多源数据融合的南海领域主题词表*
2022-11-17齐小英丁子仪杨海平
齐小英 丁子仪 杨海平
1 引言
南海维权关乎国家安全、区域和平与亚太经济发展[1]。目前,南海问题的司法解决备受国际社会的关注,不仅关涉我国的主权利益,也影响着我国在国际社会中的国家形象。在“搁置争议,共同开发”的原则下,我国也在逐步加强对国际海洋司法领域的参与度,而加快南海信息资源组织与证据链构建进程,有利于增强我国在南海国际司法上的裁判优势。
此外,随着南海文献资料的不断扩充,从法学、史学、地理学、文学、图书馆学、文献学等学科视角对南海文献资料进行整理与发掘的研究越来越多,呈现出多学科融合的研究趋势。加快南海文献资料的信息组织工作是图书馆学和文献学界义不容辞的责任。例如,1948年杜定友编撰的《东西南沙群岛资料目录》[2],1973年福建省图书馆编撰的《我国南海诸岛资料联合目录》[3],1981年许崇灏和郑资约等人续编的《琼崖志略·南海诸岛地理志略·东西南沙群岛资料目录·海南文献目录·中国南海诸群岛文献资料展览目录》合辑[4]以及1988年韩振华编著的《我国南海诸岛史料汇编》[5]等都是这一领域较早期的学术成果,为后来的文献整理和利用奠定了基础。1994年李国强和寇俊敏编撰的《海南及南海诸岛史地论著资料索引》[6]和1998年吴士存和沈固朝等人编撰的《南海资料索引》[7]等系统梳理了以往的南海研究文献,为当前和今后的南海研究提供了重要的参考。随着信息技术在各领域的应用日益深化,数据库开发成为文献资料整理与发掘的新热点,数据库也成为今后做南海文献整理与组织的重要基础性工具,如2015年厦门大学图书馆构建的“东南海疆研究数据库”[8]。中国南海研究协同创新中心构建的“南海文库数字资源库”[9],则构成了南海研究的文献资源基础。在大数据时代,随着知识组织理论与技术的不断发展,针对文献的整理与发掘研究已经从最初的书目情报研究发展到今天面向知识服务的领域知识体系构建。图情领域包括蒋永福[10]、侯汉清[11]以及苏新宁[12]等在内的许多学者的研究成果为领域主题词表和知识体系的构建等提供了借鉴和参考。
然而,由于南海文献资料数量庞大且多源异构,现有南海研究成果以文献资料的整理工作为主,未形成南海研究中标准且统一的描述逻辑、数据基础与知识体系,无法实现南海文献资料的有序化、结构化与关联化。因此,建立一套严谨准确的领域主题词表,是对南海文献资源进行知识组织与知识发现的重要基础。为了梳理南海研究的底层概念,构建其数据基础,呈现其知识脉络,本文以南海历史事件、新闻数据及文献资料为语料库,进行概念术语抽取及其词间关系识别,构建南海领域主题词表。以期为南海文献资料的智能化自动标引提供基本的规范化词典,为文献资料目录的深度揭示和智能推荐提供依据。
