基于多尺度注意力及卷积递归神经网络的端子排文本识别
2022-11-22邵雪瑾王新新马俊先
郭 科,白 英,邵雪瑾,王新新,马俊先
(宁夏宁电电力设计有限公司 变电设计中心,宁夏 银川 750001)
变电站端子排线路巡检是保证变电站稳定供电的关键环节,巡检工作的主要内容是核对端子排实际线路与设计图纸是否一致.目前,巡检工作主要依靠人工,巡检人员目测端子排线路且记录下来,然后将记录结果与设计图纸进行对比.由于端子排线路密集,容易造成目测出错,严重影响巡检工作的质量和效率.随着机器学习的发展,机器识别场景文本得到深入研究和广泛应用[1-2].场景文本识别分为两个阶段:文本检测和字符识别[3-8].常见的场景文本识别(如招牌识别、车牌识别、路标识别等)中的文本区域清晰、文本量少,且分布稀疏.然而,变电站端子排及电缆套管编号的文字分布稠密、文本区域界定不明显、文字尺度变化大,给端子排文本识别带来挑战.针对该问题,该文提出一种基于多尺度注意力及卷积递归神经网络(multi-scale attention and convolution recurrent neural network,简称MSA-CRNN)的识别方法,用于端子排文本识别.在文本检测阶段,利用多尺度注意力(multi-scale attention,简称MSA)模块对文本进行检测,解决文本区域界定不明显和文字尺度变化大的问题,在保证识别速度的同时增强对文字尺度变化的鲁棒性;在字符识别阶段,使用卷积递归神经网络(convolution recurrent neural network,简称CRNN)对文字进行识别,以提高识别的准确率.为了证明MSA-CRNN的有效性,从某变电站采集端子排图像,构建测评数据集.基于该数据集,设计实验,将MSA-CRNN方法与4种通用方法的识别结果进行对比.
1 相关研究
1.1 场景文本识别
场景文本识别是光学字符识别领域中的研究热点,应用于图像搜索、即时翻译、机器人导航、工业自动化等领域.文本检测可分为以下3种:像素级、组件级及字符级检测.像素级检测使用卷积神经网络端到端地学习和生成密集的预测图,判定原始图像中的每个像素是否属于文本实例[9-13].组件级检测仅对文本实例的局部区域进行检测[14].字符级检测通过深度神经网络学习字符中心及其链接,以高斯热图的形式呈现能代表字符区域的分割图[15].对端子排的文本识别,像素级、组件级的检测粒度过细,不能解决文本区域界定不明显的问题,故该文采用字符级检测.
随着深度学习的广泛应用,字符识别的主流技术使用卷积神经网络将图像编码至特征空间,进而获得字符的特征编码.字符识别主要有连接时序分类(connectionist temporal classification,简称CTC)[16-18]和编码-解码[19]方法.CTC方法将输入图像视为一系列垂直像素帧,网络输出像素帧的预测结果,然后将预测结果转化为字符串.CRNN是CTC的基本模型,由卷积神经网络(convolution neural network,简称CNN)、递归神经网络(recurrent neural network,简称RNN)和解码组成,其中CNN用于提取图片特征,RNN用于建模、解码用于对齐输出文本.CTC方法仅使用单词级注释就可进行端到端训练,无须使用字符级注释,计算复杂度较低.编码-解码方法借鉴机器翻译模型[20],输出长度可变,以满足不同场景文本识别的需要.编码-解码方法与注意力机制结合,将输入序列与输出序列对齐[21-24].相比编码-解码方法,CTC方法依赖语言模型程度低,且有更好的对齐方式.考虑到端子排编号非自然语言,不含有单词级语义,故该文采用CTC方法进行字符识别.
1.2 注意力机制
计算机视觉中的注意力机制源自人类视觉模仿,其核心是从图像的众多视觉信息中发现对任务最有价值的部分.文献[25]创造性地提出空间转换器结构.文献[26]设计并实现了一种注意力模块,在图像识别方面取得了不小的进展.文献[27]提出了有向自注意力网络的通用框架,在多个计算机视觉处理中均有优异表现.文献[28]将注意力机制与3维密集卷积结合,提取时空特征,成功识别了视频中的人体动作.
在端子排文本识别中,复杂背景环境给文本识别带来噪声,一些电器元件易被识别为文字,文本区域小且分散也增加了端子排文本识别的难度.因此,该文引入注意力机制辅助卷积递归神经网络识别目标文本.
