一种基于深度学习的源代码摘要生成模型
2022-11-18祝跃飞
孟 尧,祝跃飞
1(信息工程大学 网络空间安全学院,郑州 450001)2(数学工程与先进计算国家重点实验室,郑州 450001)
1 引 言
为了保持软件运行的稳定性,软件工程师需要花费大量的时间进行软件维护.据文献报道,软件维护的过程最多占据软件开发生命周期的90%[1].作为软件维护的基础步骤,维护人员需要阅读项目的文档和注释,理解现存代码的功能和结构特性.然而,大多数程序员不愿意在软件开发的过程中,同步编写详细的源代码注释.面对海量不规范的代码摘要和注释,人们很难读懂陈旧的源代码的含义[2].在软件工程领域,合格的代码摘要注释应该符合以下3个特点[3]:①正确性.代码摘要必须准确地描述源代码实现的函数功能.②流利性.由于源代码摘要和注释采用自然语言编写,它们必须符合自然语言的语法规范和表达方式,程序开发者和维护者能够轻易地理解摘要的语义.③一致性.在整个项目中,源代码摘要和注释应该遵循统一的格式和标准,方便后期的软件维护人员理解代码.为了快速地产生符合规范的代码摘要,软件工程领域的学者们开始研究代码自动摘要工具,期望将软件开发人员从重复的代码摘要撰写工作中解脱出来,进一步地提高软件开发效率.
早期的代码摘要生成算法大部分都基于传统的自然语言处理技术(NLP),使用人工逻辑编写计算机程序,自动地生成函数或类的相关注释.研究者们主要使用模板匹配、内容选择等常见的信息检索技术(Information Retrieval)生成代码摘要.Giriphrasad等人[1]通过分析源代码的语法特征,构造了若干个模板来生成注释.而Sridhara等人[4]根据自然语言处理中常见的SWUM技术生成提取模板,从源代码的符号序列中抽取关键字组成短摘要信息.经典的摘要生成算法虽然能够快速地生成代码注释,但是过于依赖相关领域专家提供的基于特定编程语言的转换规则,很难被运用于其他语言的程序代码.
随着深度学习技术的兴起,研究者们开始使用各种神经网络模型生成源代码的摘要注释.在自然语言翻译任务中大放异彩的神经机器翻译模型(Neural Machine Translation,NMT),获得了相关领域研究者的广泛关注.一个典型的NMT基于序列结构(seq2seq)搭建,使用事先收集的语料集进行模型的监督训练,最终实现一种自然语言到另外一种自然语言的翻译过程(诸如英语到法语的句子翻译[5]).在软件工程领域,人们尝试使用NMT技术将一种程序的源代码翻译成自然语言组成的代码摘要.由于神经网络强大的特征提取和表述能力,基于深度学习的代码摘要生成技术很快取代了基于信息提取的传统的摘要生成技术.然而,程序语言和自然语言之间的巨大差异使机器翻译中的NMT技术难以直接移植到代码摘要生成的任务中.源代码的编码器无法自动提取程序语言的语法和语义特征,对抽象语法树的遍历也存在着较大的问题.
结合深度神经网络技术和注意力机制,本文提出了一个基于监督学习的源代码摘要生成型At-ComGen.该模型使用NMT框架,由源代码编码器和摘要生成解码器组合搭建.At-ComGen模型首先使用混合编码器将源代码函数映射为高维空间的向量表示,再通过与之相连的循环神经网络(RNN)解码器将代码向量输出为若干词汇组成的摘要信息.为了保持源代码丰富的结构特征,At-ComGen在编码过程中使用两个独立的RNN编码器分别提取代码的词汇特征和语法特征.而在解码器内部,At-ComGen使用BERT预训练模型对摘要词向量进行解码处理.混合注意力机制的使用,使每个输出词汇的向量表示都是所有输入向量的加权求和.通过注意力权重的差异,重点的词汇和语法结构在输出向量中得到了加强.对比实验表明,At-ComGen的性能超过了业内主流的代码摘要生成模型.
