基于高光谱成像的番茄叶霉病的无损检测
2022-11-15崔江南付芸赵森邓泽宇王天枢
崔江南,付芸,赵森,邓泽宇,王天枢
(长春理工大学 光电工程学院,长春 130022)
番茄叶霉病又称黑霉病,是由黄褐孢霉菌引起的番茄病害,主要危害叶片,严重时也危及茎、花和果实。番茄叶霉病一旦发生,迅速扩展,一般造成20%~30%的减产,严重时可达50%以上,给番茄生产带来巨大的经济损失。传统的诊断方法主要以人工观察为主,借助于农学人员的判断和农民自身的经验,诊断结果易受主观因素的影响,效率低,误差大,经常会延误治理的最佳时机。因此,迫切需要一种快速、无损、准确的病害检测手段。
近年来,越来越多的学者将高光谱成像技术应用于农作物病害检测的相关研究中。例如水稻稻瘟病、水稻纹枯病[1-2]、小麦白粉病、小麦条锈病[3-4]、玉米种子质量[5-6]等粮食作物类的研究;黄瓜霜霉病[7],茄子[8]、菠菜[9]的冻伤,柑橘黄龙病[10],感染黄瓜绿斑驳病毒的西瓜种子[11],蓝莓腐烂病[12]等果蔬作物类的检测。
在番茄病害检测方面,Gu Qing等人[13]利用高光谱成像技术对受番茄斑点枯萎病毒(Tomato spotted wilt virus,TSWV)侵染初期的烟草进行了检测。结果表明,机器学习方法结合波长选择算法可用于TSWV的早期检测。Nik Susic等人[14]采用高光谱成像方法对被线虫侵染和水分缺乏胁迫的番茄植株开展了研究。结果表明,偏最小二乘法和支持向量机分类器在区分水分充足或缺水的植物时准确率高达100%,在识别线虫侵染的植物时准确率在90%~100%之间。
本文以番茄的叶霉病为研究对象,利用高光谱成像系统分别采集健康、轻微病变、严重病变等三类叶片样本的高光谱数据。首先,运用PCA和SPA提取数据特征;然后,分别利用GSA、PSO和GA三种算法对SVM法的建模参数c、g进行寻优;最后,分别将基于全谱数据、PCA提取的特征变量、SPA提取的特征变量,以及SPA-PCA提取的特征变量作为SVM模型的输入,依次构建了4种番茄叶霉病的分类模型。通过对比分析3种寻优算法及4种分类模型的准确率,确定识别番茄叶霉病的最佳分类模型,为病害的早期防治和病害程度的监测提供理论依据。
