基于MAJDA无监督迁移的旋转机械跨工况故障诊断
2022-11-09韦代平
黄 尧,韦代平,刘 万,张 池
(重庆大学机械与运载学院,重庆 400044)
0 引言
早期的旋转机械故障诊断主要是基于信号处理的方法[1]。随着各种机器学习算法的成熟,基于特征提取然后利用机器学习自动学习特征与故障模式之间的映射关系,进行故障分类的方法[2]逐渐流行。如支持向量机、k最近邻和神经网络。近年来由于深度学习[3]兴起并且在各领域得到广泛应用,基于深度学习的机械故障诊断方法[4]纷纷提出。深度学习具有优良的特征提取能力,用于轴承故障诊断可实现端到端的诊断方式,免去人工提取和筛选特征,但需大量样本,且测试样本和训练样本需同分布。而多数实际情况缺乏大量样本,或者测试样本分布不同,进而提出了域适应学习[5]。
域适应学习从分布不同但有内在联系的领域学习知识,然后迁移到目标领域,来提高模型在目标域的预测能力。旋转机械故障数据采集耗时耗力,一些文献提出利用域适应学习来解决目标域训练样本不足或无标签的故障诊断问题。GUO等[6]通过最小化源域和目标域的最大均值差异(maximum mean discrepancy,MMD)在不同域之间进行特征对齐,并同时降低分类误差,来实现跨域诊断。LI等[7]通过在多个中间层使用MMD对齐两域特征分布,以此提取跨域不变特征。LIU等[8]利用对抗思想使域鉴别器区分不出样本来自源域还是目标域,将两域分布对齐。吴静然等[9]考虑将类别之间的局部分布对齐提出了一种子域适应无监督网络,利用局部最大平均差异(local maximum mean discrepancy,LMMD)[10]实现了更细粒度的特征分布对齐。揭震国等[11]提出了一种基于深度学习与子域适配的齿轮故障诊断方法,采用多核局部最大均值差异来计算相关子域特征的分布差异并减小该差异来提取可迁移特征。张钊等[12]同时考虑源域和目标域全局分布对齐和局部分布对齐,提出了一种联合分布自适应的无监督故障诊断方法。