2 相关研究
目前,国内外尚未有南海领域主题词表的相关研究成果,“南海”与“南海诸岛”等主题词往往从属于主题词表中的地理科学[13]、海洋文化[14-16]、海洋科学[17,18]、水产渔业[19,20]等类目,例如我国《汉语主题词表》[21]自然科学卷第4册中“P722.7南海”从属于“P7海洋学”,“S922.95南海水产资源”从属于“S9水产、渔业”。不管是综合主题词表还是领域主题词表,都较少收录南海领域历史、法律以及地理空间等主题词。
词表体系结构的设计方法主要有自上而下、自下而上两种。前者是根据词表编制目的,首先建立顶层宏观框架,随后由顶层分类逐步分解出细分类别,是大粒度向小粒度分解的过程;后者是通过对领域概念与术语的归类,梳理底层细分类别,并逐层聚类获得更高级、更抽象的类目。实践表明,主题词表构建是一个不断迭代修正的过程,既需要顶层框架对词表设计方向进行宏观控制,也需要根据细分类别的合理性调整词表结构。国内学者编制的敦煌壁画叙词表[22]、文物保护主题词表[23]、民国抗战史主题词表[24]以及电子信息技术主题词表[25]等结构设计都采用了自上而下和自下而上相结合的方法。本文在南海领域主题词表结构设计中也采用二者相结合的方法。
在主题词和词间关系识别方面,国际标准ISO-25964提供了一个主题词表的数据模型和XML模式,包括主题词表概念、主题词表术语、主题词表注释以及概念之间的关系[26]。主题词识别的主要方法有依存句法分析法[27]、互信息和TF-IDF[28,29]、无监督和有监督的机器学习[30-33]等。在上下位关系识别方面,常用方法有字面成族[34]和共现聚类[35]两种;在同义关系识别方面,有同义词词典、模式匹配、字面相似度以及概念关系识别模型等方法[36,37]。但是,现有方法对领域的未登录词识别不够准确,主题词和词间关系识别过程中也未考虑主题词对领域的指示度。
基于此,本文引入分面分类法设计词表结构[38],利用深度学习技术和互信息等方法构造候选词集和未登录词以构建南海领域主题词表。
3 南海领域主题词表设计思想
