基于YOLOX和Swin Transformer的车载红外目标检测
2022-11-25楼哲航罗素云
楼哲航,罗素云
基于YOLOX和Swin Transformer的车载红外目标检测
楼哲航,罗素云
(上海工程技术大学 机械与汽车工程学院,上海 201620)
红外图像因为存在噪声大、对比度不佳等问题,容易导致目标检测时的精度降低,本文结合YOLOX和Swin Transformer,提出了一种改进的YOLOX的模型。改进的模型采用Swin Transformer替换YOLOX中的CSPDarknet主干提取网络,减少YOLOX中Neck和Head部分的激活函数以及标准化层,以提高特征的提取能力,优化网络结构。对改进的模型在艾瑞光电数据集和FILR数据集上均进行了测试,实验结果显示,改进后的YOLOX网络,在两个数据集上的平均检测精度都有明显提升,更加适合红外图像的目标检测。
目标检测;红外图像;YOLOX;Swin Transformer
0 引言
伴随红外技术的不断发展以及其“军转民”技术的不断成熟,红外技术在各个领域都有越来越多的应用。在无人驾驶领域,红外技术主要用于生命体的检测以及对车辆的可驾驶区域的检测。物体间无时无刻不在交换红外辐射,加之红外成像设备的性能限制,导致了红外图像具有分辨率低、噪声大、边缘模糊、对比度不佳等特点,上述物理特性也给基于红外图像的目标检测算法的设计与实现带来了更多的挑战[1]。
红外目标检测的方法主要分为传统方法和基于机器学习的方法。传统方法主要有基于形状的目标检测和基于运动的目标检测。
基于形状的红外目标检测方法通过预先建立目标模板,依据特定的搜索策略采用模板匹配的思想来实现目标检测。任章[2]等人依据行人目标的特点,重新构建模板特征,并融入Kalman预测器来预测目标的运动轨迹,使得虚警率降低。吴燕茹[3]等人基于核主成分分析(Kernel based Principal Component Analysis,KPCA)思想提出了一种AdaBoost红外目标检测算法,能够解决传统目标检测的繁琐参数设置问题。基于形状的目标检测方法主要依靠对象的先验知识对目标建模以形成目标模板,对模板的要求较高,只适合于特定的场所。
基于运动的目标检测为依据视频帧的差异性或目标对象的运动特性定位目标,再依据目标空间特征及先验知识检测目标[4]。Davis[5]提出一种基于背景建模差分模型的行人目标检测算法,采用高斯模型描述背景定位目标,结合梯度信息依据目标轮廓显著图检测目标提取轮廊。Fida[6]采用强度相似度和局部二值模式纹理双特征模型来表示背景信息,融入了目标的空间相关性,能有效地降低噪声干扰。基于运动的目标检测能得到较好的目标轮廓,但只适用于运动目标的检测,具有局限性。
基于机器学习的方法,主要包括支持向量机、RCNN系列、YOLO系列、SSD等。于杰[7]利用Part-based方法结合支持向量机实现了车辆的目标检测。易诗[8]等人基于YOLOv3和红外技术进行了夜间的目标识别。聂霆[9]利用道路、车辆等环境辅助信息的红外特性,采用提取感兴趣区域ROI(Region of Interest)和ISODATA(Iterative Self Organizing Data Analysis Techniques Algorithm)聚类算法进行车辆识别。陈谧[10]改进YOLOv4网络提出了一种改进的红外目标检测算法,并设计了一个嵌入式红外目标检测系统。舒朗[11]等人基于YOLOv5的网络结构,提出了一种密集连接的网络Dense-YOLOv5解决红外目标不明显的问题,对于特征不明显的小目标的检测效果较好。
