基于改进人工神经网络的大数据聚类方法研究
2022-11-04吕立新
吕立新,江 宏
(1.安徽商贸职业技术学院 信息与人工智能学院,安徽 芜湖 241000;2.菲律宾科技大学 工程技术学院,菲律宾 马尼拉 0900)
互联网技术为各领域发展带来海量信息数据,也增加了各行业有价值数据提取的难度,因此需要一种快速、精准识别信息类别的数据聚类方法方便数据整合。人工神经网络(Artificial Neural Network,ANN)是一种非线性复杂网络系统,包含大规模接近于生物神经元的处理单元,这些单元以相互连接方式组成人工神经网络[1]。ANN自提出以来被智能算法研究领域专家所青睐,广泛应用于复杂智能信息处理分析。BP(Back Propagation)神经网络是采用反向传播策略进行信息处理的人工神经网络结构,以其鲁棒性强、自学习能力优、自组织效果佳等特征,高性能实现了大规模数据聚类研究[2-3]。BP神经网络适应能力强,但也避免不了面对海量样本数据时的误差,为此,使用粒子群算法(Particle Swarm Optimization,PSO)与遗传算法(Genetic Algorithm,GA)对BP神经网络实施优化,以确定网络最佳的初始权值与阈值,提高BP神经网络在数据聚类中的精度。
1 基于GA-PSO-BP神经网络的数据聚类方法
1.1 BP神经网络结构定义
反向传播(BP)算法是人工神经网络在实际工作中采用较为广泛的一种,属于一种监督学习算法范畴,其特别之处在于“反向传播”[4],反向传播过程如下:在学习过程中通过给定的输入样本和输出样本,预先计算神经网络输出层的输出值,求取该值与数据分类标签间的误差,基于误差值对神经网络各层的权重与偏置等参数展开反向更新进行网络训练。输入层、输出层、隐含层是BP神经网络的主要结构构成。
粒子群算法结合遗传算法优化BP神经网络的原理如下[5]:首先将神经网络的输出误差作为粒子群的适应度函数,适应度函数用于评价粒子优劣;其次利用遗传算法对粒子群进行交叉变异操作,更新粒子速度与位置信息,获得最优的粒子位置信息最优解即群体极值;最后将最优解作为BP神经网络的初始权值与阈值,展开BP神经网络训练与数据挖掘测试。
1.2 基于遗传粒子群的BP神经网络优化
1)粒子群优化算法。在d维空间中展开最优解搜索,搜索粒子数量定义为N,粒子获得全局极值与个体极值的情况下采样公式(1)与公式(2)更新速度与位置信息:
(1)
(2)
公式中,i=1,2,…,N;第i个粒子的第d个速度分量、位置分量分别采用vid、xid表示;个体极值与全局极值分别采用Pbestid、gbestd描述,前者为第i个粒子的最优位置信息,后者表示全局粒子最优位置信息;另外,迭代系数与惯性权重因子用k、w表示;c1、c2分别表示学习因子,r1、r2是随机数,在[0,1]之间取值。