南海领域主题词表是南海文献资源组织的规范受控词表,能够为南海文献资源的知识元语义标注、抽取、加工、挖掘与集成提供统一的、标准的描述。该词表面向南海领域,从多角度描述领域内细分概念及其关系,具有专有性、细粒度、高维度等特点。根据南海领域主题词表的建表需求与特点,本文提出南海领域主题词表设计流程如图1所示。(1)主题词表中的主题词是对候选词进行归类、定义、结构化以及校对的结果,而语料库是候选词的主要来源。通过搜集国内外南海相关历史事件、文献摘要与新闻文本,建立专有的、完备的南海语料库,为词表的建立提供完整可靠的数据基础。(2)设计基于分面分类法的南海领域主题词表顶层框架,建立南海领域特征的多维概念描述,克服先组式主题词表结构的缺点,形成满足多元表达与多维关联需求的主题词表逻辑结构。(3)以南海历史事件为样本,构造南海领域的自定义语义词典,确定词汇边界,为实体抽取提供依据;提出细粒度候选词抽取规则,对文献摘要及新闻文本进行候选词提取,获得候选词集。(4)根据南海领域特征制定主题词选词原则,结合专家咨询确定主题词表候选词集。(5)采用后组式标引代替先组式标引,采用共现聚类法识别候选词集中的词间关系。根据聚类结果,确定更深层级的细化类目,扩展词表结构,获得南海领域主题词表。
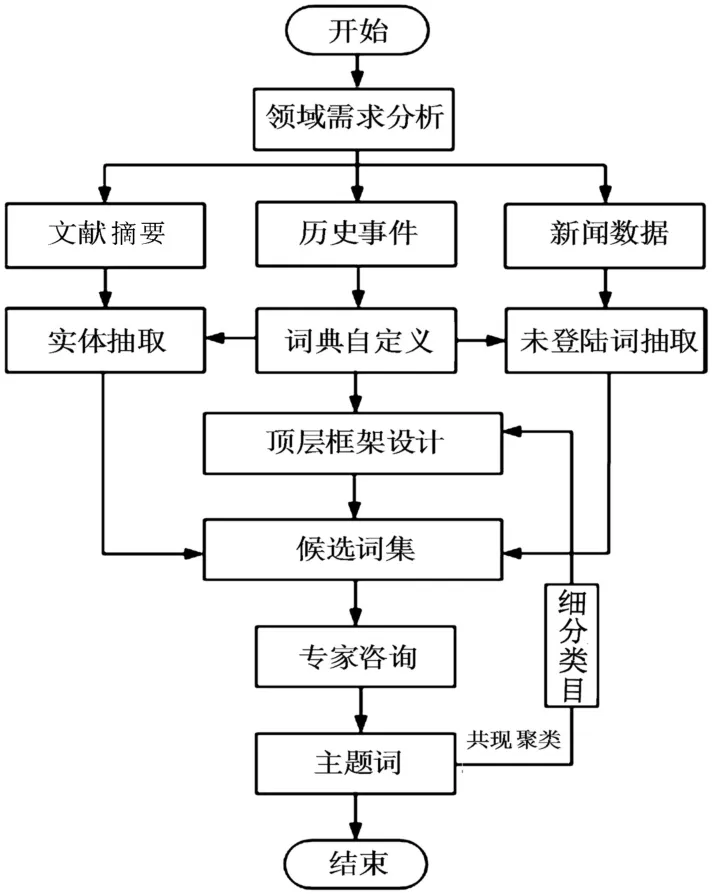
图1 南海领域主题词表的构建流程
4 南海领域主题词表构建
4.1 语料库
考虑到南海研究的学术性、权威性、客观性与严谨性,本文从中国南海网、中国南海研究院、中国南海研究协同创新中心以及南海文库(南京大学)爬取了相关的历史事件、文献摘要与新闻文本作为语料来源。历史事件是已经发生的事实,反映南海历史主权的发展过程,物体、主体、时间、空间等元素往往依附于特定历史事件,是串联各概念、主题、实例的重要桥梁。因此,历史事件中包含了与南海高度相关的词汇。利用历史事件构造语义词典,可以为候选词的抽取提供训练样本与参考依据。文献资料(仅搜集摘要)是对有历史价值与研究价值的对象与实体的意义表达和记录,是名词、数词、方位词等实体词的重要来源。新闻数据是时事热点的实时记录,同时也表达了官方、机构、团体的主流观点,是经过提炼、筛选、关联化、结构化的语料。文献摘要与新闻数据是候选词的来源。本文共搜集语料数据5664篇,其中,历史事件421个、文献摘要2843篇、新闻数据2400个,基本信息如表1所示。
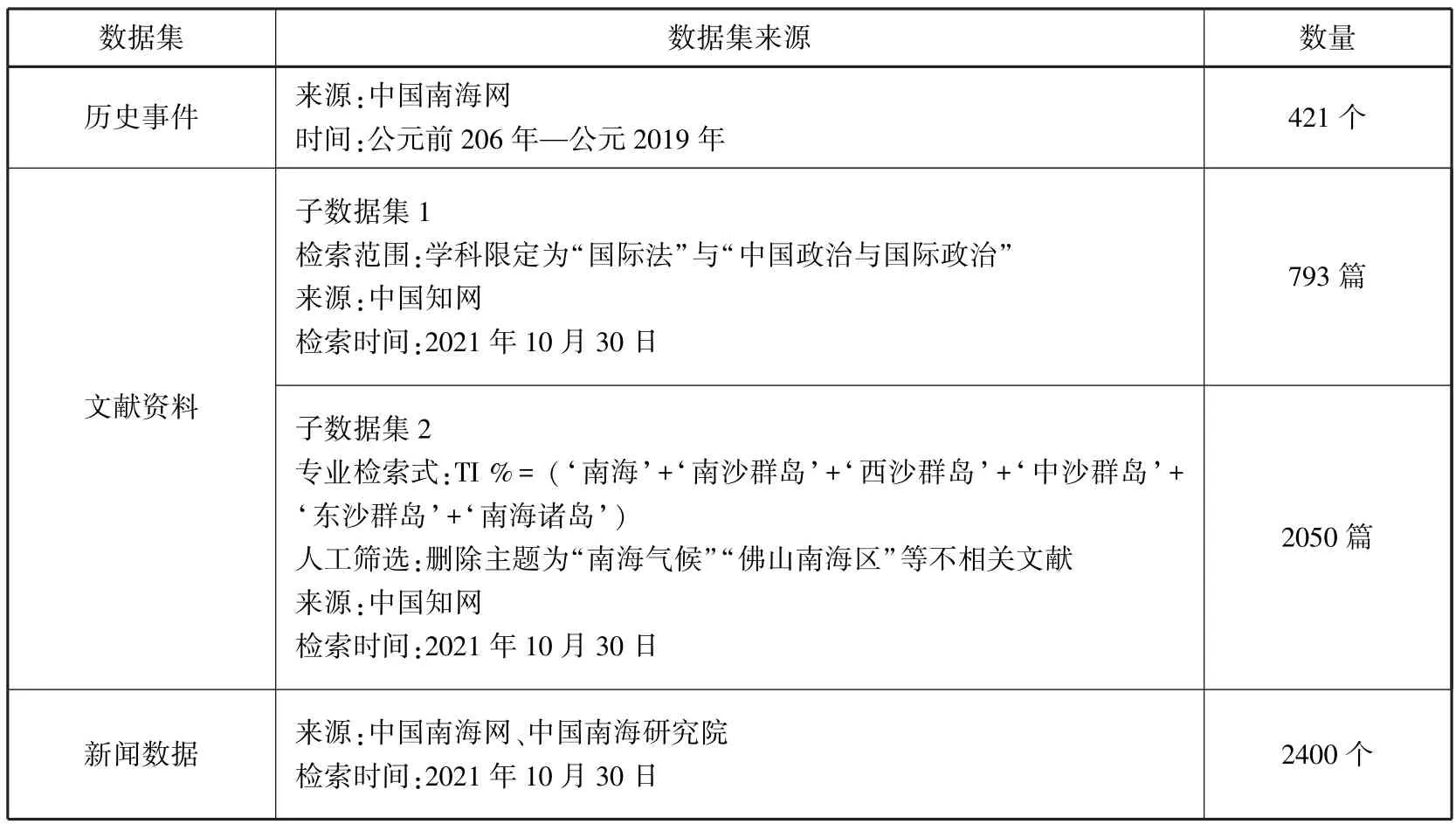
