基于多尺度加权特征融合的行人重识别方法研究
2022-11-16孙劲光吴明岩
孙劲光 吴明岩
(辽宁工程技术大学电子与信息工程学院,辽宁葫芦岛 125000)
1 引言
行人重识别(Person Re-identification),也被称为行人再识别,是指在跨摄像头跨场景的情况下,寻找特定的行人视频序列或图像。随着智能视频系统和智能安防应用的领域越来越多,行人重识别也吸引着越来越多的学者进行研究。由于摄像头参数不同和场景的不同,会有光照、遮挡或多姿态变化等问题,导致同一个人拍摄出来的行人图像也会有很大的差异,这就会为网络提取特征增加了难度。
传统的行人重识别方法主要依赖于人工手动设计特征,常见的手工特征包含颜色特征、纹理特征和形状特征以及走路时的步态特征[1]等,其中颜色特征为最经常使用的特征,颜色特征中经常使用RGB 和HSV 等颜色空间组成分布颜色直方图表示行人的特征,而步态特征作为最具有潜力的特征,常根据人体测量学数据、运动学数据、动力学数据以及视频流数据等提取行人的步态特征。这些特征在行人图像具有较大差异的时候,很难提取到具有强分辨性和鲁棒性的特征,并且在图像预处理的过程中操作复杂。所以对基于手工特征的研究工作逐步减少。与传统方法相比,深度学习方法不需要手工设计特征,它会在训练过程中自动提取数据中的样本特征,这样可以获得更强的数据特征表示。目前基于深度学习的行人重识别方法主要分为基于全局特征的行人重识别方法和基于局部特征的行人重识别方法[2]。基于全局特征的行人重识别方法将会为每一个行人图像提取全局特征向量。基于全局特征的方法比较简单,但是它很难关注到行人的细节区域,全局特征大多数为粗粒度特征,当行人图片中出现遮挡、多姿态变换或行人不对齐等诸多影响因素时,会影响模型的识别精度。基于局部特征的行人重识别方法是对行人图像中的部分区域进行特征聚合,能够考虑到更多的行人细节特征,使网络更加具有鲁棒性。在训练时,一般采用对行人图像均匀分割的方法,对每一部分图像进行特征的提取。2018年Sun[3]等人提出了PCB(Partbased Convolutional Baseline,PCB)方法,PCB 将卷积神经网络中输出的特征图水平划分为6个均匀的条纹区域,然后分别对这些区域提取特征,最后利用每个部分的特征产生独立的损失,这种方法有效提高了行人重识别的精度,但是基于局部特征的行人重识别方法只关注了单个行人图像内部的关系,忽略了多张行人图像之间的关系,所以采用全局特征和局部特征融合的方法可以达到更好的效果。