2 方法描述
图1为MSA-CRNN方法框图.该方法通过VGG19(visual geometry group 19)[29]不同层数的卷积层对端子排图像进行特征提取,将其作为MSA模块的输入.这些卷积层分别提取不同尺度文字的特征,如浅层卷积提取小尺度文字特征,而深层卷积则提取大尺度文字特征.为了融合不同尺度的特征,该文将用卷积与批归一化结合,对特征进行降采样,如图1中的MSA模块所示,其中⊕表示特征拼接操作,⊗表示矩阵点乘操作.MSA模块依据VGG19提取的特征发现文字区域,使用ROI Align(region of interest align)[30]从VGG19输出的特征图中抽取描述文本区域特征的N个特征向量.特征向量输入后续的双向长短时记忆(bi-directional long short-term memory,简称Bi-LSTM)网络模块,最后利用CTC方法对预测结果进行序列转录,得到不定长的字符串.
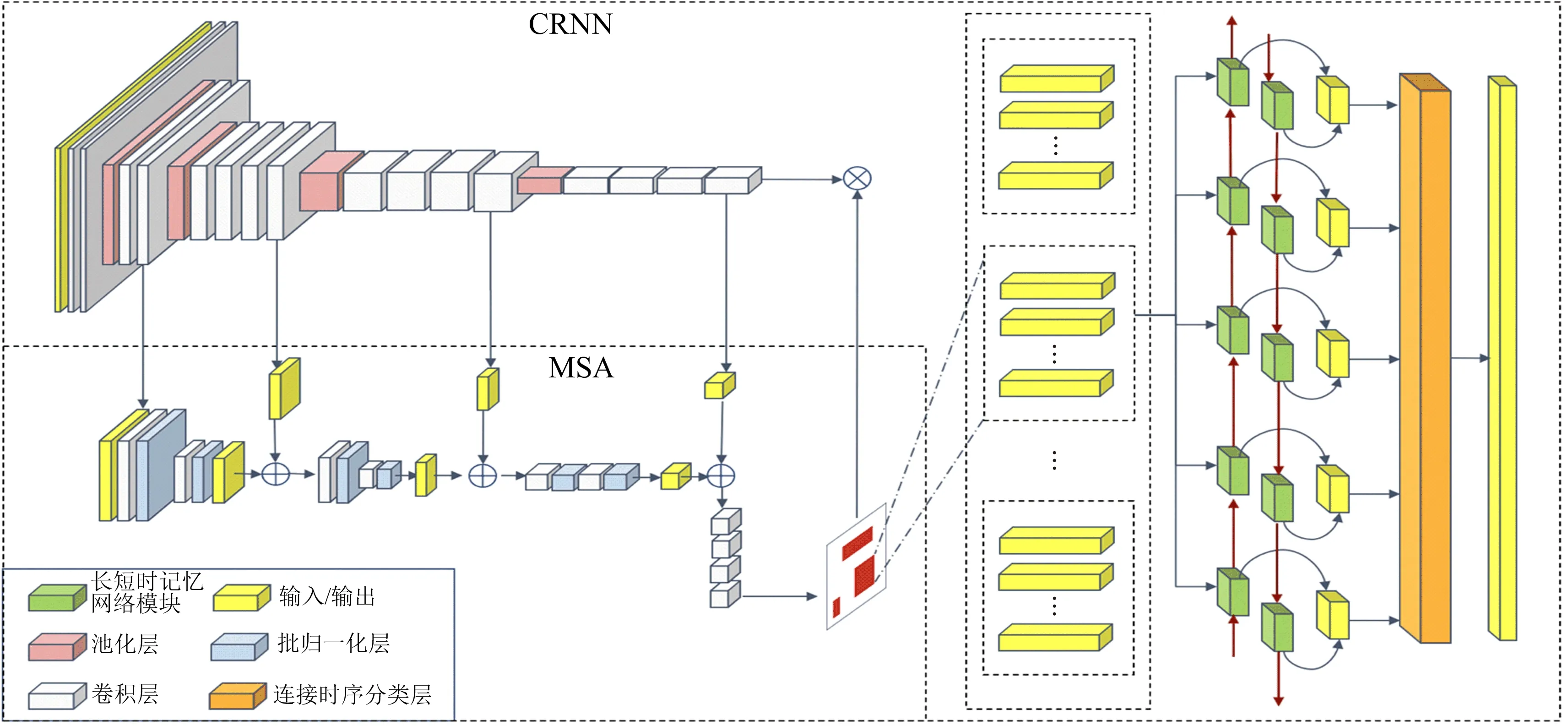
图1 MSA-CRNN方法框图
2.1 特征提取
VGG19能为后续CRNN和MSA提取视觉特征,VGG19包含19个隐藏层(16个卷积层、3个全连接层).考虑到端子排文本识别需同时对中英文和数字字符进行识别,该文将ImageNet[31]的预训练权重作为初始化参数,并去掉3个全连接层.将最大池化的第3,4个窗口像素均从2×2调整为1×2,这样做一方面是为了适应英文字符尺度小的特性,另一方面是为了使CNN输出的特征图能直接作为RNN的输入.
