MPANet-YOLOv5:多路径聚合网络复杂海域目标检测
2022-11-03王文亮李延祥张一帆韩鹏刘识灏
王文亮,李延祥,张一帆,韩鹏,刘识灏
[中船(浙江)海洋科技有限公司,浙江舟山316000]
经济全球化的不断发展使海上运输需求迅猛上升,随着船只数量日益增长,海上航行的安全性备受人们关注.船舶智能化的快速发展进一步提高了海上航行的安全性,其视觉感知系统能够实时获取周围船舶及障碍信息.近年来,深度学习技术被广泛用于目标检测领域,这进一步提升了船舶视觉感知系统的信息获取能力.
深度学习目标检测算法包括以Faster RCNN[1,2]为代表的两阶段算法和以YOLO[3-6]系列为代表的单阶段目标检测算法.由于YOLO 系列算法在保证较高精度的同时具有明显的实时性优势,因此被广泛部署于实时目标检测项目中.YOLOv5作为YOLO系列最新的研究成果,其检测速度和精度都达到了SOTA 水准.然而,在海上目标实时检测中往往伴随其他问题,如:小目标集群、船只密集且类型复杂、海面大雾影响造成目标模糊等,这些问题使得检测海域具有较高的复杂性,同时对YOLOv5 的小目标检测能力及分类能力有了更高的要求.在实际部署中发现YOLOv5 算法在复杂环境海域海面实时目标检测应用中仍需进一步改进.
针对YOLO 算法的改进方案层出不穷,在船舶目标检测中改进方法主要包括数据增强[7]、多尺度[8]、特征融合[9]与添加注意力机制[10]等.受海上船舶检测数据集的限制,现有改进方案仅在较小数据集上进行训练并不能进行实际部署.因此,本文通过收集东海、南海部分航线图像构建了大型船舶检测数据集,提出了多路径聚合网络结构通过融合多层特征以增强模型多尺度定位能力,同时结合SimAM[10]注意力模块和Transformer[11]结构增强高阶特征语义信息.在自定义船舶数据集上实验结果表明:MPANet-YOLOv5 模型在增加少量参数的情况下明显提升了海上目标检测能力,取得了良好的效果.
1 YOLOv5概述
YOLOv5 模型共包含四个版本YOLOv5s、YOLOv5m、YOLOv5l 和YOLOv5x,模型参数和性能依次提升.YOLOv5依旧延续Input、Backbone、Neck 和Head输出的网络结构,其结构如图1所示.
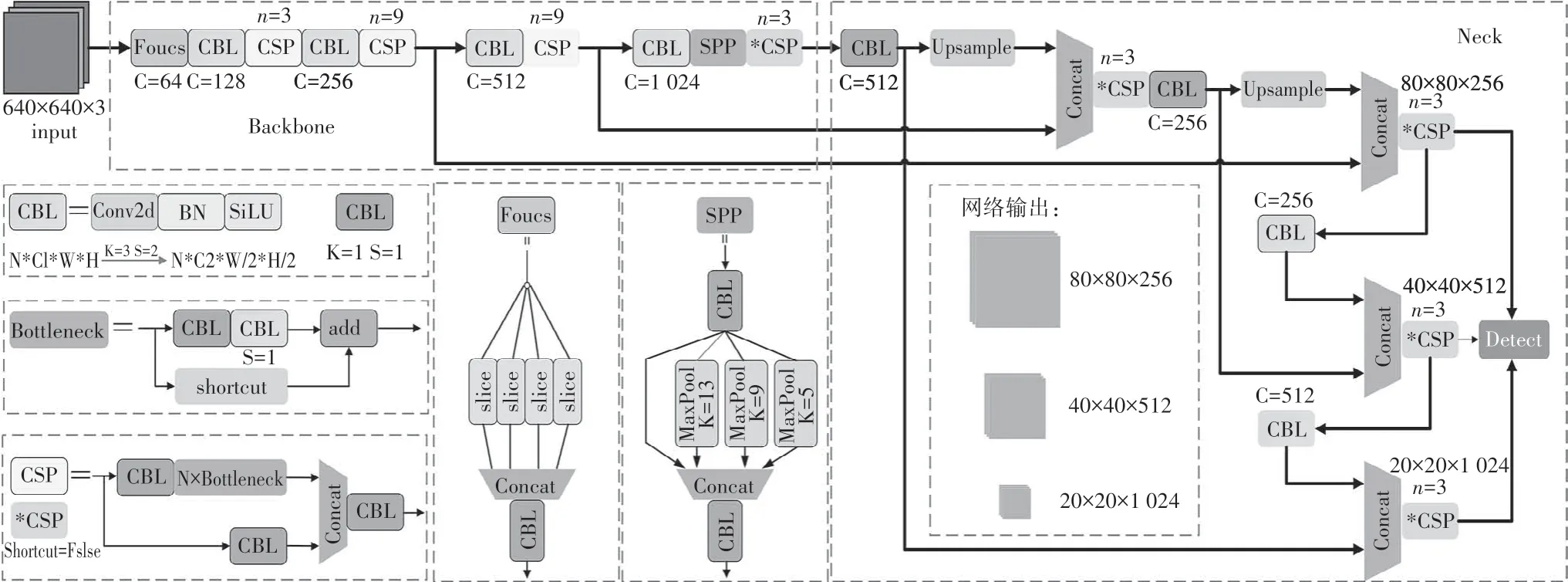
图1 YOLOv5网络结构Fig.1 YOLOv5 Network Structure