本文内容分为7节:第1节介绍了代码摘要生成的背景和本文提出的At-ComGen模型的基本情况.第2节回顾了源代码摘要生成领域内的最近研究成果.第3节介绍了本领域内的相关概念与背景知识.第4节详细介绍了At-ComGen模型的架构和实现细节.在第5节中,通过实验展示了At-ComGen和其他基准模型的性能.第6节基于对比实验的结果,分析了影响At-ComGen模型性能的关键结构.本文结束的节节讨论了此项研究工作的未来方向和发展前景.
2 相关研究
作为软件工程领域内的一项关键任务,有关源代码摘要生成的研究吸引了业内学者的广泛关注.摘要生成模型以源代码函数作为输入,通过内部的编码器和解码器,自动地输出一段用自然语言叙述的文字摘要.根据源代码的处理方式,摘要生成算法通常被分为基于信息提取的传统模式和基于数据训练的神经网络编码模式.
2.1 经典算法
在早期的有关代码摘要的研究中,人们分析特定任务的代码结构,总结代码规律生成相关模板,提取源代码的关键词组合成摘要.基于软件词汇用途模型技术SWUM,Sridhara等人[4]利用人工规则从Java类中提取函数名等关键词汇构成代码摘要.他们又在后续的研究中尝试使用不同的模板提高生成摘要的准确度.学者Moreno等人[6]预先定义了若干条启发性的规则.他们的模型能够根据规则从Java类中提取相关信息组成代码注释.这类方法的关键是使用人工定义的模板直接从源代码段中抽取关键词汇,组成符合自然语言语法规则的摘要注释.
信息提取技术在代码摘要生成领域中也得到了广泛的应用.研究者们[7,8]使用了诸如向量空间模型(VSM)和潜在语义索引(LSI)等信息提取领域中常见的技术,提取输入代码片段的关键词汇,生成相关摘要.由于功能相似的代码段通常拥有相似的代码摘要描述,部分专家尝试使用代码克隆检测的算法在目标库搜索输入代码段的相似代码,然后将克隆代码段的摘要复制给目标代码.学者Wong等人[9]提出的AutoComment模型,使用已知的代码克隆技术搜索相似代码的相关注释,合成目标代码段的摘要.
2.2 神经网络算法
随着深度学习技术的兴起,人们尝试在各个领域内使用深度神经网络搭建模型,解决原有的难题.软件工程领域的研究者们积极地引入多层感知机、循环神经网络、卷积神经网络等常见的深度学习模型[10-12],对源代码进行向量表征.他们精心地收集各类数据构造相关领域的语料库,通过监督或非监督训练的方式更新神经网络模型的参数,提高模型精度.与传统的基于信息提取技术或者经典机器学习技术实现的源代码编码器相比,深度神经网络编码器能够更加精确地提取到代码内部的结构和语义特征.
学者Iyer等人[13]首先将NMT技术引入了代码摘要的研究领域.他们结合LSTM神经网络和注意力机制,搭建了一个基于编码器-解码器架构的摘要生成模型.在数据预处理阶段,他们将源代码看成纯文档(plain text),利用常见的NLP技术将源代码转化成词汇向量的集合.词汇向量被顺序地输入到模型的编码器中,通过LSTM神经网络取得源代码的最终向量表述.在生成摘要的阶段,模型的解码器利用源代码的向量表述,依次输出对应摘要的每个词汇.Iyer等人使用循环神经网络的技术分别实现了摘要生成模型的编码器和解码器.而Allamanies等人[14]使用卷积神经网络的结束,实现了生成模型的编码器.利用卷积核能够逐层提取特征的性质,他们的模型能够自动地抽取源代码片段的核心词汇,进而预测函数的变量名称.
