基于Gist和IPCA算法的多文种离线手写签名识别*
2022-11-17麦合甫热提吾尔尼沙买买提朱亚俐库尔班吾布力
韩 辉,麦合甫热提,吾尔尼沙·买买提,朱亚俐,库尔班·吾布力,
(1.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆多语种信息技术重点实验室,新疆 乌鲁木齐 830046;3.新疆大学教务处,新疆 乌鲁木齐 830046)
1 引言
生物特征为人体所固有且不可复制、不会失窃和不会被遗忘,利用生物特征进行身份识别安全、可靠、准确。手写签名作为一种有效并且被法律认可的生物行为特征,被广泛应用于金融、司法、银行和保险等各个领域[1]。手写签名根据数据获取方式的不同分为在线手写签名和离线手写签名[1,2];根据数据组成和分类方法的不同可分为手写签名识别和手写签名鉴别[2]。手写签名自被提出可以用于进行身份识别至今,针对世界主流语言文字的研究已经取得了丰硕的成果,但是对于我国少数民族语言以及多文种混合的签名识别研究仍处于发展阶段。
Ubul等人[3]通过提取维吾尔文离线手写签名的多维改进的网格信息特征,并采用欧氏距离ED(Euclidean Distance)、K近邻KNN(K-Nearest Neighbor)和贝叶斯网络3种分类器对维吾尔文离线手写签名进行分类识别,最终得到了93.53%的平均准确率。Pal等人[4]提出了一种基于前景和背景的双语脱机签名识别技术,采用梯度直方图HOG(Histogram of Oriented Gradient)和Zernike矩等特征,在支持向量机SVM(Support Vector Machine)分类器下得到了最高为97.70%的识别率,但是该工作只进行了文种的识别,并没有实现把签名图像分类到用户个体。Serdouk等人[5]从CEDAR和GPDS-300这2个数据集中提取了图像的梯度局部二值模式GLBP(Gradient Local Binary Patterns)并利用SVM分类器进行签名鉴别,最终在2个数据集上分别得到了9.58%和14.01%的平均错误率。刘利利[6]采用形状上下文特征在GPDS960和自建的离线手写签名鉴别数据库上进行了实验,分别得到了误拒率为9.75%、误纳率为12.89%和误拒率为12.38%、误纳率为18.27%的效果。魏佳敏等人[7]通过提取图像的静态特征和伪动态特征并进行有效融合,在极限学习机和稀疏表示的两阶段分类中取得了95.53%的平均准确率,但是该工作的缺点是分类数量少,文字形式单一。艾海提·伊敏等人[8]通过提取局部中心点和ETDT 2种特征并进行有效融合,同时使用绝对距离、欧氏距离、卡方距离和cosine距离进行分类识别,最终得到了最高为98.70%的平均准确率。Mo等人[9]提出了一种基于离散曲波变换的多文种离线手写签名识别方法,在我国2种少数民族语言维吾尔语和柯尔克孜语中实现了较好的识别准确率。