YOLOv5s 是YOLOv5 系列中最小的模型结构,模型宽度和深度分别为0.33 m 和0.5 m,YOLOv5m、YOLOv5l 以及YOLOv5x 在YOLOv5s 模型基础上不断加深加宽.在数据输入端YOLOv5模型延续了YOLOv4 中的mosaic 数据增强方法,该方法将四张图片进行随机裁剪拼接至一张图像中作为训练数据,使输入端同时获得四张图片的信息,一方面丰富了图像背景信息,另一方面也减少了模型对Batch Size 的依赖.YOLOv5 的另一个特点是放弃了设定固定长宽初始锚框的思想,提出了自适应锚框,根据训练集的差异自适应计算最佳锚框数值.在Backbone 中,YOLOv5主要用到了Focus结构、SPP和CSP结构.
Focus 结构主要是将输入图像进行切片操作,增加特征通道数并减小特征尺寸,减少了FLOPs(Floating Point Operations Per second),提升了运算速度,并且减少了模型层数.CSP 网络结构由CBL 模块、Bottleneck 模块和Concat 结构组成.其中CBL 模块由Conv、Batch Normalization[11]、SiLu[12]激活函数构成.Bottleneck 模块包含CBL 模块和残差连接[13],每个CSP 结构中包含n个Bottleneck 模块,并且CSP 模块可通过设置是否使用残差连接生成两种不同的CSP结构.CSP 将输入特征分为不同分支,分别进行卷积使得特征通道数减半,其中一个分支进行Bottleneck操作,经过Concat 将两个分支特征合并,增加特征图信息.SPP[14](空间金字塔池化)使用多个最大池化操作,对于不同的输入特征SPP 结构都产生固定大小的输出.在YOLOv5 中SPP 采用[5,9,13]三个尺度特征与输入特征进行融合,SPP 处理结果进一步提升了不同尺度和长宽比输入图像的尺度不变性.
2 注意力机制
众所周知,卷积神经网络一直是计算机视觉任务中的主要方法,通过设计不同的网络结构和局部连接以丰富特征信息进而提升图像识别的性能,如全连接网络-FCN[15]、区域生成网络-RPN[1]、残差网络-Resnet[14]、级联网络-Cascade R-CNN[16]、特征金字塔网络-FPN[17]、空间金字塔池化-SPP[14]等在大规模图像识别项目中都获得了很好的效果.但卷积神经网络中往往通过增加网络深度提高卷积神经网络的表示能力,在模型中大量的模块堆叠使得网络结构十分庞大.与网络堆叠不同,注意力机制基于视觉感知过程,聚焦全局和局部特征,在减少网络参数的同时增强了图像特征信息.
