基于ADASYN与改进残差网络的入侵流量检测识别
2022-11-19唐玺博张立民钟兆根
唐玺博, 张立民, 钟兆根
(1. 海军航空大学信息融合研究所, 山东 烟台 264001; 2. 海军航空大学航空基础学院, 山东 烟台 264001)
0 引 言
入侵检测是指在计算机及数据网络正常开放运行的同时,对其进行的一种安全监测和保障。入侵检测的目标是实时识别系统内部人员及外部入侵人员对计算机系统未经授权的使用[1]。迅速发展的互联网技术在给予人们便利生活的同时,也使得计算机系统面临着恶意攻击、网络病毒等安全威胁,这使得入侵检测技术日益成为保证网络信息安全的重要技术手段。目前,与防火墙等传统网络防御技术相比,网络入侵检测系统(network intrusion detection system, NIDS)能够更好地对网络异常流量进行检测识别,从而防止网络受到可能的入侵,以确保其机密性、完整性和可用性[2]。
随着互联网技术的巨大发展,网络节点与规模在全球范围内迅速扩张,网络需处理的数据信息量呈爆炸式增长,同时大量新出现的协议均使用动态端口分配技术,端口易被重定向,这使传统的流量监测技术如基于端口的流量检测方法[3]对于入侵流量的检测效果较差。为了有效满足入侵检测技术的需求,人们广泛尝试采用机器学习与深度学习技术对网络流量进行处理。其中,基于机器学习的入侵检测系统需依靠特征工程对网络流量进行特征的筛选与剔除,从而实现对入侵流量的特征学习以完成检测识别。文献[4]提出基于支持向量机的蚂蚁系统(ant system with support vector machine, ASVM)模型,采用蚁群算法对特征进行过滤选择,而后利用支持向量机(support vector machine, SVM)对缩减的特征集进行训练和测试,在规范化的KDD99数据集上对正常流量与入侵流量进行二分类的准确率达到84.28%。文献[5]提出一种自学习入侵检测系统对数据集进行特征学习和降维,提升了SVM对攻击的预测精度,在NSL-KDD数据集进行流量监测分类实验,其二分类准确率达到84.96%,五分类准确率达到80.48%。文献[6]提出一种自适应集成学习模型,通过构造多决策树以提升入侵检测性能,在NSL-KDD数据集的检测准确率达到85.2%。机器学习技术在网络流量监测上的应用广泛,但依赖于特征降维和筛选,对于原始形式的自然数据处理能力有限,需要利用其他方法先对数据集进行特征预处理,否则难以对入侵流量达到较好的识别效果。同时,上述机器学习技术提出的模型存在识别准确率较低、泛化性不强的问题。
深度学习通过对非线性模块的组合应用,能够学习高维数据中的复杂结构[7],因此具备处理原始数据集的能力,无需采用其他算法构建特征处理器。文献[8]提出多卷积层的双向长短时记忆与注意机制(bi-directional long short-term memory and attention mechanism with multiple convolutional layers, BAT-MC)模型,结合了双向长短时记忆(bi-directional long short term memory, BLSTM)和注意机制,采用卷积层对数据集进行处理,能够自动完成网络流量层次结构的学习,在NSL-KDD数据集上进行流量检测分类实验,其五分类准确率为84.25%。文献[9]提出一种基于长短时记忆(long short term memory, LSTM)与改进残差网络优化的异常流量检测方法,提高了LSTM层的特征适应性,在NSL-KDD与来自Fsecrurify开源网站应用防火墙(Web application fivewall, WAF)混合数据集上二分类和五分类的准确率分别为92.3%和89.3%。文献[10]提出一种带逻辑回归的稀疏自动编码器,通过堆叠自动编码器创建深度网络,在NSL-KDD数据集二分类准确率达到84.6%。文献[11]提出一种基于自动编码器和变分自动编码器及单类支持向量机(one-class support vector machine, OCSVM)的半监督深度学习入侵检测方法,对CICIDS2017数据集进行检测识别,结果显示变分自编码器(variational auto-encoder, VAE)的分类效果最佳,接受者操作特性曲线(receiver operating characteristic curve, ROC)下面积值(area under the curve of ROC, AUC)达到0.759 6。