GUO、LI、LIU等[6-8]只将两域全局分布对齐(边缘分布对齐),未考虑类别之间的局部分布对齐(条件分布对齐),目标域条件分布与源域不同,导致准确率不高。吴静然、揭震国等[9、11]仅考虑条件分布对齐,张钊等[12]同时考虑边缘分布和条件分布对齐,进行联合分布对齐。进行条件分布对齐需用到目标域数据的标签,而目标域只有无标签数据,上述方法直接将目标域数据输入由源域数据训练的分类器来获得伪标签,然后利用源域特征加真实标签和目标域特征加伪标签进行条件分布对齐。训练开始阶段两域分布差异较大且分类器不够准确,此时伪标签并不准确,过多的错误伪标签将使目标域条件分布向错误的类别对齐,从而引起负迁移。条件分布对齐的关键是伪标签的准确性,可靠的伪标签策略尤为重要。
针对以上问题,本文提出了一种多尺度异步联合分布对齐(multiscale asynchronous joint distributed alignment,MAJDA)故障诊断网络。一方面,利用3种不同卷积核尺寸的一维卷积神经网络提取不同尺度的特征,分别输入3个分类器,融合3个分类结果保证伪标签更准确;另一方面,先利用MMD对齐边缘分布,边缘分布对齐后条件分布近似对齐[13],且此时分类器已经训练一段时间,故伪标签更加准确,然后利用LMMD进行条件分布对齐,该策略避免了直接进行条件分布对齐错误伪标签过多引起的负迁移。利用本文采集的轴承数据集和PHM2009齿轮箱数据集进行实验验证和分析。在目标工况数据无标签的情况下,本文方法诊断准确率显著高于其它常见的域适应方法,表明该方法具有可行性和有效性。
1 基础理论
1.1 无监督领域自适应
迁移学习给定一个源域Ds和源学习任务Ts,目标域Dt和目标学习任务Tt,在Ds≠Dt或Ts≠Tt的设定下,利用Ds和Ts中学习到的知识来提升Dt中预测函数FT(·)的性能[5]。
无监督领域自适应(unsupervised domain adaptation,UDA)为迁移学习的子方向,设定数据分布不同Ds≠Dt,但学习任务一致Ts=Tt,源域数据有标签即Ds={Xs,Ys},而目标域数据无标签即Dt={Xt}。由于源域数据和目标域数据概率分布不同即P(Xs)≠P(Xt),UDA通过探索一个变换Gf(·),使得变换后的数据Z=Gf(X)的概率分布接近即P(Zs)≈P(Zt),以此提取两域共同特征,那么由源域数据训练的分类器可用于目标域。UDA的损失函数通常定义如下:
loss=lossC(Gc(Zs),Ys)+λ·lossA(Zs,Zt)
(1)
式中,Gc(·)为分类器;lossC(·)为分类损失函数,一般选择交叉熵损失;lossA(·)为域适应损失函数,度量两域特征分布差异;λ为两种损失的平衡因子。
1.2 边缘分布对齐
边缘分布对齐最早由文献[13]提出,在不考虑数据标签的情况下,将源域和目标域数据特征的概率分布进行全局对齐即P(Zs)≈P(Zt),如图1所示,不同形状表示不同类别的分布。

图1 边缘分布对齐
利用MMD计算源域和目标域边缘分布差异损失,公式如下:
(2)

1.3 条件分布对齐
条件分布对齐考虑数据标签,将源域和目标域数据特征的概率分布按照相应的类别进行局部对齐,如图2所示。条件分布对齐需用到两域数据标签,而UDA任务中目标域数据无标签,通常利用源域有标签数据训练一个分类器,然后将目标域数据输入该分类器得到伪标签。
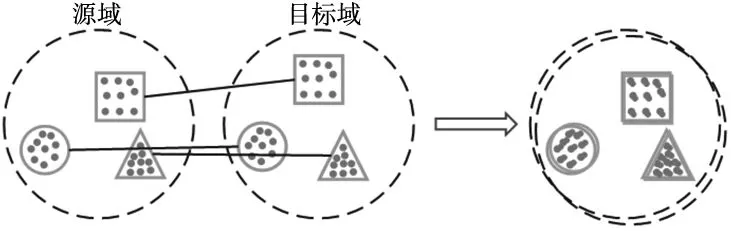
图2 条件分布对齐
文献[10]提出了LMMD来计算两域条件分布差异损失,公式如下:
(3)

2 MAJDA故障诊断网络
2.1 网络结构与损失函数
MAJDA网络结构如图3所示,包含3组预测器,每组预测器由一个特征提取器Gf和一个分类器Gc构成,Gf为1D卷积神经网络,Gc为全连接神经网络。
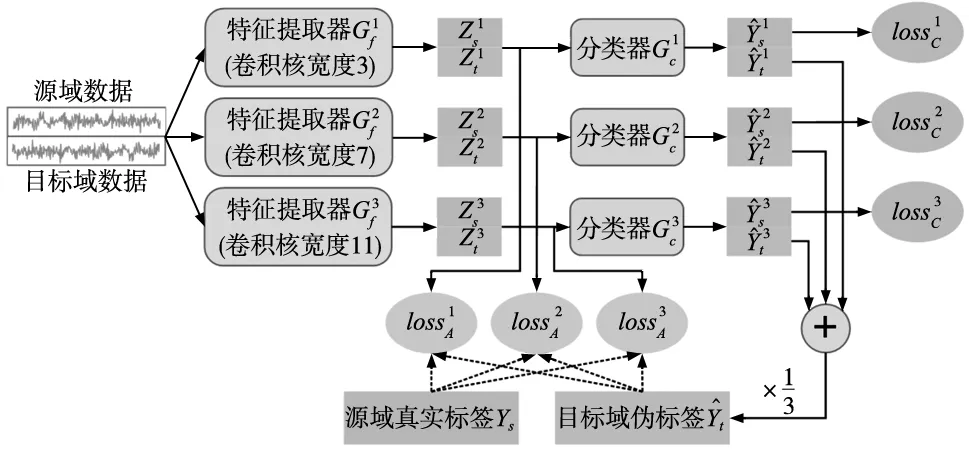
图3 MAJDA网络结构
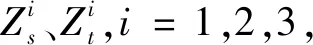
(4)
式中,n为样本数量,总损失计算式如下:
(5)
特征提取器Gf和分类器Gc的具体结构如表1所示。3个特征提取器除了卷积核尺寸不同,其他超参数均相同。

