人工智能性能评测基准现状与发展趋势分析★
2022-11-17黄林轶陈明敏彭琦黄璇童国炜
黄林轶,陈明敏,彭琦,黄璇,童国炜
(1.工业和信息化部电子第五研究所,广东 广州 511370;2.智能产品质量评价与可靠性保障技术工业和信息化部重点实验室,广东 广州 511370)
0 引言
近年来,人工智能(AI:Artificial Intelligence)技术在工业界、学术界均得到了飞速发展,与诸多领域的融合创新应用场景层出不穷,如智能无人机、智能汽车。AI现已被证明是一种可成功地用于多种任务的机器学习方法,各种算法、软件和硬件厂商均推出了各自支持AI训练推理的产品[1-3]。但是,由于各个厂商为了推广产品,制定了很多仅符合特定产品的评测基准;同时,AI测试基准互认难、落地少,使得产业链中AI产品的发展受到了一定的阻碍[4]。本文为了分析现阶段AI评测基准的发展脉络,推进行业健康发展,汇总了国内外若干个AI评测基准,从评价指标的多样性、模型的多样性和应用场景的多样性等角度进行分析评价。
20世纪80年代,为了让Unix服务器更好地发展,创建了标准性能评估组织(SPEC:Standard Performance Evaluation Corporation);为了改善关系型数据库的性能,创建了事务处理性能委员会(TPPC:Transaction Processing Performance Council),这些组织在建立后制定并维护了各自社区的基准,引导了技术发展的趋势。受其启发,众多科研机构、高校及企业也纷纷地推出了具有各自特色的AI评测基准;同时,由于市场上AI专用训练推理软硬件产品的种类繁多,为了推进该类产品发展,也有必要制定综合性的评测基准。
1 AI评测基准
1.1 MLPerf
MLPerf是由来自学术界、研究实验室和相关行业的AI领导者组成的联盟,旨在“构建公平和有用的基准测试”,在规定的条件下,针对硬件、软件和服务的训练和推理性能提供公平的评估。目前,MLPerf项目[5]是接受度较高的AI评测基准,它依托哈佛大学的Fathom项目和斯坦福的DAWNBench项目,借鉴了前者在评测中采用多种AI任务,以保证评测基准具有足够的代表性;同时借鉴了后者使用的对比评价指标,保证其公平性。
作为一套AI学习软硬件性能通用性评测基准及改善策略提供平台,MLPerf关注的是不同的AI模型算法在面对具体任务时训练和推理过程中所需的时间。该基准的测试集涵盖了4个领域9种问题的评测基准,主要有图像分类、物体识别、翻译、语音识别、自然语言处理和推荐,以及强化学习,具体如表1所示。