上述模型相比于机器学习方法,在识别准确率上均有所提升,但仍具备提升空间。大部分研究对于数据都未进行合理的预处理,尤其对于不平衡数据集,直接采用归一化处理,这直接导致神经网络忽略对小样本的特征学习,进而导致小样本的识别率低下,特征选择出现偏差,泛化性不强。基于以上问题,本文采用了自适应合成(adaptive synthetic, ADASYN)采样方法在预处理阶段对NSL-KDD数据集中的小样本数据(如来自远程主机的未授权访问(unauthorized access from a remote machine to a local machine, R2L)、未授权的本地超级用户特权访问(unauthorized access to local superuser privileges by a local unprivileged user, U2R)类型)进行过采样,使经过上采样之后的攻击类型流量及正常流量在数据集中各自占比相差不大,将不平衡数据集采样成为平衡数据集,再输入到深度学习网络中使神经网络能够对5种流量类型都进行充分的学习,避免小样本的数据特征被淹没在数据集中。采用改进的残差网络作为训练模型,有效地解决了常用深度学习网络在训练过程中出现的过拟合以及梯度消失的问题,并且在二分类及多分类的情况下,均取得了较高的分类准确率,在精确率、召回率等指标上误报率低,具备较强的泛化性,有较高的工程应用价值。
1 入侵流量检测模型与处理
本节介绍卷积神经网络(convolutional neural networks, CNN)等网络。
1.1 CNN
CNN是由卷积层、池化层以及全连接层等通过交叉堆叠构成的一种前馈神经网络。CNN具有局部连接、权重共享的特性,与全连接的网络相比使用的参数更少,并在一定程度上具有平移、缩放和旋转不变性[12]。基本结构是包含卷积层、池化层、全连接层等。
卷积层的作用是依照卷积核的大小对图像进行相应的局部特征提取。卷积层的神经元是一维的,但是一维的卷积层难以对二维图像进行特征提取。为了提高图像区域信息的利用率,卷积层的神经元通常搭建为三维结构,其大小为高度M×宽度N×深度D,由D个M×N大小的特征映射构成。如果特征映射的图像为彩色图像,则输入层深度D=3;如果输入为灰度图像,则输入层深度D=1。本文将协议数据处理成二维矩阵后,即相当于灰度图像输入。卷积层的运算过程可表示为
(1)
式中:Wp为卷积核;X为输入特征映射;bp为标量偏置;f(·) 为非线性激活函数;Yp为输出特征映射。卷积层通过对输入特征进行卷积运算并引入非线性,从而实现局部特征的提取。
池化层能够有效减少网络中神经节点的数量,对局部连接产生的大量特征信息进行采样,对高维数据进行降维,方法包括进行最大池化和平均池化,通过对特征信息进行据合同及处理,可以降低算法运行耗时,保留重要特征信息,防止训练产生过拟合现象。全连接层一般处于交替堆叠的卷积层和池化层之后,一般有0~2层,作用是调整特征输出数量,神经元数等于分类数。
1.2 LSTM网络
循环神经网络(recurrent neural network, RNN)具备短期记忆能力,对于处理具有序列关系的信息十分有效。但是当输入序列比较长时,将出现梯度爆炸或梯度消失的问题,即长程依赖问题[13]。LSTM网络通过引入门控机制的方法来解决此问题,通过信息的有用程度进行权重确定,包括向神经元中引入新信息、遗忘、输出的权重,以此来控制信息的累积速度。LSTM网络引入了3种门,分别是输入门it、遗忘门ft、输出门ot。其中,ft表示上一个时刻的内部状态遗忘信息权重;it表示当前时刻候选状态保存信息权重;ot表示当前时刻输出给外部状态信息权重。3个门均以一定比例允许信息通过,其计算方式为
(2)

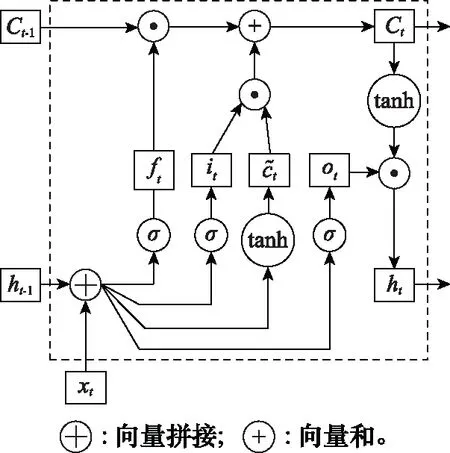