表1 网络结构
2.2 多尺度伪标签策略MCNN
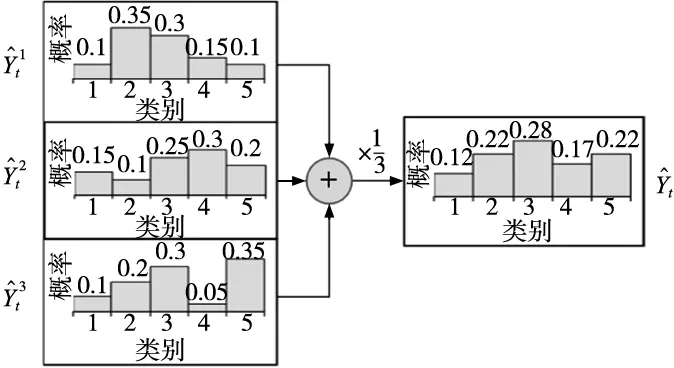
图4 多尺度伪标签
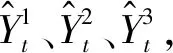
2.3 异步联合分布对齐伪标签策略AJDA
大部分域适应方法只将源域和目标域特征进行全局对齐即边缘分布对齐,若每个类别对应的局部分布未对齐即条件分布未对齐,目标域预测准确率仍不高。现有的一些考虑条件分布对齐的方法存在一个共同的弊端,即从迭代开始阶段就进行条件分布对齐,条件分布对齐需用到目标域伪标签,而此时伪标签准确率并不高,原因有两点:①如图5a所示,若目标域和源域边缘分布差异太大,此时很难正确判定目标域伪标签;②此时分类器未充分训练,不能正确分类。
针对上述两个问题,提出了异步联合分布对齐(asynchronous joint distributed alignment,AJDA)伪标签策略,即训练开始阶段只进行边缘分布对齐,边缘分布对齐后再进行条件分布对齐。文献[13]假设边缘分布对齐后条件分布近似对齐,如图5b所示。迭代一定次数使边缘分布对齐后,不但两域条件分布更接近,且分类器已充分迭代,故此时计算伪标签更准确,然后进行条件分布对齐效果将一定程度提高。对于从边缘分布对齐转为条件分布对齐的时机,本文给出如下判据:
(6)

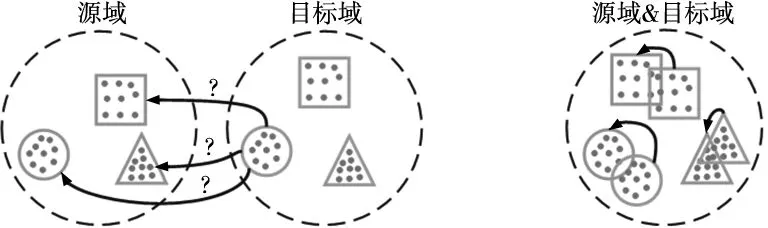
(a) 边缘分布未对齐 (b) 边缘分布已对齐
2.4 诊断步骤
步骤1:样本截取与归一化。对源工况和目标工况进行样本截取,截取长度2048/4096点,截取间隔500点,每段信号用其均值方差进行归一化;
步骤2:配置数据集。源工况有标签样本和目标工况无标签样本作为训练集,目标工况样本作为测试集;
步骤3:训练模型。训练集中每个batch包含等量的源工况有标签样本和目标工况无标签样本,正向传播按式(5)计算总loss,反向传播计算梯度,按设定的学习率迭代更新网络参数;
