技术设计基金项目和论文主题演化路径可视化方案,从而提升主题演化路径可视化结果的准确性和可读性,最终通过实证研究验证该方法的可行性和有效性。
2 方法框架
基金项目和论文主题扩散演化路径可视化方法框架,主要可以分为数据获取与预处理、主题识别、主题关联构建和主题演化路径可视化4个步骤,如图1所示。
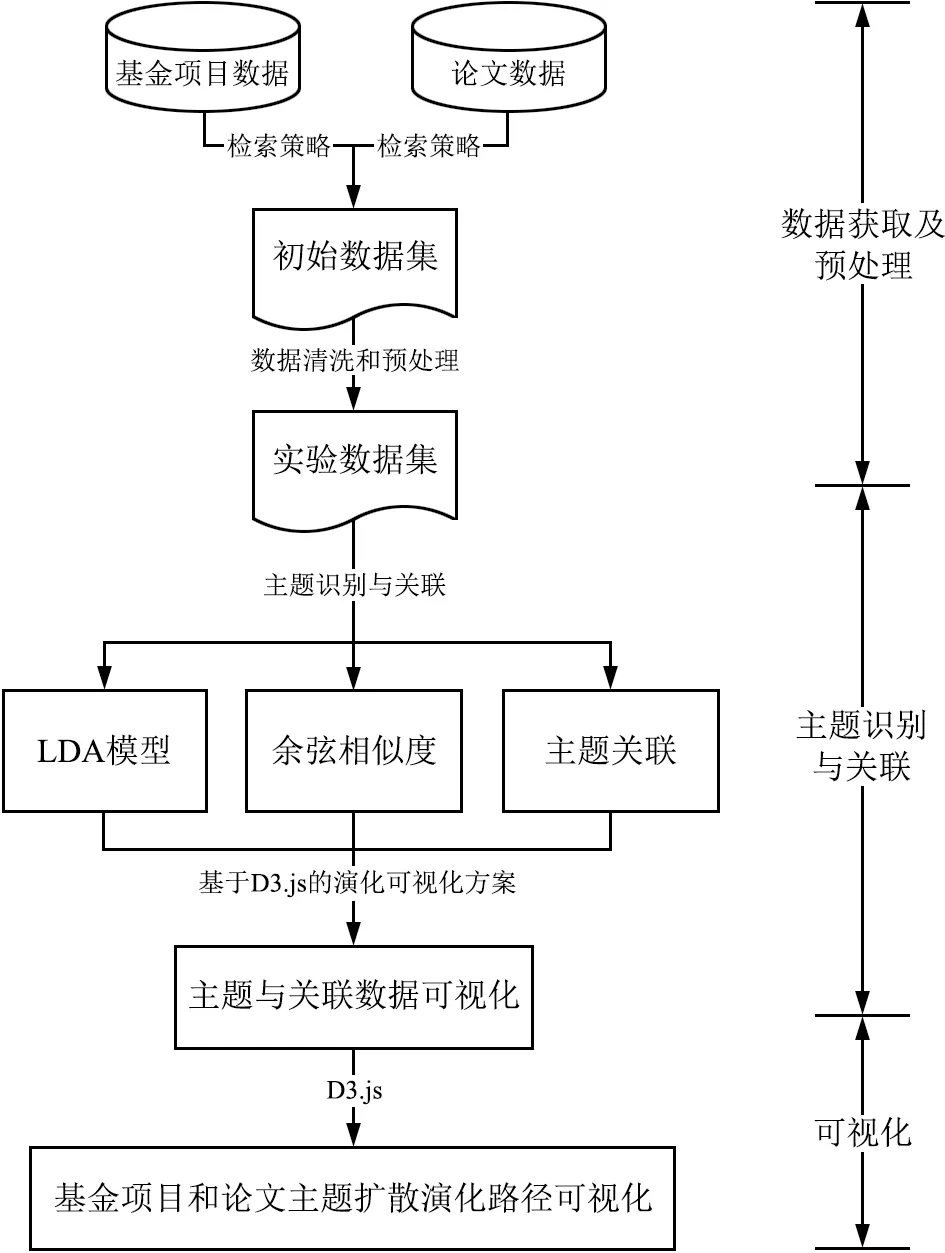
图1 方法步骤
第一步,数据获取与预处理。该步骤主要是获得所需的科技文献数据集,本研究中需要获取基金项目和论文数据,一般通过数据库公司和国家(地区)、机构的在线检索系统获取。预处理阶段主要是为了对上一步中获取到的基金项目和论文数据进行数据清洗、文本预处理等,进而有效提高基金项目和论文数据的质量,为下一步主题识别奠定数据基础。
第二步,基金项目和论文主题识别。首先根据检索得到的基金项目和论文数据进行时间窗口划分,即根据数据的时间标签划分到不同时间窗口下。然后利用LDA主题模型分别识别不同时间窗口下的基金项目和论文主题。
第三步,基金项目和论文主题关联构建。基金和论文主题关联构建是分析基金与论文主题扩散演化路径的关键步骤,LDA主题模型虽然能够识别各个时间窗口下的主要研究主题,但无法直接计算相邻时间窗口下基金项目和论文主题的关联关系,本文利用余弦相似度算法计算主题相似度来构建基金项目和论文主题的关联关系。
第四步,基金项目和论文主题演化路径可视化。本文基于Javascript语言的Web前端可视化技术进行基金项目和论文主题扩散演化路径可视化图谱制作,具体利用D3.js工具基于桑基图样式设计可视化方案,以有效可视化揭示基金项目和论文主题扩散演化路径。
下面对主要步骤进行具体介绍:
2.1 数据获取及预处理
数据获取阶段的主要目标是获得所需的科技文献数据集,本研究中需要获取基金项目和论文数据,主要包括以下步骤:首先,选择合适的数据库,根据研究需求明确检索策略、构建检索式,包括检索方式、检索词、检索范围、检索数据类型等。然后,根据检索式从数据库中检索文献并获取所需字段,保存至本地以备后续研究使用。
数据预处理阶段的主要目标是对上一步中获取到的基金项目和论文数据进行关键字段抽取、清洗、加工,从而提高数据质量,保证后续数据处理步骤的顺利进行,主要包括以下步骤:首先,对获取到的基金项目和论文初始数据(可能存在数据不完整、数据重复、数据值为空等)进行清洗。然后,将获取的基金项目和论文文本进行去除标点符号、数字剔除、过滤停用词、构建词袋等数据预处理步骤,以提高基金项目和论文数据的质量,为下一步主题识别奠定数据基础。
2.2 基于LDA模型的基金项目和论文主题识别
