聚丙烯复合材料老化数据集成学习
2022-11-12武星高进丁鹏
武星高进丁鹏
(1.上海大学计算机工程与科学学院,上海200444;2.之江实验室,浙江杭州311100;3.上海大学理学院,上海200444;4.上海大学材料基因组工程研究院材料信息与数据科学中心,上海200444)
聚丙烯因其低成本和优异的加工特性在日常生活和工业中得到广泛使用,例如纺织、家电、塑料以及汽车等领域.但是,聚丙烯材料的力学性能较差,为了改善其力学性能,通常加入稳定剂、抗氧化剂以及硬脂酸锌等材料形成聚丙烯复合材料[1],以弥补原始材料的性能缺陷,提升其力学性能.
材料在使用过程中不可避免地会受到光照、高温和湿气等环境因素的影响,导致材料外观及力学性能的恶化,这种现象称为材料老化[2].正确预测聚丙烯复合材料的老化能够得出其使用寿命,传统的预测主要采用经验试错法和基于密度泛函理论(density functional theory,DFT)[3]的方法,测试效率低并且成本高.随着人工智能的发展,许多研究者提出将集成学习的方法应用到材料科学中,通过集成学习算法解决聚丙烯复合材料小样本数据集以及材料老化性能的预测.
本工作根据现有的聚丙烯复合材料老化的力学性能指标数据集,采用集成学习算法,使用基于数据分布的虚拟样本生成(virtual sample generation,VSG)[4]算法对原始数据集使用期望最大化(expectation-maximization,EM)算法[5]优化的高斯混合模型(Gaussian mixed model,GMM)[6]生成虚拟样本,将生成的数据集划分为训练集与测试集,使用多种集成学习算法模型通过训练集训练模型,再利用训练得到的算法模型对测试集进行预测,得到回归拟合的结果.本工作分别采用随机森林(random forest,RF)[7-9]、极端梯度提升(extreme gradient boosting,XGBoost)[10]、轻量级梯度提升机(light gradient boosting machine,LightGBM)[11]以及分类梯度提升(categorical boosting,CatBoost)[12]4种集成学习算法,采用交叉验证[13]的方式建立聚丙烯复合材料老化的算法预测模型,同时对机器学习的预测结果进行比较与评估(见图1).实验结果表明,集成学习对聚丙烯复合材料老化的力学性能预测具有重要的参考意义和实用价值.

图1 基于虚拟样本生成的集成学习预测方法工作流程图Fig.1 Workflow of the ensemble learning prediction method based on virtual samples generation
1 相关工作
1.1 虚拟样本生成
材料科学领域数据代价昂贵,一般是小样本数据集,难以达到机器学习数据量的要求,而虚拟样本生成可以解决这样的数据难题.
主流的虚拟样本生成大致分为基于深度学习和基于数据分布2种,但是基于深度学习的虚拟样本生成需要高维度的表征支撑,并且不能直接用于回归任务,因此,本工作采用基于数据分布的虚拟样本生成.从深度学习的角度出发,Cai等[14]提出基于生成对抗网络来生成织物材料的摩擦的纹理信号,从而在电振动触觉显示器上进行触觉渲染.Ali等[15]提出基于深度卷积神经网络创建数字材料2D玻璃和3D碳的µCT图像方法,并在预测上具有更高的精度.从数据分布的角度出发,Lei等[4]提出一种新型的基于多元高斯概率分布的虚拟样本生成方法,并通过实验提出参数指标证明虚拟样本生成方法的有效性.但这种方法只能在指定数据分布的数据集上有效,为了提升虚拟样本生成方法的健壮性以及泛化能力提出基于高斯混合模型的虚拟样本生成方法,高斯混合模型的虚拟样本生成按照样本分布扩充数据集.Li等[16]提出基于高斯混合模型的虚拟样本生成方法,并在工业加氢裂化中建模与预测获得较高的准确性.
1.2 集成学习
集成学习[17]是有监督学习算法,通过组合多个弱学习模型形成一个强学习模型进行预测.集成学习通过结合多个弱学习器解决了单学习器由于数据量少与计算偏差导致的模型预测效果差的问题,通过使用多个学习器扩大搜索空间,并通过加权多个学习器避免陷入局部最优,以此获得较优的性能.集成学习分为Bagging集成学习与Boosting集成学习,主要区别就是Boosting集成学习模型基学习器不存在强依赖关系并加入残差,提升算法模型的预测性能.