本文基于YOLOX架构,结合Swin Transformer[12],结合图像处理技术和红外图像特点,对原始YOLOX中的CSP模块进行了改进,将其应用于车辆和行人的目标检测,增强了对于车辆的特征提取,达到了较好的目标检测效果。
1 相关工作
1.1 YOLOX
YOLO系列作为单阶段目标检测的算法,因其灵活性、高效性和泛化能力在目标检测领域被广泛使用。YOLOX[13]是YOLO系列的最新架构,是在YOLOv3的基础上,引入anchor-free、Decoupled head、Mosaic数据增强和SimOTA样本匹配的方法,摆脱了以往YOLO系列对于anchor的依赖,构建了新的端到端的目标检测框架,并在coco数据集上达到了较好的检测水平,性能上超过了YOLOv3[14]/v4[15]/v5。
YOLOX的结构主要分成3部分:Backbone、Neck和Head。Backbone部分,YOLOX沿用YOLO系列中的CSPDarknet主干提取网络,整体结构如图1所示,主要有4个模块构成,分别是Focus模块、CBS模块、CSP1模块和SPP模块。
Neck部分,YOLOX采用了FPN+PAN(Feature Pyramid Networks+Pyramid Attention Network)的结构。其中,FPN自顶而下,将高层的信息,通过上采样的方式与底层信息融合,主要传递语义特征;PAN结构自底而上,将底部的信息,传递至高层实现融合,主要传递定位信息。
Head部分,YOLOX采用解耦头,其结构如图2所示,分别进行分类、回归和IoU计算。采用解耦头时有如下特点[13]:①用解耦的Head替换YOLO的Head大大提高了收敛速度。②解耦的Head利于YOLOX实现端到端化,便于下游任务一体化。
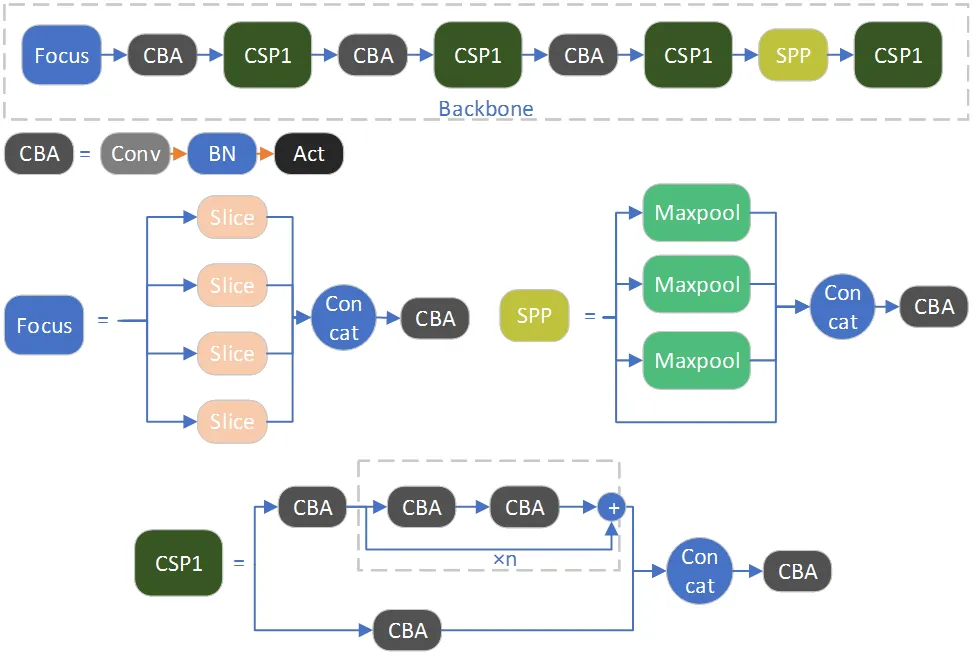
图1 YOLOX的Backbone

图2 YOLOX的Head部分
1.2 Swin Transformer
Swin Transformer作为Transformer在CV领域的一大成果,在目标分类、目标检测、目标分割等下游任务中均取得了较好的SOTA(State of The Art)效果。Transformer从自然语言处理应用到视觉领域的挑战来自两个领域之间的以下差异:视觉实体的规模变化很大;与文本中的单词相比,图像中像素的高分辨率[10]。Swin Transformer基于这两方面的问题提出了滑动窗口的形式,并采用一种分层的Transformer。采用滑动窗口的形式计算像素之间的注意力,能够降低了原有注意力计算的复杂度,同时,因为采用了不同的采样倍数,对小物体的识别有较好效果。
