基于改进残差网络的低空无人机声音识别方法
2022-11-15薛珊卫立炜顾宸瑜孟宪宇贾冰
薛珊,卫立炜,顾宸瑜,孟宪宇,贾冰
(1.长春理工大学 机电工程学院,长春 130022;2.长春理工大学 重庆研究院,重庆 400000;3.西安交通大学 信息与通信工程学院,西安 710049)
随着现代科技的快速发展,无人机的使用门槛变得越来越低,无人机越来越普遍。由于缺乏统一的行业标准和规范,无人机“黑飞”问题日益严重,使得无人机被滥用的可能性大大增加。无人机在低空空域的非合作入侵飞行事件在国内外屡见不鲜,不仅伤害了公民的隐私和生命财产安全,更对公共安全和国家安全构成了极大威胁[1]。因此,对无人机的检测和识别就显得尤为重要。
目前为止,无人机的识别方法多种多样,包括图像识别[2-3]、雷达数据分析[4-6]以及无线电信号识别[7-9]等方面。图像识别无人机时,无人机在远距离上的视觉特征较弱,尺寸较小,易受到遮挡,并且容易受到外在环境的影响。雷达探测主要是运用雷达信号的回波来探测目标,但存在固有的探测盲区,而且价格昂贵、体积大、放射性强,不适合城市环境。出于便利性和经济性考虑,运用麦克风阵列,这种基于声学的低空无人机探测识别方法[10-12]正在被越来越多地研究,它不取决于无人机的大小和位置,而是取决于螺旋桨的声音,可以有效地探测识别无人机[13-15]。如何运用声音识别无人机,如何能够更准地识别无人机成为了研究的热点。
基于此,提出了一种基于残差网络改进的低空民用无人机声音识别方法(Improved Residual Block Network,IRBNet),旨在更准地识别无人机。
1 无人机声音数据集的建立及特征提取
1.1 无人机声音数据集的建立
由于目前并没有开源且成熟的无人机数据集供使用,因此需要建立无人机声音数据集。
运用声音采集设备,在现实环境中对实验无人机声音进行录制采集,保证获得的声音信号都是真实数据。然后对采集到的音频数据进行滤波、预加重、分帧、加窗等预处理。将较长的声音信号分割为4 s的声音片段,保持50%的重叠,保证最后的无人机声音片段全部有4 s的持续时间[16]。最终,得到将近600个长度为4 s的无人机声音片段。之后对声音样本进行人工标记,获得标签数据。
Urbansound8K 数据集[17]是由 8 732个带标签的声音片段组成的数据集,每个声音片段具有最大4 s的持续时间。8 732段录音来自十个声音类别,它们是汽车喇叭、狗吠、发动机空转、风钻、空调、街头音乐、儿童玩耍、钻探、枪声和警笛。