表1 语料库
4.2 自定义词典构建
首先采用分词技术获得南海领域的主题词分布特征,构造南海领域词典。以历史事件作为样本,对421个事件的文本进行常规语义下的词性标注,并根据分词结果对词典进行迭代修正。在此过程中发现,初始分词结果的准确率仅为62%,表明了南海领域的主题词分类具有自身特殊性。对错误词分析发现,分词算法对岛礁名称、主体、会议、条约、国家判例、地图名称等南海领域专有词汇识别效果不佳,应在主题词表框架设计中充分考虑这些特殊主题。为了充分识别特殊主题的专有词汇,通过在词典中补充相关词汇并定义特殊规则来识别文本中的条约、会议、判例、地图等名词,实现自定义词典更新。抽取规则及更新后的自定义词典分别如表2和图2所示。各词典包含词汇数量分别为:南海岛礁词310个,主权行为词310个,会议词81个,条约词60个,判例词70个,地图词59个。

表2 抽取规则
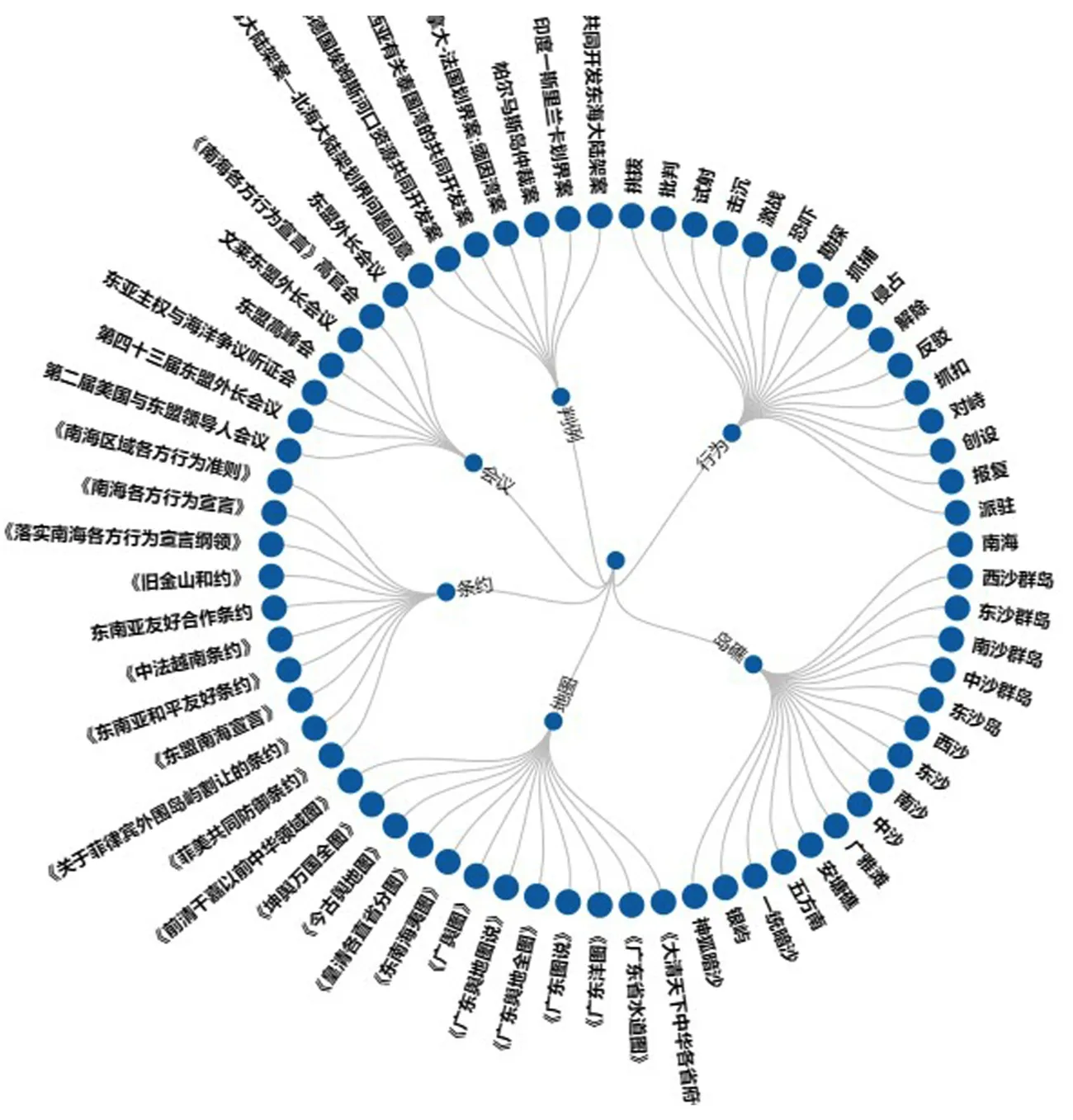
图2 自定义词典(部分)
4.3 南海领域主题词表的顶层框架
本文采用分面分类法构造南海领域主题词表顶层框架,逻辑关系结构如图3所示,其基本思想是将复杂概念分解为若干个简单概念,即组面与类目,通过组配若干个组面或类目综合表达一个复杂的主题。
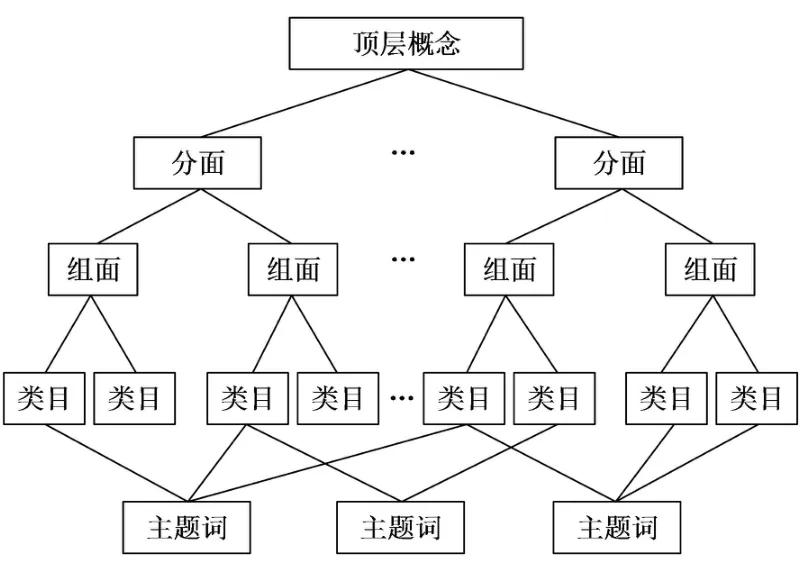
图3 南海领域主题词表的逻辑关系结构
根据SPO(Subject Prediction Object)三元组理论[38],“主-谓-宾”结构是表示知识单元和语义关系的有效方式。然而,南海领域研究具有跨学科属性,且南海历史事件、新闻、文献研究往往围绕特定资源、岛礁、边界线展开,基于传统三元组结构的分类方式粒度较粗,无法反映南海领域的多维概念。因此,本文根据南海领域研究的需求与特征,进一步加入资源维度、主题维度与空间维度,确立主体、行为、物体、资源、主题和空间六个分面,以架构南海领域的知识语义关系,其结构如图4所示。各分面内涵具体描述如下:
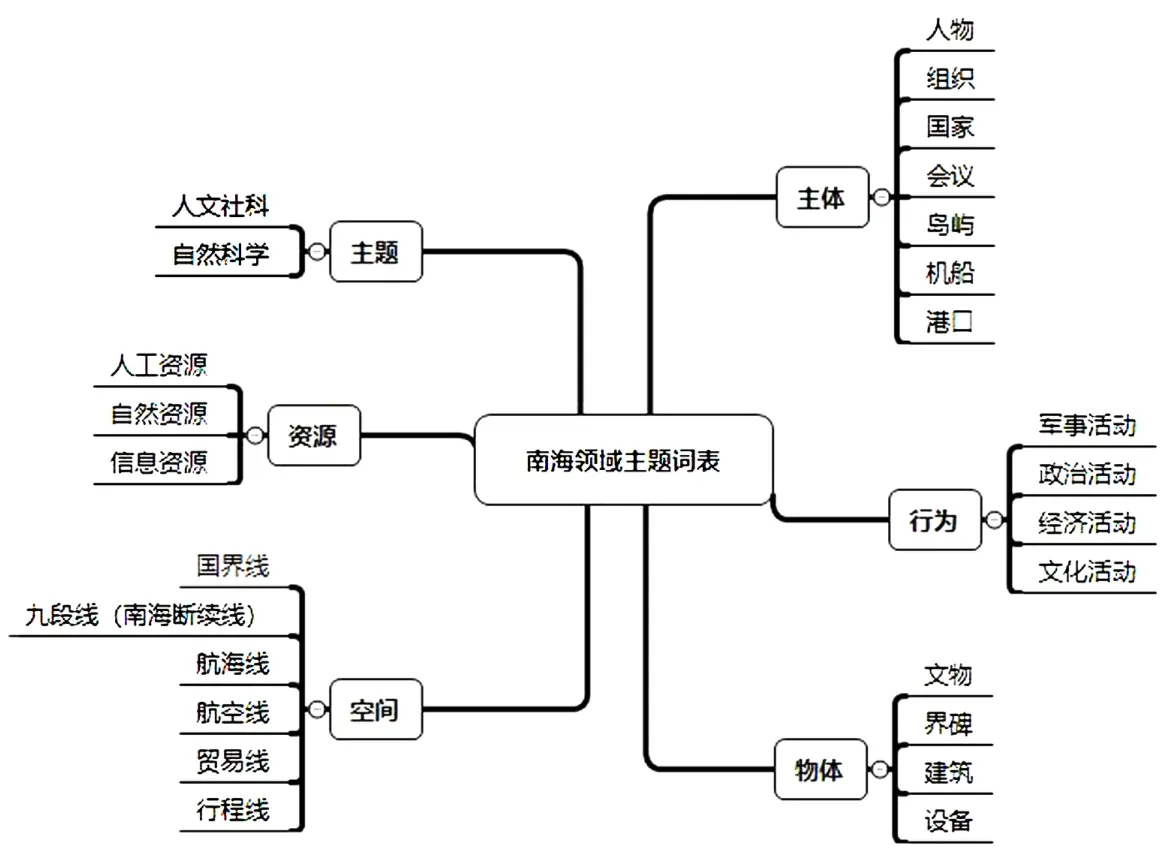
图4 南海领域主题词表的顶层框架结构
(1)主体。南海文献资料中涉及较多重要的专有名词,这些名词在知识单元中充当主语或者宾语的角色。其中,“主体”是历史事件的发起者或参与者。除了常见类目“人物”“组织”“国家”以外,对分词识别精度较低的主题词进行统计分析,得到“岛屿”“会议”“机舰”“港口”类目。这些类目体现了南海领域区别于其他领域的特征。