1 材料与方法
1.1 样本获取
本实验过程中所用到的番茄叶片均来自于吉林省农业科学院经济植物研究所。于2019年10月21日进入果树种植基地,寻找发生病害的番茄叶片,采摘后的所有病变叶片均经过病理检验,保证其仅含有单一的叶霉病。按照叶片患病区域的大小划分病害严重等级,进行分类后装入不同的保鲜袋密封保存,并放入置有冰块的便携式保温箱中保存,然后迅速送往实验室进行高光谱数据采集。通过筛选最终得到叶霉病严重病变叶片148片、轻微病变叶片160片、健康叶片152片,三类不同病害程度的番茄叶片如图1所示。

图1 三类不同病害程度的番茄叶片
1.2 光谱数据采集和预处理
高光谱图像的采集设备是由上海五铃光电科技有限公司生产的HSI-VNIR(400~1 000 nm)型推扫式可见光-近红外高光谱成像系统,分光仪采用透射式光栅分光,光谱范围为400~1 000 nm,光谱分辨率为2.8 nm,光源为21 V/200 W稳定输出卤素灯。系统主要包括成像光谱仪、CCD相机、光源、电控位移平台、暗箱和计算机等部件,高光谱成像系统装置如图2所示。

图2 可见光-近红外高光谱成像系统
为了减少环境噪声和暗电流对光谱数据采集的影响,高光谱数据采集前,首先对成像装置预热30 min左右,目的是消除基线漂移对图像质量的影响。预热完毕后,打开图像采集软件,对图像采集的相关参数进行设置,以保证图像采集质量且避免失真。设置完毕后,手动将样品放置在载物台上开始图像采集,当叶片整个轮廓完整出现在采集软件窗口中央时,点击停止按钮,此时样品高光谱图像采集完毕,并被保存在预先设置的存储路径中,每个叶片均采集10次,取10次图像数据的平均值作为最终数据,如此重复完成所有样本图像数据的采集。