2.2 文本检测
MSA模块用于文本检测.拍摄角度受限使文字尺度变化大,需从VGG19输出的多个卷积层中抽取多个尺度特征,然后将其融合.MSA模块将池化前的特征作为输入,考虑到第2层卷积的特征感受野过小,就没有使用该层的输出特征.对于第4,8,12,16层的特征,由于尺度不同,为了能对这些特征进行拼接,需使用浅层卷积网络对这些特征进行降采样.卷积层降采样能更好地将关键信息保留.特征拼接后,使用一个4层的卷积网络对特征进行融合,其参数如表1所示.该4层卷积网络的输入是一个有1 408个通道的特征图.
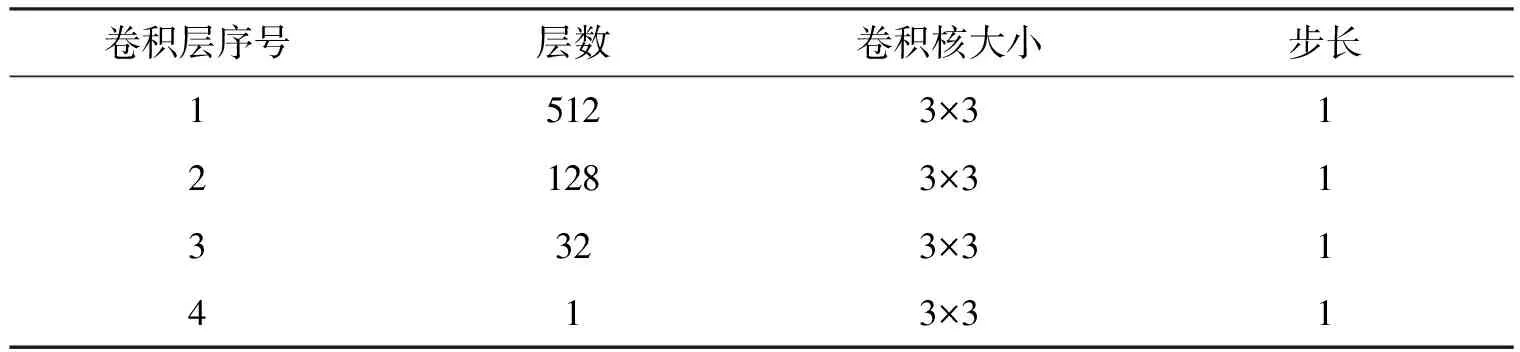
表1 4层卷积网络的参数
对融合后的多尺度特征图,使用Grad-CAM方法[32]生成文本区域的热力图.热力图用于生成文本区域的包围框,这些包围框一方面用于后续文本区域特征的提取,另一方面用于计算定位损失,指导MSA模块的训练.使用Sigmoid函数计算文本与背景的二分类概率,用于热力图的生成.
为了界定文本与背景的范围,需对热力图进行二值化.采用固定阈值进行二值化,即对文本与背景二分类概率超过阈值的像素,置为1,否则置为0.阈值越大,表征文本区域的像素越少.实际训练过程中,阈值的设置根据训练数据集样本的特征分布决定.该文根据训练数据集文本与背景像素占比的抽样统计结果,将阈值设置为0.3.
对二值化后的图像,需计算每个连通域的包围框,再对相交的包围框进行融合,进而获得文本区域图像.图2为基于热力图的文本区域包围框的融合示意图.