与传统的自然语言相比,程序设计语言包含人工设计的复杂结构.人们利用经典的信息提取算法,很难得到隐藏在代码内部的结构和语义特征.近年来,研究者们先后尝试了基于词汇特征、语法结构以及语义结构的编码算法分析源代码片段,生成相关的摘要和注释.学者Hu等人提出了基于编码器-解码器结构的著名摘要生成模型DeepCom,该模型通过对抽象语法树的特殊遍历算法得到富含结构特征的代码向量,然后使用基于LSTM神经网络的解码器将生成的代码向量解码为自然语言摘要.他们发明了一种特殊的结构化遍历算法(SBT),能够无损地将二维的抽象语法树转化为树节点的一维序列.DeepCom模型的编码器基于标准的LSTM神经网络搭建,在编码过程中能够提取树节点的顺序信息.
为了克服监督训练导致的曝光偏差(exposure bias)问题,Wan等人[3]创新地使用了强化学习的技术训练摘要生成模型.他们首先使用编码器-解码器框架搭建摘要生成模型,然后使用强化学习中的AC模式(actor-critic)对生成模型进行参数训练,也取得了较好的效果.
在2018年提出的预训练语言模型BERT[15],完全改变了词嵌入技术的发展方向.人们提出各种基于BERT的预训练模型,在NLP相关的各项研究中取得了突破性的进展.研究人员Kanade等人[16]率先将预训练的BERT模型引入到源代码的向量化过程中,取得了良好的成绩.他们通过实验得出结论:基于BERT预训练技术的搜索模型在性能上同时超过了基于LSTM和word2vec词向量[17]技术的常规模型和基于transformer架构的新型模型.
3 预备知识
3.1 长短时记忆门结构(LSTM)
为了解决传统的循环神经网络(RNN)中的梯度消失的问题,学者Hochreiter和Schmidhuber在1997年提出了长短时记忆门结构(LSTM)[18].LSTM模型的具体结构如图1所示,它的核心记忆单元由3个门控制器组成,包括一个记忆单元Ct、一个输出门it、一个输出门ot和一个遗忘门ft.在原始的RNN的基础上,LSTM借助门控单元丢弃某些历史时刻的无意义信息,避免了系统因梯度消失的问题导致训练失败,有效地解决了长期依赖问题.

图1 LSTM的基本机构图
LSTM神经网络的计算过程参见公式(1)-公式(5),其中Wi和bi是输入门的权重矩阵和偏置向量,Wf和bf是遗忘门的权重矩阵和偏置向量,Wo和bo是输入门的权重矩阵和偏置向量,σ和tanh是模型的激活函数.LSTM神经网络的模型参数通过监督训练求解.
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
Ct=ft×Ct-1+it×tanh(Wf·[ht-1,xt]+bc)
(3)
ot=σ(Wo·[ht-1,xt]+bo)
(4)
ht=ot·tanh(Ct)
(5)
3.2 带注意力机制的神经机器翻译模型
近年来提出的神经机器翻译模型(NMT)是一种基于序列到序列(Seq2Seq)理论搭建而成的编码器-解码器模型框架.NMT理论最初由Bahdanau[5]等人提出,经过其他的研究者[19,20]不断地改进和完善.本节对NMT模型进行基本描述,建议希望进一步了解NMT的读者参阅相关的文献.
根据序列到序列(sequence to sequence)学习的理论,NMT模型包括独立的编码器和解码器,编码器的输出端连接着解码器的输入端.为了处理序列数据,编码器和解码器通常使用诸如LSTM、GRU等常见的循环神经网络架构实现.NMT的工作流程如下所示:模型将预处理后的源数据片段(token1,token2,…,tokenN)依次输入到编码器的循环结构,得到隐层向量序列(h1,h2,…,hN);解码器结构再将编码器输出的(h1,h2,…,hN)输入到另外的循环神经网络进行解码,最终通过softmax函数依次计算预测词汇的概率分布.本文提出的At-ComGen模型就是基于NMT框架搭建而成的,模型的详细结构在第4节进行说明.
4 基于混合注意力机制的摘要生成模型
本节详细介绍At-ComGen模型的架构.使用基于混合注意力机制的编码器-解码器框架,At-ComGen能够充分地提取源代码片段的词汇和语法特征,输出符合自然语言规范的代码摘要.图2所示的是At-ComGen模型的整体架构.