2)遗传算法。遗传算法利用其选择、交叉、变异操作在空间内获得最优解,以优化粒子群的速度与位置信息,使其获得最优粒子位置最优解[5],作为BP神经网络的初始最优权值与阈值,达到优化构建人工神经网络的目的。遗传算法优化粒子群信息的过程为:
Step 1:确定初始种群与编码策略。种群规模在多次测试中确定;定义BP神经网络输入神经元数量为n,输出层、隐含层神经元数量分别为k、h,那么编码长度计算方法见公式(3):
L=n×h+h×k+h+k
(3)
Step 2:确定适应度函数。基于BP神经网络的真实输出值与期望输出值确定适应度函数[6],公式(4)为该次遗传算法使用的适应度函数:
(4)
其中,数据挖掘训练样本数量为n;第i个数据挖掘训练样本的真实输出和期望输出分别利用Gi、Bi描述。
Step 3:确定选择算子。基于轮盘赌策略的选择算子表达式如下:
(5)
其中,fi表示第i个个体适应度。公式(5)计算了第i个个体留下来的可能性。
Step 4:确定交叉与遗传算子。遗传算法的交叉策略和变异策略分别如公式(6)与公式(7)所示:
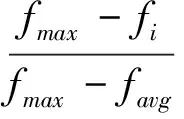
0.35 fi(6)
ω′=ω+λ(θ-0.5)Emax
(7)
公式中,α是基本编码组合系数,第i个群体在父代种群内的适应度值为fi,父代种群内个体的适应度均值与最大值分别采用favg、fmax描述。父代种群内个体适应度最大个体的误差均方值为Emax,θ是随机数,取值区间为[0,1],变异因子为λ,变异操作前后BP神经网络的权值与阈值分别采用ω、ω′表示。该研究使用的变异算子同选择算子的融合一定程度上解决了提前收敛问题[7]。
1.3 基于粒子群与遗传算法的BP神经网络优化流程
首先对带聚类的样本格式进行处理,成为适应改进人工神经网络输入的样本格式;然后基于该改进策略对BP神经网络权值与阈值寻优,构建高精度的人工神经网络聚类模型。图1为基于GA-PSO-BP神经网络的数据挖掘流程。
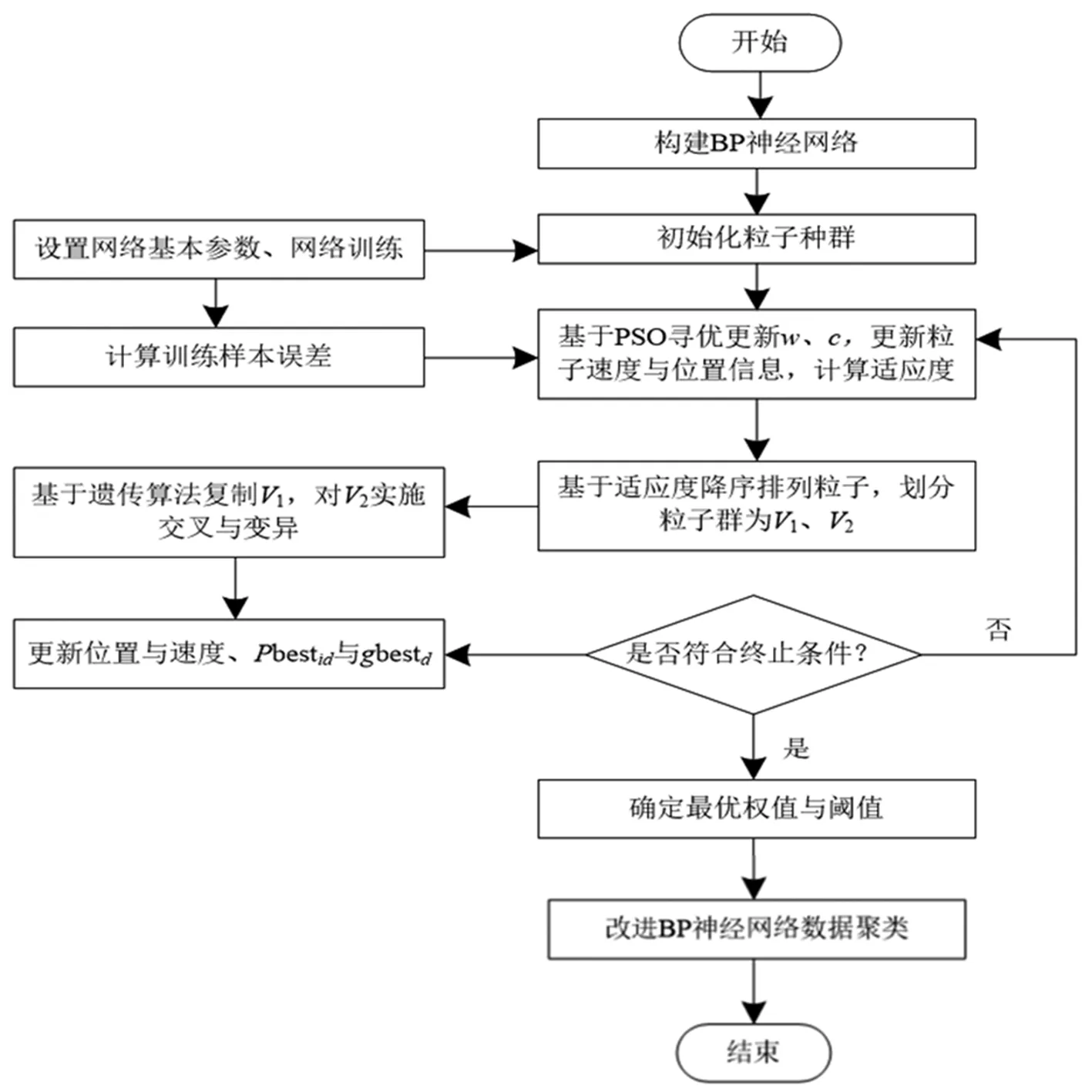
图1 基于GA-PSO-BP神经网络的数据挖掘流程
结合图1分析GA-PSO-BP神经网络的数据挖掘步骤:第一步,为BP神经网络定义基础性参数,对粒子群算法优化对象变量的数量进行选择,初始化粒子种群,动态化更新惯性权重因子、学习因子、粒子的速度信息、位置信息;第二步,计算粒子的适应度值,适应度值即为BP神经网络训练产生的误差;第三步,基于适应度值降序排列粒子的顺序,将种群划分为V1、V2两个类别[8],前者是适应度值较大的粒子、后者为适应度值较小的粒子,复制V1并对V2进行交叉与变异操作,以这种方式使粒子的位置与速度信息得到更新;第四步,循环迭代改进的BP神经网络,符合终止条件时将最优的权值与阈值输出,改进BP神经网络利用优化后的最优权值与阈值进行数据聚类仿真。
2 实验与分析