2018年Wang[4]等人提出的MGN(Multiple Granularity Network,MGN)多粒度模型,它将全局特征与局部特征结合到一起,然后使用三元组损失函数和交叉熵损失函数对特征进行优化,使行人重识别的精度有了大幅度提升,但是它没有充分的利用粗粒度特征和细粒度特征。2019 年Zheng[5]等人将特征金字塔引入到了行人重识别领域,在全局特征和局部特征的基础上,加强了粗粒度特征与细粒度特征之间的融合,使得模型可以提取到具有较强上下文关联的图像特征。但是在特征融合的过程中,并没有考虑到粗粒度特征和细粒度特征对最终行人目标的贡献度。
针对这一情况,本文提出了一种基于多尺度加权特征融合的行人重识别方法(Person Re-identification Method Based on Multi-scale Weighted Feature Fusion,MSWF),首先,使用ResNeSt-50[6]作为主干网络进行行人图像特征的提取。由于ResNeSt-50 同一层中有多个卷积核,所以可以提取更丰富的行人图像特征。其次,使用加权的特征金字塔网络进行多尺度特征的融合,最后,将融合后的富含语义信息的高层特征作为全局特征,将融合后的高分辨率特征作为局部特征。实验中采用三元组损失函数(Triplet loss)[7]、中心损失函数(Center loss)[8]和Softmax损失函数(Softmax loss)作为优化目标,分别对全局特征和局部特征进行训练,在行人预测阶段,联合全局特征和局部特征进行行人的匹配。该方法在Market-1501[9]、DukeMTMC-reID[10]、CUHK03-Labeled 和CUHK03-Detected 数据集上进行大量的实验,最终结果验证本文所提方法可以较好的提高行人重识别的精度和准确率。
2 加权特征机理及网络结构
基于多尺度加权特征融合的行人重识别方法(Person Re-identification Method Based on Multiscale Weighted Feature Fusion,MSWF)网络图如图1所示,网络由ResNeSt-50 主干网络、加权特征金字塔网络和分支网络组成。
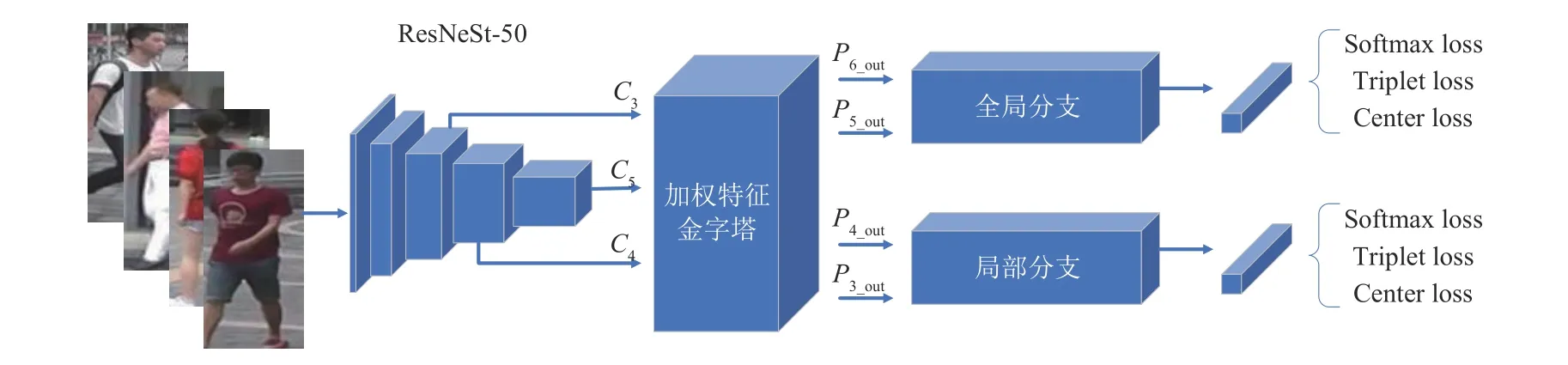
图1 网络结构Fig.1 Network structure
2.1 主干网络
