科学交流语义框架模型构建研究
2022-11-28叶均玲
徐 雷 叶均玲
(武汉大学语义出版与知识服务实验室,湖北 武汉 430072)
苏联著名情报学家米哈依诺夫在其科学交流系统理论中,将基于科技文献载体的信息交流称为正式科学交流,把学者之间的直接交流称为非正式交流[1]。互联网流行之前的科学交流过程,受到时空的严重制约,科学创作、发表、评议、传播等环节相对独立且周期较长,科学交流的效率不高。进入网络时代,科学交流的载体和方式都发生了巨大变化,不再受时空限制,科学交流环节不断出现新的交流媒介。科学知识发布与传播的过程表现出较强的即时性和动态性,正式交流和非正式交流过程在新型技术平台支持下逐渐融合,科学交流的效率得到空前提高。除传统书报刊等物理载体及交流渠道外,当前的科学交流环境主要以各类学术数据库、学术社交平台、开放科学数据等为主要技术特征,以网络评审、多渠道分发、多方式沟通等为主要交流手段,并出现了诸如预印本、网络首发、开放获取、开放评审等科学交流实践与理念,形成新的科学交流生态系统。科学成果发表周期缩短,以数字出版物为主要载体的科学知识呈井喷式增长,在看似高效的科学交流系统中,科研人员正面临着被海量科技文献淹没的困境。为了跳脱这一困境,实现高效的科学交流,满足科研人员的各类需求,显然需要新的理论和方法来适应变化中的科学交流活动。科学交流活动围绕着科学知识的生产、消费过程展开,可通过革新科学知识的组织和呈现方式来提升科学交流的效率。语义出版技术[2]通过对数字资源进行细粒度的结构化组织进而为智能化知识服务场景提供支撑,是知识组织与知识服务的有效手段,对于提升科学交流效率具有重要应用价值。实践中,语义出版技术通常表现为使用各类语义模型来对科学交流环节中涉及的各类科学交流实体进行不同粒度的语义关联组织,以出版物为中心来组织各类科技资源的语义出版实践最为常见,从科学交流的动态性及全局性视角来组织各类科学交流实体,进而构建科学交流语义模型的实践较少。本文基于科学交流相关理论及语义出版实践,将科学交流全过程语义化,提取科学交流典型场景和核心要素,并从事件视角构建科学交流语义框架模型,并将该模型应用于科学交流知识服务场景。
1 相关研究
建立科学交流语义框架模型,目的在于对科学交流的特征、演变和核心流程进行语义组织,进而为科学交流场景提供智能支撑。当前的研究实践主要从3个方面开展:宏观科学交流模型设计、具体科学交流环节语义模型构建以及科学交流事件视角下的语义模型设计。
