混流装配线平衡问题的多目标优化方法研究
2022-11-10原丕业刘佳楠
原丕业, 刘佳楠, 刘 畅, 张 萌
(青岛理工大学 管理工程学院,山东 青岛 266520)
0 引言
随着市场对产品准时化、多样化需求的增加,JIT制造逐渐受到企业的重视。混流装配线可混合、连续装配结构、工艺相似的不同产品,是一种柔性生产系统,能够帮助企业有效应对市场环境的快速变化,但是在实际应用中往往因工序分配不合理,使得工作站闲置和超载时间较多,降低了装配线整体效率。因此,必须对混流装配线进行平衡,消除等待和浪费。
目前,关于该问题的研究主要集中于算法的设计和模型的改进。查靓等[1]构建了直线型和U型装配线第一类平衡问题的整数规划模型;徐发平等[2]运用改进分支定界法求解了生产节拍固定,最小化工位数的装配线平衡问题;唐秋华等[3]以工作站数最小为目标,考虑生产中的学习效应和加强约束,建立非线性平衡模型;张则强等[4]通过研究产品作业时间的随机性,优化了混装线的工作站数;焦玉玲等[5]综合考虑作业元素的时间和位置阶位值,将平衡率最大作为目标建立不同布置下的优化模型。
以工作站数最小或装配线平衡率最高为主的单目标模型可以较快求解平衡问题,但对实际生产中的制约因素考虑较少。为了满足复杂多变的市场需求,企业在对装配线布局时,常进行多目标决策。Betul等[6]研究了平衡对生产效率、工作站间负荷均衡以及线平滑率的影响;Masoud等[7]将工位负载和装配线效率作为混合U型装配线平衡效果的评判指标;扈静等[8]引入平衡损耗系数和平滑指数研究混流装配线平衡问题;韩煜东等[9]以混装线实际节拍最小化和合理确定作业人数为目标来降低加工成本;李爱平等[10]通过测度作业元素的装配关系复杂性,优化了装配线节拍和平滑系数。综上,混装线多目标平衡问题的目标设定大多以平衡结果为依据,对因混合产品工序时间差异所导致的工作站负荷均衡性考虑较少,同时忽略了目标间数量级差异对联合目标最优性的影响。
基于上述分析,尽管关于混流装配线平衡问题的研究较丰富,但平衡过程中依然有很多问题还没有解决,理论与实践存在差距。本文将以目前应用更为广泛的U型混流装配线为研究对象,在最小化工作站数的基础上均衡工作站间负荷和工作站内不同产品的作业负荷,并将不同产品工序操作时间的加权和作为该工序实际作业时间,建立多目标优化模型,来减少装配生产中的浪费。