本方法采用的ResNeSt-50 分裂结构如图2 所示,ResNeSt-50 网络中同一层中多个卷积核分支可以分别提取不同的特征,使得网络提取到的特征多样化。ResNeSt-50 有两个超参数分别为k和r,k表示的是将特征在通道维度上分成k个基块组(cardinal groups),r表示的是在每个基块组内继续沿通道维度将特征分成r个分裂组(split groups),即将输入特征分为了k×r组。同时网络中引入软注意力机制可以实现特征通道间的权重分配。首先对所有分裂组中的特征进行1×1 卷积和3×3 卷积,然后将卷积之后的结果相加,再通过全局平均池化得到与单个分裂组卷积之后结果相同维度的特征,最后使用两组1×1 的卷积核进行权重系数的再分配,为保证特征的权重独立分布,使用软注意力机制分别计算各个分裂组的权重,这样可以使网络更加关注到行人图像的重点区域,减少对非重点区域的关注。
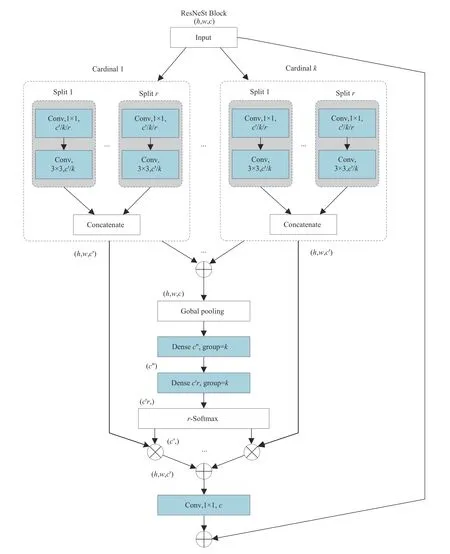
图2 ResNeSt-50分裂结构Fig.2 ResNeSt-50 split structure
本文将分辨率大小为384×128的行人图像输入到ResNeSt-50 中,然后通过下采样获取特征图C(348×16)、C(424×8)和C(512×4),作为加权特征金字塔网络的输入部分。
2.2 加权特征金字塔网络机理分析及结构
当图像中行人目标太小的时候,ResNeSt-50 提取特征时会忽略小目标行人,导致出现行人识别不出的问题。为了获得更加丰富的层级特征信息,从而提高网络的泛化能力和鲁棒性。本文采用快速归一化融合方法将富含语义的高层特征和具有高分辨率信息的低层特征进行加权融合,加权计算具体公式如下所示:
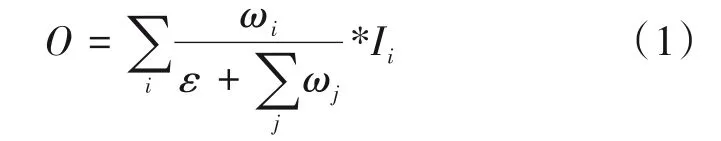
其中ωi为可以学习的权重参数,0 ≤ωi≤1,Ii为要融合的特征,在每个ωi后添加ReLU 函数确保ωi≥0,为了避免数值出现不稳定的情况,将ε设为0.0001。
加权特征金字塔网络结构图如图3 所示,其中虚线框部分为加权特征金字塔模块,加权特征金字塔模块由自底向上和自顶向下两条特征融合路径组成,在加权特征金字塔网络中共堆叠了α个加权特征金字塔模块,在堆叠过程中,前一个加权特征金字塔模块的输出会作为下一个加权特征金字塔模块的输入。C3、C4和C5分别是行人图像通过ResNeSt-50 网络下采样3 倍、下采样4 倍和下采样5倍的特征图。C3、C4和C5经过same padding 卷积获得统一通道数为512的特征图P3_in、P4_in和P5_in,然后对P5_in进行最大池化操作,获取下采样6 倍的特征图P6_in。然后对P6_in进行卷积操作获得特征图P6_td,对P6_td上采样后与P5_in相加得到P5_td,对P5_td上采样后与P4_in相加获得P4_td,每一层级以此类推,最终获得特征图P6_out、P5_out、P4_out和P3_out。在特征融合的过程中,由于不同的输入特征分辨率不同,导致它们对输出特征的贡献度不同,所以本文在特征融合的过程中引入了加权操作,让网络模型在训练中学习输入特征的权重,以P5_td和P5_out为例,运算公式如下所示:
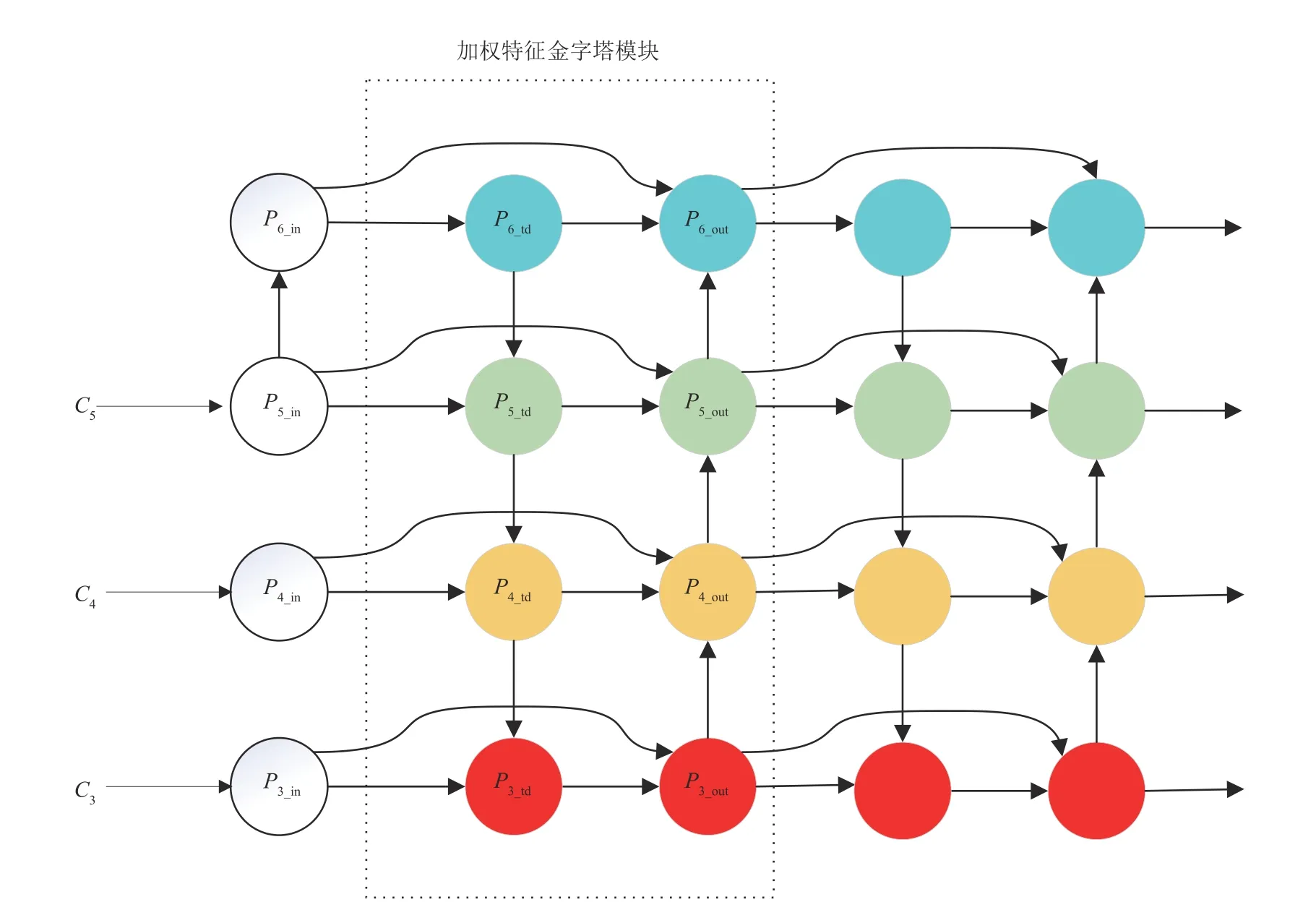
图3 加权特征金字塔网络结构图Fig.3 Weighted feature pyramid network structure diagram
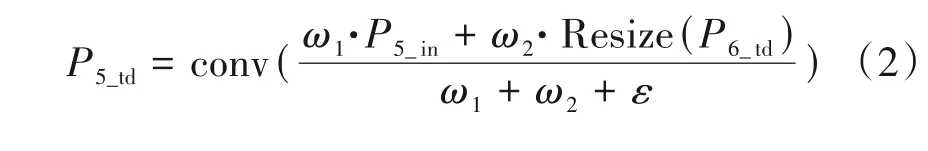
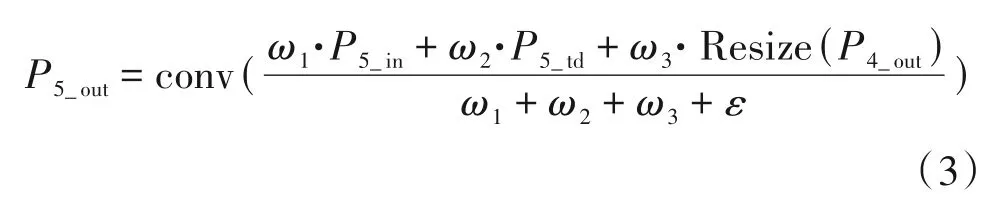
加权特征金字塔网络的输出包含了粗粒度特征和细粒度特征,同时还会在训练中自动学习分配不同融合特征的权重,这样可以更好的表达行人的信息,并增加行人识别的准确率与精度。经过实验,当堆叠加权特征金字塔模块α=2 时,实验的效果最好。
2.3 分支网络
本文的分支网络中包含两个分支,分别是全局分支和局部分支,具体结构如图4 所示。全局分支的输入是P6_out和P5_out。将P6_out上采样成与P5_out相同大小的特征图,然后在通道维度上与P5_out进行连接,然后输入到全局平均池化(Global Average Pooling,GAP)[11]中获得行人图像的全局特征。全局特征中富含行人图像的语义特征。局部分支的输入是P4_out和P3_out,将P3_out进行下采样得到与P4_out相同大小的特征图,然后在通道维度中与P4_out连接,获得大小为24×8的局部特征图,然后将局部特征图沿水平方向均匀的划分为4 份,得到6×8 的特征图。然后对这4 个特征图分别进行广义均值池化(Generalized Mean Pooling,GeM)[12],并将结果连接起来获得通道数为4096、分辨率大小为1×1 的特征图,最后经过一个1×1的卷积对特征图进行降维获得局部特征图。局部特征图中包含行人图像的高分辨率特征。在局部分支中,广义均值池化的公式为:
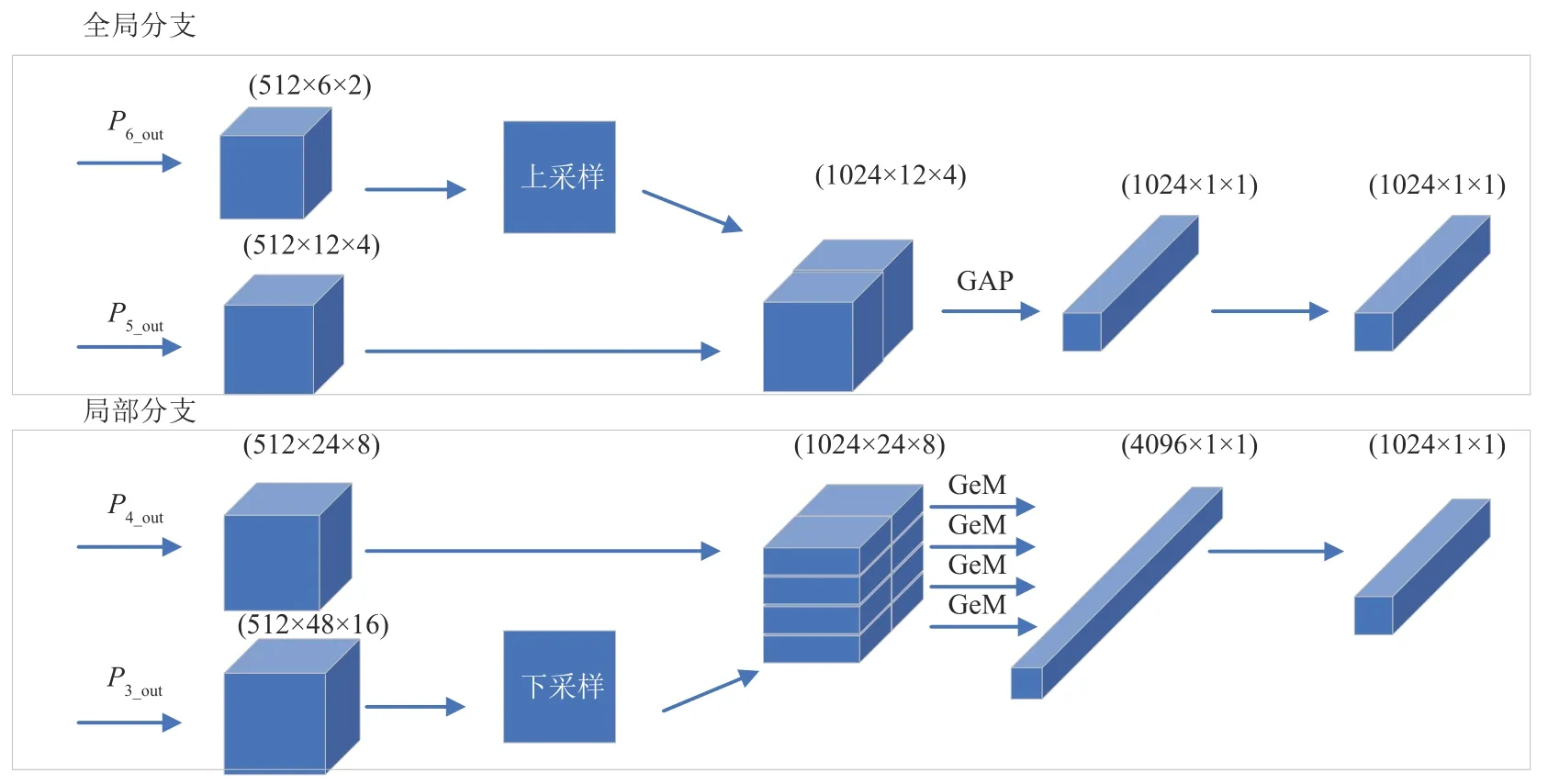
图4 分支网络结构Fig.4 Branch network structure
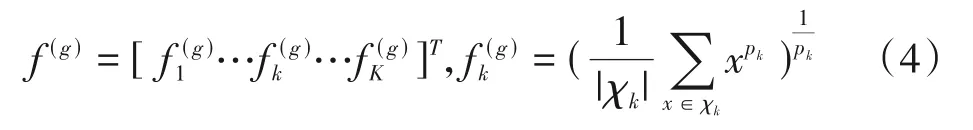
其中pk为超参数,当pk=1 时,f(g)为平均池化;当pk→∞时,f(g)为最大池化。在训练的过程中,广义均值池化会自动学习超参数pk,可以让模型更好捕获特征差异性。