作为注意力机制的代表著作,SENet[18]从全局获取上下文信息,显式地构建特征通道之间的相互依赖关系,输出结果逆向完成在通道维度上对原始特征的重新标定.ECANet[19]通过对SENet 模块进行改进,提出了一种不降维的局部跨信道交互策略和自适应选择一维卷积核大小的方法实现了性能提升.SENet 在设计中并未引入空间维度进行特征融合,CBAM[20]注意力机制在此基础上沿通道、空间两个维度推断注意力,通过将注意力图与输入特征图融合以进行自适应特征优化.同时,还有一些其他的注意力机制,如多谱通道压缩注意力方法-频域注意力网络FcaNet[21]、位置像素注意力模块-Non-local[22]、CCNet[23]、双重注意力机制-DANet[24]等.但以上注意力方法只能生成1-D 或2-D 注意力权重,这在一定程度上限制了注意力权重在通道和空间中的灵活性.Yang[25]等提出了一种即插即用的三维权重注意力模块SimAM,能够直接评估特征的三维注意力权重,基于神经科学理论在已有的空间抑制理论的基础上,为每个神经元设计了能量函数评估其重要性.
值得一提的是,Vaswani[26]等创造性提出的Transformer 机制在自然语言处理领域取得的巨大成功,吸引人们开始尝试将其应用于计算机视觉任务中.主要的应用方向包括:1)将自注意力机制与CNN架构结合[22,27],如Zhu 等[28]提出CABM 注意力机制与Transformer 检测头结合的YOLOv5 模型改进方法,在无人机捕获场景的目标检测中表现出良好的性能;Dai[29]等提出动态检测框架,采用多种注意力机制相结合的方法提升了目标检测头的表示能力.2)使用自注意力机制完全替代卷积结构[30-31],如多头注意力机制[32-33]、稀疏Transformer[34]和分层Transformer[35].
本文根据第一种思想将SimAM 注意力模块和Transformer融入YOLOv5网络,并提出多路径聚合网络以提升YOLOv5 复杂海域目标检测和多目标分类能力.复杂海域目标检测及目标分类面临的主要问题如图2 所示.图中(a)、(b)包含大量的小目标对象,并且呈现集群式分布;(c)、(d)图像为受海雾影响的海面目标;(e)、(f)包含了多种船只类型和部分小目标对象.


图2 复杂海域目标信息Fig.2 Complex sea object information
3 多路径聚合YOLOv5网络
3.1 多路径聚合网络(MPANet)
神经网络中特征信息的流动方式对结果影响明显,因为低层特征拥有精确的定位信息,高层特征拥有较强的语义信息.低层特征在向顶层特征传播过程中将会越来越难以获取准确的定位信息,而小目标信息随着特征传播将会逐渐丢失.特征金字塔网络(FPN)[36]通过自顶向下的横向连接方式丰富了每一层的特征信息,并在自顶向下传播过程中给出每一级的预测.FPN 结构解决了目标检测中多尺度变化的问题,在小目标识别能力上有明显提升.PANet[37]在FPN 网络结构基础上增加了自底向上的网络结构,保留横向连接的同时添加了路径增强和聚合,缩短了低层特征向顶层特征的传播路径,增强了低层特征传递能力,保留了精确的位置信息.
研究结果表明,特征融合的方法能够明显提升特征的分类能力[38].基于此,我们在PANet 基础上对YOLOv5 结构进行改进,我们继承了YOLOv5 主干网络的同时增加了多路径聚合.每一个顶层特征都通过融合三个不同路径特征产生,本文称之为多路径聚合网络(MPANet),如图3所示.图中(a)和(b)部分是自顶向下的网络结构,通过横向连接进行特征融合.(c)部分是自底向上的网络结构,保持横向连接同时聚合低层特征,特征上传过程中给出每层特征的预测结果(d).MPANet 保持自顶向下过程中的横向连接,使用多路径聚合方式将低层特征、中间特征与顶层特征相互融合,进一步丰富特征上下文信息并提升多尺度定位能力,保证顶层特征具有丰富语义信息的同时拥有精确的定位信息.从图4 中可以看出,MPANet在顶层特征中聚合了三个不同路径的特征信息,在研究中,我们巧妙地设计了网络结构使这些特征拥有相同的尺寸和不同的通道数,融合特征通过1×1 卷积后输入检测网络.MPANet 中仍然保留三个检测头部,检测头部特征属性与YOLOv5 保持一致,检测尺寸与通道数分别为[256,512,1 024]和[80,40,20].