RF算法[18]是Bagging集成学习典型算法,被广泛应用解决材料科学领域的材料预测、材料发现与材料分析等问题.Liu[19]在预测锂离子电池活性材料质量负载和孔隙率影响时提出基于RF方法,通过高效灵敏度分析获得电池制造的有前景的制造方法.Gao等[20]在解决碳纤维增强陶瓷复合材料的孔隙率预测问题上根据材料的组成和制备工艺的特点提出建立RF模型,准确地预测了材料的性能,提升了碳纤维增强陶瓷复合材料的应用前景.Khan等[21]根据RF算法建立模型预测生成粉煤灰基地址聚合物混凝土的抗压强度指标,并且根据基因表达编程得到一个经验方程用来估计抗压强度.
Boosting集成学习算法是基于CART树[22]的回归算法,采用加权的方式融合基学习器,不断拟合残差提升模型性能,提高材料性能预测的精度.Song等[23]在探索钢的特性以及成本与制造参数之间的关系时,引入XGBoost算法来解决多变量优化问题,准确地预测了钢的抗拉强度与塑性,从而提升钢的力学性能.Zhao等[24]在水泥熟料中的游离氧化钙含量预测问题上提出使用基于时间序列输入窗口的贝叶斯优化的LightGBM算法,解决了传统方法无法直接进行测量游离氧化钙含量的问题.Bhamare等[25]在研究相变材料集屋顶建筑的热性能预测问题上提出使用CatBoost算法来解决材料性能预测问题,并获得较高的预测效果.
目前,集成学习被大量使用解决材料领域难题,在材料预测的准确性上远远高于传统材料科学方法,该方法能够发现材料数据中属性之间的潜在知识,甚至被应用在新材料发现场景.
2 集成学习预测聚丙烯复合材料老化
传统的材料老化预测主要采用经验试错法和基于密度泛函理论的方法,测试效率低并且成本高.但是,集成学习计算成本低、开发周期短以及具有强大的数据处理能力和高预测性能,被广泛应用到材料老化性能预测工作中.
本工作在解决聚丙烯复合材料老化预测工作上,首先采用高斯混合模型虚拟样本生成算法扩充小样本数据集,然后将扩充后的数据样本分为训练集与测试集,并根据集成学习思想从训练集中集成多个弱学习器成最优的强学习器模型,最后通过最优模型预测测试集效果.
2.1 高斯混合模型
高斯混合模型生成虚拟样本是基于数据分布进行虚拟样本生成技术,能够按照原始聚丙烯复合材料老化性能的数据分布特点平滑生成验证有效的虚拟样本,解决聚丙烯复合材料老化性能预测由于样本量难以满足集成学习数据量要求而预测性能差的问题.
高斯混合模型指多个高斯分布函数的线性组合,用于描述不同数据密度组合的数据分布.设有原始聚丙烯复合材料老化样本集自变量为X,则高斯混合模型表示为

式中:N(x|µk,Σk)表示高斯混合模型的第k个高斯分布;πk是混合系数,表示每个高斯分布的权重,并且满足

对于聚丙烯复合材料老化性能进行高斯混合模型估计参数,主要采用EM算法.EM算法求解后验参数主要使用E步以及M步解决,E步通过计算每个高斯分布的后验概率参数值,M步优化后验参数值,得到最优的高斯混合模型的参数.
图2表示高斯混合模型生成虚拟样本算法.通过GMM与EM算法得到最优的数据分布,生成的虚拟样本分布往往有偏于真实样本分布.
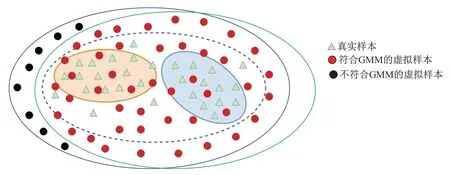
图2 高斯混合模型虚拟样本生成算法Fig.2 Gaussian mixture model virtual samples generation approach
2.2 Bagging集成学习
Bagging集成学习是将不构成强依赖关系的基学习器集成为一个强学习器预测聚丙烯复合材料老化性能指标的算法,Bagging的典型代表是RF算法.
