基于优化信息融合策略的关系抽取
2022-11-18周煜坤赵容梅琚生根
周煜坤,陈 渝,赵容梅,琚生根
1(四川大学 计算机学院,成都 610065)2(四川民族学院 理工学院,四川 康定 626001)
1 引 言
关系抽取任务的目标是从文本中抽取出两个目标实体之间存在的语义关系,是信息抽取领域的一项子任务.准确地从非结构化文本中提取语义关系对于许多自然语言应用具有十分重要的意义,如信息抽取[1,2]、自动问答[3,4]、机器翻译[5]、知识图谱[6]等.关系抽取方法主要分为两类:有监督方法和远程监督方法.本文重点研究有监督学习的关系抽取方法.
近年来,随着深度学习的快速发展,最新的有监督关系抽取研究主要集中于深度神经网络模型.这些模型解决关系抽取任务的方法大体上可以归纳为以下步骤:
1)从编码器中获得目标句子的词嵌入信息,例如,word2vec[7]词向量,glove[8]词向量,以及预训练语言模型BERT[9]词向量等;
2)使用深度神经网络,如循环神经网络RNN[10,11]、卷积神经网络CNN[12,13]、图神经网络GNN[14,15]、预训练语言模型[16-20]等对整个句子的词嵌入进行编码,以捕捉上下文信息作为全局特征,同时添加目标实体信息作为局部特征,最终生成一个固定维度的向量作为关系表示;
3)将编码获得的关系表示作为分类器(如softmax分类器)的输入,在标记训练集上进行训练.
但是,这些方法通常存在以下缺陷:以往的大量研究仅仅对从编码器中获得的信息(句向量、实体向量等)进行简单的拼接以作为关系表示,这意味着默认每种信息将在关系抽取中扮演同等重要的角色.但实际上,在不同句子中,每种信息的重要性有很大的差异,这样的方法限制了模型的性能.
本文以2019年的R-BERT模型[16]为例,从两个方面讨论这个问题.R-BERT模型是最早将BERT预训练语言模型用于关系抽取的模型之一,它将句子的[CLS]标记所对应的句向量以及两目标实体的隐向量三者连接构成关系表示进行分类,在Semeval2010 Task8数据集上的F1值为89.25,取得了state-of-the-art的效果.
首先,句向量代表了输入序列的全局特征,聚焦于整个句子,而实体向量则是一种局部特征,聚焦于目标实体.从经验上来看,二者均是关系抽取任务中的关键因素:在不同的句子中,受到复杂语境的影响,有时全局特征起决定性影响,有时则是局部特征占据主导地位.因此,将句向量以及实体向量连接的方法忽略了二者在关系抽取中的不同贡献.
其次,从直觉上来看,将两个实体向量连接的方法有一定的合理性,因为二者作为局部信息,在关系抽取任务中扮演着同样的角色.但实际上,由于复杂的语境变化及两个实体的语义、位置、主宾关系等隐含信息的不同,二者在关系抽取中的贡献往往也是不同的.
从BERT预训练语言模型的角度来看,关系抽取是一项分类任务,在不添加外部知识和人工设计、不使用外部NLP工具的情况下,其重点在于如何充分且有效地利用给定句子及目标实体的信息,可以自然地作为BERT模型的下游任务.如上所述,以往的研究常常忽略了各种信息对分类所做出的不同贡献,而是将它们作为同等重要的信息送入分类器,这在一定程度上限制了模型的性能.
因此,本文提出了一种基于优化信息融合策略(Optimized Information Fusion Strategy,OIFS)的关系抽取方法,针对关系抽取任务的特点,为其设计了一个新的BERT下游任务模型,以解决上述问题:
1)考虑到全局特征和局部特征对于关系抽取的不同影响,从BERT模型获得句向量以及实体向量后,将句向量分别融入到两个实体向量中,以融合句子的全局信息和局部信息,获得两个复合特征,它们将类似地在关系抽取中具有不同的贡献程度;
2)随后,采用一种自适应的信息学习策略,根据文本的具体结构和语义信息组合两种复合特征作为最终的关系表示,使得模型自动聚焦于对分类更有价值的部分.最后将关系表示馈送到softmax分类器中进行分类.
本文的主要贡献如下:
1)基于BERT预训练语言模型,为关系抽取任务提出了一种新的下游任务模型框架OIFS,该框架能够恰当地融合输入句子的全局句子特征和局部实体特征,并通过自适应信息学习机制,自动聚焦于对分类贡献更大的信息,解决了以往模型忽略不同特征对分类的不同贡献的缺点;
2)在TACRED、TACREV、Semeval2010 Task8基准数据集上,进行了大量实验,将本文的模型与多个基线系统进行了比较,并进行了一定的可视化分析.实验结果表明,该模型获得了最先进的性能;
3)本文的模型无需复杂的人工设计和外部知识输入,对不同的数据集只涉及微小的改动,方法简练而高效,具备良好的可扩展性和可移植性.
2 相关工作
传统的有监督关系抽取方法主要包括基于模式匹配的方法[21,22]和基于机器学习的方法.基于机器学习的方法又可以分为基于特征向量的方法[23,24]和基于核函数的方法[25,26].这些传统的关系抽取方法高度依赖于人工特征选择和提取,存在着严重的误差传播问题.因此,传统关系抽取方法的性能非常有限.
基于深度学习有监督方法进行关系抽取,能解决经典方法中存在的人工特征选择、特征提取误差传播两大主要问题,取得了良好的效果,是近年来关系抽取的研究热点.