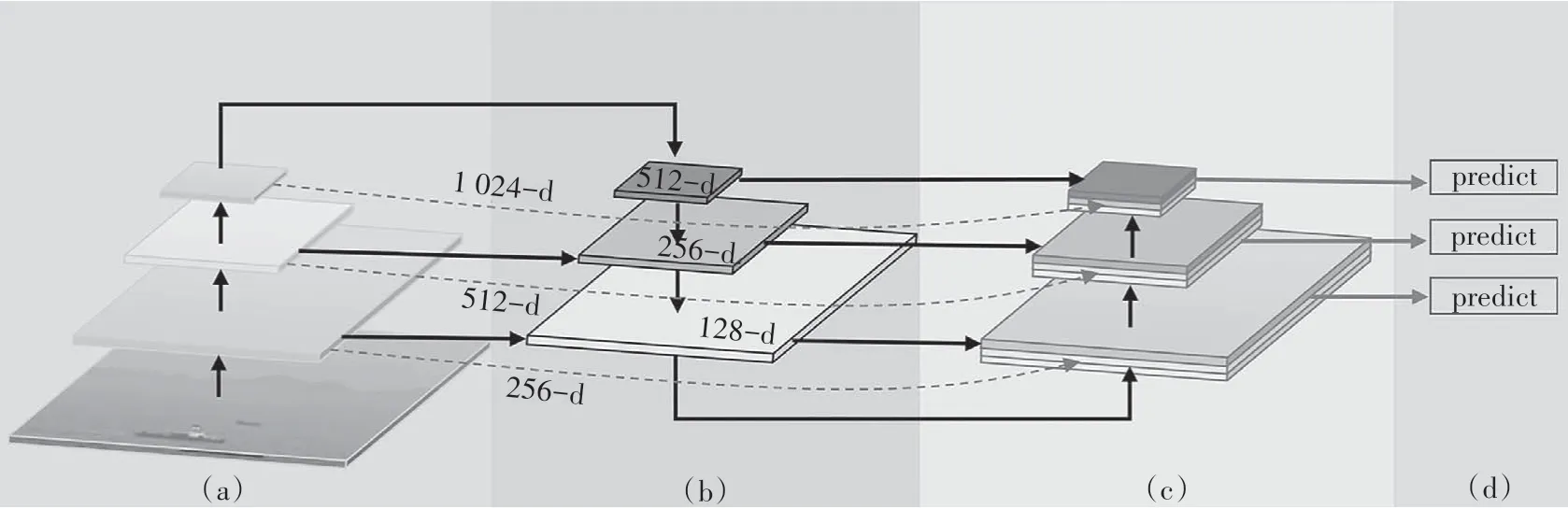
图3 MPANetFig.3 MPANet
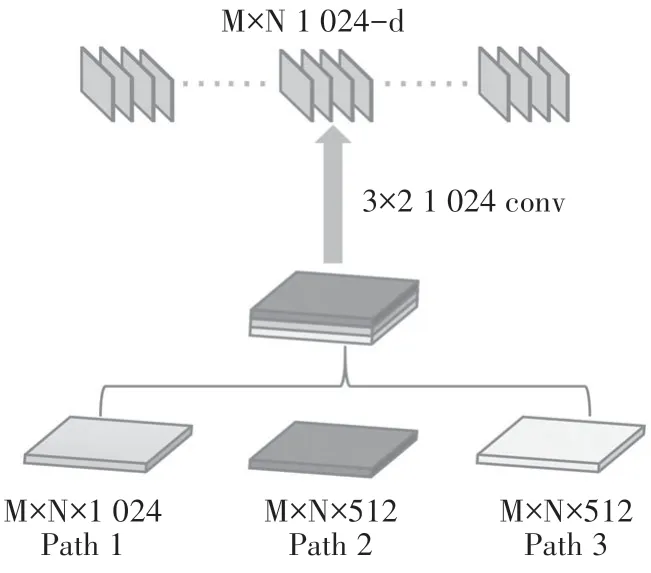
图4 顶层特征多路径聚合Fig.4 Top-level feature multi-path aggregation
在MPANet-YOLOv5中,我们使用了在目标检测中效果更好的Mish[39]激活函数,如图5所示.Mish激活函数是一个非单调、有下界、无上界、正则化的平滑激活函数,它允许一部分负梯度流入保证信息流动,非单调平滑的特性保证了梯度下降效果较好.
