基于元课程强化学习的多智能体协同博弈技术
2022-11-12丁季时雨孙科武董博杨皙睿范长超马喆
丁季时雨,孙科武,董博,杨皙睿,范长超,马喆
(中国航天科工集团有限公司第二研究院 未来实验室,北京 100854)
0 引言
多智能体系统是由一群有自主性、可相互交互的实体组成,它们共享一个相同的环境,通过感知器感知环境并通过执行器采取动作。多智能体系统的目标是让若干个具备简单智能却便于管理控制的系统能通过相互协作实现复杂智能,使得在降低系统建模复杂性的同时,提高系统的鲁棒性、可靠性、灵活性[1-3]。
复杂环境下不完全信息动态博弈问题已成为亟待解决的前沿热点问题,可应用于无人机蜂群等集群博弈对抗中,而多智能体协同博弈决策技术是其核心关键之一[4-6]。多智能体协同博弈具有实时对抗及动作持续性、多智能体并存与异构智能体协作、非完全信息博弈、庞大的搜索空间、多复杂任务和时间空间推理等特点,当前,以深度学习和强化学习为代表的人工智能技术取得了较大的突破,多智能体协同博弈决策问题的解决方法从传统的基于预编程规则的方法转向智能体自主强化学习为主的方法[7-8]。采用深度学习与强化学习结合的方法,研究多智能体间的合作、竞争和对抗任务,能为解决未来军事协同对抗问题提供新的有效途径。
目前,已有多智能体协同博弈技术包括基于通信[9-13]的和基于值分解[14-16]的强化学习方法,两类方法解决了多智能体之间通信受限以及信度分配不均的问题,但是大规模多智能体协同博弈仍存在学习训练时间长的问题。本文提出了一种基于元课程强化学习的多智能体协同博弈技术,对多智能体协同的对抗策略进行在线生成,并在《星际争霸》仿真平台上进行仿真实验,与传统的训练方法进行对比可有效地加速其训练过程,相对于传统训练方法在较短时间内可以达到较高的胜率,该方法可实现多智能体协同博弈策略的高效生成。
1 多智能体强化学习协同博弈框架
1.1 状态空间
状态空间包括外部环境、我方兵力和敌方兵力的数量、状态等内容,是一个高维的张量,需要从中选择出有限的维数作为状态空间,成为多智能体对抗决策强化学习的输入。
在本模型中,状态空间分为2 部分:①共享的状态空间,在所有智能体间共享,如战场环境信息、我方兵力和敌方兵力的部分信息等,这使得每个智能体具有全局的视野;②局部状态信息,由每个智能体通过对周围一定范围(如视距范围)内环境的感知得到,如其附近我方和敌方智能体的数量、位置和状态等信息,其特点是局部信息较为详尽、信息实时性较高,该局部视野有助于智能体采取具体的动作或对其动作进行调整。
