信息分离和质量引导的红外与可见光图像融合
2022-11-18徐涵梅晓光樊凡马泳马佳义
徐涵,梅晓光,樊凡,马泳,马佳义
武汉大学电子信息学院,武汉 430072
0 引 言
由于硬件设备和光学成像的限制,单一类型的传感器受到硬件设备的限制,只能捕捉场景的部分信息,而多传感器组合可以捕捉到同一场景的互补信息。具体来说,可见光传感器通过反射光成像,但成像质量极易受光照条件和遮挡的影响;红外传感器通过热辐射成像,不受光照和遮挡的影响,但噪声明显且纹理细节较少,不利于人眼对场景的理解。红外与可见光图像融合旨在从两幅源图像中抽取互补信息并压缩冗余信息以合成一幅具有更优场景表达能力的融合图像。融合后的图像可以辅助后续的视觉任务,例如人脸识别(Singh 等,2008)、目标检测和跟踪(Li 等,2020;Zhang 等,2019)以及安防监控(Ma 等,2020)等。
为实现红外与可见光图像融合,学者们提出了多种融合算法。根据原理及算法类型,这些融合算法可以分为传统算法和基于深度学习的算法两大类。传统融合算法主要包括基于多尺度变换的融合算法(杨勇 等,2015;陈木生,2016;Chen等,2020)、基于稀疏表达的融合算法(Wang 等,2014;Zhu 等,2018)、基于子空间的融合算法和混合融合方法(Liu 等,2015;Zhou 等,2016;Yin 等,2017)以及其他的融合算法(Ma 等,2016;Du 等,2018;宫睿和王小春,2019)。这些算法旨在将源图像分解为多维特征或将源图像映射到其他空间,然后在分解结果上运用融合策略进行融合。一方面,为了提升融合效果并且为了后续可以人为地设计融合规则,这些分解方式往往将多模源图像按照同种方式分解。然而由于成像机理或模态的不同,从不同类型的源图像中分解出的同类型信息,其物理含义不尽相同。例如,多尺度分解往往将图像分解为不同频率的子带,在可见光图像中,高频信息表示物体的边缘或者表面丰富的纹理,而在红外图像中,高频信息则表示两种具有不同热辐射属性的物体或材质的交界处。因此,对多模图像采用相同的分解方式是不恰当或者有待改进的。对于成对的红外与可见光图像来说,源图像中既包含着相同的部分(例如共有的场景信息),也包含着不同的部分(例如特有的纹理、热辐射等信息)。因此,本文以共有信息和特有信息为分解目标,并在此基础上设计相应的融合规则,这样融合图像才会更加突出细节。另一方面,人工设计的分解方式越来越复杂,这样必然导致融合效率的减退。
基于深度学习的融合算法按照理论可以分为基于卷积神经网络的方法和基于生成对抗网络的方法。由于真值融合图像的缺乏,基于深度学习的算法往往依赖自监督对网络进行训练。换句话说,这些方法往往通过人为观察来定义源图像中的特有属性,让融合图像尽可能保留源图像中人为定义的属性,以此作为约束来训练融合网络。例如,FusionGAN(Ma 等,2019)、DDcGAN(Ma 等,2020)和AttentionFGAN(Li 等,2020b)以像素强度作为红外图像的特有属性并以梯度作为可见光图像的特有属性。然而对于红外图像中热辐射属性多变(纹理丰富)而可见光图像中平滑的区域,此类约束会导致融合图像中场景信息的丢失。在另一些方法中,损失函数约束融合图像与源图像保留更高的结构相似性,或者约束融合图像保留源图像中更高频率的信息(Zhang 等,2020;Hou 等,2020)。然而,以结构或者高频信息作为源图像的特征信息会降低融合图像中目标的显著性,不利于人眼对目标的快速定位与捕捉。因此,为了客观地定义源图像中的特有信息,本文使用基于深度学习的信息分离,客观地将源图像分解为共有信息和特有信息。对共有信息和特有信息分别采用特定的融合策略更有利于源图像中信息的保留。
