基于混合深度网络的电站锅炉NOx排放预测
2022-11-22马永光
武 松,马永光
(华北电力大学自动化系,河北 保定 071003)
0 引 言
燃煤电站是我国电力生产工业的主体,同时也是NOx等大气污染物重大排放源。尤其是随着“双碳”目标的提出,我国近年来不断提高燃煤电站NOx的排放标准。如何有效降低电站锅炉NOx等污染物排放成为了企业面临的一个重要难题。为了降低NOx的排放,建立准确的NOx排放预测模型是基础。准确预测NOx排放量有利于优化锅炉燃烧过程,降低选择性催化还原(Selective Catalytic Reduction,SCR)烟气脱硝成本[1-2]。
NOx生成机理十分复杂,传统的机理分析建模难以准确估计NOx的排放量[3]。基于数据驱动和智能算法的建模因其不涉及复杂的过程机理计算而受到研究人员越来越多的重视[4]。智能建模算法主要包括人工神经网络(Artificial Neural Network,ANN)[5]、支持向量机(Support Vector Machine,SVM)[6]、深度学习网络(Deep Learning Network,DNN)[7]等。刘岳[8]等人提出了一种基于特征优化的长短期记忆(Long Short-Term Memory,LSTM)的NOx建模方法,并使用通过网格搜索和改进粒子群算法确定 LSTM神经网络的超参数,但是该模型收敛速度慢,容易发生过拟合。LI[9]等人使用卷积神经网络(Convolutional Neural Network,CNN)对锅炉NOx排放进行预测,但并未利用数据的时间依赖特征。王英男[10]建立了一种结合注意力机制(Attention Mechanism, AM)与LSTM的混合预测模型AM-LSTM,所建立的模型预测精度高,泛化能力好。李楠[11]设计了基于深层自动编码网络(Deep De-noising Auto-Encoder Network,DDAEN)的NOx预测算法,但是深度学习框架结构复杂,特征学习较为耗时。
