基于层次密度聚类的去噪自适应混合采样①
2022-11-07姜新盈王舒梵
姜新盈,王舒梵,严 涛
(上海工程技术大学 数理与统计学院,上海 201620)
现实中的很多领域存在的数据集都是不平衡的,这类数据集有着不同类别数据样本不均、数量相差较大的特点,其中大多数样本的类别称为多数类别,其余样本的类别称为少数类别.由于不平衡数据的广泛存在,从不平衡数据中学习对于研究界及现实应用都至关重要,例如疾病诊断[1]和石油储层含油量识别[2]等.任何分类器的目标都是最大程度地提高总体准确性,但是传统分类器往往更倾向于多数类样本,这就导致少数类样本分类错误[3].实际应用中,从不平衡数据中学习到的分类器需要同时在不同类别样本上均表现良好,因此在保证多数类别分类精度的前提下,如何处理不平衡数据以提高少数类别分类准确性.
1 引言
现有的一些广泛处理不平衡数据分类的方法主要分为数据预处理、算法改进及特征选择这3 个层面,当前没有一种方法能够很好地解决所有不平衡数据集分类问题,算法改进仅仅针对单一的分类器进行改进,特征选择容易造成信息丢失,但是数据层面的抽样方法显示了巨大的优越性,该方法主要是改善数据集本身而不是分类器.
欠采样是对多数类样本进行处理,选择一些多数类样本进行剔除以提高少数类样本的分类正确率.Yen等[4]提出SBC 算法,首先将整个数据集聚类,再根据每簇采样数量进行欠采样,但是容易丢失关键信息.过采样是通过合成少数类样本以增加少数类样本的算法,Barua 等[5]提出MWMOTE 算法,先选择少数类样本的适当子集,根据不同类别样本间的距离对少数类样本分配权重,再使用聚类方法并结合SMOTE 算法合成新的少数类样本; Nekooeimehr 等[6]提出自适应半无监督加权过采样,先对少数类样本进行分层聚类,并根据分类复杂度等自适应地对每个子集中靠近边界的少数类样本进行过采样,避免生成与多数类重叠的合成少数类样本.石洪波等[7]研究表明使用单一的采样算法或导致过拟合或误删重要样本,而文献[8]表明混合采样的分类性能比单个采样算法好,在提高运行效率,有效避免过拟合问题的情况下,还不易丢失含有重要信息的多数类样本.戴翔等[9]提出BCS-SK 算法,采用SMOTE 合成少数类样本,然后采用K-means 聚类算法对多数类样本进行欠采样;史明华[10]对整个数据集进行聚类,根据每簇不平衡率的大小将数据集分为4 类并采取不同的采样方法,均衡了簇内的样本分布.
以上算法各具优势,但大部分没有解决类内小分离及易合成低质量样本的问题,也没有区分不同样本的重要性,为解决以上问题,本文提出了基于层次密度聚类的去噪自适应混合采样算法(adaptive denoising hybrid sampling algorithm based on hierarchical density clustering,ADHSBHD)来有效合成高质量样本.
2 相关理论
2.1 HDBSCAN 聚类
HDBSCAN 聚类算法[11]是McInnes 等人研究提出的一种基于层次聚类的最新算法,是对DBSCAN 密度聚类算法的优化,能处理不同密度和任意形状的聚类[12],一方面是不再将Eps值作为树状图的切割线,而是通过查看分裂来压缩树状图,使用该树选择最稳定的簇,并以不同的高度来切割树,这样可以根据簇的稳定性选择密度不同的簇; 另一方面是不再需要人工设置Eps参数,只需要设置集群最小样本数量min_samples来确定样本是离群点还是分裂为两个新集群即可.
相比于K-means、DBSCAN 等常用聚类具有对参数设置不敏感的优势,通常设置两个参数: 最小集群数量min_cluster_size,集群最小样本数量min_samples.此外,HDBSCAN 具有噪声感知能力,-1 表示该样本点不在任何簇内,并且聚类结果会给数据集中的每个样本都赋予一个0.0-1.0 的概率值,用于代表属于某个簇的可能性,概率值为0.0 则表示该样本点不在集群中(所有的离群点都是这个值),概率值为1.0 则表示该样本点位于簇的核心.
2.2 Random-SMOTE 算法
由于SMOTE 算法存在合成样本区域有限、易产生噪声等问题,董燕杰[13]提出Random-SMOTE 算法,可以提高算法效率并更符合原数据集样本空间.该算法的核心思想是根据3 个样本点构成三角区域,在区域内生成新样本,首先从少数类数据集中选择样本x作为根样本,并且随机选择y1、y2这两个样本作为间接样本,根据式(1)在y1、y2间线性插值,根据设置的采样倍率N,生成N个临时样本pj,j=1,2,···,N.
