基于作业类型和优先级权重的容量调度算法
2022-11-09徐金美蒋天煜TambominyiEliasu
谭 平,徐金美,蒋天煜,Tambominyi Eliasu,丁 进
(浙江科技学院 自动化与电气工程学院,杭州 310023)
近年来,云计算已经成为共享资源的一种新方式[1-2],而Hadoop作为主流的云计算开源平台在此背景下得到了广泛的发展和应用。Hadoop是一个开源且可运行于大规模集群的分布式文件系统和分布式计算框架。调度器作为核心组件直接影响平台性能和资源利用率,其中资源调度算法是提升集群性能的关键。然而默认调度器还存在许多不足[3-5],其调度算法是基于同构集群的假设构建的,但对实际运用的Hadoop集群而言,节点往往是异构的,这种同质性假设会导致异构环境中节点负载不均,且不同类型作业间的资源需求存在差异性,原有调度算法未考虑节点实时负载情况。因此,研究调度算法的改进,对提高Hadoop系统资源利用率和性能具有重要的现实意义。
目前Hadoop调度算法的研究主要涉及异构环境、智能算法、数据本地性和实时性等方面[6-8]。王溪波等[9]提出一种计算节点负载的任务调度策略,通过节点负载情况减少非本地任务的产生和数据迁移量。潘佳艺等[10]提出负载自适应反馈调度策略,区分了作业类别,解决了负载异构性带来的资源碎片化问题。在此基础上,沈学利等[11]提出基于节点能力的自适应调度算法(node capacity adaptive scheduling,NCAS),依据节点负载与作业类型分配资源。李曌等[12]提出一种基于作业类别和截止时间的作业调度算法,该算法考虑并优化了异构环境下的作业选择机制。上述研究在异构环境下对调度算法做出改进,但对作业选择机制的优化并不完善,未能满足用户和作业的多样化需求。针对上述调度算法的不足,本研究结合作业负载类型、节点实时负载情况和优先级权重的作业选择机制,提出基于作业类型和优先级权重的容量调度算法。
1 Hadoop调度器及其调度算法