所有待测样本的高光谱图像数据采集完毕后,为了避免光照不均匀和暗电流的影响,需要对所有原始高光谱图像进行黑白标定。在相同的采集环境下,扫描标准白色校正板得到全白的标定图像,盖上相机镜头后盖得到全黑的标定图像,然后按照公式(1)对原始图像进行校正:
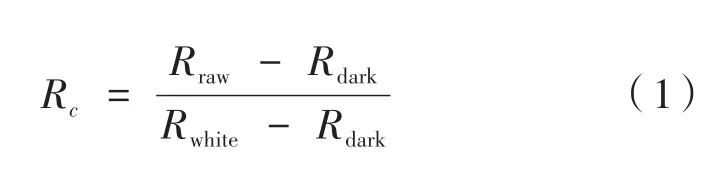
式中,Rc为校正后的高光谱图像;Rraw为利用高光谱图像采集系统采集到的原始高光谱图像;Rwhite为利用标准白色校正板采集得到的全白的标定图像(反射率接近99%);Rdark为关闭相机镜头进行图像采集得到的全黑的标定图像(反射率接近0%)。校正工具为高光谱采集系统自带的软件HSI Analyzer。
为了进一步降低噪声干扰,去除高光谱数据首尾各30个波段,得到400~900 nm波长范围内共462个波长的可见光高光谱数据。将剔除异常样本后的光谱数据按照3∶1的比例划分数据集,得到训练集样本315个,测试集样本105个。
为提取病害叶片的完整光谱信息,根据采集样本病斑特征均匀分布的特点,以叶片叶脉为中心,利用ENVI 5.3软件选取靠近叶尖部位的100像素×100像素的区域作为光谱信息采集的感兴趣区域(region of interest,ROI),最终采集的番茄样本的原始光谱信息如图3所示。
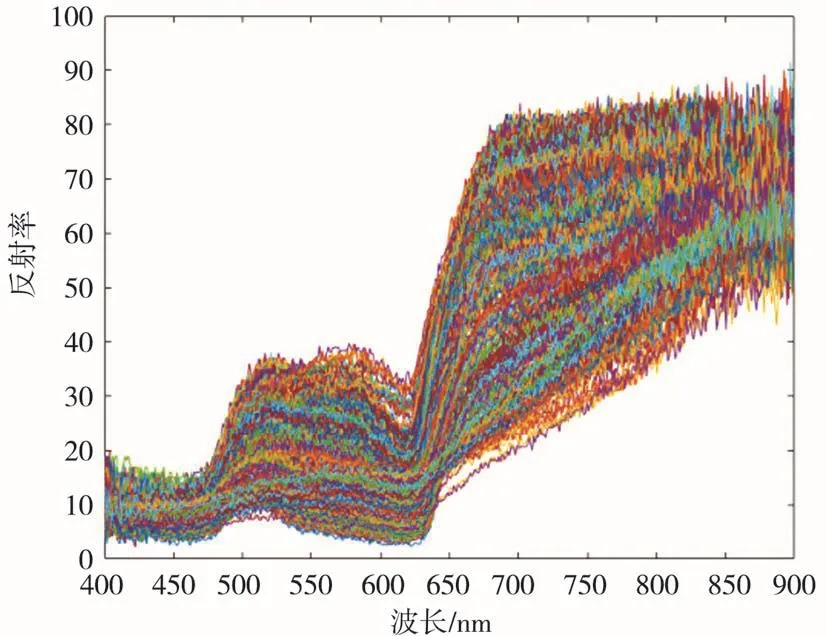
图3 三类番茄叶片的原始光谱信息
为了降低环境、仪器、测量方法等因素引入的干扰,利用MATLAB 2019b软件自带的mapminmax归一化函数对所有高光谱数据均进行降噪平滑处理。为了进一步研究不同病害程度叶片光谱信息的差异,取每组样本反射率的平均值,得到平均光谱反射率曲线。从图4可以看出,番茄叶霉病不同病害程度的光谱反射率存在差异,说明光谱反射率信息可以作为诊断番茄叶霉病病害的依据,但就轻微病变和严重病变两类番茄叶片而言,两条光谱曲线存在很大的相似性,可能导致最终两类番茄叶片的分类结果出现混淆,使分类精度变差。