随机森林算法是由BREIMAN于2001年提出的决策树组合算法,通过bagging集成学习的思想将多棵决策树合并到一起的算法.随机森林思想是随机的方式建立一个森林,森林里有许多的决策树组成,每个决策树决定选择样本与样本属性分叉,随机森林中的每一棵决策树之间是没有关联的.决策时通过多个决策树的预测汇总结果作为最终的输出.使用随机森林进行聚丙烯复合材料老化性能预测的构造过程如下:
步骤1聚丙烯复合材料老化性能样本集由N个样本组成,有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择),将选择好的N个数据样本训练一个决策树h(X,θk),决定根节点用选择的N个样本进行分支.
步骤2聚丙烯复合材料老化性能样本的特征为M个属性,在决策树的每个节点需要分裂时,随机从这M个特征中选择m个特征,满足m小于M,然后从这m个特征中采用信息增益来选择一个特征作为该节点的分裂特征.描述每个基决策树选择的聚丙烯复合材料老化性能样本与特征为

步骤3决策树形成过程中所有材料样本都要按照步骤2来分裂,一直到不能够再分裂为止.整个决策树形成过程中不能进行剪枝.
步骤4按照步骤1~步骤3建立K个决策树,构成一个随机森林模型预测聚丙烯复合材料老化性能精度.构建的随机森林模型为

2.3 Boosting集成学习
Boosting集成学习通过改变聚丙烯复合材料老化性能训练样本的权重分布训练基分类器,并通过加权融合基分类器组合成一个强分类器模型,在融合过程中拟合前分类器的残差不断迭代提升模型的精度.本工作使用的Boosting集成学习包含XGBoost算法、LightGBM算法以及CatBoost算法,3种算法都是梯度提升决策树(gradient boosting decision tree,GDBT)的改进算法,其中LightGBM与CatBoost是XGBoost在资源消耗上的优化算法.
Boosting集成学习所用树模型是CART回归树模型.n条老化性能样本、m个维度特征的聚丙烯复合材料老化性能数据集表示为
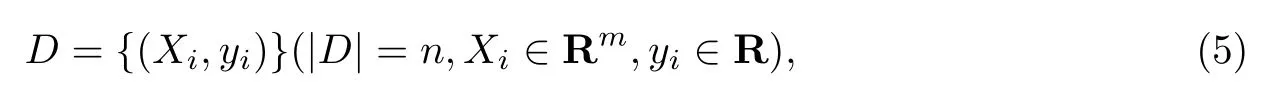
式中:Xi为聚丙烯复合材料老化性能数据集D的自变量;yi表示数据样本预测值.
树集成模型使用K个样本决策树的累加和来预测输出,

式中:K就是决策树数量;Γ表示所有可能的CART树;^yi为样本集的预测值.
Boosting集成学习算法模型第t次优化的目标函数为
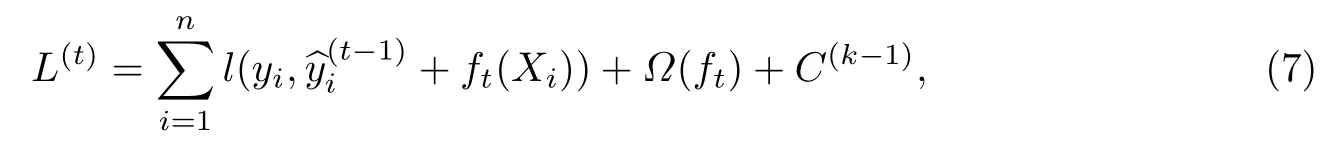
式中:l表示聚丙烯复合材料老化性能预测值与实际值的偏差函数;表示第i个样本在第t-1次迭代的预测值;ft(Xi)表示第t次优化的最小目标函数模型;Ω(ft)表示第t次优化的正则化项,用来控制当前最优决策树超出误差的聚丙烯复合材料老化样本的惩罚程度;C(k-1)表示前K-1棵树的正则化项,来惩罚已经生成的决策树.

式中:γ、λ表示CART树的复杂程度.γ、λ越大,表示越希望获得结构简单的树.
2.4 性能评估
本工作采用平均绝对误差(mean absolute error,MAE)、均方误差(mean squared error,MSE)、平方绝对百分比误差(mean absolute percentage error,MAPE)、拟合系数R2和均方根误差(root mean squared error,RMSE)作为机器学习预测结果的评估标准.
