基于代价敏感正则化和EfficientNet的糖尿病视网膜病变分类方法
2022-11-24王明智马志强赵锋锋王永杰郭继峰
王明智,马志强,赵锋锋,王永杰,郭继峰
(东北林业大学 信息与计算机工程学院,黑龙江 哈尔滨 150040)
1 引 言
糖尿病视网膜病变(Diabetic Retinopathy,DR)是最常见的视网膜疾病之一[1],这种疾病主要是由糖尿病性微血管病引起的,它会对糖尿病患者眼睛后部视网膜的小血管造成损伤,导致视网膜组织肿胀和视力模糊。根据2021年世界卫生组织(WHO)的报告显示,全球超过4.2亿人患糖尿病,预计到2030年将上升到5.78亿[2]。在全球的糖尿病人群中,约40%~50%可能会患有视网膜病变[3]。值得注意的是,DR病人失明的风险性是一般健康人群的25倍,所以,在全球范围内DR是20~65岁人群失明的主要因素之一。
事实上,如果及时发现和治疗,糖尿病视网膜病变对于视力的损害是可以控制甚至避免的。由于DR的早期几乎没有明显的症状,这使得及时诊断变得非常困难。传统的检查方案效率较低,经验丰富的临床医生可以手动检查和通过眼底数字图像进行诊断。这种诊断由于不同地区医疗水平的不一致,有时会需要很长的时间。此外,诊断的结果也因不同医生的主观性会产生一定的区别,其准确性在很大程度上取决于临床医生的专业知识[4]。通过定期眼底检查可以预防DR引起的失明。对于DR筛查的好处,部分西方国家已经形成了广泛的共识。大多数DR研究根据早期治疗糖尿病视网膜病变研究(Early Treat⁃ment Diabetic Retinopathy Study,ETDRS),使用国际临床疾病严重程度量表对DR进行分类。
在过去的10年里,研究人员已经开发了多个自动诊断系统。Pan等人[5]设计了眼底自适应成像系统的辅助工具并取得了良好的效果。Quellec等人[6]提出了一个模型,通过使用卷积神经网络(Convolution Neural Network,CNN)检测DR,利用敏感度标准[7]的修改产生热图,可视化每个像素在输出预测中的贡献。Lam等人[8]开发了几个关于二分类、三分类和五分类任务的模型,对于“无DR”或“严重DR”的病例在敏感性和特异性方面取得了较好的表现。Khojasteh等人[9]为了避免分割后的标识周围存在冗余边界和杂乱像素,采用关闭、打开和最后侵腐蚀3种形态进行了实验。然而,由于他们生成了3个输出概率映射,每种情况对应一个,因此很可能有些像素属于多种情况。Saha等人[10]利用一种Encoder-Decoder CNN来分割病灶,他们还采用一个额外的类对应视盘,以便网络能够更好地区分它与渗出物。Zhou等人[11]提出了一种融合多尺度特征及注意力机制的医学图像检索方法,引入注意力模块,对网络输出的特征图进行通道加权求和,提高关键特征通道的特征表达能力,使网络更能关注到图像中具有辨识性的病理特征区域。