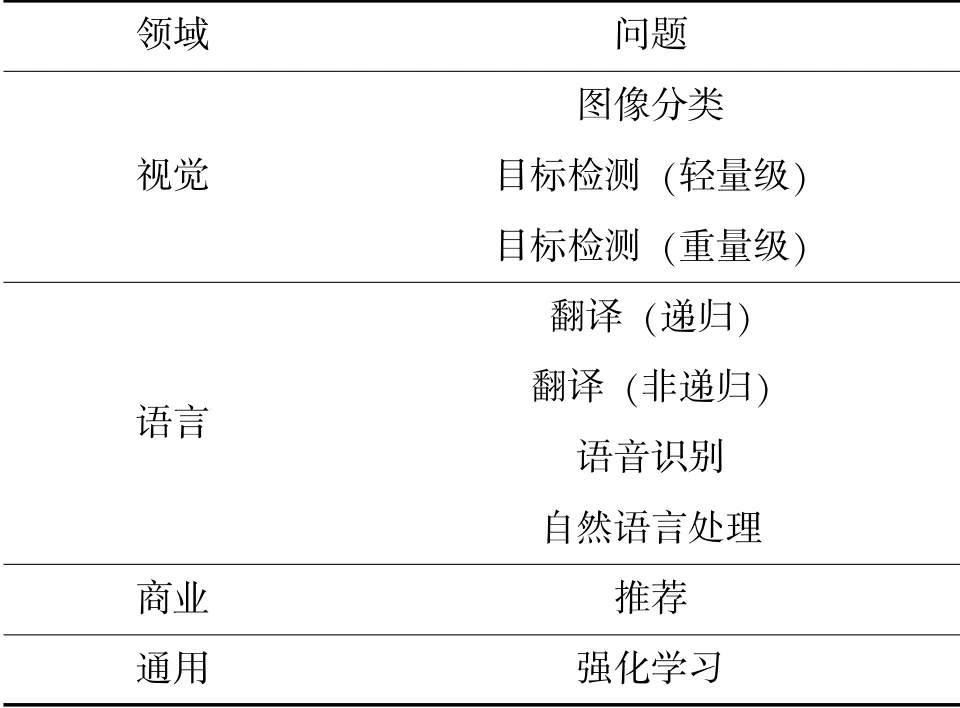
表1 MLPerf评测基准任务类型表
MLPerf将评测分为训练评测和推理评测,同时每种评测又分为开放式和封闭式;开放式允许评测过程中的某些设计的改动,封闭式必须采用MLPerf规定的设置。目前该平台还未收集到任何开放式评测结果的提交。在封闭式推理评测基准中,MLPerf兼顾了AI算法模型在大型数据中心、边缘系统、移动终端中的运行需求,同时又定义了在线、离线、并行和串行4种运行方式。
MLPerf在AI任务类型选择时,重点关注了目前应用落地较为成熟的图像分类、目标检测、语义分割、自然语言处理、推荐和强化学习等场景,同时在各种场景中挑选了基准AI模型算法和数据集,但是仅关注了训练/推理时间指标。由于MLPerf项目任务分类详细,而指标简单,众多厂商均提交了本公司产品在其基准上的测试结果。
1.2 NPUbench
2018年,中国科学院计算技术研究所智能计算机研究中心提出了一款用于评估神经网络处理器(NPU:Neural-network Processing Unit)性能的基准套件:NPUbench[6]。该基准包含8种神经网络模型、5种数据集和2种评估指标,以保证NPUbench所选择的每个神经网络模型在网络结构方面都具有代表性、多样性,如表2所示。
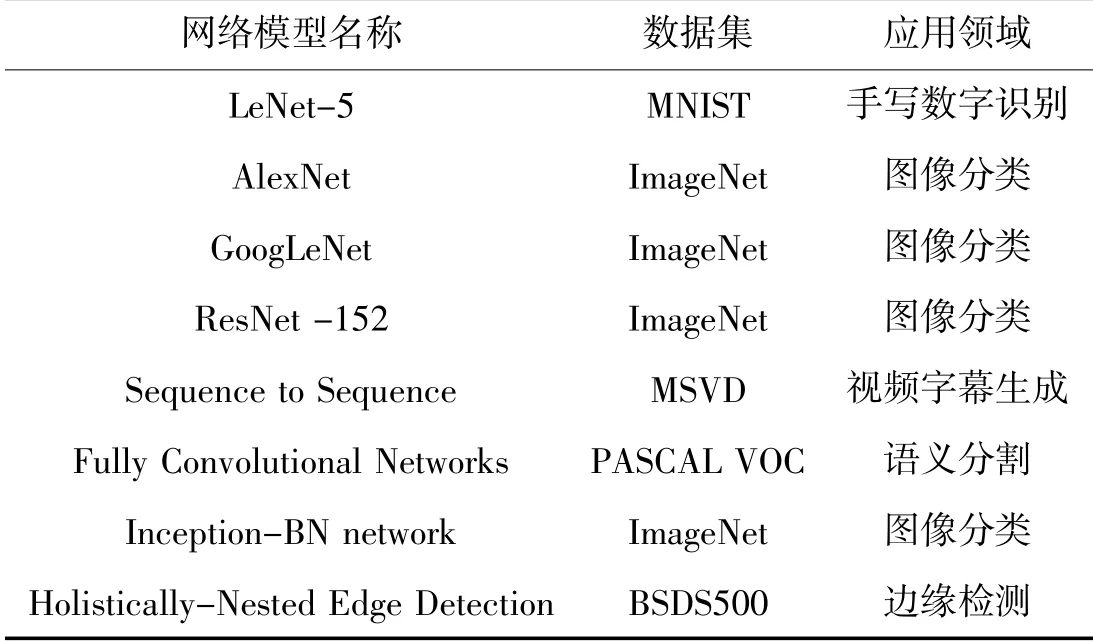
表2 NPUbench包含的模型和数据集
a)性能指标
即每秒执行乘加操作的数量,这一指标主要用于度量NPU在计算性能方面的表现。
b)功耗指标
即每秒每瓦执行乘加操作的数量,这一指标主要用于度量NPU在能耗方面的表现。
当对NPU进行测试时,首先,把指定的神经网络模型部署到待测NPU上。然后,选择模式,第一种模式是将Batch参数设置为1,从而会记录NPU处理一个Batch数据时的性能;第二种模式是把Batch参数设置到最大,尽可能地达到待测神经网络处理器的性能极限,这一模式是用来记录NPU的最大吞吐性能。最后,记录NPU的性能表现。
根据该评测基准在苹果A10X Fusion、A11 Bionic,华为麒麟970芯片,英伟达GeForce GTX 1080等硬件上的测试结果可知,NPUbench可实现对特定主流NPU的训练和推理性能评测,采用运算性能和功耗作为性能评价指标,但所涵盖的任务类型较少,并且主要集中于图像处理领域。
1.3 AI-Rank