此外,在传统的融合算法或者非端到端的深度学习融合算法中,融合规则的设计是算法必不可少的重要环节,也是影响融合性能的关键步骤。然而,由于分解结果的多样性和特征的难解释性,目前融合策略仍停留于平均、相加和最大值等几种简单传统的方式,融合策略的局限性也限制了融合性能的提升。与此同时,图像融合中存在多种评价指标可以对融合图像质量(包括图像的信息量、对比度等)做出客观评价。理论上,当融合图像在融合指标上结果更优时,融合策略的融合性能更强。然而,这些指标难以直接用做约束来训练融合网络。如图1所示,由于衡量融合图像质量的指标未对融合图像与源图像间的相似性做约束,直接以这些指标作为损失函数会使网络生成场景信息丢失且噪声严重的融合结果。针对此问题,本文提出了质量引导的融合策略,在信息分离的结果上,通过权重编码器学习特有信息对应的权重。权重编码器以分离出的特有信息特征图为输入,以融合图像质量指标为损失函数,灵活地学习通道级权重,使融合图像在保留原始场景结构信息的基础上,保留更多源图像中的信息,表现出更符合人眼感知的视觉效果,融合结果如图1所示。

图1 红外与可见光融合结果示意图Fig.1 Fusion results of infrared and visible images((a) visible image; (b) infrared image; (c) fusion result with only metric constraint; (d) fusion result of the proposed method)
本文算法的贡献或特点可概括为以下3方面:1)提出了基于神经网络的信息分离方法。相比于人为定义的源图像的特征属性,基于网络的信息分离方法客观地将源图像分解为共有信息和特有信息。本文对这两部分分别使用特定的融合策略以提升算法的融合性能。2)设计了基于神经网络的质量引导融合策略。不同于以往算法中采用固定且简易的融合策略,本文将衡量融合图像质量的指标应用于提升融合策略的性能,相比于目前常用的传统融合策略,质量引导的融合策略可以使融合图像包含更多的场景信息且呈现出更符合人眼感知的视觉效果。3)在公开的红外与可见光图像数据集上的定性及定量结果均证明了本文算法在红外与可见光图像融合任务上的有效性。与传统融合策略的对比实验也证明了本文算法可以在更低的自由度上实现更多的信息保留并取得较高的对比度及视觉效果。
本文方法的总体框架及流程如图2所示。给定一对配准的红外图像ir和可见光图像iv,先使用信息分离对源图像进行分解,从两幅源图像中分别分离出共有信息和特有信息。然后,对共有信息采用传统的融合策略进行融合,得到融合后的共有信息cf。为了最大程度地保留源图像中的信息并呈现出利于人眼感知的效果,对两幅源图像中的特有信息采用基于深度学习的质量引导融合策略,得到融合后的特有信息uf。生成器作为信息分离的逆变换,将共有信息和特有信息映射回图像域。因此,将融合后得到的cf和uf输入生成器以生成最后的融合图像f。第1节和第2节分别给出关于信息分离和质量引导融合策略的详细描述。
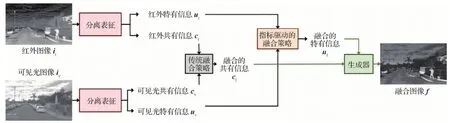
图2 本文算法总体流程图Fig.2 Overall procedure of the proposed method
1 可见光与红外图像的特有信息分离
由红外和可见光图像的成像过程,易知两种图像是对同一场景的表征,区别在于表征方式不同,红外图像捕捉热辐射属性而可见光图像捕捉反射光属性。由于源图像为同一场景的表征,场景相关信息应包含大量的共有信息,而属性相关信息与成像原理相关,包含更多的特有特征。本文采用信息分离将源图像分解为两部分:共有信息与特有信息。将两类信息分离并采用不同的融合策略,实现信息在更大程度上的保留。


图3 分离网络共有信息编码器和特有信息编码器和和生成器G的映射关系示意图Fig.3 Mapping relationships of the common encoders and the generator G in the decomposition network