Pang等人[12]构建两级深度卷积神经网络,完成了原始照片的特征提取、特征组合和结果分类,提出利用弱监督学习进行细粒度图像分类的改进方法在验证集上获得了0.85的kappa分数。Galdran等人[13]在2020年的一项研究中使用基于ResNeXt50网络的模型对DR进行分类,得到二次加权kappa分数为0.78。同年Goolge Health[14]训练了一个深度学习模型,从眼底照片预测ci-DME,模型受试者工作特征曲线(Receiver oper⁃ating characteristic curve,ROC)下面积(AUC)值为0.89。2020年,Sun等人[15]通过修改Inception模块的组成减少模型参数从而提升收敛速度,引入残差模块,解决了模型深度增加带来的梯度消失和梯度爆炸等问题,提出的DetectionNet深度卷积神经网络对糖尿病视网膜病变患病程度等级分类任务的识别率达到91%。Lands等人[16]在2020年利用DenseNet网络训练模型,该模型能够定位物体、检测物体和分割视网膜图像中的毛细血管,毛细血管异常可用于检测糖尿病患者的失明。他在EyePACS数据上得到了二次加权kappa 0.81的分数。
代价敏感正则化(Cost Sensitive Regulariza⁃tion,CSR)可应用于多种疾病的分类模型中,但很少出现在糖尿病视网膜病变检测模型中。基于上述分析,为了提高糖尿病视网膜病变分类模型的性能,本文提出基于EfficientNet网络的改进模型用于糖尿病视网膜病变的检测,有针对性地对眼底图像进行预处理和数据增强[17],然后输入到模型中,模型自动提取特征、训练参数、产生分级,引入代价敏感正则化对错误的分级施加不同程度的惩罚,尽可能地纠正模型中的分级错误。同时,从ImageNet训练得到的迁移学习[18]结果有利于提升模型的性能。
我们所提出的模型在DR主流数据集上表现出了很好的分类性能,对医生辅助诊断DR严重程度具有重要的参考意义。现在已有很多系统在实际生活中获得了很好的应用。EyeArt是美国食品和药物管理局批准的商业AI软件,该软件在检测DR时的敏感度为92%,特异性为94%。我们所提出的模型应用于临床当中,将会大幅减轻眼科医生的负担,同时也可以减少由于医生主观性所导致的误诊,具有非常广阔的临床应用前景。
2 改进的EfficientNet模型
EfficientNet是Google在ICML 2019提 出 的一个神经网络模型[19]。该模型提供了一种更有效的计算方式,并改善了最新的研究结果。通常,如果模型设计得太宽、太深或者分辨率太高,刚进行训练时,增加这些特性是有益的,但是训练很快就会达到饱和,模型的参数也会随之增加很多。通过人工去调整网络深度、网络宽度和输入图像的分辨率这3个参数使网络达到最佳性能是非常困难的,由于组合空间太大,人力无法穷举并验证所有可能组合的性能,因而效率不高。而在EfficientNet中,这些特性是按更优原则的方式扩展的,不会像传统的方法那样任意地缩放网络的维度,一切都是逐渐增加的。EfficientNet使用了组合缩放系数,用单一的组合缩放系数φ,同时缩放网络宽度w、网络深度d和输入图像的分辨率r,其缩放系数分别为α、β和γ。在约束条件下,在EfficientNet-B0中最好的参数是α=1.2、β=1.1、γ=1.15。根据算力的不同,我们提出了B0~B7的缩放尺度。EfficientNet-B0模型结构如图1所示。
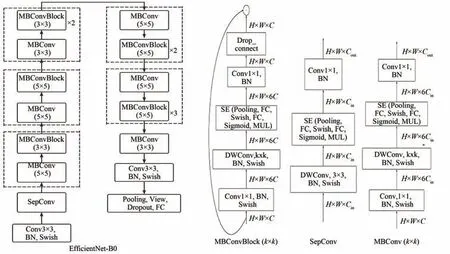
图1 EfficientNet-B0模型结构Fig.1 Model structure of EfficientNet-B0
2.1 标准损失函数改进