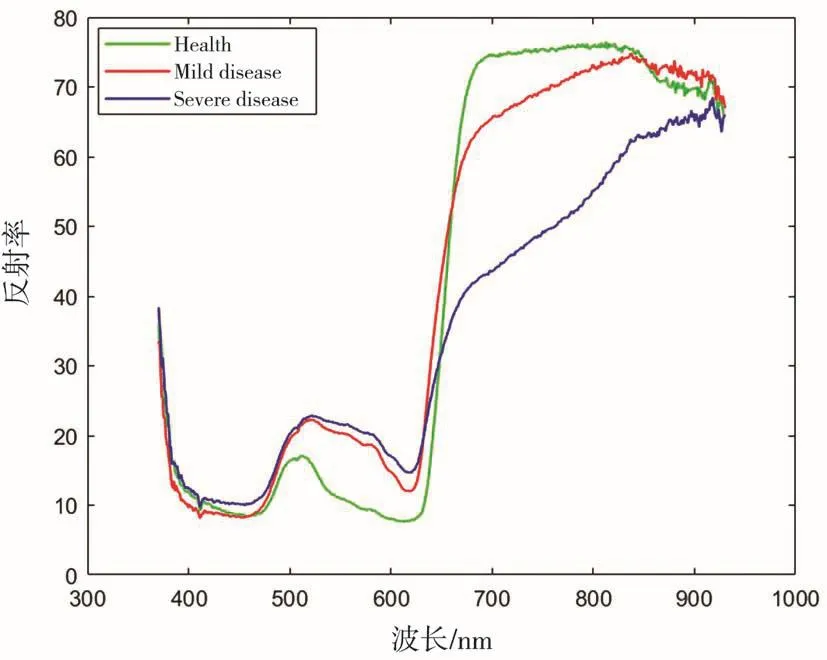
图4 三类番茄叶片的平均光谱曲线
1.3 特征变量提取
为了解决高光谱数据波段多、数据量大而产生的数据相关、冗余、共线性等问题,降低模型的复杂度,提高建模精度和计算速度,运用主成分分析(principle component analysis,PCA)和连续投影算法(successive projection algorithm,SPA)对高光谱数据进行特征变量的提取。
PCA是最常用的数据降维方法之一,它保持了数据中对方差贡献最大的特征,可提取数据的主要特征分量,常用于高维数据的降维。SPA是一种使矢量空间共线性最小化的前向变量选择算法,它的优势在于提取全波段的几个特征波长,能够消除原始光谱矩阵中冗余信息,可用于光谱特征波长的筛选。
1.4 建模方法
支持向量机(support vector machine,SVM)是由Vapnik领导的AT&T bell实验室研究小组在1995年提出的一种基于统计学习理论的分类方法,是一种有监督的机器学习方法。因SVM具有拟合精度高、学习能力强、训练时间短、选择参数少、泛化能力好和全局最优等特点,因而,在解决小样本、高维数和非线性等问题上具有很大的优势。
惩罚因子c和核函数中的参数g是影响支持向量机性能的主要参数,常见的寻优算法有:网格搜索算法(GSA)、粒子群算法(PSO)和遗传算法(GA)。本文将利用SVM建立番茄叶霉病的识别模型,并通过3种寻优算法确定SVM建模的最优参数,以发挥SVM分类器的最佳性能。
2 结果与讨论
2.1 PCA提取主成分
采用PCA算法对全部样本的高光谱数据进行降维,得到前10个主成分(principle component,PC)的特征值和累计贡献率,如表1所示。
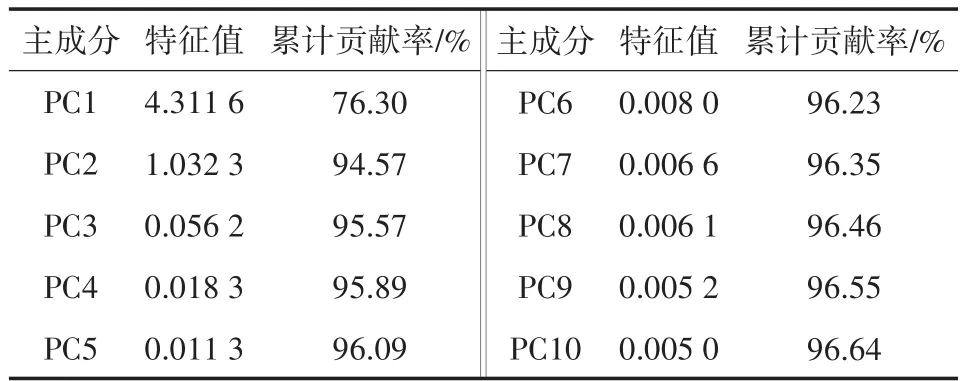
表1 前10个主成分特征值和累计贡献率