最常见的深度学习关系抽取网络结构包括循环神经网络RNN[10,11]、卷积神经网络CNN[12,13]、图神经网络GNN[14,15],均取得了一定的效果.但是,RNN及其变体在处理长序列时存在梯度消失的问题,且难以并行运算,限制了模型的性能和适用性;CNN所建模的信息往往是局部的,限制了模型处理远程关系的能力.随着深度学习技术的不断发展以及新技术的出现,基于RNN、CNN等的方法由于编码能力的不足,已经不再是关系抽取的主流方法.而基于GNN的方法高度依赖于高效的依存解析器,往往存在着难以解决的误差传播问题,限制了模型的效果.
近年来,预训练语言模型已经被证明可以有效地改善许多自然语言处理任务.其中,由Devlin[9]等人提出的BERT预训练语言模型在11个NLP任务上获得了最新的研究成果,许多学者开始着手使用它来处理关系抽取问题.
2019年,Wu等人[16]首次将BERT预训练模型运用到关系抽取任务中.由于句子的关系类型依赖于目标实体的信息,作者在目标实体前后添加位置标记,一并输入到BERT模型中,将实体嵌入以及句子[CLS]标记嵌入连接并进行分类.该文在SemEval2010 Task8数据集上实现了SOTA的效果,证实了BERT预训练模型对关系抽取任务的有效性.
2019年,Soares等人[17]提出了Matching the blanks的方法来预训练关系抽取模型.作者还测试了BERT的不同的输入和输出方式对关系抽取结果的影响,探讨了如何对包含实体信息的语句进行编码以及如何输出一个固定长度的关系表示更为合理,该模型在SemEval2010 Task8、KBP37、TACRED数据集上均达到了当时的SOTA效果.
2020年,Wang等人[18]基于语言学知识,提出了利用句法框架增强关系分类,将输入的句子分解成句法上更短的块,以获得关系抽取所需的关键信息,将其作为额外特征与实体向量和句向量连接并分类,该文的方法在SemEval2010 Task8数据集上超过了最先进的方法.
2021年,Zhou等人[19]提出了一个改进的关系抽取基线模型,对模型中的实体表示和标签表示问题进行了分析和改进,提出了一种新型的实体表示技术,并基于BERT、RoBERTa预训练模型进行实验和微调,在TACRED数据集上取得了SOTA效果.
2021年,Park等人[20]提出了一种基于课程学习的关系抽取方法,根据数据难度将数据集分成若干组,并允许模型根据难度逐步学习.使用RoBERTa编码句子得到实体向量,再将实体间的上下文送入图注意网络中进行编码得到上下文向量,将二者连接后进行分类,提升了关系抽取的效果.
以上方法往往只是将模型中的不同信息(局向量、实体向量、上下文向量、句法结构特征等)进行简单的拼接构成关系表示,忽略了句子中各种特征对关系抽取的不同影响.2018年,Zhao等人[27]提出了一种自适应的学习方法用于文本分类任务,恰当地融合了局部语义和全局结构信息.受Zhao等人[27]的启发,本文将该方法扩展为融合模型的更多不同特征,并将其用于关系抽取任务:使用预训练语言模型编码句子后,充分考虑多种信息在关系抽取中所发挥的不同作用,恰当地组合各类特征,使模型聚焦于对分类更有帮助的部分,从而提升关系抽取的效果.
3 本文方法
本文提出了一种基于自适应信息融合机制的关系抽取方法.首先,通过BERT网络编码获得目标句子的句向量以及两实体的隐状态表示,并将句向量表示分别融入到两个实体表示中,以获得两种复合特征,融合输入序列的全局信息以及局部信息.随后,采用一种自适应的信息学习策略来确定两种复合特征对关系抽取的重要程度.具体来说,将BERT模型的倒数第2层输出作为句子的上下文特征向量,根据该特征向量赋予两种复合特征适当的概率值,代表它们对分类的贡献程度.最后,根据两个概率值融合两种复合特征作为最终的关系表示,送入softmax分类层进行分类.通过这种方法,使得模型能够恰当地融合全局信息和局部信息,并自动聚焦于对分类贡献更大的部分,获得了更高质量的关系表示,提升了关系抽取的性能.模型整体框架如图1所示.

图1 模型整体框架
3.1 问题描述
关系抽取任务的目标是从一段文本中识别出两个给定实体之间的语义关系.例如,给定文本:“The was composed for a famous Brazilian.”
其中,实体song和实体musician的位置信息分别由指示符,所标示.此外,TACRED和TACREV数据集还额外提供了目标实体的命名实体类型.模型的目标为识别其关系类型:Product-Producer(e1,e2).
3.2 样本预处理
在将样本句子输入到BERT模型编码之前,采用BERT模型的原始设置,在句子S开头添加[CLS]标记,以捕获整个序列的信息,在句子结尾添加一个[SEP]标记作为结束符号.
现有的研究[16,19]已经证明在实体前后添加显式的标记可以显著提高关系抽取模型的性能.本文采取类似的方法为目标实体添加特殊token(图1中的ST).考虑到数据集中关系类型的不同特点,对3个基准数据集的样本采用不同的预处理方法,如图2所示.

图2 样本预处理
对于TACRED和TACREV数据集,沿用Zhou等[19]的设置,在实体1和实体2两侧分别添加位置标记@和#,同时,标记两实体类型并分别用*和^标记位置,从而得到序列T.其中,person是实体Bill的NER类型,city是实体Seattle的NER类型,已由数据集给出.
