基于声誉系统的软件众测任务分配机制
2022-11-15植赐佳
王 强,植赐佳,徐 佳
(1.中国赛宝实验室,广东 广州 511370;2.南京邮电大学 江苏省大数据安全与智能处理重点实验室,江苏 南京 210023)
随着移动智能终端行业的迅速发展,大量移动终端应用不断涌现,极大地丰富和方便了人们的生活。在软件产品的测试过程中,软件产品的管理者希望能够低成本且快速地获得软件产品的反馈,从而尽快修复软件产品的缺陷并改进软件产品的质量。然而,对智能移动终端而言,其系统千差万别。以Android为例,系统版本更迭频繁,从2008年的Android 1.0更新到2020年的Android 11.0[1],并且每个版本都有不同的特点与应用程序接口(Application programming interface,API)等级。除此以外,还存在各大厂商的定制系统,如华为的EMUI[2],小米的MIUI[3],OPPO的ColorOS[4]等。这就导致了软件生态系统的碎片化,给测试工作带来了极大的挑战。应用开发者需要在多种不同类型和版本的系统上对软件产品进行大量重复机械的测试工作,给应用开发者带来了极大的困难与极高的成本。因此,如何快速且低成本地获得软件产品的测试反馈,是当前软件测试领域的挑战之一。
众包(Crowdsourcing)可以在很大程度上解决软件测试领域的这一难题。众包[5]是一个公司或机构把过去由专职员工执行的工作任务,通过公开的Web众测平台,以自由自愿的形式外包给非特定的解决方案提供者群体,共同来完成任务的分布式问题求解模式。自从众包被提出以来,已经被广泛应用于人工智能[6]、车联网[7]、智慧城市[8]等领域。在软件测试中,利用众包可以较低的成本招募大量的真实用户来完成测试任务。
众测(Crowdsourced testing)作为一种新兴的软件测试手段,在很大程度上解决了传统软件测试所面临的用户数量不足、测试成本较高等问题,得到了学术界和工业界的广泛关注。不同于传统的测试方法,众测是由许多来自不同领域的测试人员进行的,而不是由雇佣的顾问和专业人员进行的。测试人员的多样性保证了能够对产品进行全面的测试,而众包的方式能够极大地降低测试成本。众测使得软件能够在不同的实际环境下进行测试,使其更加可靠、经济高效、快速和无缺陷。
通常,众测活动的参与者包括众测工人和众测平台[9]。众测平台首先确定待测试软件和众测任务,然后将众测任务发布;众测工人选择感兴趣的众测任务来完成;众测工人完成众测任务后将测试结果以指定的众测报告形式提交给众测平台。与传统的软件测试报告类似,众测报告由众测平台事先定义好,包括状态、测试环境、测试输入、预期输出、错误描述等字段。
自从众测技术在2009年被首次应用于体验质量(Quality of experience,QoE)[10]以来,针对众包技术在软件测试领域的研究不断开展。目前众测技术已经在QoE测试、可用性测试、功能测试等测试子领域中得到广泛应用,并且已经有ITest移动众包框架[11]、CrowdStudy工具包[12]等众测工具被投入使用。
相比其他类型的众包任务,软件测试任务对众测工人有较高的要求。众测工人需要对待众测软件有一定的了解,并具备相应的软件操作和测试技能。众测工人提交的测试结果的质量对软件产品的后续优化是至关重要的。例如在功能性测试中,众测工人能否完全根据指定的测试用例进行测试,测试报告的书写是否完善等因素对最终的测试结果极为重要。
然而,现有的众测算法没有关注到众测工人的能力对其提交的测试结果的影响。进一步地,众测工人的能力经常是随时间而变化的。一个成熟的众测系统通常需要一批能力稳定的众测工人,因此众测任务分配机制应能够激励长期高素质的众测工人。声誉系统使用众测工人的历史记录来构造一种激励,使众测工人可靠地发挥其能力,从而吸引在长时期内能力较强的众测工人参与众测。声誉系统已经被许多系统所采用,如在线商城eBay[13]、网络社区Stack Exchange[14]和社会新闻Reddit[15]等。
本文旨在设计基于反向拍卖[16]和声誉系统的多轮众测系统。考虑到每轮众测任务都对众测工人的能力有一定要求,提出了一种声誉系统来收集和维护众测工人的能力,并基于众测工人的标书和声誉来选择胜利者。在下一轮众测任务开始之前,众测工人的声誉值将被更新。任务分配机制的目的是在满足所有众测任务的能力要求的基础上最大化社会福利。本文提出的众测系统由众测工人、众测平台和外部评价者三方构成。首先,众测平台编写测试计划书,包括制定众测的目的、范围以及测试报告规范等;众测平台发布众测任务,众测工人参与竞标;然后众测平台选择合适的众测工人作为胜利者来执行任务,通知胜利者,并发放产品测试账号;众测工人进行测试,撰写并上传测试报告;最后众测平台将众测工人提交的报告发送给评价者,收集评价者的打分,更新众测工人的能力值,并发放相应的报酬。
1 系统模型和问题定义
1.1 系统模型
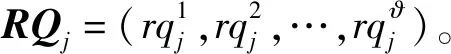
在每轮分配众测任务的时候,每个众测工人i∈W向众测平台提交一份标书Bi=(Γi,bi),其中Γi⊆Γ是该众测工人感兴趣的众测任务集合,bi是该用户对执行Γi中的众测任务的报价。每个众测工人i在执行这些众测任务的时候会产生一定成本,记为ci。本文认为ci的真实值是众测工人i的私人信息,只有他自己知道。
给定众测任务集合Γ以及众测工人投递的标书B=(B1,B2,…,Bn),众测平台需要计算胜利者集合S⊆W以及给每个众测工人的报酬p=(p1,p2,…,pn)。基于声誉系统的软件众测系统如图1所示。