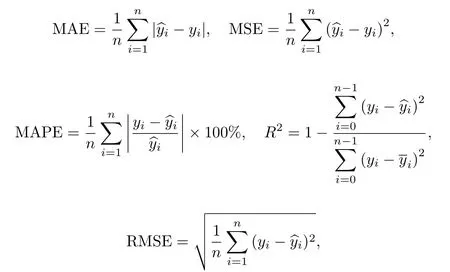
式中:n为样本数量;为真实值;yi为预测值;为平均值.
3 集成学习算法模型
本工作使用高斯混合模型生成虚拟样本并使用集成学习算法对聚丙烯复合材料老化性能进行预测,为了获得比较好的预测效果,原始数据采集工作准确性一定要高.本工作采用的数据集是12条按配方称取对应比例的滑石粉、回收聚丙烯、硬脂酸锌、抗氧剂以及光稳剂并通过挤出机制备得到的聚丙烯复合材料老化样本.为了保证老化测试样本测试的准确性,每次实验测试3次,取平均值得到聚丙烯复合材料的力学性能,形成聚丙烯复合材料初始状态性能指标、50 h性能指标、10 h性能指标、200 h性能指标、400 h性能指标以及500 h性能指标为特征的数据集,其中取500 h性能指标作为预测变量,前面的材料老化性能指标作为自变量构建集成学习算法模型.
根据获得的聚丙烯复合材料老化样本集,基于高斯混合模型虚拟样本生成的聚丙烯复合材料老化集成学习预测模型(见图3)构建如下.
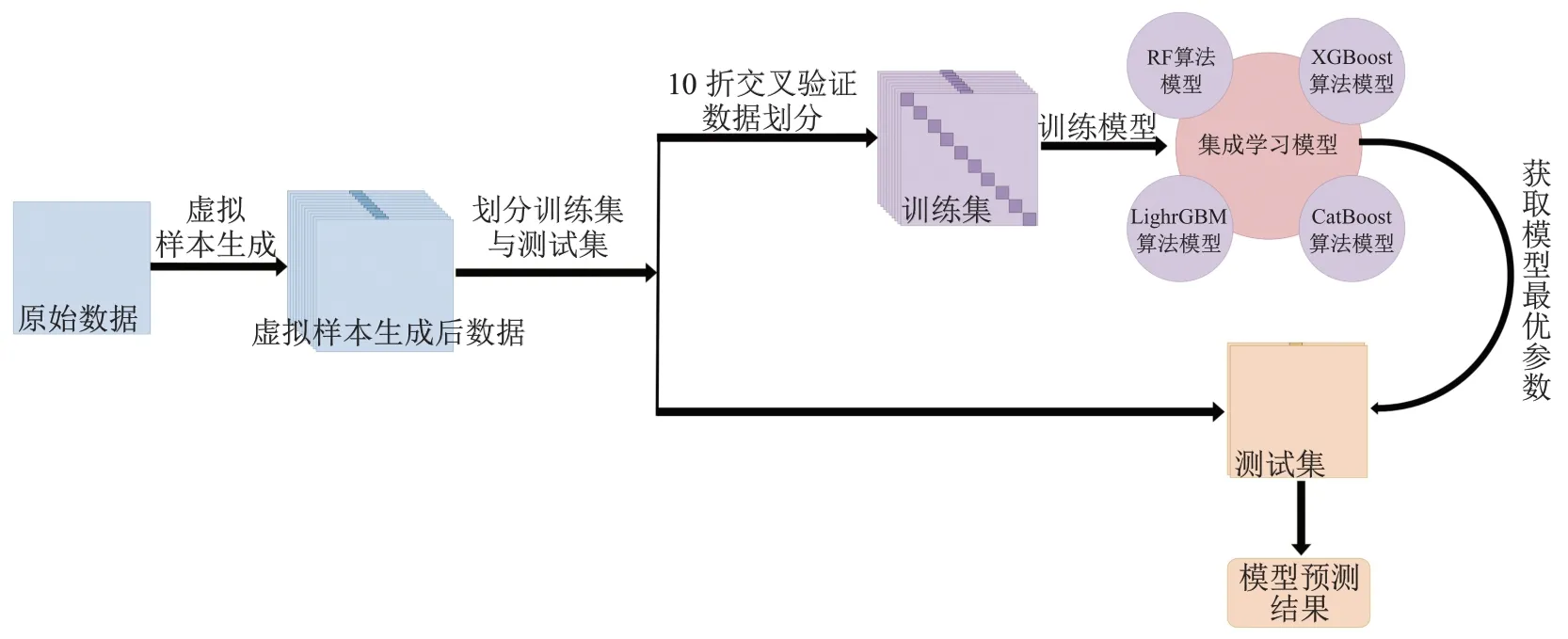
图3 集成学习算法模型流程图Fig.3 Flow chart of ensemble learning algorithm model
(1)数据预处理.将12条数据通过数据预处理得到10条聚丙烯复合材料老化样本集,通过数据的原始分布采用高斯混合模型虚拟样本生成方法平滑生成验证有效的100条数据.