Swin Transformer[12]的基本结构以模块化的形式呈现。主要有分割编码模块(Patch Embedding模块)、滑动Transformer模块(Swin Transformer Block)、移动拼接模块(Patch Merging模块)3大模块叠加构成。
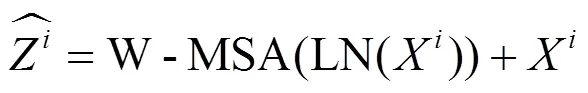

式中:Q,K,V为注意力机制中所需的3个向量,分别为Query向量、Key向量和Value向量;B为采取的偏置;d为缩放系数。
Swin Transformer所提出的滑动窗口注意力(Shifted Windows Multi-head Self-attention),如图4所示,在前一个Block中采用窗口注意力(W-MSA),而在后一个Block中采用滑动窗口注意力(Swin Multi-head Self-attention,SW-MSA),两种注意力机制交替使用,在Swin Transformer Blocks中Transformer Block成对出现。
2 改进的YOLOX模型
针对红外图像分辨率低、噪声大、对比度不佳等缺点,本文以YOLOX为基础进行改进,对其Backbone进行了替换,采用Swin Transformer作为新的Backbone,以增强特征提取能力。同时对YOLOX模型中Neck部分的FPN+PAN结构进行了改进,减少其中的标准化层和激活函数,可以在降低计算复杂度的同时提升精度。具体结构见图5所示。

图4 窗口滑动机制(左:滑动前,右:滑动后)
2.1 Backbone替换
在原YOLOX架构中,Backbone沿用YOLO系列中的CSPDarknet主干提取网络,并通过Focus结构和SPP结构优化了提取网络的结构,使精度和速度都有较大的提升。CSPDarknet采用卷积结构来提取特征,在卷积结构提取特征的过程中,感受野取决于卷积核的大小,卷积核越大,所感受的区域越大,而卷积核增大同时会极大地增加运算的复杂度;当感受野的区域不够大时,所提取的特征就会损失全局的特征信息。卷积结构具有平移不变性,对特征的全局位置不敏感,只会提取原始数据中的一小部分的局部信息。Swin Transformer采用注意力机制,在计算注意力的过程中会考虑全局的信息,在每个patch中加入位置信息,使得在保留对特征的全局位置敏感的同时扩大感受野。
在结构上,Swin Transformer与CSPDarknet相似。CSPDarknet通过堆叠卷积层以及残差结构来实现,而Swin Transformer通过堆叠Swin Transformer Block和Patch Merging模块来实现。同时,Patch Merging模块中会将每个小窗口中相同位置的值取出来,拼成新的patch,最后将所有patch都叠加起来,与CSPDarknet中的Focus效果相同。从结构而言,Swin Transformer可以替换CSPDarknet,并提高对全局特征的提取效果。
Swin Transformer依据第一个输入层的通道数、不同的层数可划分为Swin-T、Swin-S、Swin-B和Swin-L,参数如表1所示,本文选用Swin-T。
2.2 Neck和Head优化
