基于多模态特征的音乐情感多任务识别研究
2022-11-28刘渊晨裘靖文
王 昊 刘渊晨 赵 萌 裘靖文
(1.南京大学信息管理学院,江苏 南京 210023;2.江苏省数据工程与知识服务重点实验室,江苏 南京 210023)
随着人民对精神文化需求的提升,网络在线音乐已占据了国人日常娱乐生活的重要部分,截至2021年12月,我国网络音乐用户规模达7.29亿,占网民整体的70.7%[1],移动互联网的飞速发展也使得音乐传播范围更广、速度更快,但产生便利的同时,数以万计的音乐作品也对音乐检索和组织管理带来了巨大压力。众所周知,音乐是唤起和表达情感的重要载体之一,有研究认为,音乐情感是检索和组织音乐信息的重要因素[2-5],更有学者发现,情感词是描述和检索音乐最常用的词汇[6]。因此,利用音乐情感对数量庞大的音乐进行分类,帮助组织与管理音乐并提升音乐检索速度成为研究热点之一。
目前主流的在线音乐平台都将情感作为音乐的组织和检索方式之一,且通过“歌单”将某些含有相同或相近情感的歌曲聚合在同一个列表中。大部分的歌单都是由用户按照自己的喜好定制而成,用户可对歌单的名称、简介、类别、所含歌曲等进行编辑。平台利用用户对音乐作品进行情感标注的方式,虽然节省了平台自身歌曲分类的工作量,但也会带来新的问题——用户对歌单、歌曲分类主观性强、标准不统一等,导致分类准确率低下。因此,歌单、歌曲的自动化识别,不仅能够实现歌单与歌曲间情感标签的自动匹配,减少平台人工标注的工作量,也能识别出与所属歌单情感不一致的歌曲,帮助平台把控用户自定义歌单的质量,提升音乐信息组织效果与检索精度,助力完善个性化音乐推荐系统。
网易云音乐是国内首个推出用户定制歌单功能的音乐平台[7],平台设置了歌单的情感分类,且其歌单质量较高,很多歌单的播放量能达到上千万,甚至上亿,同时,每种类别的歌单数量基本一致。因此,本文以网易云音乐平台的歌单与歌曲作为研究对象,进行针对不同对象的多种情感识别任务:①对歌单而言,歌单的名称与简介等描述文本中通常包含情感词汇,本文基于歌单的描述文本构建情感词典,融合情感词典与机器学习进行歌单情感分类任务;②对歌曲而言,歌词与曲调均蕴含着丰富的情感信息[8],本文提取歌词的文本特征与音频的时频域特征、梅尔声谱图等,基于深度学习进行面向歌曲的单模态与多模态情感分类任务,分析对比分类效果。
1 相关研究
目前,国内外针对音乐情感分类的研究工作可分为三大类:单独基于音频特征、单独基于歌词特征以及融合歌词和音频特征的多模态音乐情感分类。在最近几年基于音频特征的研究当中,大多都是通过提取音乐的频谱、音色、力度和节奏等特征,再利用机器学习或深度学习算法进行情感分类,如贝叶斯、K-邻近和支持向量机等机器学习算法[9-13],以及卷积神经网络和长短期记忆网络等深度学习算法[14-16]。而很多音乐不止具有音频,还带有歌词文本,且歌词中所能体现的语义信息非常丰富,因此近年来,仅基于歌词对音乐进行情感分类的研究也相继出现[17-19]。基于歌词特征的音乐情感分类本质上来说就是文本分类研究中的一个分支,因此文本情感分类采用的基于情感词典、机器学习或深度学习的方法也都适用于音乐歌词的情感分类。
音乐是很复杂的情感载体,音频和歌词并不是完全割裂的,而是相辅相成、相互呼应,因此,融合音频和歌词特征的多模态音乐情感分类研究也逐渐涌现。陶凯云[20]采用了基于音频和歌词特征的多模态音乐情感分类方法,并对传统的子任务结合晚融合法进行了改进,改进后的分类准确率达到了84.43%;陈炜亮[21]通过对音频的MFCC和MIDI两种特征进行融合,再与歌词文本特征进行二次融合,首次特征融合的效果要好于单一特征,二次特征融合的分类准确率又得到了进一步提升。以上的多模态音乐情感分类研究都是将音频特征和文本特征转成了数值,部分学者也开始利用声谱图来表征音频特征。朱贝贝[22]提出了一种基于音频低层特征和卷积循环神经网络的音频情感分类模型,该模型以声谱图和音频低层特征作为输入特征,与歌词文本情感分类分别进行决策融合和特征融合,不论哪种融合方式得到的情感分类准确率均高于单一特征分类;谭致远[23]分别采用短时傅里叶声谱图和梅尔声谱图与歌词文本进行子任务结合晚融合,实验结果表明,梅尔声谱图与歌词融合后的结果要好于短时傅里叶声谱图与歌词融合的结果。