本文针对多文种混合模式的离线手写签名识别展开研究。由于离线手写签名图像有效的笔画部分普遍比较稀疏,存在大量的无效白色背景,但是目前现有的特征提取方法大多是对图像整体表层内容进行描述,这样会使得提取到的特征存在大量的冗余,不利于提高识别准确率。而如果想要提高识别准确率,则需要依赖大量的训练数据和提取多个特征并进行有效融合,这样又会造成提取的特征过多和特征维度过大,最终计算困难影响识别效率。为此,本文提出了一种基于Gist和增量主成分分析IPCA(Incremental Principal Component Analysis)算法的多文种离线手写签名识别方法,利用Gist特征对静态图像的宏观全局意义上的特征进行描述,使其在特征提取的过程中更多地聚焦到签名图像的整体布局和笔画部分,而忽略图像无效白色背景;同时,利用IPCA算法的批处理方式,把提取的数据特征逐批加载到内存中,递增式更新特征的主成分,以达到在对识别效果影响很小的情况下大大提高运行效率。本文使用汉语、英语和我国少数民族语言维吾尔语3个不同的数据集对本文方法进行实验。由于这3种语言来自不同中文的语系(汉语:汉藏语系,英语:印欧语系,维语:阿尔泰语系),所以能有效证明本文所提方法的有效性,而且本文还混合3种数据后进行了实验,最后都使用SVM分类器进行识别分类。实验结果表明,本文提出的方法即使使用少量的训练数据,无论是在单文种还是在多文种混合的数据上进行实验,其识别准确率与之前相关研究相比都表现较优。
2 离线手写签名识别
离线手写签名识别是模式识别研究领域的一个重要研究方向。类似于其他模式识别问题的实验流程,离线手写签名识别的基本步骤包括签名图像数据采集、图像预处理、特征提取、分类决策4个步骤。本文方法的具体实验流程如图1所示。
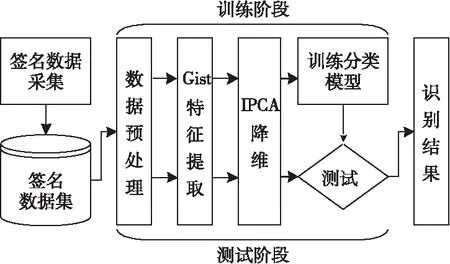
Figure 1 Experimental procedure of the proposed method图1 本文方法实验流程
(1)签名数据采集。在数据采集的过程中,首先要求每位签名者将自己的名字书写在已被等分成横七竖三共21个矩形方框的一张A4纸上。之后,把每一份手写签名样本通过扫描仪以300 dpi的分辨率扫描成电子图像,并以“.jpg”格式保存在计算机中。然后,使用切图工具将其处理成一个个单独的签名样本图像,并以“.bmp”格式24位图像保存在数据集中。
(2)数据预处理。为了更好地保留签名图像类内相似性和类间差异性,在对签名图像进行特征提取之前需要先对其进行预处理操作,以最大限度地保留签名本身的信息。本文首先依次使用高斯滤波、全局平均阈值和Unger平滑算法[10]对图像进行去噪、二值化和平滑等预处理操作;然后去除签名图像无效边缘背景,并使用最邻近插值法进行签名图像的尺寸归一化(96*384)。预处理后的图像如图2所示。

Figure 2 Pre-processing renderings图2 预处理效果图
(3)特征提取。特征提取是签名识别过程中最重要的一环,提取的特征优异与否,将直接影响分类识别的结果。本文针对离线手写签名有效特征稀疏难以提取的问题,提出了一种基于Gist和IPCA算法的多文种离线手写签名识别方法,且分别将特征维度k设置为60,80,100,120和140进行对比实验。