仿真实验基于 Matlab 软件以验证GA-PSO-BP数据聚类方法的优越性。将GA-BP 聚类算法和 PSO-BP聚类算法作为该文大数据样本聚类的对比方法。在电商企业获取6个品类的商品信息数据作为训练与测试样本,信息内容包括规格信息、样式、颜色、数量、批发价格、零售价格等,该实验的目的是对电子商务交易过程产生的信息进行有序分类。3种人工神经网络利用相同的数据样本进行训练与测试,从6个品类信息中各选取30组数据构成规模为180组的训练样本集,另外选择120组数据进行模型验证。

图2 GA-PSO-BP神经网络误差趋势图
为了客观体现GA-PSO-BP数据聚类方法的聚类效果,将其对商品信息聚类的训练误差、测试误差、误差最优值同时进行对比,GA-PSO-BP数据聚类方法产生的各种误差走势如图2所示。
由图2可知,GA-PSO-BP数据聚类方法训练过程与测试过程、验证过程产生的误差差值较小,曲线接近,说明其误差波动性小、鲁棒性优,是一种较为可靠的BP神经网络模型。表1为3种方法聚类商品信息的精准度统计结果。

表1 3种BP神经网络模型聚类商品信息的精准度 单位:%
数据显示,随着样本数量的增加,GA-PSO-BP数据聚类方法的聚类精度没有降低反而有提升的趋势,说明利用粒子群与遗传算法改进的BP神经网络模型的权值与阈值实现了最优,提升了网络学习商品分类特征的能力,进而保证了理想的商品信息聚类精度。GA-BP 聚类算法与PSO-BP聚类算法聚类效果与GA-PSO-BP数据聚类方法略有差距,因为对比方法仅使用了遗传算法或者粒子群算法其中一种优化确定BP神经网络的初始权值与阈值,具有片面性,虽然也对BP神经网络模型构建产生积极影响,却没有实现人工神经网络最优聚类。
3 结论
该文结合粒子群优化算法与遗传算法对BP神经网络进行优化,遗传算法通过交叉与变异确定粒子的最优位置信息,粒子群将BP神经网络的误差作为适应度,因此粒子群输出的最优位置信息即为网络最佳权值与阈值。在测试环节,GA- PSO-BP数据聚类方法由于结合了粒子群寻优优势,又利用遗传算法的交叉与变异功能获得粒子的最优位置信息,为粒子群获得全局最优解提供了保障,促使数据聚类结果更具可靠性。
(6)
ω′=ω+λ(θ-0.5)Emax
(7)
公式中,α是基本编码组合系数,第i个群体在父代种群内的适应度值为fi,父代种群内个体的适应度均值与最大值分别采用favg、fmax描述。父代种群内个体适应度最大个体的误差均方值为Emax,θ是随机数,取值区间为[0,1],变异因子为λ,变异操作前后BP神经网络的权值与阈值分别采用ω、ω′表示。该研究使用的变异算子同选择算子的融合一定程度上解决了提前收敛问题[7]。
1.3 基于粒子群与遗传算法的BP神经网络优化流程
首先对带聚类的样本格式进行处理,成为适应改进人工神经网络输入的样本格式;然后基于该改进策略对BP神经网络权值与阈值寻优,构建高精度的人工神经网络聚类模型。图1为基于GA-PSO-BP神经网络的数据挖掘流程。
图1 基于GA-PSO-BP神经网络的数据挖掘流程