首先考虑模型R会产生预测R(x)=ŷ∈[0,1]×…×[0,1],此预测与相应的真实标签y进行比较。用y概括地指代整体标签y∈L={0,1,2,3,4},对应的独热编码为y∈{0,1}×…×{0,1},其在相应的分级下取1,其他分级下取0。我们使用两种标准分类损失函数作为基本损失函数。
第一种是交叉熵损失函数(Cross Entropy Loss Function,CE),其定义为:
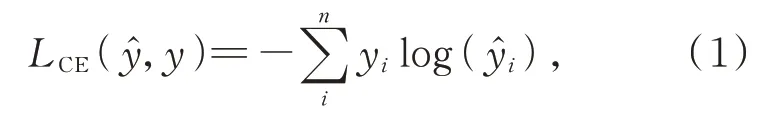
式中对于一个特定的例子(xi,yi),无论预测结果如何,最后产生的误差将保持不变[20]。
第二种基本损失函数是焦点损失函数(Focal Loss Function,FL),其定义为:
式中α是加权因子,γ是聚焦参数[21]。Focal Loss函数在多分类任务中已经得到广泛的应用,它是在标准交叉熵损失函数的基础上改进得到的,目标是克服样本类型不均匀和样本分类难度不均匀等问题。这个函数能够通过降低容易分类样本的权重,使模型在训练的过程中更专注在难于分类的样本上。相较于正确分类中的误差,Focal Loss对错误分类中的误差惩罚会更大。
2.2 代价敏感正则化改进
为了使模型能够在多分类任务的训练过程中惩罚不同类型的错误,进一步改进式(1)的结果,考虑使用一个惩罚代价矩阵M,将需要的惩罚设置到代价矩阵当中,并且随着预测标签ŷ与真实标签y之间的距离||y-ŷ||的增大,惩罚也会更大。
要想实现这种根据预测标签ŷ与真实标签y相差的不同程度来设置不同的惩罚,可以通过在代价矩阵M中的每一行编码这些惩罚,然后计算ŷ与M中对应行的标量积,如式(3)所示:
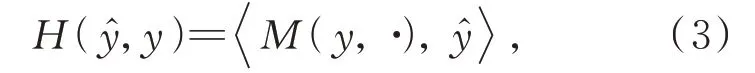
给出一个带有标签y=k和一个独热编码预测R(x)=[x1,x2,x3],代价敏感损失将通过简单的计算R(x)与惩罚代价矩阵M中第k行的标量积实现惩罚。值得注意的是,在不同的分类任务中,对于不同的错误分类情况,我们对它们的惩罚程度也不相同。本文对糖尿病视网膜病变严重程度进行5分类,根据Krause等人[22]收集的关于视网膜专家之间对于受试者严重程度的分歧以及在数据集的分级过程中裁定共识信息的研究,我们设计了具体的代价惩罚矩阵Md如式(4)所示,其中矩阵中数值越高,惩罚越低;数值越低,惩罚越高。

然而由于目前糖尿病视网膜病变数据集各分类间的高度不平衡,在实验中发现,如果只使用CSR的损失会导致复杂的卷积神经网络陷入局部最小值,因此,把CSR作为其他标准损失函数(CE,FL)的正则化结合起来,得到公式(5):
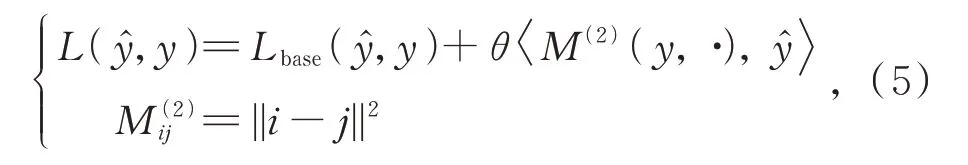
式中选择了基于L2规范化的代价矩阵M(2),它能最大化二次加权kappa分数,θ是正则化参数。
2.3 迁移学习方法引入
迁移学习是机器学习中的一种方式,也就是将源领域的知识转移到目标领域之中,让目标领域可以达到更好的学习效果。一般来说,源领域的数据量很充足,而目标领域数据量较小。如本文所研究的DR分类问题,当涉及医疗问题时,训练稳定且准确的模型是相当困难的,可用的数据也非常有限。考虑到这些分类任务之间是具有关联性的,利用迁移学习我们能够将曾经获得的模型参数共享给最新的网络模型,使模型可以更加方便地检测图像的低水平特征,进而提高并优化模型的训练效率,不再需要从零开始训练。