针对以上问题,本文基于某电站锅炉历史运行数据,提出了一种融合全局注意力机制(Global Attention Mechanism, GAM)与CNN、双向长短期记忆(Bi-directional Long Short-Term Memory,BiLSTM)的混合深度学习模型来预测未来时刻电站锅炉出口NOx排放量。首先对历史数据进行预处理,去除离群值和噪声,然后确定模型输入变量并估计输入变量与NOx排放量之间的时间延迟,重构数据序列,实现输入输出数据序列在时间维度的对齐。然后基于Matlab平台构建CNN-BiLSTMGAM模型,CNN用于提取序列数据的局部空间结构特征,BiLSTM可以利用其前后两个方向的时间依赖特性,GAM可以自动分配神经元隐藏状态输出权重,突出重要信息的影响,进一步提高模型预测精度。另外还采用了正则化技术(Dropout)结合Adam优化算法提高模型收敛速度并防止过拟合。最后将所提出模型的预测效果与其他几种典型预测模型进行对比,以说明所提出模型的有效性。
1 模型原理
1.1 CNN网络
CNN是一种前馈神经网络,主要用于从原始数据中提取特征,具有很好的非线性学习能力。它的主要特点体现在稀疏连接与权值共享,这种网络结构更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。
CNN网络具有多层结构,卷积层是CNN的核心,用来提取对象局部特征。池化层在卷积层之后,通过最大池化或平均池化操作对卷积层所得特征图(Feature Maps)再次提取其更深一层的特征。全连接层将池化层提取的特征进行汇总,把池化层输出的张量重新拼接成一个一维向量,形成最终输出[12]。CNN结构见图1。
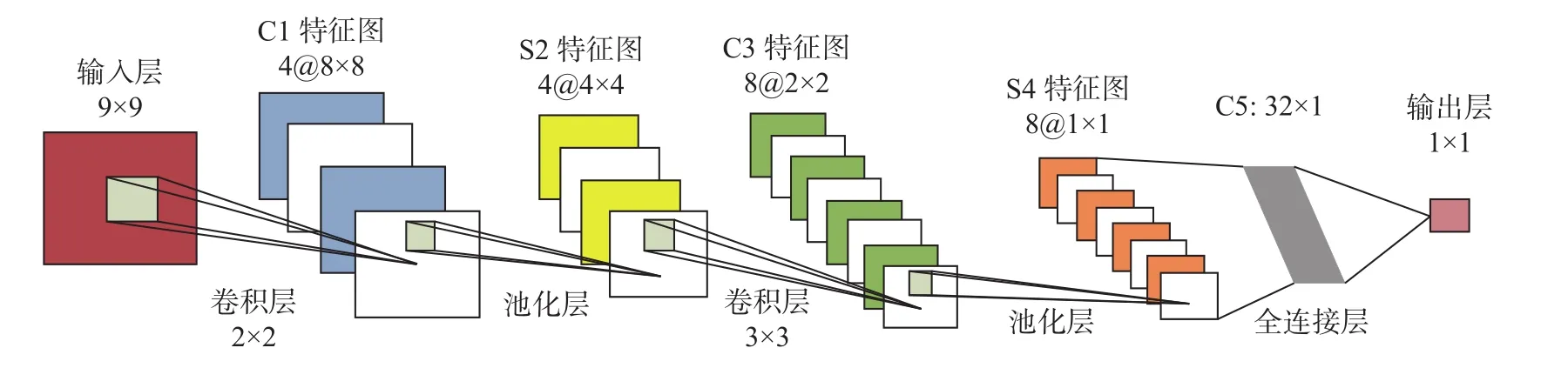
图1 CNN网络结构图
CNN网络卷积层计算过程为:
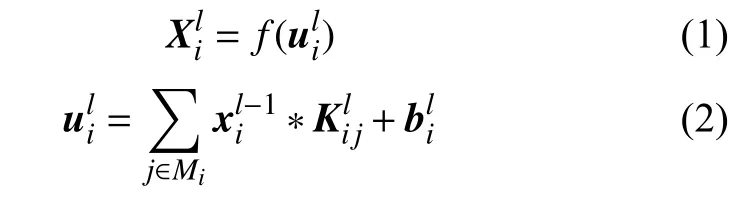
f(·)——激活函数,这里选择ReLU;
Mi——计算的输入特征图子集;
“*”——卷积;
1.2 BiLSTM网络
LSTM是一种循环神经网络(Recurrent Neural Network,RNN),通过其内部的门结构可以解决RNN在处理较长的时间序列时出现的梯度消失和梯度爆炸问题,是对RNN的一种改进,每个LSTM神经元细胞一般包括遗忘门(Forget gate)、输入门(Input gate)和输出门(Output gate)[13-14]。LSTM 神经元细胞结构如图2所示。
