藏文敦煌字体的整页文本识别研究
2022-11-16杨晓龙高红梅高定国
杨晓龙 高红梅 高定国
(西藏大学 信息科学技术学院 西藏自治区拉萨市 850000)
在20世纪初,敦煌藏经洞被世人发现后,敦煌古藏文写本的内容受到学术界极大的重视,具有很高的学术价值和出版价值。敦煌藏文古籍数字化关系着藏区信息化建设和文化建设等内容,对藏文文献内容的深度挖掘,检索研究,知识库构建起着数据支撑的作用[1]。文本识别是计算机视觉领域的重要任务之一,也是古籍文献数字化工作的一个重要步骤,不仅可以更好地保护古籍文献,同时还能更加快捷高效的检索数据,产生二次价值。目前,对于藏文古籍整页识别技术并不是很成熟,相关研究者还暂未对整页藏文文本识别进行研究讨论。
藏文文本识别现有的方法大多数是级联文本检测器和文本识别器,步骤是先用文本检测器来检测文本行的位置,之后用文本识别器来进行识别行文本。但仅仅依靠级联文本检测器和文本识别器等方法已经不能够满足对藏文古籍的识别,原因如下:首先,级联检测器和识别器存在误差累加的影响且易改变数据分布。其次,手写体文本存在粘连,弯曲等因素使得正确地切分出完整的文本实例十分困难。最后,文本段通常用回车空格等分割符进行连接,如果仅靠两段式的识别方法,格式化和缩进等信息容易丢失[2]。近年来,释放文本检测的整页文本识别已经成为了新的趋势,同时也是解决上述问题的重要途径,相对于两阶段式的文本识别,整页文本识别不仅有着更少的标注,而且有着更高的准确率。目前而言,藏文古籍整页识别技术并不是很成熟,相关研究者尚未对该任务进行研究讨论。
鉴于上述讨论,本文以《法国国家图书馆藏敦煌藏文文献》为研究对象,对藏文古籍整页识别进行探究。首先针对《法国国家图书馆藏敦煌藏文文献》影印版的藏文字形特征,古籍特点以及藏文构字规律等合成了法藏敦煌体藏文古籍文献数据集。其次对近三年出现具有代表性的四种无检测的页面级文本识别使用合成数据集进行探究。对四种目前效果较好的整页文本识别网络在藏文数据集上进行实验。最后根据藏文古籍识别的需求,分析不同特征提取网络对识别效果的影响。更换IFA 模型的特征提取网络对比在不同数据集上的性能,提高了古籍文献的特征表述能力以及在噪声下的稳定性。
1 研究现状
藏文文字识别的研究工作主要有基于传统方法和基于深度学习的方法。
传统方法主要对文字图像进行预处理,版面分析,行分割,字符分割,识别和后处理。在过去的25 年中,在传统方法上主要围绕特征提取部分进行展开[3,4],在此基础上构建了不同的系统用于藏文印刷体识别[5,6]。传统方法大多针对印刷体藏文识别进行研究,取得了很好的效果。