(2)物体。“物体”主要指南海海域内的实体。在南海维权视角下,特指文物、界碑、建筑以及设备。这些实体背后记录了各国在南海活动的历史痕迹。
(3)行为。南海领域事件是发生在某个特定的时间点或时间段、某个特定的南海地域范围内,由一个或者多个角色参与的、一个或者多个动作组成的事情或者状态的改变,是南海历史的重要构成。而事件文本中的谓语动词即事件触发词是区分主体立场、确定事件性质的重要依据。这些触发词代表相应的南海领域“行为”,即主体为实现某种目标而组织的各类军事、政治、经济、文化领域的活动。例如,1933年4月,法国侵占了我南沙群岛南威岛附近各小岛。“侵占”这一事件触发词反映了此事件属于军事活动。1951年9月18日,周恩来总理兼外交部长代表中国政府郑重声明,旧金山对日和约由于没有中华人民共和国参加、准备、拟制和签订,中国政府认为是非法的、无效的,因而是绝对不能承认的。“声明”这一事件触发词则反映了此事件属于政治活动。
(4)资源。“资源”既包括物理层面的人工资源和自然资源,也包括社会层面的信息资源。人工资源是各国在南海海域开展活动的产物,如人工岛礁、军火资源以及贸易资源等;自然资源则是各国争夺南海主权的动因之一,主要包括矿产资源、植物资源以及动物资源等;信息资源是南海活动积累起来的信息要素,包括条约判例、档案照会、法律法规、图书报纸、文献资料、图像、地图以及音频视频等。
(5)主题。“主题”分面用于区分南海相关概念的学科归属,除了包括与南海直接相关的历史学、政治学、外交学、法学、军事学、图书情报与档案管理学等人文社会科学领域外,还包括地理学、海洋科学、天文学、地质学等相关自然科学领域。前者主要研究南海领土划分、主权归属与信息资源管理等主题,后者则侧重南海自然资源环境等问题。
(6)空间。本文将国界线、九段线(南海断续线)、航海线、航空线、贸易线以及行程线作为独立于“主体”分面的“空间”分面,强调这些分界线与行程线在领土划分中的参考价值。
上述逻辑关系结构区别于现有基于学科类别的传统分类体系,是具有南海领域特色的主题词表结构。
4.4 南海候选词集构造与主题词确定
根据获得的语义词典对文献资料及新闻文本进行候选词抽取,构造候选词集,随后根据南海领域研究需求设立选词标准,确定主题词。
4.4.1 候选词识别
(1)文献数据的候选词识别