Urbansound8K数据集中的汽车喇叭和儿童玩耍两种声音数据被调用以充当无人机数据集中的负样本。然后把处理过的无人机声音片段加入其中,构成最终的数据集。数据集中的所有样本长度都小于等于4 s,共3类。在三类样本信号中随机各选取一个片段,其语谱图及波形图如图1所示。
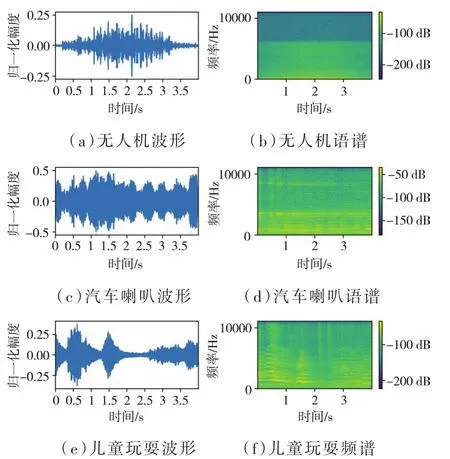
图1 三类音频的语谱图及波形图
1.2 音频特征提取
卷积神经网络识别模型需要输入选定的特征进行训练和测试,预测结果。合适的特征不仅可以以非常紧凑的方式模拟信号的属性,降低运算维度,还可以更精准地表征声音信号。因此,特征的好坏对网络模型有着很重要的影响。
常用的表征声音信号的特征有线性预测倒谱 系 数(Linear Prediction Cepstral Coefficients,LPCC)[18-19]、Log-Mel[20]、MFCC[21-22]以 及 小 波(Wavelet)[23]等。本文研究并比较了 MFCC 和Log-Mel及其一阶差分特征,最终采用最合适的提取特征。
MFCC提取过程为:首先对信号进行预加重、分帧、加窗和傅里叶变换;然后计算功率谱,并将功率谱通过三角带通滤波器进行滤波,输出结果运用Mel域频率与线性域频率间的关系转换为对数形式;最后进行离散余弦变换(DCT),得到MFCC[24]。其提取流程如图2所示。
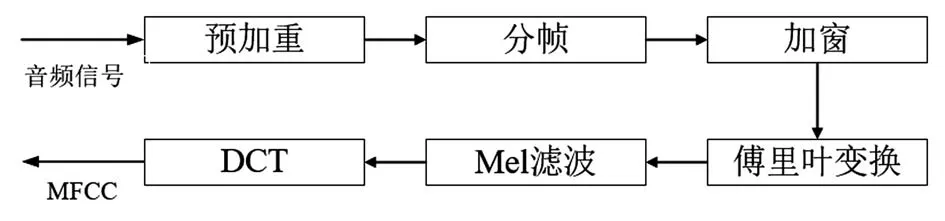
图2 MFCC提取流程示意图
Log-Mel特征与MFCC的计算步骤基本一致,区别在于前者少进行一步DCT操作。从计算量上看,MFCC是在Log-Mel特征的基础上进行的,所以MFCC的计算量更大。从特征区分度上看,Log-Mel特征相关性更高。高斯混合模型(GMM)由于忽略了不同特征维度的相关性,MFCC更适用。而卷积神经网络(CNN)可以更好地利用这些相关性,使用Log-Mel特征可以更多地降低错误指标。故最终采用Log-Mel特征。
由于声音信号在时域中是连续的,因此通过分割帧提取的特征信息仅反映了该帧信号中声音的特性。为了使特征更好地反映信号的时域连续性,通常选择加入其差分特征。本文选择一阶差分作为补充。分别提取Log-Mel特征和MFCC及其一阶差分特征矩阵一起作为双通道提供给网络。汽车喇叭、儿童玩耍以及无人机信号的其中一个片段的log-Mel谱图及一阶差分谱图如图3所示,MFCC及其一阶差分的表示见图4。从特征谱图中看出每个信号的特征都是特定的,可以被区分。