对于Semeval2010 Task8数据集,在S中的两个目标实体两侧分别添加位置标记[E11]、[E12]和[E21]、[E22]得到序列T.
3.3 BERT编码层
BERT预训练语言模型是一个多层的双向Transformer编码器,基于注意力机制对序列进行编码以充分利用上下文信息.通过微调,BERT能够为广泛的NLP任务输出有效的分布式表示,并取得良好的效果.
首先将序列T送入BERT编码器中进行编码.在BERT模型中,每一个Transformer层均会输出一组对应于输入序列T的隐状态向量.从理论上来讲,每个Transformer层的隐状态向量均可以作为输入序列T的词嵌入,但是,一般来说,越深层次的Transformer隐状态往往越适合用于进行下游任务的微调.因此,首先利用最后一层Transformer的隐向量.
在最后一层Transformer层的输出中,设Hi至Hj对应了实体1的隐状态,Hm至Hn对应了实体2的隐状态,H[CLS]对应了输入序列中[CLS]标记的隐状态.其中,Hi、Hj、Hm、Hn、H[CLS]∈Rh,h为隐状态向量的维度.
对于TACRED和TACREV数据集,取两实体的头部token的隐状态分别作为目标实体的向量表示He1和He2;而对于Semeval2010 Task8数据集,则是使用平均运算得到He1和He2:
(1)
(2)
对于[CLS]标记的隐状态,不对其进行额外的操作,直接将其记为输入序列的句向量H0.即:
H0=H[CLS]
(3)
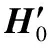
(4)
后续将在3.5节中详细阐述上下文特征向量的作用.
3.4 复合表示的获取
至此,已经获得了输入序列的句向量表示H0∈Rh,以及两个目标实体表示He1、He2∈Rh.其中,句向量表示是融合了整个输入序列信息的全局特征,两实体表示则是与目标实体相关的局部特征,它们是关系抽取任务中起决定性作用的3种信息.为了提升关系抽取的效果,本节考虑如何更恰当地融合3种表示作为最终的分类依据.
从经验上来看,句向量和实体向量在不同的语境下中的作用是不同的:句向量由一个没有明显语义信息的[CLS]符号编码得来,通过注意力机制融合文本中各个token的信息,是原始BERT模型所定义的分类任务的依据.作为一种全局特征,句向量代表了整个句子的语义信息,即“理解”了整个句子;而实体向量则是一种局部特征,往往聚焦于与目标实体更相关的token的语义信息,即“理解”了目标实体.在关系抽取任务中,样本的关系类型由众多复杂的因素决定,除了与目标实体相关外,有时还与某些关键的谓词、介词、文本段甚至整个句子的语义信息有关.为了更好地说明句向量和实体向量的不同作用,在图3中给出了4个例子.在句子S1中,通过实体room和实体house二者以及相关词inside的局部语义特征即可判断其关系类型为Component-Whole(e1,e2)(即部分-整体关系),全局信息的帮助较小;句子S2的情况与S1类似;而在句子S3中,仅凭实体distraction和incident及其局部语义特征不足以准确地判断关系类型Cause-Effect(e1,e2)(即因-果关系),而需要整个句子的全局语义信息作为主导,句子S4的情况与S3类似.

图3 全局特征和局部特征的不同作用
以往的模型往往通过简单的连接操作组合句向量和实体向量,这意味着给予它们以同等的重视程度.本文重新审视了这个问题,并提出了一种新的信息组合方式:
对于句向量表示H0,以及两个目标实体表示He1和He2,采用向量相加运算对其进行信息组合:
H1=He1+H0
(5)
H2=He2+H0
(6)
其中,H1、H2∈Rh.H1、H2融合了句向量表示和目标实体表示,可以看作是一种复合特征.这种方法对全局特征进行了更充分的利用,使得两目标实体所对应的局部特征均与全局特征完成了融合.
3.5 自适应信息学习层
H1、H2作为复合表示,在包含全局特征的同时,还分别携带了不同的实体特征,由于两个目标实体的语义、位置、主宾关系等隐含信息的不同,加之在不同的语境影响下,二者在关系抽取中的贡献程度往往也会呈现出不同大小的差异.因此,应当采用恰当的方法对两种复合特征进行组合.在本实验中,采用一种自适应信息学习策略来确定两种表示对关系抽取的重要程度,并对两种表示进行恰当的融合.
在3.3节中,通过Transformer层的输出得到了上下文特征向量Hs,它是输入序列T在某一层面上的词嵌入,随着输入句子的变化而变化,反映了文本的具体结构和语义信息.因此,本文以Hs为特征向量,为复合特征H1、H2赋予特定的概率值,作为其在关系抽取中的重要程度,从而实现自适应信息融合.