其中,PC1的贡献率最大,为76.30%,前2个PC的累计贡献率为94.57%,之后累计贡献率不断增加,但增加幅度减小,即所含的有用信息越来越少。因此,选择前2个PC作为特征变量建模。
2.2 SPA提取特征波长
利用SPA算法提取特征波长,不仅能够提取样本中的有效信息,还能够大幅度地减少构建模型的计算量和复杂度。本研究中设置特征变量的数量范围为10~50,利用MATLAB 2019b软件运行SPA算法对预处理后的光谱进行特征波长的筛选。根据均方根误差(RMSE)选择变量的数量,如图5所示。当变量个数为14时,得到最低值0.399 09,符合显著性水平α=0.25的F检验,因此选择14个特征变量,如表2所示,后续将以此14个波长作为特征变量进行建模。
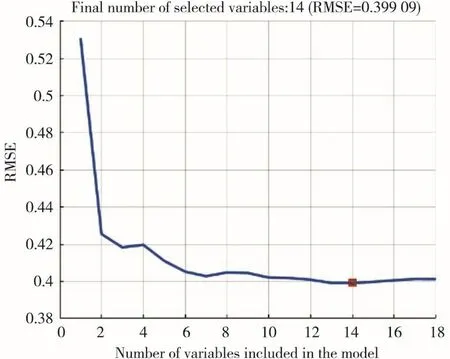
图5 SPA选择不同变量数的RMSE分布图
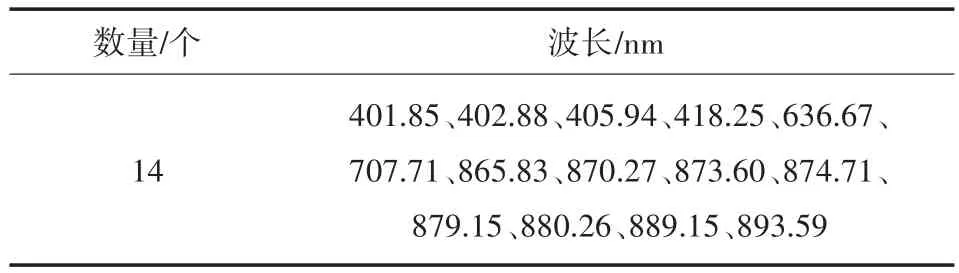
表2 SPA特征波长选择结果
2.3 SPA-PCA联合提取特征变量
通过SPA算法选取番茄叶霉病样本的特征波长数为14个,光谱特征维数仍然很高,为了进一步减少变量之间可能存在的相关性或共线性,获取更少的特征变量,本文利用PCA对SPA选取的特征变量进一步降维,结果如表3所示。由于只有前2个PC的特征值大于1,但累计贡献率没有达到85%,为了尽可能多地保留原始的光谱信息,所以选取前6个PC作为特征变量进行建模。
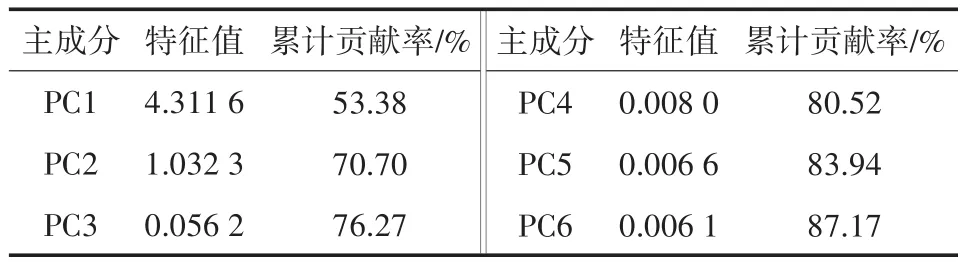
表3 前6个主成分特征值和累计贡献率
2.4 分类建模
分别以全谱、PCA、SPA和SPA-PCA提取的特征变量作为SVM建模的输入,建立番茄叶霉病的全谱-SVM、PCA-SVM、SPA-SVM和SPA-PCASVM的分类模型,核函数选用RBF,每个模型分别使用GSA、PSO和GA获取惩罚因子c和核参数g的最优值,三种算法的寻优结果如图6所示。