宏观科学交流模型通常基于信息生命周期理论,通过对科学交流过程进行调研和归纳,提取典型场景、核心要素并以流程图的形式来表达其中的科学信息流动情况。具有代表性的模型主要有Garvey-Griffith[3]、Roosendaal[4]、Hurd的科学交流预测模型[5]以及SCLC模型[6]等。其中,Garvey-Griffith模型从时间角度,梳理出了开始研究、完成研究、投稿、出版、年度评审和引用六大科学交流典型事件;Roosendaal模型从功能视角总结了4个科学交流环节,即注册(Registration)、认证(Certification)、告知(Awareness)和存档(Archiving);Hurd的预测模型提出了在2020年将会出现的科学交流要素:电子机构库、数字图书馆、自存档、聚合服务器站点等数字化要素,在当今已得到了验证。SCLC模型将科学交流视为动态循环过程,采用IDEFO建模方法详细梳理了从资助研发、开展研究、成果交流到知识应用4个阶段的近200个科学交流活动。除上述科学交流模型之外,从生命周期视角来对科学交流环节进行建模的实践还很多,如墨尔本大学图书馆的5阶段科学交流模型[7]、中佛罗里达大学图书馆的5阶段科学交流模型[8]、西悉尼大学图书馆的6阶段科学交流模型[9],这些模型基本上都包括了提出研究问题、开展研究、成果发布、传播、存档等环节。
除从宏观角度对科学交流体系进行建模外,还可以从微观视角深入科学交流的具体环节,对不同环节进行语义建模。在具体科学交流环节语义模型构建方面,SPAR[10]是该领域目前最具代表性的本体模型,其包括CiTO/C4O(文本引用类型及统计本体)、BiRO(书目参考本体)、DoCO(文档区块本体)、PSO(出版状态本体)、PWO(出版工作流本体)、PRO(出版角色本体)和SCoRO(学术贡献和角色本体)等15个本体,分别用于组织科学交流不同环节中的文献元数据、文献引用、篇章结构等资源信息以及出版流程、利益相关者、出版状态等相关实体,对于构建科学交流语义模型具有很强的参考价值。此外,还有SWRC(Semantic Web for Research Communities)[11]本体、EXPO(Ontology of Scientific Experiments)[12]本体、SWC(Semantic Web Conference)[13]本体、RO(Research Object Ontology)[14]本体分别用于描述研究社群、科学实验、学术会议和研究对象等科学活动构成要素。
此外,因科学交流活动具有很强的动态性,可从事件视角看待和组织整个科学交流体系。事件视角下的科学交流语义模型以科学事件为基础来组织科学交流活动,事件语义模型[15]一般包括Event(事件)、Agent(代理)、Time(时间)、Place(地点)等事件要素。典型的科学交流事件本体有SEDE(Scholarly Event Description Ontology)学术活动描述本体[16]、SEO(Scientific Event Ontology)科学事件本体[17]。其中,SEDE从事件的施动者和受动者的角度切入,将学术事件解构到原子级别;SEO则注重描述科学事件与其他实体之间的属性关联。