LDA模型最早由Blei D M等提出[23-24],与潜在语义索引[25](Latent Semantic Analysis,LSA)、概率性潜在语义索引[26](Probabilistic Latent Semantic Analysis,pLSA)模型相比,不仅可以得到训练集文本的主题分布,还可以准确得到非训练集文本的主题分布,目前广泛应用于科学与技术主题识别相关研究中[27-29]。本研究具体使用Python的Gensim工具包进行基金项目和论文主题识别。其中,LDA主题模型的联合分布概率如式(1)所示。

(1)
其中,M为文档数目,K为主题数目,N表示第m个文档的单词数目,θ为参数α的Dirichlet分布采样,z表示主题,w表示主题词,φ为参数为β的Dirichlet分布采样。
数据库中提供的基金项目和论文数据在文本结构、数据特征上既有联系又有区别,比如:题名、项目主持人(作者)、摘要等是基金项目和论文数据共有的字段,但是关键词、参考文献等字段是论文数据所独有的。其中题名、摘要是两者共有的关键文本字段,所以,本文在筛选基金项目和论文数据中提名、摘要等共有文本字段基础上,基于LDA模型进行基金项目和论文主题识别。
2.3 基金项目和论文主题关联构建
基金和论文主题关联构建是分析基金和论文主题扩散演化路径的关键步骤,LDA主题模型虽然能够识别各个时间窗口下的主要研究主题,但由于某学科领域的各个研究主题并不是孤立的,特别从科学研究的延续性、继承性角度来看,学科领域内各个主题之间应该存在或明显或隐含的联系,而这种联系可以通过研究主题文本内容来反映,即如果某两个研究主题包含大量相同的文本内容(大量重复的主题词),说明这两个主题之间具有一定的知识关联,因此,本文通过计算研究主题的文本相似性来构建基金和论文主题的关联关系。
目前,文本相似性计算主要有基于字符串(String-based)、语料库(Corpus-based)和知识(Knowledge-based)的方法等,其中,基于字符串的方法也称作“字面相似度方法”,以字符(Character-Based)串或词语(Term-Based)的共现和重复程度为相似度的衡量标准[30]等,由于研究主题主要由若干主题词组成,所以研究者主要利用余弦相似度、Dice系数、汉明距离、欧式距离等基于字符串的文本相似度计算方法进行主题关联构建。
本文拟利用余弦相似度算法计算主题相似度,即通过计算主题之间相似度来判定基金和论文主题之间的关联关系。具体步骤:①向量空间模型(Vector SpaceModel,VSM)构造,由于主题由若干主题词组成(上一步LDA主题识别结果),因此可以将各个研究主题表示成向量,先将主题表示为Topic={w1,w2,w3,…,wn};②主题向量计算,两两计算研究主题向量的余弦相似度(介于0和1之间,值越大表示两个主题越相似),基于余弦距离的主题相似度计算方法,见式(2):