图4描述了自适应信息学习策略的简单架构.根据上下文特征向量Hs,通过线性变换计算两个特征表示S1、S2:
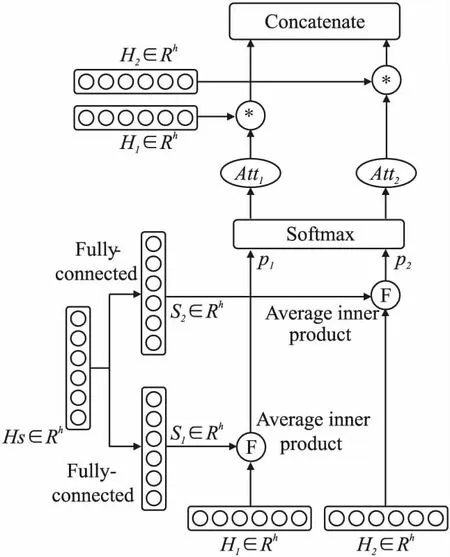
图4 自适应信息学习模块
S1=HS×W1+b1
(7)
S2=HS×W2+b2
(8)
其中,W1、W2∈Rh×h为线性变换矩阵,b1、b2∈Rh,为偏置项.S1、S2∈Rh.随后,通过平均内积运算计算复合表示H1、H2与特征表示S1、S2之间的相似度来为复合表示对关系抽取的贡献程度进行打分,记为权值p1、p2:
p1=ρ(S1,H1)
(9)
p2=ρ(S2,H2)
(10)
最后,使用softmax函数对权值p1、p2进行归一化:
att1,att2=softmax(p1,p2)
(11)
其中,att1、att2是两个归一化权值,分别代表了复合表示H1、H2对关系抽取任务的贡献程度.利用att1、att2对H1、H2进行组合,获得最终的关系表示X:
X=concat(att1×H1,att2×H2)
(12)
其中,X∈R2h.这种自适应的信息学习策略,可以使模型聚焦于对分类更有帮助的部分,更好地完成信息融合,生成更高质量的关系表示.
3.6 模型训练与预测
为了训练模型参数并预测样本类别,将关系表示X送入全连接层和softmax层进行分类:
h=(activation(X×W3+b3))×W4+b4
(13)
(14)
p=softmax(h)
(15)
其中,W3∈R2h×h,W4∈Rh×L,为线性变换矩阵,b3∈Rh,b4∈RL为线性变换的偏置项,L为数据集中关系类型的个数,activation为非线性激活函数ReLU或tanh.h、p∈RL,p中的各个元素代表了样本属于各个关系类型的归一化概率.根据p,可以计算模型损失和预测样本类别:
在模型训练过程中,计算归一化概率p与样本真实类别的one-hot向量之间的交叉熵损失作为损失函数.为了防止模型过拟合,本文在模型中添加一个dropout层,以一定的概率丢弃某些网络值.
在模型的预测阶段,选择归一化概率p中的最大值所对应的类别作为输出:
(16)
4 实 验
本文采用的实验环境配置为:Ubuntu18.04.5操作系统,Titan RTX显卡,编程语言和框架分别为Python3.6和Pytorch1.9.0.
4.1 数据集及评价指标
为了评估模型的性能,本文在公开数据集TACRED[28]、TACREV[29]以及SemEval-2010 Task8[30]上进行了实验.
TACRED数据集是关系抽取任务中最大规模的数据集之一,训练集、验证集、测试集的样例总数分别为68124,22631,15509,共有42个关系类型,其中包含一个无关系类别“no_relation”;TACREV数据集是一个基于原始TACRED数据集构建的数据集:在样本数和关系类型不变的情况下,纠正了TACRED原始开发集和测试集中的错误,而训练集保持不变.SemEval-2010 Task 8数据集是关系抽取任务的一个传统数据集,包含10717个有标记的实例,其中8000个用于训练,2717个用于测试.所有实例标记了一个关系类型,其中包括9个关系类型以及一个其他类“Other”,考虑到关系的方向性,关系类型总数为2*9+1=19种.
对于TACRED和TACREV数据集,采用其官方评价脚本评测模型的Micro-F1值以衡量模型性能;对于Semeval2010 Task8数据集,同样采用其官方评价指标:9个实际关系(不包括Other类)的Macro-F1值来评价模型.
4.2 超参数设置
在本文的实验中,使用RoBERTa-Large[31]配置作为TACRED和TACREV数据集样本的编码器,使用BERT-Large-Uncased[9]配置作为Semeval2010 Task8数据集样本的编码器.在反向传播中,对3种数据集均采用AdamW[32]优化器更新模型参数.在TACRED和TACREV数据集实验中,将dropout层设置在激活函数后;在Semeval2010 Task8数据集实验中,将dropout层设置在He1、He2、H0的获取过程中.实验中的主要超参数取值如表1所示.
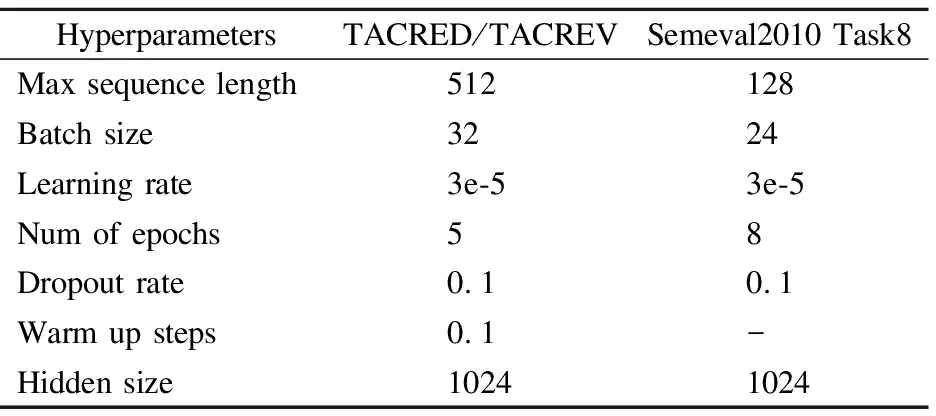
表1 主要超参数取值
4.3 基线模型
为了说明模型的有效性,将本文提出的OIFS模型的实验结果与近年来效果突出的大量主流基线模型的实验结果进行了对比,包括:基于CNN/RNN的方法、基于GNN的方法和基于预训练语言模型的方法:
Attention-CNN[33]:将注意力机制引入卷积神经网络中,以捕获对目标实体影响最大的部分.