上述实践分别从宏观和微观层面设计了科学交流的实践框架,宏观科学交流模型偏向于科学交流环节的划分,具体环节语义模型偏向于特定的科学交流组成要素,事件视角下的科学交流语义模型侧重于典型科学交流事件的组织。不同框架中涉及的科学交流要素和环节通常具有很强的同质性,但是目前这些框架缺乏统一的组织体系和广泛的关联。因此,亟需一个统一的科学交流语义框架模型,一方面对科学交流的全流程进行系统建模;另一方面对现有的相关实践进行关联。
2 科学交流场景及核心要素分析
2.1 科学交流的典型场景
通过调查现有研究与实践,综合考虑科学交流的生命周期和功能特性,本文归纳出科学交流的六大典型场景:准备研究(Prepare Research)、开展研究(Conduct Research)、发表成果(Publish Results)、传播(Dissemination)、评价(Evaluation)和存档(Archiving)。一般而言,准备研究阶段是科研人员发现科学问题,针对待解决的问题收集与处理文献资源、寻找合作伙伴、获取资助,并制定相应研究方案的过程;开展研究阶段是作者根据已制定的研究方案,选取合适的研究方法开展科学实验、进行文献研究等科研活动,进而将研究结果形成论文、专利或实验报告等多种形式文献资源的过程;在发表成果阶段,作者进行期刊投稿或专利送审,通过领域专家和学者的同行评议,再经过作者修改、编辑排版等环节后由出版商以纸质或数字化形式发布在多种平台上;传播阶段主要是在以科学出版物为代表的文献资源发表以后,科学社区中的研究人员通过正式或非正式渠道获取、阅读和分享文献资源,并基于文献资源中研究结果开展具体学术交流活动的过程;评价阶段主要是相关评价组织通过制定评价方案对研究人员、研究机构、出版物等进行评价得到评价结果并应用的过程;存档阶段是指将纸质或数字版本的文献资源保存在机构库、数据库或者档案馆中,以便于长期访问和广泛传播的过程。
需要注意的是,这6个场景不具有严格意义上的时序关系,实践中科学交流的场景通常存在重叠和交叉。从整个科学交流过程看,前3个场景是科学知识的生产阶段,后3个场景是科学知识的消费阶段。提出研究问题可视为科学交流的起点,推动新一轮科学研究的萌芽、发展和产出。评价和存档阶段产生的评价结果以及保存的文献资源可以作为准备研究阶段查找、筛选和阅读文献的依据,此阶段的科学交流信息会流入下一轮的科学知识生产中。科学交流活动的6个典型场景就产生了有机联系,科学知识的生产与消费形成了循环往复的过程,并在不断的反思和革新中推动着学科的进步。在归纳出6个典型的科学交流场景之后,进一步细化出18个子场景,如表1所示。因科学交流活动深受技术和媒介形态变革的影响,科学交流体系的场景和环节在未来极有可能会发生变化,对科学交流体系的认识应该是一个动态更新、不断修正的过程。