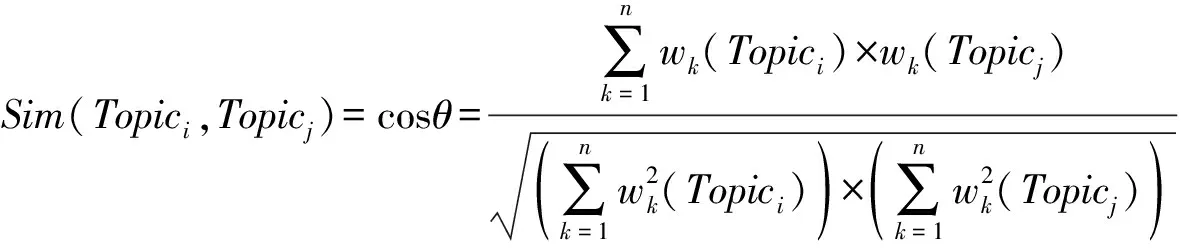
(2)
其中,分子表示两个向量的点乘积,分母表示两个向量的模的积,权重w由主题词概率表示。
2.4 基金项目和论文主题扩散演化路径可视化设计
基金和论文主题之间的扩散演化是一个较为抽象的过程,仅凭研究者肉眼观测数据难以对其进行分析,在具体研究,如何定量、准确地分析基金与论文主题的扩散演化过程十分关键,因此,为有效分析某学科领域基金和论文研究主题之间扩散演化的复杂过程,本文基于Javascript语言的Web前端可视化技术,对基金和论文关联的主题扩散演化路径可视化设计,设计目的是可视化描绘基金和论文主题之间的扩散演化时序脉络并揭示其中的主要路径,以期基于可视化技术对基金与论文关联的主题扩散演化过程进行定量化、可视化揭示,帮助后续研究中快速消化、理解其关键路径。
其中,基金与论文关联的主题扩散演化路径可视化中存在两个关键问题:
1)基金与论文主题的位置分布。通过对比垂直分布与水平分布,具体采用从左至右的水平分布方式展示基金与论文主题时序变化过程,可以根据关联主题在基金和论文路径上分布时间的先后,发现主题扩散演化的具体方向以及时差。
2)基金与论文主题的关联阈值。为了防止主题扩散演化路径可视化图谱显示不清晰、杂乱,需要根据具体情况设定主题关联阈值,即将关联度高于一定阈值的基金主题和论文主题判定为存在关联关系构建演化脉络。
本文设计的基金项目与论文主题扩散演化路径可视化方案,后端数据为主题关联数据,主题关联数据主要由主题数据、时间标签和关联路径(主题相似度)数据构成,网页前端接收后端的主题关联数据进行可视化。下面对后端数据的3种基本属性:节点、路径(边)和时间标签进行具体介绍,如表1所示。

表1 主题关联数据
在主题数据、时间标签和关联路径(主题相似度)数据基础上,为展示基金与论文关联的主题扩散演化路径的复杂过程,本文基于Javascript语言的Web前端可视化技术对主题扩散演化路径可视化进行设计,关键设计代码及其说明如表2所示。

表2 关键设计代码
代码处理思路是首先根据后端提供的主题数据、时间标签和关联路径(主题相似度)数据转换为绘制桑基图所需要的数据;然后利用这些数据结合SVG元素(rect)绘制矩形节点,结合路径元素(path)可以绘制主题扩散演化路径,基本图谱样式如图2所示。
图2中,横坐标表示时间窗口Time;纵坐标表示主题,并分为了上下两个部分,所有的论文主题lwTn位于下部分,所有的基金项目主题nsfTn位于上部分;矩形表示主题,灰色连接表示扩散演化路径,粗细由主题相似度决定。
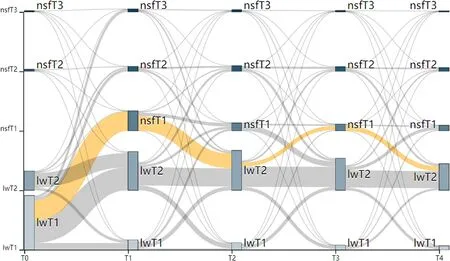