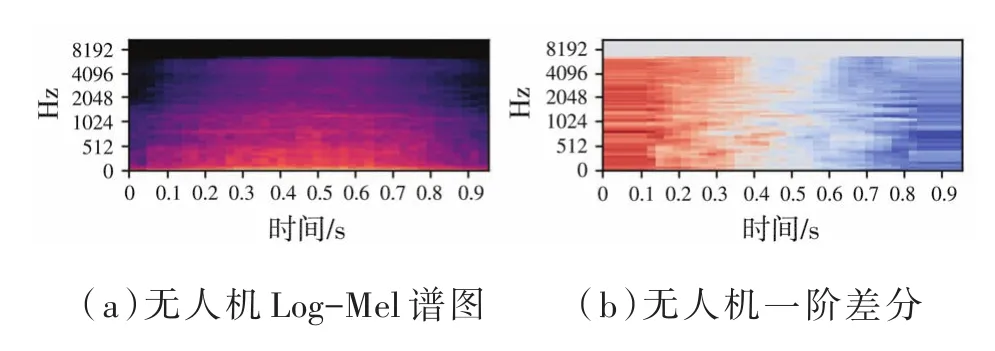
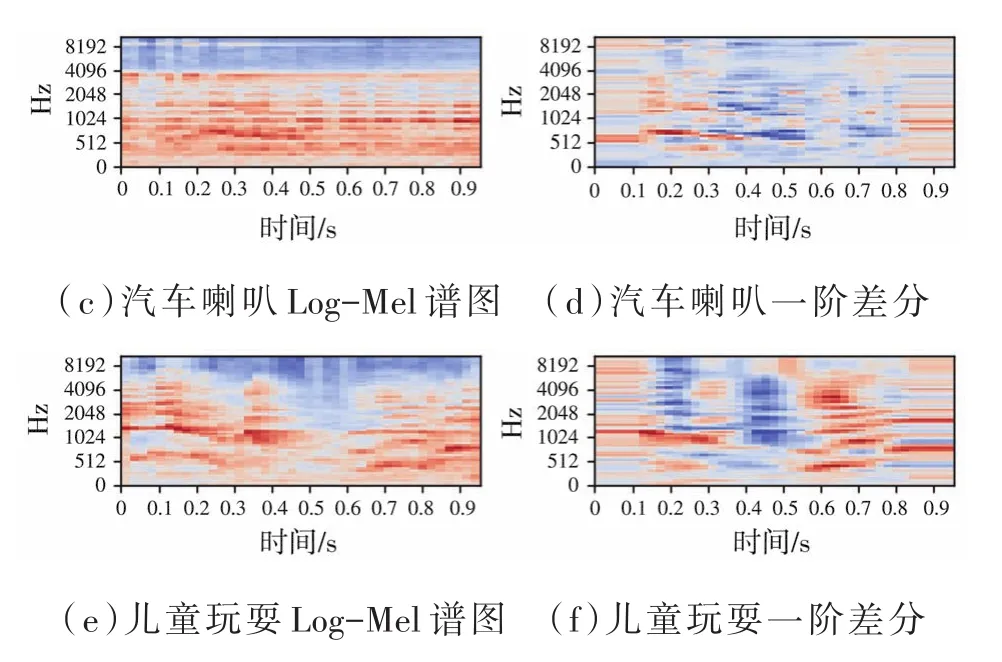
图3 三类音频的Log-Mel谱图及一阶差分

图4 三类音频的MFCC及一阶增量
2 基于残差网络改进的卷积神经网络IRBNet的设计
进行音频特征提取后,需要设计用于声音识别无人机的网络,也就是设计一种声音识别的算法。目前,在环境声音识别任务中,运用卷积神经网络进行识别的方法比较流行[25-26]。基于此,本文基于远跳连接构建IRTBlock,设计了基于残差网络的改进的卷积神经网络IRBNet,对无人机进行声音识别。
2.1 设计远跳连接IRTBlock
输入x,经过若干层卷积和激活后,得到的输出F(x),再加上原来的输入,最终输出为F(x)+x,这就是远跳连接(Skip Connection)[27]。它可以解决由于网络深度增加而导致的网络退化问题,使得深层网络的表现优于浅层网络。基于此,本文构建了如下两种模块:IRTBlock-A和IRTBlock-B。这两种模块的结构示意图如图5所示。其中num_filtes代表设置的过滤器数量;CONV表示卷积层;BN表示批归一化(Batch Normalization)层[28],它能够减少内部变量偏移从而加速深度神经网络的训练。
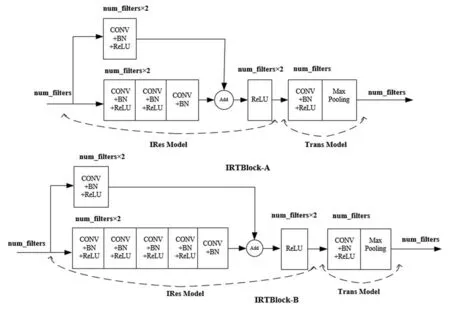
图5 设计的IRTBlock的结构示意图
IRTBlock-A:主通路为 1×1 Conv+BN+Re-LU+3×3 Conv+BN+ReLU+3×3 Conv+BN(其 中 1×1 Conv表示核大小为1×1的卷积层);远跳连接通路为1×1 Conv+BN+ReLU,通过1×1卷积来调整大小,使得维度相等;然后,把两者的输出进行逐元素相加(Add)融合,并通过ReLU激活函数来引入非线性,这一部分被称为IRes-Model;最后,把融合结果在输入汇聚层之前,运用1×1卷积进行降维,这一部分记作Trans-Model,用于连接各个IRes-Model以及进行特征降维。
IRes-Model中所有卷积层的步长均为1,卷积核数目相同,使用“SAME”填充。因此,各层输出具有相同尺寸,可以进行Add运算,构成深度融合层(add layer)。模块中所有卷积层都加入了BN层,用于加快收敛速度。把IRes-Model和Trans-Model统称为IRTBlock-A.
