基于CNN的FaceNet算法人脸图像识别研究
2022-11-05郝林倩
郝林倩
(福建船政交通职业学院 信息与智慧交通学院,福州 350007)
0 引言
人脸识别(Face Recognition),是指对人脸图像进行辨识提取,通过分析比较而获得的人脸视觉特征信息数据,并以此来对个人身份特征进行比对或鉴别的计算机技术。分析可知,该技术属于生物学特性识别算法,迄今为止也已然成为现阶段国内外学者的研究热点,即能够根据人们对自然界中某一种特定生命体(一般特指人)的自身所存在的生物学特性,来实现特征识别以区分特定生物体的个体。
卷积神经网络(Convolutional Neural Networks,CNN)算法是目前人脸图像识别训练中具有可观应用前景的一种深度学习方法。深度学习方法的主要优势就在于能够分析训练大量的人脸数据,并能够快速学到人脸训练中的数据所表现出的人脸特征变化,进而对其他未知情况做出准确可靠的人脸表征识别。这种训练方法通常不需要预先设计出对不同身体类型的类域内的差异因素(比如光照、姿势、面部表情、年龄等)所稳健具备的各种特定运动特征,而是完全可以通过从训练结果数据中学习来得到。
1 传统人脸图像识别算法
1.1 PCA算法
主成分分析方法(Principal Component Analysis,PCA),是一种使用最广泛的数据降维算法。PCA的主要思想是将维特征映射到维上,这个维是全新的正交特征、也被称为主成分,是在原有维特征的基础上重新构造出来的维特征。将2个数据轴各由某一个原本已经给定坐标的坐标系轴中转置至多个新坐标的坐标系轴中,第一个坐标的选择是原始数据中方差最大的,第二个坐标轴选择的是和第一个坐标轴正交、且具有最大方差的方向,重复该过程,重复的次数则为原始数据的特征数。因此大部分方差都在前几个新坐标中,把后面的坐标忽略,如此就完成了数据降维。
PCA在本质上主要是要将方差为最大的正交方向数据作为主要的统计特征,并且要在其各个主要正交方向上将数据写“离相关”,即尽量让数据彼此间在其不同主要正交方向数据上完全没有任何相关性,原理示意如图1所示。
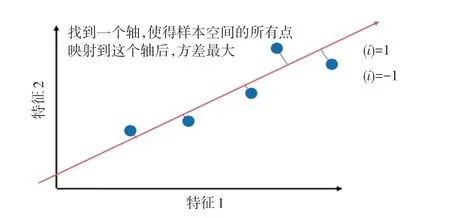
图1 PCA算法原理Fig.1 Principle of PCA algorithm
1.2 LDA算法
线性判别分析(Linear Discriminant Analysis,LDA)算法的思路与PCA类似,都是对图像的整体分析。不同之处在于,PCA是通过确定一组正交基对数据进行降维,而LDA是通过确定一组投影向量使得数据集不同类的数据投影的差别较大、同一类的数据经过投影更加聚合。在统计形式处理上,PCA方法与传统LDA算法的2个最大显著区别即在于,PCA方法中最终能求得结果的特征向量通常是完全正交的,而在LDA方法中求得的结果特征向量就不可能一定全部正交。
利用LDA寻找一个投影向量,使得不同类型的数据点在投影向量所在直线上投影能较好地做出区分,如图2所示。

图2 LDA算法向量投影Fig.2 Vector projection of LDA algorithm
1.3 LBPH算法
局部二进制模式直方图(Local Binary Pattern Histograms,LBPH)人脸识别方法中的技术核心之一就是LBP算子。LBP算子主要是指可以用来分析计算与描述图像局部纹理特征信息关系的一种算子,其最终所能反映到的抽象内容则往往仅仅是描述图像内每个纹理特征像素间与该图像及其周围所有纹理像素间信息的关系。
原始的LBP算子定义为在3*3的窗口内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于或等于中心像素值,则该像素点的位置被标记为1,否则为0。这样,3*3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数、即LBP码,共256种),就得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理特征,也就是图像区域图像中包含的所有图像纹理信息。这里给出的LBP算子计算方式如图3所示。