Hadoop1.0 JobTracker(作业管理器)组件任务繁重,负责整个系统的作业调度与资源管理。Hadoop2.0引入了资源管理框架YARN(yet another resource negotiator)[13],减轻了JobTracker的任务负担,将资源管理和作业调度分开,由全局资源管理器(resource manager,RM)负责作业的资源分配,应用程序管理器(application master,AM)负责作业管理和监控。分布式文件系统(Hadoop distributed file system,HDFS)[14]和分布式计算框架(map reduce,MR)[15]是Hadoop框架核心组成部分,HDFS为海量数据提供分布式存储服务,MR为海量数据提供计算。
Hadoop默认有3个调度器[16-17],分别是先进先出调度器(first in first out scheduler)、容量调度器(capacity scheduler)和公平调度器(fair scheduler)。本研究针对容量调度器提出改进,因此先介绍其资源调度机制。容量调度器支持多队列服务,资源按照一定的权重分配给队列,在其进行资源调度时,先计算队列中运行的任务数和应分得计算资源的比值,选择比值最小的队列执行任务,队列内部再按照初始优先级和先进先出调度机制选择作业执行,在当前运行的作业被终止后,资源才能被分配给新的作业[18]。队列并行执行的任务数等于队列个数。该调度策略的优点是可同时维护多个队列,队列可共享空闲资源,但并未考虑同类型作业之间的资源竞争和节点的实际负载情况,导致集群中节点负载不均;队列内部的作业选择机制过于简单不能满足用户和作业多样化的需求,导致集群资源利用率低下。
2 容量调度算法优化与改进
容量调度器按照初始优先级和先进先出调度策略来处理作业,但在实际资源调度时,仅考虑作业初始优先级和作业提交顺序是远远不够的。且不同类型作业之间的资源需求存在着差异性,而容量调度算法并没有对作业进行负载分类。因而相同节点上可能运行着同类型的作业,不能充分利用处理器的性能,从而导致节点上资源相互竞争、资源利用率低下等问题,影响用户作业的处理时间和整个系统的性能。文献[19]针对这一问题设计了一种动态MR工作负载预测机制,区分作业负载类型进行任务的调度,本研究以此为基础,结合作业负载类型、节点实时负载情况和作业优先级权重调度提出了基于作业类型和优先级权重的容量调度算法,能自动将用户提交的作业进行作业负载分类并结合节点实时负载情况进行作业调度,能有效地避免同节点的资源竞争问题,通过基于权重作业优先级的作业选择机制满足用户和作业多样化的需求,综合考虑多因素来衡量作业的紧急程度,实现根据用户紧急程度的作业调度,以达到优先分配资源的目的。调度算法流程如图1所示,主要分为以下3个部分:
1) 将用户提交的作业划分为CPU(central processing unit,中央处理器)负载类型作业和I/O(input/output,输入/输出)负载类型作业,并将作业自动分配到对应的队列中(内存队列和I/O队列);
2) 采集节点资源信息,计算节点负载,按照节点实时负载情况从小到大进行排序,优先给负载小的节点分配任务执行;
3) 队列中的作业按照优先级权重选择合适的任务进行调度,作业优先级权重高的作业优先执行。
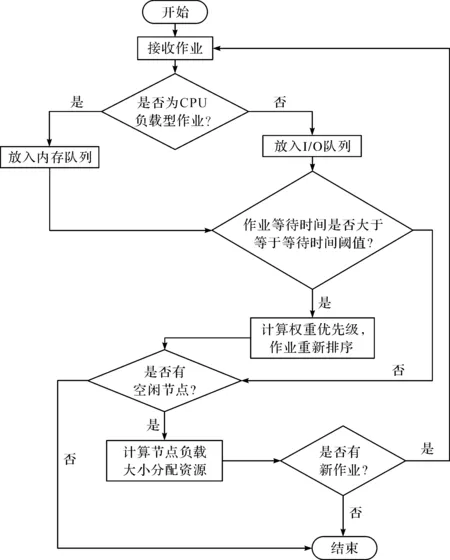
图1 调度算法流程Fig.1 Flow of scheduling algorithm
2.1 作业负载分类
MR程序主要分为两个过程,即映射(map)阶段和化简(reduce)阶段,MR工作流程如图2所示。其中map阶段是MR过程的关键,先将输入的数据进行分割,再为每个数据块分配map任务。Key/value键值对作为map函数的输入,map函数输出的中间key/value键值对存在本地磁盘中。reduce阶段运行用户自定义的reduce函数对中间key/value键值对进行处理。在当前作业的map阶段完成之后才会进入reduce阶段,且节点执行同一个作业的map任务时,每个map任务具有相同的运行特性。因此,本研究作业负载分类主要针对map阶段来衡量作业的负载情况。根据CPU和内存的利用率,对map阶段的作业负载进行了分类,划分为CPU负载类型作业和I/O负载类型作业。
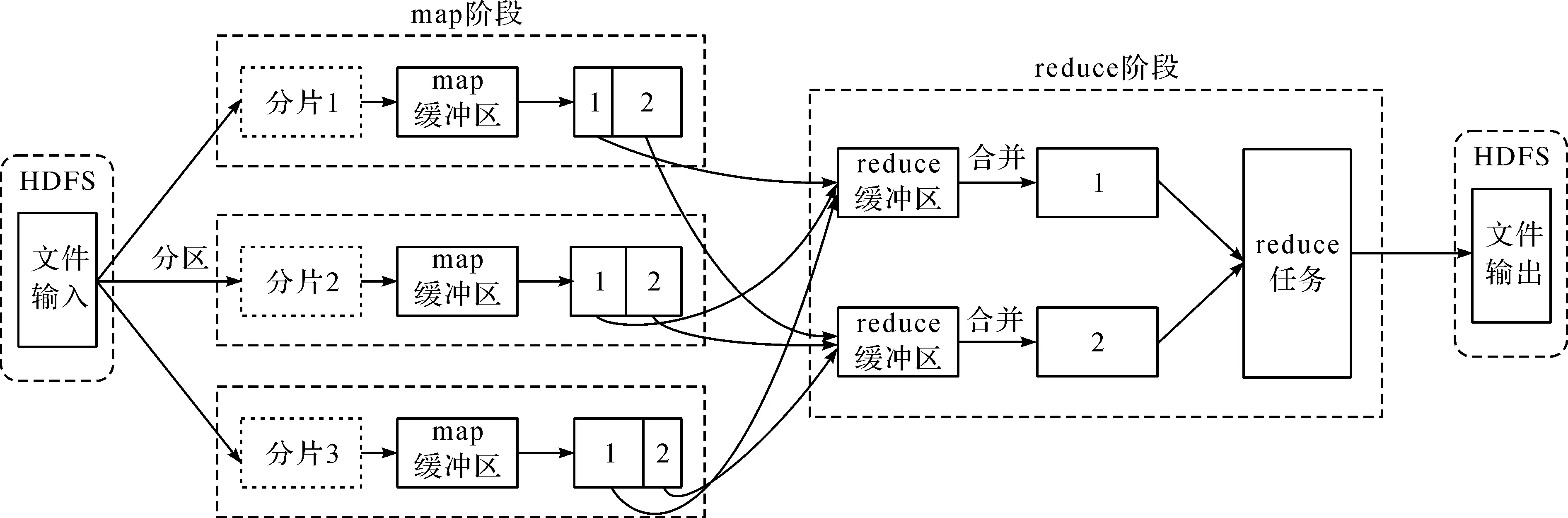
图2 MR工作流程Fig.2 Work flow of MapReduce
CPU负载类型作业指处理速度受CPU限制的进程,作业执行时需要进行大量的计算和逻辑判断,消耗CPU资源,CPU占用率高,系统的硬盘/内存效能高于CPU效能。I/O负载类型作业指处理速度受I/O子系统限制的进程,作业执行时的状况是CPU等待I/O的读写,此时系统的CPU消耗小、效率高,涉及网络、磁盘IO的作业都是I/O负载类型作业。
