数字词典学视阈下“有意学习”与“附带学习”新探*
2022-11-19SvenTarp耿云冬
Sven Tarp 撰 陈 汝 耿云冬 译
一、 引 言
本次讲座的主题聚焦“有意学习”(intentional learning)和“附带学习”(incidental learning),有关这对概念的讨论已长达至少十年之久。今天,我将尝试从一个新的技术角度来探讨这个问题,其灵感来自于爱因斯坦谈论伽利略时所说的一段话,[1]其中提到,应该“从新的角度审视一些固有的问题”(to regard old problems from a new angle)。此次讲座内容与之前我在中国的另一场会议[2]上所讲的内容相似。但此次我有更加充足的准备时间,因此,思考也更加深入。
二、 概念辨析:“有意学习”与“附带学习”
二语习得既可以是“有意学习”,也可以是“附带学习”。现有学术文献对这两大概念的定义非常多。例如,在肖恩·洛文(Shawn Loewen)和佐藤正俊(Masatoshi Sato)编著的《劳特利奇课堂二语习得手册》(The Routledge Handbook of Instructed Second Language Acquisition,2017)中,就可以找到很多相关定义,该手册在部分专栏还列出了一些重要概念的简短释义:“附带学习”指学习者不带有特定学习意图的学习,而“有意学习”的概念则相反,它与意图(intent)或意向(intention)相关联。事实上,区分这两个概念并非易事,在“有意学习”和“附带学习”之间还存在一个“灰色地带”(grey zone),而形成这一“灰色地带”的因素有很多。以我个人的教学体会为例:我在西班牙语课堂上给学生做了口语测试,有部分学生表现非常好,另外一部分却存在一些问题。近一年半以来,我们一直是线上教学,我建议学生们利用休息时间多读一些用西班牙语写作的书籍,选择感兴趣的主题,以循序渐进的方式习得语言。学生主动阅读的过程其实就是在开展“有意学习”,因为他们能够清楚地意识到自己是在自主学习。就我自己而言,我已经用西班牙语教了三十多年的书。虽然我和学生同样都是阅读西班牙语作品,但于我而言,西班牙语的学习主要是“附带学习”。即便如此,我也能够意识到我有时也在主动学习,并非完全是“附带学习”。由此,我深感要厘清这两个概念之间的差异并不容易。在二语习得环境下,我们会发现“有意学习”和“附带学习”都可与阅读活动相关联。然而,我认为,“附带学习”与文本产出(尤其是写作)的联系也非常紧密,而且通常情况下,基于书面语文本所发生的交流情境大致如下:作者和读者不处在同一时间域,当作家在写作时遇到问题,他们会查阅词典;而读者在阅读时遇到问题,他们同样是查阅词典。在这种情况下,词典似乎成为了他们交流的中介,如果阅读者只是完成“附带学习”,那么他就要尽可能缩短查阅过程,也就是说花最少的时间查阅不熟悉的单词。在本次讲座中,立足于书面语文本(包括文本阅读和文本写作),我将重点从词典学视角来探讨“有意学习”和“附带学习”之间存在的“灰色地带”。