选择EfficientNet-B3网络作为分类任务的主要模型,在此模型上进行具体的调整。将模型在ImageNet数据集上训练,得到可以识别图像低水平特征的模型参数。随着特征图分辨率的降低,模型通道的数量将成倍增长,从而尽可能地提取和保留图像的语义信息,逐渐地将图像的纹理特征组合成类别特征。在ImageNet上得到一个预训练好的EfficentNet网络模型后,删除该网络模型顶部的全连接层,将网络的剩余部分作为EyePACS和Messidor-2两个数据集的特征提取层。
加载EfficientNet网络模型,模型底层使用从ImageNet预先训练好的特征提取层参数。同时对顶层网络进行微调,在模型顶部添加平均池化和dropout为0.2的随机失活层,并使用Soft⁃max激活函数的全连接层。将EfficientNet-B3输出的1 536张大小为13×13的特征图像作为顶层的输入。根据本文研究的DR分类问题,整个EfficientNet网络结构的输出具有与每个DR严重程度相对应的5个可能性值。
3 数据集及数据处理
3.1 实验数据集
本文采用Kaggle EyePACS作为主要数据集,它是糖尿病视网膜病变分类任务中使用最多、规模最大的公共数据集[23]。加州医疗保健基金会提出一个比赛,创建一个自动检测糖尿病视网膜病变的程序,包含在各种成像条件下拍摄的35 126张高分辨率的眼底训练图像。图像由一名经验丰富的专业人员根据ICDRDSS评分标准[24]进行标注。根据DR严重程度将图像分为5个等级(0,1,2,3,4),0级图像表示没有视网膜病变的迹象,而4级图像则表示增生性视网膜病变。图2展示了眼底图像上指示性DR病变,图3展示了不同等级糖尿病视网膜病变的眼底图像。Kaggle EyePACS训练集是非常不平衡的,0级图像 有25 810张,1级 图 像 有2 443张,2级 图 像 有5 292张,3级图像有873张,4级图像有708张,如表1所示。我们对数据集进行了详细的划分,将不同等级标签的图像分别分为两部分,其中90%用于训练网络,10%用于测试模型性能,即数据集的80%作为训练集,10%作为验证集,剩下的10%作为测试集。
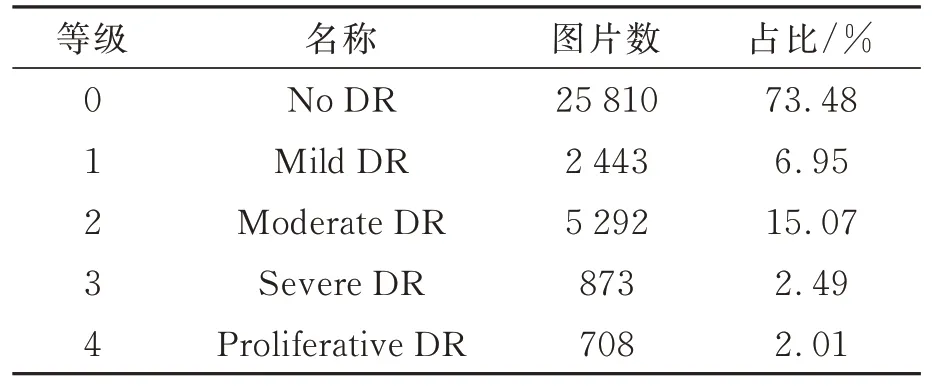
表1 Kaggle EyePACS数据集的数据分布Tab.1 Data distribution of the Kaggle EyePACS

图2 眼底图像上指示性DR病变Fig.2 Indicative DR lesions on a fundus image
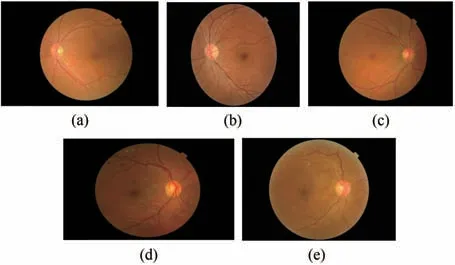
图3 不同病变等级的DR图像。(a)正常无明显病变;(b)轻度非增生性DR;(c)中度非增生性DR;(d)重度非增生性DR;(e)增生性DR。Fig.3 Different levels of DR images.(a)Normal with⁃out obvious lesions;(b)Mild non-proliferative DR;(c)Moderate non-proliferative DR;(d)Severe non-proliferative DR;(e)Proliferative DR.