参数β为map任务输出数据Mo和输入数据Mi的比值,定义如下:
(1)
该参数反映了map任务的负载状况,若作业的map任务负载状况相同,即表示具有相同的β值。由式(1),可推导出当前该任务在节点上的数据传输速率
(2)
式(2)中:n为节点中正在执行的map任务数;Tmap为map任务的完成时间。当节点上的数据传输速率大于磁盘I/O速率时,表示当前作业需要进行大量的I/O操作,因此本研究将此类作业划分为I/O负载类型作业;当一个作业的磁盘I/O速率较低时,其CPU使用率相对较高,将此类作业划分为CPU负载类型作业。I/O负载类型作业和CPU负载类型作业的定义分别如下:
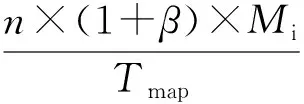
(3)
(4)
式(3)~(4)中:Dr为磁盘I/O速率。
2.2 节点负载排序
在实际集群环境中,Hadoop大多部署在异构集群上,各个节点计算能力差别较大。容量调度器忽略了节点间的差异,导致节点性能无法最大化。本算法在节点资源被调度之前,实时采集节点资源信息,计算节点实时负载状况,按照节点实时负载情况从小到大进行排序,并且每隔一定的心跳周期更新一次节点队列的节点排序。在对用户提交的作业进行作业负载分类的基础上,对节点负载进行排序,优先分配负载小的节点给作业执行,大大提高作业的执行效率。
节点负载情况受CPU、内存、磁盘资源、网络状况等因素的影响[20],本研究中节点负载计算公式如下:
wCPU+wmem+wdisk+wnr=1,wCPU,wmem,wdisk,wnr∈[0,1]。
(5)
Lnode=wCPU×μCPU+wmem×μmem+wdisk×μdisk+wnr×μnr。
(6)
式(5)~(6)中:wCPU、wmem、wdisk和wnr分别为节点CPU、内存、磁盘和网络资源的使用率;Lnode为节点负载值;μCPU、μmem、μdisk和μnr分别为节点CPU、内存、磁盘和网络资源的权重值。
2.3 作业调度执行