IRTBlock-B:先进行 1×n卷积再进行 n×1卷积,与直接进行 n×n卷积的结果是等价的[29]。非对称卷积可以减少网络参数,降低运算量,加快训练,而且可以进一步增加网络的非线性。本文顶层模块运用非对称卷积来代替IRTBlock-A中的 3×3对称卷积,即3×3卷积变为1×3和 3×1的顺序堆叠;其余结构不发生改变,与IRTBlock-A一致,被记作IRTBlock-B。
2.2 设计IRBNet网络
基于IRTBlock-A和IRTBlock-B,构建基于残差网络改进的卷积神经网络IRBNet。其中所有卷积层都加入BN层,来加快收敛速度。除输出层使用Softmax激活函数外,所有隐藏层都采用整流线性单元(ReLU)激活函数。所有填充均设为“SAME”。网络结构示意图如图6所示,框图上方数字代表输出特征图尺寸大小。“Conv”表示卷 积 层 ;“s”代表 步 长 ;“num_filters”表示 设定的滤波器数量,“FC”表示全连接层。网络结构参数如表1所示(其中,Maxpool表示最大池化;s表示步长)。详细结构如下:
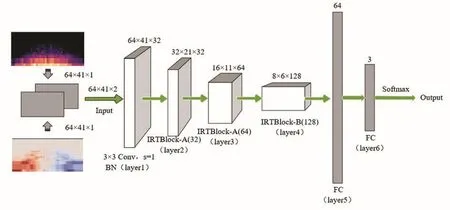
图6 IRBNet结构示意图
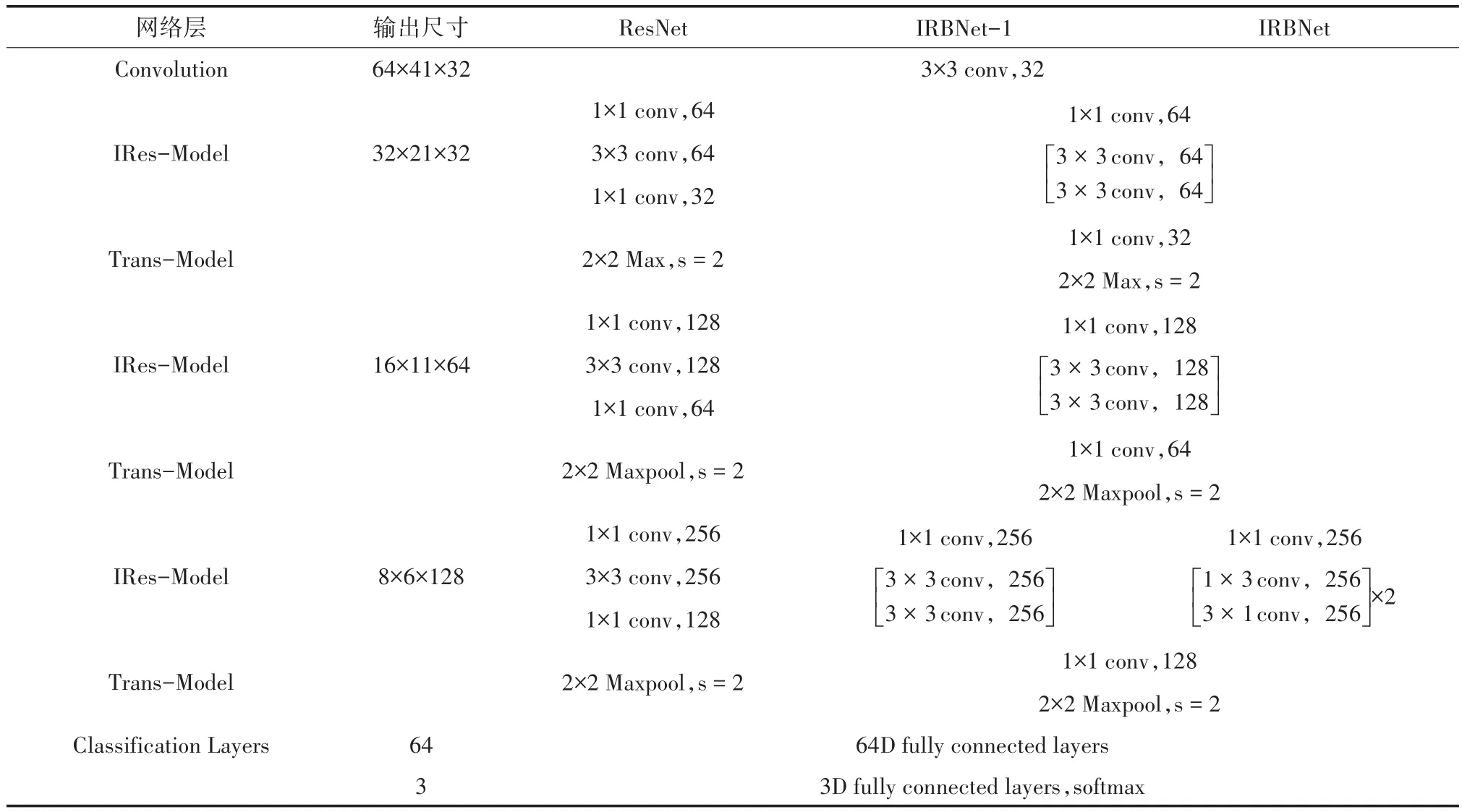
表1 包含IRBNet在内的几种网络的结构和参数表
L1:第一层,包含32个核大小为3×3的卷积核,填充设为“SAME”。不使用最大池化。运用ReLU作为激活函数。
L2:第二层,IRTBlock-A,其中“num_filters”设置为32。
L3:第三层,IRTBlock-A,其“num_filters”设置为64。