2020年,中关村智用人工智能研究院发布了面向产业应用的AI开源评测基准AI-Rank[7],该基准通过多维度拟合评测指标评估被测系统的综合性能。其具备三大特色:1)面向产业应用,设定了更广泛、更系统、更实用的量化评价体系;2)设定了3个评测赛道,不仅评比硬件速度,也测评面向产业真实应用的软件能力;3)支持国产化产品的评测,实现硬件、算法和平台的一体化协同发展。
不同于已有的评测基准,它们大多集中在对训练时间、推理时间等几个指标的计量上,AI-Rank设立了多个细分赛道,开展了对纯硬件性能和大规模集群计算能力的测试,对算法、硬件和生态等方面进行全面的测评,如表3所示。
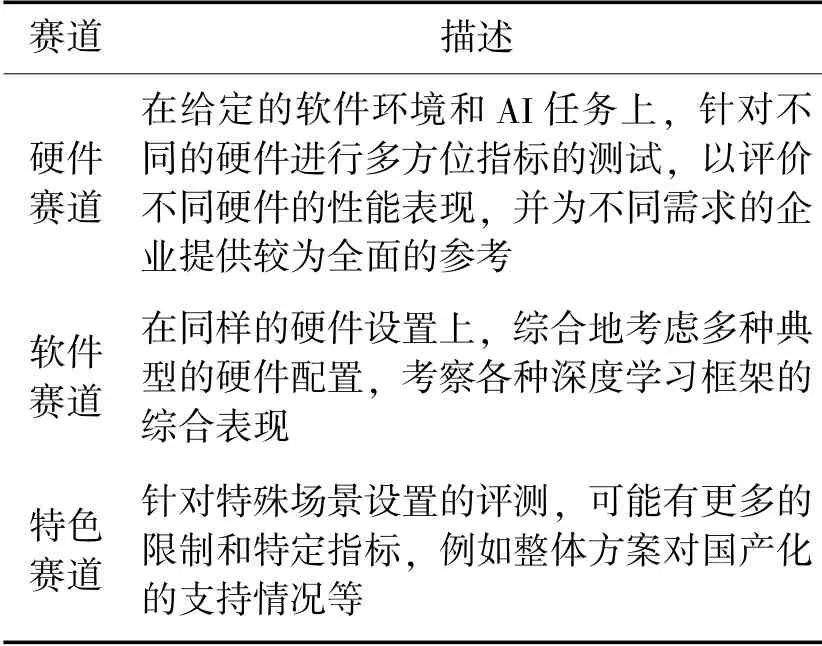
表3 评测赛道
以上每个赛道中又对AI的主要使用场景,如云端训练、云端推理和终端推理,进行了覆盖。观察可知,软件赛道主要评估深度学习框架和模型在同等硬件、数据集和网络结构前提下的性能表现;硬件赛道主要用于综合评估深度学习训练、推理所用的硬件计算设备性能。定位方面,AI-Rank在工业需求中的框架和模型选择角度,提供可供参考的测试性能数据。
1.4 AI-Benchemark
AI Benchmark[8]是苏黎世联邦理工学院基于AndroidNN技术推出的AI性能评测工具,涵盖了SOC和手机AI性能数据。该基准测试包括46项AI和计算机视觉测试,这些测试由智能手机上运行的神经网络执行。它衡量了AI性能的100多个不同方面,包括速度、精度和初始化时间等。包含了一系列全面的架构评测,允许评估各种用于解决不同AI任务的方法的性能和限制。
测试结果分为手机、手机芯片和GPUCPU 3个版本的测试展示,分别从目标识别(轻量级)、目标识别(重量级)、人脸识别、光学字符识别、图像去模糊、图像超分辨、郊外成像仿真、语义分割、照片增强和文本填空,以及设备极限等角度对设备进行评测,所选的任务类型种类多,更加贴近AI应用场景;同时兼顾了AI模型训练和推理过程的定量描述。
1.5 AImark
AImark[9]是鲁大师于2017年发布的手机AI性能评测工具,是手机行业内第一个针对AI的评测工具。在评测任务设计中,考虑到主流手机介绍中把AI优化作为产品宣传的亮点,如AI美颜、AI摄影等功能,因此制定了以图像识别、图像标注为基准测试任务的评测标准。采用4种神经网络:ResNet34、InceptionV3、Mobilenet-SSD、DeepLabV3+,分别在两项任务中进行测试并输出结果列表,最终通过识别速度来判断手机AI性能,进而给出行测试评分。
1.6 RealSafe
2020年,清华AI研究院推出了针对AI模型算法安全的检测平台RealSafe[10],该评测基准可作为AI系统的“杀毒软件”提供从评测到防御的解决方案,缓解对抗样本攻击的威胁程度。同时,该平台支持零编码在线评测,部署方仅提供相应的数据即可完成在线评估,技术难度、学习成本均得到了降低。