PA-LSTM[28]:面向关系抽取任务提出了一种认知位置的神经序列模型,充分结合基于语义相似度和位置的两种attention机制.
C-GCN[14]:将图卷积网络应用到关系抽取任务中,基于依存结构对句子进行编码,并提出了新的修剪策略.
C-MDR-GCN[34]:提出了一种基于多种表征的图神经网络模型,结合多种类型的依赖表示方法,同时引入了可调节的重正化参数γ.
R-BERT[16]:将BERT模型运用到关系抽取任务中,将[CLS]标记的嵌入和两实体嵌入连接作为关系表示进行分类.
KnowBERT[35]:联合训练语言模型和实体链接器,并使用知识注意机制和重上下文化机制,将知识库引入预训练模型,以形成知识增强的实体跨度表示形式.
MTB[17]:提出了Matching the blanks的方法来预训练关系抽取模型,并探讨了如何对包含实体信息的语句进行编码以及如何输出一个固定长度的关系表示更为合理.
Span-BERT[36]:提出了一个新的分词级别的预训练方法,通过使用分词边界的表示来预测被添加Mask的分词的内容.
LUKE[37]:提出了一种专门用于处理与实体相关的任务的上下文表示方法,在大型文本语料库和知识图对模型进行预训练,并提出了一种实体感知的自我注意机制.
ENT-BERT[38]:基于关系分类任务的特点,结合BERT和注意力机制,利用句向量和实体向量进行分类.
EC-BERT[39]:提出了一种结合句子特征向量、目标实体以及实体上下文语句信息的BERT关系抽取方法,在Semeval2010 Task8数据集上表现良好.
Typed entity marker(punct)[19]:提出了一种新型的实体表示技术,并基于BERT、RoBERTa模型进行实验和微调,在TACRED、TACREV数据集上取得了SOTA效果.
4.4 实验结果
OIFS模型与上述基线模型的实验结果对比如表2所示.实验结果显示,本文的模型在TACRED、TACREV、Semeval2010 Task8 3种数据集上分别取得了75.35、83.71、90.16的F1值.
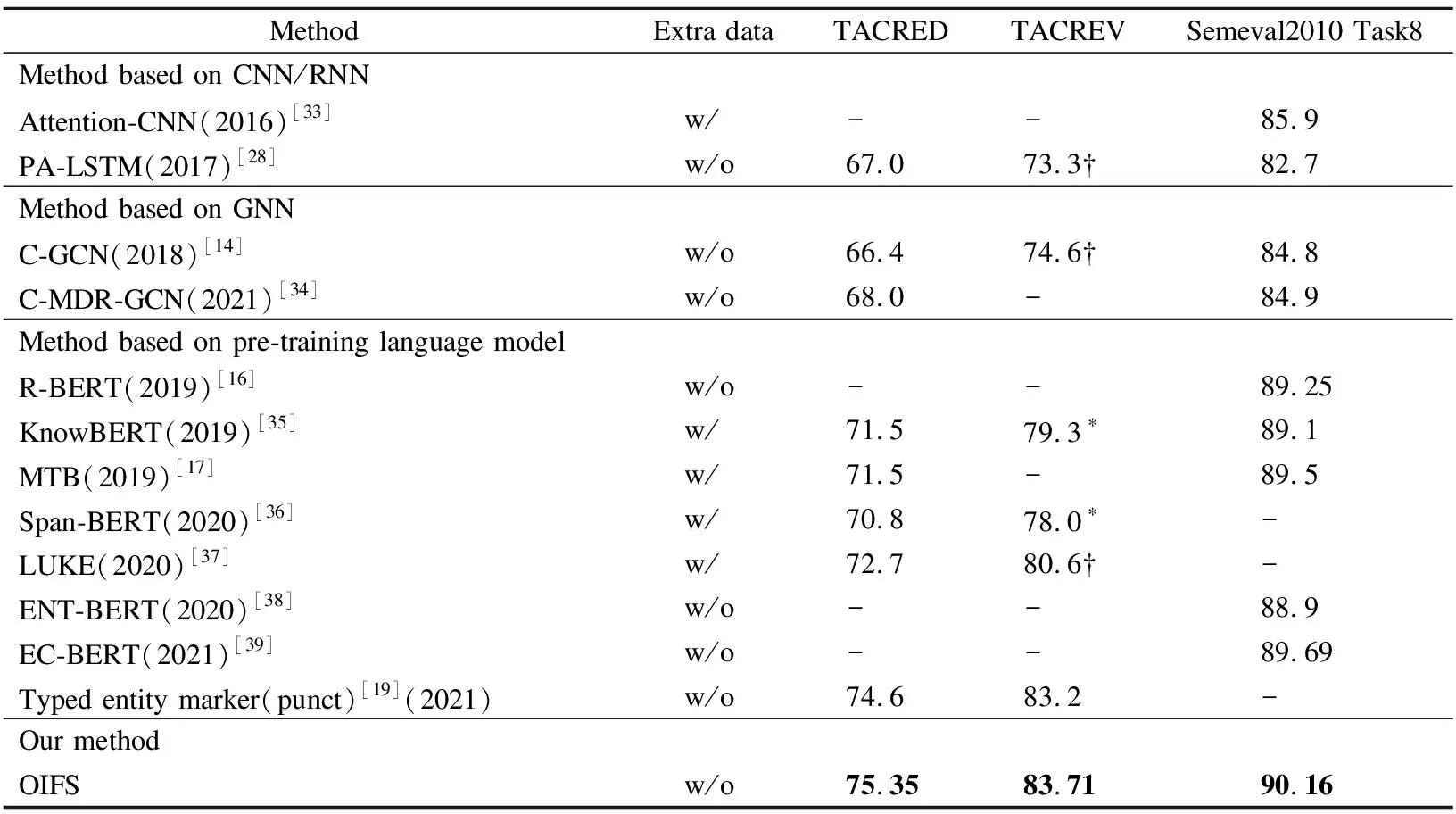
表2 模型效果对比(F1值)
相比于基于CNN/RNN的方法、OIFS模型在3个数据集上所取得的F1值分别提高了8.35、10.41和4.26,证实了预训练语言模型相较于其他传统编码模型的强大能力;
