基于大数据技术的分布式电商信息实时展示系统的设计与实现
2022-11-22李云鹏
李云鹏
(西北工业大学 陕西 西安 710129)
0 引言
随着电子商务、移动网络以及社交软件的兴起,将我们推向了一个以PB(1024TB)为单位拥有海量信息的大数据时代。面对海量的数据信息,我们迫切需要以更高效的方法进行数据挖掘、数据处理,这也是我们在大数据时代所面临的新挑战。为解决数据的存储和计算方面的难题,需要大数据技术来构建大数据平台[1]。传统的大数据平台包括Hadoop、Spark、Flink等。这些大数据平台具有对海量数据进行分析的能力,可以将海量数据转化为生产力,从而产生实际价值。针对不同的数据类型以及复杂的应用场景,对数据的计算模式分为以下四种:批处理计算、流计算、图计算以及查询分析计算。本文将聚焦于流计算进行探讨。
在传统的数据处理过程中,我们先将数据存入数据库中,当需要时再去数据库中进行检索,将处理结果返回给请求的用户,更多应用于离线计算场景中。而针对实时性要求较高的场景,我们期望延时在秒甚至是毫秒级别,于是引出了一种新的数据计算结构——流式计算,即对无边界的数据进行连续不断地处理。当今市面上主流的Spark平台,也推出了流式处理子框架——Spark Streaming。Spark Streaming是一个高吞吐、高容错、低延时的实时处理系统,可以从Kafka、flume、kinesis或者TCP套接字等多种数据源中获取数据,然后利用复杂的操作(如map、reduce、window等)对数据进行处理,最终将处理后的数据输出到文件系统、数据库或者控制台上,具体的输入输出过程如图1所示。本文基于流计算的算法,提出一种针对电商信息进行实时展示的系统设计与实现方案。

图1 Spark Streaming框架的数据处理示意图
1 环境部署
首先,为高效构建分布式处理系统,从而保证数据的高效处理,需在不同的数据节点分别部署好基于Linux(如Ubuntu、Debian等)系统运行环境,以保证对海量实时数据能高效进行模拟分析。本文推荐的大数据框架、数据库系统、辅助中间件软件及版本如下:Hadoop2.7.1,Spark2.4.0,Kafka2.11,Zookeeper3.6.3,MYSQL5.7.31。配置好基本的环境后,启动集群环境,启动了Zookeeper服务以及Kafka服务后,使用JPS命令进行验证,如图2所示。出现Master节点以及NameNode节点,证明服务已经成功启动,系统具备可运行条件。

图2 验证服务启动
2 核心技术概述
2.1 Spark Streaming流计算处理框架
与其他大数据框架Storm、Flink一样,Spark Streaming是在Spark Core(一种基于RDD数据抽象,用于数据并行处理的基础组件)基础之上用于处理实时计算业务的框架[2]。其实现原理就是把输入的流数据按时间切分,切分的数据块用离线批处理的方式进行并行计算。输入的数据流经过Spark Streaming的receiver组件,数据被切分为DStream,然后DStream被Spark Core的离线计算引擎执行并行计算。Spark Streaming与其他主流框架的对比如表1所示。

表1 Spark Streaming与其他主流框架的主要性能对比
2.2 Kafka分布式发布订阅消息体系
Kafka是一种高吞吐量的分布式发布订阅消息系统,以生产者/消费者模式,通过队列交换数据,在实时计算领域有着非常强大的功能。本系统主要利用Spark Streaming计算框架实时地读取Kafka中的电商数据然后进行并行计算。Kafka在本系统中起到了一个中间件的作用,即搭建了程序间的数据管道,用来转换并响应实时数据[3]。
2.3 WebSocket通信机制
WebSocket是HTML5中服务端和客户端进行双向文本或二进制数据通信的一种新协议。它与HTTP通信协议不同的是,WebSocket提供全双工通信[4]。对于传统的HTTP通信方式,只有当客户端发起请求后,服务器端才会发送数据。而WebSocket则可以让服务器主动发送数据给客户端,是服务器推送技术的一种[5]。由于本系统后台产生新的数据,需要在前台页面实时展示出来,故选择了WebSocket通信机制。
本系统借助的Flask-socketio模块,封装了Flask对WebSocket的支持,WebSocket在连接建立阶段是通过HTTP的握手方式进行的,当连接建立后,客户端和服务端之间就不再进行HTTP通信了,所有信息交互都由WebSocket接管。Flask-SocketIO使Flask应用程序可以访问客户端和服务器之间的低延迟双向通信,使客户端建立与服务器的永久连接。
2.4 基于Scrapy的爬虫框架
Scrapy是由Python基于twisted框架开发的一种高效、快速的web信息抓取框架,用于抓取web站点并从页面中提取结构化的数据,只需要少量的代码,就能高效地获取所需数据。Scrapy集成了高性能异步下载、队列、分布式、解析、持久化等诸多功能。值得注意的是,由于网站数据具有一定的商业价值,需科学合理地使用爬虫工具进行数据获取,本系统所获取的数据仅用于学术探索,且已经获取相关网站授权。
3 电商信息实时展示系统详细设计
网上购物,作为一种依托于互联网的新型购物方式,为人们的生活带来了不少的便利。诸如淘宝、京东、亚马逊等众多电商平台产生了大量的购物数据,通过合法的爬虫技术实时爬取这些数据,并进行可视化分析,从数据中提取关键信息,从而有利于对电商平台进行升级。因此,基于大数据相关技术(Spark Streaming+Kafka+We bsocket+Scrapy)本文设计并开发了电商信息实时展示系统,后期通过源码剖析,针对并行化的方向进行了系统的优化升级。
3.1 总体设计
在本系统中,通过爬取到的电商平台的交易数据及购物日志(注:此类信息为电商平台主动公布,仅作学术研究,不涉及版权问题;如个别电商平台未公布,需与平台进行联系,以免侵权),模拟实时数据流的产生,用Spark Streaming框架分析每秒购物人数,每秒钟平台上用户的操作类型等,并利用WebSocket将数据实时推送给客户端,最后浏览器将接收到的数据实时展现在web端,进行了数据的可视化展示。本系统采用模块化设计思路,共分为以下四个模块:数据获取模块、实时数据模拟模块、Spark Streaming实时处理模块以及可视化展示模块。本系统总体架构图如图3所示。