该平台为了提高用户对AI模型安全性的认知,采用量化的形式来展现模型在对抗样本攻击下的表现评分;同时提供模型安全性提升服务,包含针对5种去除对抗噪声攻击的通用性防御方案。实验表明,部分第三方人脸识别系统添加RealSafe后,安全性可提升40%以上。
1.7 AIIA DNN benchmark V0.5
2019年,AI产业发展联盟发布了AI端侧芯片基准测试评估方案V0.5[11](AIIA DNN benchmark V0.5)。方案聚焦能够客观地反映AI处理器或加速器的性能指标,在4个典型的应用场景(分类、目标识别、语义分割和超分辨)中设置了两类评测指标、运行速度和算法性能(top1,top5,mAP,mIoU,PSNR);同时区分了整型和浮点型模型的性能对比结果。为了涵盖更多的AI芯片,该方案采用分类、目标检测、图像超分辨、图像语义分割和人脸识别等任务分别在终端和云端进行训练、推理过程的评估。相比于其他评测方案,该方案的任务类型有限,但是评测指标较为丰富,而且考虑了整型和浮点型模型的对比。
1.8 DeepBench
继PaddlePaddle之后,百度开源了一项深度学习评测基准工具DeepBench[12]。该工具可以测量深度神经网络训练中的基础操作在不同的硬件条件下的表现。例如:稠密矩阵相乘运算是AI模型中常用的运算模块,但是,由于不同硬件的实现方式存在差异,存在深度学习硬件和软件的优化空间。
DeepBench包括7个硬件平台的训练结果,包括NVIDIA的TitanX、M40、TitanX Pascal、TitanXp、1080 Ti、P100和 英 特 尔 的Knights Landing。推 理 结 果 包 括:NVIDIA的TitanX Pascal、TitanXp和1080 Ti 3种服务平台,以及iPhone 6和7、树莓派3这3个移动设备。评测过程中针对稠密矩阵乘法、卷积、循环层和全局归约等操作分别在半精度和单精度模型中进行测试,通过计量运行时间和GFLOPS等指标对上述操作的性能进行评价。
1.9 AI Matrix
2018年阿里巴巴发布了一款AI基准测试平台AI Matrix[13],可为用户提供一个测量不同AI软件和硬件的方法并比较它们之间的优劣,了解各种影响AI硬件性能的因素并帮助用户改进硬件设计。同时,缓解了开发者关注的4个问题:1)如何反映AI应用和模型使用的真实情况;2)制定AI加速器评估和选型标准;3)如何推动AI用例过程中模型算法和硬件的融合过程,提高硬件的利用率;4)指导AI芯片设计及优化过程。