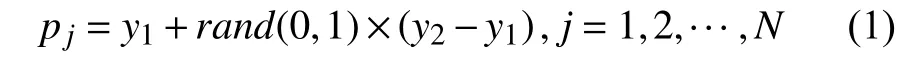
其次根据式(2)在pj和x之间线性插值得到新样本mj.
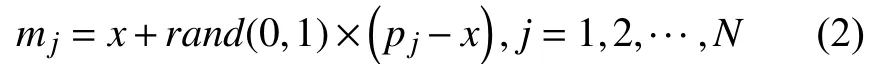
3 ADHSBHD 算法
文献[6]表明,聚类是不错的解决类内不平衡及小分离问题的方法.为了更深入研究解决噪声、类内不平衡和小分离问题,提出了基于层次密度聚类的去噪自适应混合采样算法(ADHSBHD).
3.1 基于HDBSCAN 的去噪方法
在很多情形之下,噪声样本会使分类器性能损失,聚类作为潜在的噪声检测算法,为识别噪声提供了另一研究思路.为了有效识别噪声点,提出了一种基于HDBSCAN 的去噪方法,首先对少数类样本集中的每个样本计算其k近邻,若该样本k近邻全部是多数类样本,则把该样本点视为全局离群点.然后引入HDBSCAN聚类,将少数类样本集进行聚类,得到若干个簇,将概率值为0 的样本视为局部离群点,取全部离群点集和局部离群点集的交集为噪声集,这样可以较全面地识别出噪声点,也避免直接删除处于小分离状态的样本,为接下来提出的ADHSBHD 算法在安全区域内生成样本做准备.
3.2 对少数类样本的处理
若每个簇内都合成同样数量的样本,那么容易造成类重叠,也无益于类内不平衡的解决,因此,在对少数类样本聚类并去除噪声之后,需要根据每簇的密集稀疏程度,确定每个簇所需合成的样本数量,分配给每个簇一个0 到1 的采样权重,这样可以使稀疏区域的样本增添有益信息,密集区域的样本尽可能地减少类重叠,不会忽略对小规模集群的学习.为了表示每簇的密集稀疏程度,用平均距离来表示.
定义1 (平均距离).对于数据集C和少数类样本的任意簇C(1k),1 ≤k≤m,簇C(1k)的平均距离记为Meandist(C(1k)),即:
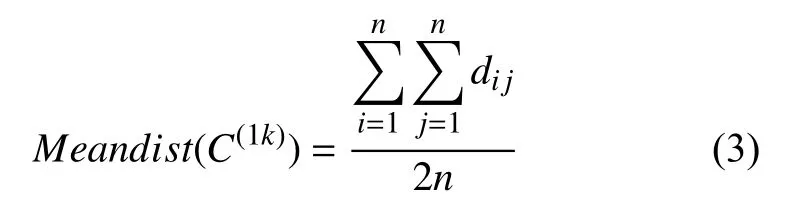
其中,dij为簇内各样本之间的欧式距离,n为簇内样本数量.
定义2 (采样权重).任意簇C(1k),1 ≤k≤m的采样权重为某簇的平均距离与所有簇的平均距离之和的比值,即:
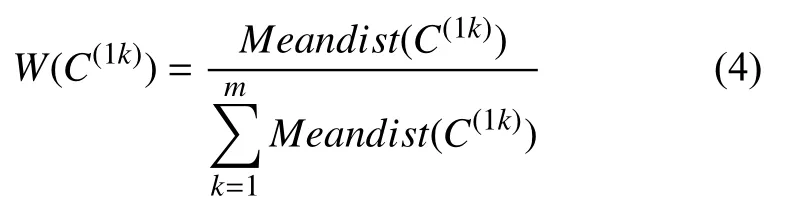
当各簇的平均距离越小时,说明簇内样本更密集,反之,则更稀疏.相应的,簇内样本越密集时,需要合成的样本越少,即采样权重就越小,反之,需要合成的样本就越多.
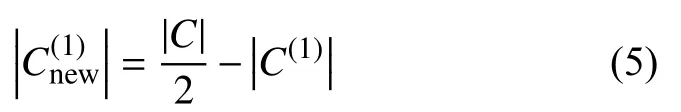
其中,|C|表示原始数据集C的样本数量,表示少数类样本的个数.
每簇C(1k),1 ≤k≤m需要合成的样本数量定义如下:

3.3 对多数类样本的处理
根据HDBSCAN 对多数类样本聚类,得到若干个簇和离群点,相应的得到每个簇的概率值矩阵,当概率值较低时说明样本点越在簇的边缘,过多的边缘样本会使分类器发生偏向而降低少数类的分类精度.为此,将所有多数类样本的概率值按照从小到大的顺序排列,按照一定规则,删减的多数类样本数量定义如下:
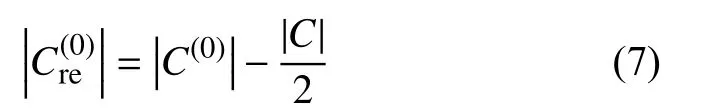
3.4 ADHSBHD 算法流程
ADHSBHD 算法的具体步骤描述如算法1.