图1 LSTM网络的循环单元结构图
LSTM单元可以使网络建立一种长时序依赖关系,各计算状态为
(3)
(4)
ht=ot⊙tanh(ct)
(5)
式中:⊙表示向量元素相乘。
1.3 残差神经网络
在深度学习网络中,层数越多,对数据特征的提取就会越细致全面,但当深层次的网络收敛时再增加网络层数,神经网络将会出现退化现象:随着网络的深度不断增加,网络训练的精度先上升达到饱和,然后出现下降。这种现象不是由过拟合产生,而是因为多余的网络对非恒等映射的参数进行学习造成的。而残差神经网络通过在深层网络中增加跳跃连接,构成残差块,能够起到优化训练、解决退化问题的效果。残差块的结构如图2所示。

图2 残差块结构
将期望的底层映射设为H(x),将堆叠的非线性层拟合的映射表示为F(x)。此时映射关系为
H(x)=F(x)+x
(6)
式中:x为输入;F(x)为残差函数。由文献[14]可知,当H(x)为恒等映射时,信号可由一个单元直接传递到其他任何单元,此时模型的训练损失和测试误差达到最小。在恒等映射为算法参数最优的情况下,相比于用堆叠非线性层来拟合恒等映射,令残差函数F(x)为0来构造恒等映射更加容易,算法难度更低[15]。
残差网络采用恒等变换和跳跃连接的方式解决了深度学习网络的层数退化问题,跳跃连接保护了信息的完整性,网络只需学习输入与输出的差别部分,复杂度降低;恒等变换有效拓展了网络深度,能够避免因为深度增加导致的梯度消失和训练难度提升,随着层数增加,残差网络的性能不会下降,而是会有一定程度的提升[16],这提升了网络的性能与可迁移性。
1.4 不平衡数据集及处理方法
不平衡数据集指各个类别数据的样本数目相差巨大的数据集。以二分类问题为例,假设数据集为Q,S1和S2为数据子集,且S1∪S2=Q、S1∩S2=Ø,此时可通过不平衡比率IBR=S1/S2的取值来界定数据集的不平衡程度。IBR的取值越接近1,则不平衡程度越小;IBR的取值越接近0和∞,则不平衡程度越大[17]。
训练集数据不平衡是实际应用问题中的常见情况,例如在信用欺诈交易识别中,所收集的数据绝大部分是正常交易,只有极少数交易是不正常的。在二分类数据集中,若样本比例大于10∶1,则很难建立起有效的深度学习分类器,大部分算法将忽略少数数据集的特征数据,而大多数的不平衡数据集的少数样本才是数据集的关键样本,此时准确率这一评价指标将失效。
对于不平衡数据集的处理方法,可以采用扩充数据集、重采样、属性值随机采样等手段对数据集进行改善。在固定使用NSL-KDD数据集的情况下,难以在相同情况下进行数据集的扩充;重采样可以分为过采样与欠采样,过采样即对小类样本进行上采样,使采样个数大于样本个数,欠采样则是减少大类样本的个数,采样算法容易实现,但可能会增大模型偏差,并对于不同类别的数据需要采用不同的比例;属性值随机采样在样本的每个属性空间都随机取值组合成为一个新样本,能够有效增加小样本的数量,但引入随机性易打破样本原有的线性关系,并且需要增设限定条件以防产生现实中不存在的数据。
2 基于ADASYN与改进残差网络(residual network, ResNet)的入侵流量检测模型
2.1 数据集分析与采样
1999年举办的KDD杯数据挖掘工具竞赛以收集流量记录为目的,以建立一个可区分攻击流量和正常流量的网络入侵检测模型,大量互联网流量记录被KDD99数据集收录,该数据集包括了41个特征指标,共5类数据[18],而后经过新布伦瑞克大学进行修订和清理产生了NSL-KDD数据集[19]。相比于KDD99数据集,NSL-KDD数据集训练集中不含冗余记录,测试集中无重复数据[20],对于算法性能的检测更加准确,训练集和测试集的数据量设置合理,无需进行筛选和选择,更适合作为入侵流量检测模型的训练数据集。
NSL-KDD数据集由正常流量及4种攻击流量组成,攻击流量类型分别为:DoS、Probing、R2L、U2R。每种攻击类型下又细分有若干小类别的攻击流量,为了统计识别便利,采用数据集给出的5个大类进行分类识别。测试集的部分流量属于未在训练集中出现的小类别,将这一部分流量进行剔除。本文采用数据集的KDDTrain+作为训练集,KDDTest+作为测试集,各数据类型的分布如表1所示[21]。