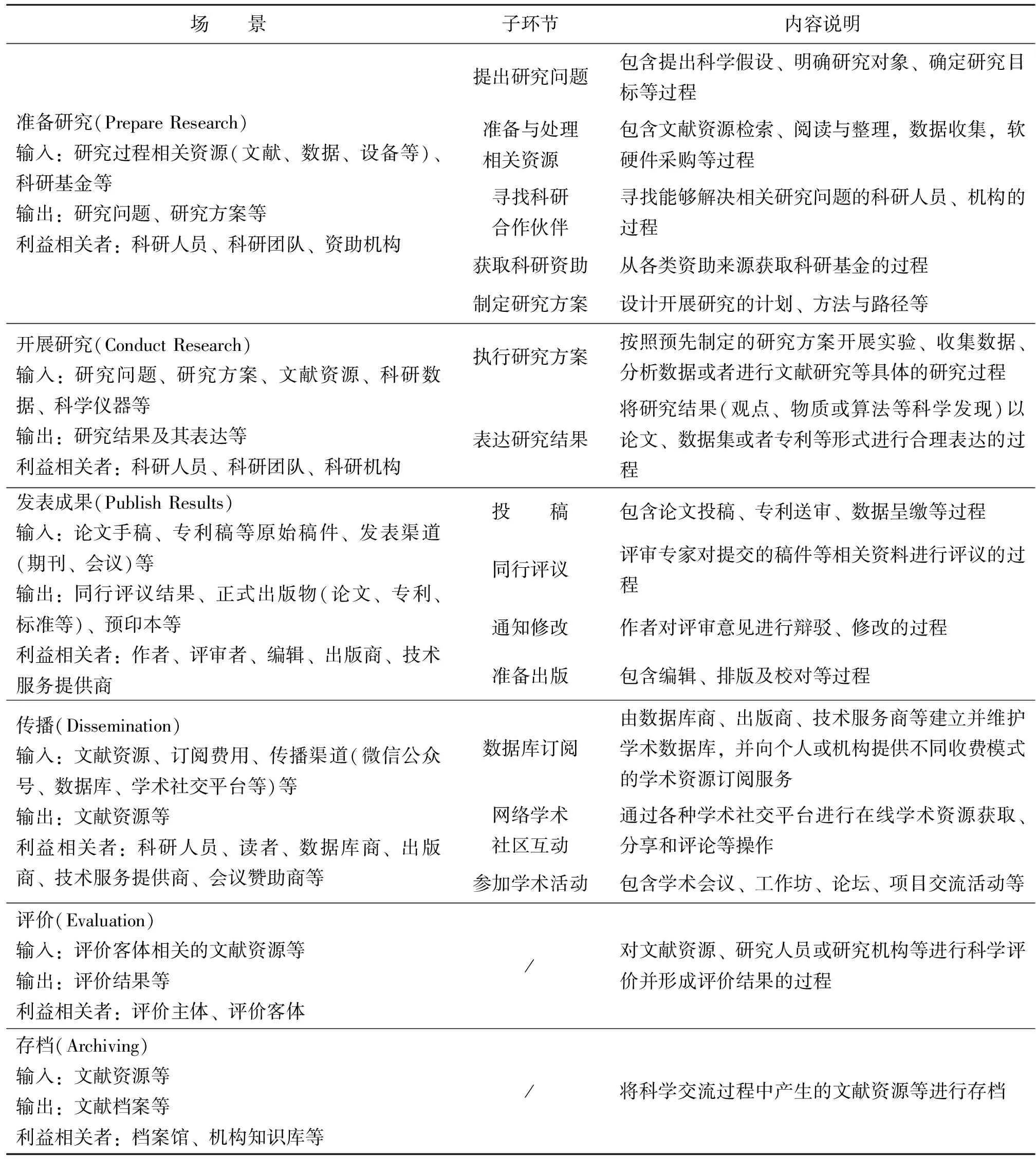
表1 科学交流典型场景
2.2 科学交流核心要素与模型顶层框架
在梳理科学交流典型场景之后,通过进一步识别科学交流的核心要素、设计顶层框架,以结构化、语义化科学交流体系。基于对具体科学交流活动的观察和科学研究的一般经验,本文从事件的视角归纳出科学交流过程的核心要素,即科学事件(Scientific Event)、利益相关者(Agent)、角色(Scientific Role)、时间(Time)、地点(Place)、科技资源(Scientific Resource)。科学事件(Scientific Event)泛指各类具有完整时空信息的科学交流活动,比如典型的同行评议、学术会议等活动,以及文献收集、数据共享、学术汇报等不同粒度的具有研究人员个人特色的科学活动。科学事件一般发生在特定的时间(Time)和地点(Place)情境中。利益相关者(Scientific Agent)即参与科学交流活动的对象,比如研究人员、研究机构、出版商、资助机构等,利益相关者一般以特定的角色(Scientific Role)参与具体的科学交流环节,比如同一个科研人员可分别作为作者、审稿人等参与到论文撰写、同行评议等科学交流环节中。科技资源(Scientific Resource)是具体科学事件开展过程中涉及各类资源的统称,比如准备研究阶段使用的各类学术数据库平台、参考的各类论文资源,开展研究阶段使用的科学数据、算法、实验设备等软硬件资源,发布成果阶段产生的评审信息、不同修订版本的论文等资源。其中,出版物(Publication)是科学交流活动中核心的科技资源,当前的科学交流活动主要围绕出版物的生产与消费展开。
在科学交流典型场景和核心要素的基础上,梳理各要素之间的语义关系,搭建起科学交流语义模型的顶层框架,如图1所示。该顶层框架以科学事件为核心,由相应的组织(Organization)或个人(Person)等利益相关者参与(hasActor),该过程需要各类科技资源的投入(hasInput),并生成各类科技资源产出(hasOutput)。科学事件包括准备研究、开展研究、发表成果、传播、评价和存档6个子类,并通过hasSubEvent、hasNextEvent等语义关系反映子科学事件之间的包含和时序关系,通过holdsRoleInEvent表征相应的利益相关者在该科学事件中承担的角色。
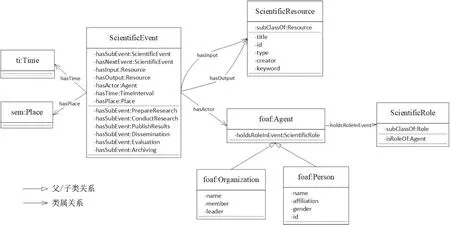
图1 科学交流语义模型顶层框架
3 科学交流语义框架模型构建过程
3.1 构建原则及流程