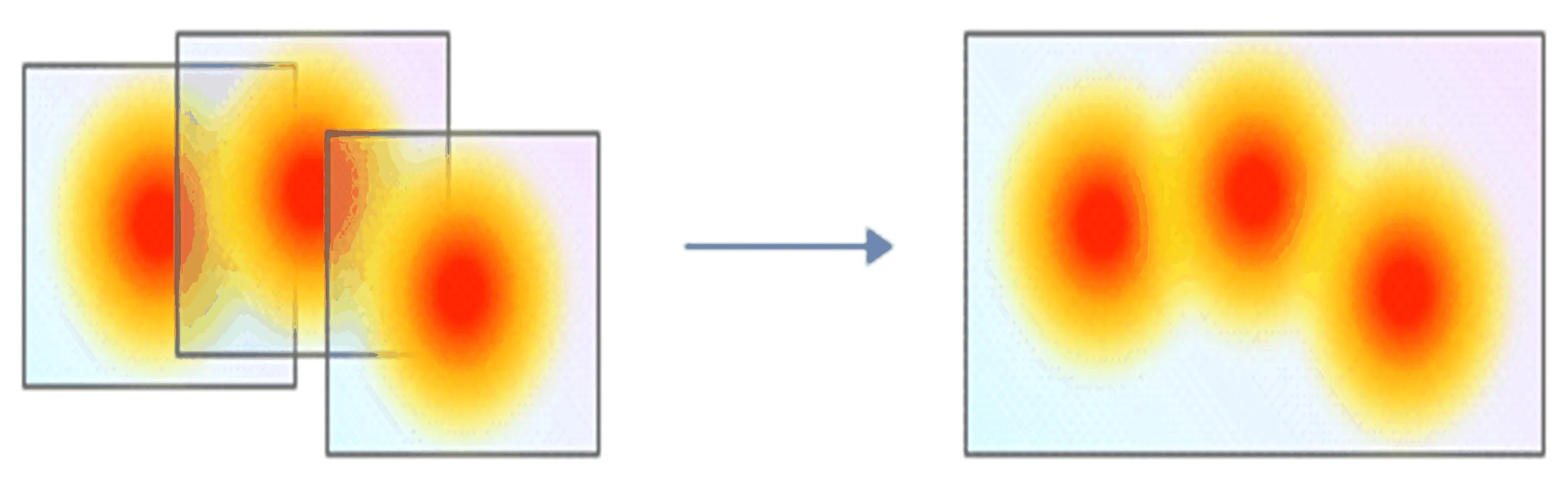
图2 基于热力图的文本区域包围框的融合示意图
2.3 字符识别
2.3.1 特征向量生成
根据MSA模块输出的包围框,基于ROI Align设计特征向量提取算法.ROI Align使用更精准的坐标计算代替四舍五入的取整,能保留更准确的特征信息.传统的ROI Align为了从候选区域提取固定大小的特征图,需预先定义2个参数:特征图的大小K和采样距离S′.将边界值为浮点数的包围框等分为K×K个网格,每个网格等分为S′×S′个计算单元,计算单元的几何中心作为采样点.根据特征图上距离某采样点最近的4个像素值,使用双线性插值法计算该采样点的像素值.获得该采样点像素值后,对于该采样点同一子区域的其他采样点实施池化操作,将最大池化值作为该子区域的特征值.
使用固定的参数K和S′时,由于包围框面积不确定,如果每个包围框均产生相同数量的子区域和采样点,小包围框会浪费计算资源,大包围框则会丢掉信息.鉴于此,该文对ROI Align算法进行改进,图3为改进ROI Align算法提取特征图的示意图.图3中,虚线表示特征图,实线表示包围框,包围框划分为3个子区域,每个子区域包含3个采样点,距离左上角采样点最近的4个像素被标出.
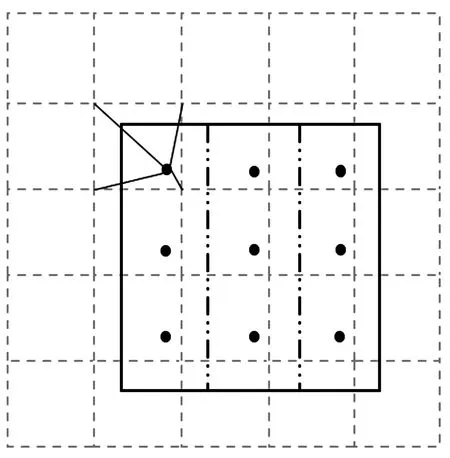
图3 改进ROI Align算法提取特征图的示意图
改进ROI Align算法动态划分包围框子区域大小及采样点数量,对小包围框能节省计算资源,对大包围框能提取更多的信息.在包围框面积变化较大的端子排文本识别场景中,改进ROI Align算法能提升计算性能和识别精度.