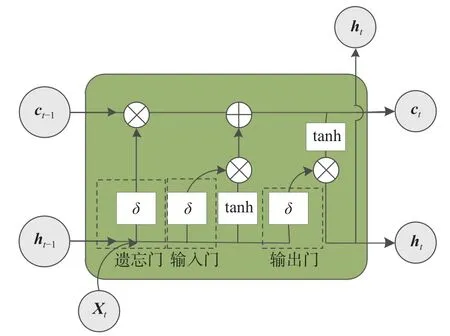
图2 LSTM细胞结构图
图2中,LSTM网络计算过程为:
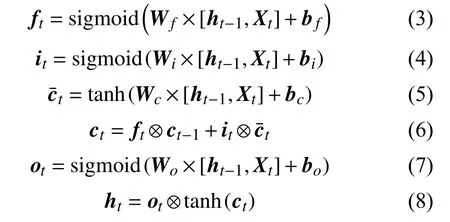
式中:Xt——当前输入;
ht-1——上一时刻神经元细胞输出;
ft、it、ot——当前时刻细胞遗忘门、输入门、输出门的输出;
W——权重系数矩阵;
b——偏置项向量;
ct-1——上一时刻神经元细胞状态;
——当前时刻细胞更新量;
ct——当前时刻细胞最终状态更新;
ht——当前时刻细胞最终输出;
“⊗”—— 矩阵对应位置元素相乘(Hadamard乘积);
δ(sigmoid)和tanh——激活函数。
BiLSTM 由两个方向相反的LSTM层组成,可以获取序列前后两个方向的信息。BiLSTM网络结构如图3所示。

图3 BiLSTM结构图
1.3 全局注意力机制
全局注意力机制由Luong等在2015年提出,它是对传统注意力机制的改进。它在经典Seq2Seq编码器—解码器(Encoder-Decoder)结构基础上构造一个注意力层(Attention Layer),通过计算网络隐含层神经元历史时刻隐藏状态与当前时刻隐藏状态之间的关联程度,将更多的注意权重分配到关联程度大的部分,实现对数据特征的自适应关注[15]。计算过程如下:
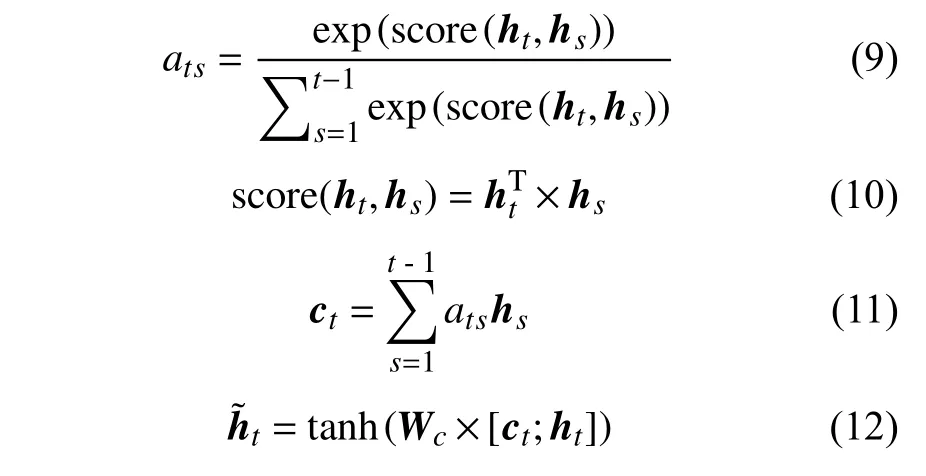
式中:ats——神经元历史时刻隐藏状态输出对当前时刻隐藏状态输出的注意力权重;
score——评分函数;
hs——神经元历史隐藏状态;
ht——神经元当前隐藏状态;
ct——中间变量;
——经注意力加权计算后的神经元当前时刻最终隐藏状态输出。
2 数据准备
本文数据来自某2×300 MW电站超临界锅炉分散控制系统(Distributed Control System,DCS),采样周期10 s,从中筛选了一段负荷变化范围大(84~300 MW)的连续运行数据,共10 069条数据样本。
2.1 变量选择