在词典学视阈下,我把“附带学习”界定为“学习者在持续阅读或写作过程中通过查阅词典来获得所需要的信息,整个学习过程完全不受到干扰,通过查阅词典,学习者习得新词(包括词语、义项、语法结构等)”。相反,当学习者暂停阅读或写作,决定对其中一些问题进行深入探究,“有意学习”就开始了:以词典使用为例,学习者可能出于兴趣或其他原因中断阅读或写作,转而去翻阅一本词典,获得一些关于词语的信息(如语法、义项或句法结构等),那么,这就意味着他已经开始有意学习了。假设阅读者查阅的是传统意义上的词典,情况会怎样呢?需要特别指出,我这里所提及的传统意义上的词典囊括了纸质词典、词典应用程序、在线词典等。无论哪一种,阅读者都得放下正在阅读的文本,在外部的词典资源中查阅信息。在可能获取的信息中,大部分与当前具体语境没有关联,而查阅这些信息,不仅花费大量时间,还会影响阅读进程。因此,需要将词典研发与数字化技术相结合。在进一步探讨这一话题前,有必要先简短回顾一下词典学发展的历程。
三、 词典发展简史:从词汇对照表迈向智能词典
我想从追溯词典在欧洲的演变史来展开论述。早在公元前8世纪末,古希腊最重要的两部史诗《伊利亚特》和《奥德赛》诞生。当时的作品全部是手写,300年后人们开始誊抄这些作品,在这个过程中,抄写员创造了一些新词,并且使用其他词汇对新词进行阐释,只不过这些词在今天已经很少或不再使用了。据我的理解,这个阐释的过程类似中国古代的训诂学。再往后200年,学者们把这些词语汇编入词典,这便是欧洲词典的起源,但这并不是人类编纂词典的开端,因为我们知道早在4000年以前,词典就以某种形式存在了。彼时,人们制作词汇对照表,并在形式上做了两个重要创新:一是增设条目或中心词,通过丰富词汇信息(包括词头、音标、词性、释义、例证等),逐步构建词典的微观结构;二是收集单词,并单独设立条目,我们称之为词典的宏观结构。这些创新无疑是一种进步。早期制作词汇表,首先需要确立词语的标准形式。文本中出现的词语有可能是基于标准形式的语法变体,这就需要编者能够加以辨别,以标准形式作为词语条目,这是词典发展的一个重要体现。正如我们所见,按照欧洲的传统,词典条目是完全按字母顺序来编排的。但不得不说,正因为有了词典,我们可以在任何情况下进行查阅,这的确是件好事。但我们也要充分认识到,查阅过程其实是一个复杂的认知过程。从词典使用者的角度看,他们需要明辨词语的标准形式,且具备按照字母排序来查询词典的能力。在微观结构方面,尤其是印刷技术得以发明之后,词语信息越来越丰富,这也就意味着编者需要思考如何在有限的印刷空间内更好地呈现词语的信息。由于印刷媒介的篇幅限制,词典中出现了许多缩写形式。总之,学习者查阅的过程是比较复杂的,需要一些训练和具备一定的查阅能力。事实上,关于英语学习者词典使用的争议长期存在,山田茂(Shigeru Yamada)曾说:“词典查检不成功的因素有两个:要么是词典的原因,要么是用户自身的原因。”(转引自Rundell 2015)26-27《麦克米伦高阶英语词典》主编迈克尔·伦德尔(Rundell 2015)则认为问题应归于词典,因为词典本该科学设计,直观呈现信息。换言之,如果在学习者查阅能力和词典直观呈现之间选择一个影响因素,伦德尔倾向于把问题归结于后者。当然,如果是词典质量低劣或词典印刷问题,则应另当别论。基于数字技术的不断发展,可以开发出信息呈现更为直观的词典,这样学习者可以轻松查阅,并实现“附带学习”,这是本文讨论的另一重要议题。