(2)数据准备.将虚拟样本与真实样本混合以8∶2的比例随机划分为训练集与测试集.
(3)模型训练.设置10折交叉验证,分别建立RF算法、XGBoost算法、LightGBM算法、CatBoost算法4种集成学习算法模型,并通过集成算法模型对测试集数据评估效果.
(4)模型效果评估.使用MAE、MSE、MAPE、R2、RMSE等评价指标对模型效果进行评估.
(5)模型应用.利用训练好的集成学习算法模型对测试集的聚丙烯材料老化性能指标进行预测,并对效果评估.
为了提升模型预测精度,采用sklearn库中网格搜索对参数进行寻优.选取不同的参数取值范围得到预测精度最高的模型.
4 实验结果与分析
基于聚丙烯复合材料老化的10条数据,使用高斯混合模型虚拟样本生成方法基于原始数据分布生成100条虚拟样本,再基于这100条数据以8∶2划分训练集与测试集,使用RF算法、XGBoost算法、LightGBM算法以及CatBoost算法4种集成学习算法采用10折交叉验证对训练集数据进行训练,得到准确度(见表1).
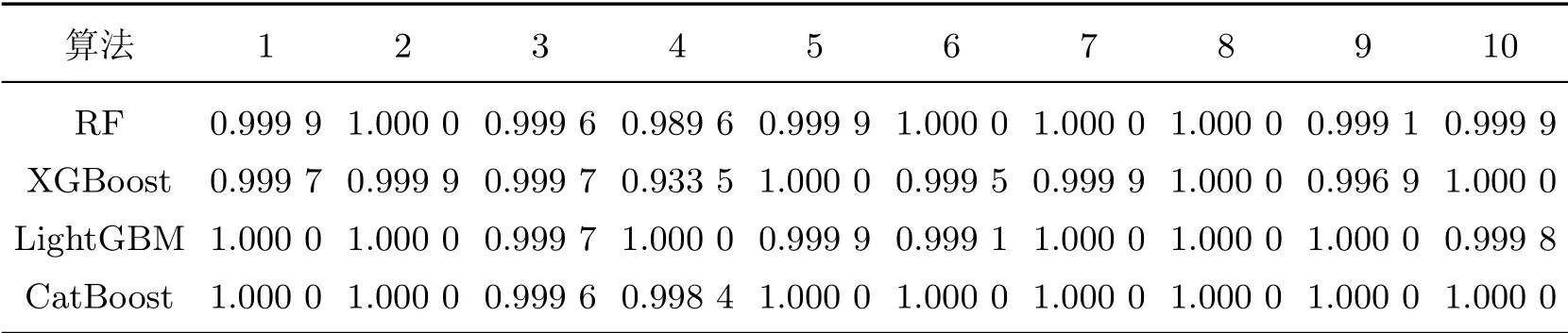
表1 集成学习模型的10折交叉验证准确度Table 1 10-fold cross-validation results for ensemble learning models
从表1中可知,4种集成学习算法训练出的模型效果比较准确,大部分准确性都达到99%.这也可以说明集成学习算法在预测聚丙烯复合材料老化性能上比较精确,这得益于基于高斯混合模型虚拟样本生成算法生成的平滑的样本集,另外,集成学习算法根据组合策略结合多个基学习器降低搜索空间中与真实值的误差,同时通过多个基学习器扩大聚丙烯复合材料老化性能预测的搜索空间,也避免了最终模型陷入局部最优的状态,这也是集成学习性能好于传统机器学习的根本原因.聚丙烯复合材料老化数据在使用高斯混合模型虚拟样本生成算法后进行集成学习模型预测的结果较优,表明集成学习在解决聚丙烯复合材料老化性能预测问题上具有较大的潜力.