L4:第四层,IRTBlock-B,其“num_filters”设置为128。
L5:第五层,也是第一个全连接层,由64个隐藏单元组成,其激活函数为ReLU。使用值为0.4的丢弃率来防止过拟合。
L6:第六层,是第二个全连接层,也被称为输出层。它的数量等于数据集中的类别总数。该层中使用的激活函数为Softmax。
3 实验与分析
本研究设置了两个实验。第一个实验重点比较几种特征的优劣,网络模型保持一致,均选用设计的IRBNet,旨在找出适合的特征;另一个实验为了对比本文设计的基于残差网络改进的卷积神经网络IRBNet与其他网络的优劣性,输入特征保持一致。
3.1 实验准备
所有的实验都是在Python语言环境下完成的,版本为3.7.6。主要运用Keras库从头开始训练网络,运用Librosa库实现各种特征提取操作。采用的是Windows10平台。运行设备CPU型号为i7-9750H,显卡为GTX1660TiMQ。
实验中,几种网络的优化方法都使用带有动量的小批量随机梯度下降(SGD),历元数设为150,批次大小设为128,动量设为0.9。损失函数均采用交叉熵损失函数。采用指数衰减学习率来提高模型的收敛速度及其泛化能力,以此来获得更好的效果。加入Dropout层来减轻因数据集小而网络模型层数较多带来的过拟合问题。
3.2 几种特征的对比实验
本实验旨在找出合适的特征,故均使用IRBNet作为基准网络,只改变输入网络的音频特征。方法一:输入Log-Mel特征及一阶差分(双通道);方法二:输入Log-Mel特征;方法三:输入MFCC特征;方法四:输入MFCC特征及一阶差分(双通道)。实验结果如表2所示,识别准确率曲线如图7所示。