在进行行人身份识别时,会将目标行人图片和所有备选行人图片分别输入到网络模型中,获得各自的全局特征和局部特征,然后将全局特征和局部特征沿通道维度拼接得到行人的特征,最后使用欧氏距离计算目标行人特征与所有备选行人特征之间的距离,距离越小,识别为相同的行人的可能性越大。
2.4 损失函数
本文的全局分支和局部分支都使用了三种损失函数进行训练,分别是Softmax 损失函数、三元组损失函数和中心损失函数。
在分类问题中,一般使用Softmax损失函数进行计算,当损失值越小时,则行人的识别率就越高,Softmax损失函数Lid的计算公式为:
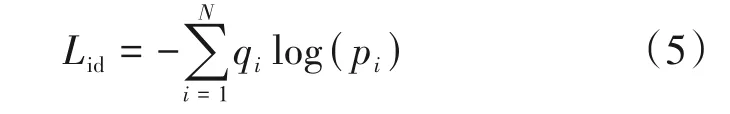
其中N为行人数量,pi为预测的概率值,qi为标签向量。
三元组损失函数是距离度量损失函数,通过最小化三元组损失函数可以缩小类内间距,扩大类间间距。例如输入三张行人图片A、P和M。A和P是正样本对,A和M是负样本对。则三元组损失函数计算公式如下所示:

其中dp表示正样本对A和P的特征距离,dn表示负样本对A和M的特征距离,β为间隔距离阈值,[z]+表示在z和0中取最大值。在本文中,β取0.3。
中心损失函数可以进一步减小类内距离。公式如下所示:

其中B代表批量大小,yj表示在mini-batch 中第j个行人图片的标签,cyj表示第yj类特征中心。
全局分支和局部分支的总损失为:
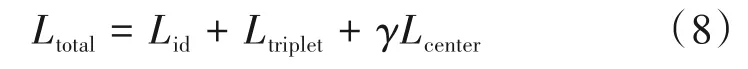
其中γ为中心损失的权重,在本文中γ取0.0005。
3 实验结果与分析
3.1 数据集和评估指标
本文在三个数据集上进行了实验,分别是Market-1501、DukeMTMC-reID和CUHK03[13]。
Market-1501 数据集是2015 年清华大学公开的行人重识别数据集,由6个摄像头拍摄而成。一共拍摄了1501个行人,每个行人最少由2个摄像头捕获。训练集一共有751 个行人,共有12936 张照片,测试集一共750 个人,共有19732 张照片,查询集中的行人是从测试集中随机挑选出来的,共有3368张照片。
DukeMTMC-reID 数据集是2014 年杜克大学在校园中收集的用于行人重识别的数据集,由8 个摄像头拍摄而成。训练集一共有702 个行人,共有16522 张照片,测试集一共有702 个行人,共有17661张照片,查询集中共有2228张照片。