4.1 模型整体框架
如图2所示,At-ComGen模型由编码器和解码器两个部分组成.作为模型的核心,源代码编码器部件使用两个独立的LSTM神经网络分别搭建词汇编码器(Lexical Encoder)和结构编码器(Syntactical Encoder),将源代码片段映射到统一的向量空间.而解码器(Decoder)基于混合的注意力机制将两个编码器的输出向量序列进行混合解码,生成源代码函数的摘要.
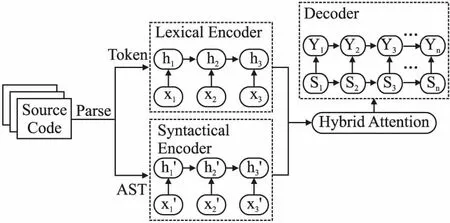
图2 At-ComGen模型的整体架构图
At-ComGen模型的工作流程主要包括两个阶段:离线模型训练和在线摘要生成.在离线模型训练阶段,At-ComGen模型首先将离线训练集合中的标签数据进行预处理,分别提取出当前源代码片段的词汇序列和抽象语法树的节点序列;然后将处理后的数据序列依次输入摘要生成模型进行监督训练,得到解码器和编码器模型的正确参数.在模型的在线摘要生成阶段,At-ComGen模型将待生成摘要的源代码函数输入编码器,并从解码器中输出基于自然语言的目标摘要.模型的详细设计见下.
4.2 源代码编码器结构
At-ComGen模型的源代码编码器由两个独立的子编码器组成.词汇编码器负责提取源代码函数中的关键词汇信息,而结构编码器负责提取源代码函数中的结构信息.
词汇编码器
源代码的函数体内包含了大量反映函数功能的关键词汇,诸如函数名称、变量名称、枚举类型等.在实际操作过程中,很多程序员直接使用这些重点词汇构成代码摘要.研究者们受此启发,在代码摘要生成模型中广泛设置词汇编码器(lexical encoder),对函数内部的重点词汇(token)进行编码.早期的摘要生成模型主要关注于源代码中的重点词汇的提取和预处理过程[13].本文的代码摘要模型使用一个标准的LSTM神经网络实现词汇编码器,其输入为预处理后的词汇向量序列.假设经过预处理后,源代码函数生成的输入向量序列为X=x1,x2,…,xn.在某个时间节点t,词汇编码器输入为词汇向量xt,循环结构通过公式(6)更新当前状态的隐层变量ht.
ht=f(ht-1,xt)
(6)
其中f是词汇编码器中的LSTM单元映射,ht-1是上一个时间节点的隐层状态变量.词汇向量序列X经过词汇编码器的循环计算后,得到隐层状态集合h=[h1,h2,…,hn].
在词汇编码器的预处理过程中,系统对源代码中的关键字和操作符等进行过滤,而数字和字符串变量值分别用NUM和STR代替.对于由多个词汇复合组成的函数名、用户自定义变量名和枚举变量等,At-ComGen模型使用以往模型的处理方式[3,21],根据驼峰或者下划线等标识符对复合词汇进行拆分.这些常见的预处理步骤能够有效地降低生成字典语料库的规模.
结构编码器
对比自然语言书写的普通文档,源代码程序蕴含着非常复杂的结构信息.早期的代码摘要生成算法将源程序看成是普通的文档,完全忽略了程序语言的结构特征,无法生成令人满意的摘要.抽象语法树是一种常见的能够完整表达源程序结构信息的数据结构.为了提取输入代码片段的结构特征,At-ComGen的结构编码器首先将源代码表示为抽象语法树,然后使用先根序(pre-order)的遍历方法,从顶向下取得树节点集合的排序,最后将这些节点生成的向量依次输入到另外一个独立的LSTM网络中进行编码.