考虑到文献数据庞大,为了提高候选词的识别精度、平衡全面性与准确性,本文将文献数据分两部分进行候选词抽取。第一,由于南海领域的文献资料具有一定的法律和证据属性,本文首先人工筛选793篇权威法律学科文献进行知识单元分解与人工标注,获得较小样本下候选词识别结果,防止样本量过大引起的识别结果分散性。知识单元分解时,将文献全文文本以句号为切分点,利用BERT+BiLSTM+CRF模型对知识单元进行实体抽取。根据上述流程,共识别命名实体2825个,经过去重处理后得到候选词1269个,其中国家和人物类词汇369个,事件类词汇214个,条约和会议类词汇307个,时间类词汇69个,岛礁类词汇310个。第二,进一步以所有文献数据为对象开展词频统计分析,共获得5090个词汇。其中,词频大于150的高频词汇共14个,频次最高的3个关键词依次为“南海”(1033)、“主权”(315)、“争端”(280);中频词(3≤词频≤150)与低频次(词频≤3)的数量分别为1502个与3574个。为了实现候选词的语用和语义价值,选择中频词进一步丰富候选词集。
(2)新闻数据的未登录词识别
采用基于SNS(Social Network Sites)的文本数据挖掘技术对新闻文本进行成词提取,并通过与候选词集对比获得未登录词(即没有被收录在词表中但需要发现出来的词)。基于SNS的文本数据挖掘技术[39]利用信息熵和互信息判断某一个单词的成词概率。“信息熵”和“互信息”都来源于香农的信息论,以单词为例,“信息熵”主要表示一个单词成词的概率,成词概率越大,它的不确定度就越小,那么它的信息量就小;而“互信息”用于测度两个单词的相关性,可以理解为某一个单词中包含的关于另一个单词的信息量,信息量越小,它的不确定度就越小,那么它们的成词概率就越大。
本文采用信息熵主要计算单词和其左右字搭配的自由度,即左信息熵和右信息熵,其计算方法[40]如公式(1)和(2)所示。采用互信息计算单词的内部凝固度,其计算方法[41]如公式(3)所示。之后,对左右信息熵和互信息值进行求和,通过设置一定的实验阈值获得成词结果。如果一个单词左右信息熵都高(表示其与左右词汇搭配丰富),并且内部凝固度也非常高(表示其单词内部固定),则表明这个单词成词的概率较大。
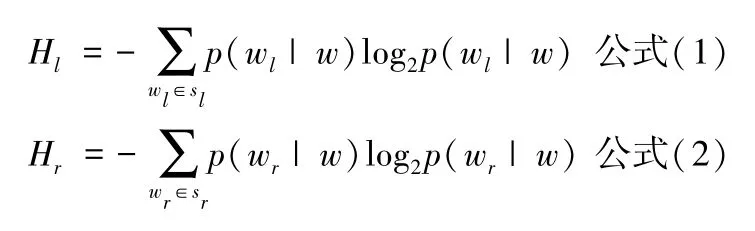