通过文献调研发现:①现有的研究基本都是针对单首歌曲的情感分类,缺少对歌曲集合——歌单的研究,而歌单作为当下各个音乐平台最流行的音乐组织方式和检索单位,歌单的名称、介绍等外部描述特征也在一定程度上体现出了歌单内的歌曲情感。因此,本文首先对歌单进行情感分类研究,弥补这部分的研究空白;②融合音频特征和歌词特征的多模态情感分类方法效果要好于基于单一特征的方法,但研究者们的侧重点一般更偏向于音频特征的处理与分析,对于歌词文本的处理通常只采用一种分类方法,未能充分发挥文本情感分类已具有比较成熟的研究方法的优势。因此,本文对歌词特征采用多种情感分类方法进行分析并比较结果,选出最优的方式再与后续音频特征的分类结果进行融合,以达到最佳的分类效果。
2 数据来源及实验设计
2.1 研究总体框架
本文研究框架如图1所示,主要包括基于描述的歌单情感分类、基于歌词的歌曲情感分类和融合音频的歌曲情感分类三大部分。主要步骤为:①采集网易云音乐歌单的名称、介绍等外部描述信息,利用基于情感词典的方法、基于机器学习的方法以及将情感词典与机器学习方法结合起来3种方式进行情感分类,分析实验结果;②挑选出歌单内的歌曲,利用5种文本分类模型对歌词文本进行情感分类,选出最佳的分类结果,作为多模态融合的组成部分;③提取歌曲音频特征,利用多层CNN模型对音频进行情感分类,采用决策级融合的方式,与歌词文本分类中的最优结果相融合,调节两部分的权重值,确定最终歌曲属于每类情感的概率,提升分类准确率。
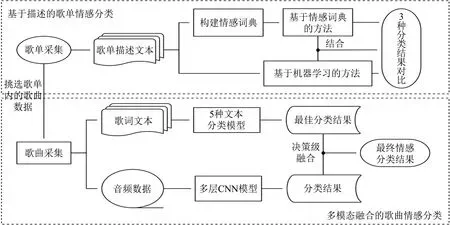
图1 研究框架
2.2 数据来源与预处理
网易云音乐平台将音乐情感分为12个类别,类别设定的初衷是提升用户体验,所以其界限划分并不明晰,不适合用于学术上的情感分类。针对这一问题,本文借鉴了Hevner音乐情感分类方式,Hevner模型[24]是出现最早、影响最为广泛的模型,被广泛应用于计算机音乐情感识别领域。该模型将音乐情感归为8大类,笔者从网易云音乐的情感分类中找到与Hevner模型相对应的类别,如图2所示,分别为安静(quiet,Q)、快乐(happy,H)、伤感(sad,S)、兴奋(excited,E)4种情感。

图2 网易云音乐歌单情感与Hevner情感模型对应关系
本文使用八爪鱼采集器登录网易云音乐网页端(https://music.163.com/)爬取上述4类歌单的链接、标签(即歌单的情感分类)、创作者、名称、介绍,以及歌单所包含的歌曲等数据,爬取得到的主要字段信息如表1所示,其中加粗斜体部分为本文实验所用特征。针对歌单的情感分类中,所用到的字段为歌单标签、歌单名称与介绍;针对音乐的情感分类中,所用到的字段为歌单标签、歌曲歌词和音频,其余字段用于数据的去重、筛选等。
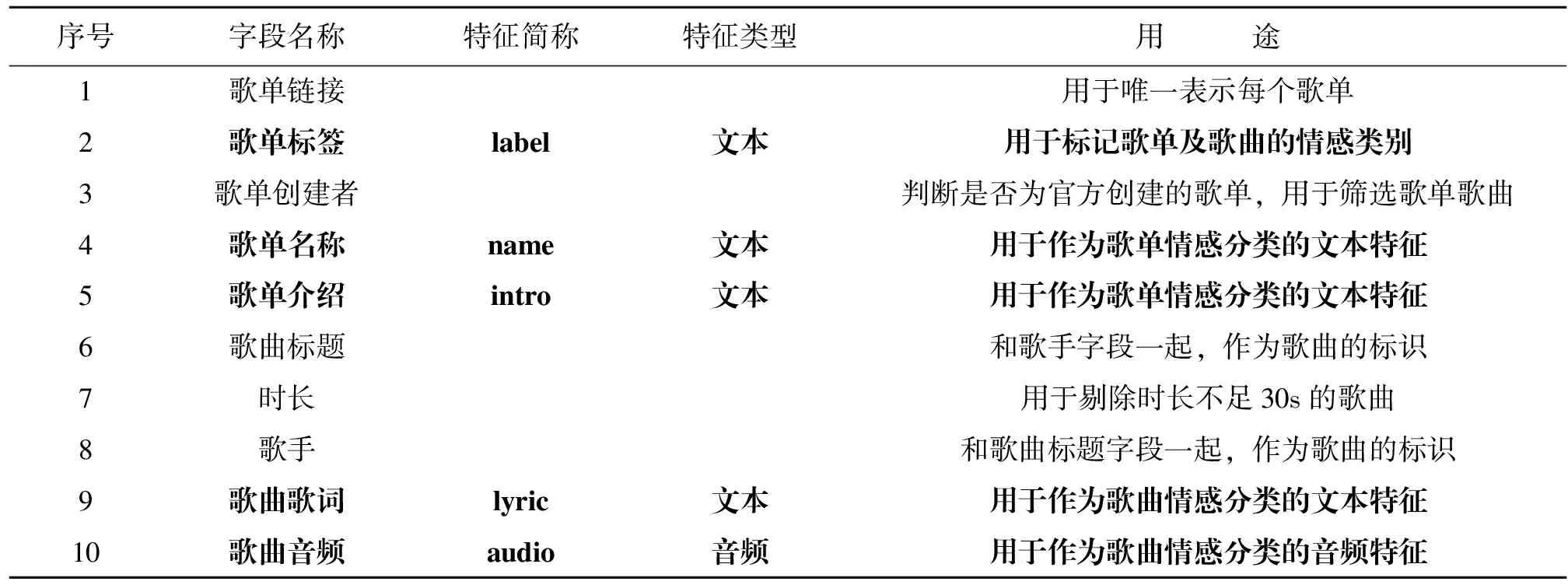
表1 爬取的主要字段信息
对于歌单数据,本文进行了如下预处理:①根据歌单链接,对重复歌单予以删除;②去除歌单名称和介绍中的特殊字符、数字等,只保留中文文本,同时利用Langconv工具包将繁体中文转化为简体;③删除名称或简介缺失的歌单;④删除名称和简介中都没有体现情感特点的歌单,提高数据质量。经过以上处理步骤,共保留了4 010条数据,包含969条安静歌单、990条快乐歌单、1 040条伤感歌单和1 011条兴奋歌单,4类歌单的数据量相当,便于后续结果比较。