(4)训练和测试。本文选取每位签名者的前S(=5,8,11,14,17)个签名用于训练,其余的用于测试,使用SVM分类器对实验数据进行分类识别,并对实验结果进行比较分析。
3 特征提取与降维
3.1 Gist特征提取
“Gist”最初源自于1979年Friedman的论文[11],用来对场景进行抽象的描述。2001年被Oliva等人[12]借用来代指空间包络特征,用于对经过分块的输入图像进行离散傅里叶变换和窗口傅里叶变换,进而提取其全局特征信息。随后,在2003年由Torralba等人[13]继续研究并进行改进,用6个方向、4尺度的小波变换代替傅里叶变换进行纹理特征提取。2004年,Renninger等人[14]又采用Gabor滤波对其进行改进,用于提取静态场景图像的Gist特征。2007年,Siagian等人[15]基于生物的中央周围滤波特征,将图像分成方向、颜色和密度3种特征通道,共34个次通道,每幅图像分割为4*4共16个小模块,采用Gabor滤波算法提取图像的Gist全局特征信息。
Gist特征是一种全局的特征描述方式,它能够很好地捕捉到场景图像的整体特征。对静态场景图像进行识别时,不需要对图像进行分割和局部特征提取就可以实现快速的静态场景图像的分类[16,17]。与以往的特征提取方法不同的是,Gist特征利用Gabor变换多尺度和多方向的特性,能很好地模拟人类视觉,以尽可能地关注到签名图像的笔画和整体,并将变换后的多通道图像分别分块取平均,再将这些平均值进行直方图均衡化得到最终的特征数据。与其他单通道图像特征提取方法相比,上述方法更加全面具体,有效解决了有效特征难以提取的问题。其计算公式如式(5)所示:
(1)
(2)
kv=2-(v+2)/2π
(3)
(4)
其中,σ为常数,i为虚数单位,z表示图像矩阵中元素的坐标值。u和v分别表示对应Gabor滤波器的方向和尺度。
将一副大小为h*w的输入图像分成n*n个图像块,每个图像块g(x,y)分别与u尺度、v方向的Gabor滤波器ψ(z)进行卷积滤波,每个网格内取平均值得到一个特征,并将这些特征进行级联拼接,得到图像的Gist特征,其计算公式如式(5)所示:
Gψ,g(x,y,μ,υ)=g(x,y)⊗ψμ,υ(z)
(5)
其中⊗在此定义为卷积运算符。这样每幅输入图像就获得了u*v*n*n维的Gist特征数据。
3.2 IPCA降维
增量主成分分析IPCA算法是主成分分析PCA(Principal Component Analysis)算法的一种改进,用于解决因样本数量或特征维数大而造成的系统资源占用问题[18]。与深度学习在数据量过大时的加载方法一致,IPCA是将数据分成多个批次,然后每次都只从外存中取一个批次的数据输入到内存中,直接用新样本对已有的主成分进行增量式修正,进而得到最终的样本最优降维。
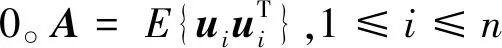