为使编码器和生成器具备上述的映射关系,以域中具体的数据为例,研究数据间的约束关系。假设红外域和可见光域中对应的图像对为{ir∈I,iv∈V},则红外和可见光图像的共有信息cr,cv∈C,具体表示为
(1)
(2)
1.1 损失函数
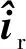
(3)
则重建损失具体定义为重建图像和原始图像间的相似性损失

(4)
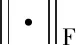
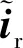
(5)
则转换损失可具体定义为
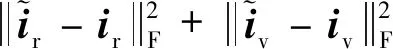
(6)
3)特有信息损失。考虑到当特有信息中包含源图像的全部信息时,生成器依旧可以完全依赖特有信息重建出源图像或者虚假图像(即满足式(4)和(6)中的损失较小),而此时共有编码器提取的cr和cv可能失去共有信息的物理意义甚至产生零解。为了避免这种情况,且让共有信息和特有信息尽可能分离,本文约束特有信息中包含的信息量,并将其定义为特有信息损失
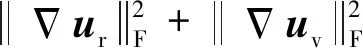
(7)
因此,编码器和生成器的总损失定义为
LE&G=Lrecon+αLtrans+βLU
(8)
式中,α和β为控制3项损失函数间平衡的超参数。
1.2 网络结构
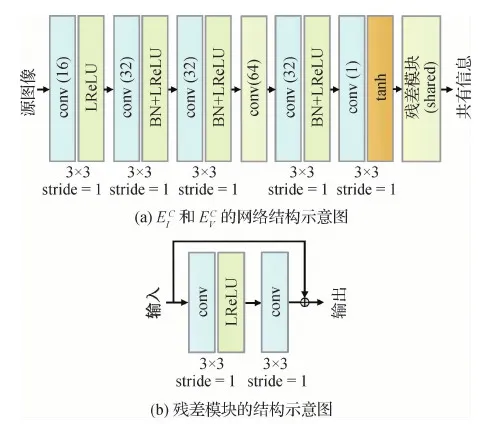
图4 共有信息编码器网络结构示意图Fig.4 Network architecture of the common encoders ((a)network architecture of (b) network architecture of the residual block)
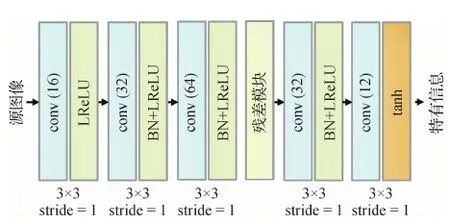
图5 特有信息编码器的网络结构示意图Fig.5 Network architecture of the unique encoders
2)生成器。生成器的输入为一组共有信息特征图和特有信息特征图的组合,依据组合的不同,其输出图像不同。当输入的共有及特有特征图来自同一源图像时,生成器输出重建的源图像。当输入的共有及特有特征图来自两幅不同的源图像时,生成器输出转换后的虚假图像。当输入融合后的共有及特有特征图时,生成器输出融合图像。生成器的具体网络结构如图6所示,图中拼接(concat)表示沿着通道维度将共有信息特征图和特有信息特征图串联。
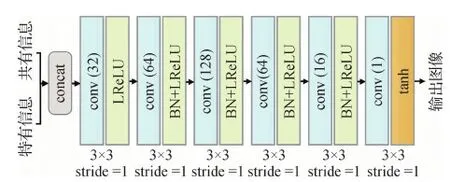
图6 生成器的网络结构示意图Fig.6 Network architecture of the generator
2 质量引导的图像融合
对分离出的共有信息和特有信息,本文方法采用不同的融合策略。由于共有信息包含了两幅源图像中大量的共有信息,具有高度的相似性,为了节约运算和时间成本,本文采用传统融合策略以提高融合效率。由于在特征图中,更大的值通常对应于更显著的特征,所包含的信息量也更大。因此,本文选取最大值融合策略来最大程度地保留共有信息。融合后的共有信息cf定义为
cf=max(cr,cv)
(9)
式中,max(·)表示逐元素取最大值。
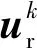
(10)


(11)
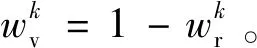
根据融合后的共有信息cf和特有信息uf,依据特有信息分离的逆变换,融合图像f可由下式生成
f=G(cf,uf)
(12)
式中,G为第1节中定义和优化后的生成器。
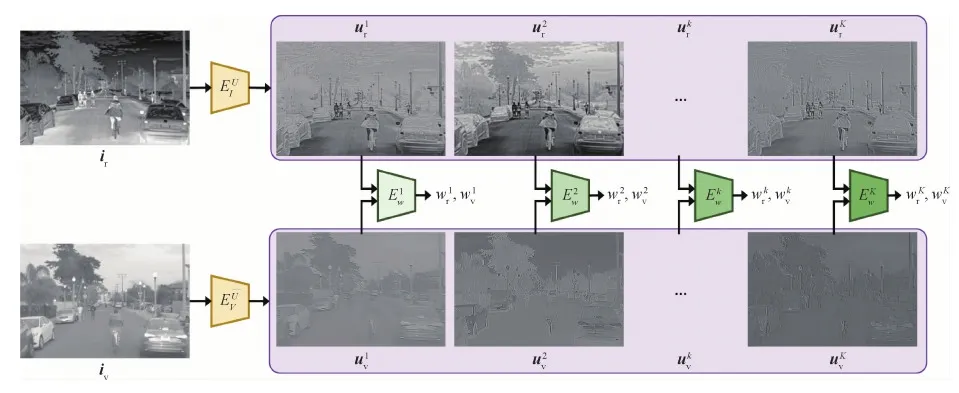