1 U型混流装配线平衡问题描述
混流装配线平衡问题就是研究在装配作业顺序、市场需求量、混合产品装配比等既定条件下,将一系列工序分配到一定数量的工作站中,同时确保各工作站实际作业时间不超过给定节拍且工作站闲置时间最小,以消除瓶颈,提高生产效率。与传统直线布置不同,U型装配线上工作站间距离较近,可按照前后两个方向同时进行工序分配,工序交叉、组合的空间更大,有效减少了工作站闲置时间。因此当需求发生变化时,能够迅速调整以适应生产,如图1显示了一种U型装配线的工序分配方案。
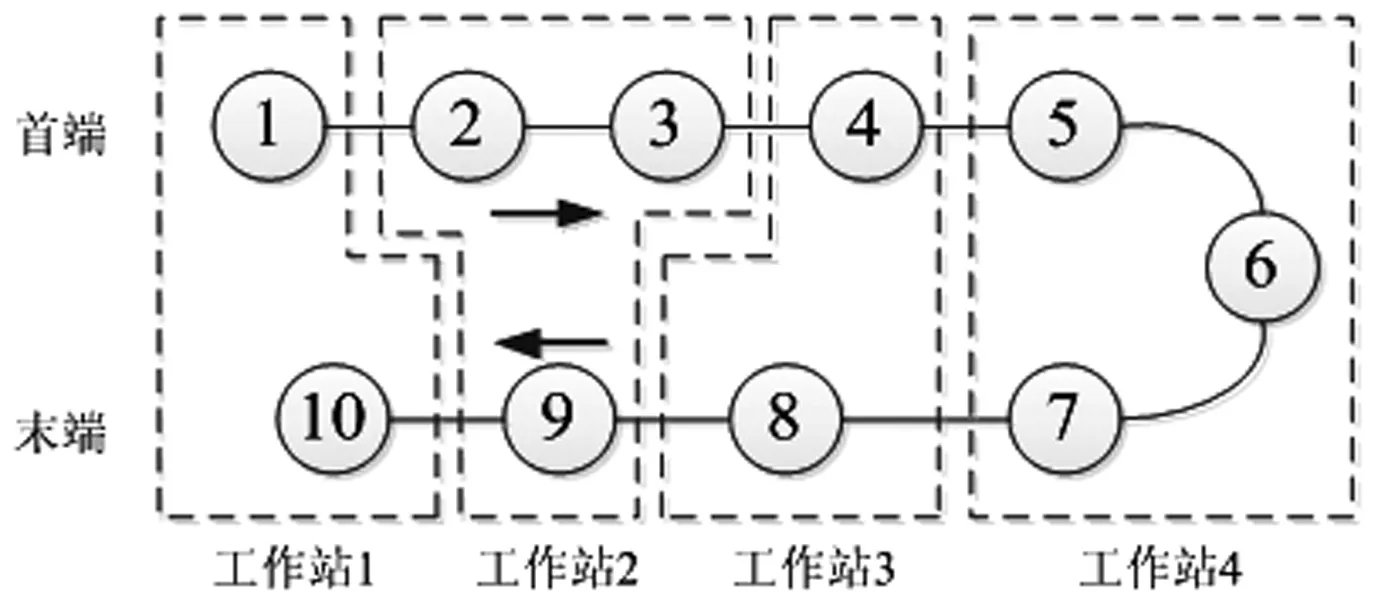
图1 U型装配线工序分配示意图
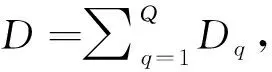
建模过程涉及到的符号和变量解释如下:
i:工序序号,i=1,2,3,…,n,n为工序总数;
j、k:工作站序号,j、k=1,2,3,…,m,m为所需工作站数;
αq:品种q的装配比例,且αq=dq/d;
tiq:品种q在工序i的装配时间;
xij:0-1变量,xij=1表示按照作业序列从前往后将工序i分配到工作站j;
yij:0-1变量,yij=1表示按照作业序列从后往前将工序i分配到工作站j;

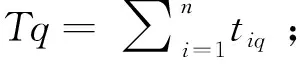
I(k):分配到工作站k上的工序集合;
E:工序全集,E={1,2,3,…,n};
P:n阶矩阵,表示工序间的综合作业优先关系,满足pst=P(s,t)∈(0,1)。当pst=1时,说明工序s是t的紧前工序;
aj:工作站j的状态变量,aj∈(0,1),当aj=1时,说明工作站j分配了工序。
为了使研究的问题更加明晰,进行如下假设:(1)作业优先关系约束对所有产品一致;(2)不同产品的同一工序应分配到相同工作站;(3)工序是不可再细分的最小作业单元。
2 多目标优化模型建立
2.1 目标识别