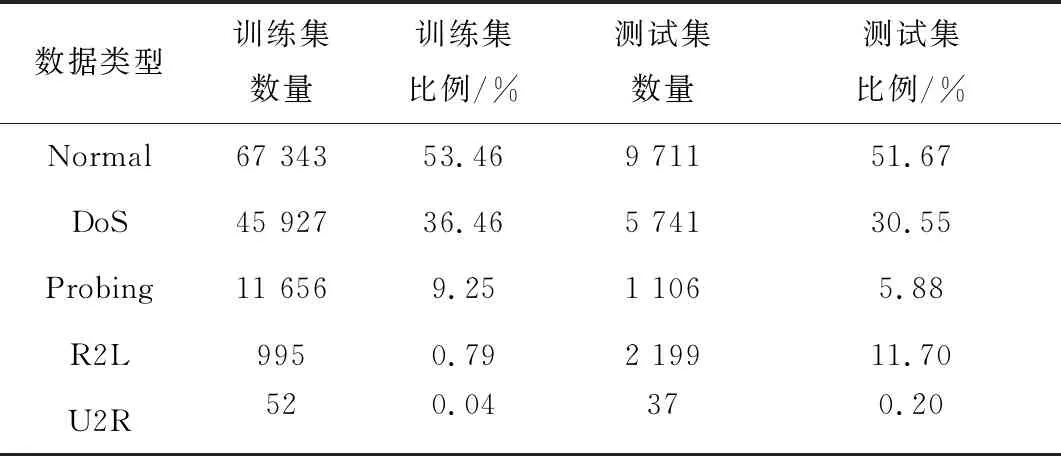
表1 各类型数据分布
由表1可知,训练集和测试集都存在明显的数据不平衡现象,最小的样本仅占比0.04%,样本比例高达1 336.5∶1,需要对数据集进行平衡化的处理。R2L数据的特点在于,测试集的数量大于训练集数量,这说明检测模型在训练集上将难以充分学习R2L的特征并在测试集中准确分类。基于以上问题,本文采用ADASYN方法进行升采样,对训练集中的小样本数据进行扩充。ADASYN算法步骤如下[22]。
步骤 1数据集小样本选择,对Normal、DoS、Probing、R2L、U2R进行样本编号,将小样本数据相加得到总数ms,大样本数据数量为ml。
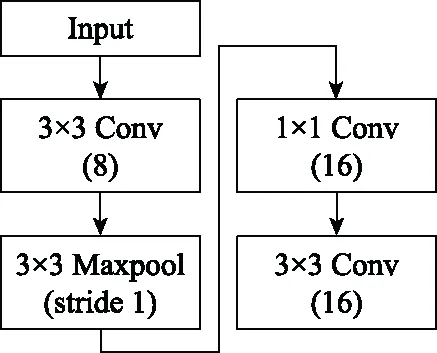
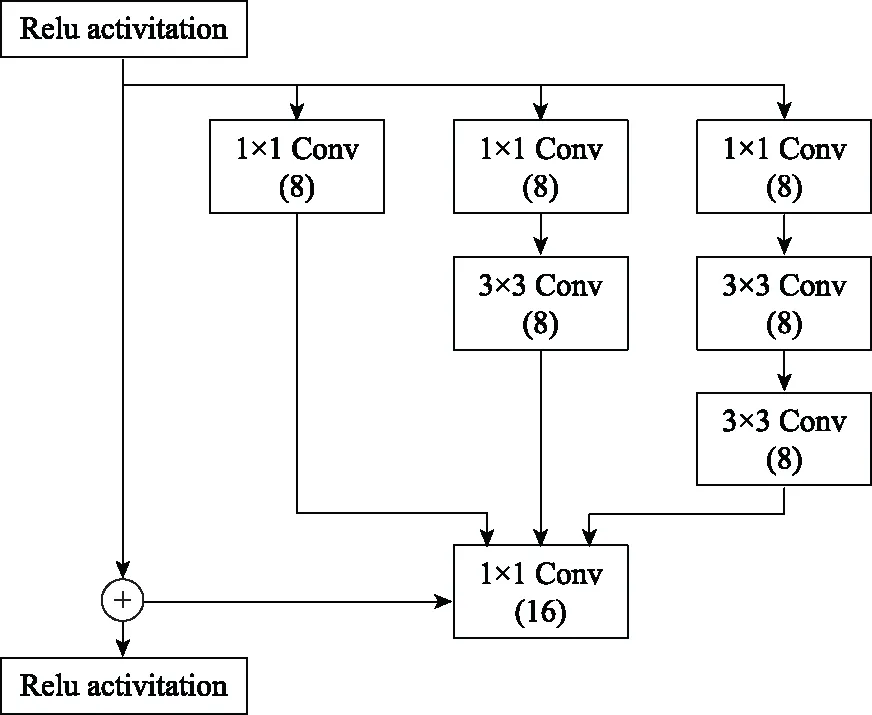
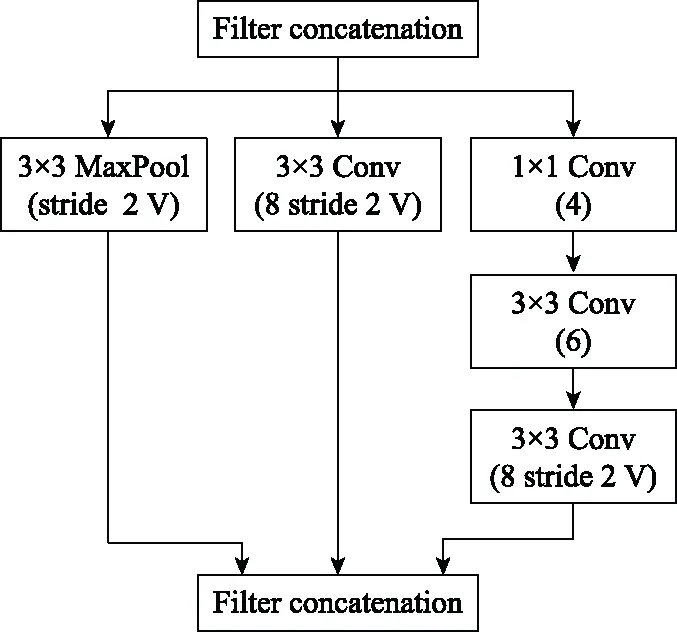
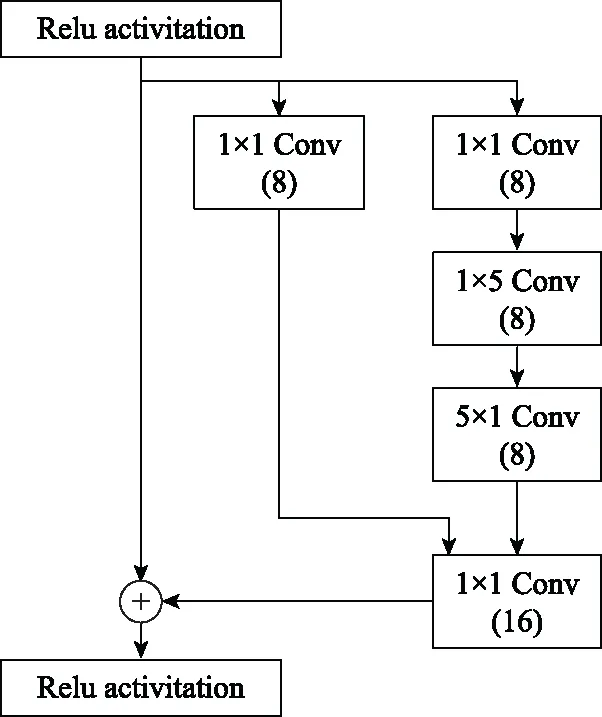
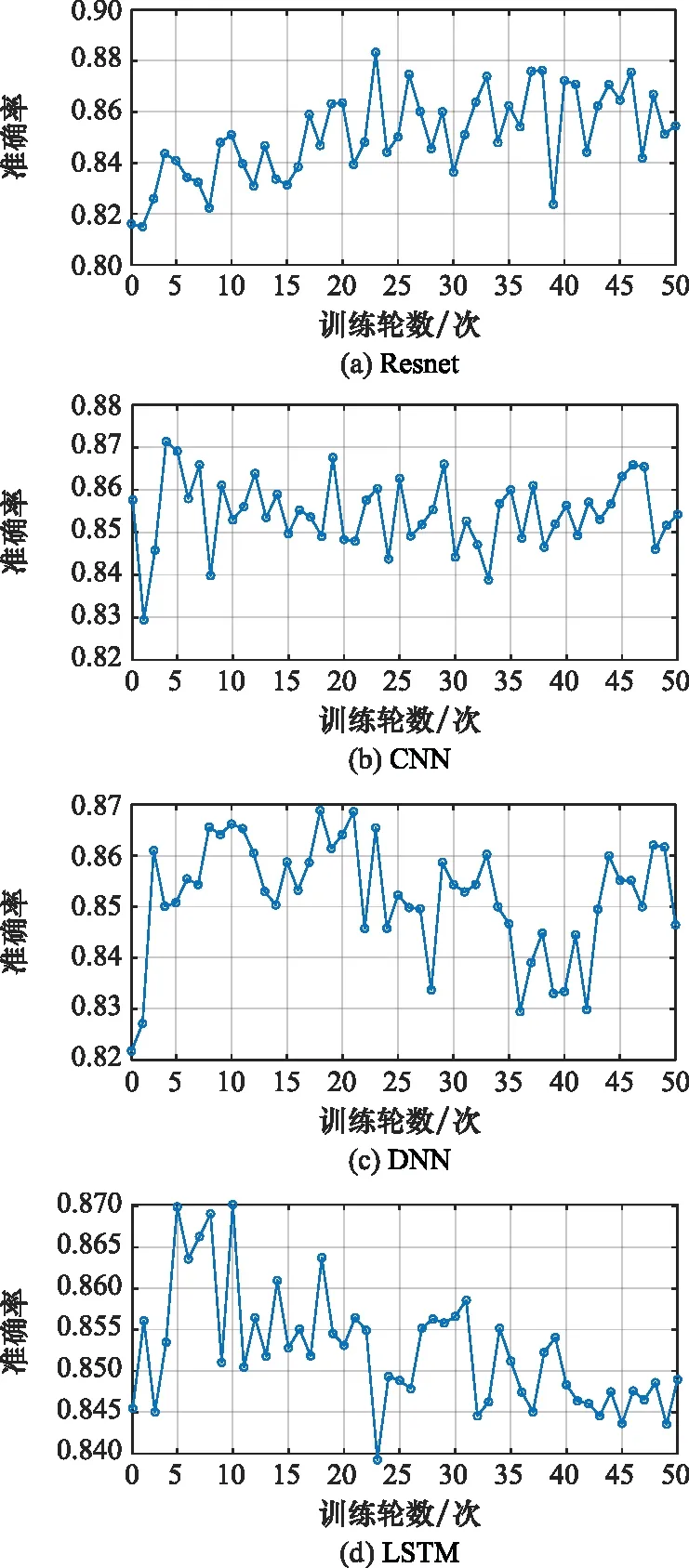
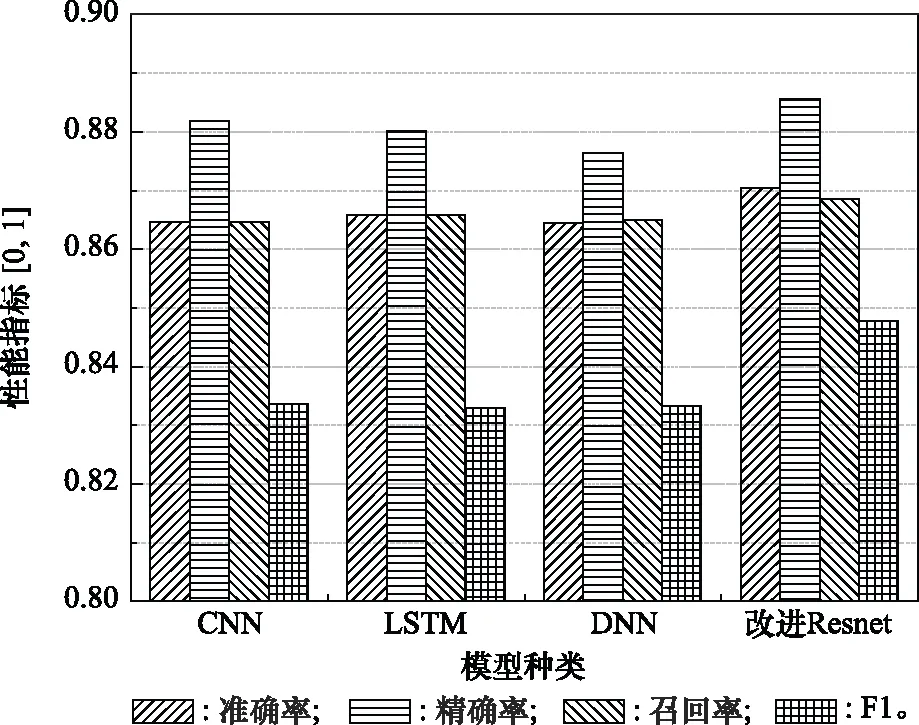
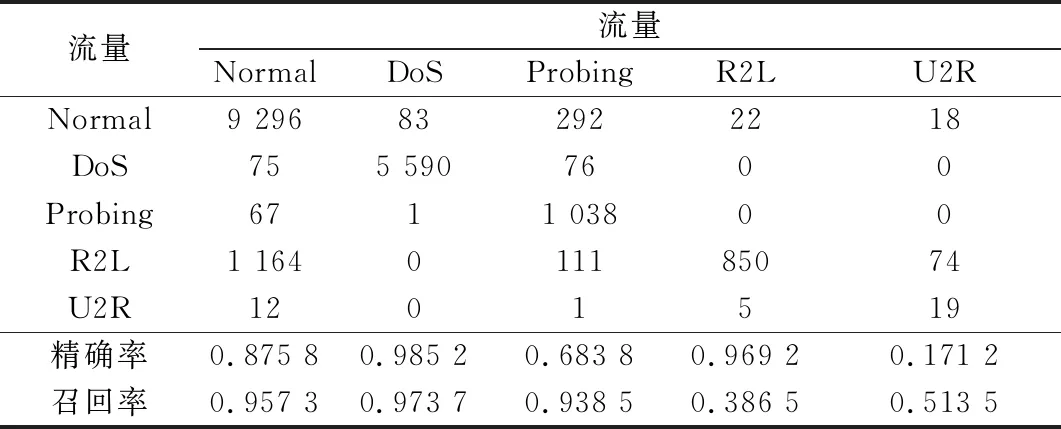
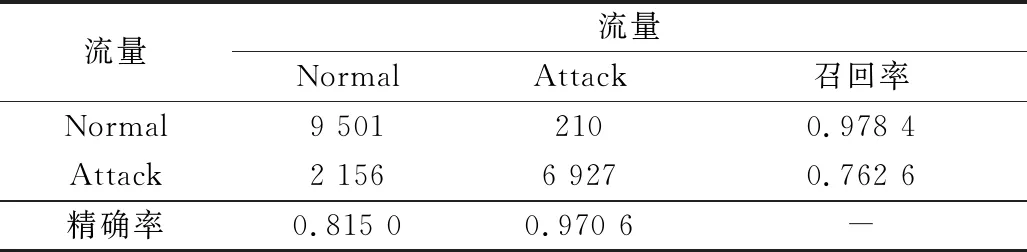
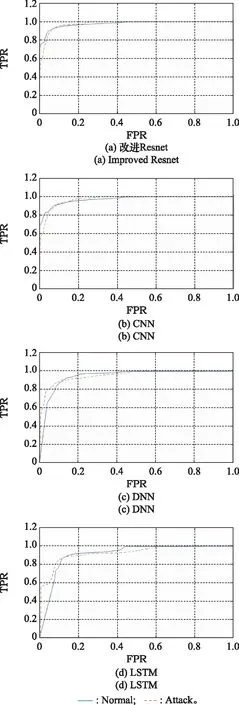
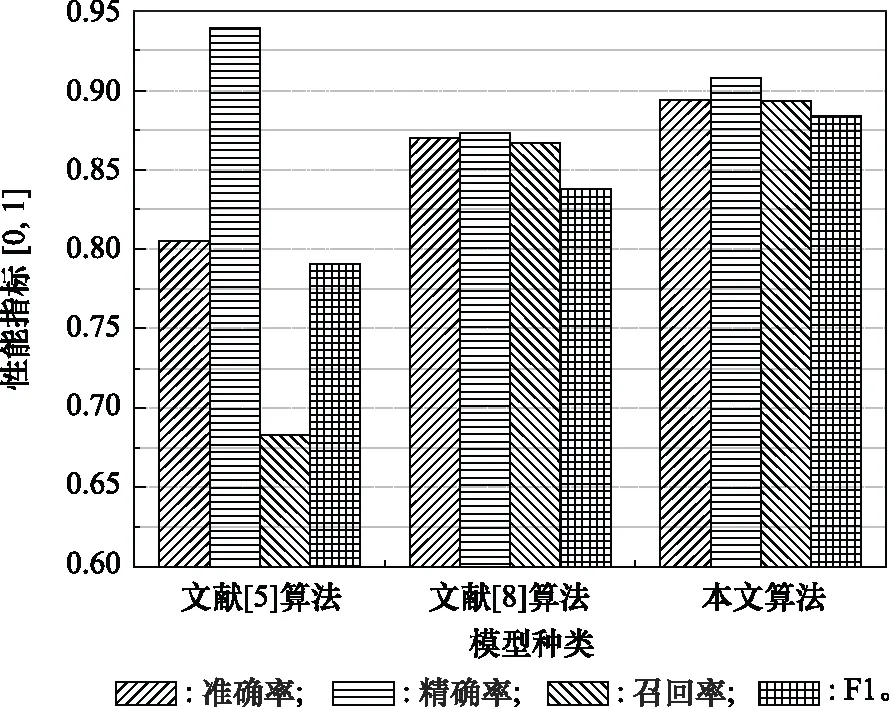
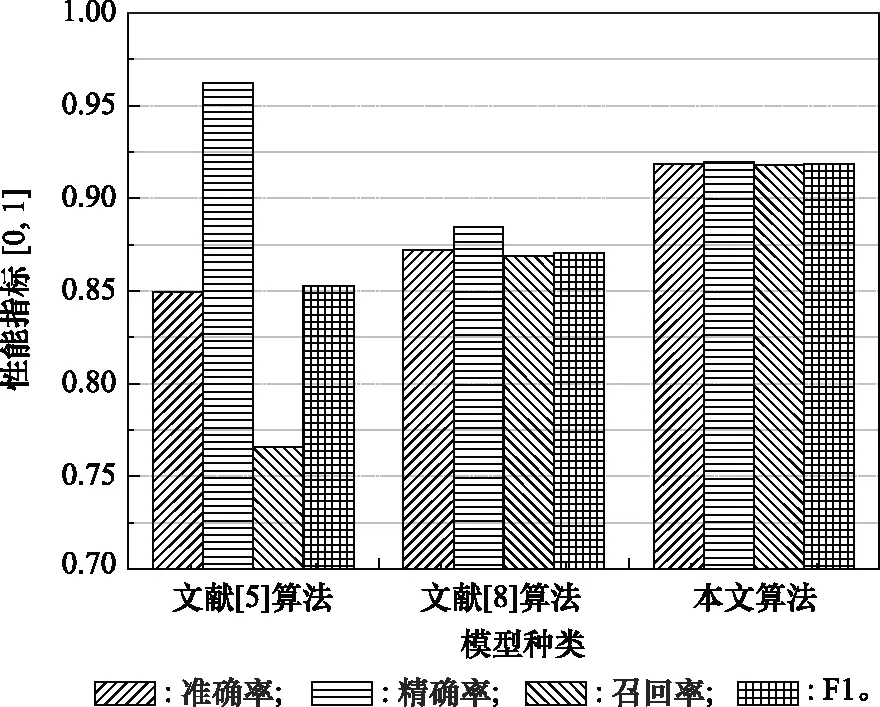
步骤 2计算样本间的不平衡程度d=ms/ml,其中d 步骤 3计算待合成的样本Q=β(ml-ms),其中参数β∈(0,1],表示新样本的不平衡程度。 步骤 6合成新样本,对于小样本的n维向量xi的k个邻近样本中随机选取一个小样本xzi,新合成样本为:Li=xi+λ(xzi-xi),其中λ∈(0,1]为随机数。 和CNN一次仅进行一种尺寸的卷积核运算相比,Inception模块使用多尺寸卷积,有1×1,3×3和5×5共3种卷积核[23],能够同时进行多个卷积路径,增加了网络的宽度,可以使网络同时对稀疏和非稀疏特征进行学习,获得一个强相关的特征集合。而添加了残差网络的Inception网络,通过跳跃连接使Inception块得到简化,并加深了网络层数[24],获得了更好的泛化性和准确度。文章引入Inception-ResNet的部分模块,并针对NSL-KDD数据集对参数进行优化改进,构建进行分类识别的残差网络模型,图3为模型结构示意图。 图3 改进残差网络结构 Stem模块由卷积层和池化层堆叠构成,在Inception模块之前引入,能够加深网络结构,扩充数据维数。卷积层采用padding=same形式,滤波器数量标注在卷积层的括号中。Stem结构如图4所示。 图4 Stem模块结构 Inception-ResNet-A模块的主要作用是提取浅层特征信息,输入特征尺寸为11×11,所有卷积核都采用padding=same形式,1×1卷积核的作用为调整滤波器输出维数,以减少计算复杂度、匹配输入和输出维度。Inception-ResNet-A结构如图5所示。 图5 Inception-ResNet-A模块结构 特征降维Reduction模块也是由Inception模块修改而来,在其基础上减少了卷积运算,增加池化运算。相比于单独的池化层,并行的卷积运算能够引入额外的特征以弥补池化压缩维度的过程中丢失的特征信息。Reduction-A模块的输入尺寸为11×11,输出尺寸为5×5,运算模块中标注“V”的表示padding=valid,否则表示padding=same。Reduction-A的结构如图6所示。 图6 Reduction-A模块结构 Inception-ResNet-B模块可以提取数据深层的特征信息,输入、输出尺寸均为5×5,所有卷积核都采用padding=same形式,模块结构如图7所示。 