在原有的卷积网络中,倾向于对每个卷积操作都添加激活函数以及归一化层,而Transformer中使用了更少的激活函数以及归一化操作。ConvNeXt[16]对比分析了ResNet和Transformer的模块的区别,对此进行了验证,适当减少激活函数和归一化操作能有效地提高精度。
本文对Neck结构中CSP层和Head结构进行了优化,减少其中的激活函数以及归一化层。减少过多激活函数层,容易导致卷积层退化,故对于CSP层,保留CSP层中第二条通道中的激活函数以及归一化层,并添加残差结构,对于Head,仅去除Head中第一个卷积层的激活函数。
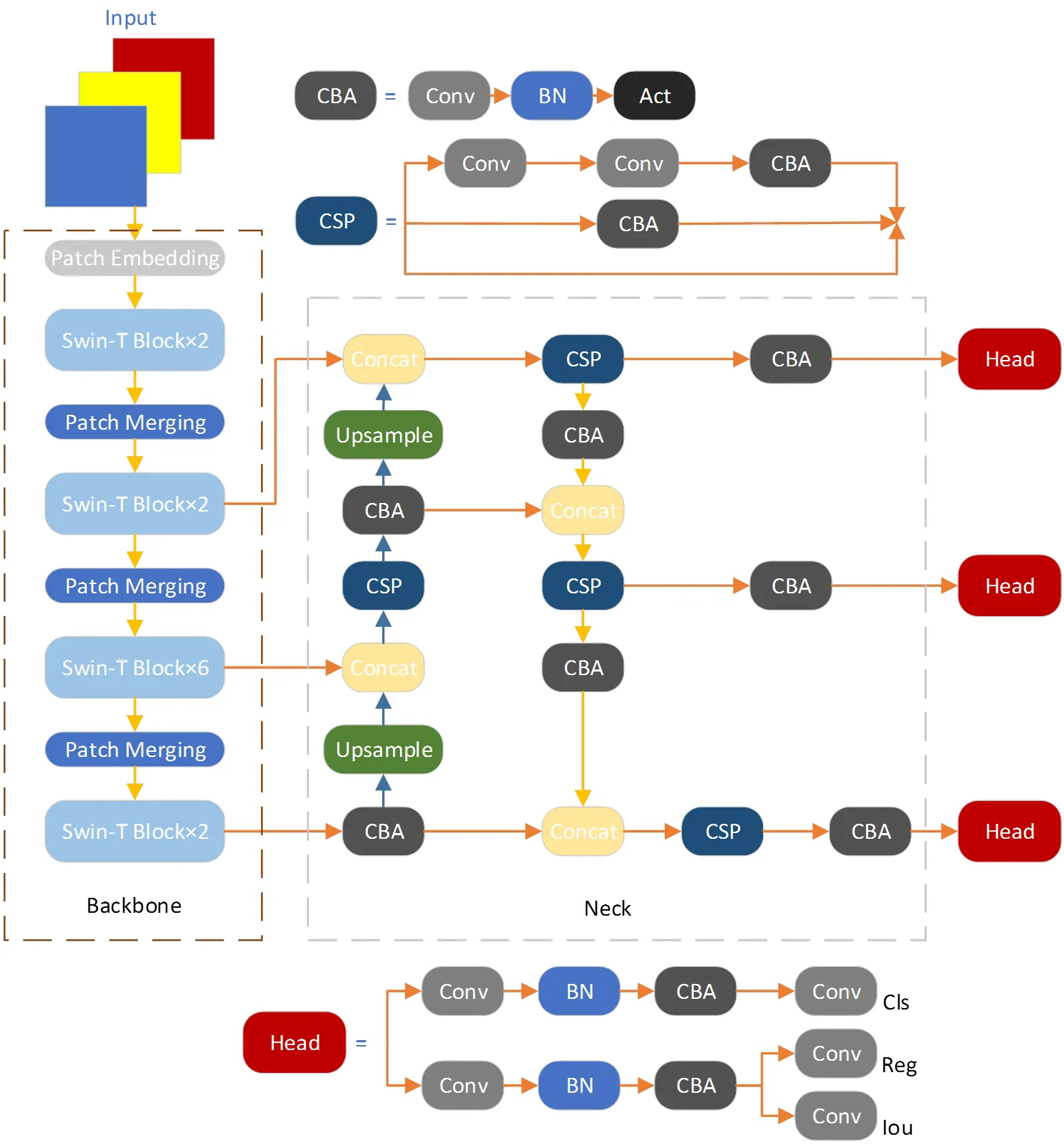
图5 改进YOLOX模型结构

表1 不同的Swin Transformer参数
RELU激活函数在输入的函数梯度过大时,容易导致参数更新后,神经元不再具有激活功能[17],本文替换Neck和Head中的激活函数为GELU函数:

优化后的CSP层和Head结构如图6所示。
3 实验设置
3.1 实验环境
本文采用Pytorch作为深度学习框架,训练以及测试均基于Linux系统,ubuntu16.04,CUDA11.1,python3.10,pytorch1.10。硬件条件为Intel(R) XEON(R) W-2150B CPU @3.00GHz,GPU为GeForce RTX 3070×2,16GB显存。
训练参数为训练周期300次迭代,最大学习率为0.01,最小学习率为0.001,优化器为“SGD”随机梯度下降,权重衰减为0.0005,学习率下降采用“COS”余弦下降,采用冻结前100个周期训练批次为8,后200个周期训练批次为4。测试时的置信度为0.001,NMS阈值为0.65。
3.2 数据集
本文基于艾睿光电(Inf iRay)所制作的双光车载场景数据库[18]和FLIR公司发布的自动驾驶开源红外热成像数据集[19]对改进的模型的效果进行了实验验证。
艾睿光电所制作的双光车载场景数据库为采用艾睿光电自研的红外传感器在道路上所采集的视频而制作形成的数据集。艾睿光电数据集分辨率高,全天候场景内容丰富,为国内道路拍摄。数据集中红外图片共计2342张,分辨率为1440×1080,目标种类共5种:人、自行车、汽车、卡车、公交车。
由于数据集照片较少,不利于训练,本文进行了数据增强,将数据集扩充至12340张。训练集与测试集的比例为8:2,在训练集中选取20%作为验证集。同时保留YOLOX原有的数据增强方式,包括Mosaic数据增强。
数据增强方式为:镜像图像、随机添加方形噪声、调整对比度、随机裁剪。每张原始图片选择其中两项组合,每张原始图像增强5次。扩充后的数据集中的部分图片如图7所示。

图7 扩充后的数据集
FILR数据集由车载热成像相机FLIR Tau2获取,驾驶环境为11月至5月期间日间(60%)和夜间(40%),在加利福尼亚州圣巴巴拉市街道和公路上。数据集总共包含14452张红外图像,其中训练集8862张,验证集1366张。目标种类共3种:Person、Bicycles、Car,其中Bicycles包括自行车和摩托车,汽车包括个人车辆和一些小型商用车。