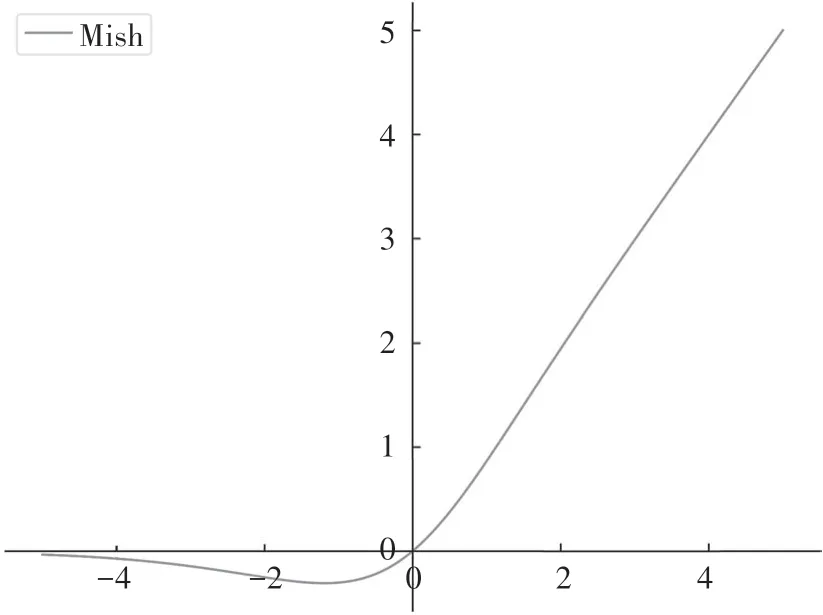
图5 Mish激活函数Fig.5 Mish activation function
3.2 MPANet-YOLOv5
我们将多路径聚合网络融入YOLOv5 结构中,并在网络不同阶段添加了SimAM和Transformer注意力模块.SimAM是一个三维权重注意力模块,能够直接评估三维注意力权重,如图6所示.SimAM基于神经科学理论在已有的空间抑制理论的基础上,为每个神经元设计了能量函数评估其重要性.能量函数定义如下:
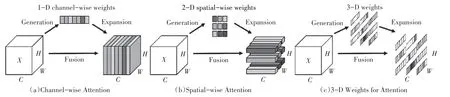
图6 不同注意力机制比较Fig.6 Comparison of different attention mechanisms
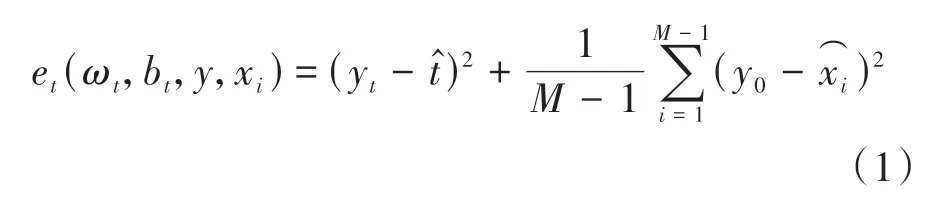

式中:E将所有跨通道和空间维度分组,Sigmoid 用来限制E中过大的值.
在MPA-YOLOv5 模型中我们设计SimAM 模块在自底向上过程中计算三维注意力权重,这有利于在多路径聚合时提供更丰富的特征信息.
Transformer Encoder Block 为自注意力机制.Transformer 在目标检测领域已经有很多的应用,在本次实验中我们引入Transformer encoder 在多路径聚合之前对特征进一步优化.Transformer encoder(图7)能够捕获全局信息和丰富的上下文信息.作为多路径之一,Transformer encoder 的输出特征对多路径特征聚合结果具有正向增强作用.在本文中所使用的Transformer encoder block 包含一个多头注意力层和一个MLP 层.多头注意力机制能够使模型在不同的表示子空间学习到相关信息[26],而MLP 能够阻止输出退化,增强自注意力机制的表达能力[40].