图3 LBP算子计算方式Fig.3 LBP Operator calculation method
2 深度学习算法
2.1 卷积神经网络介绍和卷积神经网络的网络模型
卷积神经网络(CNN)的优点有:能够将大图片数据量下的图片有效降维成更小图片数据量;可有效保留图片特征,符合图片处理的原则。
多层网络结构及组成用到了神经网络,如图4所示。由图4可知,这是一个常见的多层卷积网络,首先是输入层、然后是隐含层,隐藏层中包括了:卷积层、池化层、全连接层,最后是输出层。对此拟做研究论述如下。
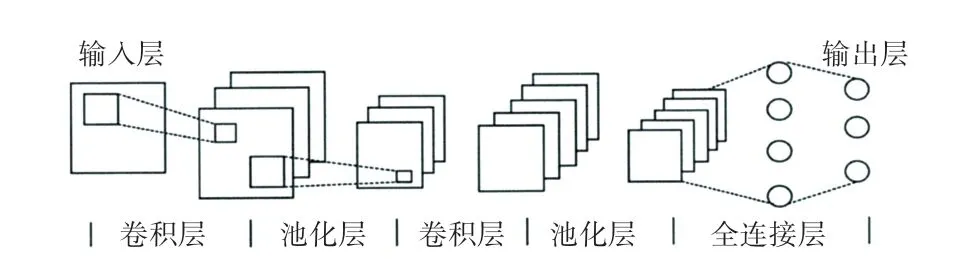
图4 CNN的网络结构Fig.4 Network structure of CNN
卷积网络模型中的图像输入层通常都可以做到只需接收到一组二维对象,卷积网络模型上的一些图像的输入层特征也大多只要预先进行一次图像输入标准化设计和处理即可,例如输入层的输入数据定义为像素,将分布到每个[0,255]像素区间上的所有原始图像的每个像素值都必须归一化地紧致分布在同一个[0,1]像素的区间。输入特征的标准化也更有利于显著提升在卷积网络学习中的学习对象的学习效率水平和学习表现。
卷积网络模型中的隐藏层中一般也包含有卷积层、池化层和全连接层等这3类网络最广泛常见层的构筑,相较于其他任何类型网络,卷积层和池化层结构多是为卷积神经网络模型中所特有。
卷积图层法就是用某一个卷积核函数来遍历出任意的一张图片,而对于卷积图层的一种基本的计算图的输出过程就是要用函数输入每一张图片信息,并把与其中的卷积核函数所对应出的所有元素信息进行相乘处理后,再做求和,这样经过计算输出后的结果就得到了一张较新的计算图(feature map),因此选择一个合适的卷积核,可以突显不同的图像特征。该过程示意如图5所示。

图5 利用卷积核提取特征图Fig.5 Extracting feature maps using convolution kernels
在处理图像时,可以选择多个卷积核,生成不同的图像。这些不同图像可以理解为不同通道,对此可称为多核卷积。
同卷积层结构一样,池化层就是对每次计算输入元素的数据都通过一个池化的窗口元素来完成计算输入元素或输出,如图6所示。不同于一般卷积核层结构的特点是,卷积核层只计算输入元素与卷积核层的互相关性,池化核层可直接完成关于一个池化窗口元素输出的最大值或最小平均值的计算。

图6 池化层计算方法Fig.6 Pooling layer calculation method
全连接层中的所有其他神经元都会与上一层中的所有其他神经元进行全连接,具体如图7所示。同时为了提高网络的整体性能,全连接层中的所有其他神经元通常只会被一个激励函数激活。

图7 全连接网络层的模型Fig.7 Model of fully connected network layer
卷积神经网络图中使用的图像分类输出层中的图像上层一般都是有一个全连接的输出层,对于图像上的分类的标签问题,输出层本身也可以考虑通过使用输出层本身用到的逻辑函数或归一化指数函数(),而后再输出图像的分类上的标签,如图8所示。
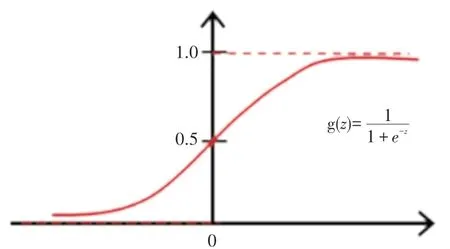
图8 Softmax激活函数Fig.8 Softmax activation function
卷积神经网络图层会在每一个隐含层的神经元中分别提取出这些图像表面上的某些局部特征,并再将其各自映射到下一个平面,技术上是通过使用激励函数来使得所有这些局部特征中的每个映射点都是具有位移性质的完全不变性。每一个神经元都要与局部神经感受野相联系、并建立连接。这样的特征提取过程使得网络对输入的样本有较强的容忍能力,对图像处理也具有非常好的鲁棒性。
2.2 深度可分离卷积
深 度 可 分 离 卷 积 (Depthwise separable convolution)的过程可分为2步。分别是:逐通道卷积(Depthwise Convolution,Dw),逐点卷积(Pointwise Convolution,Pw)。对此可做分析概述如下。
Dw中的一个卷积核负责一个输出通道,一个输入通道也只会由其中的一个卷积核来做卷积,由此得到的计算图(feature map)输出通道需要与输入通道完全一致,即如图9所示。