4 实验结果对比分析
4.1 艾睿光电数据集检测结果分析
本文首先在原始的未扩充的数据集上进行训练、验证和测试,不载入任何预训练权重,由于数据集较小,收敛较快,本文在进行50次迭代,冻结参数后,最大训练迭代次数为100次。本文选用YOLOX-l版本作实验结果的对比。
YOLOX和本文所改进的YOLOX在训练过程中所得的损失函数如图8(a)、(b)所示。从图8(a)、(b)的损失函数中可以看出,YOLOX和本文所改进的YOLOX均收敛较快,在前50次迭代中,下降平稳,在100次迭代后就收敛了,最终YOLOX的训练损失为5.0212,验证损失为4.788,本文所改进后的YOLOX的训练损失为5.0193,验证损失为4.7625。
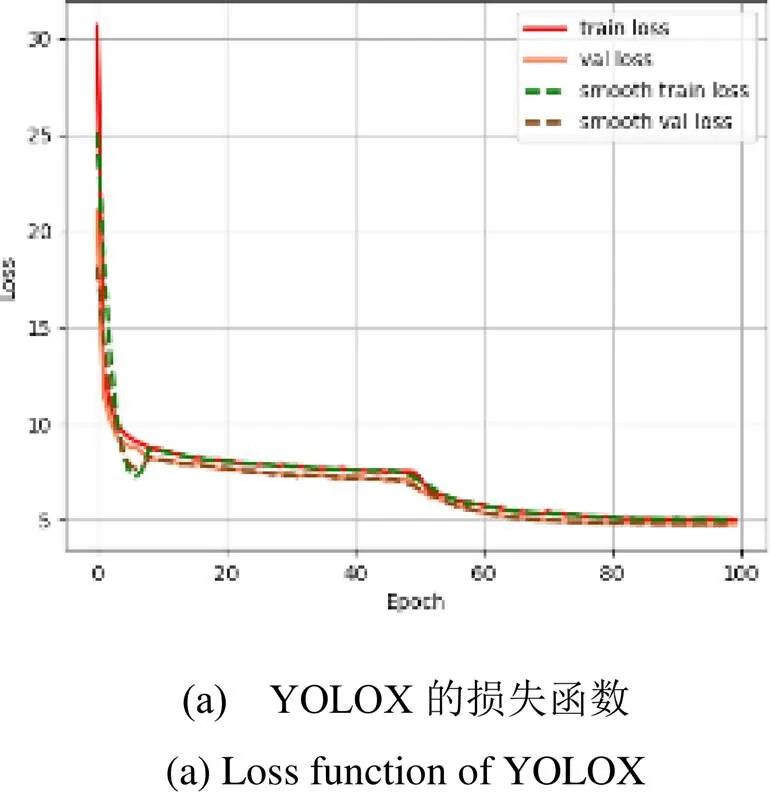
测试得YOLOX的MAP(Mean Average Precision)为29.51%,本文所改进的模型的MAP为33.74%,效果均不佳。
分析在原始艾睿光电数据集上测试结果不理想的原因,可能是数据集过小,网络未得到较好的训练,因此再在扩充后的数据集的训练集和验证集上进行训练和验证,训练时先训练100次迭代,冻结参数后,最大训练迭代次数为200次,保存训练所得的权重以及训练过程中的损失曲线如图9(a)、(b)所示,再使用该权重对数据集中的测试集进行测试,测试效果如图10所示,得到相应的AP(Average Precision)以及MAP值,如图11所示。
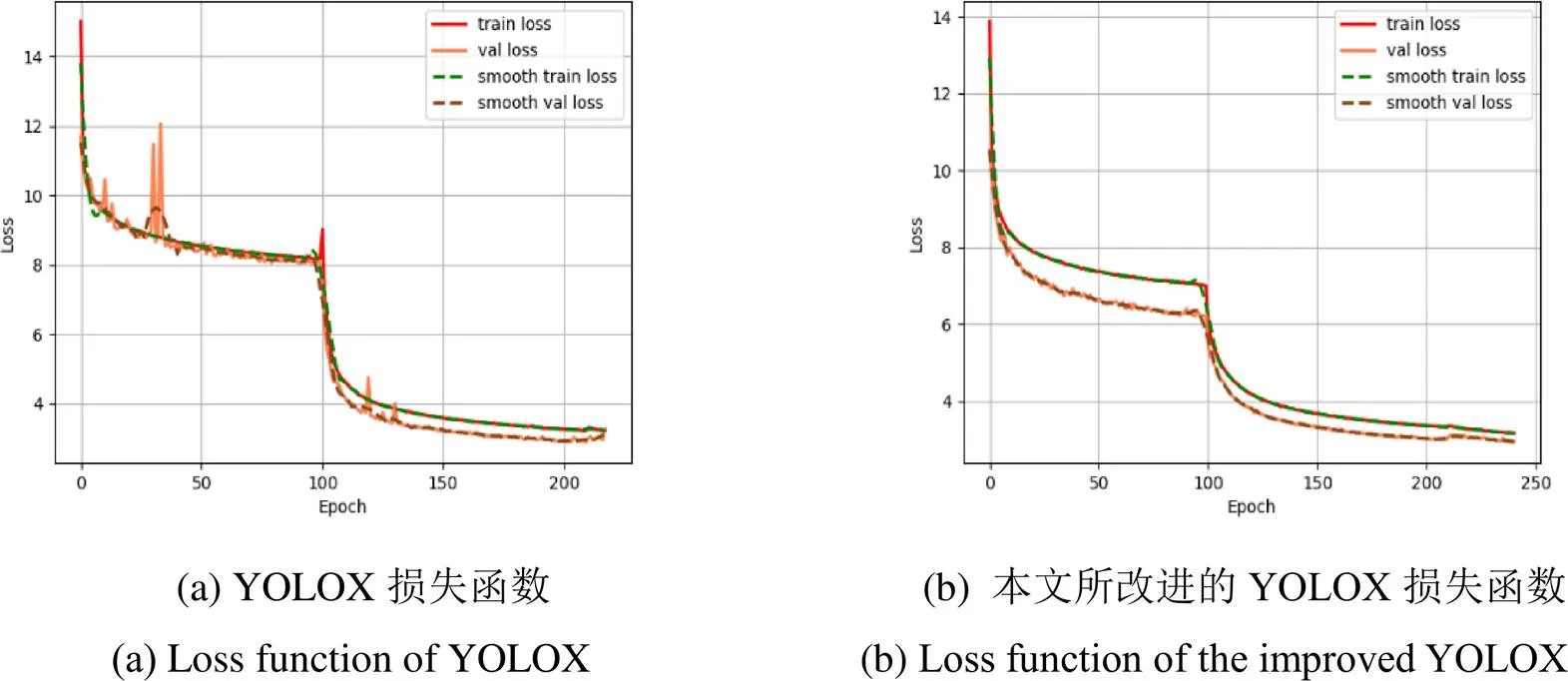
图9 扩充后艾睿光电数据集上损失函数对比

图10 测试效果(上:原图,中:YOLOX,下:本文所改进的模型)
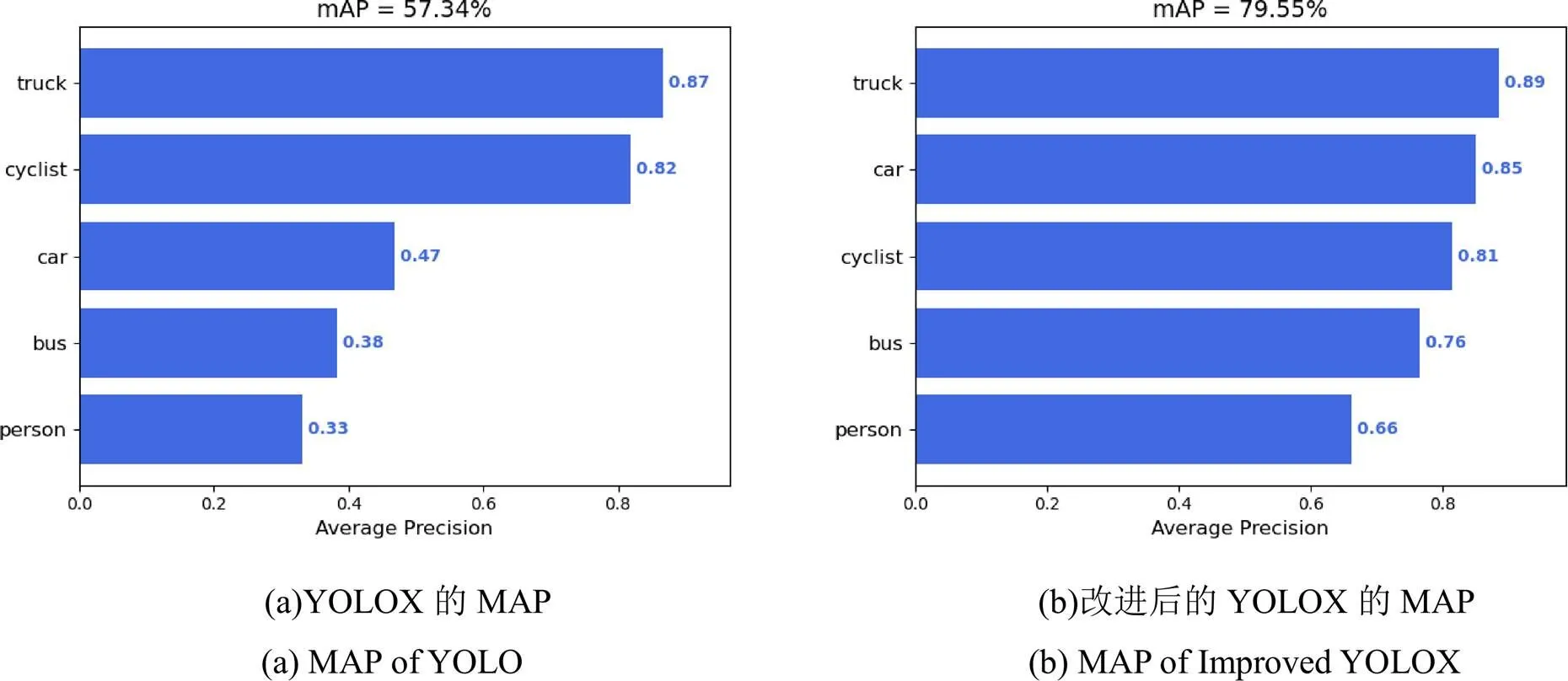
图11 MAP及AP值
从图9的损失函数中可以看出,在原YOLOX的模型下,训练集的损失函数下降比较平稳,但验证集的损失函数在前100次迭代中出现了突然上升的情况,如图9(a)所示,本文考虑是由于在扩充数据集中加入了噪声,YOLOX提取错误的信息,从而导致后续验证时出现损失突然增大,YOLOX在210次迭代后基本收敛。在采用本文改进的YOLOX时,在前100次迭代中损失曲线有小幅度波动,在240次迭代左右收敛,后120次损失函数下降平稳,如图9(b)所示。从图9(a)、(b)的对比可知,改进后的网络的损失函数下降过程更平稳,最终YOLOX的训练损失为3.2256,验证损失为3.0115,本文改进后的YOLOX的训练损失为3.1686,验证损失为2.9504。YOLOX和本文改进的YOLOX在扩充后的数据集中训练所得到的损失均小于在原始数据集中所得的损失。
从图10的测试效果可以看出,YOLOX在测试中易发生漏检和误检。在场景一中,YOLOX错误将房屋与树木之间的空间误检成小车,而本文改进的YOLOX则不存在这种情况。在场景二、三中,YOLOX均出现了漏检的情况,场景二中漏检了卡车旁的行人,场景三中漏检了停靠在路灯边的汽车,而本文改进YOLOX没有出现漏检。同时,本文改进的YOLOX对于小目标也具有更好的检测,提升了远处目标的置信度。