图7 Inception-ResNet-B模块结构 Reduction-B模块的输入尺寸为5×5,输出尺寸为2×2,对特征进行了进一步压缩,模块结构如图8所示。经过以上处理后,对数据进行全局池化处理,将特征向量压缩为1×1的尺寸输出,相比于直接添加全连接能够减少计算量,避免过拟合的发生。在经过全局池化后添加参数为0.25的Dropout层,降低神经元之间的相互耦合,减少过拟合情况的发生。之后,将数据输入到全连接层,利用Softmax函数完成对分类类别的输出。 图8 Reduction-B模块结构 NSL-KDD数据集中每个样本均有42维特征和一个标签class组成,其中accuracy特征表示21种机器学习模型中能成功识别该样本的个数,对于模型的训练无实际意义,因此舍去。数据集预处理的步骤如图9所示。 图9 数据预处理 在剩余的41维特征中有3类非数据类型的特征,分别是protocol_type、service、flag。针对非数据类型的特征,应当按照每种特征的类型数设置one-hot编码,将非数据特征转换为数据特征。同时,对数据类型的特征需要进行归一化处理以减少不同维度特征的数据差异,文章采用min-max归一化,其表达式为 (7) 数据经过ADASYN升采样后,新产生的小样本数据其One-hot编码部分为连续型小数,需要进行取整以获取贴近实际的数据。采样完毕后训练集的数据分布如表2所示,观察可知升采样后攻击流量及正常流量的占比基本相同,数据集各样本达到平衡。为保证数据的随机性,需要对数据进行随机乱序排列。经统计发现,数据中特征num_file_creations在训练集、测试集的所有样本中的取值均为0,为无效特征,故将其剔除。3种非数据类型的特征protocol_type、service、flag分别转化为3、70、11位的One-hot编码,与数据特征进行组合得到121维的特征向量,为了更好发挥卷积层的运算效果,将其转换成尺寸为11×11的二维特征向量。 表2 升采样后的训练集数据 模型架构采用图3的结构,为确定模型最佳训练轮数,从训练集中按数据类型随机抽取20%的数据作为验证集,进行轮数epoch=50次的训练,得到的准确率及损失函数如图10所示。由变化曲线可知,在训练轮数为0~30轮时,验证集的分类准确率先升高,后保持稳定;当训练轮数epoch>30时,验证集的分类准确率开始下降并在epoch>45轮后出现明显振荡,相应的损失函数取值上升并且在epoch>45轮后出现明显振荡,这说明模型在训练后期出现了过拟合现象,算法性能开始下降。因此,本文将实验模型的训练轮数设置为30轮。 图10 验证集准确率及损失函数变化曲线 此外,模型采用的优化器类型为Adam优化器,具备快速收敛、自适应学习率的能力,参数设置为β1=0.9,β2=0.99。批处理大小设置为64,算法使用categorical-crossentropy作为损失函数。 实验采用准确率Accuracy、精确率Precision、召回率Recall、调和平均值F1对多分类中各算法的性能进行评价,各性能指标的计算公式[25]为 (8) 式中:TP表示被正确分类的正例数量;FN表示被错分为负例的正例数量;TN表示被正确分类的负例数量;FP表示被错分为正例的负例数量。 在二分类的评估中,还使用AUC值及ROC曲线作为评价指标。其中准确率值越高,算法的总体性能就越好;精确率和召回率值高,算法的误报率越低。AUC值是ROC曲线下的面积大小,对于二分类问题而言,AUC取值越大,模型预测的准确率越高。 为了与实验模型产生对照,本文还设计了3种由经典深度学习方法构成的算法进行对比实验,各网络结构如表3所示。 结构表中各层命名及变量说明如下:FC(X)中X表示全连接层中包含的节点数目,取值为m表示该值等于分类数;DR(X)中X表示dropout层中随机将神经元输出置零的比例;LSTM(X)中X表示输出空间的维数;Conv(X,Y,Z,N,M)中各个参数的含义为:X表示该卷积层中用到的过滤器个数,Y、Z分别表示卷积核的宽度和高度,N表示步长,M表示padding的状态,如果写成“V”则表示设置为“Valid”,如果写成“S”则表示设置为“Same”;MaxPool(X,Y,N,M)中各个参数的含义为:X、Y分别表示池化层的宽度和高度,N表示步长,M表示padding的状态,命名规则同上。 