2.3.2 字符识别
在字符识别环节,该文构建了一个有两个隐藏层的Bi-LSTM,每个隐藏层有256个节点.采用Bi-LSTM的原因有两点:一是自然场景中的文字往往不是相互独立的,通过Bi-LSTM捕捉文本上下文信息,能增强字符识别的鲁棒性,提升模糊、遮挡字符的识别准确率;二是CNN提取的特征向量的长度与字符并不一一对应,一些尺度较大的字符需多帧描述,而Bi-LSTM能记忆前后帧的信息,能对字符进行整体识别.
3 实验及结果分析
3.1 数据集
目前还没有端子排文本识别数据集,该文从某变电站现场采集图像数据,经筛选和整理后构造了一个包含1 059张端子排图像的数据集,并对其中的端子排编号和电缆套管编号的位置和内容进行了人工标注.该数据集被随机分成包含800张图像的训练集和包含259张图像的测试集,用于验证该文方法的有效性.
3.2 评价指标
将字符识别准确率、召回率和F1作为指标,对方法进行定量评价.准确率、召回率、F1的计算公式[33-34]分别为
(1)
(2)
(3)
其中:在“检测”任务中,TP表示损失率不超过0.5的被检测图像数,FP表示损失率超过0.5的被检测图像数,FN表示未被检测到的真实标注框的数量;在“检测+识别”任务中,TP表示定位和识别均正确的字符数,FP表示定位正确但识别错误的字符数,FN表示定位错误的字符数.
为了评估方法的计算性能,该文还使用参数量及FPS(frame per second)指标,FPS可描述方法处理图像的速度.
3.3 实 验
该文将MSA-CRNN与通用的4种场景文本识别方法进行比对,实验步骤如下:
(1)使用模型DB(differentiable binarization)[8]对文本进行检测;分别使用字符识别模型CNOCR(Chinese OCR)[33],Tesseract[34],MA-CRNN(multi-scale attention CRNN)与DB模型(这些组合分别记为DB+CNOCR,DB+Tesseract,DB+MA-CRNN),对字符进行识别.
(2)使用端到端场景文本识别方法FOTS(fast oriented text spotting)[5]对文本进行检测,对字符进行识别.
(3)使用MSA-CRNN对文本进行检测,对字符进行识别.
(4)通过评价指标,对比MSA-CRNN与DB+CNOCR,DB+Tesseract,DB+MA-CRNN,FOTS的字符识别效果.
以上实验的硬件环境均为:Intel Core TMi7 CPU,Nvidia Titan XP GPU,32.7 GB,Ubuntu 16.04.
3.4 结果分析
不同方法的实验结果如表2所示.从表2可看出,在识别效果方面,MSA-CRNN的Rprecision达到87.59%,Rrecall达到61.35%,F1达到72.16%,均高于其他4种方法的对应指标,说明MSA-CRNN更适用于端子排文本识别场景;在计算性能方面,MSA-CRNN的参数量为34.98×106个,低于其他4种方法的参数量,FPS达62.03帧·s-1,高于其他4种方法的FPS,说明MSA-CRNN具有更高的计算性能.

表2 不同方法的实验结果
图4为5种方法的识别结果及人工标注结果,其中GT表示人工标注的结果.由图4可知,相对于其他4种方法,MSA-CRNN方法的识别结果更接近人工标注结果,表明MSA-CRNN对端子排文本识别的准确率更高.

图4 5种方法的识别结果及人工标注结果
4 结束语
该文提出了基于MSA-CRNN的端子排文本识别方法.将MSR-CRNN方法与通用的4种场景文本识别方法进行对比实验,结果表明:相对于DB+CNOCR,DB+Tesseract,DB+MA-CRNN和FOTS,MSA-CRNN方法更适用于端子排文本识别场景,有更高的计算性能,识别结果更接近人工标注结果.因此,该文方法具有有效性.后续将探寻使用MSA模块采样的优化策略,在MSA多尺度单元间引入短路连接,融合不同尺度的特征,开展大规模数据验证工作.