1.2 动作空间
每个智能体的动作空间采用连续状态描述,为一个三维的实数向量:第1 维为攻击概率,从[0,1]中抽取一个值,如果采样值为1,则智能体攻击;否则,智能体移动。第2 维和第3 维对应的是采用极坐标描述的角度和距离,表示智能体从当前位置移动或攻击的目的地。
1.3 奖励机制
智能体的目标被形式化表征为一种特殊信号,称为收益,它通过环境传递给智能体。奖励函数分为全局奖励和局部奖励。
(1)全局奖励
首先,定义时变的全局奖励函数为敌方智能体生命值的减少量均值减去我方智能体生命值的减少量均值,具体计算公式为

式中:rt(s,a,b)为在时刻 t、状态 s 下,我方智能体采用动作a,敌方智能体采用动作b 时,我方智能体的全局奖励。
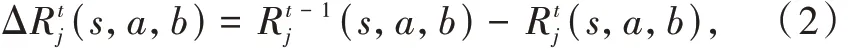
式中:R 为智能体的生命值;ΔR 为智能体生命值的减少量。我方智能体的目标是学习到一种策略可奖励折扣因子。对应敌方智能体的联合策略是最小化奖励之和。
(2)局部奖励
只使用全局奖励函数可能会忽略以下事实:团队协作通常由局部协作和奖励函数促成,并且通常包括某些内部结构,每个智能体倾向于根据自己的目标来推动合作。
为建模此种情况,可以定义每个智能体自己的局部奖励函数,我方单个智能体的奖励函数可以定义如下:
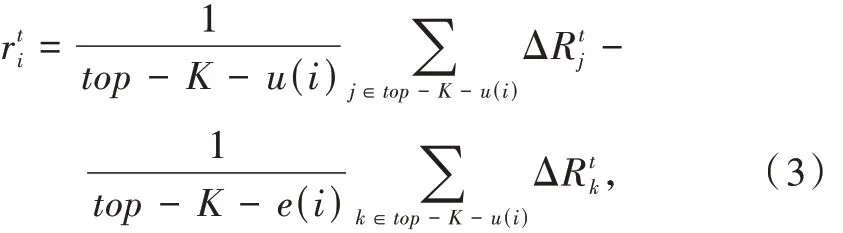
式中:top - K - u(i)表示与智能体i 交互的K 个智能体中敌方智能体的集合;top - K - e(i)表示与智能体i 交互的K 个智能体中我方智能体的集合。
式(3)表示智能体i 的奖励由最近的K 个智能体(包括我方和敌方智能体)的生命值减少量决定。具体来说,就是其中敌方智能体的生命值减少量减去我方智能体的生命值减少量。算法具体采用局部奖励函数计算每个智能体每步的奖励,这样更加利于收敛。
1.4 Actor-Critic 架构