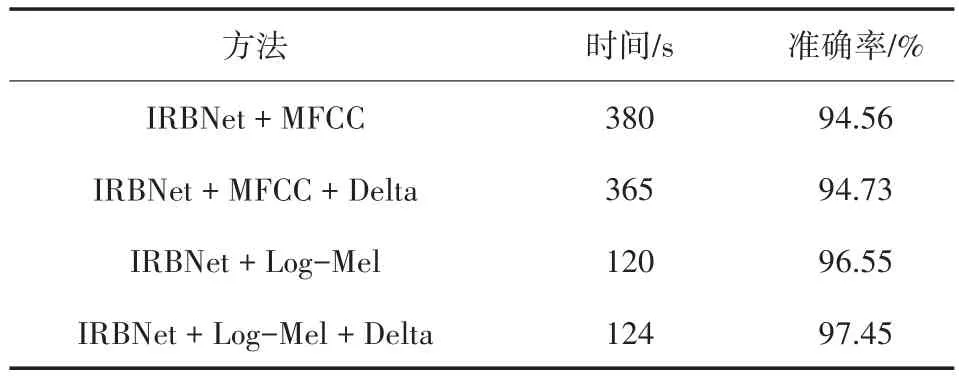
表2 几种方法的识别精度比较表
从表2和图7可以看出,选择Log-Mel特征及一阶差分输入IRBNet时,准确率最高,可以达到97.45%。在时间上,Log-Mel以及其差分组合特征和Log-Mel特征用时少,虽然前者时间略高于后者,但前者准确率要比后者高很多。实验结果表明,Log-Mel特征及一阶差分组合特征的性能最好,故本文选取Log-Mel特征及其一阶差分来表征无人机声音。
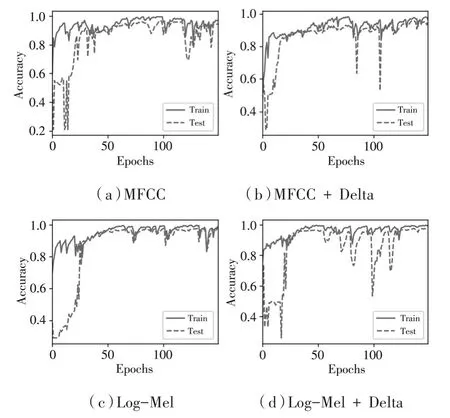
图7 IRBNet上几种特征的准确率曲线
3.3 几种网络的对比实验
本实验旨在验证本文设计的IRBNet和其他几种基准网络的优劣性,输入特征保持一致。网络的详细介绍如下。
3.3.1 基准网络
设计IRBNet-1作为一种基准网络,比较两种IRTBlock对网络性能的影响。IRBNet-1是把IRBNet的第四层模块IRTBlock-B用IRTBlock-A代替,其余与IRBNet一致。搭建ResNet作为一种基准网络,来比较IRBNet与残差网络的性能优劣。IRBNet-1和ResNet的结构参数如表1所示。
除此之外,还设计了两个卷积神经网络CNN-1、CNN-2作为基准网络。CNN-1由2个卷积层、2个最大池化层和2个全连接层构成。两个卷积层中卷积核大小均为5×5,步长为1;池化核大小为2×2,步长为2。第一个全连接层有64个神经元,且使用值为0.4的Dropout来减轻过拟合现象。第二个全连接层即为输出层。所有填充均设为“SAME”。除输出层使用Softmax激活函数外,其他层都采用ReLU激活函数。CNN-2只是把CNN-1中5×5大小的卷积变为两个3×3大小卷积的堆叠,其余结构不进行改变。两个网络的结构参数如表3所示。