假设X′=x′1,x′2,…,x′n是模型经过先根序遍历后得到的抽象语法树的节点集合经过向量映射后的特定序列.在某个时间节点t,结构编码器输入为树节点向量x′t,循环结构通过公式(7)当前状态的隐层变量h′t.
h′t=f(h′t-1,x′t)
(7)
其中f是结构编码器中的LSTM单元映射,h′t-1是上一个时间节点的隐层状态变量.抽象语法树经过结构编码器的编码映射,最终形成隐层转态h′=[h′1,h′2,…,h′n].
抽象语法树的遍历顺序决定着在结构编码器中的输入向量的顺序.随着深度学习技术的发展,人们在代码表述领域中提出了大量基于语法树的遍历方法[11,12,22].本文第六节具体讨论基于不同的语法树遍历算法实现的摘要生成模型的性能.实验证明复杂的语法树遍历算法并不能够有效地提高生成摘要的描述能力.At-ComGen的结构编码器使用传统的基于先根序的访问方法,完成语法树从根节点到叶子节点的遍历过程.算法1描述的是先根序遍历算法的实现过程.
算法1.先根序遍历算法
procedurePOT(r) //输入为以r为树根的抽象语法树
//遍历结束后,seq中存放的是所有树节点的特定序列
seq←seq+r//将根节点r存入seq序列中
ifr.hasChildthen
forcinchildsdo
POT(c)
endfor
endif
endprocedure
图3描绘的是使用算法1对抽象语法树进行先根序遍历,生成节点序列的示意图.图4(a)表示的是源代码生成的抽象语法树,图中的圆圈代表树的节点,其中1号节点是树根;

图3 抽象语法树的遍历示意图
而图4(b)表示的是经过先根序遍历后生成的节点序列.
4.3 基于混合注意力机制的解码器
At-ComGen模型的解码器由一个独立的、基于混合注意力机制的LSTM神经网络结构搭建而成,根据编码器的隐层状态向量依次输出每个预测摘要词汇的概率分布.公式(8)定义了解码器预测当前阶段的摘要生成词汇yi的概率分布:
p(yi│y1,y2,…,yi-1)=g(yi-1,si,ci)
(8)
其中g是用来预测生成词汇yi的概率分布的非线性变换,在实践中通常使用神经网络层搭建softmax函数;而si表示解码器当前阶段的隐层输出向量,ci是注意力机制中定义的环境向量,其计算方式参见下文.在At-ComGen模型中,解码器生成的当前阶段的词汇输出概率是由上个阶段的预测词汇输出、当前阶段的隐层状态变量和注意力机制中定义的环境向量共同决定的.
在自然语言处理领域,注意力机制(attention)能够使模型专注于核心词汇和重点语句的处理过程.通过环境变量(Context Vector)的设置,解码器模型能够使用编码器模型全部的隐层向量预测当前阶段的词汇概率分布.Bahdanau等人[5]率先将注意机制应用于机器翻译领域内,使用注意力权重值的差异突出了重点词汇在译文中的贡献,取得了很好的效果.
如图2所示,At-ComGen模型的编码器使用两个独立的LSTM子编码器分别处理源代码词汇和语法树结构.与经典的NMT模型不同,At-ComGen模型的解码器需要同时从两个LSTM子编码器中提取有用信息完成编码过程.为了使词汇编码器和结构编码器中的核心词汇向量都能够得到加强,At-ComGen模型使用了混合注意力机制,基于两个子编码器的隐层输出构造环境向量,其计算过程如下:
公式(9)定义的是基于混合注意力机制实现的解码器的环境向量ci的计算方法,它是词汇编码器和结构编码器的隐层输出向量与注意力权重系数的加权和:
(9)
其中hj和h′j分别是词汇编码器和结构编码器的隐层状态变量,而αij和α′ij分别是词汇编码器和结构编码器的注意力系数,它们的计算方式参见公式(10)和公式(12).
公式(10)定义了词汇编码器的隐层状态向量hj所对应的注意力系数αij的计算方法.公式(11)表示的是词汇编码器状态向量hj和解码器状态向量si-1的对齐程度eij的计算方法,其中α是注意力机制中的相似度计算函数.