随着人工智能以及深度学习的发展,神经网络在藏文识别任务的正确率和人工识别的效果不相上下甚至有所超越。深度学习的方法主要分为检测和识别两个工作。藏文识别任务方面,赵栋材[7]利用BP 神经网络对藏文进行识别,验证了神经网络在藏文文字识别的可行性。黄婷[8]首次将CRNN 网络模型应用到手写体藏文字丁的识别任务中,韩跃辉[9]基于CNN 的字丁识别算法,提高了藏文古籍7240 类字丁的识别率。在神经网络算法提出的同时,数据集构建[10]被应用于深度学习也是不可缺少的。除此之外,还有一些其他的深度学习的方法应用于藏文文字识别。为了解决文档噪声,仁青东主[11]构建基于残差网络和双向长短时记忆循环神经网络,解决图像质量差、文字粘连严重问题。
近年来,文档识别技术逐渐开始释放文本检测,从而直接对输入图像进行识别。目前虽然没有对敦煌藏文整页文本识别的工作,但对敦煌字体的研究工作[12]已经非常成熟。对于英文和其他文种的识别方面,有很多端到端的识别方法[13,14]被提出,首先级联文本检测器确定每个文本行或者每个单词的位置,之后通过文本识别器识别检测到的文本行。这种方法由于级联文本检测器和文本识别器,会造成误差累计问题。为了解决这种问题,近年来主要方法是拓展文本行识别器到整页级别。整页文本识别可以通过隐式的分割来代替分割模块提升整页的准确率。Curtis Wigington 等人[15]通过定位每一行的起始位置,然后逐步跟随和阅读行文本。Mohamed Yousef 等人[16]提出OrigamiNet 将多行图像隐式展开为单行图像,并使用CTC 来监督输出。Coquenet D 等人[17]提出A Simple Predict & Align Network(SPAN)通过简单预测和对齐网络进行无分割标签训练,Wang T 等人[18]提出Implicit Feature Alignment(IFA)试图使仅使用文本行数据训练的普通文本识别器能够处理页面级文本识别。Coquenet D 等人[19]提出Vertical Attention Network(VAN)通过逐行迭代实现段落级别的识别达到目前最先进的识别率。
2 数据集构建
2.1 敦煌藏文古籍特点分析
藏文字符不等宽,字丁不等高,相似形多,字形结构复杂,叠加变形等是藏文识别的主要难点[20]。敦煌藏文古籍字丁种类多,相似形多,字体大多与藏文乌金体类似,也有少量乌梅体的风格[12],特别是敦煌文献文档图像质量低、退化严重。具有污渍、霉变等背景干扰,文字模糊、残缺、断裂、手写风格不一、笔画粗细不一和书写潦草导致文字识别十分困难。
2.2 数据集构建思路
深度学习通常需要大量的训练数据用来测试网络的性能。目前,还没有可以对整页藏文古籍文献识别进行评估的公开数据集。数据集文本语料与背景噪声均来源于《法国国家图书馆藏敦煌藏文文献》。
原始法藏敦煌文献与生成图片对比如图1 所示,该程序可以通过不同的参数生成数据集,如生成FCNN,FCNB,FCWN,FCWB 四个数据集。