图9 逐通道卷积的计算Fig.9 Calculation of depthwise convolution
Pw与常规卷积d方法颇为相似,所要求的卷积核面积一般为11,为最上一层的下一层的卷积通道,其中的卷积核数目与计算图(feature map)的数目相同,即如图10所示。

图10 逐点卷积的计算Fig.10 Calculation of pointwise convolution
深度可分卷积的基本假设,是卷积神经网络中特征图的空间维和通道(深度)维是可以解耦(decouple)的。标准的卷积计算使用权重矩阵实现了空间维和通道维特征的联合映射(joint mapping),这样做的代价则是提升了计算复杂度、增加了内存开销,并引入了大量的权重系数计算。理论上,深度可分卷积通过对空间维和通道维分别进行映射、并将结果进行组合,在基本保留卷积核的表征学习(representation learning)能力的同时减少了权重系数的个数。考虑输入和输出通道数的差异,深度可分卷积的权重数约为标准卷积权重数的10%~25%。使用深度可分卷积搭建的一些卷积神经网络、例如Xception,在ImageNet数据集的图像识别任务中的表现要优于隐含层权重相同、但使用标准卷积和Inception模块的Inception v3,因此研究认为深度可分卷积提升了卷积核参数的使用效率。
2.3 Mobilenet v1网络模型
Mobilenet V1是一种流水线的结构,是由深度可分离卷积构建的十分轻量的神经网络,往往会应用在移动的设备端上,因此可以通过超参数对网络模型大小做出限制,使得开发人员能够更好地使用模型。
Mobilenet中的网络结构,则如前面所提到过的卷积层结构中除了第一层为标准卷积层结构外,其他层都是深度可分离卷积结构(Conv dw+Conv/s1),卷积结构的后一层连接了一个7*7的平均池化层,此后再通过一个全连接层,最末端在利用激活函数运算后是将全连接层的输出归一化到0~1中的任意一个概率值,根据概率值的高低可以得到图像的分类情况。对于Mobile的超参数,这里可做剖析详述如下。
(1)为了构造结构更小、且计算量更小的模型宽度因子(Width Multiplier),对于深度可分离卷积层,输入的通道数乘上一个宽度因子,变为,输出通道数变为,其中∈(0,1]。此时深度可分离卷积的参数量为:****(1****),计 算 量 变 为********(1********),所以参数量和计算量差不多都变为原来的*倍。
(2)为了减少计算量,引入了第二个参数,称为分辨率因子。其作用是在每层特征图的大小乘以一定的比例分辨率因子(Resolution Multiplier),改变了输入层的分辨率,所以深度可分离卷积的参数量不变,但计算量为*ρ*ρ***ρ*ρ**(*******),即计算量变为原来的*倍。
2.4 FaceNet算法
FaceNet是可以对人脸识别、验证、聚类等所有人脸问题方法进行系统解决的一个技术框架,如图11所示。即能够把全部特征都放在同一个人脸特征空间里,研究人员只要致力于如何将人脸更好地映射到特征空间中即可。文中对此拟展开阐释分述如下。