对于4类歌单下的歌曲数据,本文的挑选方式为:①由平台官方账号创建的歌单中的歌曲:鉴于官方账号权威性强,且官方账号创建的歌单数量及歌单包含的歌曲数量都非常少,对歌曲的情感分类标准较为严格,此类歌曲相当于权威的专家标注数据;②被至少3名歌单创建者标记为同一种情感类别的歌曲:由于一首歌曲可以出现在不同的歌单中,由不同用户进行情感标注,因此选取多人标注的歌曲可大大降低情感被错误分类的概率;③剔除缺少歌词的纯音乐。经过上述筛选操作,本文在安静、快乐、伤感、兴奋这4个类别下分别挑选出1 000首歌曲,以保证数据的均衡性。
对于歌曲的歌词数据,本文的预处理方式为:①去除作词、作曲等与歌词本身无关的信息,去除非中文歌曲中的外语歌词,仅保留翻译后的中文文本,去除无意义的标点符号、空格、换行符等,将繁体字转化为简体字;②去除同一首歌曲中的重复段落,减小分类模型压力,保证歌词字数在500个字以内;③对歌词数据添加索引和情感标签,索引为4位数字的序号,情感标签即安静、快乐、伤感、兴奋分别为Q、H、S、E,方便后续的研究工作。处理后的歌词数据如表2所示。

表2 处理后的歌曲歌词示例
对于歌曲的音频数据,本文的预处理方式为:①利用解码ncm格式的软件,将平台加密后的ncm音乐格式转化为mp3格式,便于音频处理;②对音频数据进行重命名操作,按照上一章节中对歌曲添加的索引,更改音频的名字为相应的4位数字编号,方便后续与文本分类结果的融合;③利用Pychorus工具包截取30s的副歌片段,主要考虑有以下4点:ⅰ.完整的音频数据文件过大,完整音频数据会对硬件基础设施造成巨大压力,延长实验时间;ⅱ.歌曲一般由前奏、主歌、副歌(又叫高潮)、过门音乐(或称间奏)和结尾5部分组成,每部分的旋律、节奏等差距较大,例如前奏一般都很平缓,副歌部分情绪波动较大,使得每部分体现的情感也会有所不同,且主歌和副歌部分通常会重复多次[25],因此若采用整首歌曲进行情感分类,会增加不必要的冗余信息,影响分类效果;ⅲ.副歌部分是音乐情感爆炸式喷涌的部分,能够强烈触发听众情感并引起共鸣[26];ⅳ.有研究表明,从语音中截取出片段进行情感分类的准确率要高于用整段语音的效果[27]。基于以上4点原因,本文提出截取最能代表歌曲情感特征的副歌部分进行情感分类的方法。
2.3 基于描述的大粒度歌单情感分类研究
通常情况下,歌单的名称和介绍都是对歌单内容或风格的概括性描述文本,文字中会出现较为明确的情感词语,方便听众快速进行选择。针对这一特征,本文对歌单的情感分析方法如图3所示:①根据歌单描述文本的特征构建相应的情感词典,利用THULAC中文词法分析工具包[28]对文本分词,采用Gensim模块的Word2vec对每个词语进行向量化表示,根据网上已训练好的大语料模型,计算歌单名称和介绍中每个词与各类情感词语之间的相似度,加权求和后,得分最高的类别即为歌单情感所属类别;②将歌单名称和简介拼接到一起,对分词后的词向量相加并求平均值,以此来表示歌单描述文本的语义向量,之后分别采用RF(Random Forest,随机森林)、LightGBM、XGBoost 3种机器学习算法进行情感分类,取十折交叉法的平均值作为最终结果;③将第①步中,每个歌单归属于不同情感的得分,与歌单描述向量一起,共同作为上述3种算法的输入特征,再次利用十折交叉法进行实验,对比实验结果。
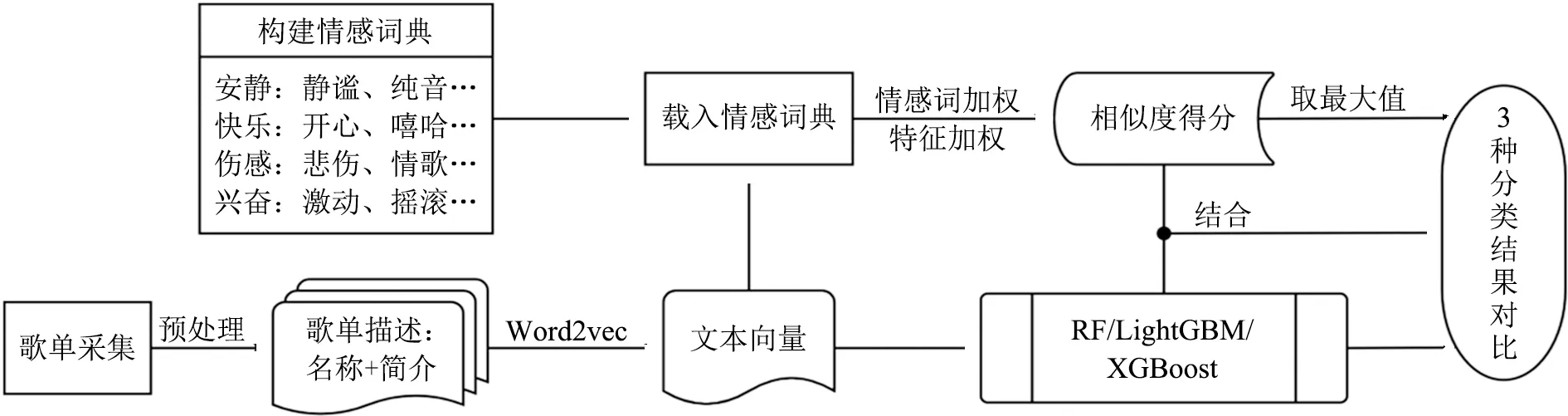
图3 基于描述的歌单情感分类研究流程图