图1 基于声誉系统的软件众测系统
1.2 问题形式化
将众测工人i的效用定义为报酬与其实际成本之间的差异
ui=pi-ci
(1)
特别地,输家的效用是0,因为他们在所设计的任务分配机制中没有任何收入,但也不会产生执行众测任务的成本。
值得注意的是,本文认为众测工人是自私并且理性的,因此每个众测工人可以通过采取策略行为,即提交不诚实的报价来最大化其效用。
众测平台的效用被定义为
(2)
式中:V(S)是胜利者集合为S时,众测平台所获得的价值。
将社会福利定义为众测平台和所有众测工人的总效用之和
(3)
任务分配机制的目标是最大化社会福利,并在满足众测任务能力要求的前提之下完成Γ中的每个众测任务。事实上,社会福利最大化问题等价于社会成本(胜利者的总成本)最小化问题,因为V(S)的值在满足能力要求的情况下是固定的。本文将这个问题称为成本最小能力覆盖(Cost minimization ability coverage,CMAC)问题,形式化如下
(4)
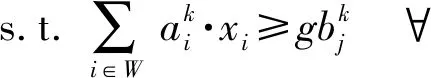
(5)

(6)
xi∈{0,1} ∀i∈W
(7)
式中:xi是关于众测工人i∈W的二元变量,如果众测工人i被选为胜利者,那么xi=1;否则xi=0。约束(5)保证所有获胜者在任意众测任务中的总能力不低于相应的总能力要求。约束(6)保证每个胜利者都满足其执行众测任务的各项最低能力要求。
本文的目标是设计一个满足以下属性的任务分配机制:
(1)计算有效性。如果胜利者集合S和报酬集合p都能够在多项式时间内计算完成,则该任务分配机制是计算有效的。
(2)个体理性。每个众测工人在提交真实成本时都有非负效用,即ui≥0,∀i∈W。
(3)防洗白攻击。众测工人不可以通过构造一个新身份重新加入系统而获得更高效用。
(4)真实性。对于任意的众测工人,无论其他众测工人的策略是什么,都不可以通过提交虚假的成本来提高自己的效用。
(5)近似度。任务分配机制的目标是最小化社会成本。如果该问题是NP难的,本文尝试设计算法满足较好的近似度。
2 基于对等预测的声誉系统
在所构建的声誉系统中,众测平台首先招募评价者去评估众测工人的能力。然后众测平台根据评价者给出的能力评估结果,更新众测工人的能力值。评价者评估众测工人能力的过程可以被建模为同时汇报博弈。本文认为评价者是自私的,每个评价者都可以采取策略行为,即通过提交虚假的评分来最大化其自身收益。因此需要保证评价者提交评分的真实性。
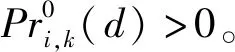
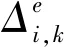
定义1一个奖励规则是严格合适的,当且仅当评价者只能通过汇报其真实的评分来最大化其期望奖励。
对数奖励规则已经被证明是一种严格合适的奖励规则[18],它会使用信号实际发生的概率的对数来计算评价者的奖励。将对数奖励规则应用于声誉系统中
(8)