相比于基于GNN的方法,OIFS模型取得的F1值分别提高了7.35、9.11和5.26,这表明基于图神经网络的模型仍然存在着较为明显的缺陷,如过度依赖于依存解析器所导致的错误传播问题;
相比于基于预训练语言模型的方法,OIFS模型在TACRED数据集上的F1值提升了0.75至3.85;在TACREV数据集上的F1值提升了0.51至4.41;在Semeval2010 Task8数据集上的F1值提升了0.47至0.91.在3个数据集上的效果均优于当前最先进的模型,证明了本文方法的有效性,表明OIFS模型能够有效地对模型中的各种特征信息进行组合,解决了现有模型忽略不同特征对分类的不同贡献的缺点.
4.5 模型性能分析
本节将OIFS模型与其他基于预训练模型的基线方法进行了性能比较,从参数量大小以及是否使用外部知识两个方面进行分析,如表3所示.
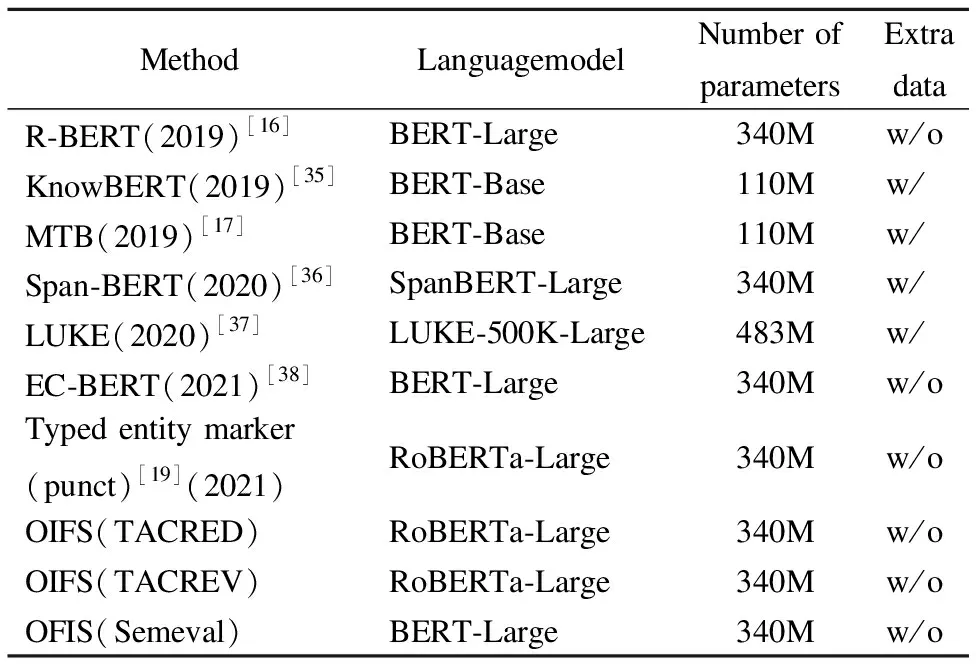
表3 模型规模对比
KnowBERT(2019)[35]和MTB(2019)[17]使用了BERT-Base作为语言模型,因此参数量较小,但它们分别在微调阶段和预训练阶段融入了大量外部知识作为数据增强;
本文提出的OIFS模型的参数量与大多数基线模型持平,且在不需要添加任何外部知识和复杂的人工设计的情况下,在3个数据集上的F1值均显著优于现有模型,显示了本文方法的简练性和高效性及其在关系抽取任务中的强大潜力.
4.6 上下文特征向量选择实验
为了使自适应信息学习机制更好地发挥作用,进行了上下文特征向量选择实验,分别选取RoBERTa模型(TACRED、TACREV)和BERT模型(Semeval2010 Task8)的最后6个Transformer层,依次作为上下文特征向量提供给自适应信息选择层,并对比模型效果,如图5、图6、图7所示.
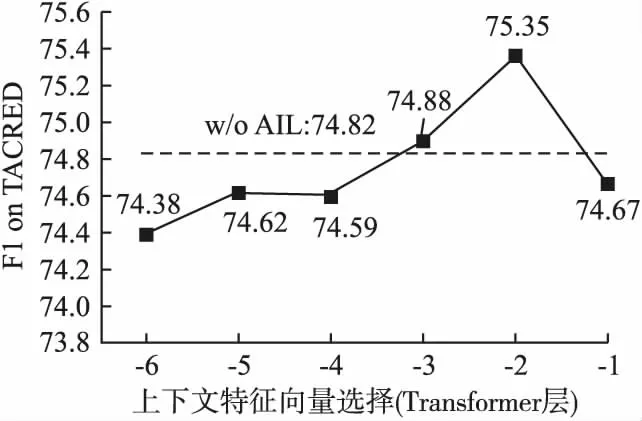
图5 上下文特征向量选择实验(TACRED)

图6 上下文特征向量选择实验(TACREV)

图7 上下文特征向量选择实验(Semeval2010 Task8)
图中的水平参考线代表不使用自适应信息学习模块时的模型效果(即消融实验模型w/o AIL,将在4.8节中阐述).