步骤4:测试模型。将目标工况所有样本输入模型,比较预测标签和真实标签,计算分类准确率。
3 实验
3.1 数据集
采用轴承和齿轮箱数据集验证本文MAJDA网络效果。轴承数据由本文搭建试验台采集,齿轮箱数据为PHM2009数据集。
轴承数据集:实验台如图6所示,轴承包含正常、内圈故障、外圈故障、滚动体故障4种健康状况,如表2所示。使用加速度计在1120、1670和2054 r/min转速下,以24 kHz采样频率采集数据,对3个工况编号为A~C。

图6 轴承实验台

表2 轴承数据集故障类别
PHM2009齿轮箱数据集:齿轮箱结构如图7所示,包含8种复合故障,故障详情如表3所示。使用安装在输入轴和输出轴固定板上的加速度计,在30、35、40、45和50 Hz轴速下,高负荷和低负荷下,以66.7 kHz采样频率采集数据。本文只使用高负荷下输入端数据,对5个工况编号为A~E。
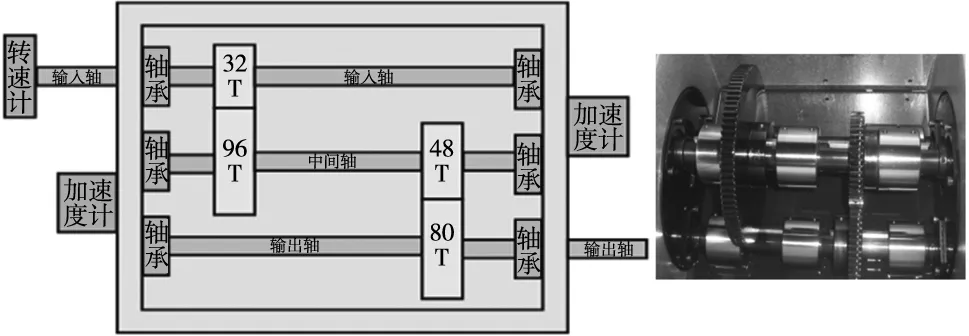
图7 PHM2009齿轮箱
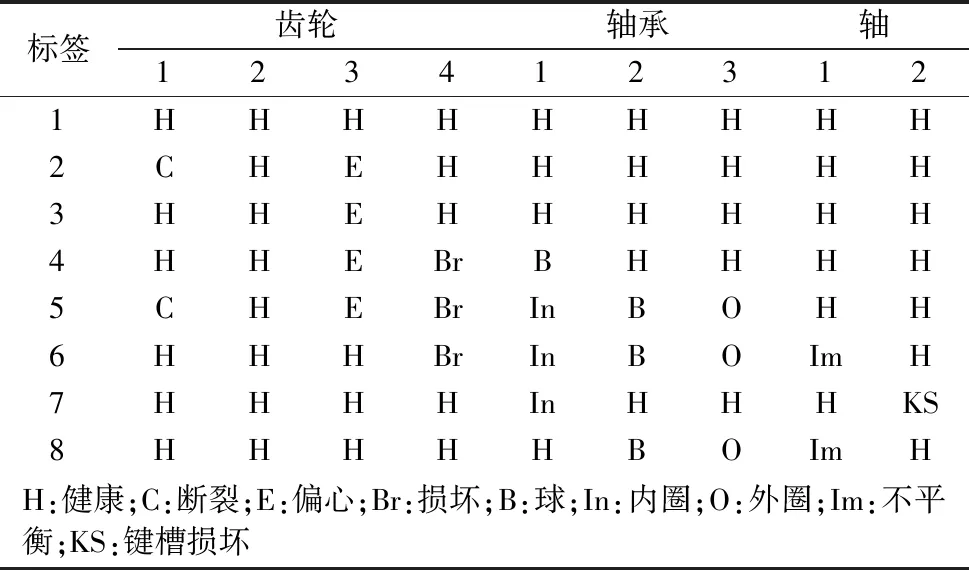
表3 齿轮箱数据集故障类别
3.2 对比方法
对比方法包括:①普通CNN:损失函数只有源域分类损失,无域适应机制;②本文多尺度卷积神经网络伪标签策略MCNN:损失函数包含3组分类器损失,无域适应机制;③本文异步联合分布对齐伪标签策略AJDA:先利用MMD对齐边缘分布再利用LMMD对齐条件分布;④深度域混淆DDC[14]:利用MMD进行边缘分布对齐;⑤深度子域适应网络DSAN[10]:利用LMMD进行条件分布对齐;⑥域对抗神经网络DANN[15]:损失函数包括分类损失和域判别损失,进行边缘分布对齐;⑦ DCORAL[16]:二阶统计特征对齐;⑧联合域适应网络JAN[17]:利用MMD对多个网络层的输出进行边缘分布对齐,本文实现方式为对Gf、Linear、SoftMax的输出进行对齐。
为实现公平对比,各方法使用的特征提取器Gf、分类器Gc以及其它公共超参数完全相同,如表1所示。本文MAJDA和MCNN使用多尺度预测器,其他方法使用卷积核尺寸为3的单预测器。各域适应方法的损失平衡因子λ的大致最优值经过多次试验确定,如表4所示。