值得一提的是,编纂词典是一种技能。“词典学”这个词源自希腊语,意为“关于词与描述”。进入数据时代,语言数据不仅用于编纂词典,还可以整合嵌入各类电子工具、写作助手等。与传统词典编纂关注词典文本本身有所不同,大数据时代的词典编纂应更加重视如何提高快捷有效地满足用户需求,这应当成为数字词典研究的重点。今天,电子阅读器、学习类应用程序、写作助手和其他学习工具基本都包含词典。但由于编纂理念过于保守和传统,我个人认为这种整合目前并不是很成功。下面以我的一次电子阅读经历为例。2021年11月,我读了一则故事,阅读过程并不顺畅,其间,我碰到mark一词,并对其在上下文中的含义不甚理解。于是,我试图借助电子阅读器中的嵌入式词典(integrated dictionary)来解决我的疑惑。我选中该单词并点击,页面便出现了与mark相关的语言知识。浏览之后,发现所展示的信息并不能解决我的问题,我想查阅的是mark做动词时的语义知识,嵌入式词典却给了我它作为名词的语义(详见图1)。继续点击more,弹出一个很长的信息界面,我不断滑动鼠标,尝试查看全部内容。显而易见,在大量信息中找到切合当下阅读语境的词义需要耗费一些时间,我想找mark作为动词的信息,却“被动”浏览了嵌入式词典给出的6个义项,甚至还有一些额外的数据或信息。实际上,如果我只是想了解mark在某一具体语境中的词义,上面这种情况就可算是信息或数据过载(information or data overload)了,因为有许多信息是无关紧要的,“附带学习”也就很难实现。查阅单词的过程扰乱了我的专注力,一度中断了阅读进程。
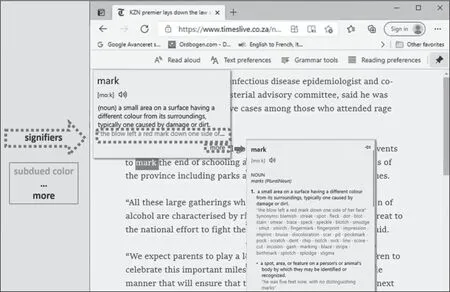
图1 电子阅读器嵌入式词典查阅过程展示
如上所示,在查阅了很多不相关的数据之后,我才找到真正所需的信息,其间花费了大量的时间。我的注意力从正在阅读的文本转移到了词汇查阅上,阅读中断,这使得我之前所定义的“附带学习”变得无法实现。某种程度而言,它只解决了我的部分问题——标记词类:我点击mark的名词用法,发现在这些被标记的词中,有些既不是名词,也不是代词或动词。这表明,该标记工具还需完善。标记可以解决部分问题,但并不完全可靠。那么,怎样才算是理想的解决方案呢?答案应该是有这样一个程序,它能够检测出文本中单词的具体语义。遗憾的是,目前还没有研发出这样的程序,但我们正通过人工智能与词典学相结合的方式寻找解决的方案。据我所知,已有欧洲的词典公司在朝着这一方向努力,只是该项技术十分昂贵,它基于机器学习、语料库、词典数据库等,显示英语单词在特定语境下的意义,识别率高达90%。当然,该技术的应用不仅取决于信息工程师,还取决于词典编纂者。只有词典编纂者提供高质量的数据库,这项技术才能快速发展。例如,目前如谷歌公司拥有巨大数据处理能力,为实现这一目标,其16个处理器能够连续长时间同时工作,时间可以长达数周。而与我合作开展研究的一家词典公司目前还负担不起这一技术。众所周知,新技术在诞生初期总是很昂贵、难以负担,但若干年后,技术会普及,我们就可以拿来使用,这意味着我们作为词典编纂者必须未雨绸缪,要为未来的发展趋势做好准备。