λh=Ah
(6)
其中,λ是对应的特征值。将A替换为样本协方差矩阵,对于每一个时间步长i,向量h替换为其在第m批样本向量待求的第i个特征,记为hi(m),每个批次一个样本数据,即m=1,2,…,n。令v=λh,可以得到式(7):
(7)
其中,v(m)是对v的第m步的估计值。考虑到h=v/‖v‖,并且在一开始,设v(0)=h(1)作为数据扩展的第一个方向,并令hi(m)=v(m-1)/‖v(m-1)‖,从而式(7)可以推出增量表达式及其递归形式,如式(8)所示:
(8)
其中,(m-1)/m是之前估计的权重,1/m是新数据的权重。
4 支持向量机
支持向量机SVM是一种有监督学习的二元分类的广义线性分类器[19],其决策边界是对学习样本求解的最大边距超平面。SVM通过核函数将输入数据映射至高维空间,为了将输入特征向量映射到高维特征空间,本文使用高斯径向基核函数,将问题转换成线性可分问题进行非线性分类,并使用其软边矩SVM分类方法对签名数据进行分类计算,具体实现公式如式(9)所示:
s.t.{yi(wTXi+b)≥1-ξi,ξi≥0
(9)
其中,ξi为松弛变量,用于把一些离群点向中心集中;C为惩罚因子,其值越大,对误分类的惩罚越大,这样对训练集测试时准确率就高,但泛化能力弱,反之,泛化能力较强;N表示样本个数,yi表示学习目标。经过实验对比,本文实验中设置C=1e3。
5 实验
5.1 实验数据
本文共采集和使用了3个完全不同语系的离线手写签名数据集,其中包括汉语、少数民族语言维吾尔语和西文英语。
(1)汉语离线手写签名数据集:汉语归属于汉藏语系,其特点是字与字之间有明显的间隔,单个字体的书写较为紧凑。该数据集包含160人的离线手写签名,每人21个,共3 360幅离线手写签名图像。
(2)维吾尔语离线手写签名数据集:维吾尔语归属于阿尔泰语系,其书写特点是字母与字母之间连写构成一个音节,几个音节写在一起构成一个词,词与词之间分开书写。该数据集也包含160人的离线手写签名,每人21个,共3 360幅离线手写签名图像。
(3)西文英语离线手写签名数据集:英语归属于印欧语系,其书写方式和维吾尔语大致相同,但两者字母结构完全不同。本文使用的是公开数据集GPDS Synthetic Off-Line Signature[20,21]中前160人的前21个真实签名样本图像,共3 360幅离线手写签名图像。
3个数据集共3*3360=10080幅离线手写签名图像。图3所示是本文实验数据样本图像。

Figure 3 Presentation of data samples图3 数据样本展示
在实验过程中,由于签名图像并没有先后顺序,所以本文使用每个数据集中每个人前S(=5,8,11,14,17)个签名图像作为训练数据,其余图像作为测试数据。
5.2 运行环境和评价标准
本文所有实验均在64位Ubuntu 18.04.5 LTS的环境下进行,其CPU为Intel i5-4200M,2.40 GHz,内存为8 GB,具体程序通过基于PyCharm实现。