基于数据驱动的模型对数据精度十分敏感,建模之前首先对数据中的离群点和噪声进行预处理,消除其对模型精度的不利影响。对于离群点,使用箱线图法(Box-whisker Plot)进行筛选,然后使用均值填充进行修正;对于噪声,使用小波半软阈算法(Wavelet Semi-soft Threshold Denoising, WSTD)进行处理,半软阈值介于软阈和硬阈之间,可以均衡硬阈值去噪带来的信号局部抖动以及软阈值去噪峰值信噪比低的问题。
锅炉燃烧过程中影响NOx生成的变量有很多,通过对NOx生成机理分析并充分结合电站运行人员的实际经验,共筛选了包含总风量、炉膛氧含量、燃烧器摆角、给煤机给煤量等26个特征变量的历史数据作为模型的输入,详见表1。
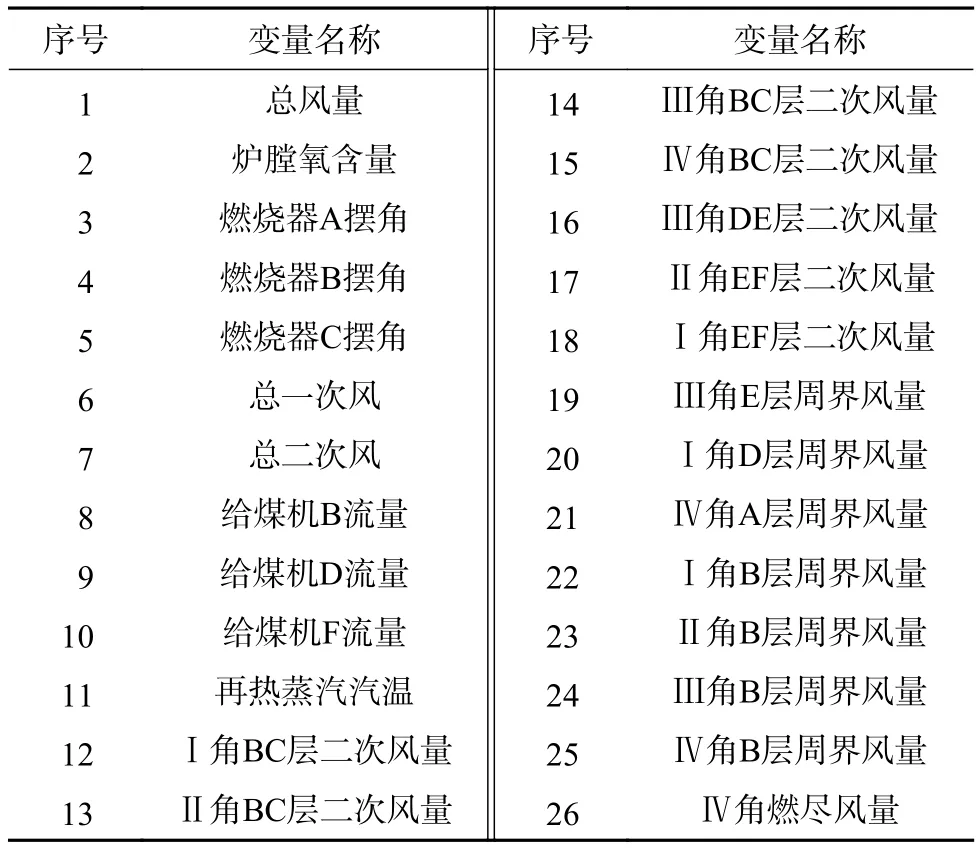
表1 模型输入变量
2.2 变量延迟时间估计
电站锅炉具有大延迟、大惯性的特点,且各个输入特征变量的测量和NOx测量值之间存在不同的时间延迟,导致DCS 记录的同一时刻运行数据中的各相关参数之间未形成准确对应关系,DCS原始数据并不能反应变量之间真实的时序关系。因此建模之前还需要校准输入变量与输出NOx之间的时间延迟,重构数据序列,实现建模数据在时间维度对齐。
互信息(Mutual Information, MI)是一种对信息的量化表达,能够反应变量之间的相关程度。定义两个离散随机变量X与Y之间的互信息为:
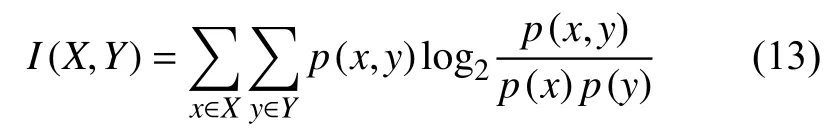
式中:p(x,y)——X与Y的联合概率分布,
p(x),p(y)——X与Y的边缘概率分布。
为了计算各输入变量与输出NOx之间的互信息值,设输入变量数据序列矩阵为X:
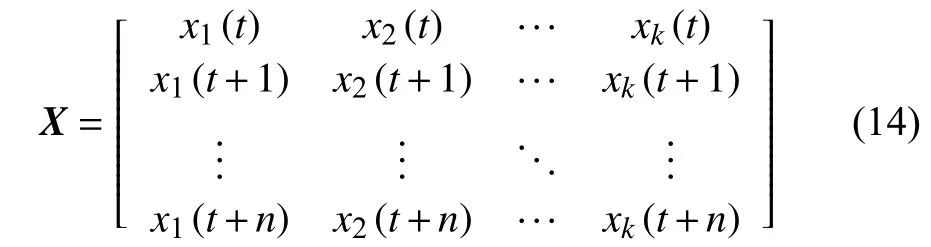
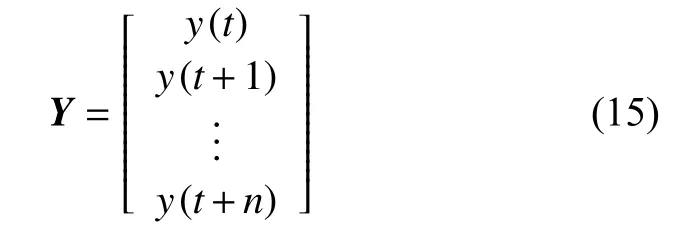
式中:n——时间序列长度或时间步长(1个时间步长度为采样周期10 s);
k——输入变量个数。
τi(τi∈[τmin,τmax])为第i个输入变量Xi(i∈(1,k))与Y之间的时间迟延,X可以重构为:
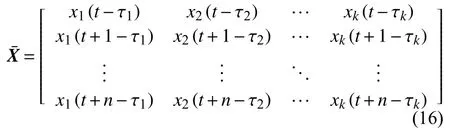