表4 各域适应方法平衡因子
3.3 目标工况准确率对比
对两个数据集分别设置了6个迁移任务,A→B表示源域为工况A,目标域为工况B。为保证数据可靠性,每个迁移任务实验5次取均值,每次实验迭代200 epoch。对于轴承数据集,目标工况准确率如表5所示。无域适应机制的普通CNN效果最差,平均准确率(Avg)为94%。DCORAL、DDC、JAN考虑边缘分布对齐在96%左右。DSAN考虑条件分布对齐为96.97%。本文AJDA策略为97.50%。DANN用对抗网络对齐边缘分布为98.71%。本文MCNN策略99.41%,比单尺度CNN高5.41%,说明多尺度伪标签比单尺度伪标签更准确。本文MCNN策略和AJDA策略相结合的MAJDA,对伪标签准确性进行双重保障,实现更加精确的条件分布对齐,平均准确率高于单方面保障的MCNN和AJDA,且显著高于其他方法,为99.61%。对于PHM2009齿轮数据集,目标工况准确率如表6所示。CNN平均准确率为84.51%(轴承数据集中CNN为94%),说明PHM2009齿轮箱数据集中源工况和目标工况差异比轴承数据集更大。同时可见其它方法在PHM2009齿轮数据集中的平均准确率比在轴承数据集中的平均准确率明显偏低,而本文MAJDA仍高达99.95%。综合两个数据集实验结果,本文AJDA策略均比只进行边缘分布对齐的DDC和只进行条件分布对齐的DSAN平均准确率高,说明AJDA有效。而本文MCNN亦均取得了相对较高的准确率,说明多尺度伪标签有效。结合MCNN策略和AJDA策略的MAJDA准确率均显著高于其他方法,说明本文MAJDA方法在旋转机械跨工况故障诊断任务中性能优良且稳定。各方法的时间消耗(s/epoch)如表最后一列所示。
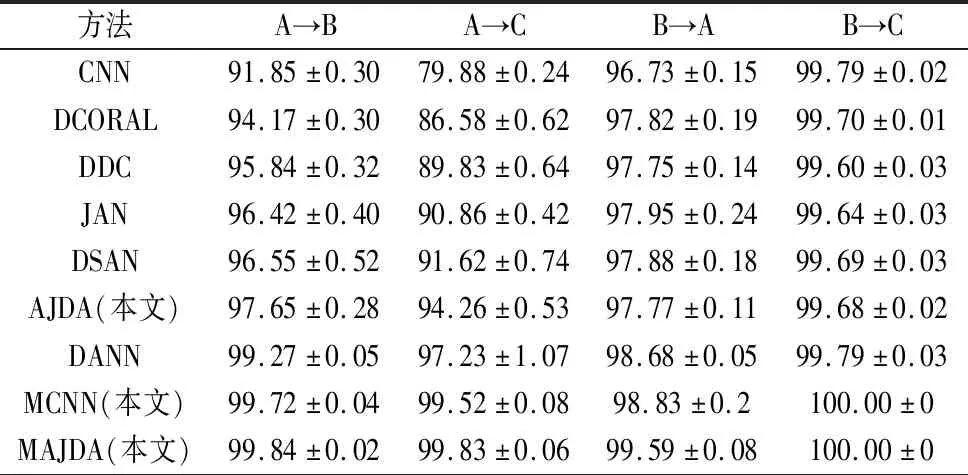
表5 轴承数据集目标工况准确率 (%)
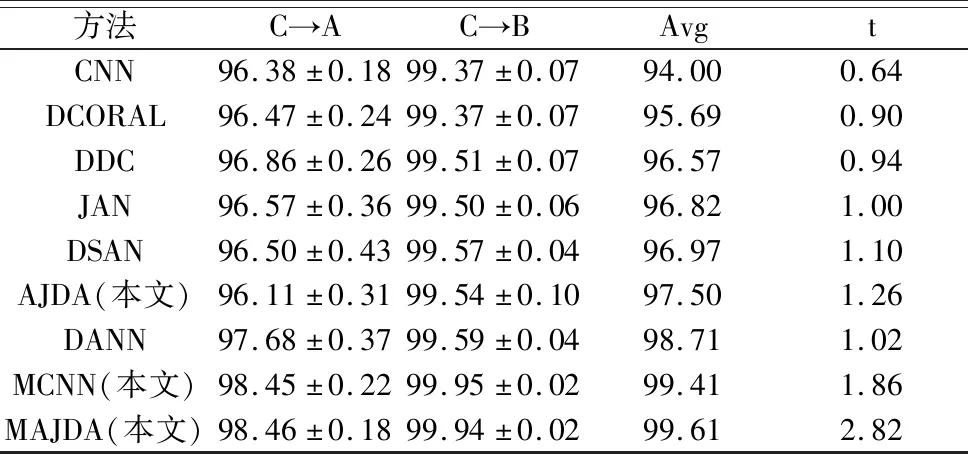