图1:《法国国家图书馆藏敦煌藏文文献》真实样例生成和生成数据集
数据集构建程序流程图如图2 所示,首先配置文件获得要生成数据集的参数,经过语料库的数据清洗得到要生成图片上显示的文字部分,之后与字体库生成前景文字,生成文字后再加入噪声增加文本识别的难度,最后将标签信息写入xml 文件。
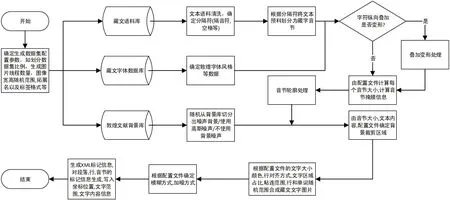
图2:数据集构建程序流程图
该程序可以通过不同的参数生成不同的数据集。参数设置主要分为四个方面,分别为总体设置,语料文字处理,背景处理,标签处理。通过不同的参数设置生成不同识别难度的数据集。
3 算法分析
3.1 Origaminet算法分析
OrigamiNet 网络的输入仅需要未分割的敦煌古籍图像和相应的文本对。先使用GTR 网络做特征提取,之后隐式地将一个输入多行图像拼成一个单行图像。如公式1 所示,网络产生的预测序列表示为P,是输入图像L 相关的标签序列,其中|L|<|P|。F 是学习字符的2D 排列转化为1D 排列的变换。I 表示输入的2D 图像。最后通过CTC 考虑两个1D 序列之间的所有可能的比对实现对齐操作。
在训练过程中,它能够很好的处理粘连问题,并且不需要字符的任何位置信息,从而简化了训练流程。

3.2 SPAN算法分析
SPAN 网络通过全卷积网络作为编码器来分析2D 的段落图像。先由一系列卷积块(CB)和深度卷积块(DSCB)组成编码器。将输入敦煌古籍图像X∈RH×W×C转化为输出特征图(H、W 和C 分别是高度,宽度和通道数)。然后,通过单个卷积层组成的解码器预测和对齐特征f 的每个2D 位置的字符和CTC 空白标签的概率。最后,通过按顺序串联预测行,得到一个一维预测序列N 是字符集的大小,之后通过标准CTC 计算一维预测序列和段落标签之间的损失。
SPAN 模型在训练过程中能够很大程度上节省GPU 内存,处理可变图像大小,能够适应多个数据集,可以用作更深层次的端到端网络的主要步骤。因为网络是串联预测行,是按照顺序进行处理的,所以在文本行和下一行有足够的空间的情况下效果较好。
3.3 VAN算法分析
VAN 模型的编码器由大量卷积块(CB)和深度可分离卷积块(DSCB)组成,目的是保持相同性能水平的同时减少参数数量,同时要有足够的信息来识别字符。编码器将输入敦煌古籍图像X∈RH×W×C转化为输出特征图(H、W 和C 分别是高度,宽度和通道数)。注意力模块用来递归生成文本行表示并进行段尾检测。线特征It 为特征行和注意力之间的加权和,如公式2 所示,在垂直维度上正确的特征行权重接近1,敦煌古籍背景以及插画噪声权重接近0。加权和能够将线特征It 处理为一维序列从而使用CTC 损失,对于每一行i,计算多尺度信息st,i,如公式(3)所示。