其中,第i个变量Xi重构为:
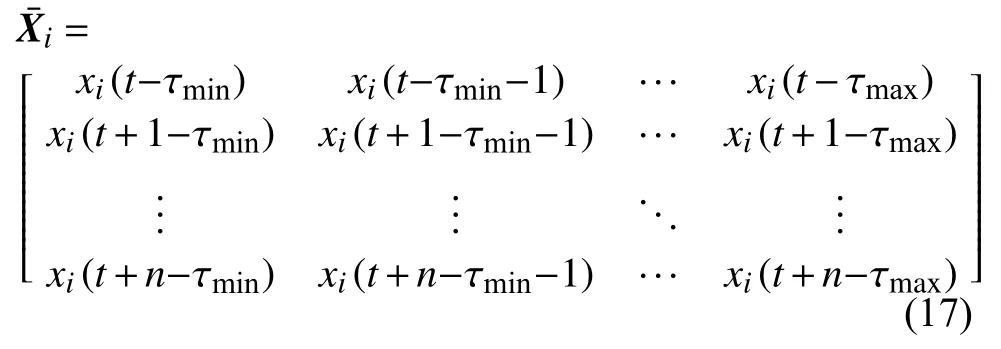
根据现场实际运行情况,变量延迟时间范围一般在 0~300 s之间,采样周期为 10 s,因此选择τmin=0,τmax=30。为了求每个输入变量Xi的最佳延迟时间,计算过程为:
1)分别计算式(17)中等号右侧矩阵每一列与式(15)输出Y之间的互信息值,其中互信息值最大的那一列对应的τ就是该变量的延迟时间估计。
2)重复步骤1)得到所有变量的延迟时间。
输入变量的延迟时间计算如表2所示。
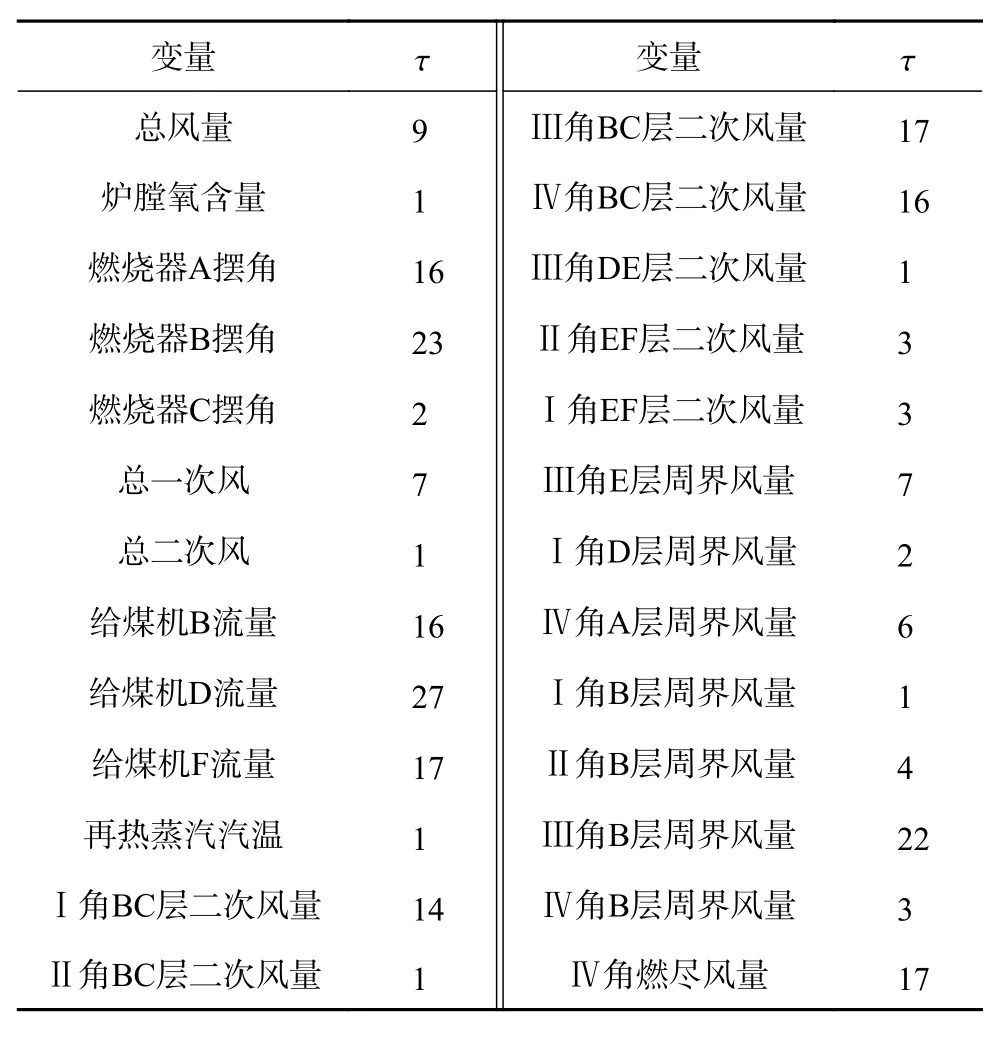
表2 输入变量延迟时间估计
在得到各输入变量的时间延迟后,对原始数据序列进行重构,实现输入变量与输出NOx之间在时间维度的对齐。
为了进一步提高模型预测的准确性,考虑到数据序列的时间依赖特性,在所选26个变量历史时刻数据的基础上,又加入了锅炉出口NOx排放量历史时刻数据共27个变量的历史时刻数据形成模型最终输入,输出为未来1个时间步的锅炉出口NOx排放量,即输入输出之间相差1个时间步。
3 模型构建
3.1 模型结构
CNN-BiLSTM-GAM混合模型结构图如图4所示。其中CNN有一个一维卷积层和一个最大池化层,对序列数据每个时间步输入都进行一次卷积池化运算,经全连接层后将结果输入到后两个含Dropout的BiLSTM层,之后由GAM层计算第二个BiLSTM层神经元隐藏状态输出权重分配,经全连接得到最终输出结果。
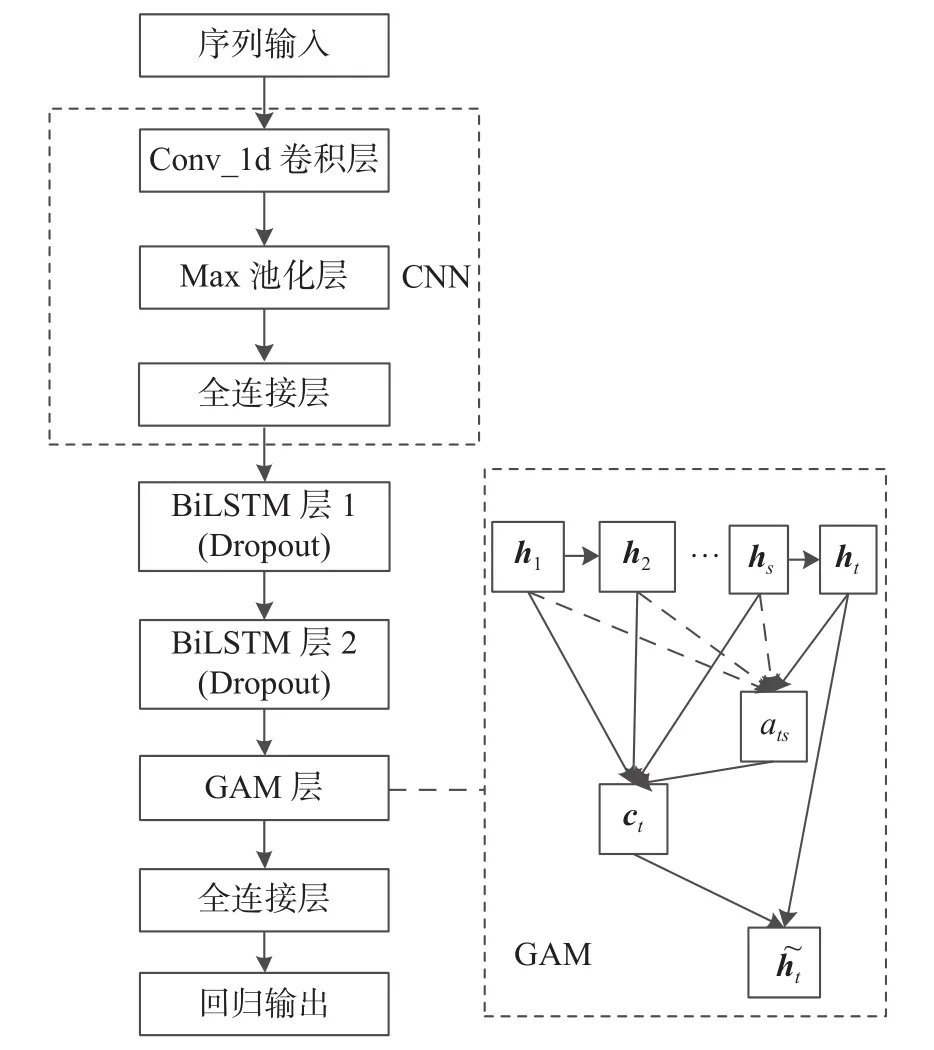
图4 CNN-BiLSTM-GAM结构图
3.2 模型超参数设置
本文实验环境为Matlab R2020b,经过反复多次实验,模型最优超参数设置如表3所示。
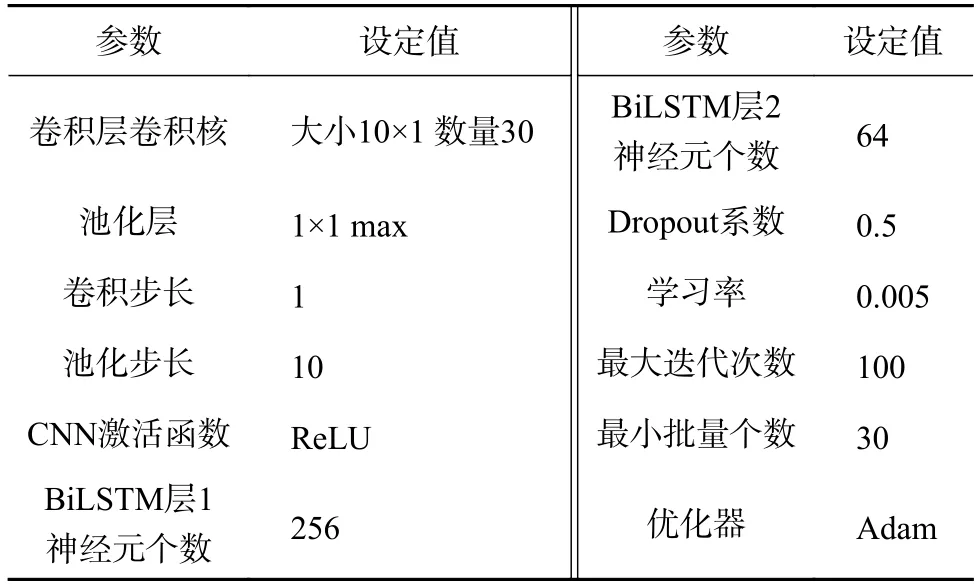
表3 超参数设置
3.3 模型输入输出
该混合模型串联过程中,上一层的输出是下一层的输入。CNN卷积层先接受某一个时刻数据样本序列的输入(一个维度为特征变量个数的列向量),然后进入模型的下一层进行运算直到最终输出,之后CNN卷积层再次接受下一时刻的输入,以此类推。各层输入输出数据格式如表4所示。