表2描述了4种集成学习算法在虚拟样本生成前使用网格搜索寻优并在测试数据上求MAE、MSE、MAPE、R2以及RMSE性能指标参数值.在生成虚拟样本之前,由R2决定系数可知,预测值可以基本解释样本自变量的方差变动,表明集成学习算法可以处理聚丙烯复合材料老化性能预测,但由于集成学习算法需要数据的支撑,小样本难以获得较优的性能效果,这也是在虚拟样本生成之前误差较高的根本原因.
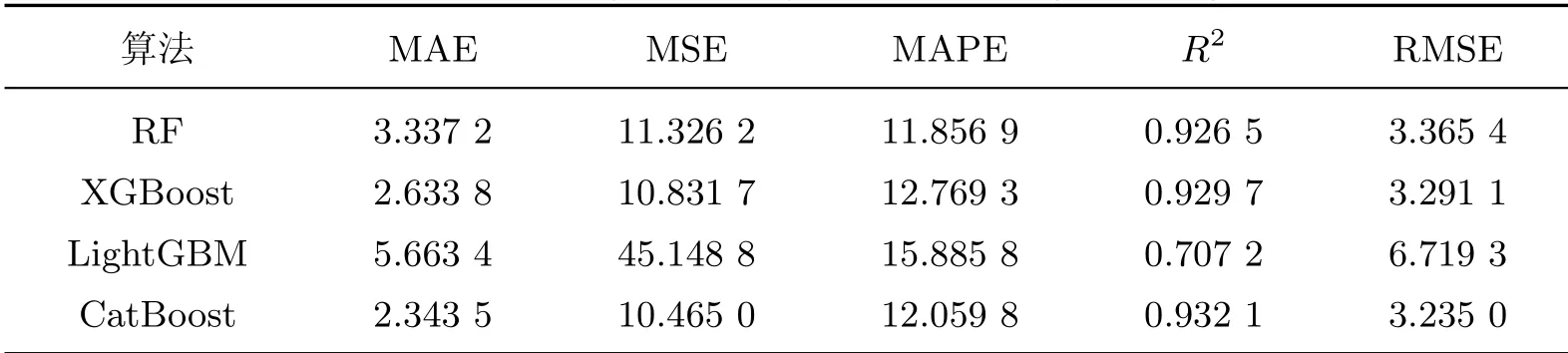
表2 虚拟样本生成前测试集拟合结果比较Table 2 Comparison of testing set fitting results before generating virtual samples
表3描述了4种集成学习算法在虚拟样本生成后使用网格搜索寻优并对测试集数据求MAE、MSE、MAPE、R2以及RMSE性能指标参数值.由表3可知,集成学习方法在处理聚丙烯复合材料老化预测问题上具有比较好的性能,一方面得益于集成学习方法在聚丙烯复合材料老化性能预测问题上需要一定的数据支撑,而高斯混合模型虚拟样本生成算法解决了小样本数据集的难题;另一方面,机器学习使用单个基学习器模型预测效果,而集成学习通过多个基学习器降低预测值偏离真实值的概率,并通过多个基学习器扩大聚丙烯复合材料老化性能预测的搜索空间,避免出现单学习器预测性能时陷入局部最优的情况,同时,集成学习通过多个基学习器的组合挖掘了数据的潜在知识以及高维知识.

表3 虚拟样本生成后测试集拟合结果比较Table 3 Comparison of testing set fitting results after generating virtual samples
图4为4种集成学习算法在训练集与测试集下真实值与预测值的误差.由图4可以看出:集成学习算法预测聚丙烯复合材料老化性能准确性较高,LightGBM算法与CatBoost算法预测误差小于RF算法.一方面,Boosting集成学习算法的基学习器之间不存强依赖关系,算法模型为每个基学习器学习到不同的权重来进行预测,通过学习不同的权重不断拟合最优模型的参数,而不是RF算法赋予每个基学习器相同的权重集成各个基学习器成一个强学习器预测结果.另一方面,Boosting集成学习在Bagging集成学习基础上加入残差,通过不断迭代前学习器的拟合结果,使得在处理聚丙烯复合材料老化性能回归预测具有更高的准确性;同时LightGBM与CatBoost在代价函数上加入了正则项,用于控制模型的复杂度,降低了模型的方差,从而提升了预测的准确性.