在确定科学交流的核心要素和语义模型的顶层框架后,本文采用自顶向下的方式,来进一步划分科学交流语义模型中的核心要素及其语义关系。由于不同的科研人员开展具体的科研活动深受个人学术经验的影响,具体科学交流环节的划分、命名、操作过程具有较大的差异。为了保证所设计的科学交流语义模型具有较强的通用性,语义模型中的概念要保证一定的抽象粒度,诸如科学事件概念,因科研人员的个人特色以及科学交流媒介的多样性,使得细粒度的科学事件无法穷尽。因此,本文将科学事件概念划分为6个典型场景和18个抽象的子环节,为未来细粒度科学事件的扩展提供可能。此外,本体作为特定领域的共享概念体系,其构建过程通常需要遵循复用性原则,因此本文构建的科学交流语义框架模型复用了FOAF、SPAR、RO等大量的本体词汇,比如时间概念复用了Time本体,可根据具体的时间信息来选择使用时间点(Time Instant)还是时间段(Time Interval)来描述,遵循复用性原则为语义框架模型的互操作奠定了基础。
对于科学交流语义框架模型的构建过程而言,本文选用本体构建七步法[18],具体构建流程如图2所示。首先基于科学交流的一般经验,梳理科学交流的典型场景和核心要素,建立语义模型的顶层框架;然后通过收集科学交流相关本体、科学交流理论模型等资源,复用相关本体词汇及分类方法;之后使用OWL本体描述语言对科学交流语义模型中的核心要素及关系进行形式化表达,初步形成语义模型的类属结构;再通过随机抽样的方法选取20个不同学科领域的学术会议官网,判断该模型是否蕴含会议网站中提及的科学事件和实体,以验证该模型的合理性;最后,通过具体的科学交流场景对该模型进行实例化,以验证该模型在应用中的有效性。
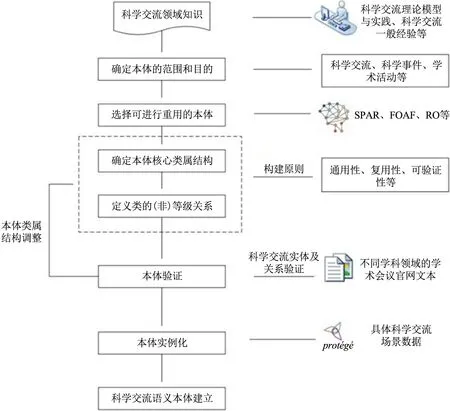
图2 科学交流语义本体构建原则与流程
3.2 科学交流语义本体核心类属结构
在科学交流语义模型顶层框架的基础上,对本体的核心类及属性进行细化和分类,进一步规范和完善科学交流语义框架模型的类属结构,并将该本体命名为科学交流本体(Scientific Communication Ontology,简称SCO)。本体的核心类如表2所示,主要属性如表3所示。
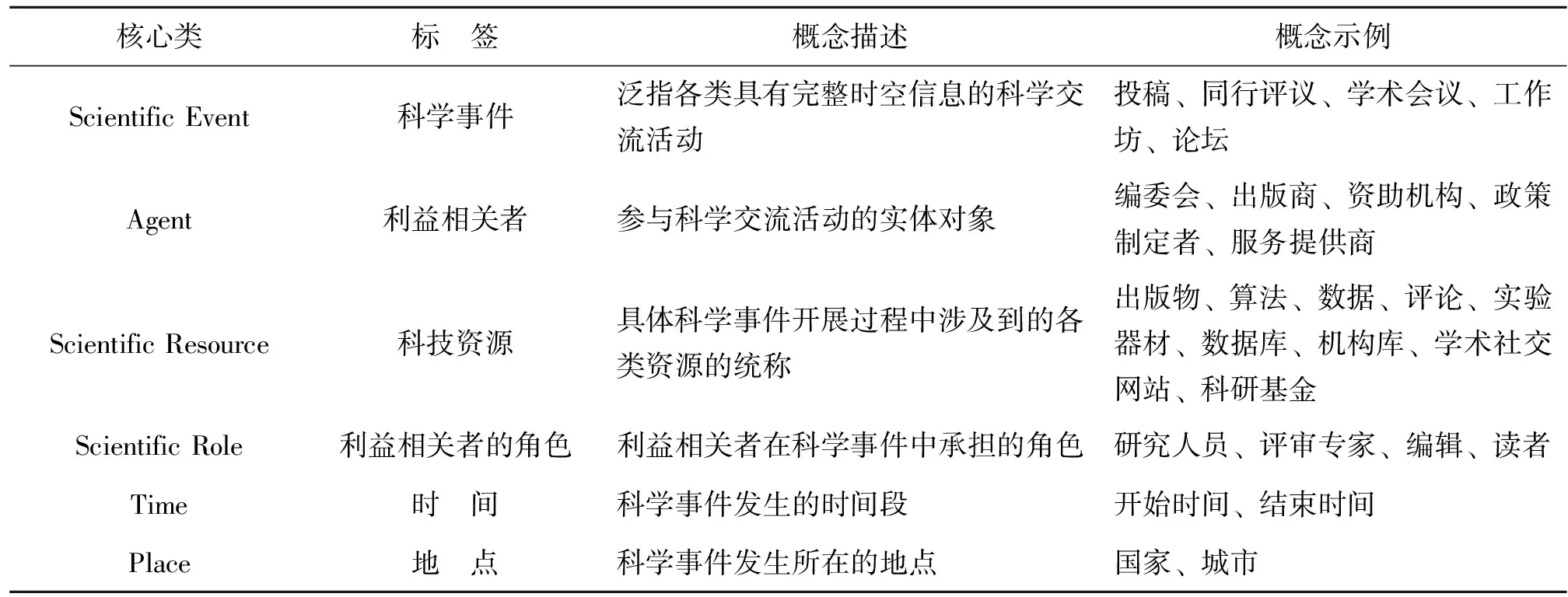
表2 科学交流本体中的核心类

表3 科学交流本体中的主要属性
学术会议是典型的科学交流活动,为了验证该本体模型类属结构的合理性和全面性,本文随机选择20个不同领域的学术会议网站,通过解读这些网页中的征文、会议议程、会议主题等不同板块的内容信息,抽取其中的科学交流相关实体、具体科学领域实体、行为动词等词汇,通过抽象出这些词汇的概念类型来检验这类具体科学交流信息与本文设计的框架模型的映射匹配程度。通过匹配映射操作,验证本文设计的框架模型能够很好地覆盖该类特定类型的科学交流场景。
3.3 科学交流语义框架模型中的本体复用
