网络媒体语音的法庭说话人识别
2022-11-18张翠玲刘奔航
张翠玲 刘奔航
(1 西南政法大学刑事侦查学院 重庆 401120;2 重庆高校刑事科学技术重点实验室 重庆 401120)
1 引言
随着社会的不断发展,网络媒体及音视频技术也越发普及。众多网络交流媒体平台为人们提供巨大便捷的同时,也带来了较大的社会安全隐患。近年来,越来越多的不法分子利用网络平台从事违法犯罪活动。2021年3月8日,最高人民检察院发布的工作报告显示,2020年共起诉网络犯罪14.2万人,在刑事案件总量下降背景下,网络犯罪却同比上升了47.9%[1]。典型的网络犯罪包括诸如“杀鱼盘”“杀猪盘”等诈骗案件,以及诸如“快播案”[2]等利用“抖音”“快手”等短视频社交平台实施造谣、传播虚假信息类案件。随着网络媒体的井喷式发展,媒体平台上的大量语音信息成为侦查破案的有利线索和重要证据。由此,网络媒体语音数据也成为司法语音研究中的一类新的场景对象。
法庭说话人识别通过对检材语音与样本语音的分析比较,推断二者的同源性[3]。司法实践中,法庭说话人识别的基本方法可以大体分为两类,即听觉-声学-语音学分析方法和自动说话人识别方法。听觉-声学-语音学分析方法主要依靠人工专家,提取检材语音和样本语音中的相同音节,进行听觉和声学上的分析比较。该方法严重依赖专家的主观经验,客观性较差,对检材语音和样本语音的要求较高,且耗时费力。比较而言,自动说话人识别不仅对检材语音和样本语音的要求低,省时省力,而且客观性、透明性、可重复性都很好。特别是面对存在大量涉案语音数据的复杂场景,自动识别的优越性则更加凸显。此外,基于似然比框架的法庭说话人识别不仅可以量化评估语音证据的价值,还可以通过对反映案件现实条件的、相关背景语音数据的系统验证,测试该案件场景下系统识别的准确性和可靠性[4],从而更好地满足法庭对科学证据的标准要求[5-7]。
近年来,国际国内都不同程度地开展了法庭说话人自动识别系统的研究,并基于似然比框架方法对不同系统进行了实验测试和性能验证。2016年,Morrison等人基于一起实际语音案件条件构建了一个法庭语音评价数据库(forensic_eval_01),并对国际上基于不同统计模型的10个说话人自动识别系统开展了性能验证研究[8]。验证的结果表明,相对GMM-UBM(Gaussian Mixture Model-Universal Background Model)和i-vector PLDA(Probabilistic Linear Discriminant Analysis)模型来说,x-vector PLDA模型系统取得了最好的识别效果[9]。2021年,国际上13位法庭科学家和7位支持者联名发表了关于法庭语音比较系统验证的共识声明[10],建立了似然比框架下进行法庭说话人识别系统验证的国际标准。该声明明确提出,应该使用反映案件现实条件的数据库,基于似然比框架进行系统的验证测试。在国内,张翠玲等也利用forensic_eval_01数据库,对基于GMM-UBM模型的法庭说话人自动识别系统BATVOX 3.1进行了验证测试,结果表明其识别性能是所有参评系统中性能最差的[11]。张艳云等基于深度神经网络的x-vector模型系统和似然比框架方法,对较大规模的重庆方言标准采集语音数据进行了法庭说话人识别测试,验证了该场景下自动识别系统的良好性能[12]。总的来看,国内在这方面开展的研究还相对较少。此外,不同案件的场景不同,条件不一,涉及的语音数据的类型和特点也不尽相同。在同一案件场景和验证数据库条件下,不同系统的识别性能会有所不同;而在不同案件场景和验证数据库条件下,同一系统的识别性能也会有所差别。司法实践中,不管使用任何系统,都应该进行所涉案件现实条件下的系统验证,从而有利于证据价值的客观评价和科学采信。因此,针对各类案件场景语音数据开展说话人识别系统的验证及其相关研究是十分必要的。
本文以网络媒体语音为研究对象,基于似然比框架的法庭说话人自动识别系统,对不同特性和不同条件的语音数据进行验证测试,评估该系统的性能表现,分析研究其中的规律问题,进而为法庭说话人自动识别的司法实践提供参考和依据。
2 法庭说话人自动识别系统
2.1 特征提取
本研究中使用的法庭说话人自动识别系统(FREES lite 1.0)是基于深度神经网构建的x-vector[13]模型系统。系统首先对语音进行预加重、分帧、加窗、短时傅里叶变换、Mel滤波,然后提取FBank(Filter Banks)作为前端语音特征。每个语音段提取23维的FBank特征,提取的帧长为25ms,帧移为10ms。
2.2 说话人识别模型
系统采用的说话人识别模型是基于embeddings方法的深度神经网络的DNN x-vector模型。这是目前说话人识别领域的一种主流模型,因其性能优越而得到业内普遍认可。该模型基于时延神经网络(Time-delay Neural Network,TDNN)结构[14],将每一帧的fbank特征放入TDNN网络学习,得到帧级别语音特征后,再通过池化层将各帧特征聚合为段级别语音特征,最后再连接2个全连接层和一个softmax层,将每个语音段映射到对应的说话人标签。从第一个全连接层中提取出低维特征向量x-vector后,再使用线性判别分析[15]对embeddings进行降维处理,将特征数据从512维降至128维。关于本系统模型的详细介绍见文献[12]。
2.3 识别打分
系统使用概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)[16]模型作为分类器,进行说话人识别打分,同时进行跨信道补偿。PLDA是概率形式的线性判别分析,具有良好的信道补偿能力,可用于解决实际场景语音数据与已经训练好的基础模型之间的信道失配问题,有效提升系统的识别性能。
PLDA基于两种假设,计算两段语音的比较得分。公式(1)为PLDA得分计算公式,其中,Hs为同一空间假设,代表假设检材语音与样本语音的embeddings来自同一说话人;Hd为不同空间假设,代表假设检材语音与样本语音的embeddings来自同一说话人。n1和n2分别为两段语音的x-vector矢量。得到的对数似然比得分score值越大,检材语音与样本语音来自同一说话人的可能性越大。