图2 基金项目和论文主题扩散演化路径可视化基本图谱
3 实证研究
为了验证本文提出的基金项目和论文主题扩散演化路径可视化方法的可行性、有效性,以美国纳米农业领域为例进行实例验证。目前,纳米农业领域相关理论、方法与技术在学术界、企业界和国家(地区)间受到了广泛关注(产生了大量科技文献数据,数据可获取),此外,采用纳米技术与新材料等前沿科技推动农业科技原始创新,有利于实现农业可持续发展,对于我国未来的加速发展有着重大的战略意义。
3.1 数据获取及预处理
1)基金数据:选择美国国家自然科学基金委员会(National Natural Science Foundation,NSF)数据库作为基金数据检索数据源。NSF数据库收录历年来资助的基金项目数据,包括资助基金项目的题名、摘要、资助时间、资助金额和项目主持人等关键信息。本文为准确、全面获取美国纳米农业领域的基金数据,通过领域专家的介入、指导构建了检索策略。
具体采用高级检索方式,检索式主要为(篇幅所限,部分检索式)TI=((“molecul*motor*” OR “molecul*ruler*” OR “molecul*wir*” OR “molecul*devic*” OR “molecular engineering” OR “molecular electronic*” OR “single molecul*” OR fullerene*OR buckyball OR buckminsterfullerene OR C60 OR “C-60” OR methanofullerene OR metallofullerene OR SWCNT OR MWCNT OR “coulomb blockad*” OR bionano*OR “langmuir-blodgett” OR Coulombstaircase*OR “PDMS stamp*” OR graphene OR “dye-sensitized solar cell” OR DSSC OR ferrofluid*OR “core-shell”)NOT nano*)AND TS=(breed*or dry farm*or irrigat*farm*or soil improv*or irrigat*ditch*or irrigat*channel or weed*or plough*or fallow*or harrow*or plant*or plantout*or seed*or sow*or graft*or reap*or mow*or ensile*)and TS=AGRICULTURE AND AD=USA。
时间范围:资助时间(EffDate)为2000年1月1日—2019年12月31日;检索日期:2020年1月11日;导出格式:全纪录,XML格式。