混流装配线平衡的最终目标是使生产保持一种均衡、连续的流动状态,各工作站作业同步进行,减少工作站的闲置和超载时间,提高资源利用率。因此,保证各工作站间平均负荷的均衡性十分重要,以最小化工作站间平均单件产品作业时间值的均方差来衡量该目标,如公式(1)所示。
(1)
此外,在装配线平均负荷均衡的前提下,由于不同产品作业时间的差异,工作站的瞬时负荷也可能会超过设计节拍,造成生产不稳定,因此对装配线进行平衡时还应保证工作站内不同产品的作业负荷差异最小,对该目标定量化表示如下:
(2)
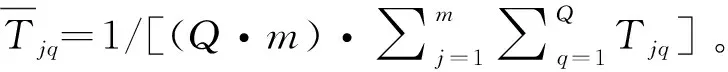
最后,工作站的数量影响着系统初期的建造成本,所以必须将工作站数维持在合理水平。
(3)
2.2 联合目标函数的建立
由于各目标函数分别代表着问题在不同维度的最优化,目标之间存在量纲差异,因此,本文提出了一种目标函数标准化方式——目标法,用来解决联合目标中的多目标兼容性问题。目标法的中心思想是以各单目标最优值的倒数作为标准化系数,将不同维度的目标函数值转换为相同维度的百分比误差值,实现多目标联立。
另外,不同目标对平衡总目标的贡献度不同,可以通过目标权重的大小来反映,采用层次分析法得到f1、f2、f3的权重系数分别为0.45、0.23、0.32。
综上,定义联合目标函数为:
J=min(0.45×v1f1+0.23×v2f2+0.32×v3f3)
(4)
其中,v1、v2、v3分别为目标f1,f2,f3的标准化系数。
2.3 模型的约束条件
U型混装线平衡模型的约束条件主要有:
(1)工序分配约束。即所有工序均被分配,且每个工序只能分配给一个工作站;
(5)
(2)工作站分配约束。即每个工作站至少分配一项工序任务;
(6)
(3)优先关系约束。对于任意工序来说,只有它的所有直接紧前工序或所有直接紧后工序都已经分配完毕,该工序才能进行分配;
(7)
(4)节拍约束。各工作站实际作业时间不超过给定节拍;
(8)
(5)最大分配原则约束。在保证节拍约束的前提下,将尽可能多的工序分配到该工作站内;
(9)
(6)保证相邻工作站的任务集没有交叉,且所有工作站任务集的并集等于工序全集E。