为了进一步确定经典深度学习算法及本文实验算法对测试集进行分类识别的最佳训练轮数,本文利用KDDTrain+对4种算法进行训练,然后使用4种算法对测试集KDDTest+内的数据进行分类识别,观察不同训练轮数下各算法的识别准确率和损失函数,以研究每种算法取得最佳效果时对应的训练轮数。训练总轮数设为50轮,图11和图12分别为4种算法在不同训练轮数下对测试集数据识别的准确率及损失函数曲线。 图11 各算法准确率变化曲线(测试集) 图12 各算法损失函数变化曲线(测试集) 从图11和图12的变化曲线可以发现,4种算法对测试集的识别准确率呈现快速收敛的特点,在5轮以内的训练轮数就能够达到较高的性能指标,并且随着训练轮数增加,准确率和损失函数呈现振荡的特点,这与算法采用的Adam优化器特征相一致,即Adam优化器采用自适应学习率设置,在优化后期对于学习率的调节会导致模型收敛结果的振荡。由图11可知,4种算法均在30轮内取到了准确率最大值,即Resnet算法在第23轮、CNN算法在第4轮、DNN算法在第18轮、LSTM算法在第10轮实现了模型的最佳分类效果。在训练轮数epoch>30轮后,4种算法准确率处于较低水平,损失函数振荡幅度加大且取值逐步上升,这说明训练轮数大于30轮后,算法均出现了不同程度的过拟合状态,这与模型在验证集上的表现相吻合。 在这种情况下,为了取到经典深度学习算法及改进Resnet模型的最佳识别效果,文章采用Keras框架中的callbacks.EarlyStopping进行训练的提前终止,以保证在节约内存的条件下输出模型不会错过最佳训练效果。以图11和图12各算法的振荡情况为参考,将提前终止的耐心度设置为8,即当模型输出的准确率连续8轮都小于之前能达到的最大值时,模型将终止训练并输出之前训练的最佳模型。同时为了避免各算法出现过拟合现象,将训练轮数上限设置为30轮。为了对比模型的性能差异,经典深度学习模型的训练轮数、优化器、损失函数类型与改进的Resnet模型保持一致。 3.3.1 多分类性能对比分析 本节分别使用CNN、LSTM、DNN、改进Resnet模型对原数据训练集KDDTrain+和经过ADASYN采样的新训练集进行学习,以测试集KDDTest+作为两次学习的测试集,分别在有重采样和无重采样的情况下对比各模型对攻击流量的分类识别性能,并对重采样前后各模型自身的性能变化进行比较以验证ADASYN重采样的有效性。图13和图14分别为各模型在原训练集和重采样训练集下学习后的性能评估图。可以看出,各模型的性能指标均是精确率最高、准确率和召回率次之,调和平均值最小。无论是否进行ADASYN采样,改进的Resnet网络的4项性能指标均高于经典的深度学习网络,并且在新训练集上两者的差异更加明显。 图13 各模型性能评估(原训练集) 图14 各模型性能评估(新训练集) 由于实验中测试集不变,因此该组实验结果说明了在多分类问题的情况下,改进Resnet模型的各性能均优于CNN、DNN、LSTM等经典深度学习网络,验证了模型解决多分类问题的有效性和泛化性。残差网络的设计是基于堆叠卷积池化层并添加跳跃连接,提升了网络深度,本文的模型又向其中添加Inception模块使模型网络宽度变宽,最终使得改进的Resnet网络在特征提取、分类识别方面性能获得提升。 为了验证多分类情况下ADASYN采样的有效性,将基于原训练集和新训练集得到的模型性能指标进行对比,如表4所示。由表4可知,除了LSTM模型的精确率、召回率在过采样后出现了极小的下降,其余的模型在采样后的新训练集下得到的所有性能指标均高于原训练集,这验证了ADASYN过采样的有效性。其中改进的Resnet网络在采样前后性能提升的最大,采样前后的混淆矩阵如表5所示。 表4 各模型性能指标对比 表5 无上采样的改进Resnet混淆矩阵(多分类) 表5数据由两部分构成,第一部分是由预测类型与实际类型相构成的混淆矩阵,为表格内容前5行,其中行表头表示将测试集样本预测为该类型流量,列表头表示测试集样本的实际类型;第二部分是5种类型流量在测试集预测的精确率与召回率,为表格内容的后2行。