图7 基于权重编码器Ew的质量引导融合策略示意图Fig.7 Quality-guided fusion strategy by applying the weight encoder Ew
2.1 损失函数
对于衡量融合结果图像质量的指标,本文从以下方面进行考虑。
由于人类视觉系统对图像对比度的敏感性,图像中对比度更高的区域往往更容易抓住人眼的注意力。基于这种敏感性分析,对比度更高的融合图像往往能呈现更符合人眼感知的视觉效果。为此,本文采用标准差(standard deviation, Std)这一融合指标来客观衡量图像的对比度。具体来说,标准差是基于图像统计数据的融合指标,依据图像的像素强度分布和对比度来衡量图像质量,具体定义为
(13)
式中,fm,n表示图像f中第m行、第n列的像素点,M和N分别表示总行数和总列数,μf表示图像的均值。融合图像的对比度越高,标准差就越高。因此,更高的标准差代表融合图像包含更多的信息,热目标相对背景更加突出,视觉效果更清晰。
此外,融合图像需要尽量保留源图像中的信息,呈现出最多的信息量以对场景做出全面描述。为此,本文使用平均梯度(mean gradient, MG)对融合图像f中的信息量做出衡量。MG越大说明融合图像中的平均梯度越高,纹理信息越丰富,对场景的描述越完善。融合图像f的平均梯度具体定义为
(14)
式中,|·|表示取绝对值。梯度损失弥补对比度损失容易忽略的像素强度较为相似的局部细节;对比度损失弥补梯度损失无法关注的整体对比度。
为使融合图像的对比度最大且纹理信息最丰富,权重编码器Ew的损失函数定义为
Lw=-Std(f)-λMG(f)
(15)
式中,λ为平衡两项指标的超参数。
2.2 网络结构

图8 权重编码器Ew的网络结构示意图Fig.8 Network architecture of the weight encoder Ew
综上所述,本文融合模型结合了第1节所述的特有信息分离和在此基础上设计的第2节所述的质量引导的特有信息融合策略。整体的融合框架如图2所示,各个子网络的具体训练流程如下所示:
1)训练特有信息分离网络:
初始化θD;
在每次迭代过程中:
随机采样m对红外与可见光图像块;
生成共有信息{cr,cv}和特有信息{ur,uv};
用RMSProp优化器最小化式(8)以更新θD;
2)训练权重编码器:
固定θD,初始化θw;
在每次迭代过程中:
随机采样m对红外与可见光图像块;
用RMSProp优化器最小化式(15)以更新参数θw;
3)得到θD和θw的最优解。
3 实验结果及分析
为了验证本文方法在红外与可见光图像融合上的有效性,将本文算法与6种先进融合算法进行定性和定量对比。包括4种传统融合算法:GTF(Ma 等,2016)、FPDE(Bavirisetti 等,2017)、VSM-WLS (Ma 等,2017)、MDLatLRR(Li 等,2020)以及两种基于深度学习的融合算法:DenseFuse(Li 和Wu,2019)、FusionGAN(Ma 等,2019)。
3.1 实施细节
本文训练和测试的数据集均来自U2Fusion(Xu 等,2020)公开的红外可见光融合数据集RoadScene(https://github.com/hanna-xu/RoadScene)。训练集由该数据集中的150对图像对构成,这些图像对被有重叠地裁剪成3 200对大小为128×128像素的图像块用于分离网络和权重编码器的训练。超参数的设置如下:α=1,β=0.000 01,λ=1 000。批大小(batch size)设为12,分离网络训练4轮(4个epoch),权重编码器Ew训练1轮(1个epoch)。开始训练两个网络时,学习率均设为0.000 15,随后,学习率随着训练过程进行指数衰减。整个框架在TensorFlow 上实现,实验在NVIDIA Geforce RTX 2080Ti GPU和2.4 GHz Intel Core i5-1135G7 CPU上进行。
3.2 定性结果分析