对于歌单情感词典的构建,本文通过统计歌单文本词频,发现每类的情感词典可以由近义词、相关场景以及音乐风格3部分构成,如表3所示。其中,近义词的选取参照了哈工大信息检索研究中心同义词词林扩展版[29];相关场景表示每类情感产生于何种场合或情境下;音乐风格代表音乐的类型,不同的旋律、节奏等给听众带来不同的情感认知。最终得到的情感词典共包含448个词语,每类情感均包含112个词语。

表3 情感词典所含词语示例
2.4 基于歌词的小粒度歌曲情感分类研究
与歌单名称、简介等描述性文本不同,歌曲歌词的内容千变万化、语义丰富,因此本文采用的研究方法如图4所示:①采用Ngram2vec预训练模型[30]将歌词文本转化成300维的向量,该模型的训练语料包含百度百科、中文维基百科、人民日报、搜狗新闻、知乎问答、微博、文学作品等多个领域,可以全面覆盖歌词文本;②采用TextCNN、TextRNN、TextRNN+Attention、TextRCNN和FastText 5种经典文本分类方法,对歌词文本向量进行分类,探究不同模型的情感分类效果;③选出歌词情感分类效果最佳的模型结果,用于后续多模态结果融合研究当中。
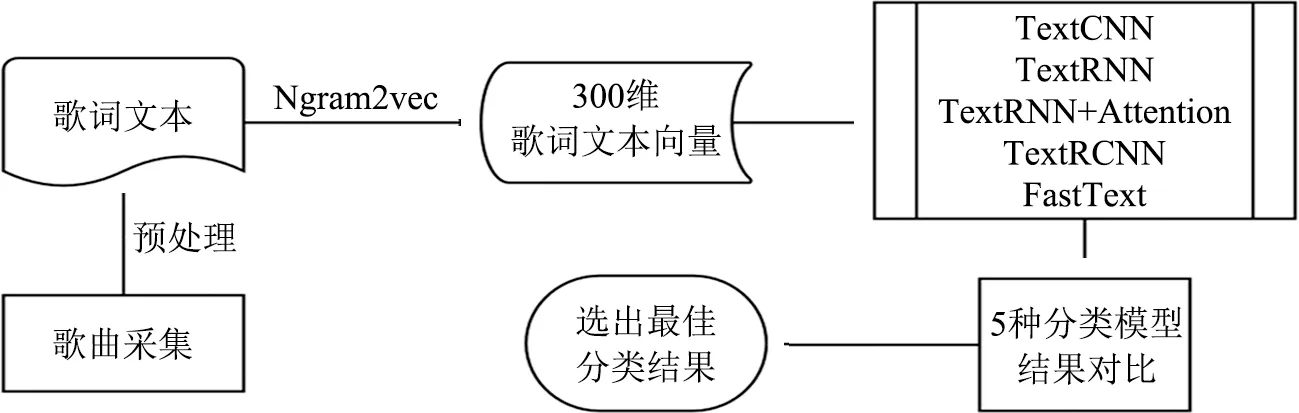
图4 基于歌词的歌曲情感分类研究流程图
在歌词文本表示中,Ngram2vec模型是由Zhao Z等[31]于2017年提出的语言模型,该模型是将Ngram模型纳入各种基本的文本嵌入模型,如Word2vec、GloVe、PPMI和SVD等。Ngram是一种统计语言模型,它根据前n-1个词来预测第n个词,即用大小为n的滑动窗口对文本里面的内容进行操作,按照字节形成长度为n的字节片段序列,优势在于包含了前n-1个词所携带的信息[32]。Qiu Y Y等[33]也发现引入Ngram能够有效提升词语相似性和词语类比任务的模型性能,因此本文将其用于歌词文本的表征。
2.5 融合音频的小粒度歌曲情感分类研究
根据孟镇等[34]的研究,深度学习方法下的音频分类效果优于机器学习方法,且融合音频的时域、频域特征和梅尔声谱图的方法要好于基于单种特征的方法,因此本文融合音频的情感分类方法如图5所示:①抽取音频的时域和频域特征,包括:中心距、过零率、均方根能量值、节拍、梅尔倒谱系数、色度特征、频谱质心、谱对比度、频谱衰减、频谱带宽等,计算上述特征的均值、方差、偏度、峰度等统计值,拼接成518维特征向量;②利用librosa工具包将音频转成梅尔声谱图,梅尔声谱图是将音频信号经过短时傅里叶变换后把频率转换为梅尔尺度,再经过梅尔滤波器组把幅度值加权求和,将梅尔频谱拼接起来所形成的声谱图。本文中梅尔声谱图的采样高度为64,宽度为256,每个连续帧包含的样本数为2 048。4类情感的梅尔声谱图示例如图6所示,可看出不同情感下的梅尔声谱图间存在明显差距,因此可以将音频分类问题转为图像分类问题;③由于CNN模型在图像分类问题上的优秀表现,所以本文构建了多层CNN模型,如图7所示,卷积核大小设为3,利用多层感知机将第①步提取的518维音频低层特征向量转化为128维向量,与64×256维的梅尔声谱图向量进行拼接,输入到多层感知机中计算得到4类情感的概率,概率最大的类别即为待分类歌曲所对应的情感类别;④利用线性加权融合法,将基于音频的情感分类结果与最优的歌词文本分类结果相结合,调节两部分的权重值,确定最佳分类结果。
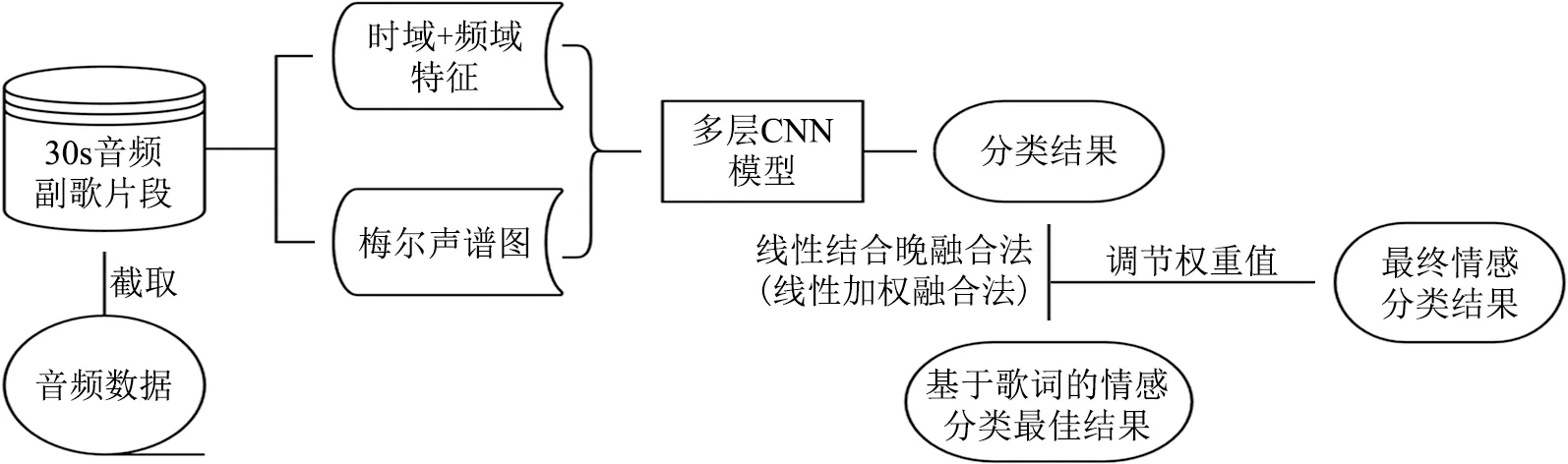
图5 融合音频的歌曲情感分类研究流程图
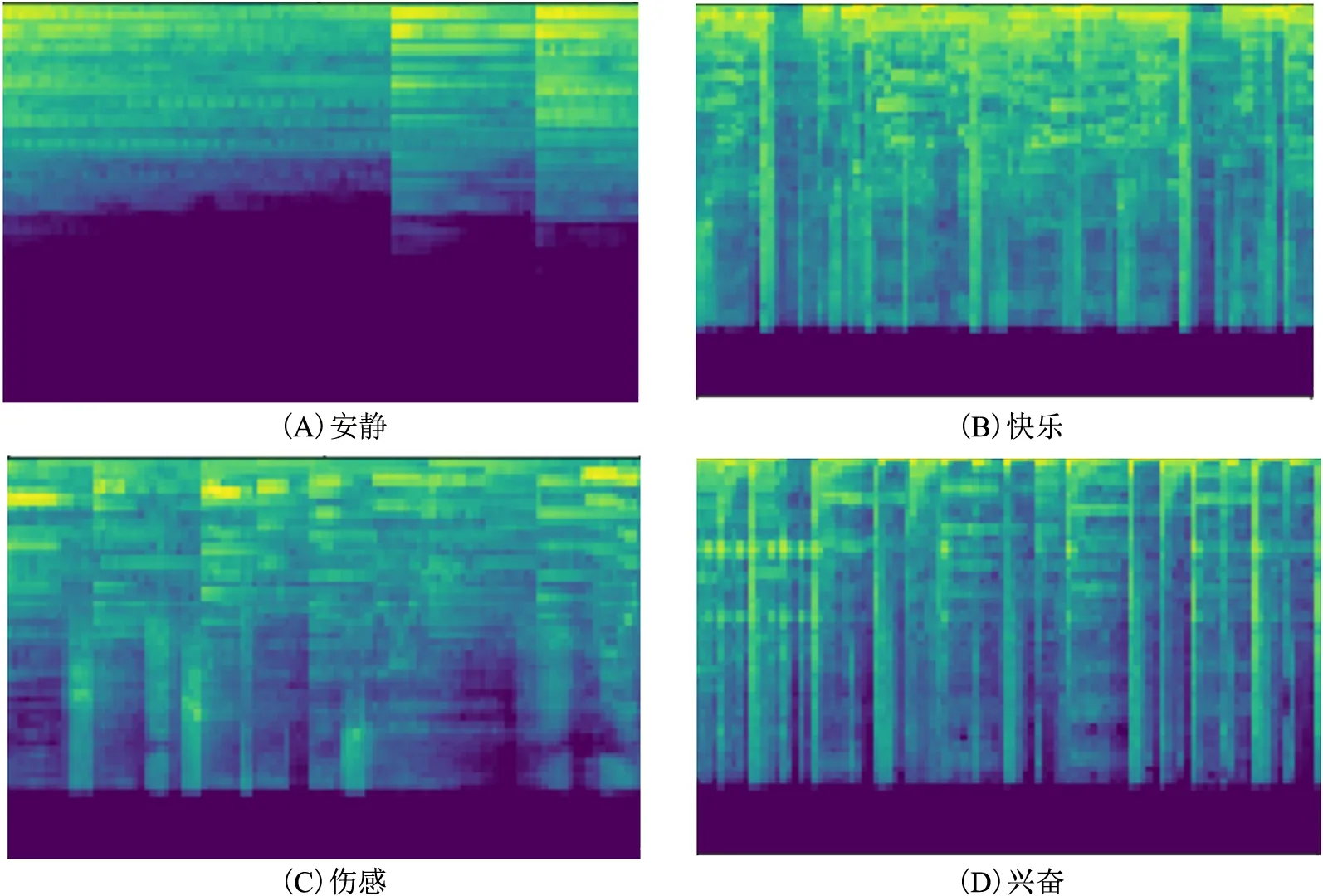
图6 4种情感歌曲的梅尔声谱图示例
3 实验结果及分析
3.1 分类模型评价指标