表5是模型在无ADASYN上采样的原训练集下训练,并在测试集上得到的预测结果,表6是在新训练集上得到的相应测试结果。 表6 含上采样的改进Resnet混淆矩阵(多分类) 对比表5和表6可得出以下结论: (1) 在新训练集上得到的模型,对测试集正确预测分类的结果更好。除Normal流量的预测数量有极小的减少外,其余4种攻击流量在新训练集的模型下正确预测的数量都得到了较大提升,其中R2L的正确预测数量增加的最明显,数量由541增加至850,增加了36.35%。 (2) U2R类型流量在不进行上采样时的模型上正确分类的个数为0,精确率和召回率值都为0,因为在原训练集中U2R的样本数量极少,不平衡的数据分布导致算法在学习过程中直接忽略了U2R的特征信息,导致模型不具备检测U2R类型流量的能力,这说明了采用残差网络进行入侵检测时,解决数据集不平衡问题的必要性。在进行了上采样后,各类数据分布变得平衡,算法在学习过程中所有类型的特征信息都可学习提取,因此对于5种流量类型都可进行有效的分类,算法的泛化性和可靠性得以提升。其中U2R的召回率的上升最明显,增加了51.35%。 (3) 两种情况下算法都将大部分R2L类型的流量误判为Normal类型,其原因在于R2L流量在训练集中的数量少于在测试集的数量,因此算法在学习中无法完全掌握测试集中R2L的特征信息。这说明NSL-KDD数据集存在一定的数据划分不合理性。 3.3.2 二分类性能对比分析 在入侵流量检测的实际应用中,通常也使用二分类的手段对流量进行划分,从而方便快捷地筛选找出入侵流量并进行处理。为了检验在二分类情况下ADASYN采样及改进Resnet网络的分类性能,将4种攻击流量标签进行合并,统一改写为“Attack”类型,便得到了用于二分类检测识别的训练集和测试集。图15和图16为4种算法模型在二分类情况下的,分别在没有ADASYN采样的原训练集和有上采样的新训练集下训练的测试集评估结果。 图15 二分类模型性能评估(原训练集) 图16 二分类模型性能评估(新训练集) 由图可知,在原训练集下得到的模型中,CNN在测试集中的性能最优,准确率为88.01%,精确率达到89.30%,改进Resnet网络的性能其次;而在新训练集下得到的模型中,改进Resnet网络的性能得到了明显提高,性能为4种模型中最优,性能的提高程度比多分类情况下的上采样还要大,其中准确率达到91.88%,提升了4.47%,精确率达到91.94%,提升了2.92%。 经过上采样后,4种模型在测试集的性能均得到不同程度的提高,这说明了在二分类情况下,ADASYN上采样的方法依旧能够有效改善数据的不平衡性,使算法对特征信息的提取更加全面,提升了算法的分类准确率和泛化性。而改进的Resnet网络在各项指标上都优于其他模型,这体现出改进残差网络对于二分类的流量检测识别具有更好的适应性,算法结构和参数设计合理。 表7和表8给出了在二分类的情况下改进Resnet网络在原训练集和新训练集下的测试集预测混淆矩阵。表格数据由两部分组成,第1部分是由预测类型与实际类型相构成的混淆矩阵,其中行表头表示将测试集样本预测为该类型流量,列表头表示测试集样本的实际类型;第2部分为Normal流量与Attack流量在测试集上预测的精确率和召回率。由表可知,在新训练集下得到的改进Resnet模型对Attack流量的正确分类数量明显提升,Attack流量的TN样本数量上升、FN样本数量下降也使得Normal流量的精确率及Attack流量的召回率提升,这充分说明了在经过ADASYN采样后,模型对于Attack流量的特征信息学习更加充分,算法的总体分类能力得到提升。 表7 无上采样的改进Resnet混淆矩阵(二分类) 表8 含上采样的改进Resnet混淆矩阵(二分类) 通过比较表7和表8,发现在二分类的情况下,测试集的TN样本数量更多,FP、FN样本数量更少,整体的分类性能也是二分类情况优于多分类情况,这说明在二分类情况下,改进Resnet网络的分类效果更好,对入侵流量有更准确的检测能力,缺点在于二分类无法对入侵流量的类型进行细化区分。 