本文基于元课程强化学习的多智能体协同技术采用Actor-Critic 架构,Actor-Critic 从名字上看包括2 部分,演员(Actor)和评价者(Critic)。其中Actor使用1.3 节讲到的策略函数,负责生成动作(Action)并和环境交互;而Critic 使用之前所提到的动作价值函数,负责评估Actor 的表现,并指导Actor 下一阶段的动作。
该架构利用深度神经网络对强化学习中的策略函数以及动作价值函数分别进行近似:

式中:πθ(a|s)为策略网络;P(a|s)为给定状态 s 下选择的动作a 的概率;Qw(s,a) 表示价值函数网络;q(s,a)为在给定状态动作 (s,a)下的价值。
如图 1 所示,智能体 1,2,…,N 通过与环境进行交互,获取局部观测 oi,执行动作 ai,获得奖励 ri,进行分布式策略执行。同时将动作、奖励等信息传递到中心式训练评价网络,将总的动作价值进行分解,为每个智能体分配相应的动作价值,最后每个智能体更新相应的策略网络。

图1 多智能体强化学习协同博弈框架Fig.1 Multi-agent reinforcement learning autonomous coordination framework
因此Actor-Critic 算法拥有2 部分参数:动作价值函数(Critic 网络)参数 w 以及策略参数(Actor 网络)θ。2 类参数的更新方法为
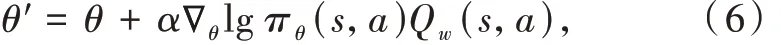
式中:θ 为策略网络参数;α 为更新步长;Qw(s,a)为价值函数。
对于Critic 网络本身的模型参数w,一般都是使用均方误差损失函数来做迭代更新,可以表示为

式中:δ 为时间差分奖励;Rt+1为 t + 1 时刻的奖励;Q(St,At)为 t 时刻的动作价值;w 为价值网络的参数;β 为更新步长;φ(s,a)为线性函数。
1.5 训练方法
为了给评价者Critic 提供学习所需的其他智能体的信息,本文采用集中式训练-分布式执行的训练框架,即训练时采用全局信息集中式学习训练Critic 与Actor,使用时每个智能体的Actor 只需要获取局部信息就能运行,如图1 所示。在应用中只使用局部信息进行决策的条件下,允许使用一些额外的信息(全局信息)进行学习,这也改善了Q-learning在学习与应用时必须采用相同的信息的局限性。
2 基于元课程学习的协同博弈技术