结合图1分析GA-PSO-BP神经网络的数据挖掘步骤:第一步,为BP神经网络定义基础性参数,对粒子群算法优化对象变量的数量进行选择,初始化粒子种群,动态化更新惯性权重因子、学习因子、粒子的速度信息、位置信息;第二步,计算粒子的适应度值,适应度值即为BP神经网络训练产生的误差;第三步,基于适应度值降序排列粒子的顺序,将种群划分为V1、V2两个类别[8],前者是适应度值较大的粒子、后者为适应度值较小的粒子,复制V1并对V2进行交叉与变异操作,以这种方式使粒子的位置与速度信息得到更新;第四步,循环迭代改进的BP神经网络,符合终止条件时将最优的权值与阈值输出,改进BP神经网络利用优化后的最优权值与阈值进行数据聚类仿真。
2 实验与分析
仿真实验基于 Matlab 软件以验证GA-PSO-BP数据聚类方法的优越性。将GA-BP 聚类算法和 PSO-BP聚类算法作为该文大数据样本聚类的对比方法。在电商企业获取6个品类的商品信息数据作为训练与测试样本,信息内容包括规格信息、样式、颜色、数量、批发价格、零售价格等,该实验的目的是对电子商务交易过程产生的信息进行有序分类。3种人工神经网络利用相同的数据样本进行训练与测试,从6个品类信息中各选取30组数据构成规模为180组的训练样本集,另外选择120组数据进行模型验证。
图2 GA-PSO-BP神经网络误差趋势图
为了客观体现GA-PSO-BP数据聚类方法的聚类效果,将其对商品信息聚类的训练误差、测试误差、误差最优值同时进行对比,GA-PSO-BP数据聚类方法产生的各种误差走势如图2所示。
由图2可知,GA-PSO-BP数据聚类方法训练过程与测试过程、验证过程产生的误差差值较小,曲线接近,说明其误差波动性小、鲁棒性优,是一种较为可靠的BP神经网络模型。表1为3种方法聚类商品信息的精准度统计结果。
表1 3种BP神经网络模型聚类商品信息的精准度 单位:%
数据显示,随着样本数量的增加,GA-PSO-BP数据聚类方法的聚类精度没有降低反而有提升的趋势,说明利用粒子群与遗传算法改进的BP神经网络模型的权值与阈值实现了最优,提升了网络学习商品分类特征的能力,进而保证了理想的商品信息聚类精度。GA-BP 聚类算法与PSO-BP聚类算法聚类效果与GA-PSO-BP数据聚类方法略有差距,因为对比方法仅使用了遗传算法或者粒子群算法其中一种优化确定BP神经网络的初始权值与阈值,具有片面性,虽然也对BP神经网络模型构建产生积极影响,却没有实现人工神经网络最优聚类。
3 结论
该文结合粒子群优化算法与遗传算法对BP神经网络进行优化,遗传算法通过交叉与变异确定粒子的最优位置信息,粒子群将BP神经网络的误差作为适应度,因此粒子群输出的最优位置信息即为网络最佳权值与阈值。在测试环节,GA- PSO-BP数据聚类方法由于结合了粒子群寻优优势,又利用遗传算法的交叉与变异功能获得粒子的最优位置信息,为粒子群获得全局最优解提供了保障,促使数据聚类结果更具可靠性。