本文选取6组典型的红外可见光图像对,包含行人、车辆和建筑等场景。6种对比算法及本文算法在这些场景上的融合结果如图9所示。整体来看,GTF和FusionGAN通过保留红外图像的像素强度来凸显热目标,但是其融合图像未能保留可见光图像的丰富纹理信息,导致融合图像的边缘模糊。相比之下,FPDE、VSM-WLS、DenseFuse和MDLatLRR基本保留了来自两幅源图像中的信息,但融合图像对比度较低,热目标不易识别。在所有结果中,本文方法生成的融合结果具有最高的对比度和丰富的纹理,因此更容易抓住人眼的注意力,在所有方法中呈现出最优的视觉效果。
从不同场景的结果来看,本文方法的融合具有以下3个特征:1)本文方法可以更清晰地凸显热目标。如第1列和第2列的结果所示,在本文结果中,热目标与背景间具有最高的对比度,在整幅图像的复杂场景中,人眼更容易根据这种强烈的对比捕捉到热目标。即使在背景较亮的情况下(如第2列所示),热目标在本文的融合结果中依旧清晰可辨。相反地,若可见光图像中存在欠曝光区域而红外图像能捕捉到对应区域的热辐射信息(如第1列和第3列所示),本文的融合结果能将两幅源图像中的信息更好地融合,更清晰地呈现出欠曝光区域的场景信息。2)本文方法结果呈现出更丰富的场景信息和更清晰的边缘。如第3列和第4列结果所示,本文方法的结果对源图像中场景的信息进行了增强。在一些对比方法中,可见光图像中信息的引入削弱了红外图像中的场景信息,导致融合图像的场景或者边缘模糊。在另一些对比方法中,红外图像的场景信息被尽可能多地保留,但是低对比度的场景信息仍不利于人眼的观察。本文结果不仅保留了原始场景信息,也对场景信息进行了增强。3)在一些极端情况,本文方法的结果依旧表现出更多的信息量。如第5列所示,当可见光图像中存在过曝区域时,在所有对比算法中,红外图像对应区域的信息在融合结果均未得到保留。相比之下,本文方法在过曝这种极端情况下仍可以保留更多的场景信息。如第6列所示,当红外图像与可见光图像像素强度相反时,这种情况极易造成场景信息的丢失。而本文方法在这种情况下可以较多地保留场景中的信息,避免像素强度相反带来的影响。

图9 本文算法和6种对比算法在6组红外可见光图像对上的定性实验结果图Fig.9 Qualitative experimental results of the proposed method and six competitors on six infrared and visible image pairs((a) infrared images; (b) visible images; (c) GTF; (d) FPDE; (e) VSM-WLS; (f) DenseFuse; (g) FusionGAN; (h) MDLatLRR; (i) ours)
3.3 图像融合评价指标及定量结果分析
其中,EN测量信息量,Std衡量对比度,EI反映边缘点的梯度幅值,SCD衡量融合图像与一幅源图像之差和另一幅源图像之间的相关性,MI度量从源图像传输到融合图像的信息量,CC测量融合图像与源图像间的线性相关性。以上指标值越大,融合性能越佳。
本文选取了RoadScene数据集中的30幅红外与可见光图像对构成测试集,测量融合算法在30对测试图像和6种融合指标上的定量结果,统计分布如图10所示。图中,红色线表示中位数,蓝色的上下边界分别表示上四分位数(75%值)和下四分位数(25%值),黑色上下边界为数据的最大值和最小值,“+”表示离群点。在EN、Std、SCD和MI上,本文方法表现最优,虽然在Std上的最大值低于GTF,但是用整体分布来看,所提方法比GTF具有更高的标准差,即更强的对比度。尽管本文结果在MI上的最大值低于VSM-WLS,但是最小值、下四分位数、中位数以及上四分位数均表现更优。