本文所研究的情感分类问题本质上是多分类问题,因此采取的评价指标包含准确率(Accuracy,见式(1))、精确率(Precision,见式(2))、宏平均精确率(Macro-P,见式(3))、召回率(Recall,见式(4))、宏平均召回率(Macro-R,见式(5))、F1值(见式(6))和宏平均F1值(Macro-F1,见式(7))7种。
(1)
(2)
(3)
(4)
(5)
(6)
(7)
其中TP为实际为真预测也为真的样本数,TN为实际为假预测也为假的样本数,FP为实际为假预测为真的样本数,FN为实际为真预测为假的样本数,class_num为总的类别数。Accuracy即为在所有样本中分类正确的样本比例,Macro-P、Macro-R和Macro-F1则分别为每类样本的精确率、召回率、F1值的平均值。以上7个评价指标的取值范围均在0和1之间,越接近1表明分类效果越好。
3.2 基于描述的大粒度歌单情感分类
1)基于情感词典的方法
在将歌单描述文本与情感词典进行相似度计算时,本文对歌单的名称与介绍分别赋予了不同的权重值a和1-a,计算方式如式(8)所示,S1为歌单名称在不同情感下的得分,S2为歌单简介在不同情感下的得分,最终S在哪一类情感下得分最高,该歌单则归属于相应的情感类别。
S=a*S1+(1-a)*S2
(8)
根据以上方法进行实验,以0.05为歌单名称权重a的调节单位,不同权重取值的实验结果如图8所示,当歌单名称的得分权重a为0.6,歌单简介的得分权重为0.4时,歌单情感分类的整体准确率最高,为68.18%。
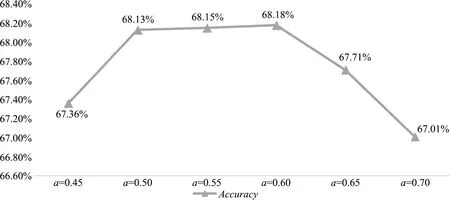
图8 调节权重a歌单情感分类整体准确率
在权重a设定为0.6的情况下统计每类歌单数据的精准率、召回率和F1值,结果如图9所示。
从图9可以看出:①F1值的排序为:S>Q>H>E,且S的Precision、Recall和F1值都已经接近80%,相较于其他类别的分类效果遥遥领先,表明用户对于伤感类歌单的文本描述会较为明确,这可能与网易云平台以“网抑云”著称有关,用户偏爱在网易云平台上宣泄负面情绪[35],所以对于伤感歌单名称和简介的描述也会带有较为明显的悲春伤秋色彩,与其他3类的区分度较高。②H的Precision最低,仅为54.29%,E的Recall最低,仅为42.73%,且二者的F1值均与S、Q有较大差距,E的F1甚至不足60%,探究原因主要为快乐和兴奋两个词语本身的含义区分度不高,很多歌单创建者对兴奋情感的描述与快乐过于接近,导致很大一部分兴奋类型的歌单被识别成了快乐类型,使得E的召回率变低,H的精准率相应变低,从而也拉低了整体的分类效果。
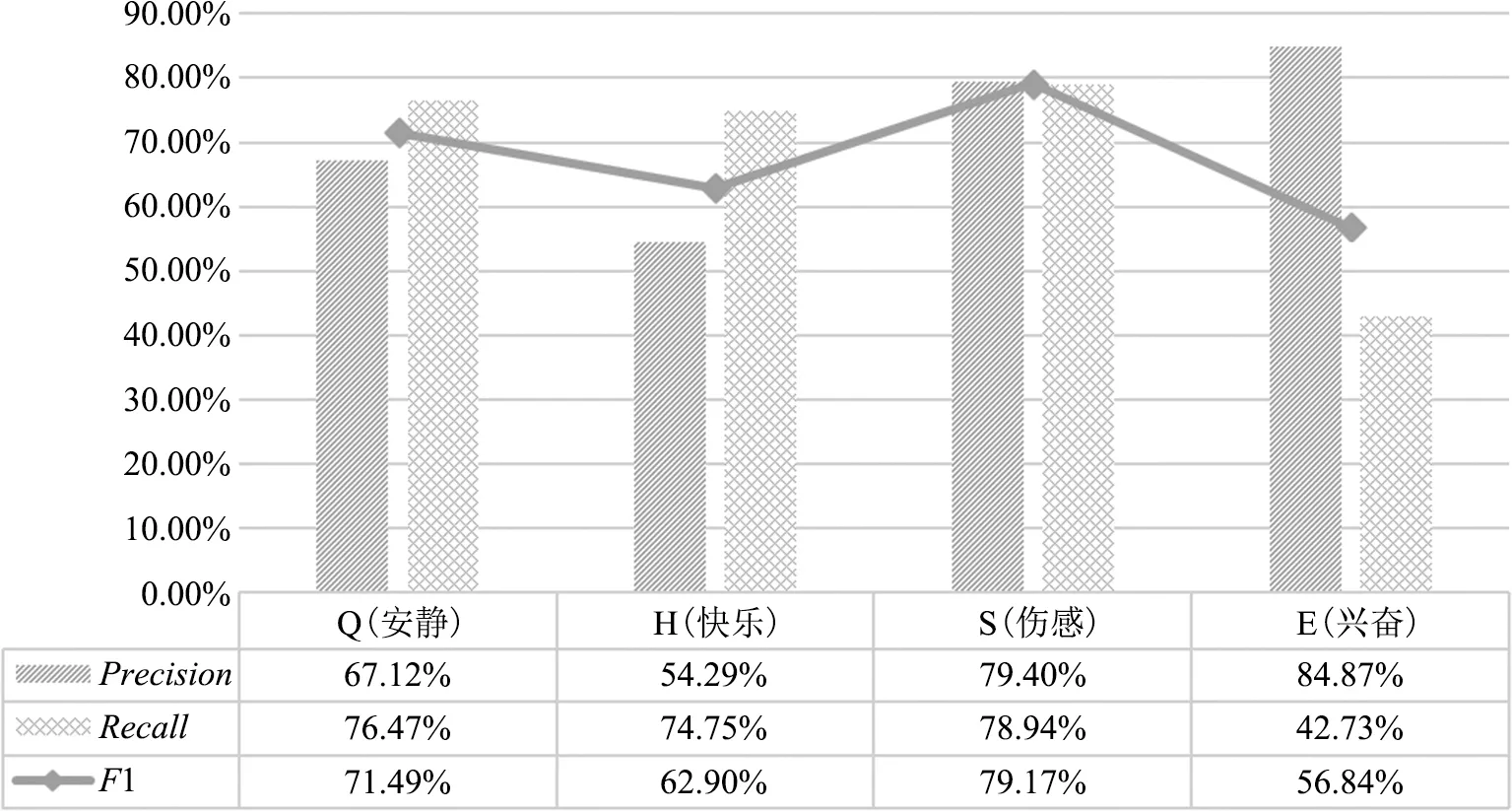
图9 权重a=0.6时各类歌单情感分类结果
2)基于机器学习的方法
本小节采用RF、LightGBM和XGBoost 3种性能优秀的集成机器学习算法对歌单描述进行情感分类,将预处理过的歌单名称和简介拼接到一起形成描述文档,再采用Word2vec模型将每个歌单的描述文本转换为100维的词向量,作为该歌单的描述向量,输入机器学习算法进行分类实验。针对4 010条歌单数据,采用十折交叉验证的方法划分训练集和测试集,最终结果取10次实验结果的均值,从而减少数据选取的不平衡对实验结果造成的影响。实验结果如图10所示。
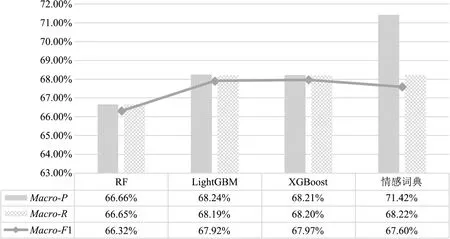
图10 RF、LightGBM、XGBoost与基于情感词典的歌单情感分类结果