本体构建中必不可少的环节就是本体复用,在明确SCO类属结构的过程中共复用了20个相关本体,并通过relatedModel关系提供了关联更多相关语义模型的能力。具体涉及SPAR系列本体、SEM事件本体、Time时间本体、DBO地点本体、PAV来源及版本控制本体、RO研究对象本体等。图3呈现了在SCO基础上,通过relatedModel属性来关联科学交流语义本体词汇与被复用的本体的情况,可以看到本文构建的科学交流语义框架模型的核心类属结构都有相对应的本体被复用,该本体可以作为导航、集成和链接其他科学交流相关语义模型的门户,增强科学交流相关实践的体系性和规范性。对被复用本体和复用具体情况的描述如表4所示,在复用方式上,可分为直接复用和间接复用两大类型。其中,直接复用即指通过类、属性的重用或者父/子类、属性的继承进行直接关联,如出版物(Publication)类直接复用FaBiO本体中的对应类(fabio:Publication)、科学事件类(Scientific Event)则继承了SEM本体中的sem:Event类;间接复用指通过属性的定义域、值域或者属性之间的互逆等关系进行间接关联[19],比如对出版物(Publication)类引用计数情况的描述使用了C4O本体中的c4o:GlobalCitationCount类作为其值域(range)。统观表4中被复用的本体,大多数从学术资源等科学交流实体的视角来进行建模,实践中科学社区对同一类型的资源描述存在大量的重复建模现象,而从动态流程视角构建本体的实践较少。本文从事件动态的维度来组织科学交流过程中的各类要素进而构建科学交流语义框架模型,克服了以资源为中心的组织模式不能有效反映科学交流动态性的不足,同时从科学交流全生命周期视角进行建模可以将现有的语义模型以及未来的相关实践都纳入到一个宏观的科学交流体系,加强科学交流领域中语义模型的自动发现、复用、补充、完善等实践环节。
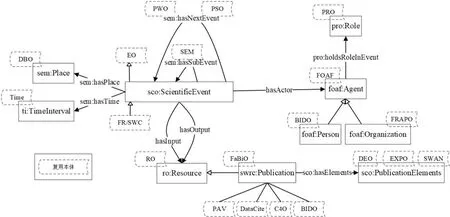
图3 本体复用关联关系
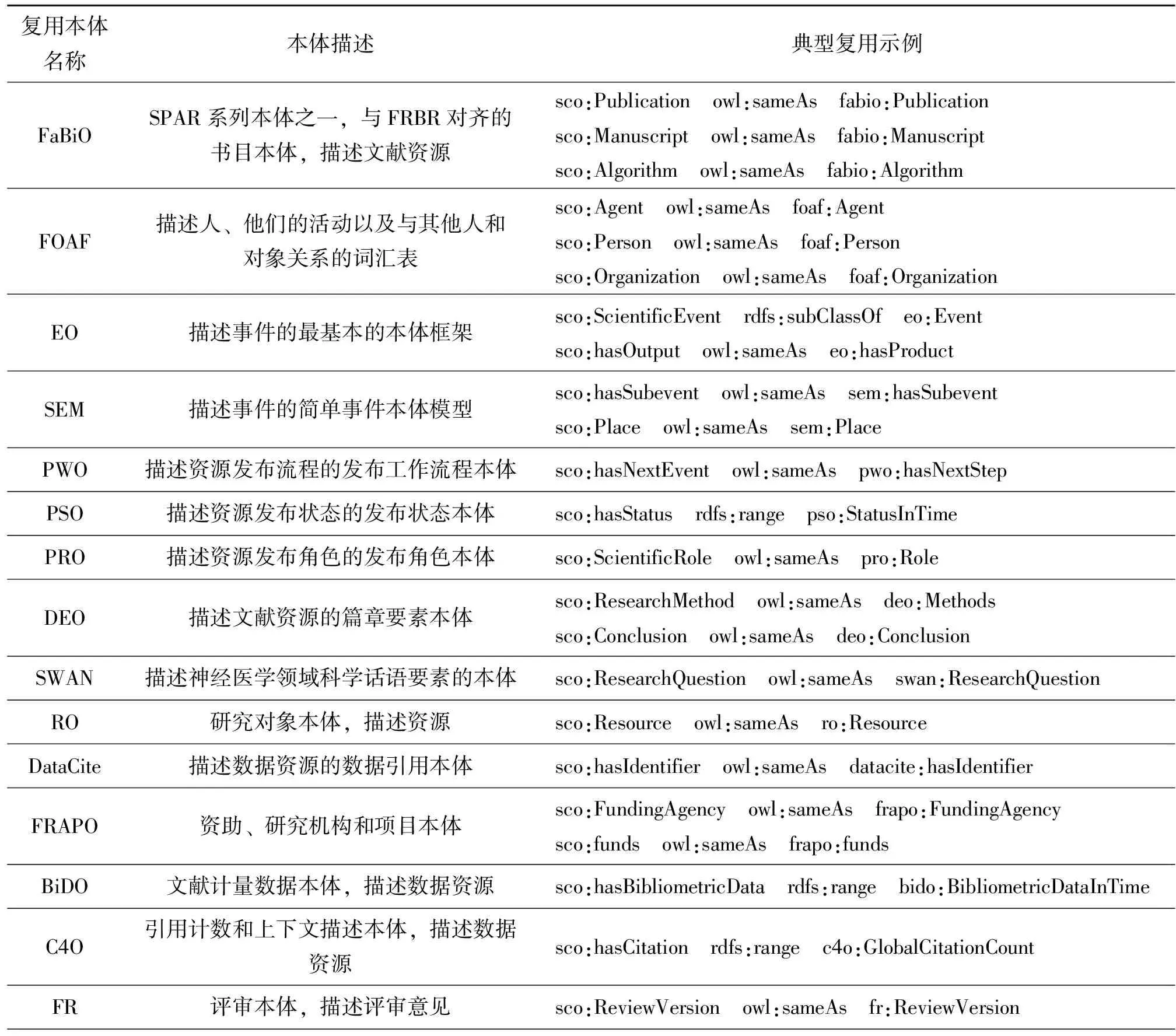
表4 科学交流本体复用情况
4 科学交流语义框架模型实例化示例
基于科学交流语义框架模型,对6个典型场景进行实例化操作,准备研究、开展研究、发表成果和传播阶段以上海交通大学金耀辉教授团队2021年在国际顶尖人工智能联合会议(International Joint Conference on Artificial Intelligence,以下简称为IJCAI)上发表的会议论文《A Generative-Symbolic Model for Logical Reasoning in NLU》为实例,展示相对完整的科学研究过程。评价和存档阶段则分别选取评价科研人员和存档图书两种科学场景,以显示科学交流语义模型的适用性。
4.1 准备研究阶段实例化