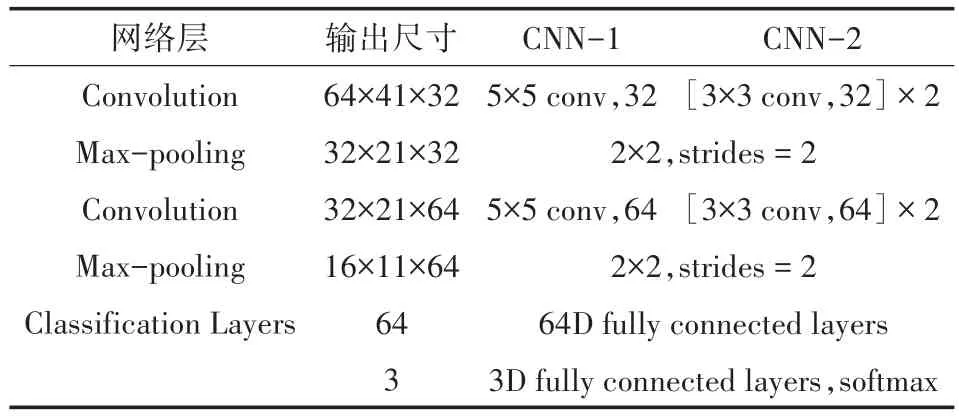
表3 两个CNN的结构及参数表
3.3.2 实验结果与分析
本实验的主要目的是比较几种基准网络与IRBNet的性能优劣。几个网络同时输入相同音频特征(Log-Mel特征及一阶差分)。实验比较了几种基准网络与IRBNet在无人机声音数据集上的识别准确率,其对比统计结果如表4所示。几种方法的准确率曲线如图8所示。

表4 几种方法的识别精度比较表
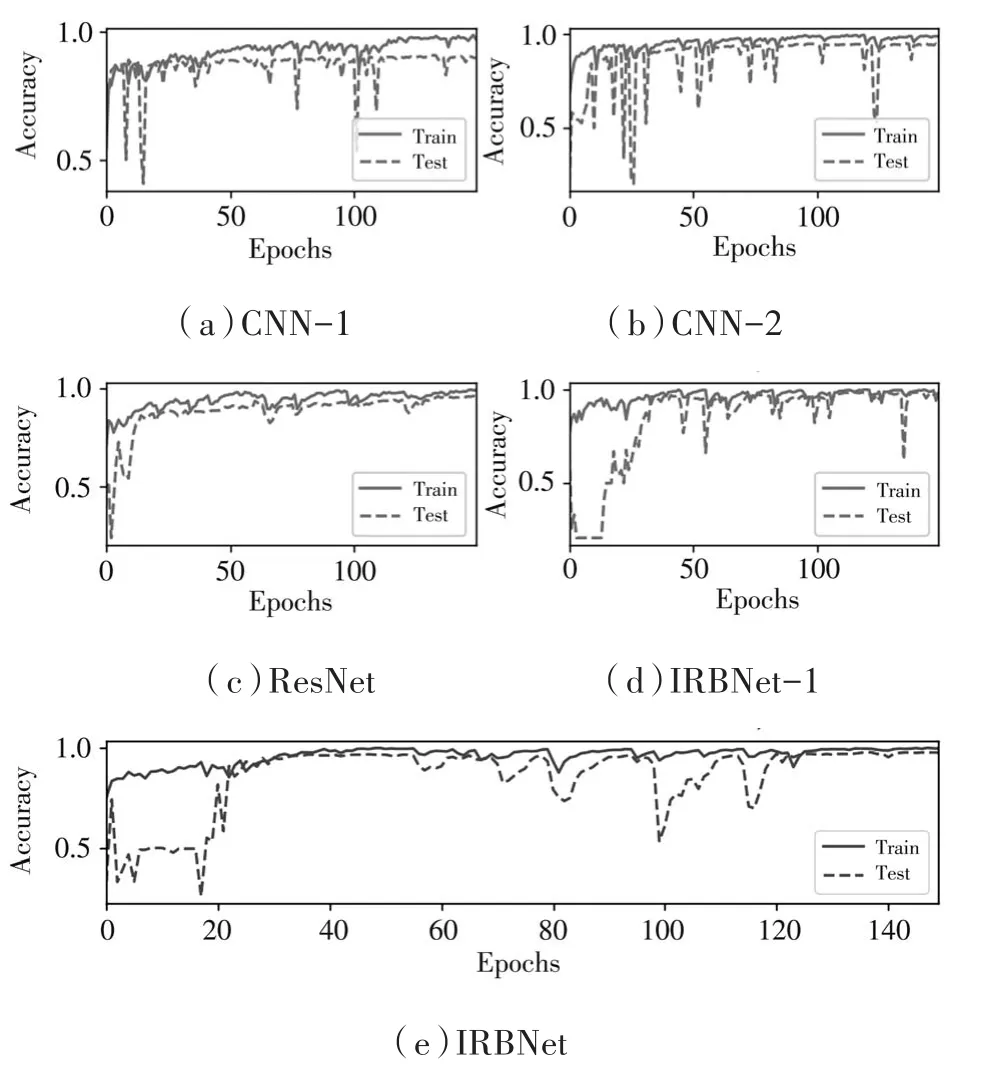
图8 几个方法的准确率曲线
从图8以及表4可以看到,相同特征输入IRBNet和几种基准网络,设计的IRBNet和IRBNet-1准确率更高。其中,IRBNet的准确率最高,可达97.45%。结果表明,非对称卷积使得网络的非线性特性增强,使得信息的流通得到了优化,可以学习音频信号中更多的局部特征,使得对于特征的学习能力增强,从而提高了实验效果。实验结果表明,IRBNet的识别准确率最高,性能更好。
4 结论
(1)针对无人机分类识别问题,提出了一种基于残差网络改进的卷积神经网络的低空民用无人机声音识别方法,即IRBNet。
(2)采集低空无人机声音数据并进行预处理,得到低空无人机声音数据集,提取特征参数输入IRBNet进行识别,实验结果表明所设计的网络能够更准确地识别无人机,其识别精度可以达到要求。