图10中可以看出:①RF、LightGBM、XGBoost这3种方法对歌单情感分类的效果差别极小,RF算法稍微逊色,LightGBM与XGBoost结果几乎一致,表明在歌单描述情感分类问题上,3种机器学习模型都能达到类似的效果;②3种算法和基于情感词典的方法进行比较,情感词典的Macro-P稍高一些,但Macro-F1值稍低于XGBoost与LightGBM,整体来看基于机器学习的方法和基于情感词典的方法效果基本一致,说明本文构造的歌单情感词典以及情感词加权和特征加权的情感分类方式毫不逊色于基于机器学习的分类方法;③3种算法的分类结果并不是非常好,XGBoost的Macro-F1值最高,但也仅达67.97%,探究原因可能是歌单描述文本自身特征问题,主要有以下两点:ⅰ.虽然本文的歌单数据都选自网易云音乐平台情感分类下的歌单,但多数歌单除包含情感标签外,还含有风格、语种、场景、主题等其他类别的标签,这一因素使得部分歌单的文本描述与情感无关,而和歌单风格、语种等有关,造成算法无法准确识别;ⅱ.网易云音乐平台以“网抑云”著称,因为用户UGC内容主要由负面情绪的发泄、网络“段子”、心灵“鸡汤”组成,不止用户评论,用户歌单的创建同样也迎合这一特点,此外,平台对用户撰写的内容并不会加以限制,造成部分歌单名称和简介内容充斥着“无病呻吟”的语录,这些句子含义复杂晦涩,对机器学习算法的情感分类形成了一定阻碍。因此,若能提升歌单描述文本的数据质量,提高其中情感描述语句的比例,算法的分类准确率能进一步增加。
3)融合情感词典与机器学习的方法
本小节将情感词典和机器学习的方法融合到一起,具体方法为:在基于情感词典的方法中,每条歌单在每类情感下都有不同的得分,本文将每条歌单的4个得分数值与100维的描述向量组合在一起形成104维特征,再次输入到RF、LightGBM、XGBoost 3种算法当中,同样采用十折交叉验证的方法划分训练集和测试集,数据划分的随机数种子不变,使得数据集的划分与前述机器学习实验保持一致,方便比对实验结果。融合情感词典前后的实验结果对比如图11所示。

图11 融合情感词典前后3种机器学习算法实验结果对比
从图11可以看出:①在融合了情感词典方法后,3种机器学习方法的情感分类效果均有较为明显的提升,说明在歌单描述文本的处理上,加入人工预处理操作,能帮助机器学习算法更好地学习数据特征,进一步提升分类准确性;②RF和LightGBM的Macro-F1增加了约5个百分点,XGBoost的Macro-F1上涨了约6个百分点,XGBoost算法在融合情感词典后不止分类性能表现最好,且效果提升也最为显著,更适合应用到歌单的情感分类问题研究之中。
3.3 基于歌词的小粒度歌曲情感分类
本小节将歌词文本数据集按照4∶1的比例随机划分为训练集和测试集,即训练集共3 200条数据,测试集共800条数据,4种类别的歌词文本各占200条,利用TextCNN、TextRNN、TextRNN+Attention机制、TextRCNN和FastText这5种文本分类模型进行情感分类,不同模型的整体分类Accuracy和Macro-F1如图12所示。可以看出FastText模型的整体分类效果最佳,因此选用FastText模型的分类结果作为后续多模态融合的组成部分。
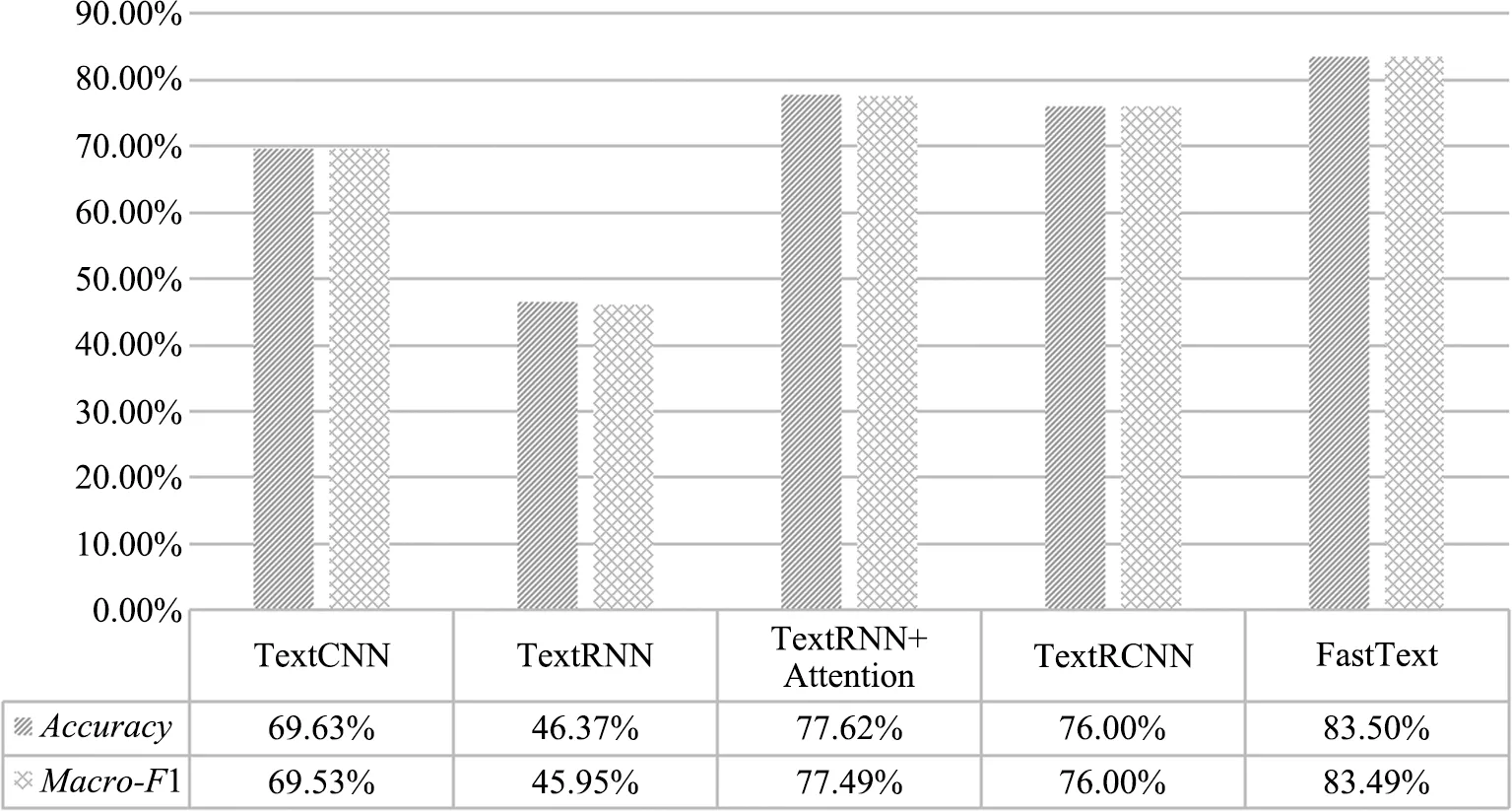
图12 不同模型的歌词情感分类结果
对4类情感的分类结果进行分析,FastText模型的混淆矩阵如图13所示,可以看出:①S的准确率最高,达90%,而H的准确率最低,不足80%,表明对于歌曲歌词来说,伤感的歌词情感表露会比较明显,能较为准确地被机器所识别,而快乐的歌曲里面存在很多说唱类型的歌曲,说唱的歌词篇幅会普遍大于其他类型的歌曲,且说唱歌词所包含的内容比较宽泛,因此会对机器识别造成一定的困难,导致分类效果稍差于其他3种类别;②Q类歌曲中被错误归为E类歌曲数量最多,且E类歌曲中被错误归为Q类歌曲数量也最多,即安静和兴奋的歌曲歌词混淆比较大,探究原因可能是安静和兴奋这两类情感下的大部分歌曲都是外语歌曲,这就导致大部分听众在不看歌词翻译的情况下几乎难以听懂歌词所表