容量调度器不支持资源抢占,优先级高的作业会被当前作业阻塞。队列中作业执行顺序会直接影响作业等待时间并间接影响总的作业完成时间。调度算法的核心是如何为作业分配合适的资源,仅考虑作业初始优先级对作业进行调度是不可取的。因此,本算法提出了一种新的作业选择机制,作业的优先级权重能综合考虑作业初始优先级、作业等待时间、作业占用CPU和内存资源大小这4个因素,根据权重优先级来衡量作业紧急程度,优先执行紧急程度高的作业,以满足用户和作业的多样性需求,从而提高系统性能。
对等待时间超过阈值的作业,通过提高其权重实现作业优先级提升,进而提高作业实时性。对占用CPU和内存资源过大的作业,可基于负载类型及节点负载情况进行作业分配优化,降低总的作业完成时间,提高作业执行效率。Hadoop默认初始作业优先级分为5个级别,分别为VERY_HIGH、HIGH、NORMAL、LOW、VERY_LOW。作业权重优先级能满足用户作业多样性的需求,优先完成紧急程度高的作业。本调度算法在用户提交作业后,首先划分作业的负载类型,并把作业分配到相应的队列中;其次进行作业初始优先级的判断,并将默认的初始作业优先级量化,调度器按照优先级权重公式更新权重优先级,并将队列中的作业重新排序;最后结合节点负载情况优先给权重作业优先级高的作业分配资源。作业优先级权重计算公式如下:
(7)
式(7)中:Pw为权重优先级;P为作业初始优先级;Twait为当前作业等待时间,Twait=Tcurrent-Tstart;T为等待时间阈值;PCPU为当前作业占用CPU资源大小;Pram为作业占用内存资源大小;Tcurrent为当前时间;Tstart为作业提交的时间。权重值之和满足
wtime+wCPU+wram+wpriority=1,wtime,wCPU,wram,wpriority∈[0,1]。
(8)
式(8)中:wtime、wCPU、wram和wpriority分别为作业等待时间、作业占用CPU资源大小、作业占用内存资源大小和初始优先级的权重值。
3 试验结果及性能分析
3.1 Hadoop集群架构
Hadoop测试集群由1台工作站、3台计算机搭建而成。1台为主节点,另外3台为从节点。4台主机处于局域网中,网络设备为1台小型8口TP-Link交换机。搭建本集群的运行环境安装版本为:Ubuntu18.04、JDK1.8.0、Hadoop2.7.6,具体集群环境配置见表1。

表1 集群环境配置Table 1 Cluster environment configuration