I(j)={xij+yij=1|i,j=1,2,…,n|},

(10)
3 自适应遗传算法设计
为了使自适应遗传算法(AGA)能更好地求解混流装配线平衡问题,对其编码和运算迭代机制做如下改进。
3.1 染色体的编码与解码
本文采用作业序号编码的方式。按照各工序分配至工作站的先后顺序,将作业序号排成一列,分别对应染色体的各个基因位,得到的基因序列就是一条编码后的染色体。解码就是将染色体各基因位对应的工序按照约束条件依次分配到相应工作站中。图2为一条染色体基因编码与解码的示例。
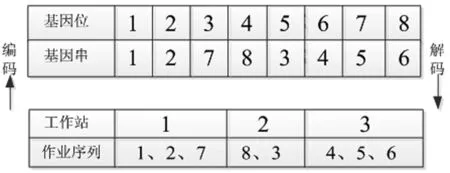
图2 染色体编码与解码
3.2 初始种群的产生
为保证解的质量和多样性,加快算法收敛速度,在生成初始种群时借鉴小生境思想。首先按照规则生成十个指定规模的原始种群,然后对每个原始种群中的个体按照适应度值大小进行排序,最后分别选择各种群适应度值排在前10%的个体,组成一个新的种群,实现种群初始化。
原始种群可通过如下步骤产生:
步骤1输入综合作业关系矩阵P、节拍C、工序总数n、种群容量popsize。初始化个体计数器size=1、基因计数器l=1、工作站计数器m=1,工作站空闲时间idle_time=C。
步骤2生成一条可行的染色体:
(1)对矩阵P同时按照行列进行搜索,将没有紧前作业和没有紧后作业的工序放入待分配工序集合N中;
(2)随机选择N中的工序i,若i的作业时间≤idle_time,则将i放入工作站m,并计算当前工作站m的空闲时间idle_time=idle_time-工序i的作业时间,转到(3);否则,增加新工作站,令m=m+1,并重置工作站空闲时间idle_time=C,返回(2);
(3)更新关系矩阵P。当工序i没有紧前作业时,令P中第i行所有非0元素等于0,P(i,i)=1;当工序i没有紧后作业时,令P中第i列所有非0元素等于0,P(i,i)=1;
(4)令l=l+1,判断l≥n是否成立。若满足条件,则表示所有工序均已分配到相应工作站,得到一条可行的染色体,执行步骤3;否则,返回步骤2。
步骤3对生成的染色体进行编码。