针对大规模异构多智能体训练时间长、难度大等问题,本文提出基于元课程学习的大规模异构多智能体强化学习训练框架,运用基础课程元模型提取、基于课程学习的元模型迁移等机制,降低了大规模异构多智能体强化学习训练的难度,提高学习效率。
本文将大规模学习问题基于部分可观测性自然地转化为若干小规模问题,并且在多智能体系统中,智能体往往只需要与邻域内的个体进行合作,最终实现整体目标协调,这形成了一个稀疏的交互环境。基于元课程学习的大规模异构多智能体强化学习训练框架从小型多智能体场景下开始学习,并逐步增加学习目标任务的多智能体数量,跨越不同任务,加快元课程学习过程。下面将定义课程学习以及元课程的相关概念。
定义1:课程学习是指多智能体协同博弈模型先从容易的任务开始学习,并逐渐进阶到复杂的任务,将该课程表示为 T ={T1,T2,…,Tk-1,Tk}。
定义2:元课程是指上述课程列表中较为简单的任务,即T1,T2,…,Tk-1,Tk表示需要学习的复杂任务。
定义3:元模型是指针对元课程进行训练得到的策略模型,即 π1,π2,…,πk-1。
随着智能体数量的增加,逐步构建课程来进行大规模异构多智能体学习训练,课程序列可以手动设计或自动生成。图2 展示了一个包含3 个课程的动态多智能体元课程学习机制示例。在星际争霸Ⅱ中,目标课程是在20 对战20 的场景,先学习课程1,即 5 对战 5 的场景,然后学习课程 2,即 10 对战 10 的场景,最后学习终极目标课程。
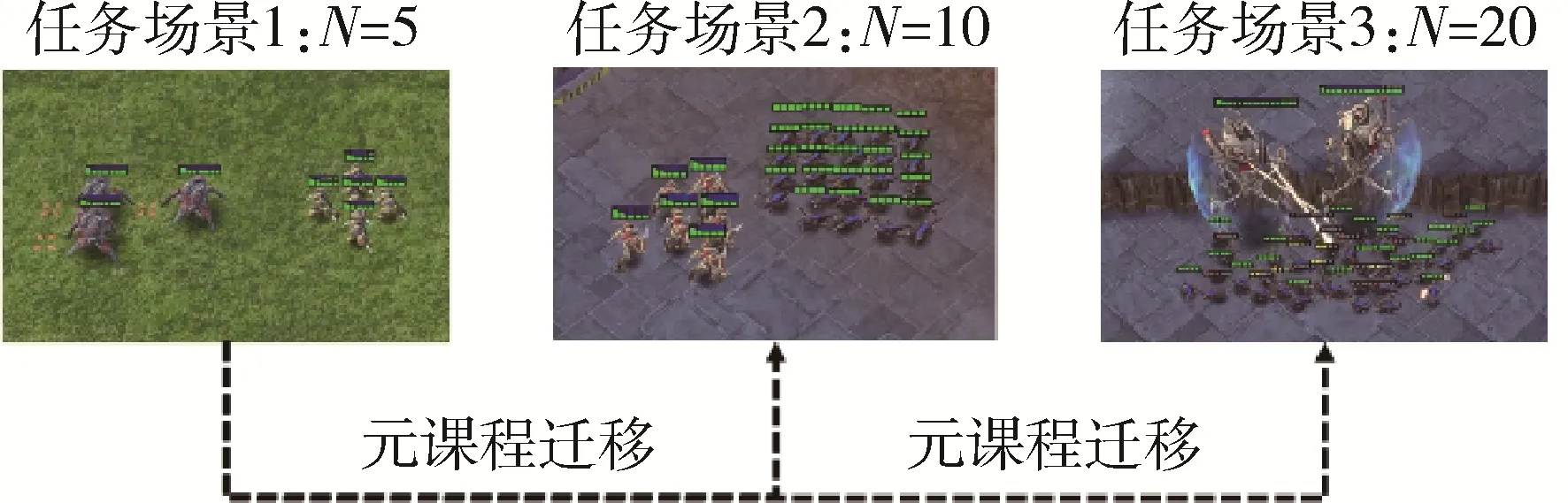
图2 星际争霸Ⅱ元课程构建示意图Fig.2 Meta curriculum construction based on Star Craft Ⅱ
2.1 元课程模型提取
距离蒸馏法(kullback-leibler,KL)作为一种更普遍的监督模式,适用于on-policy 和off-policy 的强化学习算法。给定元课程序列T ={T1,T2,…,Tk-1}以及当前复杂课程Tk,为了加速当前的学习训练过程,通过对学习过的课程进行蒸馏把基础课程的知识进行转化,利用元学习方法针对元课程序列T ={T1,T2,…,Tk-1}训练元模型。具体来说,增加了一个额外的蒸馏损失LDistil,作为常规强化学习损失的正则项。

图 3 中,πi为课程 Tk的策略网络,π*为元模型策略网络,由于元课程序列 T ={T1,T2,...,Tk-1}的智能体数量不断增加,不同的元课程网络输入有所不同,网络维度逐渐增加,将维度较小的网络进行补零处理。