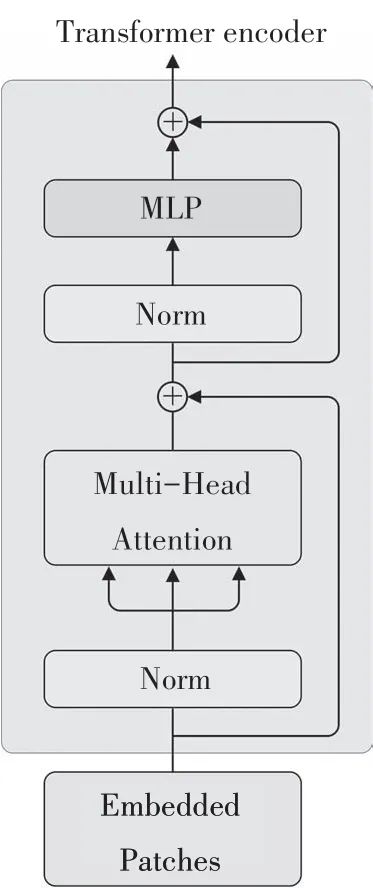
图7 Transformer 编码器结构Fig.7 Transformer encoder structure
MPA-YOLOv5 在主干网络中依然继承YOLOv5的网络设计,在主干网络之后使用SPP 固定输出尺寸,并将特征提取网络的高层特征输入Transformer中进一步增强特征信息.在Neck 部分我们只使用了1×1的卷积结构用于降低图像通道数,并在每个上采样之后使用CSP 进一步提取特征信息.上采样的特征经过SimAM注意力模块生成三维注意力权重并传递至Transformer 模块.SimAM 注意力模块主要添加在至自底向上的特征传递过程中并保持横向连接,同时聚合低层特征信息进行特征融合.
多路径聚合过程中我们使用低层、中层和顶层三个层级的特征信息进行融合,三个路径特征尺寸相同,通道数不同,通过多路径聚合可得到预测所需特征.多路径聚合一方面保证了融合后特征信息具有定位信息和语义信息,另一方面缩短了低层次特征向顶层特征传递的距离.
在检测头部分依然保持[20,40,80]三个尺寸的特征输出并与自适应锚点匹配.添加SimAM 注意力模块与Transformer 的MPANet-YOLOv5 网络结构如图8所示.
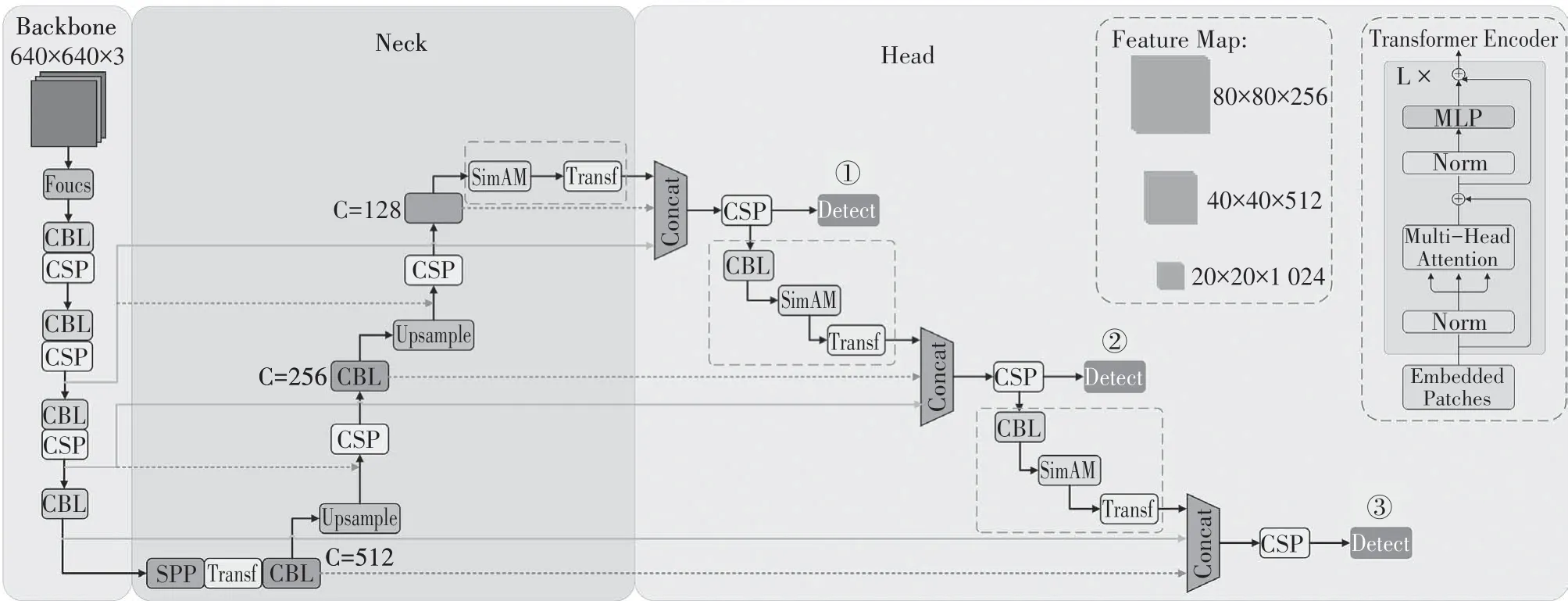
图8 MPANet-YOLOv5网络结构Fig.8 MPANet-YOLOv5 network structure
4 实 验
本次研究采集了复杂场景下海面图像,以船舶作为主要的海上目标建立了自定义船舶检测数据集,并使用该数据集进行模型训练和测试.数据集包含五种目标类型(货船、集装箱船、渔船、游轮、岛屿)共计5 380 张图片,训练集和测试集分别占80%和20%,在训练过程中使用640×640尺寸作为输入.