算法1.ADHSBHD 算法输入: 原始数据集 ,近邻参数,最小集群数量min_cluster_size,集群最小样本数量min_samples Cnew C k输出: 均衡数据集C(0)C(1)C=C(0)∪C(1)C(0)∪C(1)=Ø Step 1.将原始数据集划分为多数类样本集和少数类样本集且且,并识别噪声.C(1)xkk Nt Step 1.1.计算中各个样本,计算其近邻,若近邻均为多数类样本,则将该添加到全局离群点集 中.C(1)m C(11),C(12),C(13),···,C(1m)pij,0<i≤m,0<j≤■■■C(1i)■■■NlN=Nt∩NlC NC′■■■■C′■■■■=|C|-|N|Step 1.2.用HDBSCAN 对聚类,得到 个相互独立且不同规模的簇和若干个离群点,并且得到每个簇的样本概率值矩阵,而离群点的概率值为0,将其添加到局部离群点集 中,则噪声集群.从原始数据集 中删去噪声集群 ,得到 ,其样本量.for i=1 to■■■C(1i)■■■Step 2.,计算每个簇需要合成的新的样本数量并自适应合成.Step 2.1.计算每个簇中样本之间的欧氏距离,并得到各簇的平均距离.Meandist(C(1k))W(C(1k))Step 2.2.计算每簇的采样权重.■■■■C(1k)new■■■■x Step 2.3.计算每簇新的样本数量,并选中簇内样本做目标样本,从它的近邻中随机选择两个样本 、 ,先通过 、 随机生成一个辅助样本,再在目标样本和辅助样本之间线性插值随机生成新样本,即采用Random-SMOTE 在三角形区域内随机合成样本,将合成样本添加到中,直到新样本数量为.k y1y2y1y2 a x a C(1k)new■■■■C(1k)new■■■■C(1k)C(1k)new Step 2.4.合并每簇的与,各簇原始的少数类样本集与合成样本组成新的数据集中.C(1)new C(0)Step 3.对多数类样本进行处理.C(0)n C(01),C(02),C(03),···,C(0n) t pij,0<i≤n,0<j≤■■■C(0i)■■■Step 3.1.对用HDBSCAN 聚类,得到个相互独立且不同规模的簇和个离群点,并且得到每个簇的样本概率值矩阵.t<■■■C(0)■■■-|C|2C(0)Step 3.2.当时,将中的样本按照概率值从小到大排序,删去离群点和部分概率值小的点,共个样本; 当时,对删除个离群点,剩余的多数类样本添加到新的数据集中.Cnew=C(0)new∪C(1)new Step 4.并对分类器进行训练.■■■C(0)■■■-|C|■■■C(0)■■■-|C|2 t≥■■■C(0)■■■-|C|2 C(0)2 C(0)new
4 实验结果与分析
4.1 评价指标
准确率作为分类器评价指标对于非平衡数据有失公平,为了客观评价分类算法性能好坏,研究学者常常根据混淆矩阵引入的概念来评估算法性能.根据表1的混淆矩阵,引入查全率(Recall)、查准率(Precision)、F-value值、G-mean值、AUC等定义.

表1 混淆矩阵
各定义的公式如下:

此外,AUC作为可视化指标,是根据引入的ROC曲线下的面积来表示,值越大,说明分类器性能越好.ROC曲线则是以真正例率为纵轴,以假正例率为横轴绘制的.
4.2 数据集描述
为了验证ADHSBHD 的有效性,本文从国际机器学习标准库UCI 中选取了Ionosphere、Glass、Abalone、Haberman、Vehicle、Ecoli、Yeast 这7 组不平衡数据集,其中,Glass 的少数类特征为“1”; Abalone 的少数类特征为“F”; Vehicle 数据集中,将第一类视为少数类;Ecoli 的少数类特征为 “om”“omL”和“pp”; Yeast 数据集中将“MIT”视为少数类.7 组数据集的具体信息如表2所示.

表2 数据集信息
4.3 实验分析
为了验证本节所提出的ADHSBHD 算法表现良好,ADHSBHD 算法分别与SMOTE 算法、ADASYN算法、Random-SMOTE 算法(以下简称R-SMOTE)、SVMSOMTE 算法在这7 组数据集上做重采样的对比实验,用F-value、G-mean、AUC作为评价指标,实验环境均在Jupyter Notebook 中运行,所使用的对比算法除R-SMOTE 外均调用imbalanced-learn 程序包实现.