由图11的AP和MAP可知,经本文改进后的YOLOX在MAP上提升较大,从57.34%提高到79.55%,增加了22.21%,效果明显。具体到每个类的AP时,对truck和cyclist进行检测的AP的提升不是很明显,而对于car,bus,person检测的AP的增加很显著,其中car提升了约38%,bus提升了约38%,person提升了约33%。由实验结果可知,本文所改进的YOLOX网络在各类上均有不错的提升,验证了本模型的改进的有效性。
4.2 FILR数据集检测结果分析和消融实验
本文在艾睿光电扩充数据集上训练、验证、测试后,检验模型的泛化能力,再在FILR数据集上进行了训练、验证、测试。参数设定与在艾瑞光电扩充数据集上所采用的参数相同。
同时,为分析本文改进的部分对模型性能的影响,本文进行了消融实验,每次实验均采用相同的训练参数,在不同的模型上进行测试。
结合相关实验数据,本文改进的网络与目前主流的网络Faster R-CNN、YOLOV3、YOLOV4-Tiny、YOLOV5-s进行比较,所有实验的AP与MAP在表2中列出。
从表2中的结果可以看出,随着YOLO版本的更替,YOLOX相较于YOLOV3、YOLOV4-Tiny、YOLOV5s的AP和MAP均有较大的提升。本文对Backbone、Neck和Head的优化对于YOLOX有所提升,可以发现将YOLOX的Backbone替换为Swin Transformer,对于Person的精度提升了9.78%,提升了对于行人特征的提取能力,整体检测精度提升了5.74%。Neck和Head的优化,对Person和Bicycle也有所提升,整体精度提高1.55%。

表2 主流目标检测对比及消融实验
Note: The categories corresponding to the FILR dataset are Car, Person and Bicycle; The corresponding categories of Inf iRay dataset (including before and after expansion) are Car, Person and bus. See Figure 11 for the results of trunk and cyclist categories in the Inf iRay dataset .
与主流算法Faster R-CNN、YOLOv3、YOLOv4-Tiny、YOLOv5-s及改进版的对比,本文所改进的模型,相较于YOLOv3的改进版的精度提升了9.23%,相较于YOLOv4-Tiny的改进版的精度提升了11.53%,相较于YOLOv5s的改进版的精度提升了14.33%。
由此表明,本文所提出的基于YOLOX和Swin Transformer的模型对于各类目标的检测精度都有所提升。在两个数据集上精度的提升,也说明了本文所提出的模型的目标检测效果。
5 结论
针对红外图像噪声大、对比度不佳等问题,本文结合YOLOX和Swin Transformer,对YOLOX网络进行了优化,根据实验结果可得出以下结论:
1)采用Swin Transformer替换YOLOX中的backbone能有效地提高网络特征提取的能力,并具有一定的抗噪声能力。通过滑动窗口的方式,也能有效地降低计算量,提高性能,同时利于信息的交互,利于下游检测任务;
2)通过减少Neck和Head中的激活函数和标准化层,能够有效地提高精度;
3)本文提出的基于YOLOX和Swin Transformer改进的网络,能有效地提高车载红外目标检测精度,在扩增后的艾睿光电红外数据集上,总体精度提升22.21%,在FILR红外数据集上,总体精度提升10.2%。
4)对比两个数据集中各个类别提升的效果,Swin Transformer对于加强行人的特征的提取效果最为优异。
[1] Caniou J.[M]., 2013.
[2] 任章, 李露, 蒋宏. 基于红外图像序列的运动目标检测算法研究[J]. 红外与激光工程, 2007, 36(9): 136-140.
REN Zhang, LI Lu, JIANG Hong Research on moving target detection algorithm based on infrared image sequence[J]., 2007, 36(9): 136-140.
[3] 吴燕茹, 程咏梅, 赵永强. 利用KPCA特征提取的Adaboost红外标检测[J]. 红外与激光工程, 2011, 40(2): 338-343.
WU Yanru, CHENG Yongmei, ZHAO Yongqiang. Adaboost infrared target detection using KPCA feature extraction[J]., 2011, 40(2): 338-343.
[4] 陈炳文. 特定视场中红外成像目标检测关键技术研究[D]. 武汉: 武汉大学, 2013.
CHEN Bingwen. Research on Key Technologies of Infrared Imaging Target Detection in Specific Field of View[D] Wuhan: Wuhan University, 2013.
[5] James W Davis, Vinay Sharma. Robust background-subtraction for person detection in thermal imagery[C]//, 2004: 1-8.
[6] Ei Baf Fida, Bouwmans Thierry, Vachon Bertrand. Fuzzy foreground detection for infrared video[C]//, 2008: 1-6.
[7] 于杰. 基于红外摄像机的夜间场景监控方法研究与实现[D]. 北京: 北京邮电大学, 2013.
YU Jie. Research and Implementation of Night Scene Monitoring Method Based on Infrared Camera[D]. Beijing: Beijing University of Posts and Telecommunications, 2013.