假设我们已经拥有这项技术,那么,在查询中就会快速获取所需的词义,即mark作为“通过某一具体行动来庆祝或纪念”解的义项,这一查询结果对“附带学习”来说就足够了。如果我想从“附带学习”转为“有意学习”,就可以点击more获得更多信息。如果将来能够根据概率(probability)统计来对不同义项进行排列就更加有趣了。虽然目前没有这项技术,但至少在未来有实现这一技术的可能。
我们学习语言还面临另外一个挑战——如何处理“多词语义单位”(multi-word units of meaning)。例如,随着语料库相关研究的不断深入,与辛克莱(Sinclair)合作的词典学家愈发地意识到,很多单词在与其他词的搭配组合时会产生新的语义,它们被称作“扩展的语义单位”(extended units of meaning)或“多词语义单位”。对词典学家而言,这一语言现象非常有趣。辛克莱建议将这些词作为“中心词”(headwords)使用,这在大多数词典中仍然存在。以单词part为例。假设你想知道文本中part的词义,鼠标选中并点击part,嵌入式词典会“打包”显示take part这个词组,同时弹出对等释义词participate。这种学习模式很有趣。你以为你的问题是要知道part的词义,实际上,你的问题是take part的词组意义。但是最开始查询时并没有意识到这一点,你点击了part,得到的答案已然是take part。目前,这一技术已经存在,但需要推广。(详见图2)
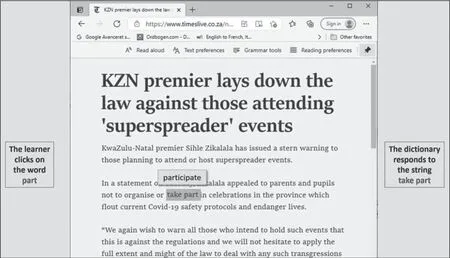
图2 电子阅读器嵌入式词典多词语义单位查阅展示(1)
再举一例。我曾与广东外语外贸大学的黄芳老师合作开展过一项研究(Huang,Tarp 2021),涉及一款中国学习者常用的英语学习软件“开言英语”(Kaiyan Open Language)。以set的查询为例,点击set,该学习软件会弹出很长的词条信息,屏幕上显示出该词有两种不同的词性,分别是动词和名词。继续点击屏幕上的“查看完整释义”,会出现set作为形容词的用法,可见set是一个复杂的英语单词。然而,读者希望看到的只是set在此语境下的释义,满屏的词条信息不仅会影响读者的阅读体验,还妨碍阅读者的“附带学习”。(如图3所示)
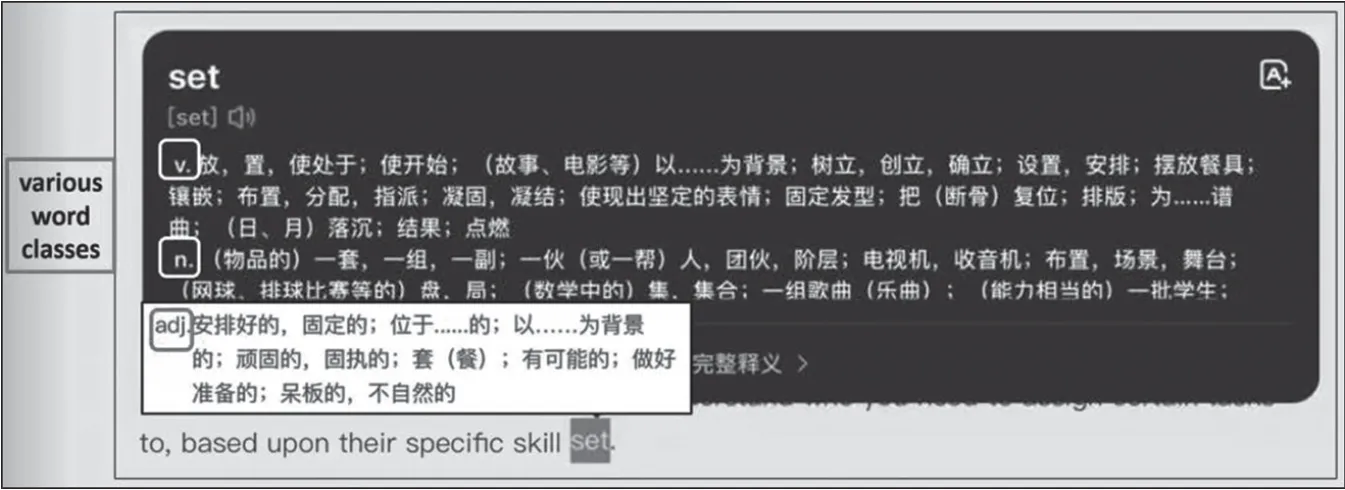
图3 电子阅读器嵌入式词典多词语义单位查阅展示(2)
事实上,在set词条的释义内容中,它作为名词的含义“(物品的)一套,一组”,才是我需要的情境语义,其他信息均不相关。如何不显示冗余的、不相关联的信息是未来的研究方向。遇到以上情况,我认为理想的词典应该是这样的:点击set,只出现“(物品的)一套,一组”这个释义,自动屏蔽不相关联的信息(如图4所示)。大家可以看到,在释义内容左侧还有一个“小喇叭”的图标,如果读者需要获取该词的读音,点击图标即可;在释义内容右侧有一个“向右箭头”(>)的图标,点击查询更多词条信息,这样“附带学习”就转化成了“有意学习”。

图4 电子阅读器嵌入式词典多词语义单位的新设计理念