在对等预测中,对于任意一个评价者e,众测平台会随机选择一个参考评价者w(e)。将对数奖励规则应用于对等预测中
(9)


(10)

由于式(10)中的期望收益恒为负值,因此需要加入一个较大的常数φ将其转化为正期望收益。显然,这个操作并不会影响其诚实汇报的性质。那么,对于众测工人i和能力k,每个评价者e的收益为
(11)
基于对等预测的声誉系统如图2所示。

图2 基于对等预测的声誉系统
下面给出系统初始化、新众测工人能力初始化以及众测工人的能力的更新方法。
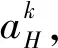
(12)

(2)新众测工人初始化。如果存在新众测工人i在某个时刻加入众测系统,将其所有能力初始化为整个系统中所有众测工人的最小值,即
(13)
(3)能力更新。当众测平台收到评价者上传的评分后,众测平台通过式(14)对众测工人的能力值进行更新
(14)
式中:σ∈(0,1)是遗忘系数,用于调整历史能力的权重。
3 基于声誉系统的任务分配机制设计
首先分析CMAC问题的难度。
定理2CMAC问题是NP难的。

(15)
s.t.Γ⊆∪i∈SΓi
(16)
由于带权重的集合覆盖问题是已知的NP难问题,所以CMAC问题是NP难的。
由于CMAC问题是NP难的,本文基于贪心法设计了反向拍卖算法,详细在算法1中说明。

算法1基于声誉系统的软件众测任务分配机制
输入:众测任务集合Γ,标书集合B,众测工人集合W,最小能力要求RQ,总能力要求GB
输出:胜利者集合S,报酬p
//系统初始化
1: if this is the first round of crowdsourced testing then
2: system initialization based on(9)for ∀i∈Wand ∀k∈Ω;
//新众测工人初始化
3: for eachi∈Wdo
4: ifiis a new worker then
5: new worker initialization based on(10)for ∀k∈Ω;
//胜利者选择
6:S←∅,GB′←GB;
7: for eachi∈Wdo
8:Γ′i←Γi;
9: for eachτj∈Γdo
10: for eachk∈Ωdo
12:Γ′i←Γ′i{tj};
13: whileGB′≠0 do
15:S←S∪{i};
16: for eachτj∈Γ′ido
17: for eachk∈Ωdo
//计算报酬
19: for eachi∈Wdopi←0;
20: for eachi∈Sdo
21:W′←W{i},S′←∅,GB″←GB;
22: whileGB″≠0 do
24:S′←S′∪{ig};
26: for eachτj∈T′igdo
27: for eachk∈Ωdo
//能力更新
29: ability updating based on(11)for ∀i∈Wand ∀k∈Ω;
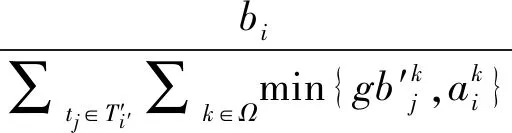