续表
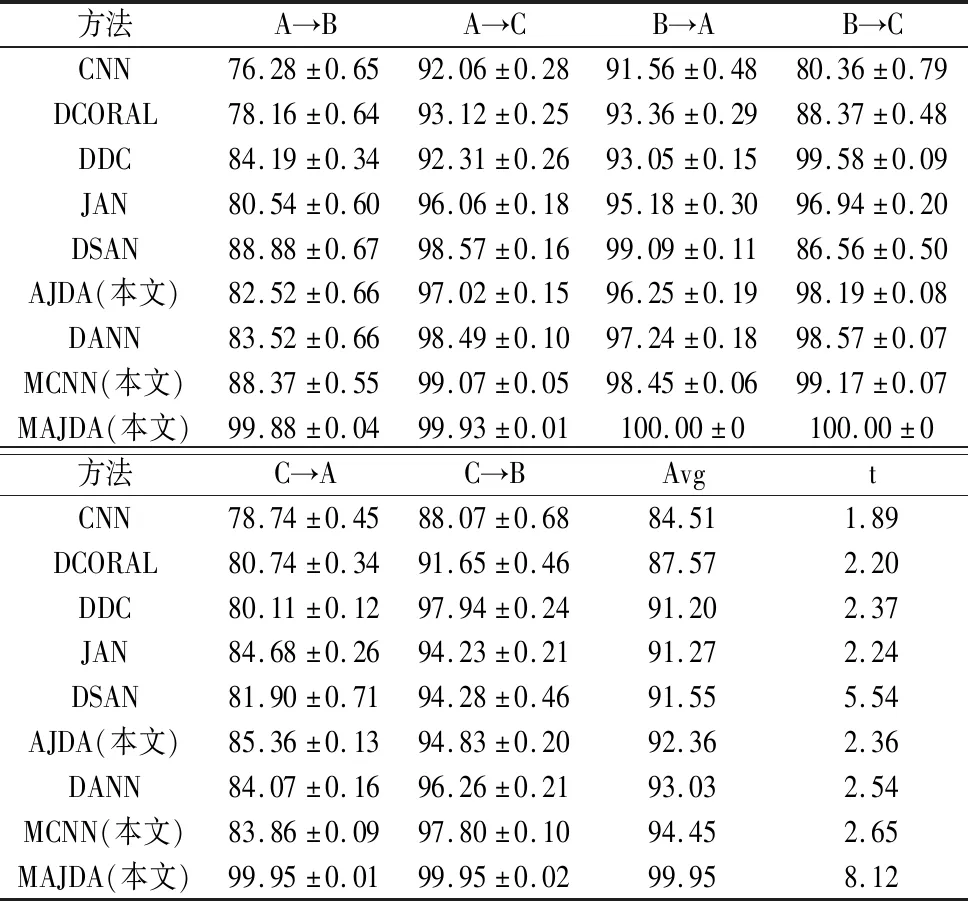
表6 PHM2009齿轮数箱据集目标工况准确率 (%)
3.4 结果分析
(1)目标工况准确率曲线。为分析本文MAJDA效果,每迭代完1个epoch测试一次目标域准确率。因CNN、DCORAL、DANN、JAN与MAJDA分析无关,此处不予讨论。将PHM2009齿轮箱数据集中迁移任务D→E、D→C的目标域准确率曲线绘制如图8所示。DDC为边缘分布对齐,DSAN为条件分布对齐,本文AJDA先边缘分布对齐再条件分布对齐。对于迁移任务D→E如图8a所示,AJDA在第57 epoch时准确率上升变缓,说明边缘分布已大致对齐,此时切换为条件分布对齐,准确率陡增。在第57 epoch之前AJDA和DDC均为边缘分布对齐,由图可见两者曲线全完重合,而之后两者出现明显分叉,且AJDA准确率比DDC和DSAN均高,可见 AJDA实验过程和理论吻合,效果明显。本文MCNN策略和AJDA策略相结合的MAJDA目标域准确率变化过程如绿色曲线所示,在第52 epoch时亦出现陡增点,准确率更高,且收敛更快。对于迁移任务D→C如图8b所示,过程亦如上述分析。综上可见MAJDA实际与理论吻合,且相对于其他方法具有显著优势。
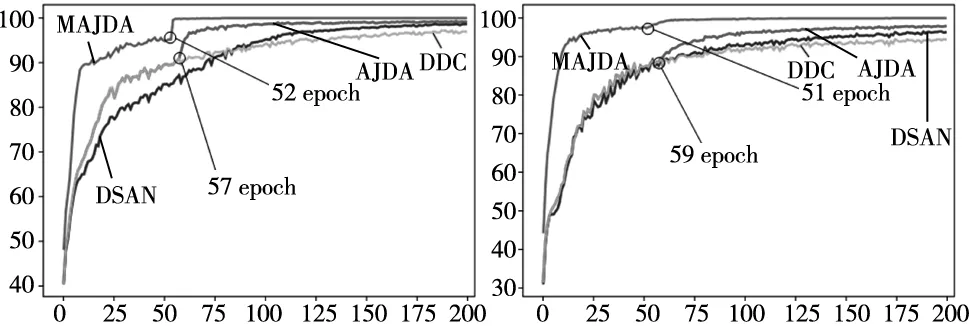
(a) 迁移任务D→E (b) 迁移任务D→C
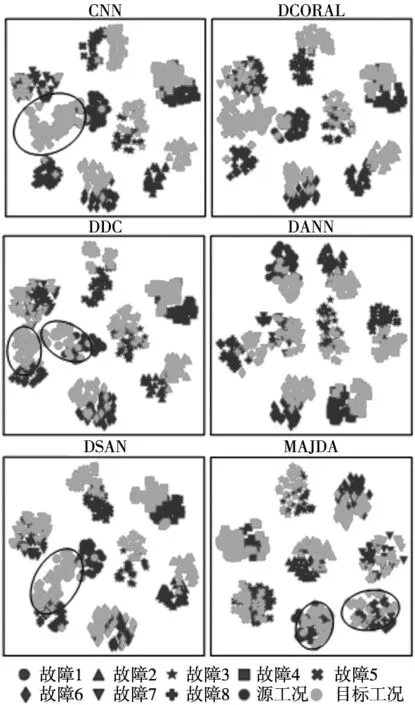
图9 各方法特征对齐效果
(2)特征对齐效果。为分析MAJDA的特征对齐效果,使用t分布-随机邻域嵌入[19](t-SNE)将卷积神经网络提取的特征向量降维至二维空间进行可视化。因MCNN与CNN一样无特征对齐机理,JAN特征对齐机理和DDC相同,故此处无需赘论。对于PHM2009齿轮数据集迁移任务B→C,各特征分布如图9所示。CNN目标域第1、7、8类区分不明显,且各类别分布和源域差别较大。