2)论文数据:选择Web of Science(WOS)数据库作为论文检索数据源。WOS数据库收录自然科学、工程技术等诸多领域内的近万种学术期刊,包括题名、作者、关键词、摘要和参考文献等关键信息,是目前进行相关研究的主要数据源。本文为准确、全面获取美国纳米农业领域的基金数据,通过领域专家的介入、指导构建了检索策略。
具体采用高级检索方式,检索式主要为(篇幅所限,部分检索式)TS=(nano*)AND TS=(Farm*or husbandry*or animal*husbandry*or animal*breed*or dairy*farm*or crop product*or market garden*or planting industry*or arboricult*or silvicultur*or livestock*or horticultur*or livestock*or agricultur*product*or farm*product*or foodstuff*or dairy*produc*or dairy product*)and(SU=AGRICULTURE or TS=AGRICULTURE)。
国家限定:USA;文献类型:Article;时间范围:出版年份(Publication Year)为2000年1月1日—2019年12月31日;检索日期:2020年1月11日;导出格式:全记录,TXT格式。
根据上述检索策略对美国纳米农业领域的基金和论文数据进行检索、获取,共得到基金数据1 074条,论文数据5 068条。按照年度时间窗口进行统计,得到基金和论文数据的时间分布、比例及其增长趋势情况,如图3所示。
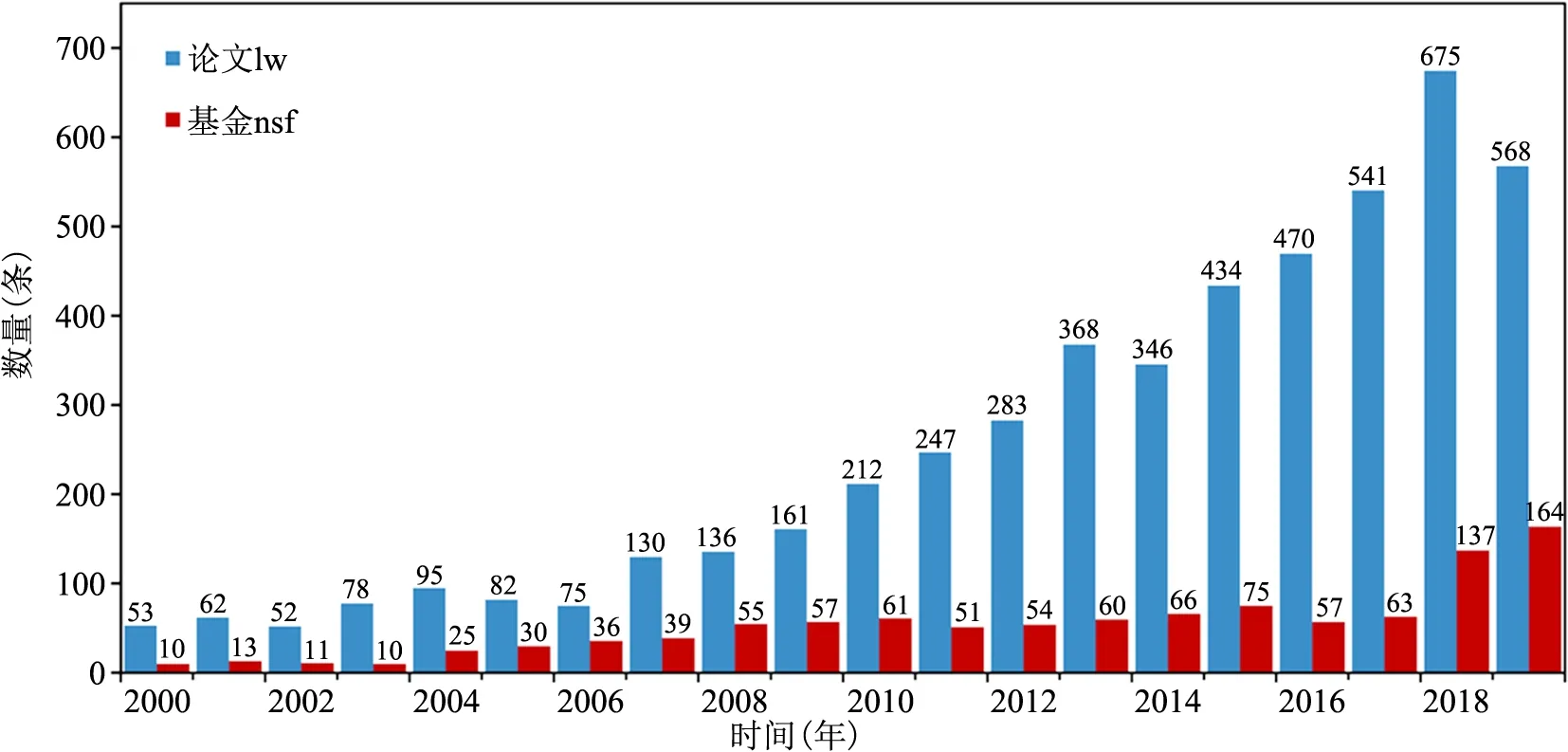
图3 美国纳米农业领域基金和论文数据情况
由图3分析可知,美国纳米农业领域的基金和论文数量总体呈稳定增长趋势,虽然论文数据在2019年略有回落,但整体呈现上升态势,说明美国纳米农业研究领域受到美国政府和研究人员的重视,并且正处于快速发展阶段。
3)数据预处理:数据清洗的目的是对后续主题识别所需的题名、摘要等文本字段进行清洗与规范,从而有效保证数据清洗的效果质量,保证后续数据处理步骤的顺利进行。美国纳米农业领域基金和论文的数据清洗工作主要包括以下步骤:首先,对获取到的基金项目和论文初始数据(可能存在数据不完整、数据重复、数据值为空等)进行清洗,进行删除包含空值的记录、格式变换、去重、去杂和精简日期信息只保留年份等操作后,得到所需的基金项目和论文数据集。然后,将获取的基金项目和论文文本进行去除标点符号、数字剔除、过滤停用词、构建词袋数据预处理等步骤,以提高基金项目和论文数据的质量,为下一步主题识别奠定数据基础。