它包含局部和全局的信息,为剩下的垂直表示,表示解码器处理前一行文本后的隐藏层状态。ct为所有先前注意力权重的总和。之后计算每一行的得分et,i。如公式(4)所示。最后通过Softmax 激活函数计算注意力权重,如公式(5)所示,段落识别需要段尾检测,通过3 种,固定停止,提前停止和学习停止的方法。经过注意力模块之后垂直轴已经折叠为一维特征序列,通过LSTM 和卷积得到每帧的字符概率Pt,最终通过CTC 解码器去除连续字符和空白符的到最终文本。
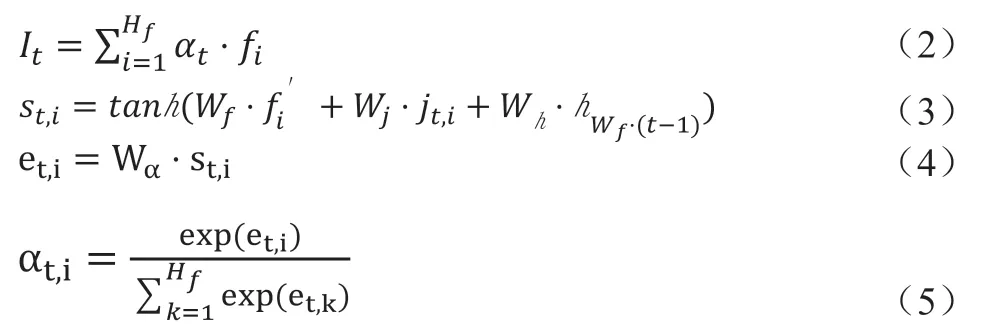
VAN 模型参数较少,但是直接在段落上训练时间成本较高,所以网络在行级别进行预训练后再进行段落级别的训练更易于收敛。网络对于重叠部分识别还有待解决。
3.4 IFA算法分析
特征提取器F 基于卷积神经网络构成,将S={s1,s2,s3,s4...st}的输入图像X 编码为特征图F,如公式(6)所示,C、H 和W 分别表示特征图的输出通道、高度和宽度,之后,分类器C 将特征图的每个像素进行分类,如公式(7)所示,K 表示字符类别总数加上空白符号。列挤压模块S(两个批归一化和ReLU 的卷积构成)将二维特征图F∈RC×H×W使用列注意力图沿着垂直方向压缩成1D 特征序列F′∈RC×1×W,如公式(8)所示。垂直注意力图为公式(9),F′计算为公式(10),之后转化为CTC 进行计算。这个时候,C 有能力训练每一列的正像素,去除S 之后对齐的正像素仍然能够正确的识别,达到了简单的对齐和训练F 的正像素。WH‐ACE模块用来抑制标签外的负面预测,同时保持正面预测不受影响。WH‐ACE 的损失函数为公式(11),W1 表示1‐Wasserstein距离,目的是将标签外概率转移到标签内类别分布,总的训练损失函数为公式(12)。
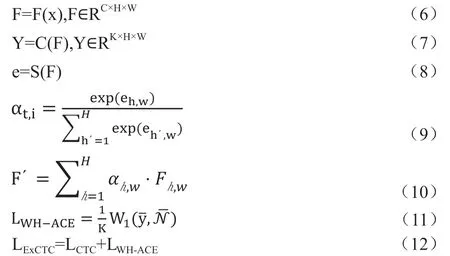
IFA 模型有着很快的推理速度。可以通过训练单行图像来识别段落级文本,可以有效的处理单行和多行文本。
4 实验部分
4.1 实验设置
为了验证整页文本识别模型对于敦煌藏文古籍识别任务的可行性,我们在四种数据集上进行了各个模型的对比。本文基于Ubuntu 20.04.2 LTS 操作系统,在python 3.8.8,Pytorch 1.9.0,CUDA 11.4,cudnn 8.2.1,RTX 3070 GPU 环境下进行实验。
4.2 数据集以及评价方法
4.2.1 数据集介绍
法藏敦煌藏文古籍文献为稀缺资源,目前没有可用的数据集。本文所用的数据集语料和背景噪声均来自《法国国家图书馆藏敦煌藏文文献》。我们在4 个数据集上进行了对比实验。即FCNN,FCNB,FCWN,FCWB。每个数据集数据采用958 张古籍图片作为训练数据,136 张古籍图片作为验证数据,273 张古籍图片作为测试数据。单张图片最小字符数300,最大字符数750,平均字符数442。