4 任务分配机制的理论分析
本节给出算法1的理论分析。
引理1算法1是计算有效的。

引理2算法1是个体理性的。
证明令ig为在众测工人集合W{i}的排序中第i个位置的众测工人。如果众测平台将众测工人i纳入众测工人集合考虑,众测工人ig的顺序就不会在第i个位置,因此可以得到
由此可得

引理3算法1是防洗白攻击的。

(1)众测工人i没有被选为胜利者。由胜利者选择部分的算法,可得
这表示如果众测工人i选择使用新身份i′重新加入系统,那么i′在胜利者选择的过程中将会使得i的排名向后推移,并且i′依然会是竞拍过程中的失败者,因此对最终结果没有任何影响。
(2)众测工人i本来是胜利者,即i∈S。考虑如下两种情况:①i′在竞拍过程中失败:由于算法1算法满足个体理性,因此有ui′=0≤ui;②i′在竞拍过程中胜利:由算法1中的报酬分配规则,可以得到
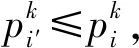
由上,可以得到ui′=pi′-ci′≤ui=pi-ci。
在分析算法1的真实性之前,首先引入梅尔森定理[20]:
定理3一个拍卖机制是真实的,当且仅当如下两个条件成立。
(1)选择规则是单调的。如果众测工人i能够通过报价bi来赢得拍卖,那么当他使用一个小于bi的价格竞拍时仍然能够获胜。
(2)每个胜利者都被按照其关键价格进行支付报酬。众测工人i的竞标价格如果高于该价值,那么他将在竞拍中失败。
引理4算法1是真实的。
证明基于定理3,只要证明算法1的胜利者选择规则是单调的,并且对每个众测工人i,其获得的报酬pi是其关键价格,那么即可证明算法1的真实性。
算法1的胜利者选择规则的单调性是显而易见的,因为众测工人i以一个较低的报价参与竞拍并不会令众测工人i的排序靠后。
接下来,证明pi是众测工人i的关键价格,如果众测工人i竞标的报价超过pi,那么他将不会成为竞拍的胜利者。由于在报酬分配规则中,众测工人i所得的报酬为

那么如果众测工人i的报价高于该报酬,即bi≥pi,由于
可得
那么众测工人i的排序将位于位置L之后。此时,因为前L个众测工人已经满足了所有众测任务的能力要求,所以众测工人i将不会在竞拍中获胜。由此可得pi是众测工人i的关键价格。
在对算法1的近似度进行分析之前,首先对式(4)中定义的CMAC问题进行一定的转换。
定理4CMAC问题等价于带权重的集合多覆盖问题。
证明本文将原有的有ϑ维的总能力要求的m个众测任务,转换为每个众测任务都只有一维的总能力要求的m×ϑ个众测任务。对众测任务集合Γ′i使用同样的转换方法,其中Γ′i是经过过滤后的众测工人i的感兴趣的众测任务集合,即判断其能力是否满足最小能力要求后的众测任务集合。接下来,问题可被转化为在每个众测任务都只有一维能力要求的基础上,从众测工人集合中选择一个子集,从而能够完成所有的众测任务。
CMAC问题可以被重新形式化如下
(17)
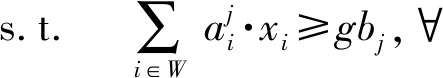
(18)
xi∈{0,1},∀i∈W
(19)
实际上,该问题是元素个数为m×ϑ的带权重的集合多覆盖问题[19]。显然,原始的CMAC问题和该问题是等价的。
由于CMAC问题等价于带权重的集合多覆盖问题,其贪心算法具有明确的近似度,因此有得出如下结果。

