基于线性注意力机制的单样本生成对抗网络研究*
2022-11-17赵红东杨东旭徐柯南任星霖封慧杰
陈 曦,赵红东,2,杨东旭,徐柯南,任星霖,封慧杰
(1.河北工业大学电子信息工程学院,天津 300401;2.光电信息控制和安全技术重点实验室,天津 300308)
1 引言
图像分析作为机器学习一个特别重要的应用领域,如何利用已有的信息合成出新的图像是该领域的重点研究内容。2014年,Goodfellow等人[1]创造性地利用零和博弈的思想提出了一种新的网络模型——生成对抗网络GANs(Generative Adversarial Networks)。经过不断的发展,GANs衍生出了许多优秀的模型。其中,将卷积神经网络引入GANs模型取得了巨大的成功[2]。传统的GANs训练需要海量的训练样本[3 - 5]。过去一段时间,研究人员将GANs生成样本的质量与训练集的容量进行绑定,认为只有海量的训练样本才可以训练出稳定的模型。但是,大多数情况下研究人员无法获得足够多的样本。因此,少样本甚至单样本训练逐渐成为关注的重点。在传统的少样本GANs训练中,通常会出现具有混合特征的生成图像,例如生成的小狗图像具有房子的特征信息[6]。出现这种现象的原因是生成器G(Generator)和判别器D(Discriminator)更多的是通过局部信息而非全局信息进行参数迭代。为了克服大量训练样本难以获取的困难,文献[7]在少样本研究的基础上提出了一种单样本学习自然风景的网络模型SinGAN(Learning a Generative Model From a Single Natural Image),该模型可以通过单样本学习到图像的基本特征并且进行生成。但是,SinGAN模型的训练时间过长不利于实际应用。研究人员想到如果模型可以尽早获取训练样本的全局信息,这样更有利于训练收敛,从而达到缩短训练时间的目的。Vaswani等人[8]在2016年提出了一种可以抓取更远距离特征的提取结构——自注意力SA(Self-Attention)机制。在2019年,Zhang等人[9]将此结构应用至GANs模型实现了自注意力和生成对抗网络的融合SAGAN(Self-Attention for GANs),在ImageNet数据集[10]上取得了巨大成功。但是,应用自注意力机制意味着加深网络层数,需要更多的计算资源。
为了解决上述问题,研究人员将自注意力机制中的2个全卷积层用线性层代替,这种结构能大幅降低计算次数[11]。于是,本文使用一种更加轻量的注意力方法,并将其命名为线性注意力LA(Linear Attention)机制,简称LA方法。
对于单样本生成对抗网络模型而言,模型的稳定性更加重要。研究人员在SAGAN中已经证实了光谱归一化SN(Spectral Normalization)[12]对GANs模型的稳定性发挥了巨大作用。此外,本文还使用控制变量法对模型的各项性能进行了大量测试,评测结果详见本文第4节。
2 相关工作