图11 FaceNet结构框架Fig.11 FaceNet structural framework
(1)直接学习图像到欧式空间上点的映射,2张图像对应特征的欧式空间上的点的距离直接表示着2张图像是否相似。
(2)总 体 网 络 结 构:基 于GoogLeNet或Zeiler&Fergus模型、CNN+Triplet和loss方法,直接学习从人脸图像到紧凑的欧几里德空间的映射,提取的嵌入特征有助于实现人脸识别、验证和聚类分析等项目任务,训练的损失函数能够直接针对实际误差,端到端训练能得到更高的精度。
(3)嵌入:128维特征,可通过直接使用网络训练优化嵌入本身。而不是像以前中间的瓶颈层的表示,是间接的分类网络。
(4):将正对与负对分开一个距离余量。
(5):半困难三元组样本选择方式。
(6)最小的对齐:面部周围紧密的裁剪。近期研究还尝试进行了相似性变换对齐,并没有注意到这一项设计实际上可以用来进行小幅性能提升,但却也会带来复杂性的额外略增。而其他模型则需要复杂的3D对齐。
(7)人脸相似性验证:用来对2个人脸嵌入空间特征点之间的平方距离进行阈值比较,这2个嵌入特征空间点中人脸的平方距离值直接对应着人脸的相似性,同一人的2个人脸图像仅具有较小的距离值并且与不同人之间的一个人脸图像间具有相当大的距离。
(8)在LFW上有着99.63%的正确率,YouTube Faces上有95.12%的正确率。
3 实验与分析
3.1 实验环境
本次实验中,使用的开发环境是:硬件选用了RAM 16 G、CPU Intel(R)Core(TM)i7-1260P@2.1 GHz 4.7 GHZ,操作系统选用了Windows10,开发测试 软 件 选 用 了pytorch_GPU+python3.8、pychram、Anaconda。
3.2 数据采集与处理
目前,互联网上已有不少采集完备的数据集,可以下载并进行数据清洗和标注,以此来获得本文研究所需的数据集。本次研究中使用的数据集为CASIA-WebFace,该数据集源主要来自于IMBb网站,包含1 w个人的近500 w张图片。与此同时,又通过相似度聚类方法滤掉了其中的一部分噪声。CAISA-WebFace的数据集源和IMDb-Face几乎是完全是一样的,唯一的不同点就是在数据集清洗后,CAISA-WebFace的图片会相对少一些,而且噪声也相对较少,故适合用来作为训练的数据。具体步骤可做阐释如下。
(1)数据标注。通过以下代码,生成对应的文件夹下的图片标签,并写入cls_train.txt文件。


(2)构 建 网 络 并 训 练。通 过 构 建 一 个Mobilenets来进行模型训练,这可能是基于一种超轻量的深度级卷积神经网络,该网络核心部分为深度级可分离的卷积。使用的算法为FaceNet人脸特征识别算法,这个识别算法就是通过抽取人脸图像上的人脸某一层的特征,学习到一个从人脸图像到欧式空间图像的编码识别方法,再基于这个图像编码来做人脸特征识别。下面将给出具体的处理流程。
①构建第一个网络结构。研究中用到的代码如下:

该网络结构可用来加速网络模型的推理速度,通过堆叠网络,第一层为2卷积层、第二层为层、第三层为6激活层,分析可知2和都是线性运算,所以该网络结构融合后就减少了推理时间。
②构建Dw深度可分离卷积网络。研究中用到的代码如下:

这个网络的构建就是深度可分离卷积层的构建方法,用参数来选择。
③构建MobilenetV1模型。研究中用到的代码如下:


通过第一个_层提取特征,此后用的都是_深度卷积。
④用主干特征提取网络获得特征层。研究中用到的代码如下:


经过一个平均池化、一个、再经过一个后,又经过全连接,最后标准化输出一个128的特征向量。
⑤的标准化。在进行标准化运算前一般都会计算范数,对特征向量中的每个元素绝对值取平方和后、再去求其开方,的标准化过程就是先计算出每个元素的范数。此时用到的代码为:

结合使用了和作为一种总体上的,单一使用的可能会导致人脸网络的收敛困难,的则可同时用于2种不同类型人脸特征向量间在欧几里得的空间距离范围上的扩张,同一个人的2个人脸图像的特征向量间的距离由欧几里得缩小。用于人脸分类,加速了的收敛。接下来,可开始进行模型训练,如图12所示。

图12 进行模型训练Fig.12 Conducting model training
3.3 实验结果与分析
选取2张人脸图像,用训练好的模型来对其进行验证,如图13所示。FaceNet的阈值设置为1.1。
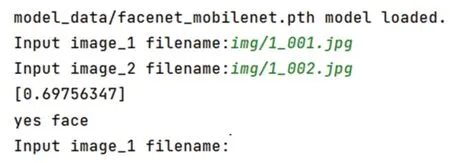
图13 进行图像验证Fig.13 Performing images verification
通过FaceNet预测显示为0.698,比预测前设置的阈值小,所以是同一张人脸,如图14所示。

图14 相同人脸预测Fig.14 Same face prediction
再选取2张人脸图像,通过FaceNet预测显示为1.337,超出预测前设置的阈值,所以是不同的人脸,如图15所示。

图15 不同人脸预测Fig.15 Different face prediction
4 结束语
本文对已有的CASIA-WebFace数据集进行数据清洗和标注,以获得所需的训练数据,而后通过构建一个Mobilenets,来进行模型训练,并采用CNN算法,通过FaceNet预测显示的值与事先设置的阈值对比情况,验证人脸图像特征,从而达到人脸识别的目的。仿真结果表明,该算法在人脸识别方面取得了较好的效果。