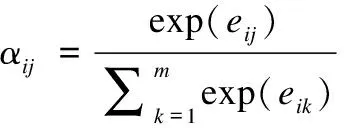
(10)
eij=a(si-1,hj)
(11)
公式(12)定义结构编码器的隐层状态向量h′j所对应的注意力系数α′ij的计算方法.公式(13)表示的是结构编码器状态向量h′j和解码器状态向量si-1的对齐程度e′ij的计算方法,其中a是相同的相似度计算函数.
(12)
e′ij=a(si-1,h′j)
(13)
4.4 损失函数
本文使用常见的最小化的交叉熵定义模型训练的损失函数,如公式(16)所示[21]:
(16)

5 实验与分析
5.1 对比模型
为了全面评估At-ComGen模型的性能,本文选择业内有代表性的几个摘要生成模型进行对比实验,其中包括基于注意力机制的CODE-NN模型[13],基于代码结构解析的DeepCom模型[21],基于强化训练的摘要生成模型等.下面简要介绍这几种对比模型的结构.
第1个对比模型是经典的CODE-NN模型[13].该模型直接使用循环神经网络结构搭建了一个端到端的摘要生成系统,根据源代码的词向量生成相关摘要.注意力机制的引入不但突出了重点词汇在解码过程中的贡献,而且解决了过长代码生成的摘要难以满足需要的问题.本文对原始的CODE-NN模型进行了必要的修改,使原来处理C#和SQL的模型编码器能够适用于JAVA数据集.
第2个对比模型是基于序列到序列学习算法(Seq2Seq)实现的代码摘要生成模型.该模型的编码器和解码器分别使用独立的LSTM神经网络搭建,能够提取源代码的词汇特征生成摘要.该模型输入源代码函数的重点词汇序列,输出该函数相关的英文摘要.
第3个对比模型是DeepCom模型.为了提取源代码中隐藏的结构信息,DeepCom首先通过特殊的遍历算法将抽象语法树输出为特定顺序的节点序列,再使用经典的编码器-解码器模型生成目标代码的摘要.作者认为DeepCom使用的遍历算法能够无损地表达抽象语法树的结构特征,生成的摘要也能准确地描述源代码的功能特性.
第4个对比模型是wan等人近期提出的基于actor-critic模式进行参数训练的强化学习模型.与业内常见的代码摘要生成模型不同,作者创新性地使用了强化学习的方式更新模型参数,能够进一步地降低曝光误差(exposure bias).作者通过对比实验证明,他们提出的强化学习模型的性能超过了以往所有的基线模型.
5.2 数据集描述
由于代码摘要生成领域内可供使用的标签数据十分稀少,本文使用论文[21]中构造的Java数据集进行对比实验.数据集的作者在GitHub中大量收集的带有注释的Java函数段,使用函数注释的首句作为相关代码段的摘要标签.
如表1所示,本文使用的Java数据集包含超过58万条带摘要的函数片段,按照大约8∶1∶1的比例划分实验使用的数据集、验证集和测试集合.表2描述了Java代码函数的长度统计信息,而表3描述了标签摘要的长度统计信息.源代码和标签摘要的平均长度分别是99.94和8.86行,源代码的长度远大于标签摘要的长度.超过95%的代码摘要的长度少于50个单词,而超过90%的Java源代码的长度少于200个词汇.

表1 Java数据集的统计信息

表2 Java函数的长度统计

表3 Java函数注释的长度统计
5.3 数据预处理与环境设置
在进行数据预处理的过程中,编码器模型首先使用javalang(1)https//github.com/c2nes/javalang和NLTK等工具将源代码和相关摘要拆分成小词汇(token),然后将词汇进行小写化处理,数字和字符串分别用
为了方便计算,At-ComGen模型设置词汇编码器中的LSTM循环体长度最大为300.系统对预处理后低于300词的代码序列添加
本文中的实验使用16核心CPU的Intel服务器,基于CUDA9.0的GPU加速,训练深度学习模型的参数.服务器总共花费了大约95个小时,对At-ComGen模型进行了50轮的监督训练.At-ComGen模型使用机器学习框架Tensorflow搭建,设置词向量和LSTM隐层状态为768维.监督训练使用随机梯度下降(SGD)算法优化模型参数,设置Batch_size为64,使用Adam优化器并设置学习率为0.05.为了防止模型参数过拟合,模型设置dropout值为0.5.