准备研究阶段包括提出研究问题、准备与处理相关资源、寻找科研合作伙伴、获取科研资助和制定研究方案等子环节。一般而言,科学研究的开展主要依靠科研人员自主进行研究规划设计,准备研究阶段的实例化可由科研人员借助各类科研辅助工具进行,诸如文献管理工具、科研笔记工具、研究数据管理工具等都可用于对准备研究阶段的行为数据进行收集管理,语义框架模型可嵌入到这类工具中进行实例化。由于该阶段信息的获取程度有限,为了验证该阶段模型实例化的可行性,本文通过事后验证的方式获取这类信息进行实例化。具体而言,合作伙伴和科研资助对应于科研成果的作者、科研基金信息,这些信息可以直接获取并被实例化。而研究问题、研究方案的内容往往隐藏在正文中,一般不能直接获取,需要通过人工或自动化程序对科学论文进行解读与抽取。本文通过人工阅读理解的方式获取这类信息,并通过复用SWAN、FaBiO等本体中的词汇进行实例化,如图4所示。
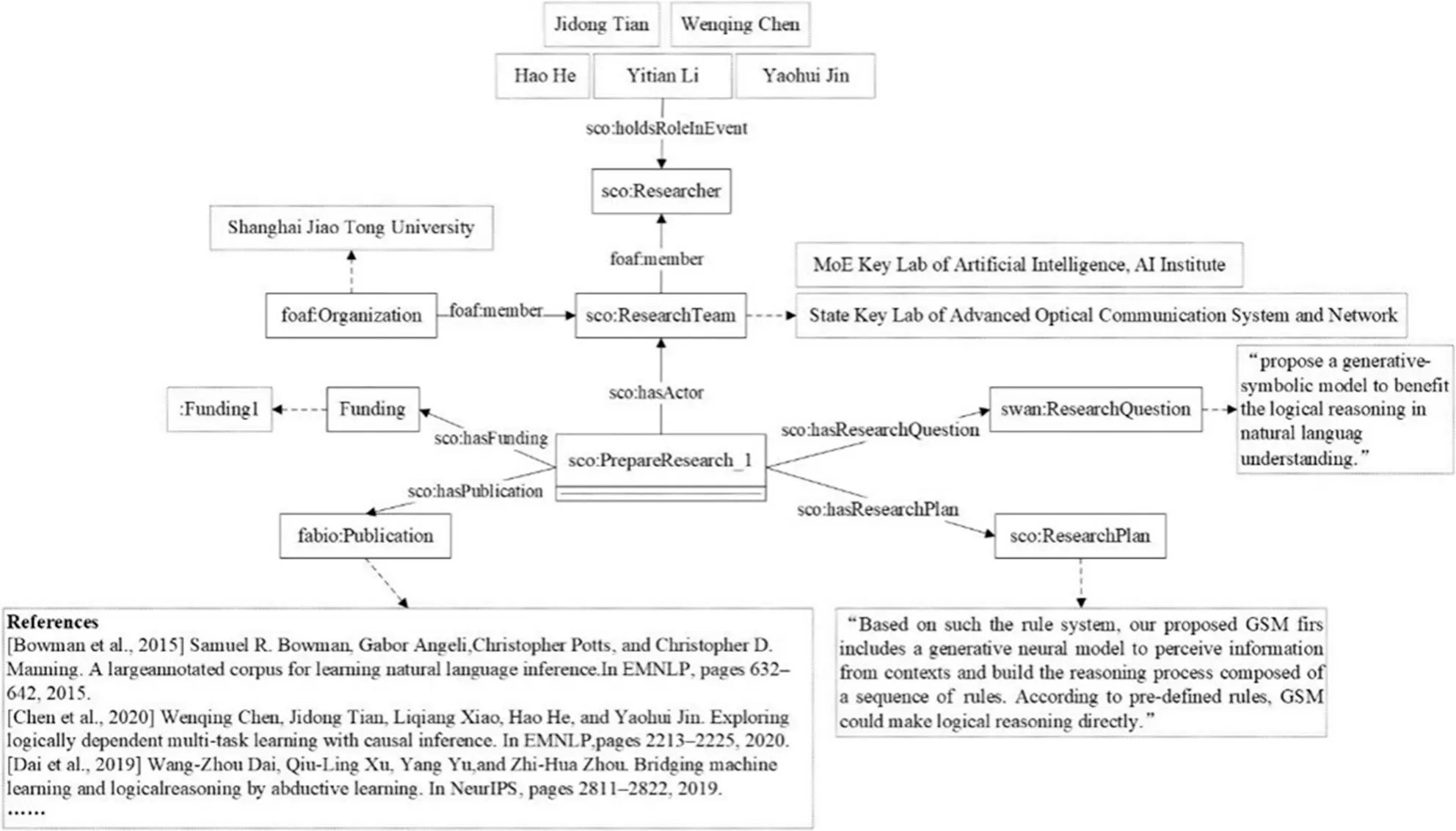
图4 准备研究阶段实例化示例
4.2 开展研究阶段实例化
开展研究阶段包括执行研究方案和表达研究结果等子环节。类似于准备研究阶段,本文也通过从已发表的论文等相关资源中获取开展研究阶段包含的科学事件,如开展科学实验、数据分析等,实例化结果如图5所示。
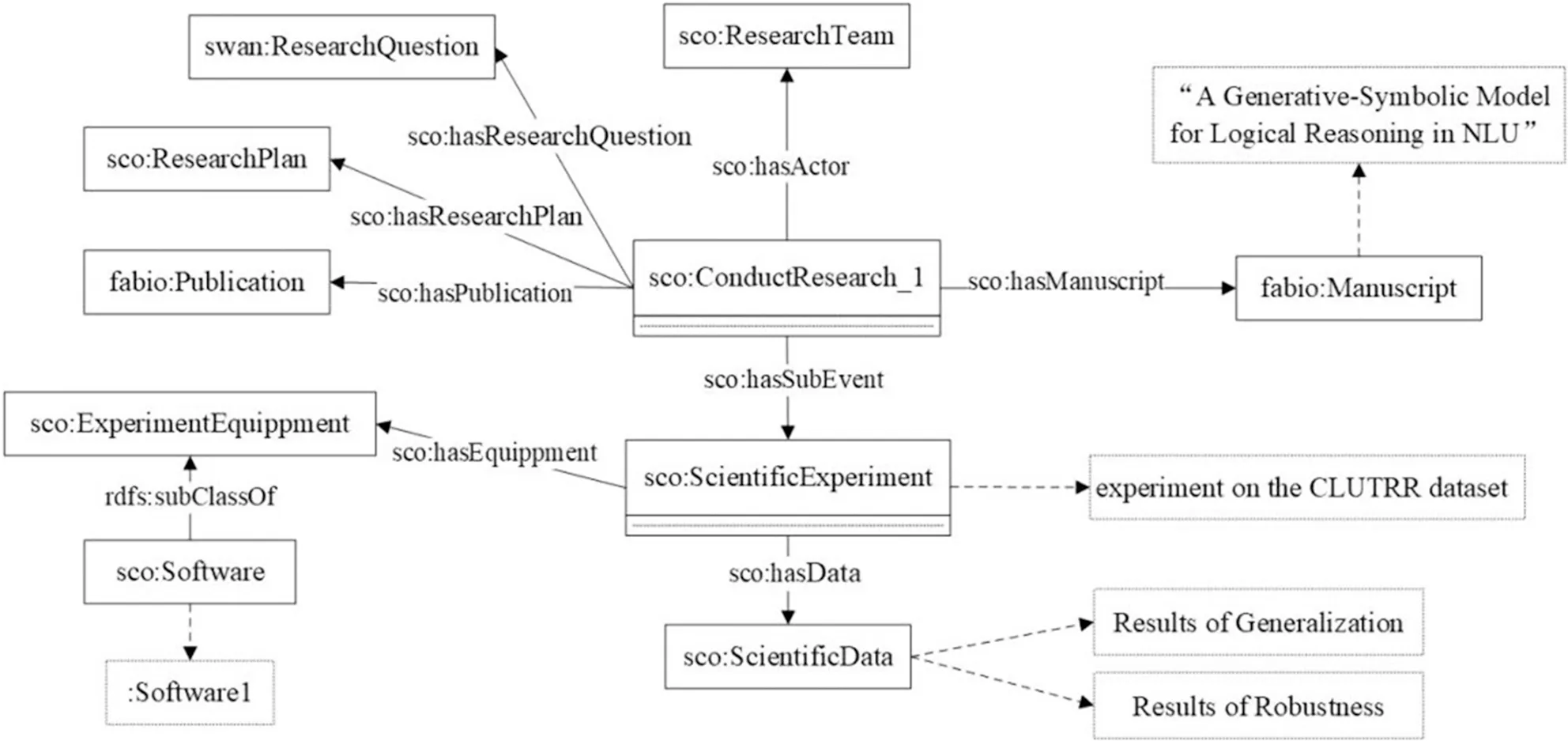
图5 开展研究阶段实例化示例
4.3 发表成果阶段实例
发表成果阶段包括投稿、同行评议、通知修改和准备出版等子环节。发表成果阶段在出版商等外部中介的参与下,此阶段的科学信息相对研究阶段更加开放,但部分科学信息如责任编辑信息、同行评议结果、手稿不同修改版本等都保存在平台内部,其可见性由平台的开放程度决定。因此,发表成果阶段一方面可借助投审稿系统、期刊网站、开放同行评审平台等的公开信息;另一方面也可从已发表文献资源中提取有关科学信息进而对投稿、同行评议等科学事件进行实例化,实例化结果如图6所示。
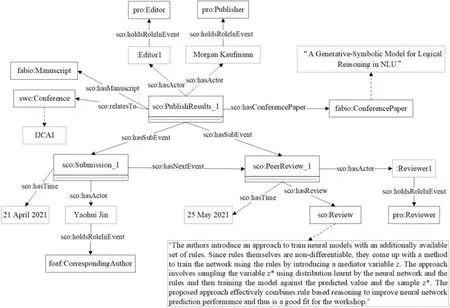
图6 发表成果阶段实例化示例
在实例化的基础上,可以进行语义查询以支撑科学信息的共享和利用。此处以科学出版物在同行评议环节的评审信息的查询为例,查询结果不仅能够增强对评审过程和质量的信任[21],还能为作者提供期刊会议投稿注意事项、审稿风格等信息。此处查找以“NLU”作为研究问题的论文的评审信息,如图7所示。

图7 科学评审结果SPARQL查询
4.4 传播阶段实例化
传播阶段包括数据库订阅、网络学术社区互动和参加学术活动等子环节。传播阶段实例化可借助科学交流工具如学术会议官网、网络学术社区、学术数据库等发布的信息来完成,相关实例信息的开放程度较高但较为分散,可从多种渠道检索与获取,实例化结果如图8所示。
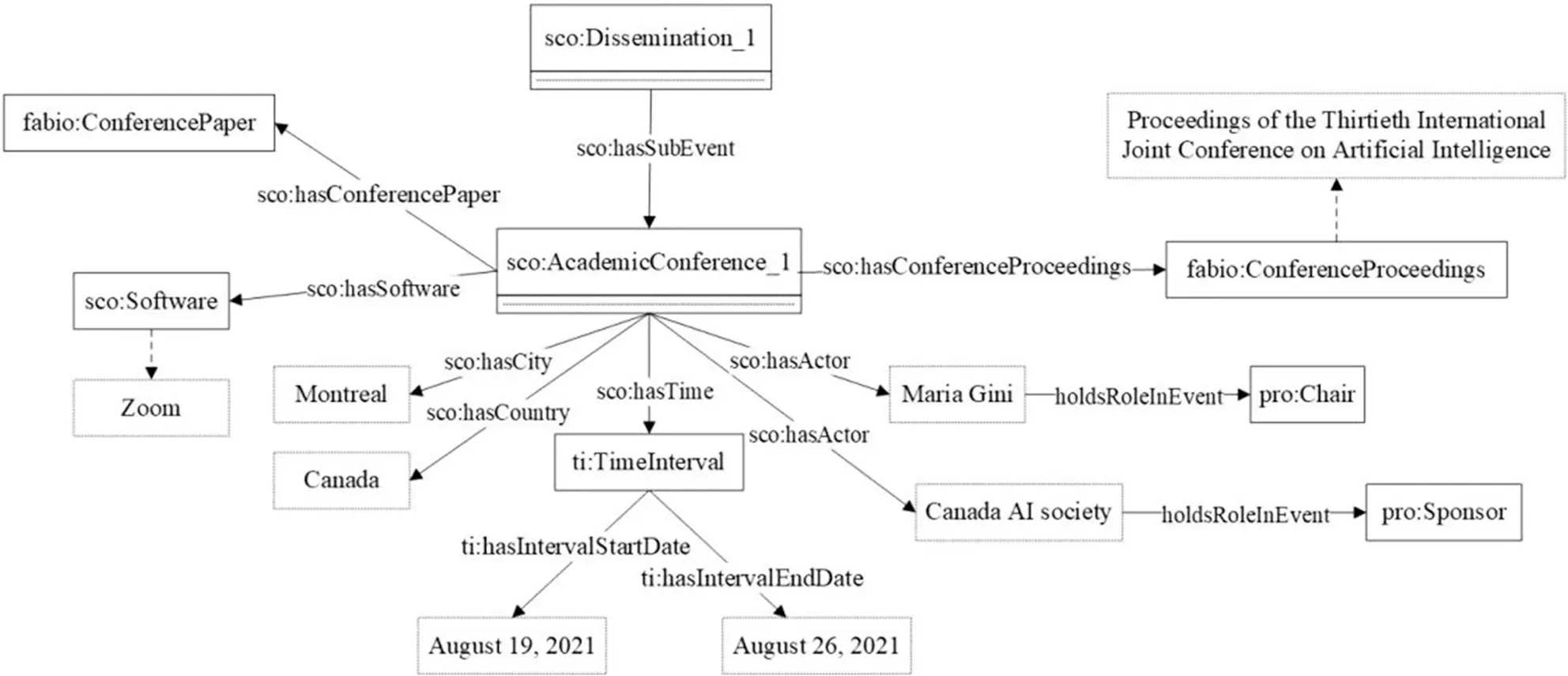