具体来说,在EN上最优的结果说明本文的融合结果包含更多的信息量。本文方法在Std上最优的结果说明本文的结果表现出最高的对比度,能呈现出最符合人眼感知的视觉效果。本文方法在MI和SCD上最优的结果说明源图像中的信息在本文的融合图像中得到了最多的保留,并且融合中引入的伪信息最少。这些结论与定性结果一致。在EI和CC上,本文方法表现出具有竞争力的融合性能。在EI上,本文结果次于VSM-WLS和MDLatLRR,由于本文注重提高融合图像的对比度以提升视觉效果,这造成了背景信息中部分纹理的削弱,导致本文结果在边缘强度上略低。但相比于其他对比算法,本文结果依旧包含较多的边缘,纹理较为丰富。此外,由于本文融合结果对源图像中的对比度进行了增强,而CC通过像素强度及其均值来衡量融合图像与源图像间的相关性,因此本文方法并未在几种统计值上均达到最优,但是仍达到了最高的下四分位数和最小值。这说明本文的结果和源图像间保持了较高的线性相关性。
3.4 在RGB输入上的定性结果
验证本文方法对RGB可见光图像和单通道红外图像的融合性能。由于网络在单通道红外与可见光图像上训练,在输入为RGB可见光图像时,RGB图像首先被转换到YCbCr颜色空间。其中,Y通道为亮度通道,Cb和Cr通道为色度通道。由于结构信息通常存在于亮度通道且红外图像不包含色度信息,因此本文将可见光图像的Y通道与红外图像融合。融合后的图像作为融合图像的Y通道,和原始可见光图像的Cb和Cr通道沿通道维度拼接,转换回RGB颜色空间,得到最终的融合图像。本节同样以RoadScene数据集中的图像作为测试数据,融合的定性结果如图11所示,融合结果基本上保留了可见光图像中的色度信息,同时融入了红外图像中的热辐射信息,使得场景的纹理信息更加丰富,增强了可见光图像中的细节。

图10 本文算法和6种对比算法在6种评估指标上的定量实验结果Fig.10 Quantitative results of the proposed method and six competitors on the six evaluation metrics ((a) EN; (b) Std; (c) EI; (d) SCD; (e) MI; (f) CC)

图11 本文算法对RGB可见光图像和红外图像的融合结果Fig.11 Qualitative fusion results of the proposed method for RGB visible images and single-channel infrared images ((a) RGB visible images; (b) infrared images; (c) fusion results)
3.5 消融实验
本文提出了特有信息分离以分离出源图像的共有和特有信息,然后在特有信息上学习通道级质量引导的融合策略。为了验证在特有信息分离基础上设计的质量引导融合策略的有效性,将本文方法的结果与4种常用融合策略的结果进行定性和定量比较。4种常用融合策略包括mean、max、addition和l1-norm(Li 和Wu,2019)。假设从红外与可见光图像中提取的待融合特征分别为A和B,若采用mean融合策略,则融合后的特征为(A+B)/2;若采用addition融合策略,则融合后的特征为A+B。
在4组图像对上的定性融合结果如图12所示。addition融合策略由于直接将两种特有信息特征图相加,使得融合后的特有信息超出了原始的范围,导致融合结果的像素强度超出范围被截断,信息丢失严重。mean和l1-norm的融合结果较接近,基本上保留了源图像中的信息,然而由于缺乏对特有信息的分析及测重,结果对比度较低。max策略和本文方法的融合结果表现出更高的对比度,呈现出更优的视觉效果。在max策略的融合结果中,对于可见光图像中过曝或像素强度较高的区域,融合结果倾向于保留可见光图像中的信息,这造成了红外图像中的信息在融合结果中的丢失。相比较之下,本文方法所生成的融合图像能够尽可能保留红外图像的信息,避免红外图像信息在融合结果中的丢失。