3.2 美国纳米农业领域基金项目和论文主题识别结果
美国纳米农业领域基金和论文主题识别,旨在识别蕴含在基金和论文中的主要研究主题。首先,将上一步数据预处理得到美国纳米农业领域待分析数据集,按照年份划分到20个时间窗口下,然后,基于LDA模型分别对不同年份美国纳米农业领域的基金和论文数据,具体利用Python的Gensim工具包进行LDA主题识别。
具体利用一致性模型CoherenceModel函数计算主题最优个数,并结合人工判读确定最终主题个数,分别确定各个时间窗口下的基金和论文主题数量,然后基于LDA模型对美国纳米农业领域的基金和论文文本进行主题识别,最后得到20个时间窗口(2000年—2019年)下基金和论文的主题识别结果数量分布情况,如表3所示。
由表3分析可知,经过LDA模型处理20个时间窗口下的美国纳米农业领域基金和论文文本,得到基金主题131个,论文主题228个。其中,2019年论文主题及其下位主题词识别结果,如表4所示,限于篇幅基金和论文主题及其下位主题词,在文中一一展示美国纳米农业领域基金和论文主题识别结果。
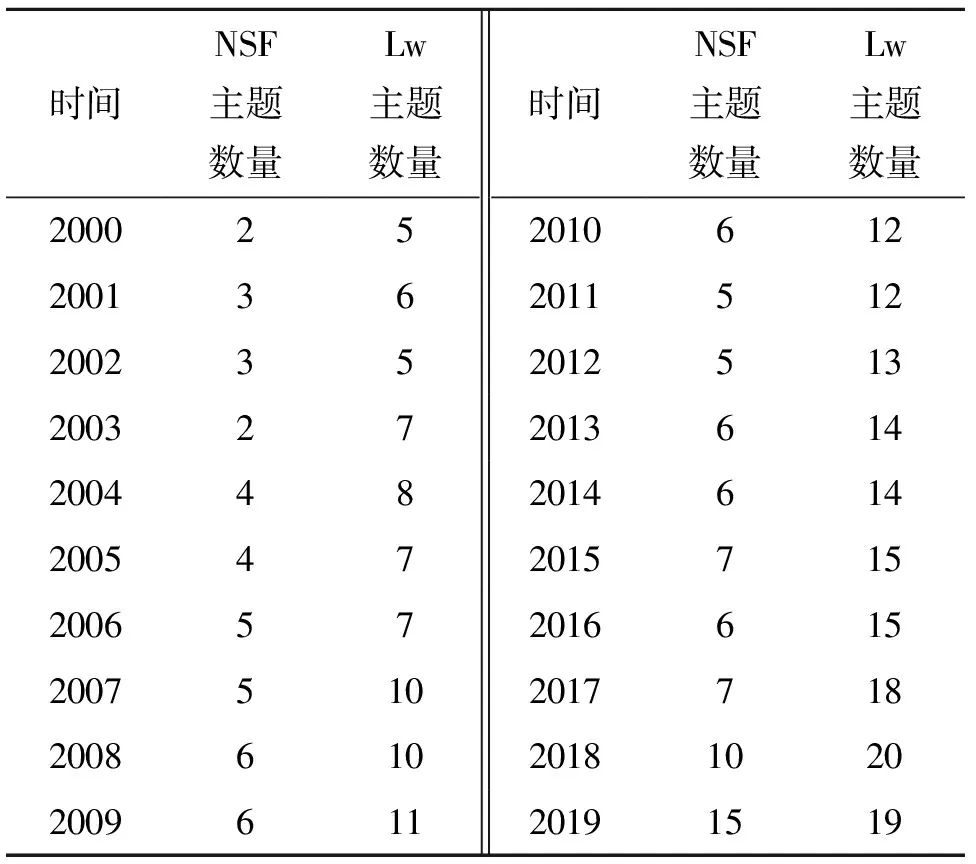
表3 基金项目和论文主题数量时间分布

表4 美国纳米农业领域论文主题—主题词结果(2010年部分)
3.3 基金项目和论文主题关联构建结果
在美国纳米农业领域基金项目和论文主题识别结果基础上,利用cosine余弦相似度算法计算进行主题关联构建。具体过程是:首先,将各个时间窗口下的主题表示成短文本;然后,利用cosine余弦相似度算法两两计算主题文本的相似度(取值范围为0≤sim≤1),得到初始主题相似度结果后去除相似度为0的主题对,由于本小节主要分析基金和论文主题之间的扩散演化关系,从而帮助揭示出基金和论文主题的相互影响,因此筛选出基金——论文主题对,且将主题关联的时间间隔设定为5年,即基金和论文主题的时间差异≤5年;最后,选择合适的主题相似度阈值(防止基金与论文主题关联过多掩盖真实、有效的演化关联),最终确定相似度阈值γ为0.39,即基金主题和论文主题相似度大于0.37判定为同一主题在基金和论文之间发生扩散演化关联,最终得到1735个基金和论文主题关联构建结果,部分结果如表5所示。
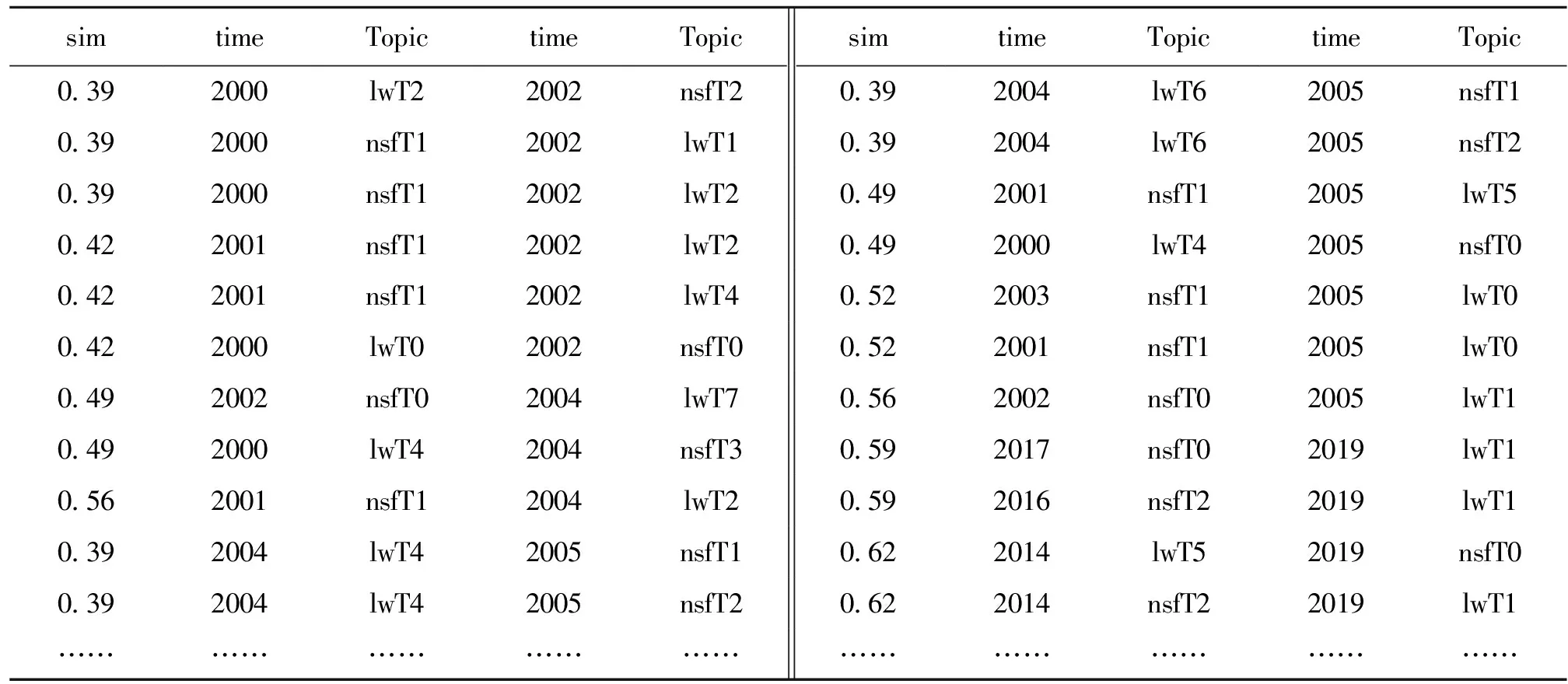
表5 基金与论文主题关联构建结果(部分)
表5中,sim表示基金和论文主题相似度结果(结果已保留小数点后两位),nsf-time和nsfT分别表示基金项目主题的时间标签和主题标号,同理,lw-time和lwT分别表示论文主题的时间标签和主题标号,滞后时间表示基金和论文主题扩散演化的时间间隔。