图8 传播阶段实例化示例
4.5 评价阶段实例化
评价阶段是对文献资源、研究人员或研究机构等进行科学评价并形成评价结果的过程。本文以爱思唯尔2021年发布的中国高被引学者年度榜单为例,该评价活动向社会面公开透明,能够借助机构发布的评价相关信息完成实例化过程,实例化结果如图9所示。
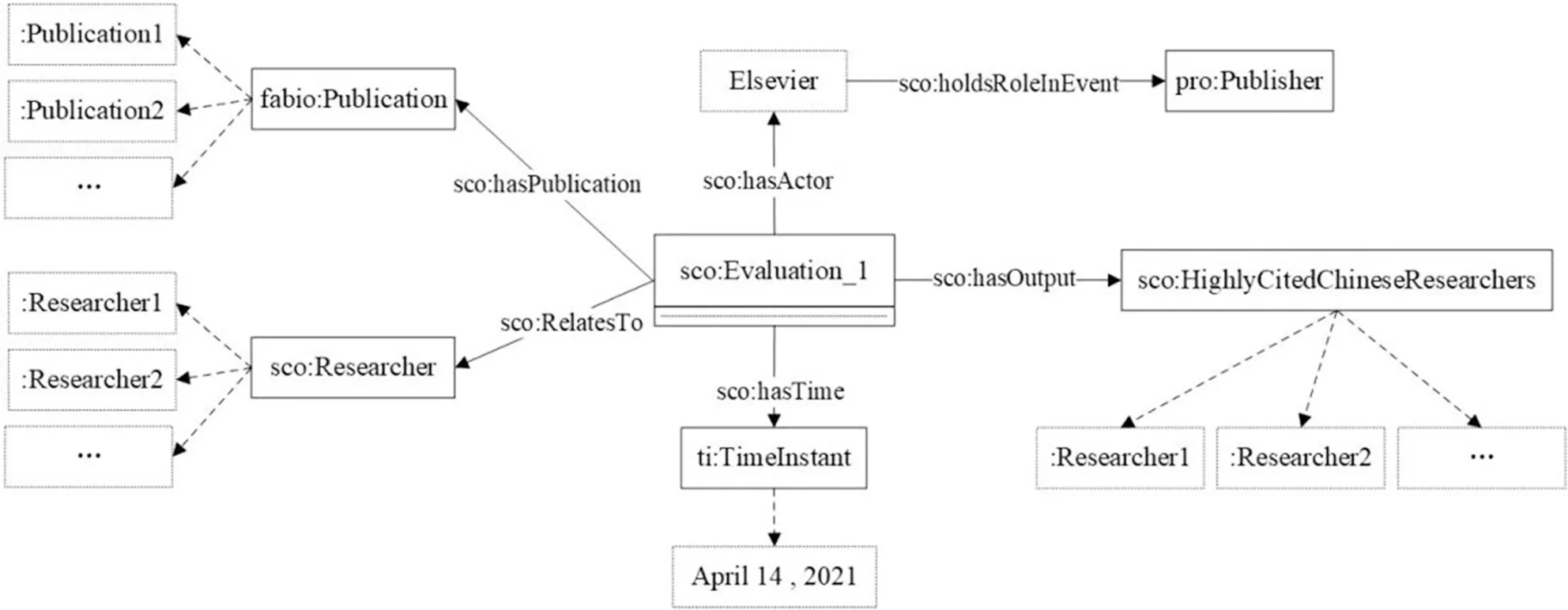
图9 评价阶段实例化示例
4.6 存档阶段实例化
存档阶段是将科学交流过程中产生的文献资源等进行存档的过程。本文以书籍《科学交流与情报学》在武汉大学图书馆存档为例,图书在图书馆员的操作下入库后会生成相应的存档版本,实例化结果如图10所示。
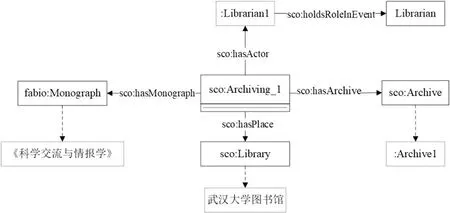
图10 存档阶段实例化示例
从上面的实例化过程可以看出,科学交流的不同环节具有不同的开放程度,这就意味着科学交流语义框架模型的应用需要不同的主体协同参与,才能更好地实现科学交流全流程的语义化。具体来说,可从研究人员视角切入,在其准备、开展研究阶段,就结构化、语义化其研究过程中的数据,为未来科学研究的可共享性和可再现性提供支撑,实现真正的语义出版[22];还可以从出版商视角入手,结构化并开放同行评议流程、评审意见、评审结果等信息,提升科学交流过程的透明性、可信任性。其他参与主体诸如期刊编辑、会议赞助商和技术服务商等都可以在科学交流全流程语义化中发挥作用。
5 总 结
本文提出了一种面向科学交流全流程的语义框架模型,构建了一个可用于描述不同粒度科学交流事件的顶层框架,致力于科学交流全生命周期过程的语义化。本文首先基于科学交流理论与实践,归纳出科学交流的典型场景,再从其中识别科学交流核心要素构建科学交流语义模型顶层框架。基于本体构建原则和方法,完善科学交流语义本体的类属结构,同时进行本体复用情况分析,最后以科学研究实际开展过程作为实例来验证本体结构的科学性。
科学交流语义模型的设计为科学交流的全流程提供了统一的语义框架,其类属结构在设计时保持一定的抽象性来容纳具体科学交流环节的差异性,并通过复用大量语义出版本体模型来增强该框架模型的可重用性。语义框架模型的设计为科学交流各个阶段的语义化实践提供了关联接口和可复用的候选本体集合,也为开拓新的科学交流语义化场景提供了宏观视角。同时,在语义框架模型的具体实例化等实践过程中也看到,不同科研主体介入科学交流的不同环节会产生不同权属与开放程度的科学数据,这就需要多方科研主体参与到科学交流不同环节的语义实践中,进一步开放各个阶段的科学数据,集成多种科学交流工具和平台,革新科学交流生态体系,实现开放科学实践的全流程覆盖与互通,才能更好地发挥语义框架模型在科学交流全流程中的作用,为实现科学交流全生命周期的智能化知识服务场景提供支撑,从而进一步提升当前科学交流的效率。