CUHK03数据集是在香港中文大学由10个摄像机拍摄采集而成的,共收集了1467 个行人的照片。根据标注方式的不同,分为了CUHK03-Labeled数据集和CUHK03-Detected 数据集。在CUHK03-Labeled数据集中,训练集共有7368 张照片,测试集共有5328张照片,查询集共有1400张照片。在CUHK03-Detected数据集中,训练集共有7365张照片,测试集共有5332张照片,查询集共有1400张照片。
本文使用两种评估指标用来评估模型,分别是平均准确率(mean Average Precision,mAP)和首位命中率(Rank-1)。平均准确率可以在一定程度上反应正确匹配的行人图像排序靠前的程度,可以更加全面的评估模型。首位命中率指的是计算相似度排序后的第一张图片与查询图像是同一行人的准确率。
3.2 实验参数和环境配置
实 验 在Ubuntu18.04、Intel(R)Core(TM)i7-8700K CPU@3.70GHz、NVIDIA GeForce GTX 1080 服务器上调试。使用的软件环境为Python 3.6、Pytorch 1.7.0和Cuda 11.2。
输入的行人分辨率大小为384×128,使用Adam[14]优化器,初始学习率设置为3.5×10-5,在前10 个epoch 学习率慢慢增长到3.5×10-4,当到第40个epoch 和第70 个epoch 时分别衰减至3.5×10-5和3.5×10-6,最大迭代次数为150。
在训练中,为了防止网络依赖单一区域特征,导致对高遮挡行人识别率降低,并且为了有效避免模型出现过拟合的现象,本文采用随机擦除[15]方法对数据集中遮挡行人的数据量进行扩充。
3.3 消融实验
为了验证网络中主干网络和加权特征金字塔网络的有效性,本文将在Market-1501、DukeMTMCreID、CUHK03-Labeled 和CUHK03-Detected 数据集上进行消融实验。为了保证实验的公平性,所有消融实验没有使用Re-ranking[16]。
3.3.1 加权特征金字塔堆叠参数分析
为了验证参数α对实验结果的影响,保持其他条件不变的情况下,对α的值为1、2和3的网络模型进行了实验对比,结果如表1所示。

表1 不同α值的实验对比结果Tab.1 Experimental comparison results of different α values
由实验结果可知,当α=2时,mAP和Rank-1的值最高,当α=3 时,mAP 和Rank-1 的值反而会下降,甚至低于α=1 时的值,这说明当加权特征金字塔堆叠3层时,会增加模型的参数,导致过度拟合训练数据,降低了模型的泛化能力。
3.3.2 主干网络分析