为了评估不同的AI软硬件组合时的训练推理性能,AI Matrix设计了4类测试:底层测试、分层测试、完整测试和合成测试。其中,底层测试着重于AI硬件计算中重要的基础运算性能计算;分层测试着重于评价神经网络里面的每一层;完整测试着重于评价不同应用领域的完整模型;合成测试是针对设计人员提出的一种创新想法,通过合成模型从统计的角度来模拟模型,同时提供一些灵活性以测试硬件。
2 发展特点分析
近些年,AI技术在计算机视觉、自然语言处理、自动驾驶和机器人等领域开展了诸多应用落地案例,为了更加科学、客观地评估AI模型在某些软硬件组合下的性能,国内外专家学者提出了各自具有领域特色的AI评测基准。展望未来,本文认为该领域具有以下特点。
a)从单纯的AI算法评测向AI软硬件联合评测发展。现阶段,单纯的AI算法评测不能满足现阶段应用落地过程中对AI算法性能提升的需求。AI模型落地应用过程离不开深度学习框架和高计算性能硬件的协同,在软硬件协同测试环境下寻找最优的组合方式是现阶段AI评测的发展趋势之一。
b)现有的应用场景测试不完善,新增的应用场景测试需求难以满足。AI算法模型需要结合具体应用场景的特点进行部署,现存的评测基准中定义的场景过于理想,未考虑实际应用过程中出现的异常情况,如对抗攻击。同时,随着深度学习落地应用业务的开展,更多新的应用场景急需客观科学的方法进行评测,在帮助开发者选择最佳的软硬件组合的同时,指导生厂商对其产品进行优化升级。
c)通用性、专用性评测基准共同发展,完善了AI模型算法和软硬件的设计框架。通用型与专用型训练推理架构是AI装备领域的发展趋势,领域内的高校、科研院所和公司均试图在AI通用评测基准和专用评测基准角度寻找自己的立足点。目前,专用型基准更受青睐,不同领域的公司相继地提出了各自的评测基准,在产品设计、制造和测试阶段均发挥了指导作用。
d)AI测试基准种类多,在实际指导生产中的作用存在提升空间。一方面,AI评测基准的提出可以指导终端用户选择恰当的产品;另一方面,可以指导AI产品制造方对其产品进行迭代优化升级。但是,目前两个方面均未起到应有的作用。未来在AI评测基准指导生产方面应增加研究力度,提升所提基准的实际价值。
3 结束语
AI评测基准可有效地改善应用过程中落地效果差的问题,同时也可以指导AI模型、AI产品在设计、制造、部署和测试过程中的工作,保障AI产业健康发展。本文结合国内外AI评测基准的发展现状,从设计目的、特点、场景、指标和涵盖范围等方面总结介绍了9款基准,并进行了适当的分析评价,最后针对该领域4个方面的发展趋势进行了详细的分析阐述。