4 实验与对比
对2.2中最后得到的数据序列取其前10 000条作为最终实验数据并进行数据集划分,将这10 000条数据中前9 000组作为模型训练数据,后1 000组为测试数据,用以验证模型的性能。
4.1 数据标准化
将实验数据进行标准化处理,将其转化为无量纲的表达式,提升模型的收敛速度。这里使用ZScore方法对数据进行标准化。
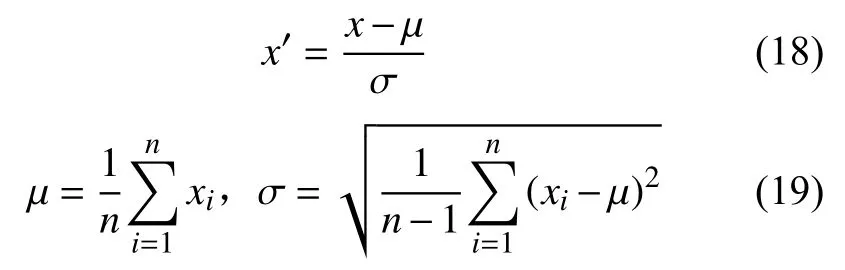
式中:µ——数据样本均值;
σ——标准差;
x——原数据;
x′——标准化数据。
4.2 评价指标
本次实验选择均方根误差(Root Mean Square Error,RMSE)、平均绝对百分比误差 (Mean Absolute Percentage Error,MAPE)、决定系数(R-square,r2)作为检验模型准确性的评价指标。其中,RMSE和MAPE值越接近0说明模型越精确,r2越接近1(r2∈(0,1))说明输入变量对输出变量的解释程度越高,变化曲线拟合优度越好。
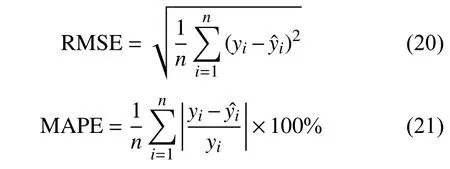
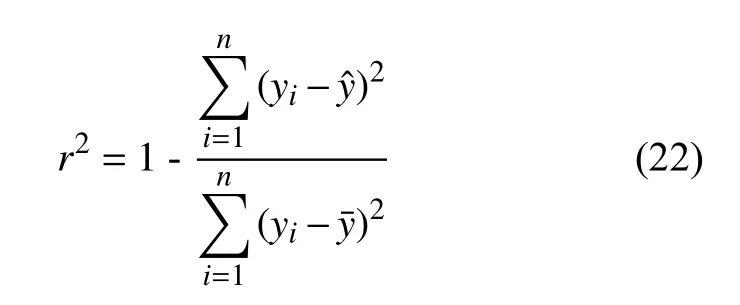
式中:yi——NOx实测值;
——模型预测值;
——NOx实测平均值;
n——样本总数。
4.3 实验结果与分析
4.3.1 变量延迟时间估计对模型精度的影响
为了说明2.2中变量延迟时间估计的有效性,分别选取未进行时延估计的数据与校正时延后的数据作为所提出的混合深度神经网络模型CNNBiLSTM-GAM的建模数据,同时使用3.2中设置的超参数对模型进行训练,并预测锅炉NOx输出,最后计算预测结果的性能指标。性能指标计算结果对比如表5所示。
由表5可以看出,模型使用含有时延估计的数据,其预测结果的三个性能指标均比使用不含时延估计数据所得结果要好,充分说明了对变量的延迟时间估计提高了建模数据的精度,从而提高模型的预测精度。
4.3.2 模型预测结果的对比验证
利用3.2中设置的超参数对所提出混合网络模型CNN-BiLSTM-GAM进行训练,并预测锅炉NOx输出。