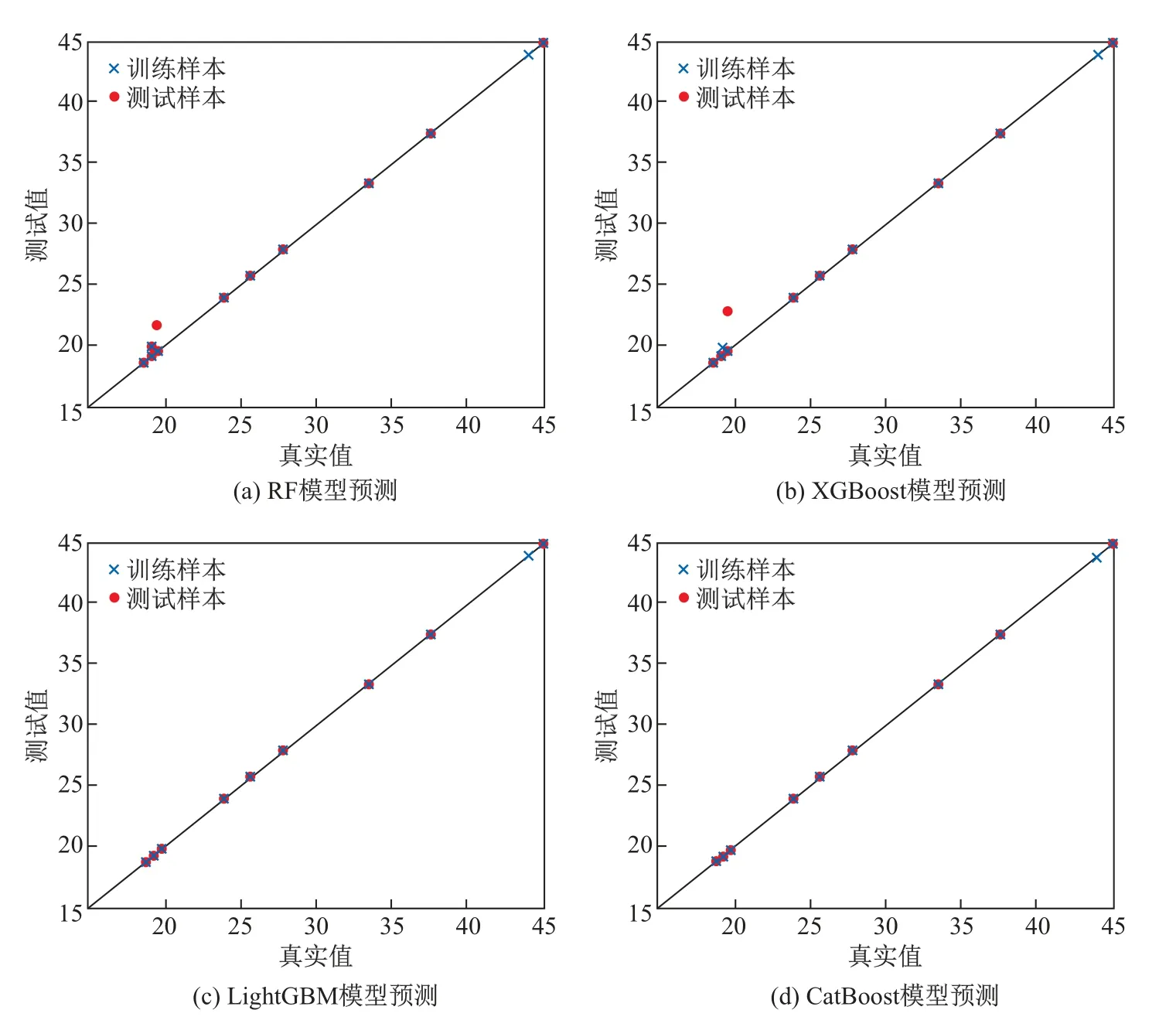
图4 集成学习预测模型预测精度Fig.4 Ensemble learning prediction models prediction accuracy
表4为使用高斯混合模型生成虚拟样本下非集成学习算法的拟合结果.由表4可知,非集成学习算法预测聚丙烯复合材料老化性能指标拟合误差远远大于集成学习算法的拟合误差,主要原因是非集成学习算法是通过单一的学习器来预测回归问题,在聚丙烯复合材料老化回归问题上执行局部搜索时容易陷入局部最优状态,同时单一学习器的搜索问题的有效空间比较狭隘,难以取得较优的结果,而集成学习通过多个学习器的集成解决了单一学习器存在的问题.比较显眼的是KNN的结果,与集成学习算法的预测结果相似,根据最优的KNN模型的分类结果显示,模型最优参数n_neighbors为4,这表明将5个样本分为一个类别来预测结果,而KNN算法结果较优的原因是虚拟样本生成算法按照样本原始的数据分布扩充样本,使得样本近邻附近生成了大量的虚拟样本,用分类算法能有效地划分大量聚集的数据,所以KNN的效果较优.但是KNN算法是一种使用聚类的思想进行回归的算法,从算法角度来看,不适合处理聚丙烯复合材料老化性能回归预测问题.从总体数据来看,非集成学习算法在预测聚丙烯复合材料老化性能问题上的准确性明显低于集成学习算法,集成学习在聚丙烯复合材料老化性能预测上更有优势.