为了验证主干网络ResNeSt-50 的有效性,在其他条件不变的情况下,将ResNeSt-50 和ResNet-50[17]分别作为主干网络进行实验,比较模型的平均准确率和首位命中率,实验结果如表2所示。
由表2 可以看出,当使用ResNeSt-50 作为主干网络提取特征时,mAP和Rank-1都有了很明显的提升。可以说明使用ResNeSt-50 提取行人特征时,可以提取行人的多个特征,并且重点关注图像中的行人区域。在行人重识别的任务中,使用ResNeSt-50网络提取行人特征可以有效提高行人识别的精度和准确率。

表2 主干网络对比结果Tab.2 Comparison results of backbone networks
3.3.3 加权特征金字塔网络对实验结果的影响
为了验证特征金字塔网络以及在特征金字塔网络上进行加权操作是否可以提升模型的精度和准确率,本文进行了关于特征金字塔的消融实验,下述模型均使用ResNeSt-50 主干网络,并且在分支网络中既使用全局分支也使用局部分支。模型一表示没有特征金字塔网络的模型,模型二表示没有加权操作的特征金字塔网络模型,模型三表示有加权操作的特征金字塔网络模型,结果如表3所示。
由表3 可以看出,当加入没有加权操作的特征金字塔网络模型时,mAP和Rank-1的值低于没有特征金字塔网络的模型,可能由于加入不带权重的特征金字塔网络模型会增加模型的参数,引起过拟合,导致mAP 和Rank-1 的值降低。而本文提出的有加权操作的特征金字塔网络模型,虽然也会增加模型的参数,但是引入了加权操作后,会让模型自动学习不同特征融合时的权重,获得更加精确的多尺度行人特征,因此该模型在这三个模型中取得了最高的mAP 和Rank-1 值。本次实验结果证明了有加权操作的特征金字塔网络模型的有效性。

表3 特征金字塔实验对比结果Tab.3 Comparison results of feature pyramid experiment
3.3.4 分支网络对实验结果的影响
为了验证分支网络的必要性,本文对分支结构进行了消融实验。下述模型均使用ResNeSt-50 主干网络和加权特征金字塔网络,模型一表示分支网络中仅使用全局分支,模型二表示分支网络中仅使用局部分支,模型三表示既使用全局分支又使用局部分支。实验结果如表4所示。
由表4可知,仅使用全局分支进行训练时,mAP和Rank-1值都低于仅使用局部分支训练的结果,可能是由于局部分支可以有效提取行人的细粒度特征,可以获得判别力更强的行人特征。而联合全局分支和局部分支训练的模型mAP和Rank-1值最高,说明在该模型中联合全局分支和局部分支不仅仅可以提取行人的细粒度特征,还能提取行人的粗粒度特征,有效提升本网络对行人的识别率。本次实验证明了联合全局分支和局部分支网络的必要性。