为更好说明所提出模型的预测效果,使用相同的实验数据与实验条件,选取另外三个预测模型即BiLSTM、BiLSTM-GAM、CNN-BiLSTM进行对比实验,为了使各个模型的总体结构复杂度尽可能接近,所选三个对比模型中的BiLSTM层均采用三层设计,各层神经元数量分别为128、116、96;且CNNBiLSTM中的CNN层与所提出混合模型CNNBiLSTM-GAM中CNN层结构相同。学习率等其他超参数设置也均相同。
四个模型的预测结果评价指标对比如表6所示,时间耗费情况对比见表7。
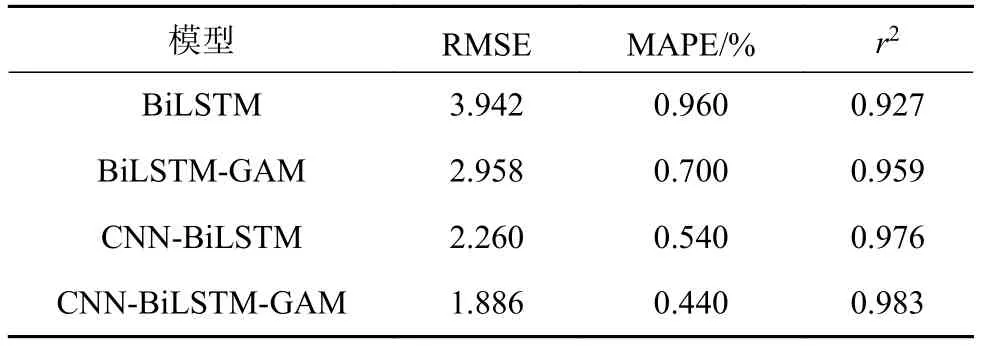
表6 模型评价指标对比
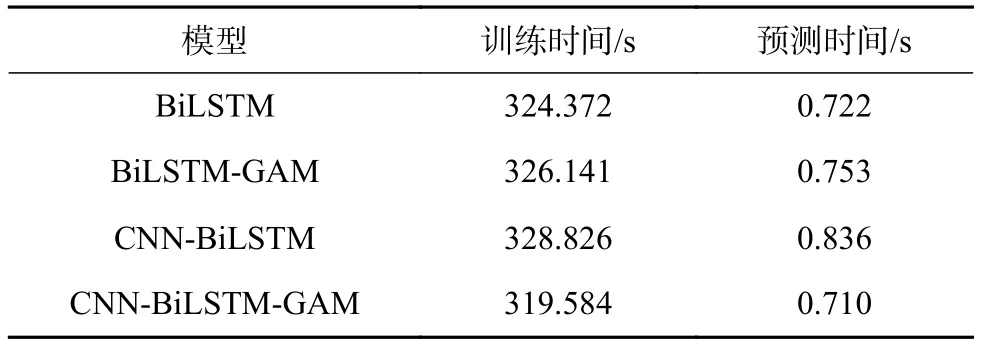
表7 模型时间耗费情况对比
由表6可以看出,CNN-BiLSTM-GAM模型的RMSE和MAPE值最小,说明该模型的预测精度最高,且该模型的r2系数最大,说明该模型的数据跟踪能力最好;BiLSTM-GAM模型的指标计算结果比不含GAM的BiLSTM要好,说明GAM的使用可以在一定程度上提高模型的预测精度;CNNBiLSTM要比BiLSTM的计算结果好,说明CNN的使用可以深入提取对象的特征,提高特征学习效果,从而提高预测精度;所提出模型的预测效果最好,说明三种不同算法的结合使用实现了三种算法之间的优势互补,提高了模型性能。
考虑到模型耗时与其内部因素(模型本身结构复杂度)以及外部因素(数据量大小、计算机硬件环境等)有关,对于外部因素,表7中模型时间耗费数据都是在Intel Core i5-2400 CPU(主频3.1 GHz),内存4 GB,集成显存2 GB的硬件环境下取得的,其他实验条件也都相同。由表7可以看出,无论是训练时间还是预测时间,四个模型之间相差并不大,且CNN-BiLSTM-GAM耗时最少。CNN-BiLSTM-GAM之所以比CNN-BiLSTM耗时少,是因为GAM计算开销很小,不会过多增加额外计算量,而CNNBiLSTM比CNN-BiLSTM-GAM多一个BiLSTM层,其网络权重参数数量要比CNN-BiLSTMGAM多,导致训练过程网络学习速度低,耗时增加;CNN-BiLSTM-GAM相比于 BiLSTM、BiLSTMGAM耗时少,除了因为GAM计算开销小的缘故,还因为CNN-BiLSTM-GAM串联了一个CNN层代替了一个BiLSTM层,CNN权重参数数量比BiLSTM少,计算效率高,且CNN通过卷积核池化操作可以充分提取对象的特征,加快特征学习速度,从而减少模型所耗费的时间。