其中,图6(a)、图 6(b)为GSA算法的参数寻优结果,根据经验,利用网格搜索算法进行参数优化的SVM其惩罚参数c和高斯核函数参数g的取值范围为 2-10≤c≤210,2-10≤g≤210,参数设置如下:步长cstep=0.5,gstep=0.5,其余参数默认。图6(c)为PSO算法的参数寻优结果,根据经验,利用粒子群算法进行参数优化的SVM其惩罚参数c和高斯核函数参数g的取值范围为0.1≤c≤100,0.1≤g≤10,参数设置如下:初始种群数量 pop=20,加速系数c1=1.5,c2=1.7,最大迭代次数T=200,其余参数默认;图6(d)为GA算法的参数寻优结果,根据经验,利用遗传算法进行参数优化的SVM其惩罚参数c和高斯核函数参数g的取值范围为 0.1≤c≤100,0.1≤g≤10,参数设置如下:初始种群数量pop=20,最大迭代次数T=100,其余参数默认。
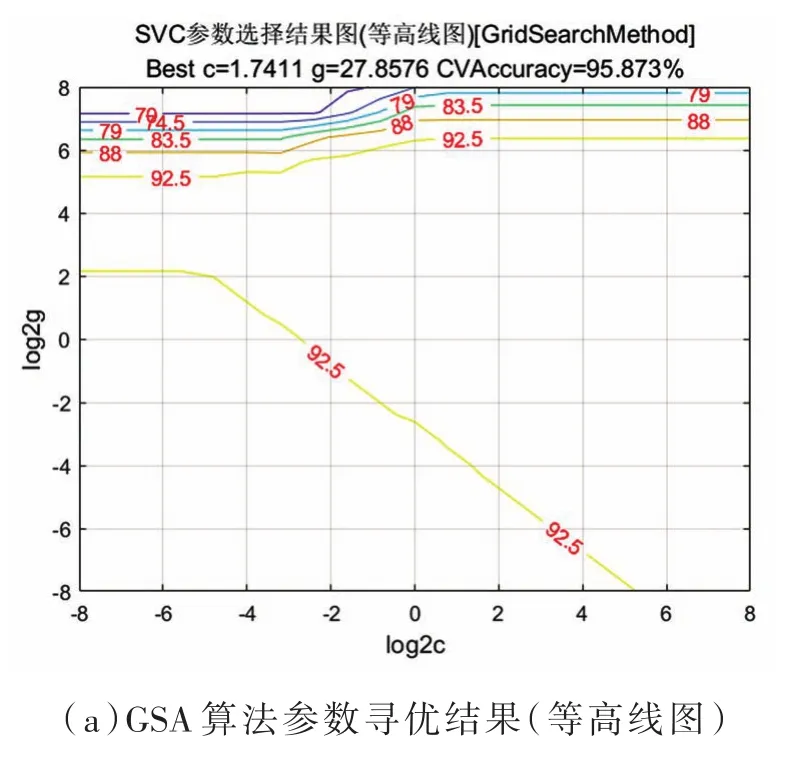

图6 三种不同寻优算法的寻优结果
各分类模型预测准确率如表4所示。
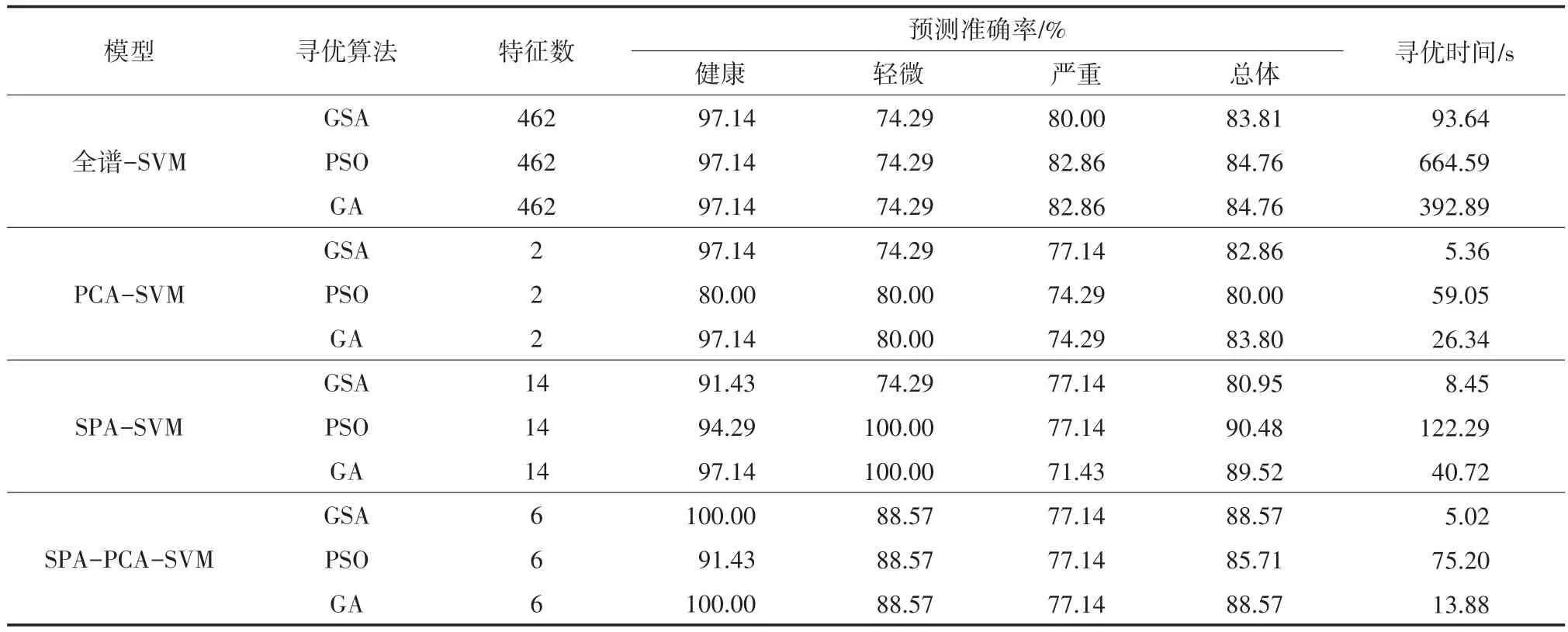
表4 SVM各分类模型预测准确率
由上述分类结果可知,所有模型的总体预测准确率均高于80%,精度较好,模型对健康样本的分类准确度最高,对病变样本的分类准确度稍差。PCA-SVM模型的总体预测精度略低于全谱-SVM模型,但输入变量数由462降为2,在大幅度降低特征维数、缩短运行时间的同时,也丢失了某些特征信息,从而导致分类精度的下降。SPA-SVM模型相比于全谱-SVM模型,特征波段数减小到14,在维持原有健康样本的预测精度时,对轻微病变样本的检测精度大幅提升,可能是提取到了健康样本与病变样本存在差异的特征波段,从而使分类精度提高,但对严重病变的预测结果依旧很差。