其中:sl是单词w的左邻接字集合;wl是sl中的元素;sr是w的右邻接字集合;wr是sr中的元素。如果单词的左右熵都较大,则说明与该单词搭配的左右相邻的字集合比较丰富,单词与相邻字集合构成词的概率较低。如果单词的左右熵中有一个较小,则表示与该单词搭配的相邻字集合频率分布并不均匀,此时,单词与相邻频率较高的字集合组成词的概率较高。
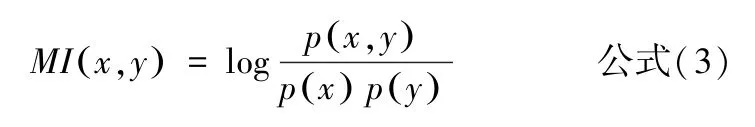
其中,MI表示互信息值,p(x,y)表示两个相邻单词x和y共同出现的概率,p(x)和p(y)表示单词x和单词y单独出现的概率。MI越大,说明单词x和y的内部凝固度越大,单词x和y构成词的概率越大。
基于上述原理计算2400个新闻数据的左信息熵、右信息熵以及内部凝固度以获得成词集合。实验参数如表3所示,实验结果如表4所示。经过与候选词集的对比、筛选和去重之后,最终获得的未登录词如表5所示。综合上述,从文献数据及新闻文本中共抽取候选词2788个。
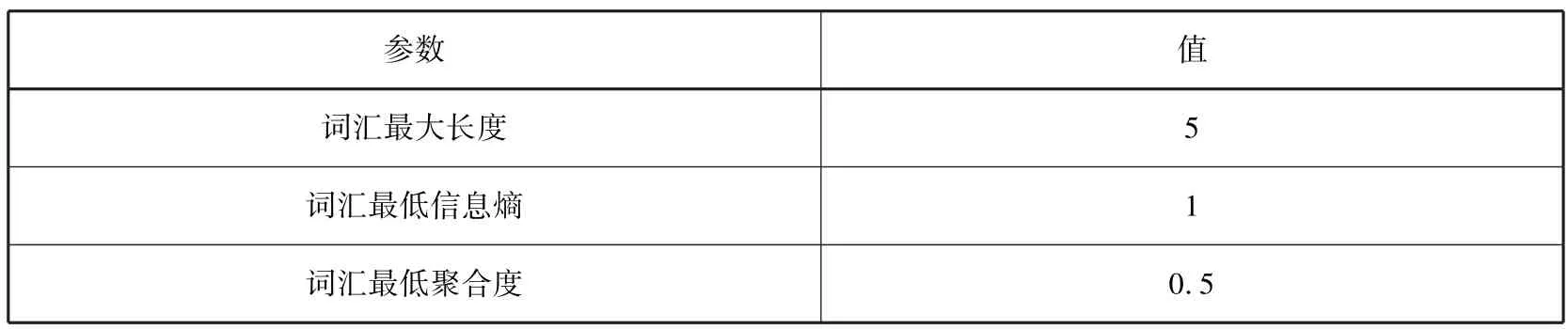
表3 基于SNS的文本数据挖掘模型参数
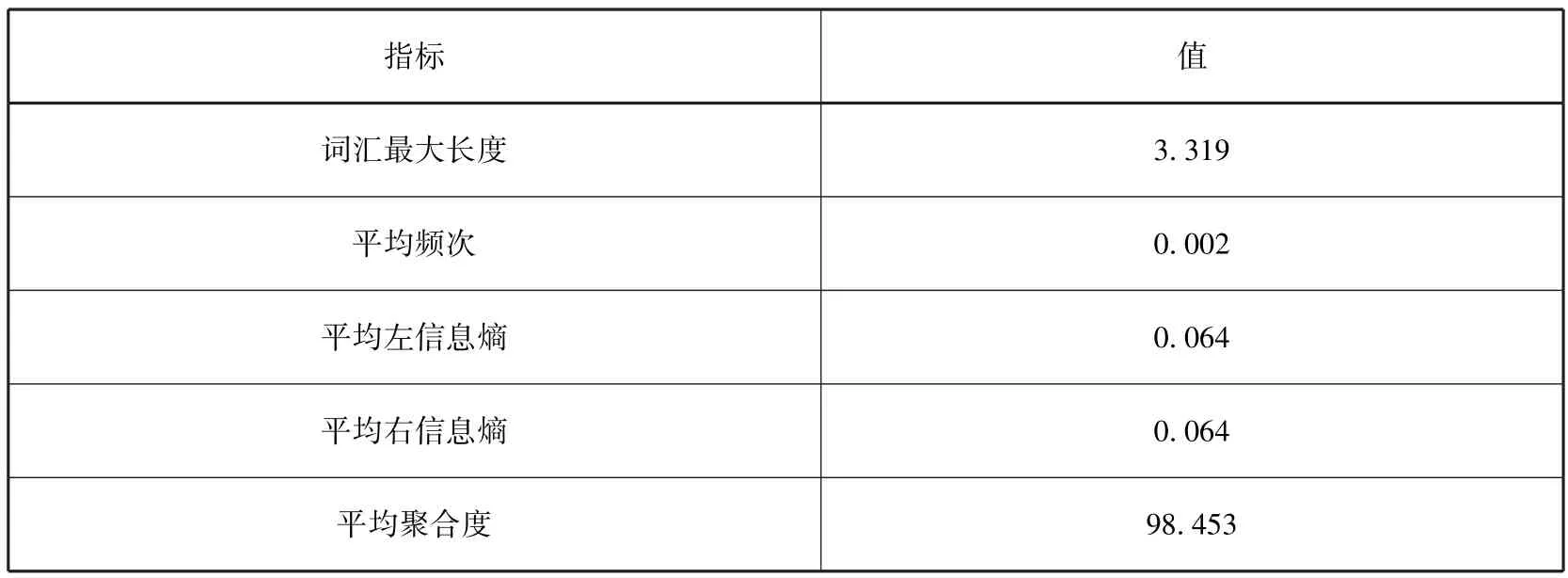
表4 成词提取结果
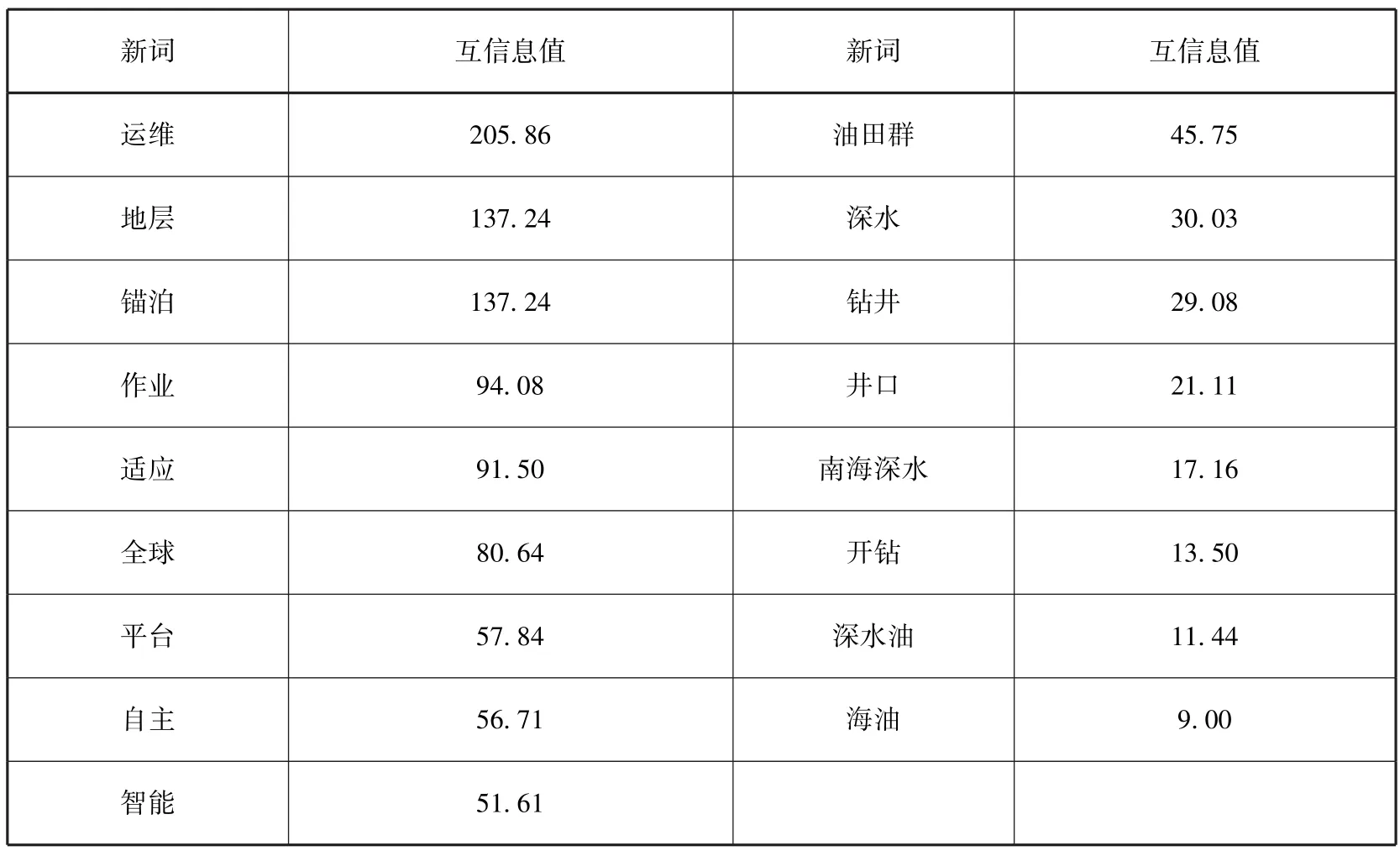
表5 未登录词
4.4.2 主题词确定
根据宜实不宜虚、范围宜小不宜大、构成宜短不宜长、时效宜新不宜旧、交叉组配法、语义、语法、可获得性、互操作性等原则[42,43],本文从词义、词性、词长、词用4个方面对主题词的重要性与合理性进行定量表示,提出南海文献资料实体选词标准如表6所示。其中,词义、词用分别反映主题词的概念明确性与相关性,词性及词长则分别反映特定术语充当主题词的易用性与代表性。
根据选词标准对所获得的2788个候选词进行筛选和归类,当候选词有多重语义关系时,利用组配规则进行标引。随后,由领域专家对新增术语进行审核,保留合格词汇,删除不合格词汇,最终确定主题词2744个。
4.4.3 “行为”细分类目确定
正如前述,“行为”细分类目被划分为各类军事、政治、经济、文化领域的活动。本文采用共现聚类法对“行为”主题词进行词间关系识别以确定具体类目,具体流程为:(1)选取特定分面、类目中的主题词为词间关系分析对象,建立共现矩阵;(2)通过聚类分析,获得主题词之间的链接强度;(3)以链接强度作为主题词之间的关联强度。根据聚类结果并辅以人工干预,得到不同领域的7个细分类目,如表7所示。