就这个例子而言,“附带学习”的内容包括set的发音和情境释义,但不包括词语条目、词性、语法变体、非情景释义等其他信息。这种释义模式其实是受到汉语训诂学的释义方法、荷马史诗抄写员所采取的释义方法的启发,它们之间有相似之处。在阅读过程中,读者碰到生僻词语,只希望在最短时间内得到解释。
一旦读者想要获得除释义之外的其他信息(比如词头、词性等),就意味着“附带学习”开始向“有意学习”发生转变。那么,问题在于如何才能让计算机在最短时间内给读者提供当下所需的释义?首要的方法是数据过滤,主要分两步:第一步,用户界面加载从数据库中提取出来的词典数据;第二步,以定量计量的方式呈现数据,以满足读者“附带学习”和“有意学习”过程中的特定需求。这里还涉及另一个重要的概念,即“人工辅助智能”(human-assisted intelligence,以下简称“人助智能”),这个概念既有趣又重要。众所周知,利用人工智能(artificial intelligence)可以做很多事情,例如,它能够判断文本模式,这是人类仅靠双眼观察无法做到的。如果是要给出单词在具体语境下的特定含义,人工智能就行不通了,但人类可以做到。此时,为了解决这一问题,可以引入“人助智能”,具体做法如下:语言专家点击电子文本中想要查询的词汇单位,可以是单词,也可以是词组,然后弹出一个释义框,紧接着,专家就能够在其中标记出正确的、符合语境的释义,这整个操作流程被一个特定编写的程序自动记录下来。第二次有读者需要查询这个单词或词组时,用户界面弹出的释义框就只会显示专家标记之后的内容,帮助读者在具体语境中快速准确地理解词汇单位。整个操作过程只需要用手指触碰屏幕即可,所需信息会自动呈现。通过这种方式,词典释义和语境的关系更加紧密,用户界面出现的信息必须有助于上下文的理解,这也是普通电子词典迈向智能词典的第一步。这一方法十分高效,我们希望在未来,一个训练有素的“专家”每分钟可以标记2—3个词汇单位。此外,这一特定程序的编写很容易实现。从长期维护来看,还需要添加用户反馈,这样才能不断提升学习类应用软件的质量。
上述例子是我们目前在阅读/学习类应用软件、互联网以及数字技术方面的一些思考,希望未来能够继续发展。
四、 数字词典新进展:写作助手(Writing assistants)
帕特里克·汉克斯(Patrick Hanks 2013)399曾言,“原则上,可能的(语言)组合(possible combinations)从数量上来说可以是无限的,可行的(语言)组合(probable combinations)却相对有限”。[3]迈克尔·伦德尔(Michael Rundell 2018)6也曾说过,“尽管语料库分析能让我们观察大多数语言产出的内在可预测性(inbuilt predictability),但学习者远不能够对此做出预测”。[4]母语者可能较容易掌握本族语的语言组合,但是这对于非母语学习者而言就非常困难。针对这一问题,我们来看看写作助手的相关情况。应用软件不同,技术和功能也会不同。有些写作助手能够在作者写出第一个词之后马上提示可能出现的下一个单词,甚至是整个句子。当作者不知道应该使用第二语言中的哪一个单词时,写作助手就会提供最有可能的对应词。这些技术的核心主要是依靠语境给出判断。通过此类应用,二语学习者在习得过程中也能实现“附带学习”和“有意学习”。