值得注意的是,这些图像是由不同类型的成像设备在各种环境下拍摄的。由于这种可变性,数据存在模糊、聚焦、曝光、倒置、人为干扰等问题,因此在Kaggle EyePACS的数据集中,图像和真实标签都存在不可避免的噪声,这对任何模型的鲁棒性都有很高的要求。
我们使用Messidor-2作为第二测试集,该数据集包含了874名患者的1 748张图像,全部用于测试。与Kaggle EyePACS不同的是该数据集没有任何形式的明显噪声,包含了每幅图像关于糖尿病视网膜病变严重程度的图像级医疗诊断。由于它本身的自定义分级系统与ICDRDSS评分标准不同,我们采用Krause等人[22]发布的真实标签,这些标签是由3个视网膜专家共同表决得出的,因此,它们的质量比EyePACS的真实标签更加可靠。
无论是Kaggle EyePACS还是Messidor-2都是糖尿病视网膜病变等级分类相关研究中主流且具有代表性的数据集,数据集规模大、数据质量高等特点使其在训练实验和对比实验中可以有效地训练模型并真实地反映出模型性能的变化[25-26]。
3.2 数据预处理和数据增强
由于原始数据存在噪声和严重的数据不平衡问题,我们对数据集进行了有针对性的预处理和数据增强处理操作:
(1)随机缩放每幅图像10%;
(2)将图像从中心裁剪到416×416像素,以提高模型的训练速度;
(3)对图像进行对比度受限的自适应直方图均衡化(CLAHE)[27]处理,使视网膜的微妙结构变得更加清晰可见,更容易被检测;
(4)采用非局部均值去噪(NLMD)[27-28]方法去除图像中的部分噪声;
(5)将图像的色调、亮度统一到一定的范围内,将其归一化以提高模型的训练效果[29];
(6)将所有图像由原来的方形图像裁剪为以中心为圆点,以208像素为半径的圆形图像。
为了平衡训练集并增加用于训练的图像数量,处理数据集的类别不平衡问题,我们使用0°~360°的旋转、0~15像素的放大和缩小以及水平和垂直的翻转进行数据增强,对训练集中所有的图像进行随机的增强,对类1、类2、类3和类4设置不同的增强参数重复图像[30-31]。改进Effi⁃cientNet的糖尿病视网膜病变分类模型如图4所示。
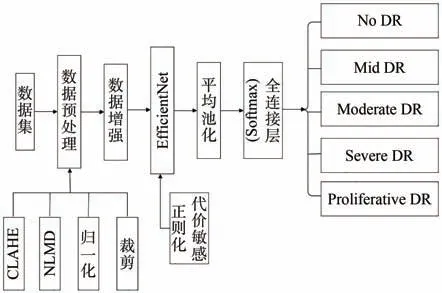
图4 改进EfficientNet的糖尿病视网膜病变分类模型Fig.4 Diabetic retinopathy classification model of improved EfficientNet
4 实验结果与分析
4.1 实验设置
本实验在Intel(R)Xeon(R)CPU E5-2407、32G内 存、Geforce RTX 3060 12G显卡 的Ubun⁃tu18.04服务器上调试运行。本文所提出模型的训练过程是基于Pytorch模型框架实现的。我们选择EfficientNet-B3体系结构,首先使用在ImageNet数据集中预先训练的权重文件进行训练,然后传输到EyePACS数据集并执行微调。设置式(4)中的参数θ=10来训练网络,使用随机梯度下降(Stochastic gradient descent,SGD)算法,Momentum设置为0.9,batch-size设置为8,学习率初始化为0.000 1。性能二次加权kappa分数在验证集中停滞时,学习率会降低10倍。本文设置了早停机制(Early Stopping),在10个epoch后性能没有提升时,训练就会停止。
损失函数会影响模型的性能,在相同网络条件下不同的损失函数会导致不同的实验结果。为了验证交叉熵损失函数和焦点损失函数在EfficientNet网络中的影响,设计了2组对比实验。实验1使用交叉熵损失函数的EfficientNet网络,实验2使用焦点损失的EfficientNet网络,2组实验均引入代价敏感正则化。