其中,政治活动分为“管辖”“表态或说明”“司法”3个子类目;经济活动分为“开发”与“贸易”2个子类目。词汇链接强度结果如表8所示,其中,链接强度排名前三的“声明”“举行”“磋商”均属于政治活动,分别归属于“表态或说明”“管辖”“司法”子类目;链接强度排名第四的“侵占”则属于“军事活动”。由此可见,政治活动和军事活动数量较多,这与南海现状较为一致,进一步反映了本文“行为”细分类目划分的合理性。在避免概念碎片化的基本原则下,采用机器辅助的半自动协同编制策略结合三轮专家咨询,完成了南海领域主题词表的构建,其规模如表9所示。根据主题词表的各细分类目,可以对特定南海词汇进行多维描述,具体标引示例如表10所示。
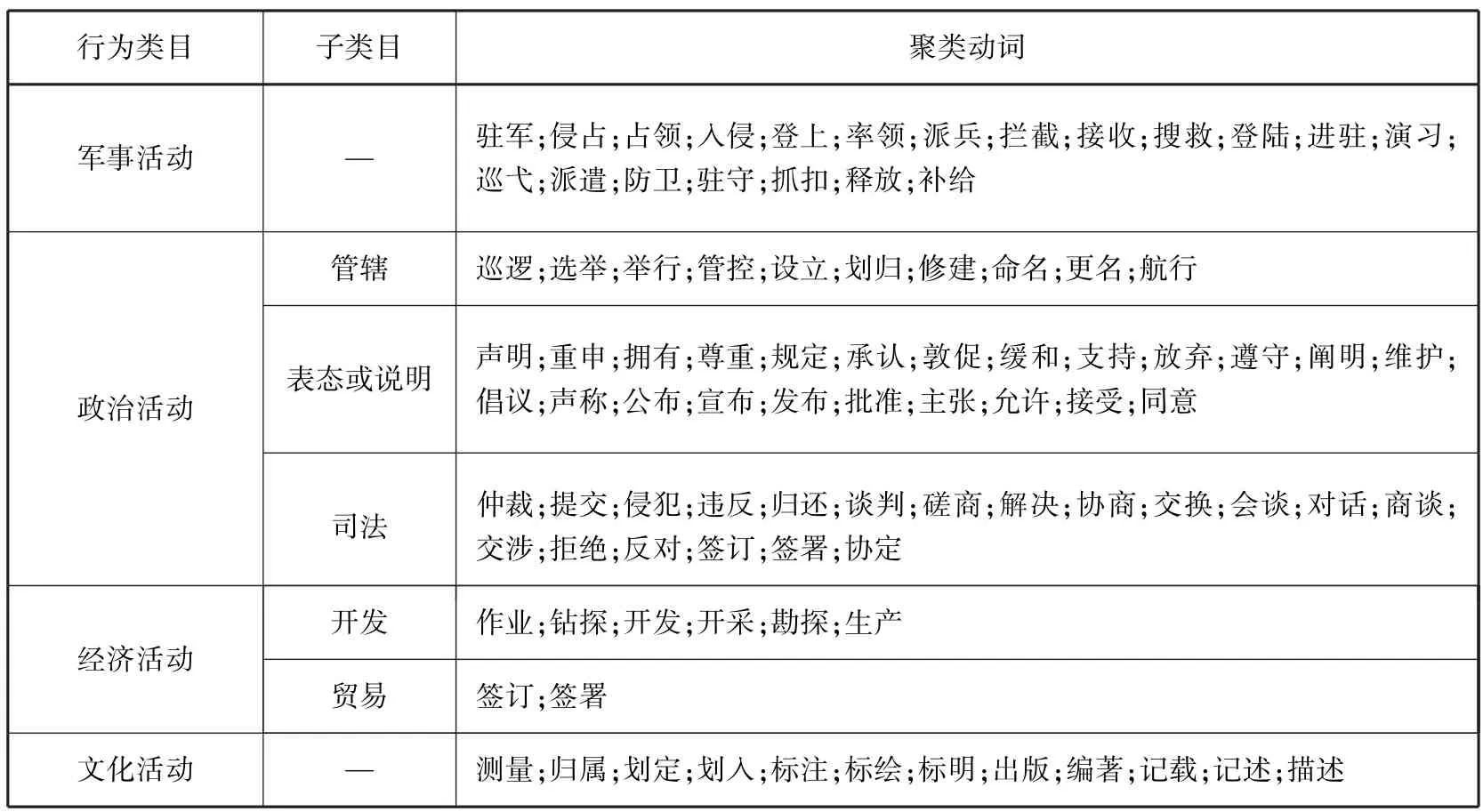
表7 共现聚类结果
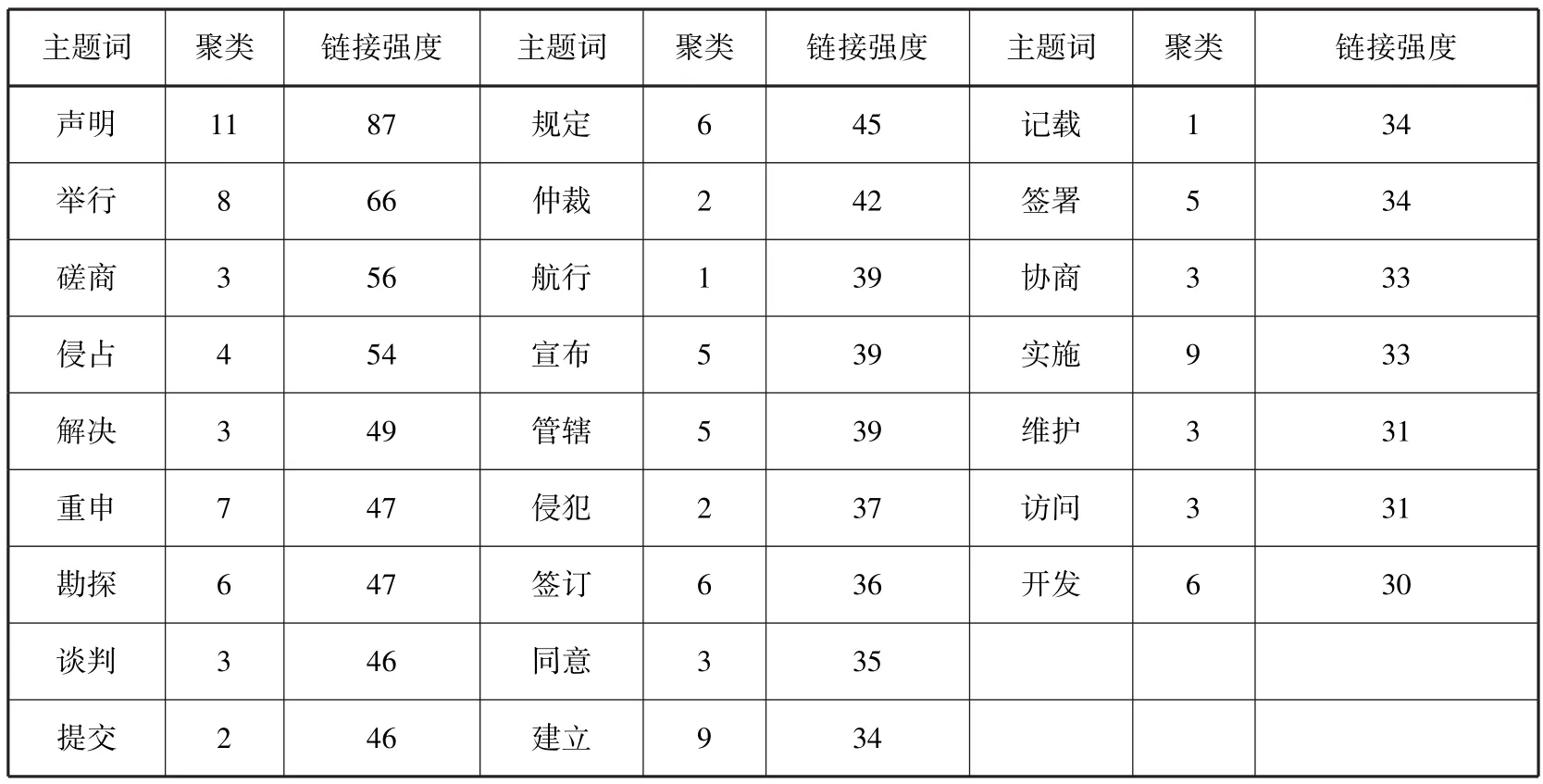
表8 链接强度大于30的“行为”主题词
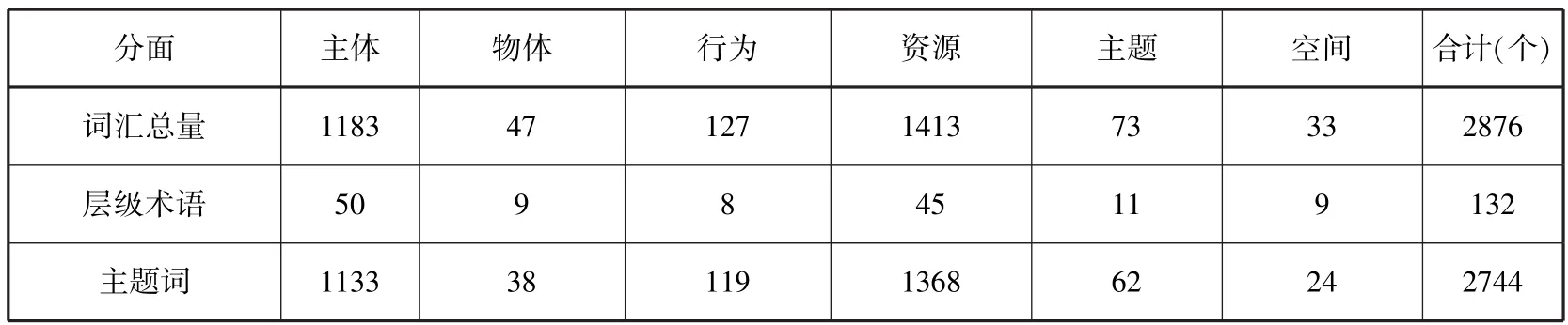
表9 南海领域主题词表规模

表10 南海领域主题词标引示例
4.5 主题词表可视化
根据南海领域主题词表进一步构建本体模型,实现词表的可视化,并针对主体、行为、物体、空间等分面定义概念类以及子类,根据分面下属类目定义对象属性和数据属性。流程为:(1)根据类目主题词定义属性值域及关联范围,生成关联标签;(2)根据关联标签,进行复合维度标签的语义关联,形成本体模型;(3)加载主题词表本体模型(rdf格式)。根据这一流程,得到南海领域主题词表的本体模型(局部)如图5所示,其命名空间(NameSpace)如图6所示。
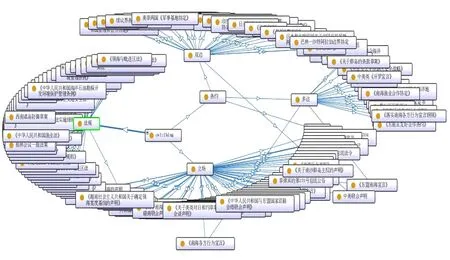
图5 南海领域主题词表本体模型(局部)

图6 命名空间(部分)
5 总结与展望
在南海局势司法化与国际化趋势下,梳理南海领域核心概念与知识脉络是我国南海重大战略的迫切需求。本文围绕南海领域主题词表开展研究,构建南海文献资源组织的底层描述逻辑。所建立的主题词表涵盖了南海历史性主权、法理维权、地名考证、地学分析、资源开发、历史考古、多模态数据融合等南海相关研究视角,可促进南海领域细粒度元数据描述、领域知识图谱构建等研究创新,加快南海信息资源组织以及南海知识发现的语义化进程,推动信息组织方法在国家战略需求中的应用实践。未来,将基于该词表开展南海文献资料的自动目录生成、多源异构数据的知识关联等研究。