试验选取Hadoop自带性能测试集:TeraSort和GrepCount。文献[19]论证了TeraSort为I/O负载类型作业,GrepCount为CPU负载类型作业。在本地搭建的Hadoop测试集群上分别配置容量调度算法及基于作业类型和优先级权重的容量调度算法,按照相同的方式和作业提交顺序来进行对比试验。试验数据均为重复5次测试所取的平均值,以保证其有效性。测试集群网络拓扑图如图3所示。
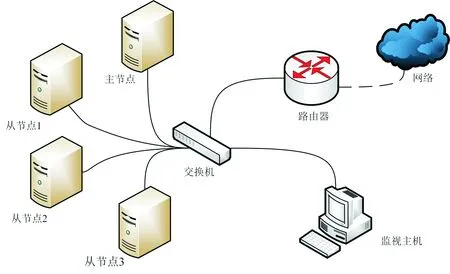
图3 测试集群网络拓扑图Fig.3 Network topology of test cluster
3.2 试验结果与分析
本试验中基于作业类型和优先级权重的容量调度算法等待时间阈值T取值为30 s,权重取值为:wtime=0.2,wCPU=0.3,wram=0.3,wpriority=0.2。
试验1在测试集群上配置和使用容量调度算法及基于作业类型和优先级权重的容量调度算法,运行TeraSort和GrepCount作业,输入数据量分别为1、3、5 GB,作业平均完成时间如图4~5所示。由图4~5可知,本算法明显缩短了TeraSort和GrepCount的作业平均完成时间,较容量调度算法缩短了9.7%。本算法对作业进行作业负载分类,虽在一定程度上延长了作业完成时间,但本算法划分了作业负载分类并结合节点实时负载情况将不同类型的作业匹配给适合的节点执行,从而减少了同类作业的资源竞争,提高了资源利用率。
试验2依次在测试集群上配置容量调度器和基于作业类型和优先级权重的容量调度器,按照相同的方式和作业顺序提交数据量为5 GB的作业流,研究集群运行结果并统计和分析数据。用户提交作业流列表见表2,作业提交时间间隔为1 s。
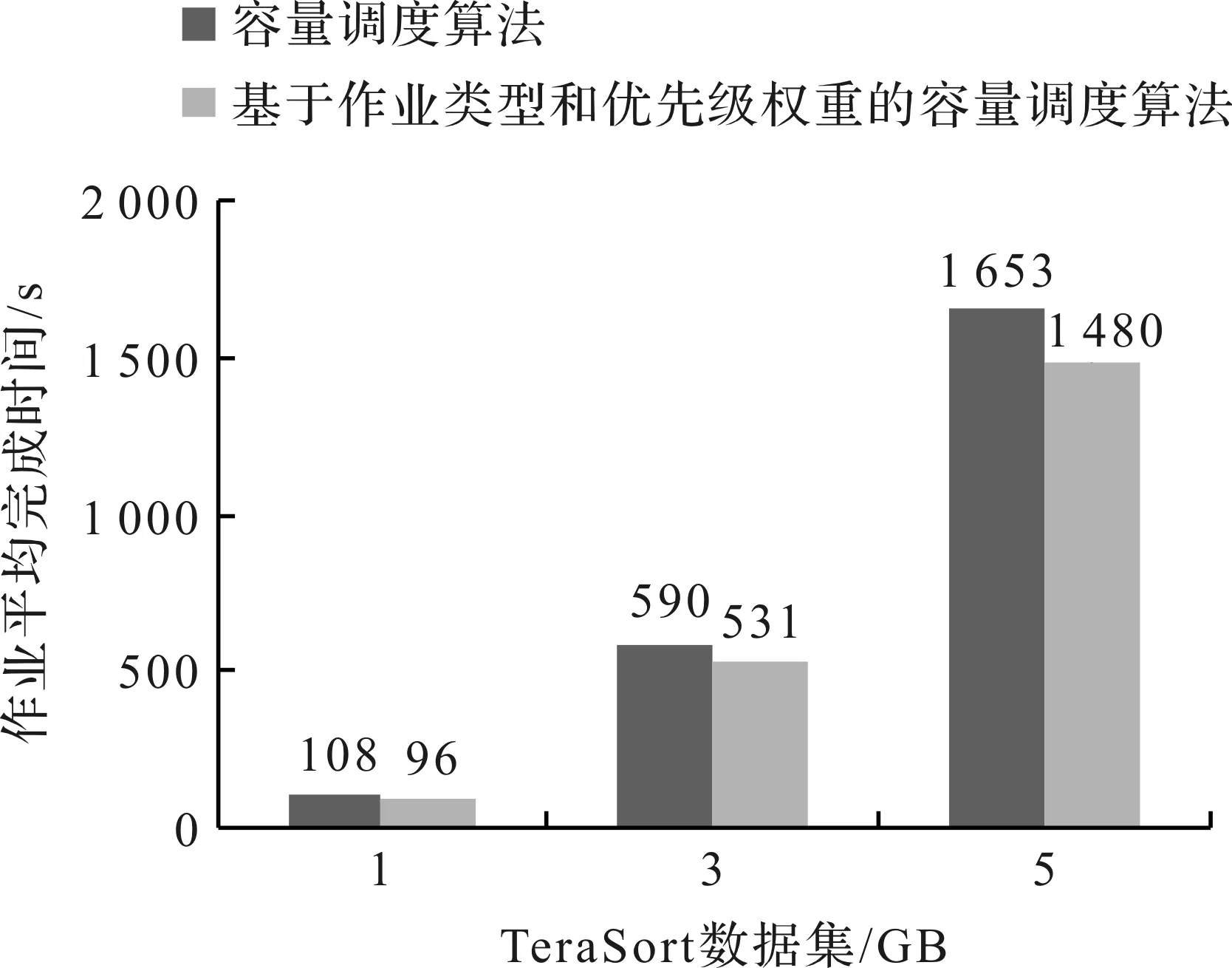
图4 TeraSort作业平均完成时间Fig.4 Average job completion time of TeraSort
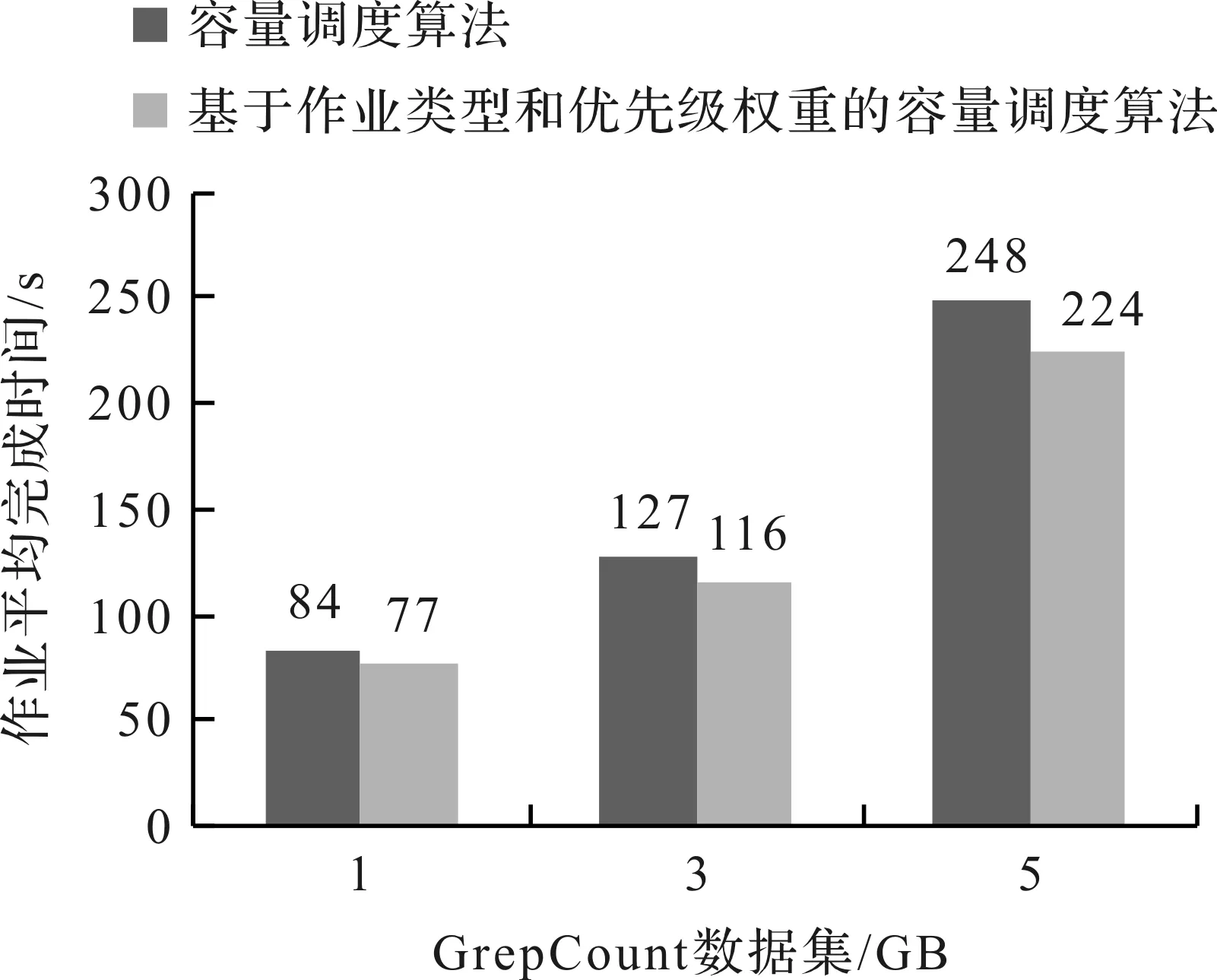
图5 GrepCount作业平均完成时间Fig.5 Average job completion time of GrepCount