3.4 基金项目和论文主题扩散演化路径可视化分析
本文将利用上述美国纳米农业领域基金和论文主题关联构建结果进行主题扩散演化路径可视化分析,利用本文设计的基金项目和论文主题扩散演化路径可视化方案,加载美国纳米农业领域基金和论文主题关联构建结果,进行可交互的主题扩散演化可视化图谱绘制(可以在线访问),以辅助具体内容维度的基金项目和论文主题扩散演化路径分析,具体可以细分为5个滞后窗口(滞后1年—滞后5年窗口,指基金项目主题和论文主题扩散演化的时差),图中基金主题(nsfTn)向论文主题(lwTn)的扩散演化路径添加了黄色标记,可交互版本已上传网站https://www.informationscience.top/agriculture/nsflw.html。部分结果如图4所示。

图4 美国纳米农业领域基金和论文主题扩散演化路径可视化结果
在分析图4的基础上,选取纳米颗粒在农作物代谢过程中诱导应激机制为样例主题,分析该主题的主要内容在基金项目和论文数据中的扩散演化过程。
纳米颗粒在农作物代谢过程中诱导应激机制,值得关注的主题词有:nanoparticle、crop、cellular、cyanobacterium、iron、polymer、Oxidative、cell、surface、metabolic、stress、interaction、plant、impact、bioenergy等。该研究主题关注生物纳米粒子在农作物细胞水平上的独特作用及其对工业有用分子生产的影响,全面了解TiO2和Fe等金属纳米颗粒在农作物中的作用,将对推进生物能源、环境安全修复、纳米聚合物和生物传感等多个方向的发展具有深远的意义。
该主题起源于基金项目主题nsfT1(2000)在2001年向论文主题lwT0(2001)和论文主题lwT4(2001)扩散演化nsfT1(2000)——lwT4(2001),随着研究的拓展和深化,该主题不断在基金项目和论文中扩散、融合和交叉,逐渐发展出多条子路径,其中,TiO2和Fe等纳米粒子由于其高度的化学反应性而吸附在农作物细胞表面,并能产生氧化应激导致代谢变化是一个重要路径nsfT0(2002)——lwT1(2003)。此外,零价铁纳米颗粒如何诱导氧化应激,并影响光合色素沉着、蛋白质调节和脂质分布相关研究主题也是一条重要路径nsfT2(2008)——lwT2(2009)。涉及的研究内容主要有:评估纳米颗粒诱导的应力对农作物细胞中活性氧和色素积累的影响;利用大数据分析破译纳米处理二倍体中的抗氧化酶的差异蛋白质调节;综合二维气相色谱分析和傅里叶变换离子回旋共振质谱分析独特的脂肪酸甲酯和极性脂质。