由于本文实验的是多分类任务,所以只使用平均准确率AAR(Average Accuracy Rate)作为评价指标,其计算公式如式(10)所示:
(10)
其中,T表示所有参与测试的数据量;CT表示参与预测的数据中得到正确结果的数据量;N=10,表示本文把每次实验进行10次,并取平均值得到AAR。
5.3 结果分析
5.3.1 Gabor滤波器尺度和方向的选择
首先,本文混合3个数据集的所有数据,分别使用不同尺度u(=1,2,3,…,8)的Gabor滤波进行Gist特征提取,得到对应的8种d(=64,128,192,256,320,384,448,512)维Gist特征。其对应的识别结果如图4所示。
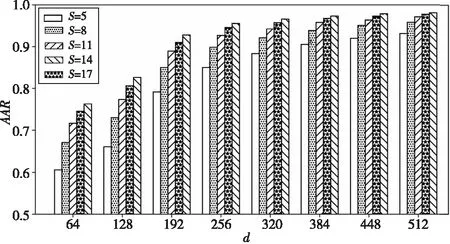
Figure 4 Experimental results of classification using Gist features with different scales图4 使用不同尺度Gist特征的分类结果
一般情况下,提取的特征维度越小,特征数据就越难以完整表示原本的图像数据,进而直接导致分类结果差。由图4可以看出,当使用1尺度4个方向的Gabor滤波器提取得到64维Gist特征时,识别准确率最高为76.26%;当提取的特征维度为384维(6尺度4个方向)时,即使训练数据个数S仅为5,识别准确率也达到了90.54%。但是,随着提取特征的维度不断增大,识别准确率增幅越来越小,而实验运行时间复杂度的增幅也越来越大。
对于不同方向的Gabor滤波器,本文使用8尺度1个方向(0°)、8尺度2个方向(0°和90°)和8尺度4个方向(0°,45°,90°和135°)进行对比,如图5所示。不难看出,使用的方向越多,提取到的特征越详细,具体识别准确率也就越高。
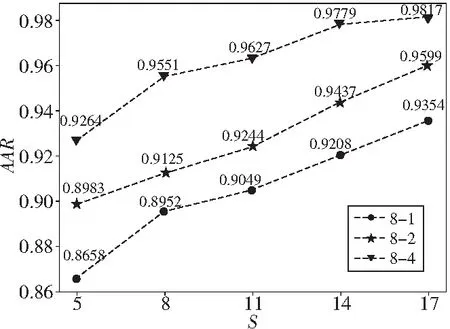
Figure 5 Experimental results of classification using different directional GIST features图5 使用不同方向Gist特征的分类结果
图6给出了当每个人的训练数据个数S为11时,不同方向的Gist特征在不进行降维的情况下的识别准确率与实验运行时间对比。
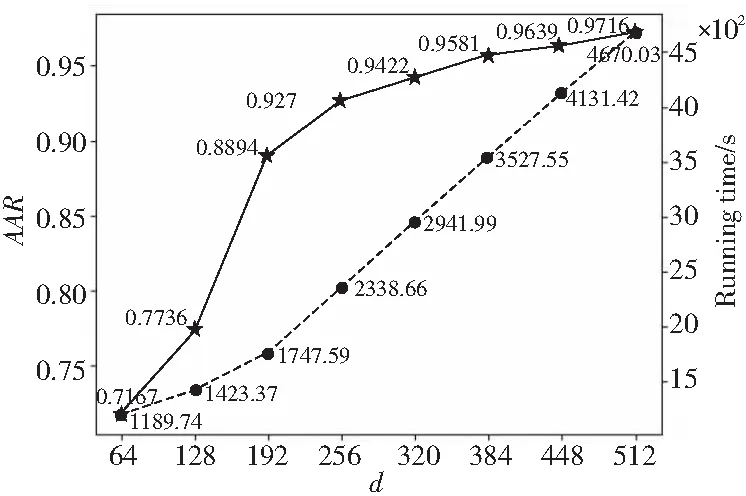
Figure 6 Comparison of running effects when S=11图6 S=11时运行效果对比
所以,本文选用8尺度4个方向的Gabor滤波器进行Gist特征提取,共得到d=512维的特征数据。
5.3.2 IPCA降维维度选择
一般情况下,特征数据降维后,其表示能力也会相对降低,而实验运行速度会相应提高。本文使用不同降维算法:主成分分析法PCA、稀疏主成分分析法SPCA(Sparse Principal Component Analysis)和核主成分分析法KPCA(Kernel Principal Component Analysis),把特征维度约减到100维后进行识别得到的实验结果如表1所示。