实验结果表明,在3个数据集上,模型均在使用倒数第2个Transformer层作为上下文特征向量时达到了最好的效果.而使用倒数第1个Transformer层时,模型效果有所下降,这可能是由于对该层的过度利用导致了模型的过拟合.因此,在本文的实验中,均选择倒数第2个Transformer层作为上下文特征向量.
4.7 特征维度选择实验
为了提升模型效果,进行了特征维度(Hidden size)选择实验.RoBERTa-Large和BERT-Large模型输出的隐状态表示维度均默认为1024,将后续特征维度分别设置为256、512、768、1024、1280,在3个数据集上分别进行实验,并对比模型效果,实验结果如图8、图9、图10所示.
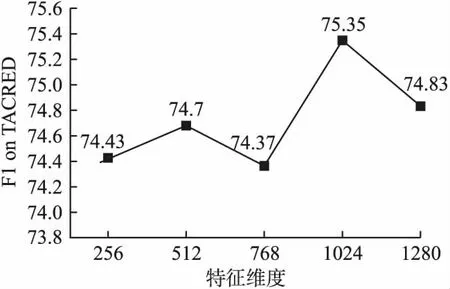
图8 特征维度选择实验(TACRED)

图9 特征维度选择实验(TACREV)

图10 特征维度选择实验(Semeval2010 Task8)
实验结果表明,在3个数据集上,模型均在特征维度为1024时达到了最好的效果.因此,在本文的实验中,均选择将特征维度设置为1024.
4.8 消融实验
为了揭示OIFS模型中各组成成分的有效性,本节设计了4个消融模型,并对比了实验结果:
w/o AIL:在得到复合向量H1、H2后,不使用自适应信息学习层(Adaptive Information Learning,AIL),直接将二者连接后送入全连接层和softmax层进行分类,其他设置不变.
w/o GLIF:在获得句向量H0和实体向量He1、He2后,不对句向量和实体向量进行融合,即全局信息和局部信息间的融合(Global and Local Information Fusion,GLIF),直接将三者送入自适应信息学习层,其他设置不变.
w/o Entity1:在模型前馈过程中,不使用实体1的信息,即不获取He1及其衍生表示H1,仅使用复合表示H2进行分类.
w/o Entity2:在模型前馈过程中,不使用实体2的信息,即不获取He2及其衍生表示H2,仅使用复合表示H1进行分类.
表4报告了消融实验的结果.
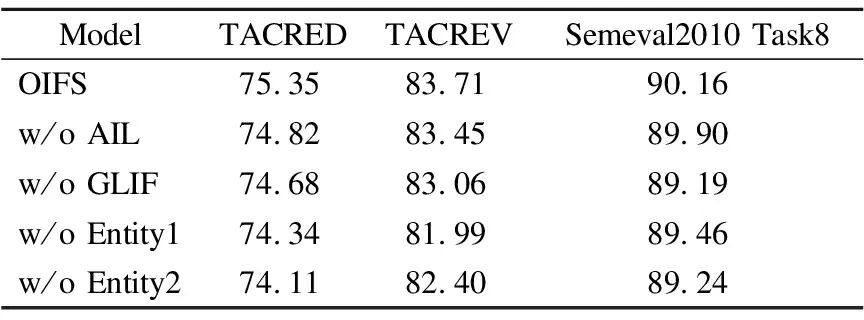
表4 消融实验结果对比
在不使用自适应信息学习层的情况下,模型在3个数据集上的F1值分别下降了0.53、0.26和0.26,表明自适应信息学习机制确实有利于对模型特征进行恰当地融合,从而提升模型效果;
在不对全局信息和局部信息进行融合的情况下,模型的F1值分别下降了0.67、0.65和0.97,表明本文的方法有利于聚合模型中的全局句子特征和局部实体特征;
在不使用实体1和不使用实体2的情况下,模型在TACRED数据集上的F1值分别下降了1.01和1.24,在TACREV数据集上的F1值分别下降了1.72和1.31,在Semeval2010 Task8数据集上的F1值分别下降了0.70和0.92,取得了不同的效果,表明实体1和实体2在关系抽取中的作用确实存在差异,应当对其加以不同的考量.
4.9 模型对各关系类型的影响
为了进一步说明OIFS模型的有效性,在表5中列出了模型在Semeval2010 Task8数据集中的每个类别上取得的查准率(Precision)、查全率(Recall)以及F1值,并与Wu等人[16]的R-BERT模型进行对比,该模型曾在Semeval2010 Task8数据集上取得了89.25的F1值.由于原论文没有列出每个类别的具体数据,本文选取Wang等人[18]对R-BERT模型进行的复现实验的结果,其取得的F1值为89.26,与原论文持平.

表5 Semeval2010 Task8数据集上各类别的查准率、查全率、F1值对比
实验结果表明,与R-BERT模型相比,本文的方法在6个类别上的查准率有提升,在7个类别上的查全率有提升,在8个类别上的Macro-F1值有提升,进一步证明了OIFS模型在关系抽取任务中的有效性.