本文所有模型都在2 张TITAN RTX 2080TI 24G GPU 上训练和测试,MPANet-YOLOv5 基于Pytorch 1.9 深度学习框架.在对比实验中将MPANet-YOLOv5 与YOLOv3、YOLOv4、YOLOv5、YOLOv5-SPPF 和YOLOv5-Transformer 算法进行对比,所有模型均设置300 次迭代.通过模型测试结果可以发现:YOLOv5-Transformer 仅在Backbone 中添加Transformer 后模型计算量有所下降,模型性能与基础YOLOv5 模型相比平均精度上升了1.4%,召回率降低了1%,AP0.5与AP0.5:0.95有微弱下降,分别降低了0.2%和0.5%.YOLOv5-SPPF 使用卷积替换Focus 结构,结合SPPF 使模型计算量下降了0.6GFLOPs,精度提升了1%.MPANet-YOLOv5 结果优于所有的对比模型,与YOLOv3 相比,我们的模型精度提升了8.2%,召回率提升了1.2%,AP0.5与AP0.5:0.95分别提升了4.9%和3.8%.与YOLOv4 模型相比,MPANet-YOLOv5 精 度提升了3.6%,召回率提升了3.8%,AP0.5与AP0.5:0.95分别提升了3%和1.9%.MPANet-YOLOv5 与YOLOv5模型测试性能相比,AP 提升了5.4%,召回率提升了3.3%,AP0.5与AP0.5:0.95分别提升了3.3%和2.2%.可以发现,MPANet-YOLOv5 在性能表现上大幅领先,特别是与YOLOv5 模型相比有明显提升.各模型具体测试结果如表1所示.

表1 模型测试结果对比Tab.1 Comparison of model test results
在实际检测中,MPANet-YOLOv5小目标检测效果突出,在发生遮挡时也能准确地检测出目标类型.两种模型检测结果如图9所示.

图9 模型小目标检测结果对比Fig.9 Comparison of model small target detection results
在研究中,我们分别在东海和南海通过两种不同方法对MPANet-YOLOv5 复杂海域目标检测效果进行测试.1)在固定海域搭建检测站,对多条航线目标实时检测;2)通过在固定航线航行,获取航线上图像进行目标检测.两种测试结果如图10、图11所示.

图10 东海固定检测站点目标检测结果Fig.10 East China Sea fixed detection site object detection results

图11 南海固定航线目标检测结果Fig.11 South China Sea fixed route object detection results
5 结论
本文提出了一种基于注意力机制的多路径聚合网络结构MPANet-YOLOv5,以提升YOLOv5 在复杂海域的目标检测与分类能力.实验结果表明:使用多路径聚合网络将带有定位信息的低层特征与高层语义特征融合增强了多尺度定位能力,丰富了顶层特征语义信息和上下文信息,有效提升了YOLOv5 复杂海域目标检测精度,特别是在小目标检测方面有明显的提升.事实证明:MPANet-YOLOv5 在复杂海域场景中目标检测性能优于YOLOv3、YOLOv4、YOLOv5及其变体,是一种可靠的海上目标检测算法.