近年来,计算机视觉领域内针对少样本训练GANs开展了诸如文本生成图像、图像超分辨和图像编辑等多项研究[13 - 15]。Shaham等人[7]提出的SinGAN模型是第1个将自然图像引入基于GANs内部结构的网络模型,并且对图像特征进行了详细的描述。最近的研究表明,在单样本上训练模型可以学到图像的基本特点,并且生成具有训练图像基本特征的高质量图像。但是,鉴于单样本生成对抗网络的模型依旧很少,现有较为成熟的大多数都只适用于纹理图像,对于特征信息复杂的样本图像生成结果依旧不理想。针对SinGAN模型存在的问题,文献[16]提出了新的解决方案,缩短了模型的训练速度。目前,用于单样本训练生成对抗网络的模型中,比较成熟的有SinGAN和InGAN(Internal GAN)[13],它们都是基于对图像整体结构的把控以及生成图像和真实图像之间双向相似性度量进行图像生成的。
最近,注意力模型活跃在计算机视觉的各个领域中,并发挥了其显著优势。其中,作为注意力模型中的代表,自注意力模型可以有效地学习全局的依赖结构,尤其在单样本任务中学习到有效的全局依赖结构显得十分重要。Parmar等人[17]提出了一种添加了自注意力机制的图像到图像的转化模型来实现图像生成。文献[18]建立了一种添加了自注意力机制的最先进的图像翻译模型。Wang等人[19]设计了一种包含自注意力机制的空间到时间独立且无局部信息的音频模型。文献[20]提出来的Attn-GAN对输入的顺序信息进行编码处理,但是自注意力机制并不需要此步骤。SAGAN模型是一种基于自注意力机制的GAN模型,该模型并不是基于某一特定任务,但是该模型的成功以消耗大量训练资源为代价。SAGAN针对模型训练不稳定的问题提出了诸多解决方法,在稳定训练模型方面为本文提供了新的思路。此外,文献[21]提出将光谱归一化方法应用至判别器模型中,以此来防止Lipschitz出现崩溃,该模型在ImageNet数据集的有条件图像生成方面取得了巨大成功。文献[22]对自注意力方法进行了改进,并将其应用至GAN中,其相较于SAGAN并没有太大的性能提升,但所需要的计算资源却远远小于SAGAN。受到上述思想的启发,本文设计了一种新的线性注意力模型,并将其应用至单样本生成对抗网络中,实验结果表明,该模型可以有效学习全局结构和图像内部更大范围的特征结构。
3 模型构建
生成对抗网络包含2个主要的结构模型:生成器和判别器。生成器是利用已有信息生成具有样本特征的新图像。判别器更像一个简单的二值分类器,其目的是将输入样本中的假样本找出来,并且利用反馈机制更新生成器的参数,使生成器可以输出更加真实的图像。传统的生成对抗网络模型的目标函数如式(1)所示:
Ez~PZ(z)[log(1-D(G(z)))]
(1)
其中,z表示随机噪声,x表示训练样本,x~Pdata(x)表示训练样本x来源于数据集Pdata(x),z~PZ(z)表示噪声z来源于噪声序列PZ(z)。
3.1 自注意力模型
本节将简化后的自注意力网络和线性注意力网络进行详细对比(如图1所示),并分析网络的优缺点及其所带来的影响。接下来通过数学推导阐述各个网络模型的原理和优缺点。