以上引理共同证明了如下定理。
定理5算法1是计算有效、个体理性、防洗白攻击、真实性、以及满足Hmϑ近似度的。
5 性能评估
将本文算法与如下两个算法进行对比。
(1)成本贪心。该算法每次贪婪地选择具有最小成本的众测工人直到所有众测任务的能力要求都被满足。
(2)能力贪心。该算法每次贪婪地选择具有最大边际能力的众测工人直到所有众测任务的能力要求都被满足。
试验设置中,使用了四维的能力,每个维度的能力值都在[0,1]中随机取值。每个众测工人的成本从拍卖数据集[21]中随机选取,该数据集包含了在eBay上对Palm Pilot M515的5017个竞标。设置ϑ=6,n=500,m=100,σ=0.8作为默认参数。每个任务的总能力要求在[1,2]中随机取值,对众测工人的单个能力要求在[0.2,0.4]中随机取值。试验将变化部分关键参数的值,来探索它们的影响。所有试验都运行在具有Intel(R)Xeon(R)CPU和128 GB内存的Windows 10服务器上运行,每次测量均取100轮中100个实例的平均值。
5.1 社会成本分析
首先对任务轮数对社会成本带来的影响进行分析。由图3可知,当轮数增加时,本文算法和能力贪心的社会成本都逐渐降低。这是因为随着轮数的增加,众测平台逐渐掌握了众测工人们的能力值,从而能够选择更加合适的众测工人。随着轮数继续增加,社会成本趋于稳定,但成本贪心的社会成本随轮数增加变化不大。因为成本贪心在选择胜利者时只关注众测工人的成本。

图3 不同轮数下的社会成本
由图4可知,随着众测工人数量的增加,3种算法的社会成本都逐渐降低。这是因为具有较低成本的工人数量增加,可以使总成本降低。由图5可知,随着任务数量的增加,3种算法的社会成本都逐渐升高,这是因为众测平台需要寻找更多的众测工人以满足任务的能力要求。

图4 不同众测工人数量下的社会成本
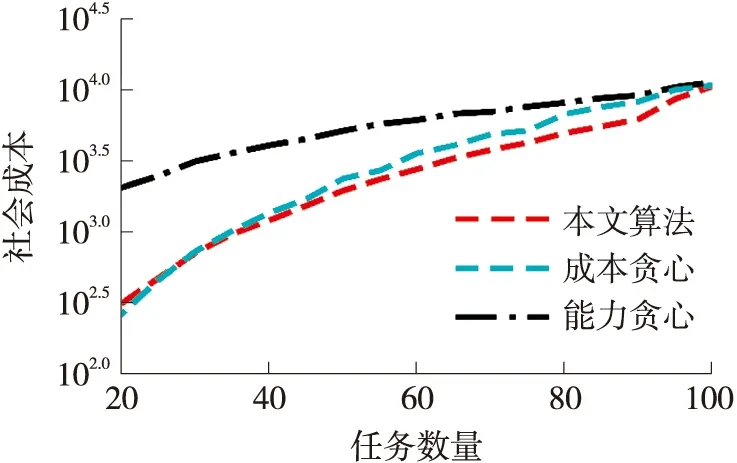
图5 不同任务数量下的社会成本
综上,可知成本贪心的社会成本总是大于本文算法。这是因为成本贪心所选择的众测工人的能力无法被保证,因此它需要选择更多的众测工人去完成任务。能力贪心的社会成本总是最高的,这是因为能力贪心在选择胜利者的时候完全不考虑众测工人的成本问题。对于所有的场景,本文算法的社会成本分别是成本贪心和能力贪心的76.52%和78.21%。
5.2 平均数据质量