4.10 模型注意力可视化
为了更清晰地展示OIFS模型捕捉信息的能力,以Semeval2010 Task8数据集中的一个样本:“[CLS]the minister attributed the slow production of the[E11]materials[E12]by the local[E21]industries[E22]to their limited capacities”为例,针对目标实体“materials”,对模型中的最后一层Transformer的自注意力权重进行了可视化,同时,为了与现有模型进行对比,本文复现了Wu等人[16]的R-BERT模型并对其进行了类似的可视化,如图11所示.
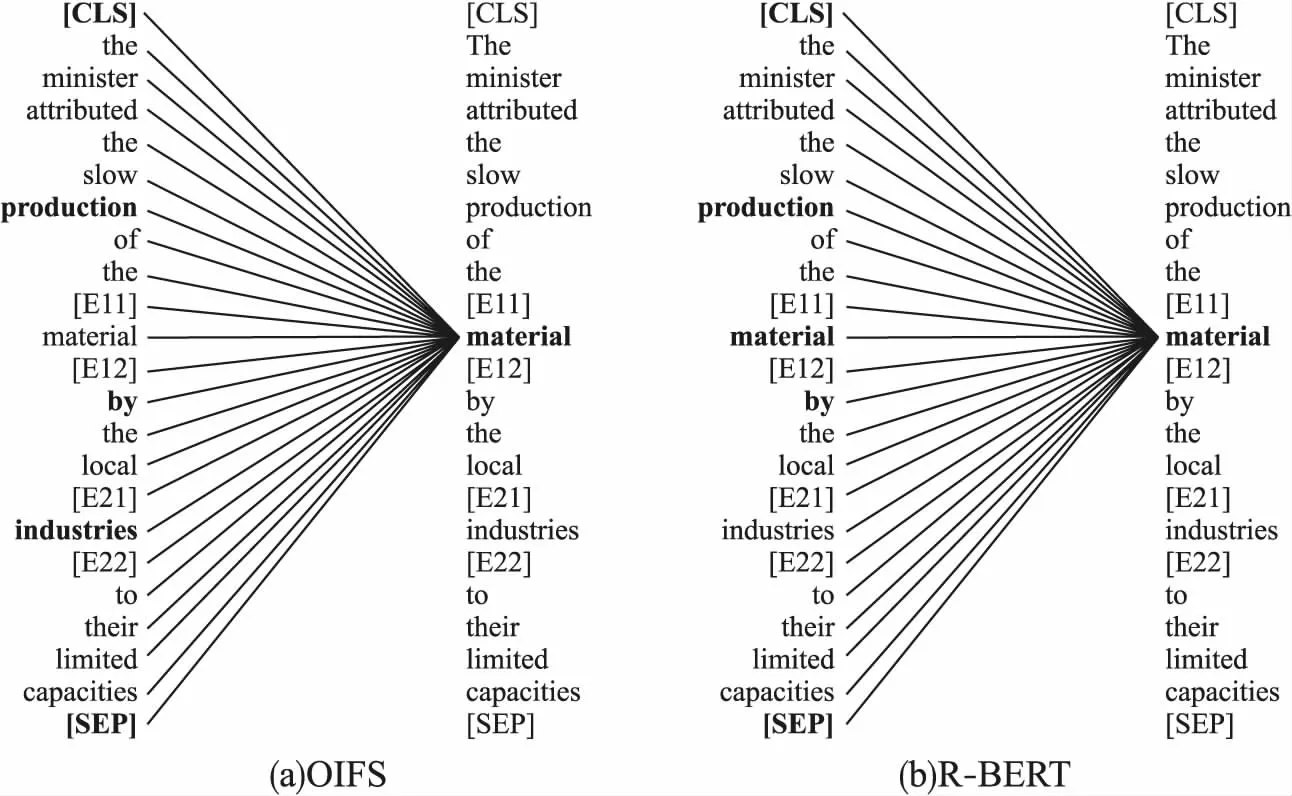
图11 模型注意力权重可视化
在OIFS模型中,目标实体materials对[CLS]、production、by等token有更高的注意力权重,这些信息有利于模型判断样本的关系类型“Product-Producer(e1,e2)”.而在R-BERT模型中,目标实体materials对[CLS]、by的注意力权重有所下降,而将部分权重分配到了to、their等无关词上.
可视化结果表明,OIFS模型能够更准确地聚焦于模型中的关键信息,降低了模型中噪声信息的影响,有助于提升关系抽取的效果.
5 总结与展望
本文提出了一种基于优化信息融合策略的关系抽取模型OIFS,针对以往模型对不同层次的信息一视同仁的缺陷,对BERT下游任务模型做出了改进:分析了关系抽取任务中不同信息在分类中的贡献,并针对每种信息提出了不同的信息融合策略,使得模型不仅恰当地融合了全局表示和局部表示的不同层次的信息,且自动聚焦于对分类起更大作用的信息,从而得到了更高质量的关系表示,提高了关系抽取的效果.在TACRED、TACREV和Semeval-2010 Task 8基准数据集上,该文的方法在无需任何外部知识和人工设计的情况下,分别获得了75.35,83.71,90.16的F1值,显著优于当前的最优模型.
在未来的工作中,将尝试将本文的方法与其他预训练模型结构相结合,同时考虑将自然语言推理的方法结合到模型当中,并探究其在更多复杂关系抽取数据集以及远程监督数据集中的表现.