达的含义,而很多情况下听众只将歌曲当作背景音乐,不会关注歌词内容,因此听众主要根据旋律而非歌词对外语歌曲进行情感分类,使得安静和兴奋歌曲中的部分歌词内容比较相近;③H与S、Q的歌词混淆较大,而与E类歌词混淆较小,对快乐中分类错误的歌曲进行分析,发现分类错误的歌曲歌词大部分都是描写爱情的中文情歌,而伤感歌曲几乎全是由中文情歌组成,安静歌曲则是由不到一半的中文情歌组成,只有兴奋歌曲几乎全是外语歌曲,由于语言和文化差异,虽然兴奋歌曲中的外语歌曲也包含很多的情歌,但翻译成中文的歌词与正宗的中文歌曲歌词还是有较大的差异,因此导致快乐与兴奋的歌词混淆程度很小,反而与伤感、安静的歌词混淆程度较大。根据以上分析,单独靠歌曲歌词进行情感分类存在一定的弊端,即歌词的语言、题材等特征的相似程度会影响分类结果,且产生不符合人们常规认知的结果,因此,音频特征对歌曲的情感分类也是不可或缺的一部分。
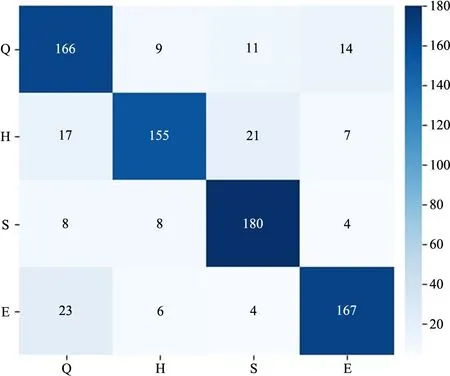
图13 FastText模型歌曲情感分类结果混淆矩阵
3.4 融合音频的小粒度歌曲情感分类
本小节采用了上一节中的训练集和测试集的歌曲音频数据,提取音频低层特征与梅尔声谱图特征,拼接后输入多层CNN架构中进行情感分类。在低层特征处理方面,本文选取音频30s副歌片段的中心距、过零率等时频域特征,计算各特征的多维统计值作为音频低层特征;在音频向声谱图的转换处理上,本文对副歌片段进行采样,将其转换为梅尔声谱图,采样参数及说明如表4所示。在本文中,duration和sampling_rate的数值是固定的,另外3个参数则根据硬件设施配置及CNN处理能力,初步设定多个取值,并比较模型分类效果确定最优取值组合,用于最终声谱图采样及歌曲情感分类实验。

表4 梅尔声谱图最优采样参数及说明
多层CNN模型对歌曲音频的情感分类结果如图14所示。由图可见:对于F1值来说,E>H>S>Q,即兴奋这一情感整体的分类效果最好,达86%,而安静整体的分类效果最差,不足74%,且安静的Recall值在4类情感中最高,但是Precision最低,说明其他3种情感的歌曲很多被识别为安静类型,探究原因可能是在提取歌曲的副歌片段时,本文是按照副歌一般情况下符合的规律进行提取,而实际上歌曲的旋律、风格等千变万化,有些歌曲的副歌部分并不满足一般规律,所以导致这些歌曲提取出来的并非副歌片段,而除了歌曲的副歌外,歌曲的前奏、主歌等部分的情感波动都比较小,旋律也较为缓和,与安静情感的音频片段更为相似,因此导致安静的Precision最低,也拉低了F1值。
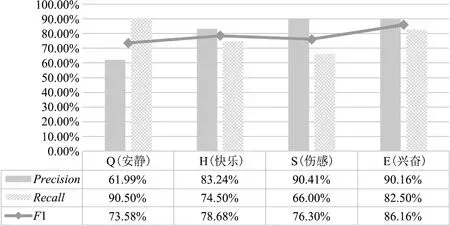
图14 多层CNN模型的音频情感分类结果
歌曲的歌词与音频并非完全割裂,而是相互呼应、相辅相成的。融合两种模态的特征进行情感分类任务,能够弥补单种模态情感特征表达不足的问题,进一步提升分类效果。此外,由于多数歌曲的词曲作者并非同一人,词曲的创作可能有时间差,且存在其他作者对歌曲的词或曲进行改编的情形,上述因素均会导致词曲情感不完全匹配。因此,本文首先联合分析单独基于歌词与单独基于音频的歌曲情感分类结果,探讨词曲情感不匹配的情况,再融合多模态特征以探讨模态融合能否达到最优分类效果。
本文将基于FastText模型的歌词文本情感分类结果记为M1,将基于多层CNN模型的音频情感分类结果记为M2。对M1和M2进行联合分析,结果如表5所示,可以看出:①两种方法对于快乐类别分类不一致的歌曲总数最多,对于安静类别分类不一致的歌曲总数最少,一定程度上表明安静歌曲的词曲情感较为匹配,而快乐歌曲的词曲情感不匹配的情况较多;②4类情感都或多或少地存在一种方法分类正确而另一种方法分类错误的情况,因此,对单独基于歌词和单独基于音频的分类结果进行融合,可以帮助纠正基于单一模态分类错误的结果,提升情感分类准确率。