此外,SVM 中核函数为高斯核函数,其他超参数均为imbalanced-learn 中的默认值,为了直观验证上述各对比采样算法的有效性,设置k=5,相应的算法中的其他超参数也均为默认值,而ADHSBHD 算法中使用到的HDBSCAN 算法设置最小集群数量min_cluster_size=2,集群最小样本数量min_samples=4.
表3、表4 和表5 展示了7 组数据集6 种不同采样算法下的F-value值、G-mean值和AUC值以此来衡量算法分类结果,黑体加粗的数值表示同一数据集的最优算法对应指标值,avg 表示不同数据集在不同组合形式的算法下的平均值.从各表中可以看出,虽然对Haberman 数据集使用Random-SMOTE 算法的结果优于本文算法结果,这是由于本文在引入聚类算法后,在如何选择最佳样本参与合成时存在不足,而Random-SMOTE 算法的合成方法更符合Haberman 数据集.但是从整体性能上看,ADHSBHD 算法应用到SVM 分类器后提升了整体分类精度,在F-value、G-mean、AUC这几种性能指标方面均优于文中所提其他4 种对比算法.
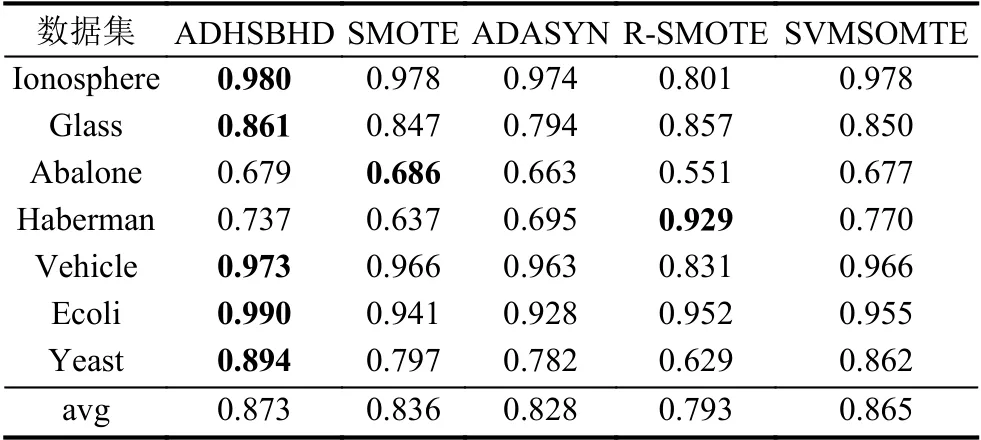
表3 不同数据集在支持向量机下的F-value 性能对比
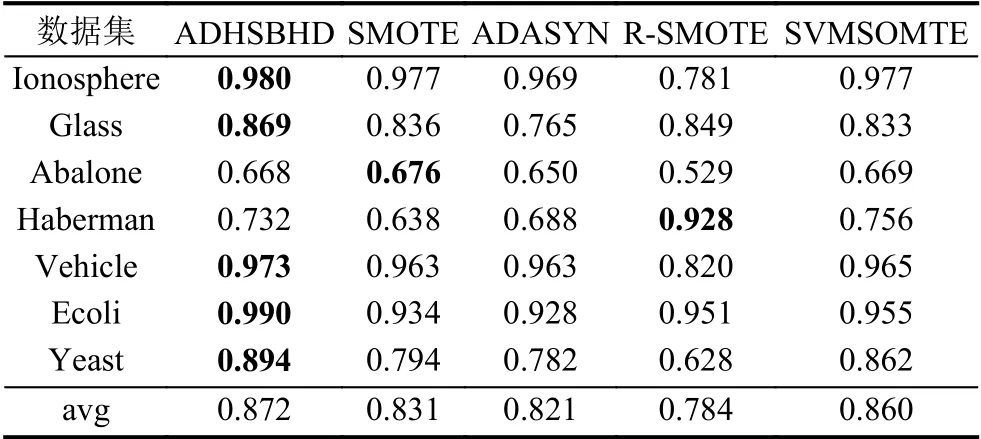
表4 不同数据集在支持向量机下的G-mean 性能对比

表5 不同数据集在支持向量机下的AUC 性能对比
5 结论
本文提出了基于层次密度聚类的去噪自适应混合采样算法(ADHSBHD),以层次密度聚类为基础,考虑到不同类别样本的样本空间分布,为了验证ADHSBHD的有效性及稳定性,将该算法与SVM 分类器结合在一起,并与4 种采样算法进行实验对比,实验结果表明,该算法与不同的分类器的组合有较好的泛化性,Fvalue、G-mean、AUC这3 个评价指标在上述大部分数据集上都有所提升.由于该算法是基于聚类算法展开,后续可以研究其他的聚类技术能否为该算法带来更高性能.