步骤4更新个体计数器size=size+1,判断size≥popsize是否成立,若是,则退出程序,输出所有个体即为原始种群;否则,返回步骤1,继续生成新的染色体。
3.3 适应度函数
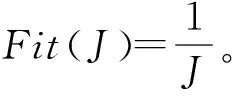
3.4 自适应交叉和变异概率设计
在遗传算法运行初期,种群个体的适应度差异较大,算法易陷入早熟,此时交叉和变异概率应该取较大值,以扩大搜索空间,产生更多新个体;在迭代后期,算法逐渐收敛,种群个体的适应度普遍较高,这时应该减小交叉、变异概率,防止破坏优良基因,加快算法收敛到最优解。综上,给出本文自适应交叉概率pc和变异概率pm的调整公式:
式中,pcl表示种群进化到第l代时,染色体的交叉概率;pml表示第l代个体的变异概率。mpcl与mpml为中间变量,pcmax为交叉概率的上限值,pmmax为变异概率的上限值,mpcl=pcmax×2-ΔZ/Zmax,mpml=pmmax×e-ΔZ/Zmax。Zmax表示当前种群个体的最大适应度值,Zavg表示当前种群个体的平均适应度值,ΔZ=Zmax-Zavg。
3.5 遗传算子
3.5.1 选择
为了防止遗传退化,保留优秀基因,选择操作采用轮盘赌与精英保留策略相结合的方法,具体操作过程为:
(1)保留父代种群中适应度值较大的前20%精英个体;(2)利用轮盘赌方法从父代种群中选择个体组成子代新种群;(3)将子代种群中适应度较小的20%个体用保留的父代精英个体替换。
3.5.2 交叉
优良基因的交叉组合在一定程度上更容易产生优秀个体,按照交叉概率随机确定待交叉个体,两两配对,交换部分基因。以两条各包含7个基因的染色体为例,说明交叉操作过程。
假设待交叉的两个父代个体为R1、R2,交叉后产生的子代个体为S1、S2。对于R1来说,随机产生两个交叉点c1和c2,只保留区间[c1,c2]的基因完整遗传给子代S1。然后删除R2中含有的与片段[c1,c2]相同的基因,将剩余基因顺序不变的补充到S1缺失的基因位上,得到新个体S1,上述过程如图3所示,S2的生成过程同S1。

图3 交叉操作过程示意图
由于交叉操作具有随机性,交叉后子代个体的某些基因可能会违反综合作业优先关系,因此还需要对新生成的染色体进行基因冲突检测,调整违反优先关系的基因位置,保证染色体的可行性。