目前,糖尿病视网膜病变的分类通常采用Inception V3网络[32-34]进行数据训练。为了验证所引入的代价敏感正则化对模型的影响,本文设计了4组实验更加全面地对比实验结果。实验3使用Inception V3网络,实验4使用EfficientNet网络,实验5使用引入代价敏感正则化的Incep⁃tion V3网络,实验6使用引入代价敏感正则化的EfficientNet网络,4组实验均使用在实验1和实验2中表现更好的损失函数。
4.2 实验结果
本文采用准确率(Accuracy,ACC)、二次加权kappa分数和ROC曲线下面积AUC等指标来评价模型的性能。TP、FP、FN、TN分别表示真阳性、假阳性、假阴性、真阴性,ACC的计算公式为:

二次加权kappa分数的计算公式为:
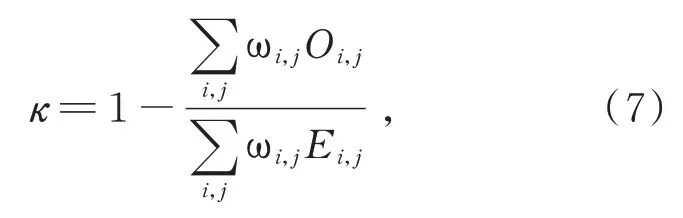
式中Οi,j表示将第i类判别为第j类的个数,ωi,j为加权系数,ωi,j和Ei,j的公式分别如式(8)和式(9)所示:
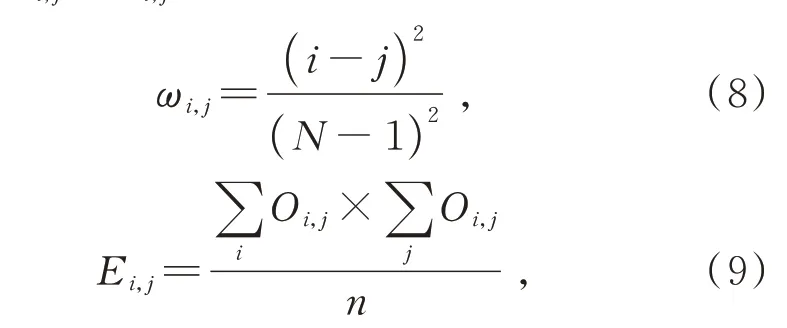
式(8)中N为分类的总类数,式(9)中n为样本的总数量。
4.3 实验对比分析
4.3.1损失函数的影响
从表2可以看出,在引入代价敏感正则化的EfficientNet网络中使用交叉熵损失函数时,模型的准确率为0.88,二次加权kappa分数为0.85,ROC曲线下面积AUC的值为0.91;使用焦点损失函数时,模型的准确率为0.90,二次加权kappa分数为0.86,ROC曲线下面积AUC的值为0.93,各项指标都有约2%的提升。交叉熵损失函数已经广泛应用于多分类任务中,而本实验结果验证了焦点损失函数在样本类别不均匀的多分类任务中能够通过对分类错误施加不同程度的惩罚来提升模型的结果,对性能产生更好的影响。
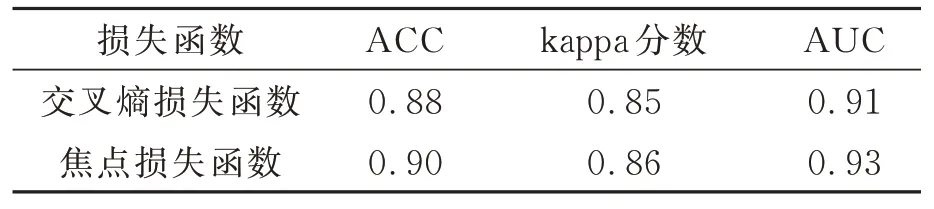
表2 使用交叉熵损失函数和焦点损失函数的Efficient⁃Net网络性能Tab.2 EfficientNet network performance with cross en⁃tropy loss function and focal loss function
4.3.2引入代价敏感正则化的影响
从表3可以看出,EfficientNet网络在使用焦点损失时引入代价敏感正则化所得到二次加权kappa分数为0.86,AUC值为0.93,表明该模型具有很好的性能,相较于不引入代价敏感正则化的EfficientNet网络各项性能指标提高了3%~5%。
为进一步验证引入代价敏感正则化对分类网络模型的影响,在Inception V3网络中引入代价敏感正则化。由表3的实验结果可以看出,作为DR分类常用的Inception V3网络在引入代价敏感正则化后准确率、二次加权kappa分数和AUC有2%~4%的提升。从上述结果可以看出,两种分类模型的各项性能指标均有所提高,特别是EfficientNet网络准确率提升到0.90以上,证明引入代价敏感正则化能够有效提高分类网络的性能。
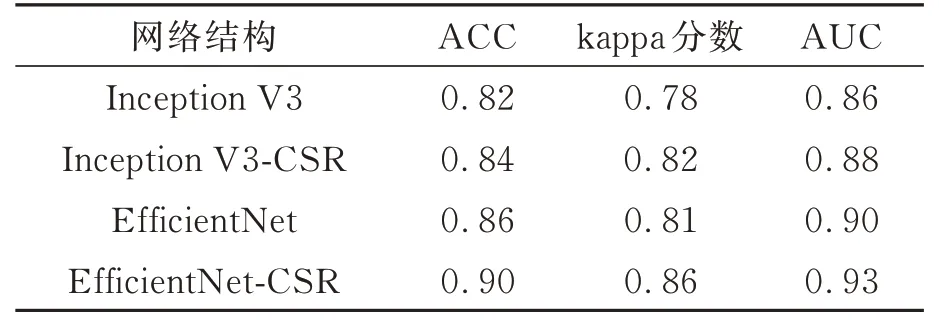
表3 实验结果对比Tab.3 Comparison of experimental results
4.3.3与其他网络模型的比较
[