如表1所示,使用不同的降维算法的分类识别在识别准确率上,IPCA算法相对最低,但是只比使用PCA算法的识别准确率低了0.17%,而其实验运行时间只有使用原始特征的1/50以下,只有核主成分分析算法KPCA的1/2。在保证识别准确率变化不大的情况下,极大地提高了实验运行效率,可见这种算法在实际应用中是可行的。所以,本文使用IPCA算法进行维度约减,并利用IPCA算法批处理的能力来提高运行效率。
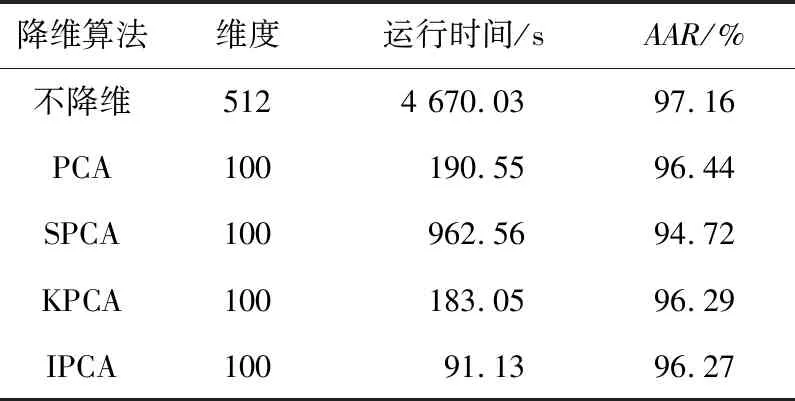
Table 1 Experimental results of classification using different dimensionality-reduction methods
除此之外,本文把提取得到的512维的Gist特征分别约减到k(=60,80,100,120,140)维,并进行识别实验。图7和图8分别为使用不同维度的Gist特征的分类识别效果对比。
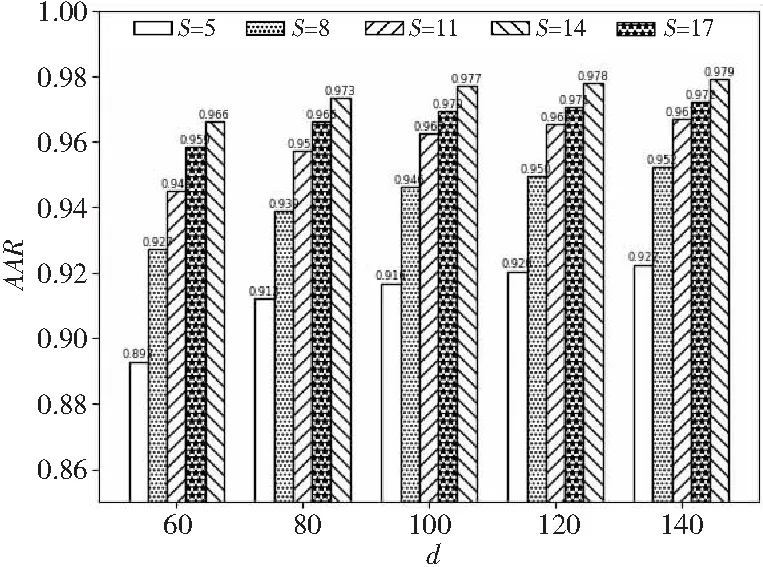
Figure 7 Recognition results of classification using different dimension features图7 不同维度特征的分类识别结果
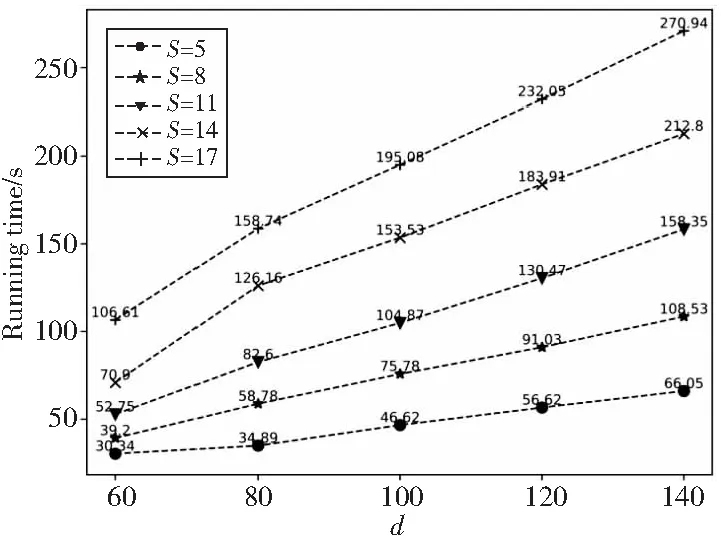
Figure 8 Running time of classification using different dimension features图8 不同维度特征的实验运行时间
与使用原始特征数据的识别结果相比,图7中的实验结果表明,当维度降到一定程度时,识别准确率会大大减小,但是与表1中使用原始低维特征数据的实验结果相比,即使维度约减到k=60维时,识别准确率依然比使用原始64维(1尺度4个方向)特征的平均高出10%以上。当维度k=80时,即使训练数据个数为5,其实验结果依然能达到90%以上。本文希望在不影响实验结果的情况下,尽可能地提高运行效率,所以在接下来的工作中只展示了维度约减到k=100时的实验结果。
5.3.3 实验结果
上述实验结果展示了3个数据集混合情况下的识别结果,除此之外,本文还在单文种及两两混合的实验数据集上分别进行了识别实验。表2和表3分别表示单文种和两两混合实验数据集上的签名识别结果。

Table 2 Experimental results of classification on single-language dataset
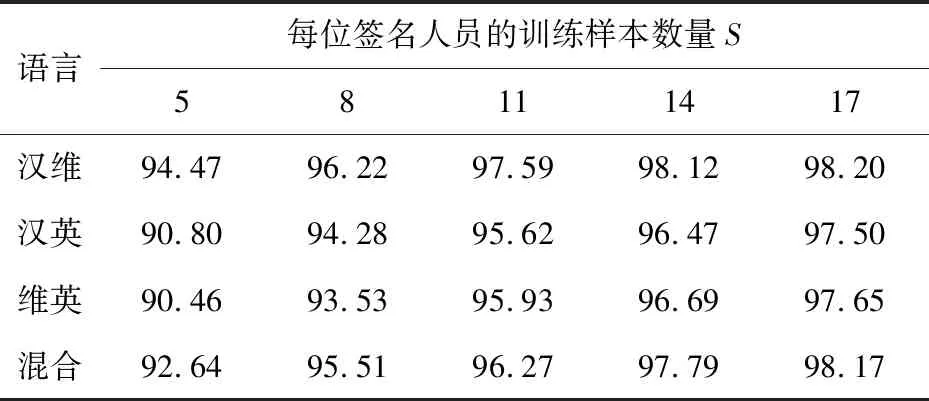
Table 3 Experimental results of classification on mutil-language dataset