表2 作业流列表Table 2 List of job flow
据作业运行日志,统计5 GB作业流的队列分配情况,其结果见表3。本算法配置2个队列(内存队列和I/O队列)来存放用户提交的作业。由运行日志可以看出调度器区分出了作业负载类型,并准确地将其分配到队列中。

表3 作业队列分配Table 3 Job queue allocation
容量调度器作业流测试及基于作业类型和优先级权重的容量调度器作业流测试结果如图6~7所示,图中不同颜色代表不同的作业,两幅图中相同颜色代表作业流中的同一作业。结合表3、图6和图7可知,本算法改变了作业的执行顺序,且缩短了作业平均完成时间。从单个作业的完成时间来看,大部分作业的执行时间比容量调度器有大幅度的减少。有个别作业如T3、G4的完成时间落后于原调度算法,这是因为在执行T3作业和G4作业之前,用户提交作业的等待时间超过了等待时间阈值,作业根据权重公式更新了优先级和队列中作业执行顺序,优先执行了初始优先级大和需要占用大资源的作业,这些优先执行的作业占用了队列资源,从而拉长了T3和G4的完成时间。但从整个作业流的完成时间来看,本算法让不同类型作业使用不同的节点资源,有效地将作业流平均完成时间缩短30.8%,实现了对集群资源的充分利用,提高了集群的吞吐率。

图6 容量调度器作业流测试Fig.6 Job flow test of capacity scheduler
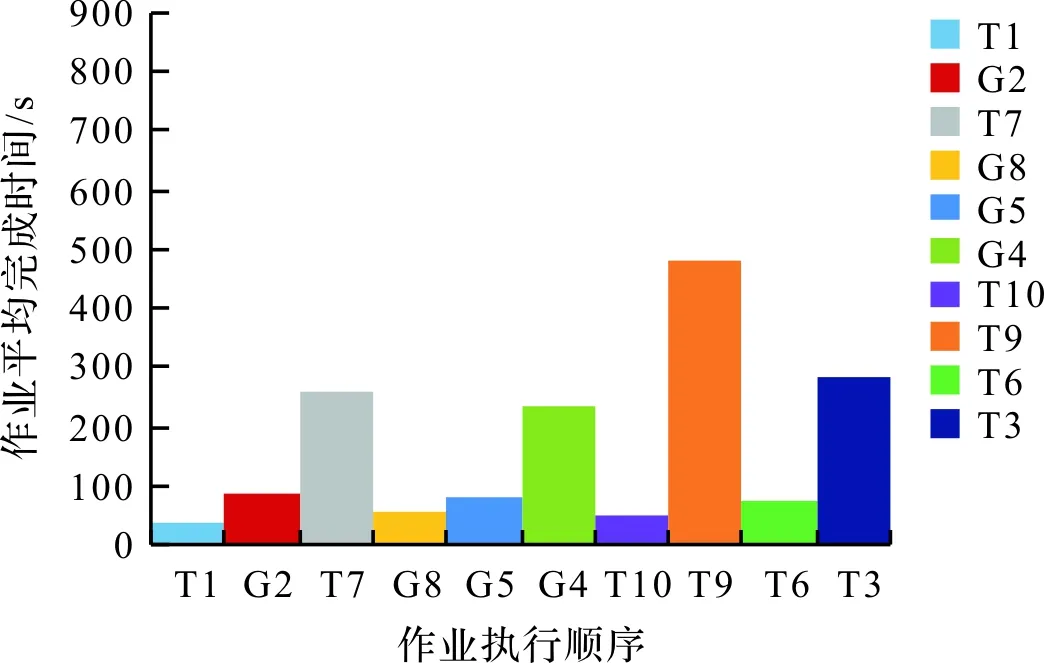
图7 基于作业类型和优先级权重的容量调度器作业流测试Fig.7 Job flow test of capacity scheduler based on job type and priority weight
4 结 语
本研究分析了Hadoop平台调度算法在异构环境下调度策略的不足,并针对容量调度算法提出了基于作业类型和优先级权重的容量调度算法。在本地搭建集群进行试验,其结果表明:本算法划分了作业负载类型并将其分配到对应的队列中,结合优先级权重对队列中的作业进行重新排序,优先为权重高的作业分配资源,充分利用了集群资源,以缩短了作业平均完成时间。在后续研究中,会考虑延迟作业的备份,对备份任务的处理策略进行研究,进一步优化提高调度算法性能。