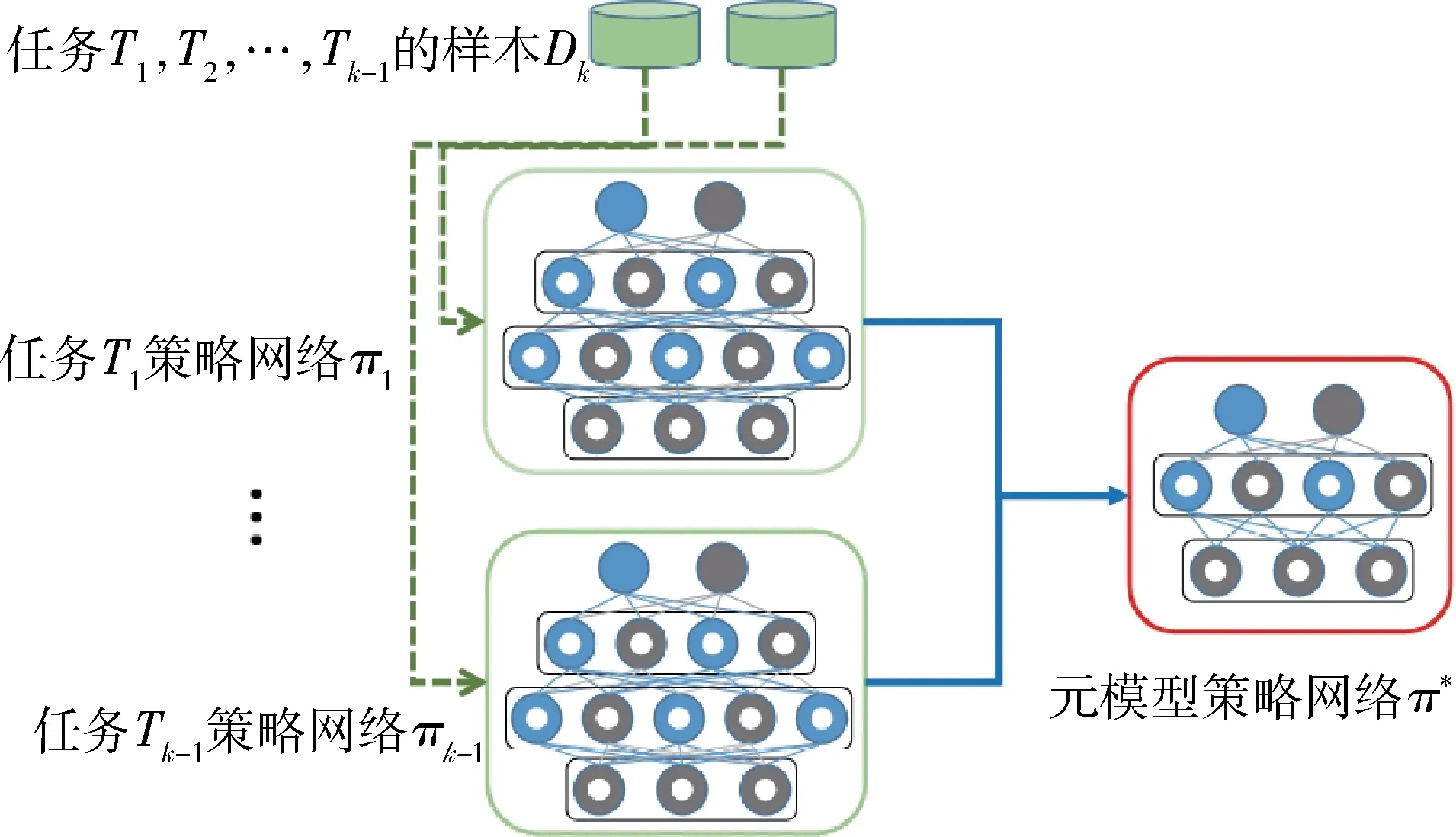
图3 基础课程元模型提取示意图Fig.3 Meta model extraction in basic tasks
2.2 基于课程学习的元模型迁移
在对基础课程元模型π*进行提取后,利用基于课程学习的模型迁移方法来初始化目标课程场景的策略网络。
如图4 所示,针对元模型迁移再训练问题,保留原网络中的历史知识信息,也即基础课程元模型π*,并且引入新的扩展网络权重再训练新网络,提升模型在新课程下的泛化能力及准确性,主要用于保留公共部分权重,完成迁移训练,加快收敛速度。由于智能体数量不同,策略网络的动作空间也会有所不同,同样会将维度较小的网络进行补零处理。

图4 基于课程学习的元模型迁移Fig.4 Meta model transfer based on curriculum learning
3 基于《星际争霸Ⅱ》的仿真与实验
在众多实时策略游戏人工智能研究环境中,星际争霸相比之前大多数平台更具规范性和挑战性。DeepMind 和暴雪联合开发了基于《星际争霸Ⅱ》的深度学习研究环境SC2LE,如图5 所示。该环境可在指定地图上提供AI 接口,利用基于规则或者基于学习的方法控制相应智能体。因此,选择了在《星际争霸II》指定地图上进行仿真与实验。
图5 《星际争霸II》地图Fig.5 "Star Craft II" map
在《星际争霸Ⅱ》3m_vs_3m 以及5m_vs_5m 2 个地图上进行基础课程元模型提取,将得到的元模型策略网络迁移至8m_vs_8m 目标地图上进行再训练,得到仿真结果如图6、7 所示。
从图6 中可以看出基于元课程强化学习的训练方法可以有效地提升训练速度,在训练的初始阶段便可以获得较高的胜率,而传统训练方法的胜率则上升较为缓慢,体现出了元课程强化学习的优势。
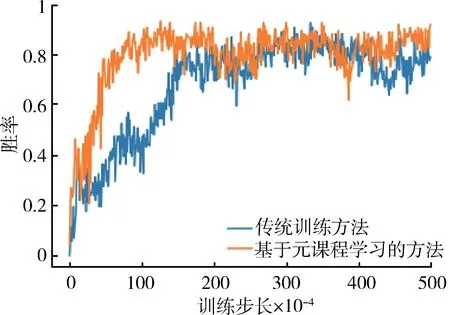
图6 基于元课程强化学习的训练过程对比图Fig.6 Training process based on the meta curriculum reinforcement learning