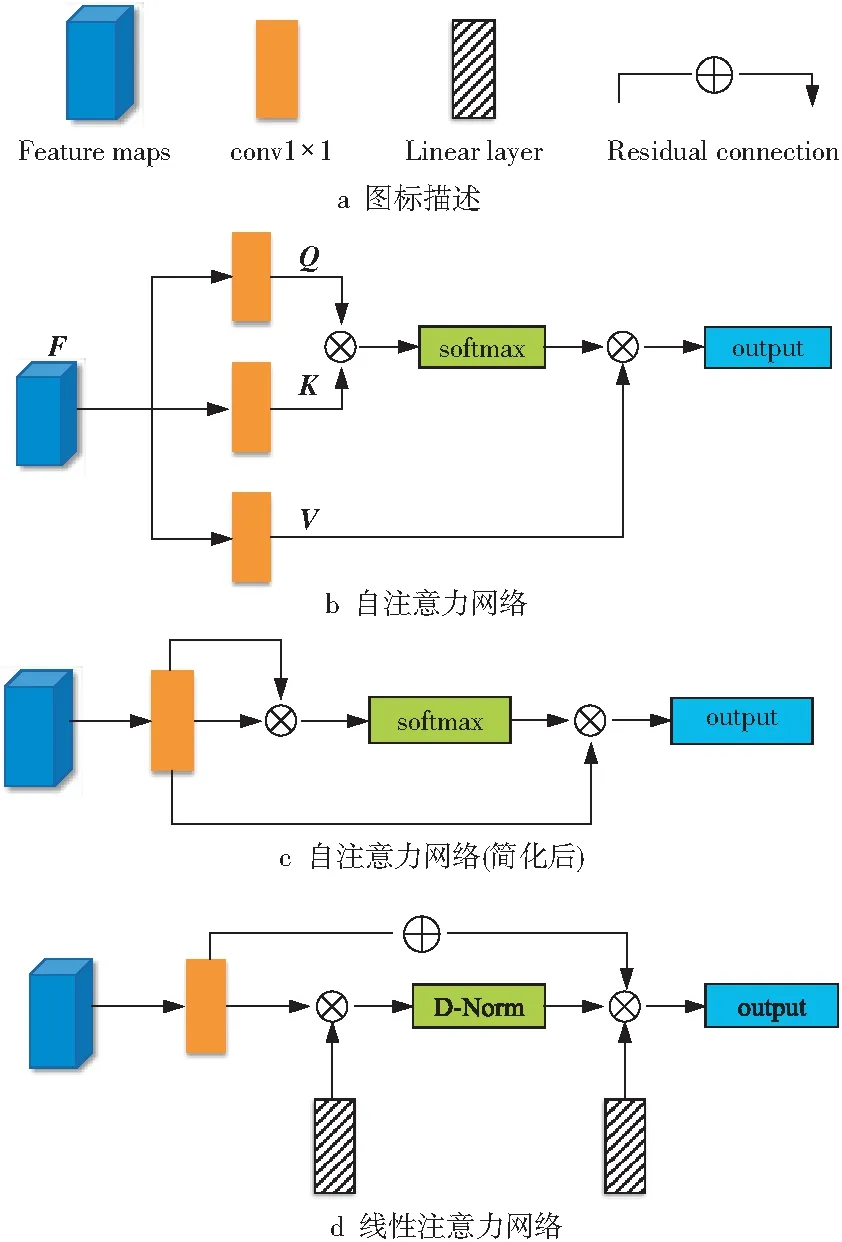
Figure 1 Structure of the attention network图1 注意力网络结构
如图1b所示的自注意力网络[8]中,输入特征F∈RN×d,其中,N表示输入像素的数量,d是输入特征的维度。自注意力网络将输入特征采样为3个特征矩阵,分别是Q,K和V。自注意力机制可以表示为式(2)和式(3):
A=softmax(QKT)
(2)
Fout=AV
(3)
其中,A∈RN×N,这是由于Q,K和V都是维度为N×d的特征矩阵;softmax(·)为激活函数;Fout为自注意力机制的输出结果,即计算得到的特征图谱。自注意力网络的计算复杂度为Ο(dN2),二次方运算意味着模型需要大量的计算资源。
目前更受研究人员关注的是如图1c所示的简化后的自注意力网络[23]。其中,自注意力中的Q,K和V仍使用与之前相同的特征矩阵。将输入的特征矩阵定义为F,则简化后的表达式如式(4)和式(5)所示:
A=softmax(FFT)
(4)
Fout=AF
(5)
注意力图谱是通过计算输入特征相似空间上的像素得到的,其输出信息中包含训练样本的特征信息。与传统的自注意力网络相比,简化后的自注意力网络省略了2个特征提取过程,结构更加简洁。
但是,即使是简化后的网络,其计算复杂度依旧是Ο(dN2),输入像素的二次方复杂性仍会导致其不能直接应用在图像上。因此,以前的工作是使用信息补丁而不是利用像素降低计算复杂度。
观察自注意力工作过程可以发现,从N到N的注意力矩阵是多余的,且大多数的计算仅与少部分像素相关。因此,本文提出了一种线性注意力代替方案,通过计算输入特征和独立线性层获得特征图谱信息。
3.2 线性注意力机制
仔细观察自注意力网络结构可发现,无论是传统的结构还是简化后的结构,它们都是通过反复计算输入特征得到特征图谱[22]。这样的设计虽然对于获得远距离特征结构有一定的益处,但是重复计算会导致大量特征信息冗余,信息利用率不高。研究人员将Q,K和V中的2个使用额外的独立线性层L1和L2代替(如图1d所示),用于解决计算过程中出现的信息冗余问题。因此,表达如式(6)和式(7)所示:
(6)
Fout=AL2
(7)
其中,L1,L2∈RH×d,其参数值会根据A进行更新。
与自注意力不同的是,线性注意力模型计算复杂度为Ο(dHN),不会出现二次方复杂计算。这样的设计大大缩减需要的计算资源,缩短了训练时间。本文提出来的方法是在像素级别进行线性运算,弥补了之前在信息补丁层面计算存在的缺陷。此外,线性注意力模型采用了残差项,这对于抑制模型崩塌十分有用。综上可知,线性注意力模型比自注意力模型更加有效,适合规模化使用。
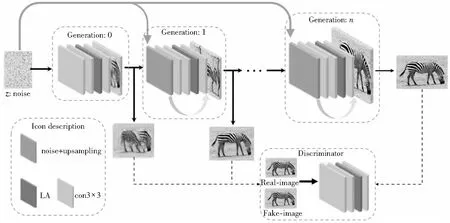
Figure 2 Structure of single sample generative adversarial network based on attention using linear layers图2 基于线性注意力机制的单样本生成对抗网络结构