5.4 结果与分析
对比实验使用了自然语言处理领域内常见的BLEU,METEOR和ROUGE-L度量值,评价各种模型生成的摘要和参考摘要之间的相似度.为了防止N-gram取0导致的对数趋于负无穷的情况出现,对比实验中的BLEU参数使用NLTK工具包提供的平滑修正的方法.表4显示了At-ComGen模型和CODE-NN,Seq2Seq模型、DeepCom模型和强化学习模型的实验数据.对比结果表明At-ComGen模型生成摘要的性能,在3种评价指标中均领先于其他的基线模型.

表4 摘要生成模型的对比实验结果
CODE-NN模型没有使用语言模型,而是通过端对端的循环神经网络系统直接从源代码中提取词汇信息生成相关的摘要.在所有参加实验的模型中,CODE-NN模型生成的摘要质量最差,BLEU测量值只有27.89%.而Seq2Seq模型忽略了代码的结构特性,也没有使用注意力机制突出重点词汇的作用,生成摘要的质量也不够理想.DeepCom模型在对源代码的编码过程中,通过抽象语法树的遍历算法提取了部分的结构特征,生成摘要的准确性也得到进一步提高.而近期提出的强化学习模型放弃了传统的监督学习的方式,使用了强化学习对模型进行训练,进一步降低模型的曝光误差.在所有的模型中,强化学习模型的性能仅次于本文提出的At-ComGen模型.At-ComGen模型不但在编码器中融合了两个独立的LSTM神经网络结构,同步提取源代码的词汇特征和结构特征,而且在解码器中还创新地引入BERT预训练模型对摘要词汇进行编码和解码.由于出色的摘要生成性能,At-ComGen已经成为代码摘要生成领域中新的基线模型.
在2018年前后,谷歌提出的transformer架构[19]和随后产生的BERT预训练模型,在文本处理、文本阅读、情感分类等任务中取得了突破性的进展.自然语言处理领域的研究者们纷纷使用BERT预训练模型进行单词映射编码.受此启发,本文在搭建At-ComGen模型的过程中,也尝试使用BERT预训练模型对摘要词汇进行向量映射.通过在相同数据集上的对比实验,讨论不同的词向量映射技术对代码摘要生成模型产生的影响.
基于At-ComGen模型的基本框架,本节使用不同的词向量映射技术搭建了3种模型进行对比实验.模型1是基础版本的At-ComGen,它使用Word2vec技术对源代码中提取的词汇和语法树节点进行词向量映射,使用谷歌提供的“BERT-Base,Uncased”预训练模型对代码摘要进行词向量映射.模型2使用了Word2vec技术对源代码词汇、语法树节点和代码摘要进行词向量映射,源代码和生成摘要使用不同的语料字典.模型3使用谷歌提供的“BERT-Base,Uncased”预训练模型对源代码词汇、语法树节点和代码摘要进行词向量的映射.3种模型在Java测试集上生成摘要的性能对比如图4所示.