图7 展现了训练过程中的奖励回馈情况,可以看到在训练初始阶段,由元模型策略网络初始化的训练网络可以获得较高的奖励,而传统训练方法则需要进行探索以提升获得的奖励。奖励机制的增加过程展现了元课程强化学习,可以有效地支撑多智能体协同博弈策略的高效生成。

图7 不同训练步长下的平均奖励对比图Fig.7 Training process based on the meta curriculum reinforcement learning
进一步对2 种方法分别进行了20 次独立的仿真实验,绘制了不同训练步长下元课程学习训练方法与传统直接训练方法的胜率箱线图,如图8 所示。可以看出,在不同训练步长下,元课程强化学习的胜率分布均大幅高于直接训练方法,而且提升幅度在初始训练步长中体现尤为明显,证明了基于元课程强化学习的多智能体协同博弈技术的有效性。
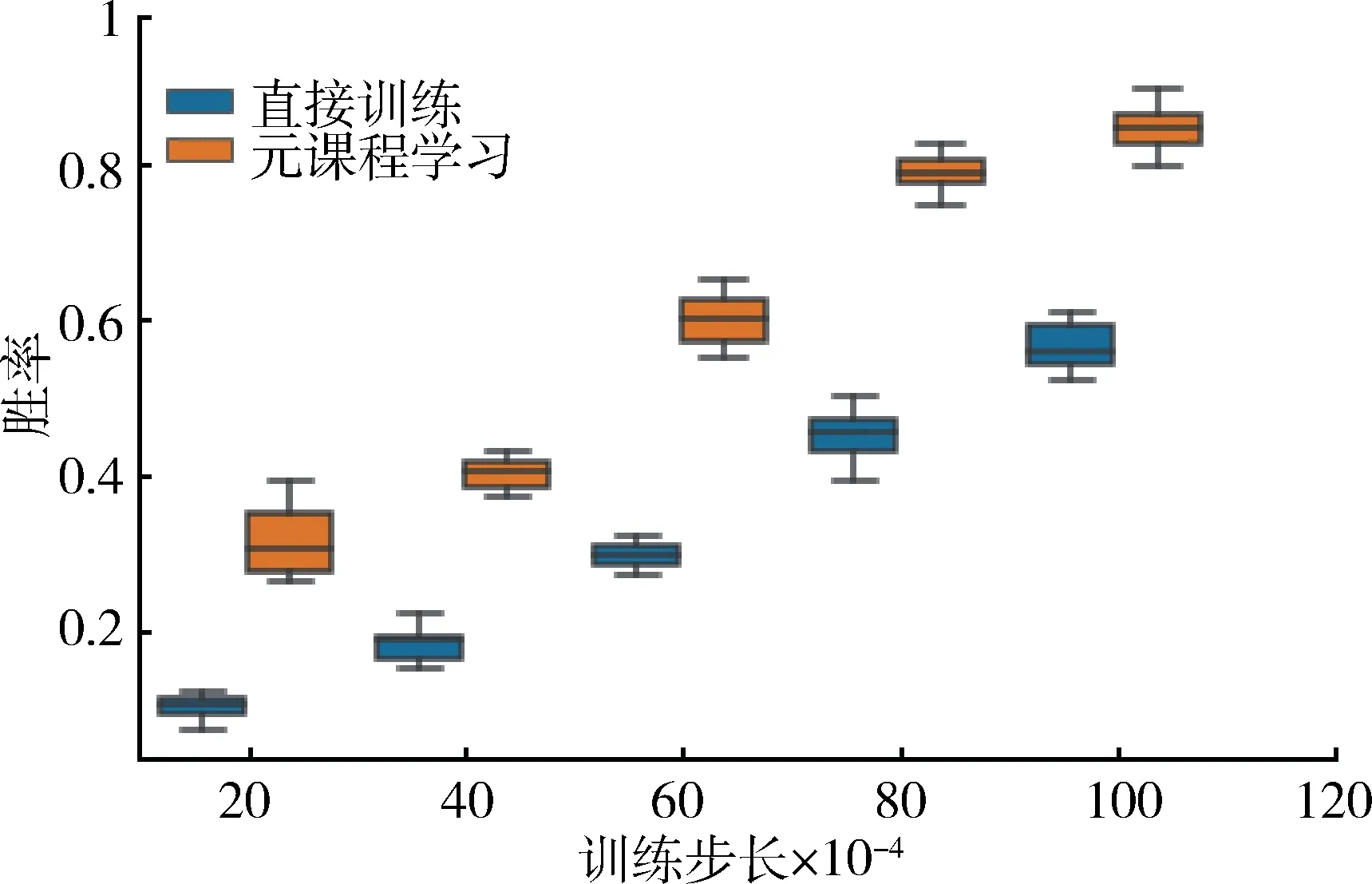
图8 不同训练步长下的胜率对比图Fig.8 Win rate under different training steps
4 结束语
针对大规模多智能体协同博弈训练时间长的问题,本文提出了一种基于Actor-Critic 的多智能体强化学习协同博弈框架,利用元课程强化学习方法对小规模场景进行元课程模型提取,并且基于课程学习向大规模场景进行模型迁移训练,最终得到较优协同策略。仿真实验结果表明基于元课程强化学习的多智能体协同博弈技术可有效地加速其训练过程,相对于传统训练方法在较短时间内可以达到较高的胜率,训练速度提升约40%,该方法可有效支撑多智能体协同博弈策略的高效生成,为低资源下的强化学习高效训练提供可靠支撑。
非完全信息下的多智能体博弈研究是当前众多人工智能研究团队努力攻克的难题,虽然有新的成果不断产生,但至目前为止,完整游戏情况下,人工智能游戏程序仍无法达到人类高水平玩家的水平。为了达成这一目标,除了文章前述的研究方法之外,一些研究者将注意力放在多智能体分布式决策上。分层和分任务决策对星际争霸来说可能是一种发展方向,通过将对抗任务分为不同的层次和拆分成不同的任务模块,在小的任务范围内进行学习,最终将这些模块整合成一个完整的人工智能游戏程序。另外,将博弈论作为对抗分析的指导方法,会给该领域带来新的解决思路。除此之外,模仿学习、迁移学习以及增量式学习也可能在该领域具有良好的表现。