图12 本文方法和4种常用融合策略在4组红外可见光图像对上的定性实验结果图Fig.12 Qualitative experimental results of the proposed method and four common fusion strategies on four infrared and visible image pairs ((a) visible images; (b) infrared images; (c) mean fusion strategy; (d) max fusion strategy; (e) addition fusion strategy; (f) l1-norm fusion strategy; (g) ours)
此外,mean、max和addition策略均是特征图的像素级融合,而本文方法为了保证场景的一致性,采用的是特征图的通道级融合。本文算法能在自由度更低的情况下保留更多的场景信息,呈现出更优的视觉效果,这也说明了本文方法的有效性。
同样地,定量评估使用3.3节所述的6种指标对几种融合策略的融合结果进行测试。定量评估的统计结果如图13所示。如定量结果所示,addition策略的融合结果由于存在严重的信息丢失,因此与两幅源图像的相关性最低。此外,由于融合图像本身的场景信息或纹理细节较少,融合结果的熵和标准差较低。因此在各种指标中,addition策略的融合结果融合性能较差。在其他几种融合策略中,在几种指标上,max策略和本文方法比mean和l1-norm表现出更优的综合性能。与max策略相比,本文方法在EI、SCD和CC等3个指标上表现出更优的性能,说明本文方法的融合结果在边缘点的梯度幅值更高,融合过程引入的伪信息更少,融合结果与源图像间的相关性更高。在其他指标上,max策略比本文方法表现出相当或更优的性能,这也是因为max策略是像素级的融合策略而本文方法是通道级的融合策略,在更高的自由度上融合更易于融合图像获得更高的对比度。在此基础上,本文方法可以使融合图像达到与源图像更高的相关性以及更锐化的边缘信息,也说明了本文方法的有效性。
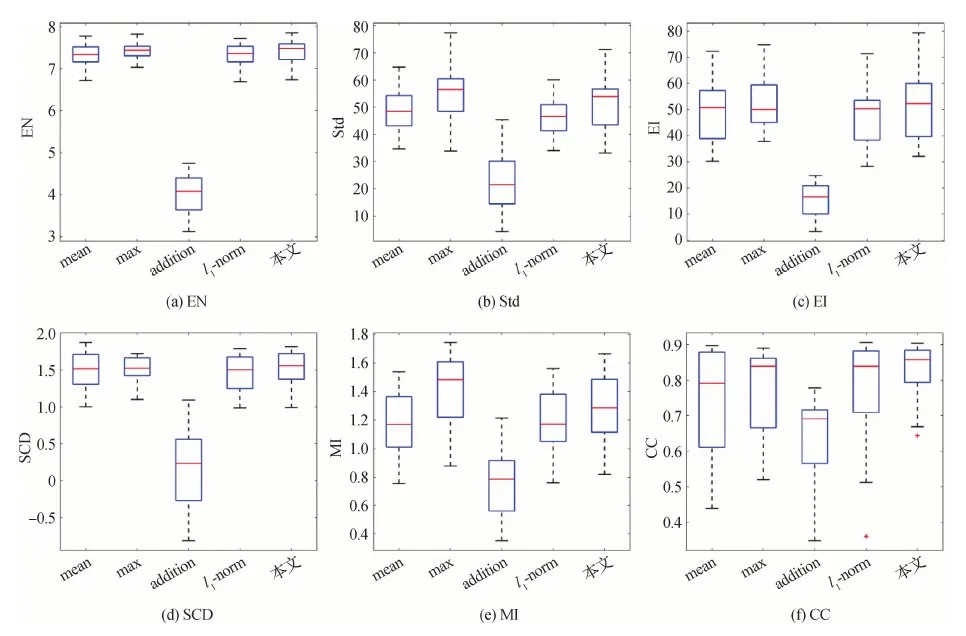
图13 本文算法和4种常用融合策略在6种评估指标上的定量实验结果Fig.13 Quantitative results of the proposed method and four common fusion strategies on the six evaluation metrics((a) EN; (b) Std; (c) EI; (d) SCD; (e) MI; (f) CC)
4 结 论
本文提出了一种新的基于特有信息分离和质量引导融合策略的新的红外与可见光图像融合算法。算法主要包含以下两部分内容。1)本文设计了基于神经网络的特有信息分离以将源图像客观地分解为共有信息和特有信息,对分解出的两部分分别使用特定的融合策略。2)本文设计了权重编码器以学习质量引导的融合策略。权重编码器以分解出的特有信息为输入,以融合图像的客观定量指标为损失函数优化编码器的参数,依据特有信息自适应地生成对应的通道级权重。
在公开数据集RoadScene上的定性和定量结果表明了本文算法的有效性。与领先水平的红外与可见光算法相比,本文的融合结果在对比度更强的前提下,具有更丰富的场景信息,视觉效果的细节更为丰富。此外,由于本文设计了可学习的权重编码器对特有信息进行融合,这种融合方式相较于常用的融合策略可以使融合结果呈现更多的纹理细节且更凸显热目标,与常用融合策略的定性及定量对比结果也证明了本文质量引导融合策略的有效性。
本文方法的不足在于目前的质量衡量未对融合图像的场景结构进行约束,因此仅能自适应地学习通道级融合权重,无法学习像素级融合权重。
目前的实验数据仅限于红外与可见光图像,下一步工作是改进现有的质量衡量标准以学习像素级的融合权重,并使模型具有更强的泛化性,可用于其他多模图像,例如医学图像融合。