2.4 得分校准和似然比计算
通过PLDA算法得到得分score后,还要基于一定规模的相关背景人群语音数据库进行得分校准。校准过程也是似然比转换过程,可以通过逻辑回归算法将得分值转换为似然比LR。LR值是证据强度的量化评价指标,以1为界限。LR值大于1,表明证据支持同一说话人假设;LR值小于1,表明证据支持不同说话人假设;LR值距离1越大或越小,表明证据支持对应假设的力度越大,证据价值越高。LR值等于1,表明支持两个竞争假设的程度相等,因而没有价值。关于似然比框架的详细介绍,参见文献[17-18]。
3 实验数据和测试方法
3.1 数据收集与处理
本文的数据来源于“抖音”“快手”等网络自媒体平台,通过这些自媒体软件进行开放视频的下载。从“抖音”平台和“快手”平台上分别选择了75名用户,每名用户下载10个视频。视频中的发音人均为男性,年龄在20-55岁之间,普通话发音,水平良好。发音人职业比较广泛,包括教师、律师、主持人、医生、自媒体从业者等。每个用户的视频均为室内录制,比较安静,噪声小。视频录制的时间间隔为几天到一个月不等,视频时长在一分钟以上不等。对视频进音频提取处理,采用格式工厂软件(X64 5.6.0),将全部视频中的音频提取出来,保存为“PCM.wav”格式,总计提取到1500个音频。
3.2 测试内容与数据类型
本文重点关注采样率、校准集规模、音频数量及音频时长对法庭说话人自动识别的影响,因此测试内容共有4项,即分别测试不同采样率、不同规模校准集、不同音频数量及不同音频时长条件下系统识别的性能表现。由于测试的内容各有不同,每项测试使用的数据集、数据类型、数据规模也有一定差别。关于每项测试中所使用测试集的音频基本属性、数据类型和数据规模,详见表1。