3.5.3 变异
变异操作可以使遗传过程迅速跳出局部最优,防止算法陷入早熟。
(1)随机确定变异个体的变异点a1,在矩阵P中遍历a1位置上工序i的所有直接前序和后序作业,并确定它们在该变异染色体中的位置;
(2)令i的所有紧前工序中排在末位的工序基因位置为b1,所有紧后工序排在首位的工序基因位置为b2;
(3)将a1处的基因随机插入到区间[b1,b2]的任意位置,生成新个体。
3.6 算法终止
每迭代一次,更新算法运行次数generation=generation+1,当达到最大迭代次数max_gen时,终止程序,输出当前结果作为最优解。
3.7 算法性能测试
选择混流装配线经典问题对自适应遗传算法的性能进行验证。表1给出了标准遗传算法和自适应遗传算法求解不同节拍的12个测试问题的解,其中mmin表示最优工作站数。从表中可以看出,当作业元素的个数较小时,标准GA和AGA都可以取得最优解,随着问题规模的扩大,AGA逐渐表现出优势,所得平衡方案的平滑指数和联合目标函数值均比GA求解结果要小,说明了自适应遗传算法在求解混流装配线平衡问题时是有效的。
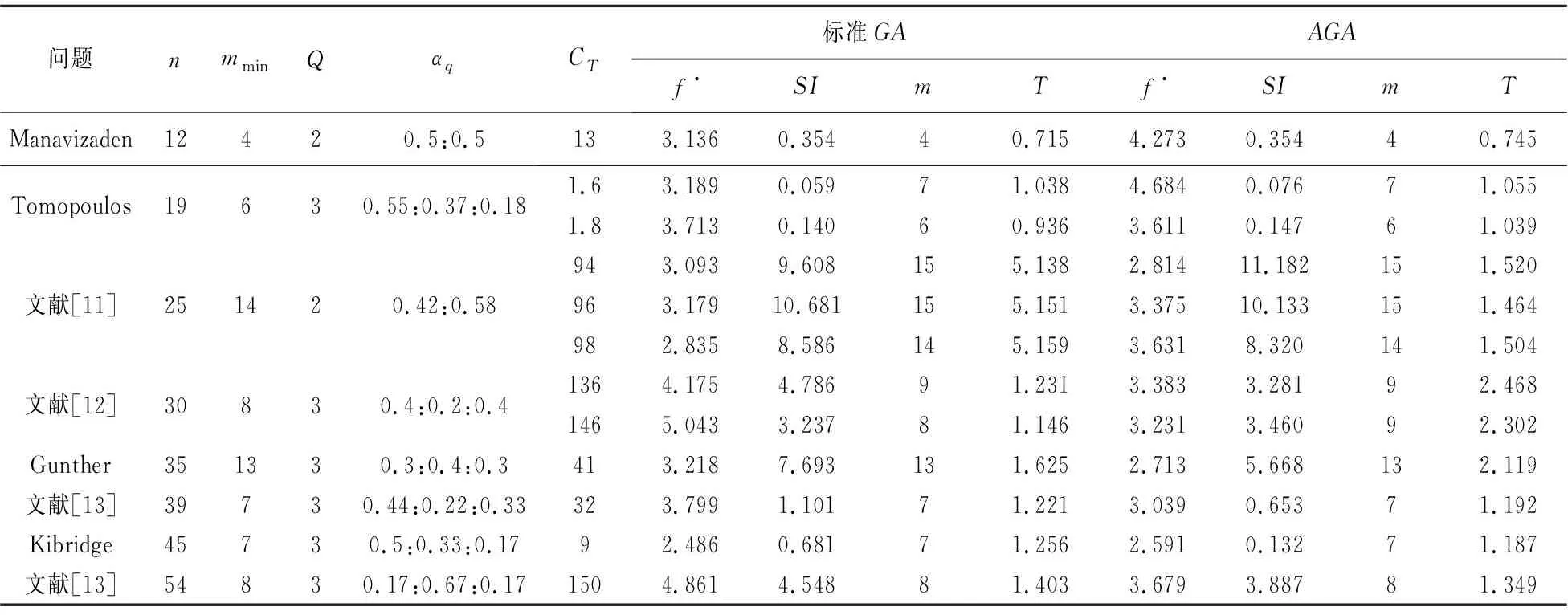
表1 测试问题的解
4 算例研究
混流装配线上生产A、B、C三种产品,计划期内的需求量为DA=400、DB=200、DC=300,则在每个最小生产循环内,各产品将按照4:2:3的比例组织生产,即αA=4/9、αB=2/9、αC=1/3。所有产品的工序操作时间及综合作业优先关系的数据来自于文献14,见表2所示。
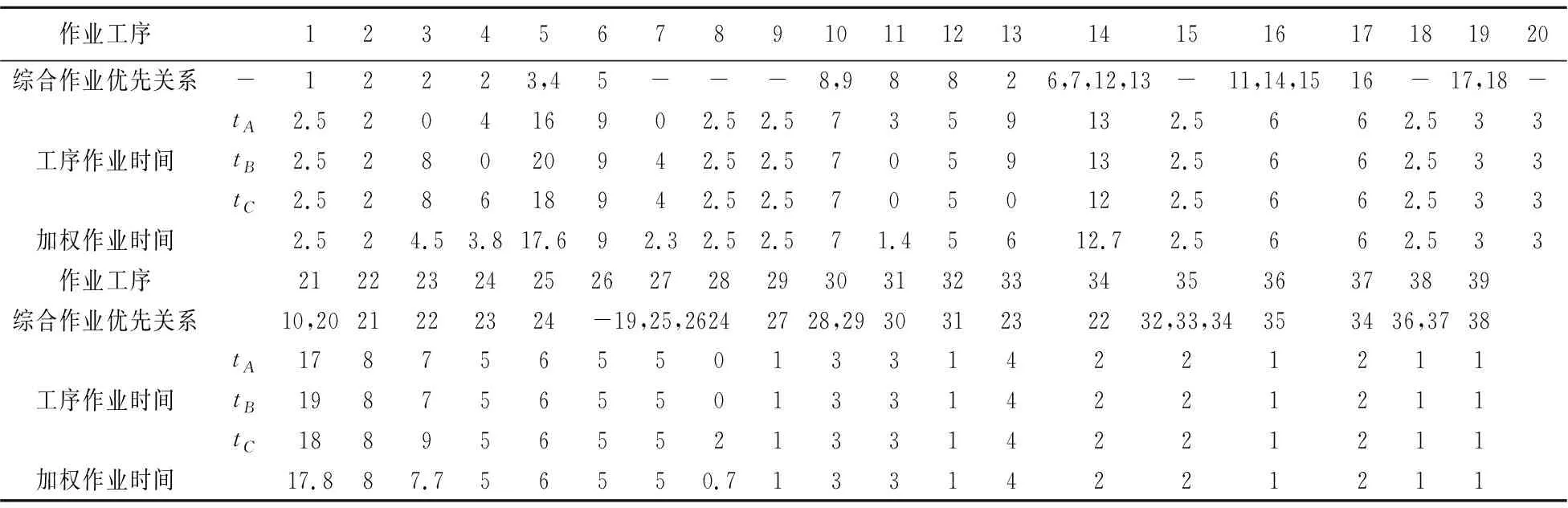
表2 产品的综合作业关系和作业元素时间
已知该混流装配线的设计节拍为32s,共39个工序,按照本文所述多目标优化方法进行工序平衡。运用MATLAB语言编写算法程序,设置自适应遗传算法的参数为:最大交叉概率pcmax=0.9,最大变异概率pmmax=0.1,种群规模popsize=30,最大迭代次数max_gen=100。以三种产品的加权平均作业时间作为该工序操作时间,得到问题的最优解如表3所示,混流装配线上需设置6个工作站,线平衡率为95.01%,平滑指数为5.93,各工作站间作业负荷较均衡,说明应用本文的多目标平衡优化方法能够得到相对最优的工序分配方案。