在本文中,语料由藏文和梵文转写构成,对语料进行了清洗,将多余的空格,无法文字识别的标记字符,不常用的图画符号以及部分特殊符号进行过滤。其中四个数据集特点分别为:
FCNN:法藏无噪数据集。字体单一,距离固定,背景为白色背景。
FCNB:法藏背景噪声数据集。字体单一,距离固定,具有背景噪声。
FCWN:法藏文字噪声数据集。字体为多字体。距离大小不同,行与行之间随机粘连。背景为白色背景。
FCWB:法藏混合噪声数据集。字体为多字体,多字号,音节之间随机进行粘连,行之间进行随机粘连。背景噪声为真实敦煌古籍文档的背景。
数据集和标签可视化如图3 所示,数据集从左上到右下以此为FCNN,FCNB,FCWN,FCWB。

图3:数据集和标签可视化样例
4.2.2 评价方法
为了评估敦煌文献整页识别的效果。我们用字符错误率(CER)和单词错误率(WER)进行评价。如公式(13)所示,他们是用真实标签y 和预测值 之间的编辑距离(表示为dlev)进行计算,由标签总长度进行归一化。K 表示图像的数量。WER 公式完全相同,由原来的字符级别改变为单词级别即可。

4.3 实验结果分析
表1 展示了各个模型在不同数据集下识别的字符错误率和单词错误率,对于增加了文字噪声的FCWN 和FCWB 来说,重点测试网络对字体的特征提取能力。对于增加了背景噪声的FCNB 和FCWB 数据集,重点测试网络对背景噪声的鲁棒性。

表1:模型在测试集上的准确率
OrigamiNet 网络在不需要单词级别或行级别的标注下仍然保持较高的准确率。无论是对于文字噪声还是对于背景噪声都具有很强的鲁棒性,在四个数据集上字符错误率分别是0.11%,0.09%,0.08%,0.14%,保持着最低的字符错误率。VAN 网络首先对每行藏文进行训练,在行训练上网络对于背景噪声情况不敏感,但对于字体噪声错误率由原来的1.15%提升到3.56%。然后在行训练的基础上进行整页识别的训练,都达到了1%以下的错误率。网络对单独的文字变化和单独的背景噪声情况下影响较小,但是该网络对于二者叠加的情况下会大幅度影响网络的收敛。SPAN 网络对于单独文字的变化或者单独背景噪声的变化影响较小,对背景噪声和文字变化组合时候错误率明显增加。IFA 网络虽然也使用注意力机制,通过WH‐ACE 模块抑制背景噪声,特征提取部分对比了两个特征提取网络Resnet18 和Resnet34。浅层网络不仅在保持较高速度的推理的同时,还有着较低的错误率。
在整页藏文文本数据集上,模型OrigamiNet 性能最好,其次是VAN,SPAN,最后是IFA 网络。