表4 分支网络结构对比结果Tab.4 Comparison results of branch network structure
3.4 对比实验
为了验证模型的优越性,本节将在Market-1501、DukeMTMC-reID、CUHK03-Labeled 和CUHK03-Detected 数据集与近几年行人重识别主流方法进行比较,其中包括PCB[3]、OSNet[18]、PISNet[19]和GPS[20]等先进算法,比较结果如表5所示。

表5 与先进算法实验对比结果Tab.5 Experimental results compared with advanced algorithms
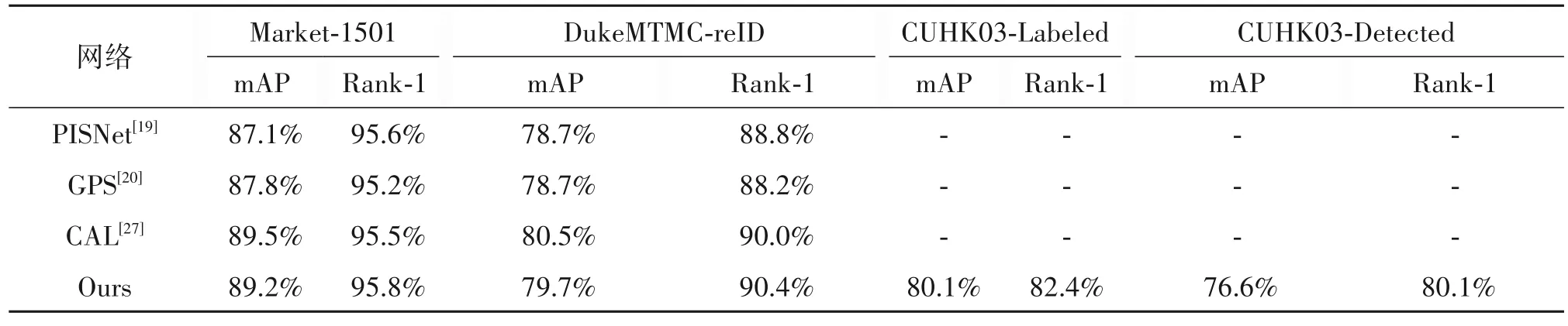
续表5
由表5 可知,本文所提出的方法在没有重排序的情况下,在Market-1501 数据集中mAP 可以达到89.2%,Rank-1 达到95.8%,虽然Rank-1 比RGA-SC相比低了0.3%,但是mAP 的值高了0.8%。在DukeMTMC-reID 数据集中,mAP 到达79.7%,比ISP低了0.3%,但是Rank-1 比ISP 高出了0.8%。在CUHK03-Labeled 数据集中,mAP 和Rank-1 达到了80.1%和76.6%。在CUHK03-Detected 数据集中,mAP和Rank-1达到了76.6%和80.1%,大幅度领先其他算法。实验证明了使用ResNeSt-50 网络提取行人特征与加权特征金字塔网络联合使用的方法在行人重识别领域的有效性。
4 结论
本文提出了一种基于多尺度加权特征融合的行人重识别方法。首先,使用主干网络ResNeSt-50提取行人图像的不同尺度的特征,然后输入到加权特征金字塔网络进行加权融合,获得包含高层语义信息和低层高分辨信息的多尺度特征,并分别作为全局特征和局部特征,最后分别通过分类损失函数、三元组损失函数和中心损失函数进行联合训练。与其他方法相比,本文方法可以让模型在训练中找到合适的权重用来进行特征之间的融合,有效解决了行人被遮挡和行人多姿态导致网络识别不准确的问题,提高了行人重识别的精度和准确率。本文在Market-1501、DukeMTMC-reID、CUHK03-Labeled和CUHK03-Detected 数据集中进行了对比实验和消融实验,对比实验结果证明了本方法的精度和准确率优于其他算法,消融实验结果证明了本方法改进的有效性。