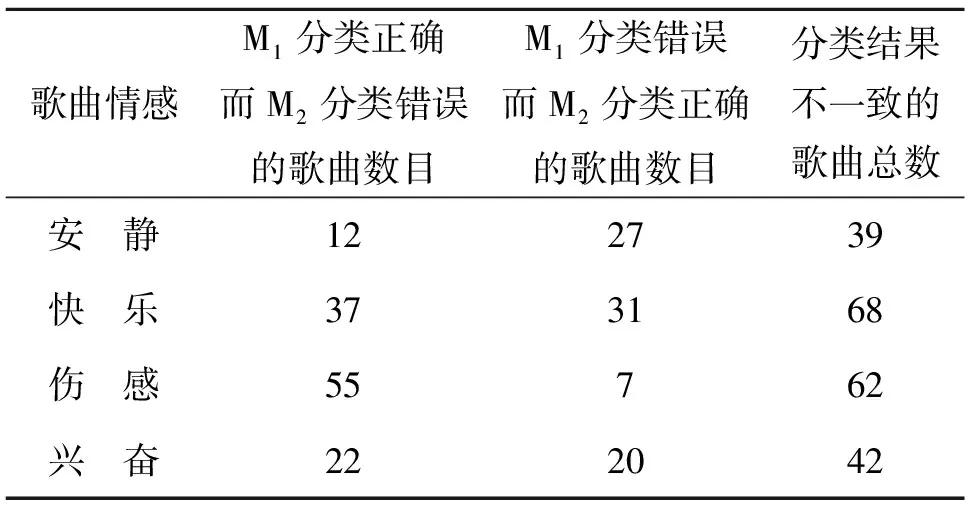
表5 M1和M2分类结果联合分析
将M1对应的每首歌曲归属于各类情感的概率向量记为R1,M2对应的概率向量记为R2。对R1和R2分别赋予权重a和1-a,且0≤a≤1,加权相加后得到结果R,如式(9)所示。
R=a×R1+(1-a)×R2
(9)
结果R依旧为歌曲归属于4类情感下的概率值,概率值最大时所对应的类别即为歌曲最后的情感分类,以0.05为单位调整权重a的实验结果如图15所示。
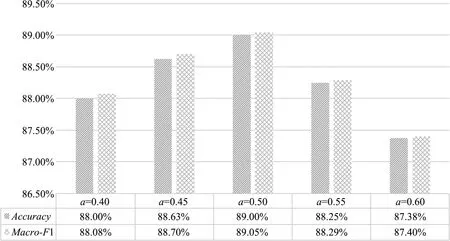
图15 权重值a不同取值下的分类结果
从图15中可以看出,当R1的权重值a=0.5时,情感分类的Accuracy和Macro-F1值均最大,达89%,此时R2的权重值同样也为0.5;而当权重值a从0.5逐渐减小或逐渐增大时,分类效果都在变差,所以针对本文的歌曲数据,歌词与音频在情感表达方面所起到的作用同等重要。将单独基于歌词的最优情感分类结果、单独基于音频的最优情感分类结果、融合歌词与音频的最优情感分类结果进行对比,如图16所示。
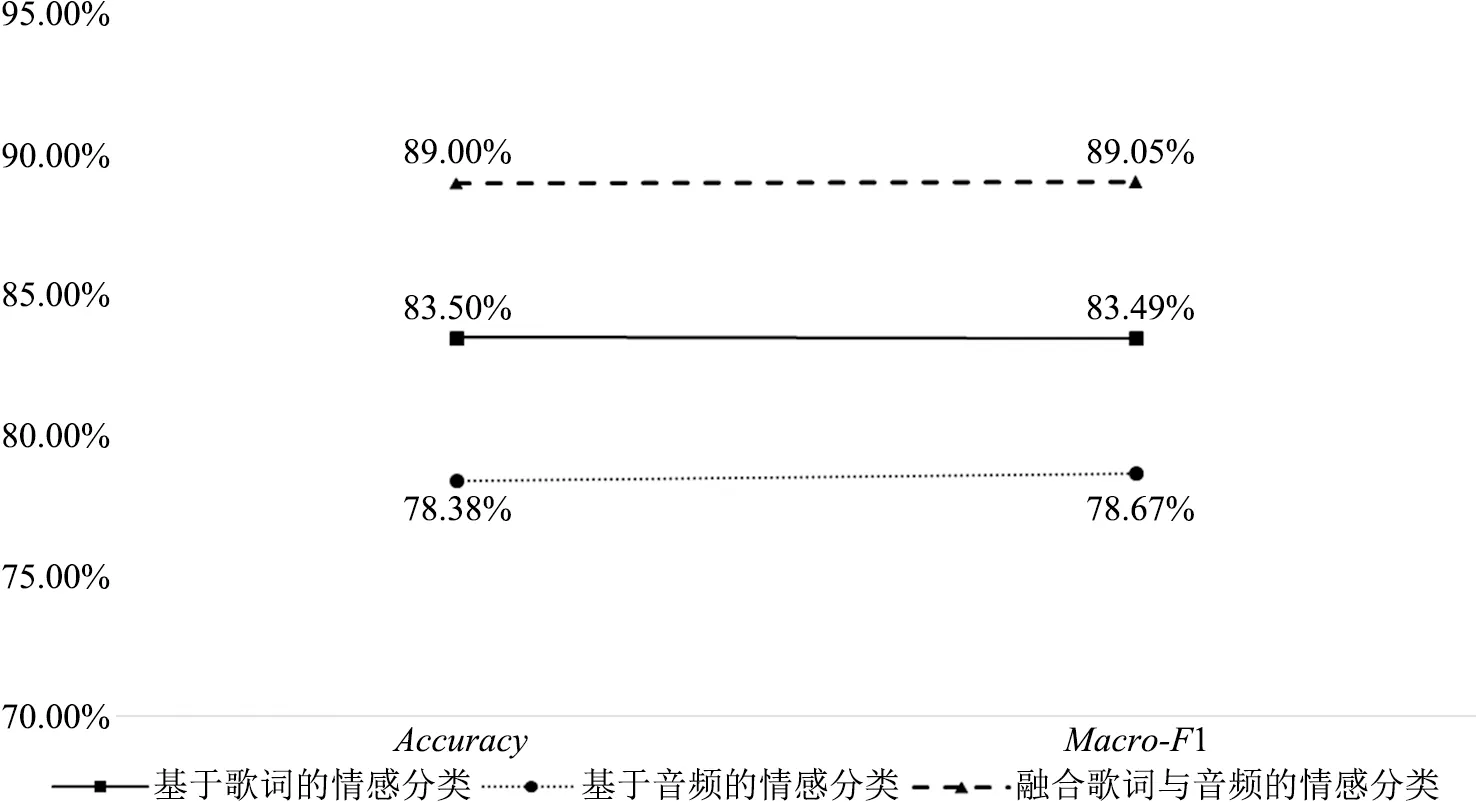
图16 3种歌曲情感分类方法的结果对比
从图16中可以看出:①不论Accuracy还是Macro-F1值,均为融合歌词与音频的方法>基于歌词的方法>基于音频的方法,且融合歌词与音频的结果将近90%,比单独基于歌词的方法高约5.5个百分点,比单独基于音频的方法高约10.5个百分点,说明融合两类特征的情感分析方法能极大地丰富歌曲的情感信息,弥补了单类特征信息单一化的不足,帮助提升了歌曲情感分类效果;②基于音频的歌曲情感分类效果最差,探究原因可能是音频数据相对文本来说更为复杂,对于音频深层语义特征的提取较为困难,处理和分析音频数据的技术还有较大的提升空间。因此,采用多模态融合的歌曲情感分类方法仍将是今后的重点研究内容。
4 结 语
本文以网易云音乐平台上安静、快乐、伤感、兴奋这4类情感下的4 010条歌单数据及4 000首歌曲为例,首先,利用基于情感词典的方法、基于机器学习的方法、融合情感词典与机器学习的方法对歌单情感进行分类;其次,采用TextCNN、TextRNN、TextRNN+Attention机制、TextRCNN和FastText 5种模型对歌词文本进行情感分类;最后,利用多层CNN模型对歌曲音频进行情感分类,并采用线性加权晚融合法,将音频情感分类结果与歌词分类效果最好的FastText模型实验结果进行加权融合。实验结果表明:①对于歌单的情感分类,融合情感词典与机器学习的方法要优于单一方法,但由于歌单自身数据特征影响,歌单的文本描述与情感无关,或是由难以辨明情感的“非主流”语句构成,导致情感分类准确率不能达到较高的水平;②对于歌曲的情感分类,多模态融合的情感分类准确率比单独基于歌词的情感分类准确率提升了约5.5个百分点,比单独基于音频的情感分类准确率提升了约10.5个百分点,分类准确率有显著提升,说明融合两类特征的情感分析方法能极大地丰富歌曲的情感信息,弥补了单类特征信息单一化的不足。因此,本文提出的多模态融合方法在音乐情感分类问题上能取得不错的效果。
本研究依然存在可完善之处。其一,由于网易云音乐歌单除了文本描述特征外,还包含封面图片特征,因此后续可以考虑将歌单文本和图像特征结合到一起实现多模态融合情感分类;其二,由于网易云音乐平台本身展现的歌单数量较少,以及受实验条件和平台对歌曲的版权保护的限制,本文的歌单数据集和歌曲数据集规模都不是特别大,未能充分发挥深度学习模型对大规模数据的处理能力,后续应考虑加入更多的数据。