一般而言,写作助手是基于语言模型的,同时还会使用数据库和词典数据作为数据资源。无论是通过统计编程还是机器学习来处理自然语言,其结果都是基于语言模型。结合具体语境,语言模型为写作者提供建议。这一项技术已然存在,当然,它还有改进完善的空间。下面以丹麦一家词典公司研发的写作系统(WriteAssitant)为例(检索过程如图5所示):假设我现在是一名西班牙人,正在用英语写作,一时想不起某个英语单词,只好用自己的母语西班牙语单词cerrado来替代,输入之后马上出现了一组英语对等词,而且是按照它们在具体语境中出现的概率来排序。这里我不讨论概率是如何计算出来的,因为太过于复杂。在这一组对等词中,只要我认识其中一个,比如sealed,我就可以选择使用。如果我仍然不确定选择的单词是否正确,我可以点击sealed右侧的“向右箭头”(>)继续查询,出现了一些非常简短的定义,而其中一个定义看起来非常有趣,继续点击,就可以看到完整定义。在这个过程中,我从“附带学习”转为“有意学习”。这项技术虽已经研发出来,但也面临着后台的词典数据库不够好这一问题,这也说明相关技术仍然没有为迎接真正的数字辞书时代做好准备。
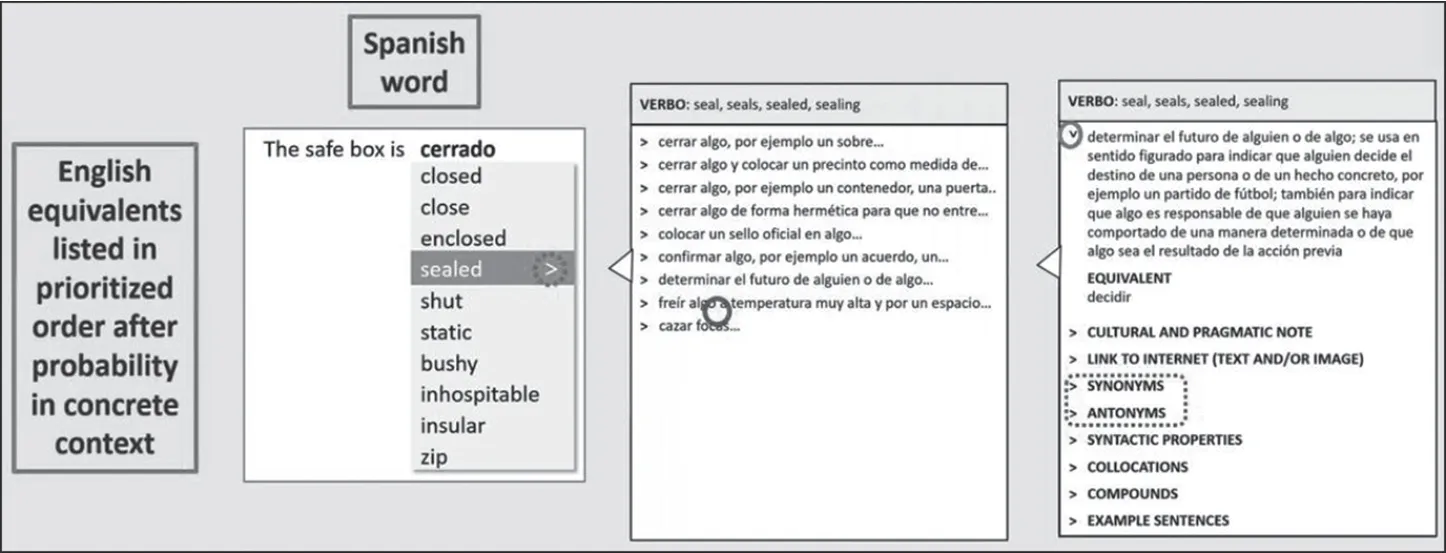
图5 WriteAssistant检索界面
再举一例,仍然是关于写作的问题。比如,因为缺少明确的辨析规则,而且词典中也没有明确的界定,学习者常常难以区分-ic和-ical为词缀结尾的形容词之间的差异。翻开《牛津派生形态学手册》(Oxford Handbook of Derivational Morphology),你会发现几乎有1.2万个英语词干可以同时添加这两个后缀。根据《朗文交际3000词》(Longman Communication 3000),英语中以这些后缀结尾的形容词占1%左右。大家可以参见我与广东外语外贸大学词典学研究中心马立东老师共同撰写的一篇文章(Ma,Tarp 2020)。我们发现,以-ic和-ical为词缀结尾的形容词对(adjective pairs)总会给二语学习者带来困扰,造成使用错误的情况。在有些情况下,两个变体含义不同,词频不同。另外,在某些固定搭配或术语表达中,其中一个变体更为常见,另外一个变体则使用频率低、甚至不被使用。以academic和academical为例。往前追溯200年,academical比academic更常见,但今天,人们几乎不再使用academical。
从图6可知,8年前有一门俄语课程《学术写作》,英语译成Academical Writing。2018年发表在《欧洲跨学科研究期刊》(European Journal of Multidisciplinary Studies)上的一篇文章,其标题里面也用了Academical Writing。这就意味着,即使是学术界人士,如果他们的母语不是英语,也可能会错误使用这些形容词对。这是一个非常棘手的难题。我们应思考:如何处理这一问题?写作助手又该如何应对这个问题?