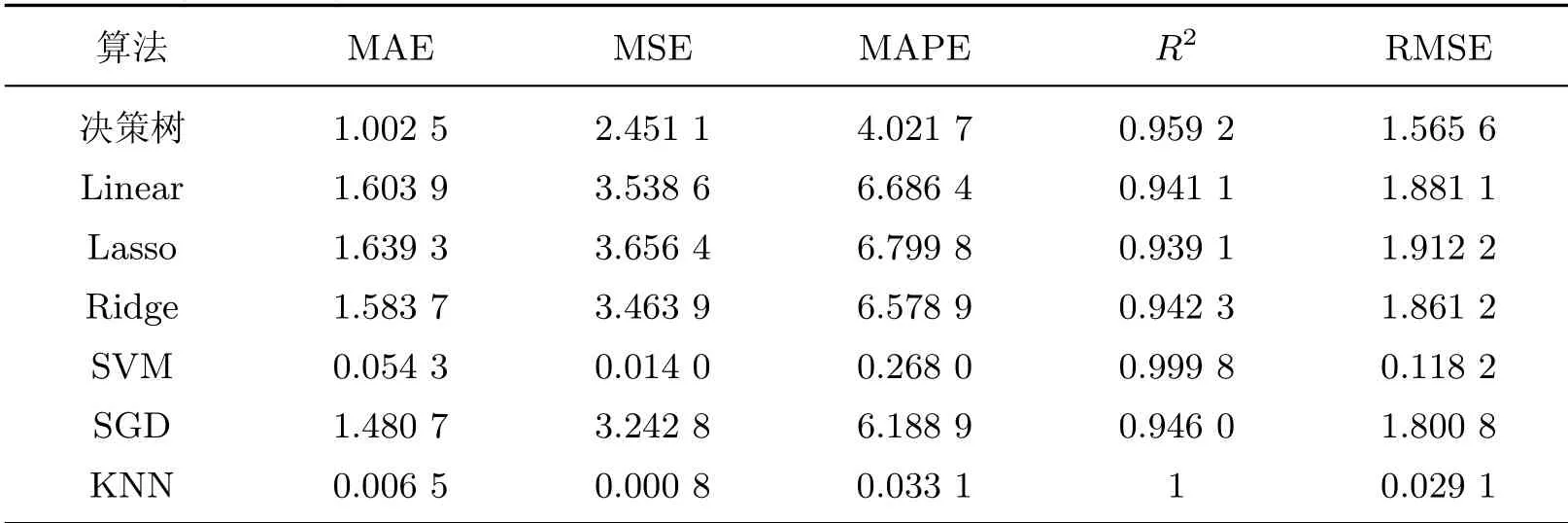
表4 生成虚拟样本后非集成学习测试集拟合结果比较Table 4 Comparison of testing set fitting results of non-ensemble learning algorithms after generating virtual samples
5 结束语
本工作主要包括高斯混合模型虚拟样本生成与集成学习算法预测聚丙烯复合材料老化性能.在对原始聚丙烯复合材料老化数据集样本进行扩充时,选择高斯混合模型基于数据分布特点平滑地对数据集进行虚拟样本生成,再使用集成学习算法对聚丙烯复合材料老化性能进行预测.本工作讨论的模型中,使用LightGBM算法与CatBoost算法得到的模型的性能最优,训练集与测试集的预测值的R2指标表明预测值能解释自变量的方差变动,模型精度比较高,并由对比实验可知,高斯混合模型虚拟样本生成算法与集成学习算法都为提升聚丙烯复合材料老化性能预测精度做出了贡献.