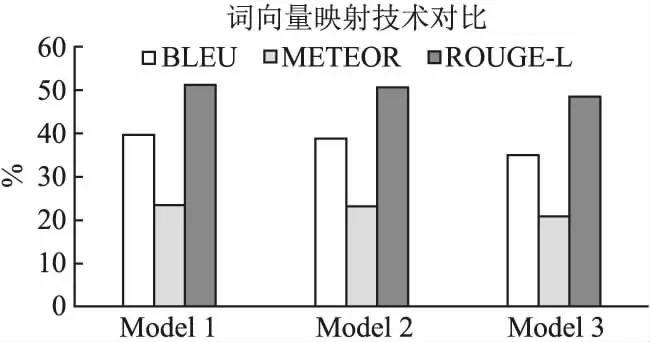
图4 基于不同的抽象语法树遍历算法实现的摘要模型的对比实验
图4显示了模型1(At-ComGen模型)生成的摘要在BELU,METEOR和ROUGE-L等评价参数上领先于其它两个模型.模型2使用了相对陈旧的Word2vec技术,无法动态地表述摘要词向量之间的关系,在模型性能上稍逊一筹.而令人意外的是全面使用BERT预训练技术的模型3,竟然在生成摘要的质量上落后于前两个模型.本文认为模型3性能较差的原因是由于源代码中出现的某些词汇,特别是抽象语法树的内部节点诸如InfixExpression,SimpleName等都是罕见的复合词汇.由于不属于自然语言中的常用词,这些复合词汇无法根据谷歌提供的预训练模型的字典进行词向量映射.而模型2在使用Word2vec进行词向量映射之前,会根据所有产生的词汇生成语料字典,而Word2vec能够根据包含高频罕见词汇的语料字典生成相关词汇的向量表示.代码摘要中出现的都是常见的自然语言词汇,它们大都包含在谷歌的预处理模型的字典中,因此针对代码摘要能够直接使用BERT预训练模型进行正常地转码.
受计算机硬件性能的限制,At-ComGen模型目前无法利用自己的语料库从头训练BERT模型.笔者希望未来能够解决算力问题,训练一个适用于源代码的BERT模型,使At-ComGen能够同时在编码器和解码器内使用BERT进行词向量映射.
为了充分地提取源代码中的结构特征,人们在以代码表述为基础的研究中,先后提出了若干种基于抽象语法树的遍历算法[10,12,14,21].为了研究各种抽象语法树遍历算法的影响,本节接着设计对比实验:在原有的At-ComGen模型框架上,分别使用树形LSTM神经网络(Tree-LSTM)[23],结构遍历(SBT)和先根序遍历(pre-order)算法实现模型的结构编码器.实验结果如图5所示,实验结果表明复杂的抽象语法树遍历算法并不能够提高模型生成摘要的质量.基于Tree-LSTM神经网络实现的结构编码器,反而略微降低了生成摘要的性能.某些抽象语法树的层次过多可能是产生这种现象的原因.为了更新Tree-LSTM网络的模型参数,编码器首先需要将原始的多分支语法树转化为普通的二叉树.复杂的转化操作会加深语法树的层次,加剧模型训练的困难,造成模型可能的性能下降.而基于SBT算法实现的编码器模型,和基于先根序算法实现的模型在生成摘要的质量上并无明显差距.考虑到算法的实现难易程度和时间复杂度,At-ComGen模型在编码过程中使用了简单的先根序遍历算法.

图5 基于不同词向量映射算法实现的摘要模型的对比实验
6 结 论
本文针对源代码摘要的生成任务,提出了一种基于注意力机制的深度代码摘要生成模型At-ComGen.该模型基于神经机器翻译(NMT)架构搭建,将输入的源代码转化成用自然语言描述的代码摘要.与其他基线模型相比,At-ComGen拥有以下优势:1)在编码过程中同时使用基于词汇的编码器和基于结构的编码器,更加全面地提取源代码特征;2)混合注意力机制的使用,使代码中的核心词汇和重要语法节点在代码表述的过程中得到进一步地加强;3)在对代码结构进行预处理的过程中,语法树叶子节点的特殊处理可以大大减少生成语料库的规模和“UNK”的出现次数;4)在解码器中使用BERT预训练模型对代码摘要词汇进行向量化,明显地提高了生成摘要的表达能力.
通过迁移学习,本文提出的代码表述算法能够运用在软件工程的许多领域内,诸如代码搜索、代码克隆、代码补全等.未来版本的At-ComGen模型计划从源代码和语法树中提取词汇构成全新的语料库,使用自身训练的BERT模型进行词汇向量化,进一步提高生成摘要的描述能力.