网络在不同的数据集上的收敛曲线如图4 所示。通过分析不同网络的错误率曲线。OrigamiNet 通过折叠的方法在各个数据集上的收敛速度大致相同。SPAN 在单独的文字噪声和单独的背景噪声可以很好的处理,但是在混合噪声收敛速度较差。VAN 网络对于仅加入背景噪声情况能够较好收敛,对于更改文字大小,混合字体后收敛比较困难,在此基础上加了背景噪声后更加难以达到收敛。IFA 网络使用Resnet34 特征提取的效果比Resnet18 特征提取网络差,在使用Resnet34 错误率为21.28%,在更换为Resnet18 之后,错误率达到了2.86%。大大降低了网络的错误率。
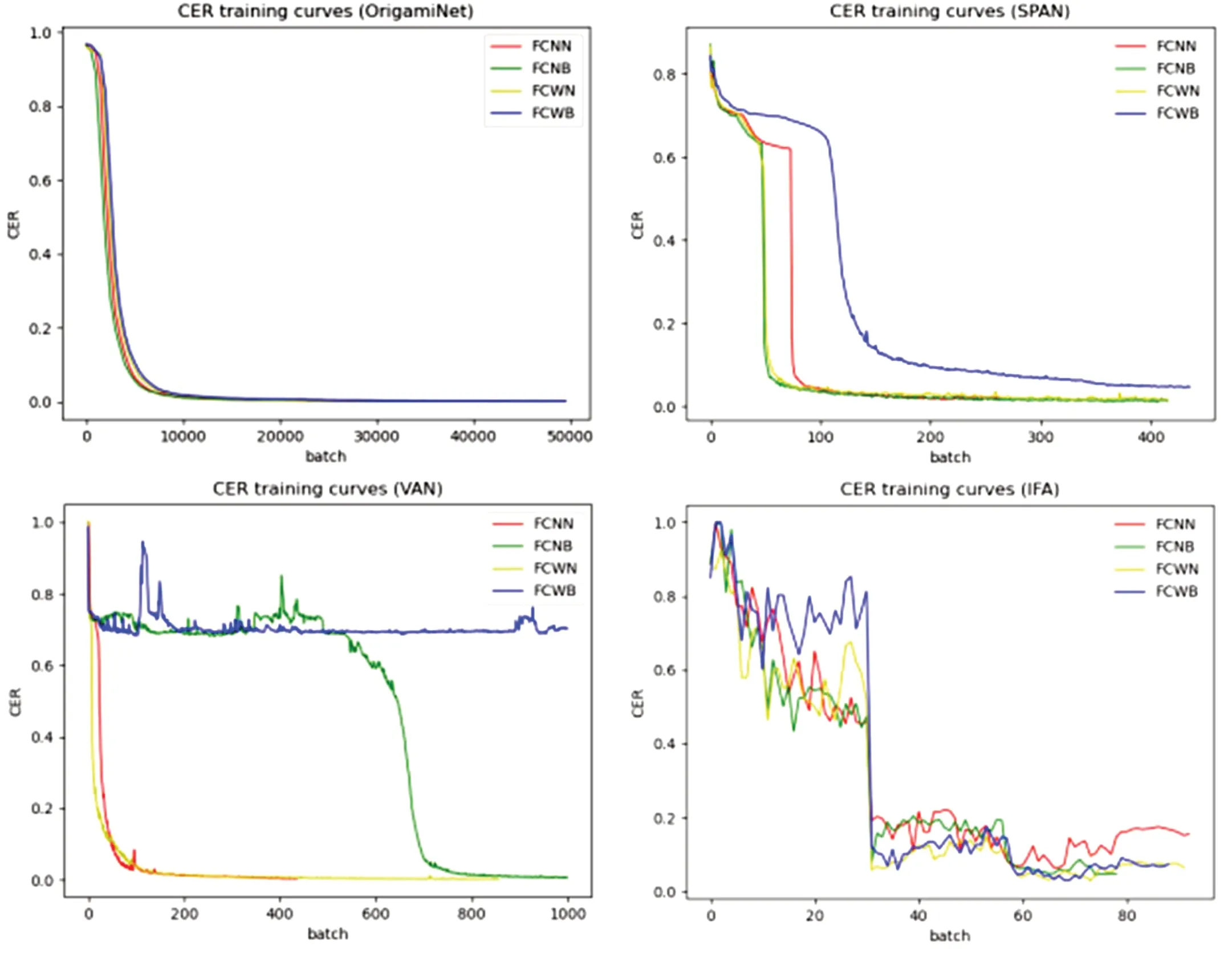
图4:网络在不同的数据集上的收敛曲线
使用注意力模块的是VAN 和IFA 网络。依赖于参数化的注意力模块,性能随着序列长度的增加而衰减,对于整页级敦煌古籍文献识别任务较为勉强。VAN 网络必须依赖行训练才能进行整页训练,直接进行整页训练收敛较为困难,违背了整页识别的初衷。IFA 网络不同的特征提取模块达到不同的识别效果,虽然IFA 引入了对背景噪声抑制的模块WH‐ACE,推理速度也远超过其他网络,但是准确率方面还是和不使用注意力模块的有一定的差距。不使用注意力模块的是OrigamiNet 和SPAN 网络。OrigamiNet 网络通过折叠达到一维的输入要求,SPAN 网络通过特征的拉伸达到一维的输入要求。最终四个的网络都是通过CTC 模块对齐两个一维序列,达到整页识别的效果。
对于识别结果较差的IFA 模型,通过引入了WH‐ACE抑制背景噪声,对于干净背景噪声和复杂背景噪声的情况,网络都能够很好的注意在文字上面,甚至在有背景噪声的情况下,由于WH‐ACE 的加入,反而能够更好的关注到文字的部分。如图5 所示,上方的图片为不同噪声的数据集进行二值化后的样例,下方图片分别为数据集样例的注意力图可视化。

图5:不同数据集注意力可视化
IFA 网络中不同提取网络的结果如图6 所示,网络几乎在同一个时间字符错误率呈大幅下降趋势,网络学习到了图片中文字的特征。使用Resnet18 网络的效果优于Resnet34。
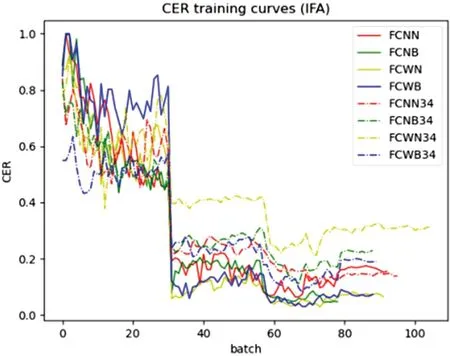
图6:不同提取网络的IFA 实验对比
5 总结
本文针对整页文本数据集稀缺问题,首先提出一套合成整页数据集的方法,有效的运用到藏文整页识别任务中。其次通过微调分析了近几年整页识别网络对藏文古籍整页识别的效果,随着噪声的增加,不同模型在不同噪声的数据集上鲁棒性各不相同,对于结果较差的模型更换不同的特征提取网络进行实验分析。在构建的敦煌整页古籍文献数据集上几乎都达到了90%以上正确率。本文初步完成了基于敦煌体藏文整页识别研究工作,填补了对于藏文整页识别的研究空缺。