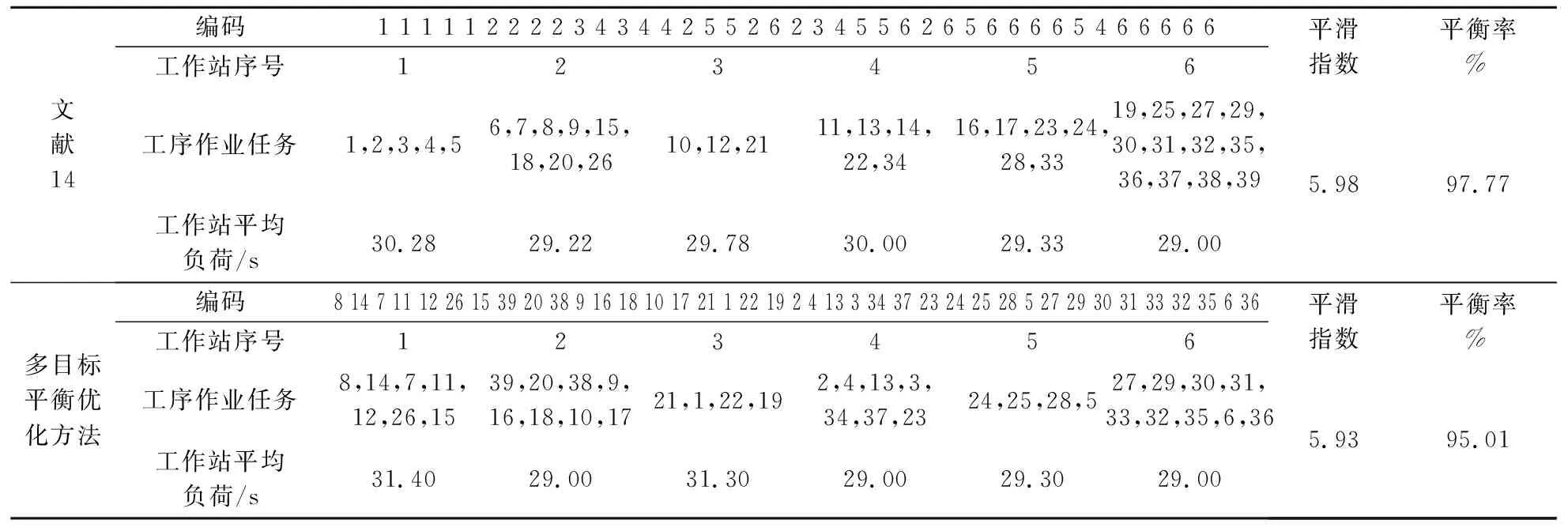
表3 优化结果对比分析
与文献14的最优解进行对比,虽然本文优化结果的平滑指数较优,但线平衡率却比文献14低2.82%。分析原因如下:表4、表5分别列出了在表3所示的两种最优工序布置下,三种产品在各工作站内的实际作业负荷。可以看出,在本文的最优解下,各产品的平衡率较高,而文献14中三种产品在各工作站间的负荷差异较大,尤其当工作站1加工产品C以及工作站4加工产品A时,工作站瞬时负荷分别达到36.5s和35s,这使得装配线实际节拍大于设计节拍32s,造成生产不稳定。另外,表6中文献14最优解对应的目标函数值f2较大,f3较小,也说明文献14的方法仅考虑了工作站间作业时间的一致性,而忽略了因不同产品作业时间差异所导致的工作站瞬时负荷不均衡问题。因此,在混流装配线平衡过程中应综合考虑工作站间负荷平衡以及工作站内不同产品之间的作业负荷平衡,以最大限度的发掘装配线效率。

表4 文献14中三种产品在不同工作站的作业情况
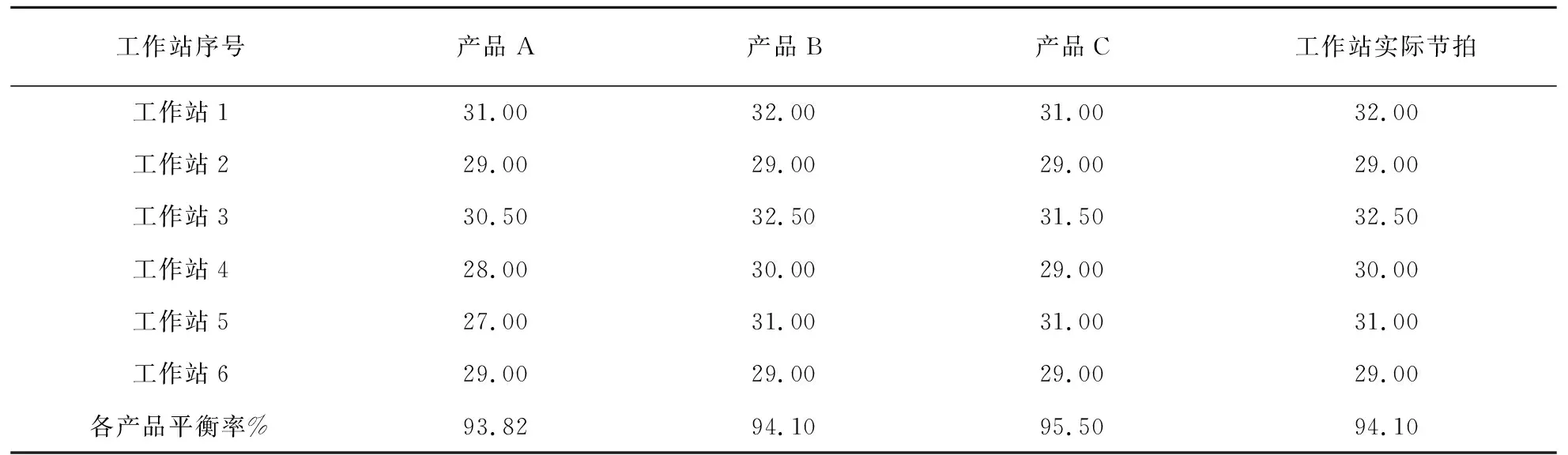
表5 本文多目标优化方法下三种产品在不同工作站的作业情况
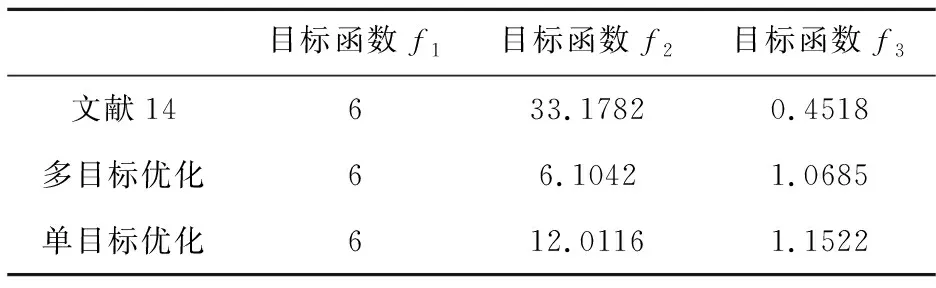
表6 各目标函数值对比
5 结论
针对U型混流装配线平衡问题的特点,本文兼顾工作站平均负荷与瞬时负荷均衡问题,建立了以工作站数最小、工作站间平均单件产品以及工作站内不同产品负荷均衡为目标的优化模型,同时应用目标法对各目标函数进行标准化处理,算例验证的结果表明多目标优化方法能够有效的解决混装线平衡问题。采用自适应遗传算法作为模型的求解方法,进行标杆案例研究,说明改进AGA在求解大规模混流装配线平衡问题时具有明显优势。本文的研究成果能够为企业提供借鉴和参考,具有一定的理论与实践意义。