正常情况下,提取特征变量后会丢失原始样本的某些有效信息,使分类精度降低,但SPA-PCA-SVM模型相比于全谱-SVM模型,健康样本的预测精度有所提升,可能是在特征提取的过程中去除了原始健康样本中的噪声,提高了分类精度。综上所述,从每类分类准确率和总体分类准确率来看,最优模型为SPAPCA-SVM模型,该模型在牺牲少许精度的同时,大幅度减少了输入的特征变量数,提高了计算速度,能够最大程度地区分病变样本与健康样本,但对不同病变程度的样本的区分效果较差,SPA-PCA-SVM模型最优分类结果如图7所示。
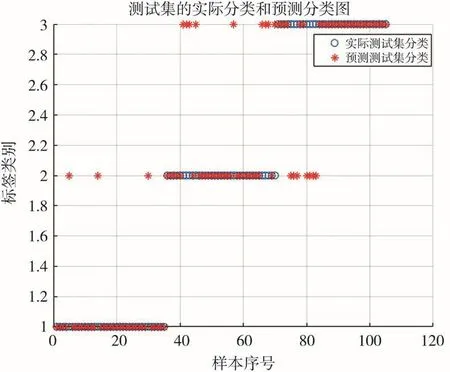
图7 SPA-PCA-SVM模型的最优分类结果
3 结论
本文以不同病变程度的番茄叶霉病叶片样本为研究对象,采用不同的算法提取特征变量,构建了各种番茄叶霉病的识别模型,主要结论如下:
(1)所有模型都对健康样本的识别效果较好,而对不同病变程度的叶片的分类效果有待提高。
(2)PCA、SPA和SPA-PCA等算法均能对高光谱数据进行特征变量的提取,从而大幅度地降低数据的冗余度,减少参与建模的数据量,同时,还能较好地保留样本的特征信息。结果表明,SPA-PCA-SVM模型的分类效果最优,建模输入变量少,检测精度较高,运行速度较快。
(3)从对番茄叶霉病的寻优结果可知,GSA的运行时间最少,GA次之,PSO的运行时间最长。从分类准确率上来看,GSA的分类准确率较高,在大多数情况下,PSO和GA的分类精度与GSA接近,但耗时较长。综合考虑,在利用SVM进行建模时,参数寻优函数可优先选择GSA。
总之,高光谱成像技术可应用于番茄叶霉病的无损检测。今后将从数据预处理、特征变量提取、建模方法等方面加以改进,以提高分类精度。此外,由于仅通过肉眼根据患病区域大小来定义标签,存在人为误差,导致标签精度不高,严重影响了分类准确率,后续将借助病变多层分级、聚类分析和叶绿素定量分析等手段提高标签精度。大量研究表明,高光谱图像中的纹理和颜色等特征也包含了重要信息,接下来将对光谱特征与图像特征进行融合,进一步提升分类效果。