从图6可见,除成本贪心以外,其他两个算法的平均数据质量都随着轮数的增加而增加。这是因为这两个算法随着轮数的增加,在不断更新众测工人的能力,因此随着轮数的增加,它们可以选择具有更高能力的众测工人。本文算法和能力贪心的平均数据质量在后期趋于稳定,这是因为在经过一定轮数以后,众测工人的能力值不再变化。从图7可见,本文算法和能力贪心的平均数据质量随着众测工人数量的增加而轻微增加,这是因为它们可以选择更多高能力的众测工人。然而,成本贪心的平均数据质量随着众测工人数量增加而没有变化,这是因为成本贪心在选择众测工人的时候并不关注工人的能力值。从图8 可见,除成本贪心以外,其余两个算法的平均数据质量都随着任务数量的增加而有所降低。这是因为众测平台需要从给定的众测工人集合中选择更多的工人去完成任务,导致平均数据质量降低。
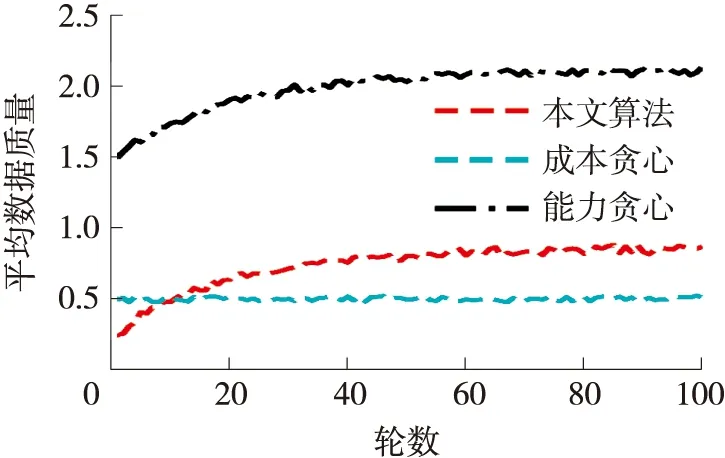
图6 不同轮数的平均数据质量
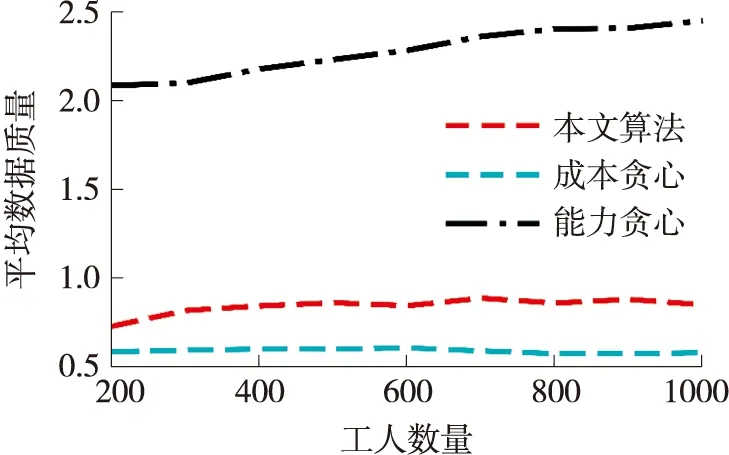
图7 不同众测工人数量的平均数据质量

图8 不同任务数量的平均数据质量
综上,能力贪心的平均数据质量总是高于其他两个算法,因为它总是选择具有最高能力声誉值的众测工人。然而,能力贪心是不真实的,并且它总是具有最高的社会成本。
5.3 防洗白攻击
本文随机选择了一个编号为61的工人,并允许其在第10轮的时候通过一个新身份重新加入。由图9可得,在以新身份重新加入后,工人61在后续任务中将获得较低的效用。

图9 不同轮数下的工人累积效用
本文提出了一种基于声誉系统的软件众测任务分配机制。在满足所有任务的能力要求的基础上,将众测任务分配建模为成本最小能力覆盖问题来最小化社会成本。为了激励具有长期高质量的工人,提出了基于对等预测的声誉系统来衡量工人的声誉,并使用对数奖励规则来保证评价者的真实性。在此基础上,提出了基于反向拍卖的任务分配机制,采用贪心法根据工人的报价和声誉来选择胜利者并决定其报酬。通过严格的理论分析和模拟试验,证明了所提出的任务分配机制具有计算有效、个体理性、真实性、防洗白攻击、保证的近似度等性质。