表1 4项测试使用的音频数据列表
3.2 测试方法
开展说话人识别系统验证时一般使用3类语音数据集,即训练集、校准集和测试集。训练集用于对PLDA模型做域自适应训练,以解决测试集语音的言语风格、方言特征、信道条件和录制环境与已训练基础模型不匹配的问题。校准集用于对PLDA模型的打分结果进行校准,需要使用人工标定好的、已知真实来源的数据进行。训练集和校准集的使用,都是为了提高识别系统的准确性。测试集用于对说话人识别系统的性能进行测试,测试结果通过具体评测指标进行评价。
3.3 评价指标
系统评价采用基于似然比框架的系统评测的标准指标进行。系统评价的数据指标有两个,一个是对数似然比代价函数(Log likelihood ratio)[19],另一个是等误率(Equal Error Rate,EER)。的表达式见下式(2):

3.3.2 EER值
EER是说话人识别测试中常用的评价指标,是指系统的错误接受率和错误拒绝率相等时的概率。EER值越低,系统的识别性能越好。
3.3.3 Tippett图
Tippett图,也称可靠性函数图,是似然比框架下法庭说话人识别系统验证的标准图示[20]。Tippett图的横轴为以10为底的对数似然比(log10LR),纵轴为同一说话人和不同说话人比较的概率累计分布(见图1)。Tippett图中,向右上延伸的曲线代表同一说话人之间的比较,向左上延伸的曲线代表不同说话人之间的比较。两条曲线交点处对应的概率就是EER。两条曲线分得越开,交叉点越低,系统识别的效果越好。
4 实验结果和讨论
4.1 采样率对系统识别性能的影响
一般来说,语音的采样率越高,代表语音的质量越好,因而说话人识别的效果也就越好。然而,现实案件条件下,基于信道传输和存储空间的考虑,通常情况下语音数据的采样率保持在8KHz,如手机通话语音。采样率降低会造成法庭说话人识别性能的下降,但是具体下降到何种程度还需要实验测试和量化评价。为此,我们将50人(每人10个音频)的校准集和50人的测试集(每人10个音频)中的全部音频进行了采样率调整,分成16KHz和8KHz两个组别,音频长度均为60秒。将两组测试集数据分别输入系统进行说话人识别,利用相同采样率的校准集进行校准,测试结果见表2。

表2 两种不同采样率条件下的说话人识别结果
从表2中的数据可以看出,总体上,两种采样率条件下的系统识别效果都很好。在8KHz采样率条件下,值达到0.217,已经充分表明了系统的有效性能。但是,相对于16KHz的采样率组来说,8KHz采样率组的识别性能大幅下降,值增加了103%,EER值增加了138%。这充分说明采样率不同直接对系统识别的准确性造成了较大影响,使其识别性能下降一倍还多。图1为两种采样率条件下系统识别的Tippett图。

图1 8KHz和16KHz采样率条件下说话人识别的Tippett图
就本文采集的短视频平台语音来说,语音的采样率都很高,绝大部分的音频都能达到44KHz,这是网络平台对音质要求较高的缘故。这为法庭说话人识别提供了非常好的数据质量和识别性能。需要指出的是,过高的采样率并不会带来系统识别性能的显著提升。对于8KHz频率范围的人类语音来说,16KHz的采样率已经足够保证说话人识别的性能。而多数场景下8KHz采样率的语音的说话人识别效果也在合理范围。当然,司法实践中,有条件情况下还是要首选高采样率语音数据。
4.2 校准集规模对系统识别性能的影响
校准集的使用是法庭说话人自动识别的一个标准步骤,可以有效提升说话人识别的效果。但是,究竟使用多大规模的校准集最为合理,目前还没有固定标准。校准集过小,起不到应有的效果;校准集过大,又会给数据采集带来较大困难。为了研究校准集规模的大小对系统识别性能的影响,我们基于16KHz的采样率数据,在50人测试集(每人10个音频)不变条件下,调整校准集的大小分别进行说话人识别测试。校准集的规模从20人开始,依次递增,每次增加10人,直到最后达到100人规模。10组校准集规模的说话人识别结果见表3。