另外,所有模型的训练时间都要比其预测时间大得多,是因为训练过程要不断学习特征以更新网络各个权重参数,因此比较耗时,模型一旦训练好其网络权重也就固定下来了,进行预测时只需与输入进行常规代数运算即可,因此耗时很少。
CNN-BiLSTM-GAM预测结果如图5所示,四个模型的预测结果对比见图6。
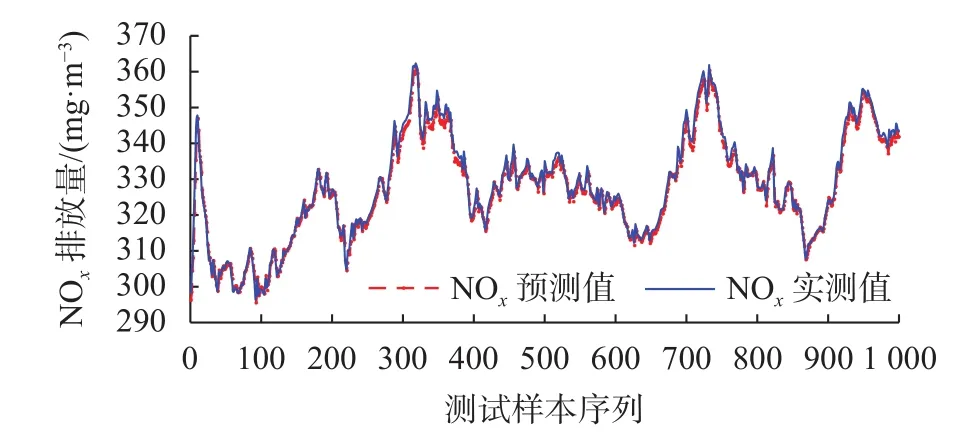
图5 CNN-BiLSTM-GAM模型预测结果
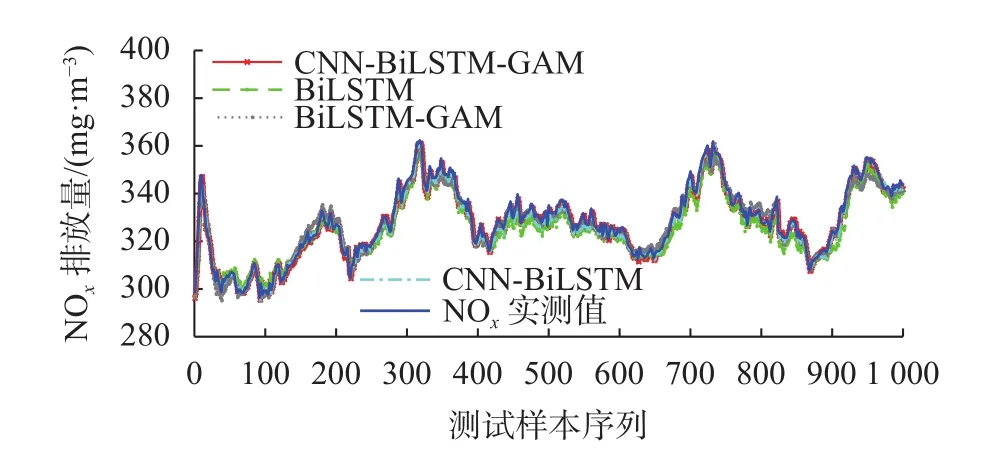
图6 四种模型预测结果对比
由图 5可以看出,CNN-BiLSTM-GAM模型NOx预测值与实测值之间差距极小,曲线几乎完全重合;由图6可以看出,四个模型的NOx预测值都可以很好地跟踪实测值变化,且CNN-BiLSTMGAM模型最贴近实测数据。
为了进一步分析对比模型的泛化能力,分别将四个模型的预测结果进行线性拟合,见图7。
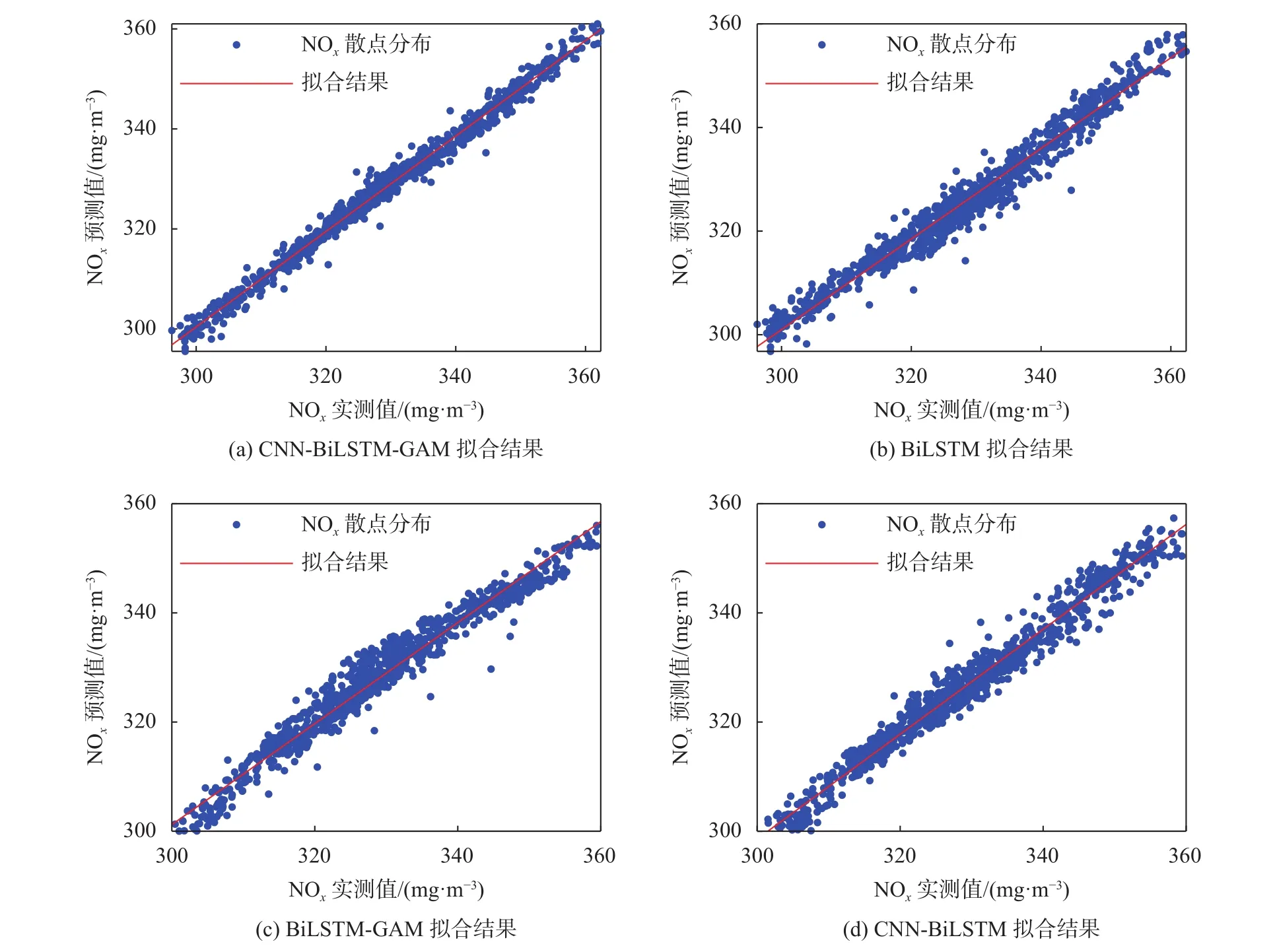
图7 四种模型线性拟合结果对比
如图7所示,四个模型预测值和实际值散点基本都均匀分布在拟合直线附近,拟合直线均比较接近理想直线(直线方程:x-y=0),且CNN-BiLSTMGAM模型拟合直线最接近理想直线,拟合效果最好。
5 结束语
本文提出一种基于数据驱动的融合CNN与BiLSTM并引入全局注意力机制GAM的混合学习模型来预测未来时刻电站锅炉NOx排放量,所提出的模型能充分提取数据序列的空间和时序特征,自适应分配网络隐含层状态输出权重,收敛速度快,且不容易发生过拟合。实验验证该模型与其他典型预测模型相比,RMSE仅有1.886,而r2系数达到0.983,模型预测精度高,误差小,泛化能力好。在今后的研究中计划寻找一种优化算法对模型的超参数进行自动寻优而不是通过经验手动调节,以提高工作效率,进一步提高模型的性能。