通过表2和表3可知,就单文种的离线手写签名识别结果而言,英语数据集上的识别结果相对较差。以往实验经验和实验结果证实,维吾尔语数据集上的识别准确率会相对较高,但是本文提取的Gist特征在汉语的离线签名数据集上的识别准确率较好。这是因为之前的实验大部分提取的是局部特征,维吾尔语的离线手写签名笔画较为稠密,有效的局部特征表示能力相对较强;而在整体性方面汉语手写签名特征表示能力较强;对于英语数据集中的签名数据,其笔画相对稀疏,也不似中文汉字签名那样字与字之间具有整体性,且不同的2个签名间的整体差异更大,所以其识别结果较差。对于两两语种混合的数据集,由于类别数翻倍,所以识别准确率有所下降,但降低幅度不大,这样正说明了本文算法的有效性和实用性。
5.4 对比分析
为了证明本文所提方法的有效性,本文使用了几种常见的纹理特征提取方法:局部二值模式LBP(Local Binary Pattern)、局部方向模式LDP(Local Direction Pattern)和局部相位量化LPQ(Local Phase Quantization),并分别结合Gabor变换进行特征提取,结果如表4所示。

Table 4 Experimental results of classification using different amount of training data
根据上述实验结果易知,本文提出的基于Gist特征的离线手写签名识别方法,无论是在单文种还是在3种不同语系的手写签名混合的数据集上,即使使用少量的训练数据,也都具有较高的识别准确率。同时,为了提高实验的运行效率,本文使用IPCA算法对提取的特征数据进行特征降维,与使用原始特征的运动时间进行对比,降维后的实验运行效率得到了很大的提高。为了表明本文方法准确有效,本文与之前相关方法的实验结果进行了比较,如表5所示。
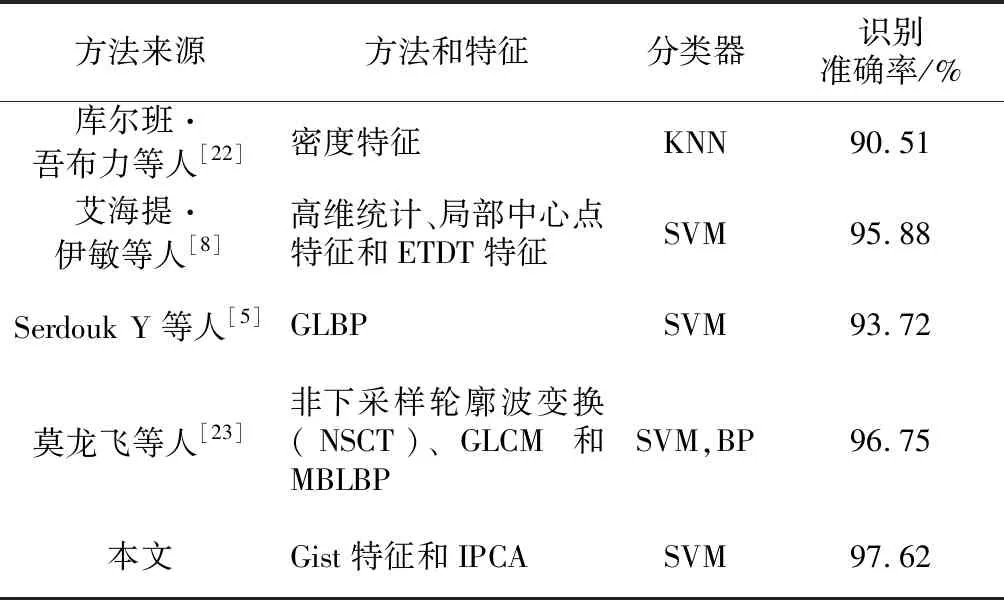
Table 5 Comparison between the proposed method and related methods表5 本文方法与相关方法的对比
通过实验对比,本文提出的基于Gist特征的多文种混合模式的离线手写签名识别方法有效地实现了多文种混合方式下的多文种离线手写签名识别,而且即使使用少量的训练数据,依然有很好的识别结果。
6 结束语
针对多文种混合模式的离线手写签名识别,本文提出了一种基于Gist特征的方法:利用Gist特征对静态图像的宏观表示能力,提取了具有较强表示能力的数据特征,提高了识别准确率;同时使用IPCA算法进行特征维度约减,提高了实验运行效率。与之前的研究方法相比,本文方法在实验结果和实验效率上都相对较优。本文方法是一种传统的模式识别方法,与目前比较流行的深度学习方法相比,本文方法所需中间步骤较多,如预处理、特征提取和分类决策;相对而言,传统方法的优点在于所需训练数据较少、运行效率较高、运行环境要求较低等。所以,在接下来的工作中,将致力于实现更加高效的和实用的多文种离线手写签名识别方法。