表3 9种不同规模校准集条件下的说话人识别结果
图2为不同规模校准集的识别结果的折线图,从中可以更为明显地看到这种变化规律。值和EER值以60人规模为分界点,逐渐趋于平稳,也就是说,60人规模处于拐点位置。由此,司法实践中,可以考虑将60人规模的校准集作为下限使用,至少在该类案件语音场景下可供参考。
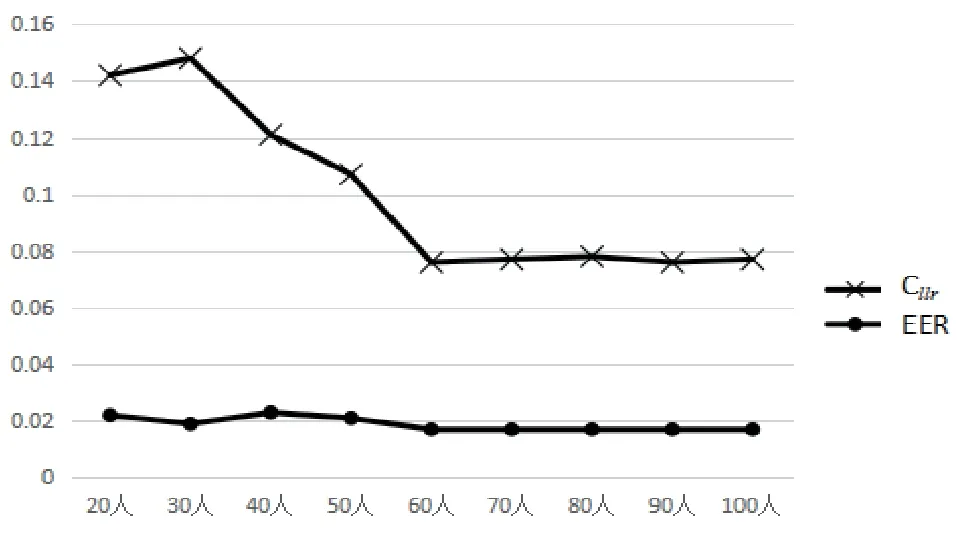
图2 不同规模校准集条件下的系统识别性能图
利用不同规模校准集进行说话人识别的Tippett图,见图3。

图3 不同规模校准集条件下说话人识别的Tippett图
4.3 校准集的音频数量对系统识别性能的影响
对于校准集来说,一般要求每个人至少要有两个以上音频才可以实现校准功能。校准集中每个人的音频数越多,校准和识别的效果越好吗?我们利用50人的校准集,基于16KHz的采样率数据,将每个说话人的音频数量分为2、3、5、7、10等5个组,然后对50人(每人10个音频)的测试集进行了说话人识别测试,结果见表4。
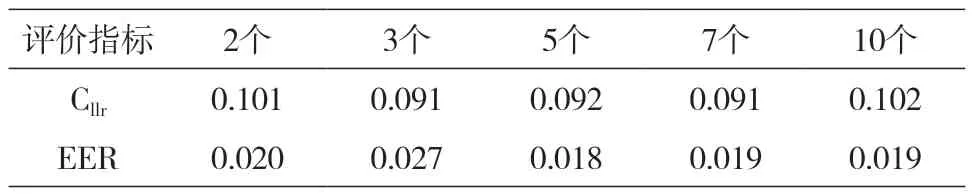
表4 不同音频数量校准集条件下的说话人识别结果
从表4可以得出,对校准集进行不同音频数量的调整之后,系统识别的值、EER值发生了一定程度的变化,但整体上相差不大。就值来说,音频数量为3个和7个时的值最低(0.091),但与音频数量为5个的结果(0.092)没有本质差别。音频数量为10个时的值最高(0.102),但与音频数量为2个的结果(0.101)在同一水平。对于EER值来说,音频数量为5个时的EER值最低(0.018),但是与音频数量为7个和10个时的EER值基本保持在同一水平。音频数量为2个和3个时的结果接近,都在0.02左右。综合来看,校准集中每个人音频数量的持续增加并没有带来系统性能的稳定性提高,加之各组指标之间的变化幅度比较小,因此,基于系统性能和样本采集成本的双重考虑,我们认为实践中校准集的每个人音频数仍是至少两个,当然有条件能够采集3个更好。
利用不同音频数量的校准集进行说话人识别的Tippett图,见图4。