图3 系统总体架构图
3.2 数据获取模块设计
数据获取模块通过爬虫技术,借助Python提供的Scrapy、Requests等库,爬取电商平台的购物日志,并以csv的格式存储到了本地。由于仅做研究使用,本系统中需要关注的数据只有:gender项,其中0表示女性,1表示男性,2和NULL表示未知性别;action项,其中0表示点击行为,1表示加入购物车,2表示购买,3表示关注商品;cat_id项,表示商品类别id。该数据集包含上万条用户购物日志,可模拟大批量的实时数据。然后实时数据模拟模块把对数据进行预处理后发送给Kafka,接下来Spark Streaming再接收gender数据进行后续处理。
3.3 实时数据模拟模块设计
该模块需要启动Kafka服务,实例化多个Kafka生产者,用于读取用户日志文件。每次读取一行或多行,对关注的数据进行清洗后,每隔固定时间发送给Spark Streaming实时处理模块,这样在固定时间间隔内,可发送一定数量的购物日志,以便后期进行可视化展示。
3.4 Spark Streaming实时处理模块设计
该模块为整个系统的核心模块,基于Spark流计算的模式按秒来处理Kafka发送来的数据流。利用Spark Streaming接口reduceByKeyAndWindow,设置窗口大小和滑动步长进行数据处理、格式转换等操作,并把检查点文件写入分布式文件系统HDFS。最后,再实例化一个KafkaProducer实例,用于向Kafka投递消息,这里发送数据的topic为result。由于Web端最后可视化展示所需要的数据又来自Kafka,所以可以实例化一个KafkaConsumer来测试实时处理模块是否已经把处理后的数据发送到“result”的topic上,测试结果如图4所示。

图4 测试结果
3.5 可视化展示模块设计
本模块主要利用Flask-SocketIO接收来自kafka的处理后的数据,并将结果实时推送到浏览器端,同时存入MySQL数据库进行数据备份。通过编写对应的html文件以及js文件,实时接收服务端的消息,利用pycharts在web端绘制可交互的图表,将结果实时进行展示。值得一提的是,该可视化图表均为动态展示效果,随着时间变化实时数据改变,图表也随之而变化。后期,针对不同的数据,均可进行不同形式的可视化展示。部分效果图如图5、图6所示。
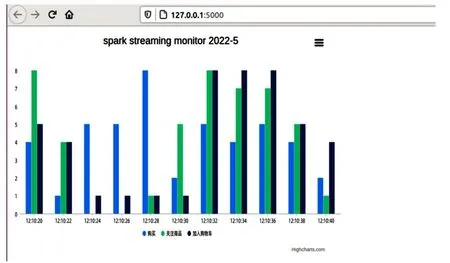
图5 效果图1

图6 效果图2
4 结语
综上所述,本文基于分布式大数据技术,设计并实现了电商信息实时展示系统,可以实时模拟流数据,并借助Spark Streaming对数据进行处理,并做可视化动态展示。针对系统的优化问题,参考了Spark框架中的部分开源代码,进行了分析测试,选用了高性能算子,替代常规的算子,达到性能上的提升。通过Spark Streaming、Kafka、WebSocket等技术,可将此开发模式复制到其他类似应用场景,对海量数据实时处理提供了一种可行的解决方案。