DCORAL、DDC和DANN通过不同方式进行边缘分布对齐,目标域各类别分布和源域有一定重合度。DSAN直接进行条件分布对齐,但由未进行特征对齐的CNN特征图可知目标域第1、8类分布处于源域第1、7、8类分布中间位置,故目标域第1、8类样本伪标签并不准确,直接进行条件分布对齐可能会向错误的类别对齐,同时由DSAN的特征图可知目标域1、8类分布并未与源域对齐。而本文MAJDA对目标域伪标签准确性实行双重保障,进行更精准的条件分布对齐。由DDC特征图可见先进行边缘分布对齐后,源域和目标域条件分布比未进行特征对齐的CNN更接近,故此时再进行条件分布对齐伪标签更准确,由MAJDA特征图可见目标域各类别分布和源域重合度很好。
4 结论
旋转机械跨工况故障诊断常用的域适应方法中,一些方法只考虑边缘分布对齐而目标域条件分布与源域仍有差异,导致准确率不高。另一些方法考虑条件分布对齐但未保障目标域伪标签准确性,导致条件分布对齐效果不好,错误伪标签过多时甚至导致目标域数据向错误的类别对齐,引起严重负迁移,准确率甚至低于边缘分布对齐。针对以上问题本文提出了多尺度异步联合分布对齐MAJDA,进行条件分布对齐之前对伪标签的准确性采取两方面保障。使用本文采集的轴承数据集和PHM2009齿轮箱数据集进行实验验证,可得出以下结论:
(1)多尺度预测器MCNN利用3个不同卷积核尺寸的卷积神经网络提取3种不同尺度特征,分别输入3个分类器,得到3个尺度的伪标签,融合3个伪标签最终得到多尺度伪标签,比单尺度伪标签更准确。
(2)异步联合分布对齐AJDA先利用MMD对源域和目标域特征进行边缘分布对齐,边缘分布对齐后条件分布也更接近,且此时分类器也充分训练,故伪标签更加准确,再利用LMMD进行条件分布对齐。AJDA比边缘分布对齐和直接条件分布对齐效果更好。
(3)多尺度异步联合分布对齐MAJDA一方面利用MCNN获取更准确的多尺度伪标签,一方面利用AJDA确保在进行条件分布对齐前伪标签更准确。对目标域伪标签准确性进行双重保障,实现精确的条件分布对齐,最终跨工况诊断准确率显著高于单方面保障的MCNN和AJDA以及其他域适应方法。