我 们 将 本 文 方 法与Lands等 人16]在2020年利用DenseNet169网络所提出的方法进行对比,该方法在利用CNN对糖尿病视网膜病变进行分类的任务中具有较高的性能结果。使用二次加权kappa分数和ROC曲线下面积AUC作为评估模型性能的指标。同时为了进一步验证本文方法的先进性,另外选择了Galdran等人[13]在2020年使用的ResNeXt50网络模型和Inception V3网络模型,分别在EyePACS和Messidor-2两大分类数据集上进行实验,实验结果如表4所示。同时使用集平均方式计算了模型5分类的平均真阳性率和假阳性率,并绘制了模型在EyePACS测试集上的ROC曲线以及混淆矩阵,如图5所示。
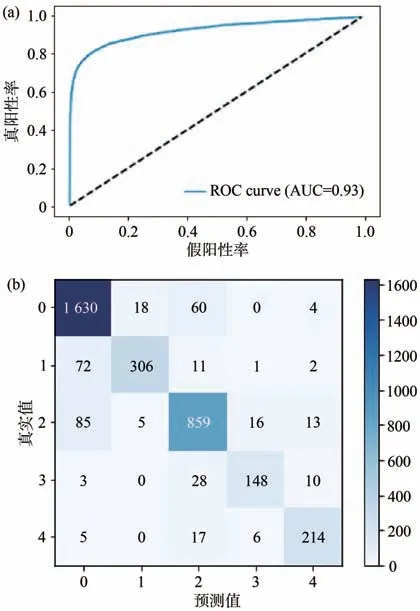
图5 EfficientNet-CSR模型在EyePACS测试集上的性能。(a)ROC曲线;(b)混淆矩阵。Fig.5 Performance of EfficientNet-CSR in the EyePACS test set.(a)ROC curves;(b)Confusion matrix.

表4 4种网络模型在两个数据集上的性能Tab.4 Performance of four Network models on two data sets
从 表4可 以 看 出,ResNeXt50网 络和Incep⁃tion V3网络在两个数据集上的二次加权kappa分数未超过0.80,AUC值未超过0.90,分类器性能一般。Lands等人[16]所提出的模型二次加权kappa分 数 为0.81~0.83,AUC超 过0.90,分 类器性能较好。本文所提方法在EyePACS数据集上的二次加权kappa分数为0.86,AUC值为0.93;在Messidor-2数据集上的二次加权kappa分数为0.88,AUC值为0.95,分类器性能很好,特别是二次加权kappa分数超出Lands等人[16]所提出模型的5%。
从图5的混淆矩阵可以看出,数据大部分分布在主对角线上,说明模型的准确率很高。模型把第0类预测成第2类,把第1类预测成第0类,把第2类预测成第0类,3种错误所占比例较高,我们可以在后续的实验中通过修改惩罚矩阵中的值加大对这3种错误的惩罚。ROC曲线位于偏左上角位置,表明我们的分类器性能较好,AUC值为0.93表明模型综合性能很好。
Lands等人[16]所提出的模型复杂,无法优化网络,模型参数量和计算量较大。利用Efficient⁃Net网络在网络宽度、网络深度等方面进行特征提取,同时引入代价敏感正则化加大对难分类别的惩罚,提高了模型对DR的分类效果,弥补了EfficientNet网络模型分类准确率不高的缺点。上述结果与分析表明,EfficientNet网络模型在该分类任务中比其他CNN模型具有更好的性能。与目前主流分类模型相比,本文所提出的引入代价敏感正则化的EfficientNet网络模型在糖尿病视网膜病变分类任务中具有更好的结果。
5 结 论
本文提出了一种引入代价敏感正则化的Ef⁃ficientNet网络模型对糖尿病视网膜病变进行分类的方法。将代价敏感正则化引入到焦点损失函数中,使模型能够惩罚错误的分类结果,更好地区分不同类别之间的差异。通过代价敏感正则化和EfficientNet的结合,使DR分类任务的综合性能得到了提升。在EyePACS和Messidor-2上得到0.86和0.88的二次加权kappa分数,实验结果充分证明了所提方法的优越性。与其他模型相同,EfficientNet网络模型也无法给出分类的具体原因,这也是糖尿病视网膜病变分类模型无法有效应用于临床当中的主要原因之一,未来可以在模型的结构上进一步优化完善。