二分类问题中,ROC曲线及其下面积AUC值可以用作衡量分类器的分类效率及平衡性,因为AUC不受先验概率及阈值的影响[26],AUC取值为[0,1],取值越大,算法的预测准确率越高;ROC曲线的变化不受正负样本数据分布的影响,能够客观反映出模型的分类性能。图17、图18分别给出了4种算法在原训练集、新训练集下得到的模型在测试集中的ROC曲线图,其中实线代表将Normal流量作为正例绘制的ROC曲线,虚线代表将Attack流量作为正例绘制的ROC曲线。 图17 模型测试集ROC曲线(原训练集) 图18 模型测试集ROC曲线(新训练集) 表9表示使用ADASYN采样前后的各模型测试集预测的AUC值。 表9 模型测试集AUC值 结合观察图17、图18和表9,可以得出如下结论: (1) 4种算法在经过上采样的训练集中得到的模型AUC值均大于在原训练集中得到的模型,而ROC曲线基本不受测试集数据不平衡的影响,导致AUC值提高的根本原因就是模型的分类能力提高,因为在经过ADASYN采样的训练集上,大幅提高了小样本数量,使模型在训练过程中不会忽略小样本的特征信息,提高了模型识别的泛化性和准确性。 (2) 在上采样后的ROC曲线中,改进的Resnet模型AUC值高于其他3种模型,ROC曲线更加饱满,贴近左上角。这表明改进Resnet模型的分类效果优于其他模型,这一结论与图15、图16和表7的结果相一致,充分说明了本文提出的算法在二分类的情况下能够获得最高的准确率和AUC,并且误报率低,具备良好的入侵流量检测能力。 本节为验证算法模型的实际性能和应用价值,采用文献[5,9]提出的算法与本文算法进行性能对比,分别在多分类和二分类的情况下针对准确率、精确率、召回率和F1值进行评估。其中,文献[5,9]采用NSL-KDD的原始KDDTrain+作为训练集,本文提出的改进Resnet算法采用经ADASYN采样后的数据集作为训练集进行训练。结果如图19和图20所示。 图19 算法性能比较(多分类) 图20 算法性能比较(二分类) 由图可知,文献[5]采用的STL-IDS进行特征降维,并使用SVM进行分类识别,虽然具备较高的精确率,但是在多分类和二分类情况下均存在准确率、召回率低下的问题,尤其是多分类情况下算法的召回率只有68.29%,这表明算法在查全率上存在较大缺陷,各性能指标效果差异大。文献[9]算法采用堆叠LSTM和空洞残差网络进行构建,和本文的改进残差网络具备一定相似性,在多分类情况下F1值取值较低,整体各个性能指标表现均衡,在查准率和查全率上都具备较好的性能。 相比于两种文献算法,本文提出的改进Resnet算法在经ADASYN上采样的训练集上得到的模型在多分类和二分类情况上都具备最高的准确率和最低的误报率。这充分说明了算法设计的合理性,模型分类识别具备较高的准确性和泛化性,可靠性良好。 本文提出了一种基于Inception-ResNet模块改进的残差神经网络模型,算法通过添加跳跃连接的方式增加了网络深度,解决了网络过深导致性能下降的问题,同时使用Inception-ResNet模块拓宽了网络宽度,利用特征降维模块有效减少了池化过程中的特征丢失。通过ADASYN对数据训练集进行上采样,改善小样本在不平衡数据集中的分布,解决了深度学习网络在不平衡数据集的学习中易忽略小样本特征信息的问题,通过采样前后的对比说明了自适应合成采样对于算法性能提高的重要作用。 文章最后在多分类、二分类情况下分别对经典深度学习算法和改进Resnet算法进行性能评估,并进行算法的效能对比,使用的指标包括准确率、精确率、召回率、调和平均值、ROC曲线和AUC值。实验结果表明,在多分类的情况下,改进的Resnet算法在上采样训练集下得到的模型准确率可达到89.40%,二分类时为91.88%,均在所有算法中达到最高,同时算法的误报率低、泛化性好,具备较高的可靠性和工程应用价值。

2.2 残差网络构建


3 实验分析
3.1 数据预处理


3.2 模型参数与评估指标

3.3 模型性能对比验证

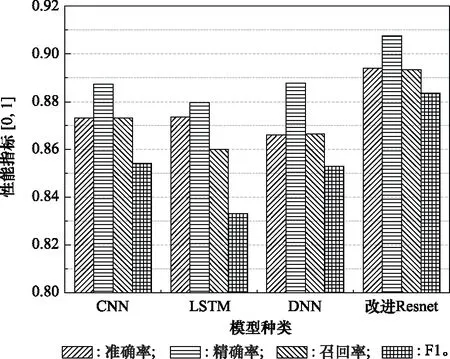


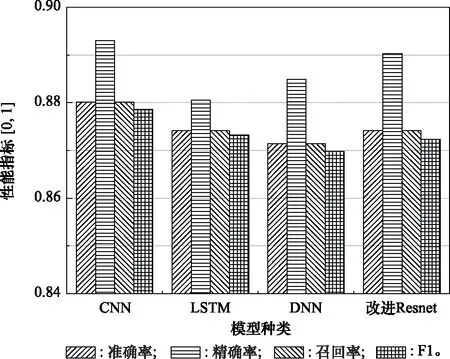




3.4 算法性能验证
4 结束语