自注意力模型采用softmax函数对注意力图谱进行归一化处理。但是,注意力图谱是通过特征矩阵的乘法得到的,对输入特征十分敏感。为了避免这个问题,文献[24]提出了一种新的双重归一化方法,分别对行和列的像素点进行了归一化。其函数表达式如式(8)~式(10)所示:
(8)
(9)
(10)
本文将线性注意力模型应用至单样本生成对抗网络的生成器和判别器中,还将WGAN-GP的损失函数[25]和光谱归一化应用到生成器网络中,用来稳定模型,防止出现模型崩塌等问题。光谱归一化的Lipschitz函数的梯度上界被限制,使得梯度函数更加光滑,在神经网络优化过程中参数变化会更加稳定,不容易出现梯度爆炸。
3.3 LA模型
本文的目标是建立一个可以捕获到训练样本内部统计数据的生成器模型。与传统的GANs任务不同,此处的训练集不是数据库中的全部数据,而是单幅样本图像,且要求模型关注样本更大范围内的特征信息,以使输出图像结构合理化。
此外,大量实验表明,金字塔结构和多尺度的训练对提升图像的质量和训练速度具有显著作用[26]。其中,最为有效的便是搭建拉普拉斯金字塔结构的生成器模型,生成的样本图像从低分辨率逐渐向高分辨率过渡。生成器每一层中添加随机噪声,以保证输出图像的多样性。此外,相比于SinGAN模型,文献[27]提出不需要冻结生成器之前的参数权重。实验结果表明,这种设计有利于改善生成图像的质量。
本文搭建了如图2所示的模型,并将线性注意力机制应用至模型中。刚开始训练时,生成器从低分辨率图像开始输出,直至图像达到设定的分辨率。模型的训练机制使用了多尺度训练方法。如图2所示,将生成器模型以3个为1组进行绑定训练。例如,当模型训练生成器n时,已经训练好的生成器n-1和生成器n-2也会参与生成器n的训练。具体而言,就是生成器n-1和生成器n-2的权重参数还会随着生成器n的训练再更新,并不对模型的权重进行锁定。其中,权重的变化主要体现在学习率的变化。本文分别设定了2种学习率缩放因子进行比较,分别是0.1和0.5。将线性注意力机制应用至模型中有3种不同的设计方案,即分别将其放置在3个不同卷积层后,依次将其记为第1、2、3种方案。本文对上述3种方案进行了实验比较,结果显示:第1种方案的模型依旧难以快速抓取全局信息,生成的图像质量差且结构布局不合理;其余2种方案的输出结果并无太大差异,但是第3种方案获取的信息更多,需要更多的训练资源与训练时间,且获取太多的特征信息降低了生成图像的多样性,使得输出图像的布局与原始图像的过于相似。因此,本文选择第2种方案为最终的方案。此外,本文将残差网络的设计理念应用至模型中(如图2所示),在每一个生成器的最后一个卷积层加上对上一层的输出上采样结果与随机噪声的和。
最近的工作发现光谱归一化对稳定GANs模型的训练尤其重要。但是,如果仅在生成器中应用光谱归一化方法,会破坏生成器中的参数更新和梯度更新。实验发现,将光谱归一化放置在生成器和判别器中,可以减少判别器更新生成器参数的次数,因此会有效降低训练过程中的资源消耗,训练模型的表现也更加稳定。其中,单样本生成对抗网络的目标函数如式(11)和式(12)所示:
LD=-E(x~Pdata(x))[min(0,-1+D(x))]-
E((z~PZ(z)),(x~Pdata(x)))[min(0,-1-D(G(z),x))]
(11)
LG=-E((z~PZ(z)),(x~Pdata(x)))D(G(z),x)
(12)
4 实验
本节将模型在不同风格的图像上进行测试。并且利用控制变量法对其进行对比,分别对比不同训练阶段的生成结果以及不同学习率缩放因子对模型输出结果的影响。关于评价方法,选择文献[6]提出来的SIFID(Single Image Fréchet Inception Distance)。相较于IS(Inception Scores)和FID(Fréchet Inception distance)等其它生成对抗网络评价指标,SIFID的测评机制更加合理。
FID的提出者通过预先训练的空间来提取全连接层之前的向量作为图像的特征[28]。IS则是通过计算生成图像与ImageNet中训练图像相似性进行判定。由于实验并未采用ImageNet数据集,因此这样的评价设置并不适用于本文模型。众所周知,预先训练好的神经网络顶层可以提取图像的高级信息,能一定程度上反映图像本质。SIFID通过计算真实图像和生成图像在特征层面的距离来衡量生成图像的质量,以及判断纹理结构是否合理,其数学表达式如式(13)所示:
SIFID=‖μr-μg‖2+
(13)
其中,μr表示真实图像的特征均值,μg表示生成图像的特征均值,Σr表示真实图像特征的协方差矩阵,Σg表示生成图像特征的协方差矩阵。SIFID本质上计算的是真实图像、生成图像提取的特征向量之间差值的均值和协方差矩阵的均值。当生成图像和真实图像特征相近时,均值之差的平方越小,协方差也越小,SIFID的值越小。这意味着生成图像的分布更接近真实分布。
4.1 结构设计及实验细节
实验中将生成图像的尺寸设置为250×250。光谱归一化被默认应用至生成器和判别器中。对于生成器和判别器,实验中使用β1=β2=0.999的Adam优化器[29]进行训练。默认生成器和判别器的学习率均为0.000 5。模型对学习率进行了缩放设计,即随着训练的进行,学习率也会进行更新,默认学习率缩放因子为0.1。训练网络每完成2 000次迭代记为一个阶段,默认训练阶段为3。实验是在显卡为NVIDIA GTX 1060的硬件环境下进行的。
4.2 评价模型
本节从各个方面对本文提出来的模型进行评测,主要包括模型的稳定性评价、生成结果结构是否合理及模型的训练时间等。对比测试了单样本生成对抗网络SinGAN模型、添加自注意力机制后的单样本生成对抗网络SA-G/D模型及使用LA模型的单样本生成对抗网络LA-G/D模型在不同数据集上的表现。