此外,金属和金属氧化物纳米颗粒对全球重要粮食作物生长和生理的影响有关研究也属于该主题的主要演化路径lwT5(2018)——nsfT8(2019):由于纳米颗粒产品需求的增加,工程金属和金属氧化物纳米颗粒(NPs)的浓度在环境中增加,金属和金属氧化物NPs影响重要农作物的生长、产量和质量,NPs改变了矿物营养、光合作用并引起了氧化应激,诱导了农作物的基因毒性。在低NPs毒性下抗氧化酶的活性增加,而在作物中更高的NPs毒性下降。由于农作物对NPs的接触,NPs浓度在不同的植物部位,包括可能转移到食物链中的水果和谷物增加,对人体健康构成威胁。大多数NP对生理、形态、生化和分子水平的作物都有正面和负面的影响。NPs对作物植物的影响随着农作物种类、生长阶段、生长条件、方法、剂量和NPs暴露的持续时间以及其他因素而变化很大,TiO2和Fe等纳米粒子被认为是优异的吸附剂和高效的光催化剂,能够降解农作物中蕴含大量的全有机氯及其毒性代谢产物。
3.5 讨 论
通过对近20年美国纳米农业领域基金项目和论文数据的实证研究,在一定程度上可以验证本文提出方法的可行性和有效性。此外,与现有学科领域主题演化路径可视化分析方法相比,本文提出的基金项目和论文主题扩散演化路径可视化分析方法,不仅能够分析单一数据的主题演化过程,还能够有效识别基金项目和论文主题之间的扩散演化路径并实现演化路径的可视化,可在一定程度上提高主题扩散演化路径结果的直观性和可读性;此外,由于该图谱基于Web前端可视化设计,因此具有可交互、直观等特点,并且适用于处理海量数据,相较于本地软件工具更加具有拓展性。
4 结 语
本文在调研总结现有学科领域主题演化路径可视化方法的基础上,提出了基金项目和论文主题扩散演化路径识别及其可视化方法,可以用来分析某学科领域的基金项目和论文主题之间的扩散演化路径。创新之处主要有两点:一是研究探索了基金项目和论文等不同科技文献主题扩散演化路径;二是利用Web前端技术实现了对基金项目和论文主题隐含关系的定量化、可视化揭示。最后以美国纳米农业领域近20年的基金项目和论文数据为例进行了实证研究,绘制了交互式美国纳米农业领域基金项目和论文主题扩散演化路径可视化图谱并进行了解读分析,证明了本文提出的方法是可行、有效的。
但是,本文提出的基金项目和论文主题扩散演化路径可视化方法还存在两点不足:一是基金项目和论文主题难以有效解读,专业领域的分析需要领域专家的介入并且依赖情报分析人员的学科背景知识,否则只能概览描述,难以准确揭示基金项目与论文之间的关联机理;二是基金和论文主题关联关系丢失,依赖于主题相似度而建立的关联有一定意义但是并不充分,在未来研究中,将尝试探索结合神经网络技术,从语义层面结合上下文信息揭示主题之间隐含的关联关系。因此,接下来的工作将结合语义分析技术,提升基金项目和论文主题扩散演化路径可视化结果的易用性和可解读性。