[8] 易诗, 聂焱, 张洋溢, 等. 基于红外热成像与YOLOv3的夜间目标识别方法[J]. 红外技术, 2019, 41(10): 970-975.
YI Shi, NIE Yan, ZHANG Yangyi, et al. Night target recognition method based on infrared thermal imaging and YOLOv3[J]., 2019, 41(10): 970-975.
[9] 聂霆. 基于红外图像的前方车辆识别与车距检测[D]. 西安: 西安电子科技大学, 2015.
NIE Ting. Forward Vehicle Recognition and Distance Detection Based on Infrared Image[D]. Xi'an: Xi'an University of Electronic Science and Technology, 2015.
[10] 陈谧. 基于深度学习的红外目标检测方法研究与实现[D]. 成都: 电子科技大学, 2021.
CHEN Mi. Research and Implementation of Infrared Target Detection Method Based on Depth Learning[D]. Chengdu: University of Electronic Science and Technology, 2021.
[11] 舒朗, 张智杰, 雷波. 一种针对红外目标检测的Dense-Yolov5算法研究[J]. 光学与光电技术, 2021, 19(1): 69-75.
SHU Lang, ZHANG Zhijie, LEI Bo. Research on Dense-Yolov5 algorithm for infrared target detection[J]., 2021, 19(1): 69-75.
[12] LIU Z, LIN Y T, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows[J/OL]., 2103.14030.
[13] GE Z, LIU S, WANG F, et al. Yolox: Exceeding yolo seriesin[J/OL]. arXiv Preprint arXiv, 2107.08430.
[14] Redmon J, Farhadi A. YOLO V3: an incremental improvement[J/OL]., 1804.02767.
[15] Bochkovskiy A, WANG C Y, LIAO H M. YOLOv4: optimal speed and accuracy of object detection[J/OL]. arXiv Preprint arXiv, 2004.10934.
[16] ZHUANG L, Hanzi M, CHAO Yuan W, et al. A ConvNet for the 2020s[J/OL]., 2201.03545.
[17] 王周春, 崔文楠, 张涛. 基于支持向量机的长波红外目标分类识别算法[J]. 红外技术, 2021, 43(2): 153-161.
WANG Zhouchun, CUI Wennan, ZHANG Tao. Long wave infrared target classification and recognition algorithm based on support vector machine [J]., 2021, 43(2): 153-161.
[18] Inf iray. Double light vehicle scene database[EB/OL]. [2022-04-02]. http://iray.iraytek.com:7813/apply/Double_light_vehicle.html/.
[19] Flir. FLIR Thermal Data Set[EB/OL]. [2022-04-02]. https://www.flir. com/oem/adas/adas-dataset-form/.
[20] 张汝榛, 张建林, 祁小平, 等. 复杂场景下的红外目标检测[J]. 光电工程, 2020, 47(10): 128-137.
ZHANG Ruzhen, ZHANG Jianlin, QI Xiaoping, et al. Infrared target detection in complex scenes[J]., 2020, 47(10): 128-137.
[21] 张鹏辉, 刘志, 郑建勇, 等. 面向嵌入式系统的复杂场景红外目标实时检测算法[J]. 光子学报, 2022, 51(2): 203-212.
ZHANG Penghui, LIU Zhi, ZHENG Jianyong, et al. Real time infrared target detection algorithm for embedded systems in complex scenes[J]., 2022, 51(2): 203-212.
[22] 宋甜, 李颖, 王静. 改进YOLOv5s的车载红外图像目标检测[J]. 现代计算机, 2022, 28(2): 21-28.
SONG Tian, LI Ying, WANG Jing. Improved vehicle infrared image target detection of YOLOv5s[J]., 2022, 28(2): 21-28.
Vehicle Infrared Target Detection Based on YOLOX and Swin Transformer
LOU Zhehang,LUO Suyun
(School of Mechanical and Automotive Engineering, Shanghai University of Engineering Science, Shanghai 201620, China)
Owing to the problems of high noise and poor contrast in infrared images, the accuracy of target detection is easily reduced. Here, an improved YOLOX model combined with YOLOX and a Swin Transformer is proposed. To improve the feature extraction ability, reduce the activation functions and standardization layers of the neck and head parts in YOLOX, and optimize the network structure, the Swin Transformer is used to replace the CSPDarknet backbone extraction network in YOLOX. This study tests the improved model on both the InfiRay and FILR datasets. The obtained experimental results indicate that the improved YOLOX network has significantly improved the average detection accuracy on both datasets and is more suitable for infrared image target detection.
object detection, infrared image, YOLOX, Swin Transformer
TP391.4
A
1001-8891(2022)11-1167-09
2022-06-10;
2022-08-10.
楼哲航(1999-),男,硕士研究生,主要从事无人驾驶车辆环境感知方向的研究。E-mail:15968194691@163.com。
罗素云(1975-),女,副教授,主要从事无人驾驶汽车环境感知及控制的研究。E-mail:lsyluo@163.com。