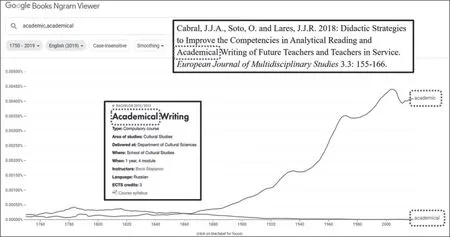
图6 academic与academical使用情况历时分析
事实上,有些以-ic和-ical为词缀结尾的形容词对,其含义并不相同。受一些词典设计的启发,我们提出三种可能的解决办法:一是增加用法比较说明,二是简要解释两个形容词的含义,三是增加固定搭配用法。如果是数据库,可以在两种形式后面附加单词使用说明,包括此类形容词对的使用特征。如果是弹出的查阅窗口,那么应该默认显示词汇辨析,如果辨析详细具体,需要多页显示,则应予以标记,方便用户查阅。整个查阅过程同样包含了从“附带学习”到“有意学习”的转变。
对于所有以-ic或-ical词缀结尾的形容词对,我们都需要设置“X或Y”文本段:其一是为了提示读者,两个形容词不是互换关系,只能二选一;其二是引起读者关注,这两个形容词存在差异。比如,我先写一段英文,在写作过程中弹出了economic和economical这两个单词,我对它们的用法有一定的困惑,举棋不定。为了进一步了解二者的区别,我点击单词弹出框,出现了两个简短的定义(详见图7):当然,如果想获得更多信息,可以继续点击查看。以上操作需要一个前提条件,那就是提前准备好单词辨析的相关内容,否则就无法通过写作助手来帮助作者选择正确的单词。

图7 economic和economical辨析程序设计示意图
还有另外一种情况:词义相同,单词使用频率却明显不同。针对这种情况,写作助手可以提供三种用法说明,分别是“不用X,用Y”“很少使用X,用Y”和“已经弃用X,用Y”。以上三种用法说明只在作者选择使用X的情况下出现,如果作者一开始就选择使用Y,那么就不会弹出提示窗口。也就是说,该窗口只会在用户输入不推荐的形式之后才会被激活。接下来,我们看看具体的操作(详见图8)。比如,我现在输入单词specifical,单词上方马上弹出信息,表明specifical已经过时了,可以用specific代替。如果我想了解更多关于specific的知识,点击该单词即可。
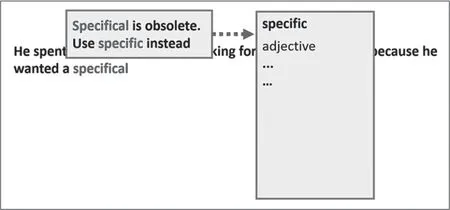
图8 specific和specifical用法辨析设计示意图
你可能并不知道specifical这个单词的存在,但有些词典,比如《柯林斯词典》同时收录了这两个单词,词条信息中却找不到类似“不用specifical,用specific”的提示信息。也有词典,比如《韦氏词典》,只收录了其中一个单词。综上所述,对于二语学习者来说,词汇辨析与选择的确是一个复杂的问题,上文提及的解决方法有三大优势:直接推荐用法;推荐的原因直截了当;标准化的信息标注方法也易被词典编纂者所掌握。
在“附带学习”场景下,写作助手推荐的用词必须稳妥、合乎语境且简单直接,避免冗余信息带来的干扰。然而,“有意学习”强调轻松便捷地获取附加信息,当然,在这个过程中用户也会受到不相关信息的干扰。目前,我们已经拥有人工智能、人工辅助智能、高级编程等技术,下一步是思考如何将它们充分应用到词典数据库构建和写作助手的软件开发中。
五、 对未来的展望
如果我们充分利用前沿科技,就能帮助用户自动检测扩展语义单位,就能通过概率计算确定词汇的语境意义,就能根据具体语境将所有对等词优化排序。除此之外,我们还能借鉴中国古代的训诂学思想,突破具体语境的限制,尽可能呈现出丰富的释义内容。新时代背景下,词典学领域面临着重大的技术突破,比如,“语境敏感型词典”(contextaware dictionary),伴随着它的出现,词典内部逐渐会形成一个语境适应选择系统。然而,正如我所指出的,“语境敏感型词典”的研发不仅需要信息工程师、程序员等提供先进的技术,还需要词典编纂者不断完善词典数据库设计和优化用户界面,方便目标用户快速获取所需数据。这意味着公司股东、词典编纂者、语言专家、教师、设计师、信息程序员等必须开展密切的跨学科合作。我认为,这是未来词典学发展的必然要求,因为大多数人都有查阅词典的需求,通常情况下,他们都希望能够通过词典简单快速地找到解决问题的答案,而词典设计与研发也应朝着这个目标不断努力。在数字词典使用场景下,词典的首要功能应是满足用户“附带学习”的需求。如果词典用户想获取更多信息,“附带学习”又可转变成“有意学习”。这正好呼应了达芬奇那句反复被引用的句子——“至繁归于至简”(Simplicity is the ultimate sophistication)。
附 注
[1]爱因斯坦的原话如下:“To raise new questions,new possibilities,to regard old problems from a new angle,requires creative imagination and marks real advance in science.”(转引自 Tarp 2009)30
[2]第七届学习词典与二语教学国际研讨会(福建泉州)。
[3]原文:“Although the number of possible combinations may in principle be limitless…the number of probable combinations…is rather limited.”(Hanks 2013:399)
[4]原文:“Although corpus analysis enables us to observe the inbuilt predictability of most language output,much of this is far from predictable to a learner or non-fluent user of a language.”(Rundell 2015)6