图4 不同音频数量校准集条件下说话人识别的Tippett图
4.4 语音时长对系统识别性能的影响
音频时长会对说话人识别的效果造成较大的影响,因为从理论上讲,音频时长越长,语音所含的特征信息越丰富,因而越有利于说话人的识别。但是,在案件现实条件下,检材语音都比较短,特别是在刑事案件中,有的案件中检材语音仅有几秒钟。为了探究较短时长语音对说话人自动识别系统的影响程度,我们在50个人的测试集中,基于16KHz的采样率数据,从每人的10个音频中随机选取2个音频进行剪辑处理。前面的测试集中每个人均采用的是10个音频,目的是为了增加测试的难度,该项测试中之所以选择两个音频,主要是基于案件现实场景考虑。实际案件中,检材语音和样本语音各有一段的情况居多。
利用“Adobe Audition 2019”软件对所有的音频进行批量剪辑,将全部音频分别剪切为5s、10s、15s、20s 4个长度组别,然后进行说话人识别测试,结果见表5。
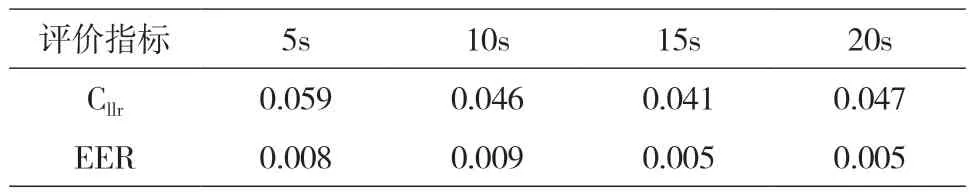
表5 不同音频时长条件下的说话人识别结果
表5中的数据表明,整体上,音频时长的增加确实带来了系统性能的改善,时长为15s时系统识别效果最佳。以15s为基准,当时长从5s增加到15s时,值降低了31%,EER值降低了38%,系统性能得到了明显提升。当时长从10s增加到15s时,值降低了11%,EER值降低了44%,系统性能仍在提升。但是,当时长由15s增加到20s时,值未降反升,提高了15%,EER值也未改变。这意味着,音频时长达到一定程度以后,继续增加并没有带来系统性能的持续改善。当然,这与相同音频时长内的有效语音信息量并不相等有关。实践中,在检材语音长度可控性较低的情况下,还是应该尽可能采集较长的样本语音进行比较,以保证识别的效果。
不同音频时长条件下进行说话人识别的Tippett图,见图5。

图5 不同音频时长下进行说话人识别的Tippett图
此外,需要指出的是,本研究中4项测试的时长均是音频的总体时长,并非去掉静默段后的有效时长。针对4种时长音频的有效时长进行了初步统计,每种选择了10个代表性音频进行了有效时长的平均值提取,5s、10s、15s、20s音频去掉静默段的有效时长平均在4.5s、8.7s、13.7s、17.8s左右。网络媒体的音视频鉴于时长的限制,一般语速为中等偏上,因此有效时长相对较长。在这种情况下,系统取得了很好的识别效果,进一步验证了该模型系统的良好性能。
5 结论
本文采用基于似然比框架的法庭说话人自动识别系统,对150名男性的1500个网络媒体语音进行了法庭说话人识别验证研究,分别测试了不同采样率、不同规模校准集、校准集不同音频数量、以及测试集不同音频时长条件下的系统性能,量化分析和评价了这些因素对系统识别性能的影响。研究表明,在未进行PLDA自适应训练情况下,系统识别仍然得到了很好的识别结果,表明系统在该类网络媒体语音场景下的良好识别性能。总体上看,虽然音频的采样率越高、校准集的规模越大、校准集说话人音频数量越多、测试音频时长越长,系统的识别性能越好,但是这一趋势并不稳定,当指标达到一定程度后,继续增加指标并不会带来系统性能的稳定提升。
司法实践中,我们需要在系统性能和时效成本之间找到一个平衡点。基于本研究的语音数据质量,8KHz采样率、60人规模的校准集、校准集中每人2~3个音频,以及15s的音频时长条件下已经取得了很好的自动说话人识别效果,而这些条件也反映了一定的案件现实情况。因此,本研究结果不仅可以为法庭说话人自动识别技术的实践应用提供量化依据,还可以为自动识别系统的性能改进提供参考。