实验在公开数据集Generation[6]、Places和CIFAR-100数据集上进行,上述数据集中包含各种类型和风格的图像,可以很全面地检验模型的稳定性和鲁棒性,部分实验结果如图3所示。研究发现,无论是自注意力还是线性注意力模型都能在较低阶段快速获取训练样本的全局结构,如图3a~图3c所示。此外,通过对比使用不同学习率缩放因子的模型生成的结果发现,较高的学习率缩放因子对模型的复原样本结构有显著帮助。

Figure 3 Comparison of the results among different models图3 不同模型的生成结果对比
在评价结果选择时并未区分不同的数据集,而是按照不同的模型、阶段和学习率缩放因子进行。其中,实验分别随机选取每个模型的50个生成样本测评其SIFID值并取平均值(如表1所示),得到不同模型各个阶段的SIFID值曲线图,如图4a~图4c所示,SIFID值越小则代表模型表现越好。对比之下,LA-G/D(将LA应用至生成器和判别器)模型要略优于SA-G/D(将自注意力模型应用至生成器和判别器)模型。并且,与SinGAN模型相比较,本文设计的LA-G/D模型的SIFID值、训练时间和生成图像视觉效果均有大幅改善,远超过SinGAN的评测结果,并与图3所示的生成结果相符合。
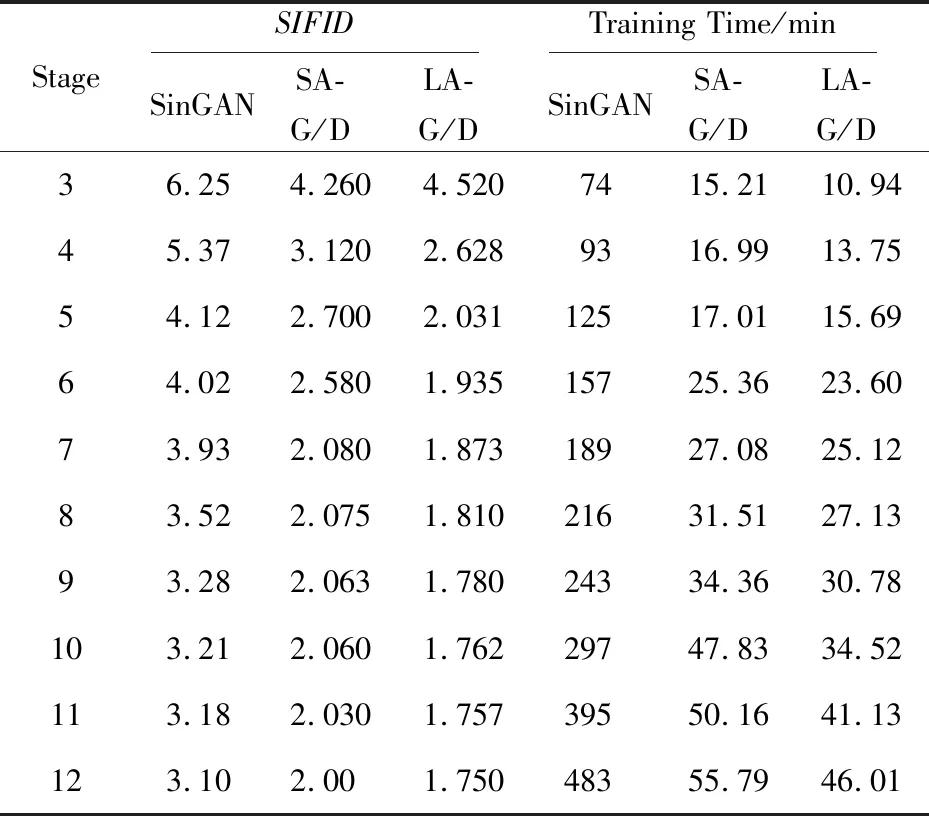
Table 1 SIFID and training time of different models (average value)
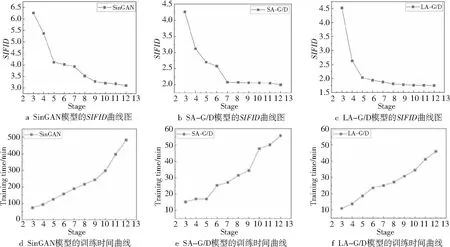
Figure 4 Comparison of SIFID and training time among different models图4 不同模型的SIFID值和训练时间对比曲线
LA-G/D模型由于其在注意力模型中采用了独特的线性结构,相较于SA-G/D模型节省了更多训练时间。实验分别对比了SinGAN、SA-G/D和LA-G/D模型不同阶段的训练时间,如图4d~图4f所示。以最高训练阶段为例,SA-G/D模型的训练时间只需SinGAN模型的1/9,而LA-G/D模型的训练时间只有SinGAN的1/10。实验结果表明,LA-G/D模型在训练时间方面具有绝对优势。
综上所述,本文提出的基于线性注意力机制的单样本生成对抗网络模型较之已有模型具有显著优势,在评价指标SIFID和训练时间上均改善明显。
5 结束语
本文提出了一种基于线性注意力机制的单样本生成对抗网络模型。首先,该网络仅需要单样本就可以完成模型训练,避免了需要获得海量数据集所带来的困难。然后,模型中应用了一种全新的线性注意力机制,相较于传统的卷积注意力模型,避免了大量卷积计算带来的信息冗余,提高了信息的利用率。其次,该模型相较于已有的网络模型,更加容易在低阶段获得训练图像的全局结构,这对输出图像纹理结构是否合理十分有用,且更加有利于节省训练时间。最后,本文在模型中借鉴了残差网络的设计思路,将带有残差项的线性注意力机制和光谱归一化方法应用至模型中,以抑制模型发生崩塌的风险。本文的工作依旧有改进的空间,之后将着重研究如何构建基于线性注意力模型的单样本多任务的生成对抗网络结构。
