广域级电网在运智能电能表的烧损故障关联分析和预测方法
2022-11-03谈丛黄红桥陈石东李恺解玉满刘谋海
谈丛,黄红桥,陈石东,李恺,解玉满,刘谋海
[1.国网湖南省电力有限公司供电服务中心(计量中心),湖南长沙 410004;2.智能电气量测与应用技术湖南省重点实验室,湖南长沙410004]
智能电能表目前已经在我国实现了大面积覆盖,智能电能表的发展为人们生活带来了很多便利,但受智能电能表安装施工工艺、运行年限、运行环境以及用电负荷等因素的影响,智能电能表烧表的现象时有发生,由此造成的停电以及表箱或线路火灾给用电的安全以及便利带来了诸多风险,给供电企业造成了较大损失.以某省份数据为例,2019—2020年,每年共有数万件的烧表事故,由此带来的经济效益损失与社会效益损失巨大,建立一种能提前预测烧表的方法或者模型,成为行业内的一种迫切的需求.
由于电能表烧损是一种偶发现象,且引发烧表的因素多种多样,基层供电服务员工的运维水平、接线材料、电能表运行环境等多重因素都可能导致烧表,这些因素通常不可直接对其进行量化表示,基于以上困难,业界未曾对烧表建立起一种普遍可行的预测机制.
近年来,与智能电能表配套发展的用电信息采集系统不断完善,积累了大量智能电能表的运行数据,通过对这些数据的挖掘和分析,构造烧表特征模型,成为破解烧表预测模型的一种可能[1-2].
目前,国内外学者针对电能表运行中的故障提出了多种预测和分析方法,对于解决烧表问题具有一定的借鉴意义.文献[3]提出的智能电能表故障类型分类和预测模型,主要基于Bayes Network,模型主要考虑了电能表产品特征数据,采用了基于评分搜索的方法构建Bayes Network 结构,构建了电能表故障预测模型,但该模型并未使用智能电能表的运行数据,评价的维度不够全面.文献[4]提出了智能表故障风险预估算法,针对智能电表的首检数据进行筛查,将筛查结果划分为四个风险等级,但评价模型只应用了智能电表的首检数据,没有全面利用智能电表的产品特征数据和电气运行数据,模型的评价也不够全面.文献[5]提出了一种多分类集成树模型,首先利用聚类方法实现了数据的预处理和维度的压缩,从数据预处理的角度克服了不平衡数据集在机器学习过程中的弊端,本模型在数据预处理方面取得了较大的进展,但由于没有引入电气运行数据,预测精度较低.文献[6]设计了基于梯度提升决策树(Gradient Boosting Decision Tree,GBDT)的故障大类、故障小类以及设备寿命周期的预测,但使用的数据维度较少,仅限于部分到货批次信息以及气候数据信息.文献[7]提出了一种多分类融合模型的智能电表故障预测算法,通过传统的欠采样和过采样相结合的方式解决了数据集中类不平衡问题,但欠采样和过采样都引入了较大随机因素,传统的欠采样会导致样本信息的缺失,传统的过采样可能会导致过拟合.文献[8]提出了一种智能电表故障多分类方法,主要针对现有算法无法实现标签值与概率值的基类模型融合问题,但该方法选取的特征均为静态变量,对电能表使用过程中的变化无法进行监测,无法解释故障的偶发性.文献[9]设计了一种基于深度信念网络对计量装置故障溯源的方法,使用卷积神经网络对历史电流、功率曲线序列进行了特征提取,实现了异常电能表的故障溯源,该方法既使用了电能表的产品批次信息,也利用了运行电气数据,虽然未对烧表问题进行研究,但具有较好的借鉴作用.文献[10]提出了一种智能电能表异常数据检测方法,能够对窃电用户和异常设备进行在线监测,能够提升供电公司的线损指标,该方法侧重于研究电能表数据异常,但对于电能表故障的研究不够深入.文献[11]设计了基于智能电能表运行故障数据的纵向分析模型,可以对不同厂家、不同批次的智能电能表的故障率随时间的变化进行分析,该方法也是侧重于利用电能表产品信息进行建模,没能对电能表运行数据进行分析.文献[12]提出了一种基于条件变分自编码器-卷积神经网络模型的不平衡多分类方法,将类标签作为约束条件,搭建由全连接层构成的CAVE网络生成少数类样本,学习各类分布特点和数据集全局特征,提高生成数据质量,对于解决数据不平衡问题,可以借鉴该方法.文献[13]提出了一种基于LSTM的电力负荷预测方法,该方法能够有效预测电力负荷数据,对于电能表的运行缺失数据,可以借鉴该方法,对缺失值进行填充.
GBDT 的基本算法思路是将弱分类器进行线性组合后得到强分类器[14],在训练的过程中,GBDT 能够根据上一轮的结果,迭代更新梯度的方向,使得模型能够以最大的速率向误差不断减小的方向进化[15-16].
XGBoost 算法在GBDT 的基础上进行了优化,能够根据计算机CPU 的运行情况进行多线程的并行计算;同时还能在一定程度上提高泛化能力,将单决策树模型的复杂度作为正则化的优化目标;在公式推导中引入了二阶导数,准确率更高,不易过拟合[17].
为了构建电能表烧损故障关联分析和预测模型,本文研究思路如下:
1)结合某省供电公司部分电能表的产品信息等静态数据和电能表的历史运行数据,进行烧损关联性分析,使用XGBoost 模型对包含“烧表”和“不烧表”的二分类数据集进行训练,形成算法模型.
2)使用XGBoost 算法模型进行交叉验证测试,并与KNN、SVM 和Naive Bayes 等传统机器学习算法进行对比,以观察XGBoost 算法对实验准确度的提升是否有影响.
3)将模型进行系统部署,以某省供电公司所有在运的电能表为数据源,针对缺失的运行数据,使用LSTM 算法对其进行预测并填充,构建完整的测试集数据,验证模型运行的实际效果.
1 电能表多维数据统计与分析
1.1 数据源
某省公司计量中心拆回分拣实验室从2019 年开始对退出运行的电能表进行集中回收处置,对因烧坏而退出运行的电能表进行了逐块记录,形成了烧表原始数据集.数据集包括已烧坏电能表所在市州、生产厂家、安装时间、运行时间、所在台区近年历史烧表数量以及退出运行前的每日电量、电压和电流数据,所在台区每日线损数据共形成了22 567 条烧表信息记录.同时,在用电信息采集系统选取185 710块正常运行的电能表的同样维度的数据,形成了未烧表数据集.
1.2 数据统计与分析
1)根据历史统计结果,不同市州的表计烧表率有较大的区别,全省14 个市州的年烧表率范围大致为0.2%~0.5%,将各市州属性按风险程度等级进行分类,赋予不同的标签,如表1所示.

表1 市州属性风险程度等级分类Tab.1 Risk degree classification of different cities
2)根据历史统计结果,不同生产厂家的表计烧表率有较大的区别,运行在全省的电能表所属厂家共有78 家,不同厂家2020—2021 年平均每年的烧表率范围大致为0~1%,将各生产厂家属性按风险程度等级进行分类,赋予不同的标签,如表2所示.
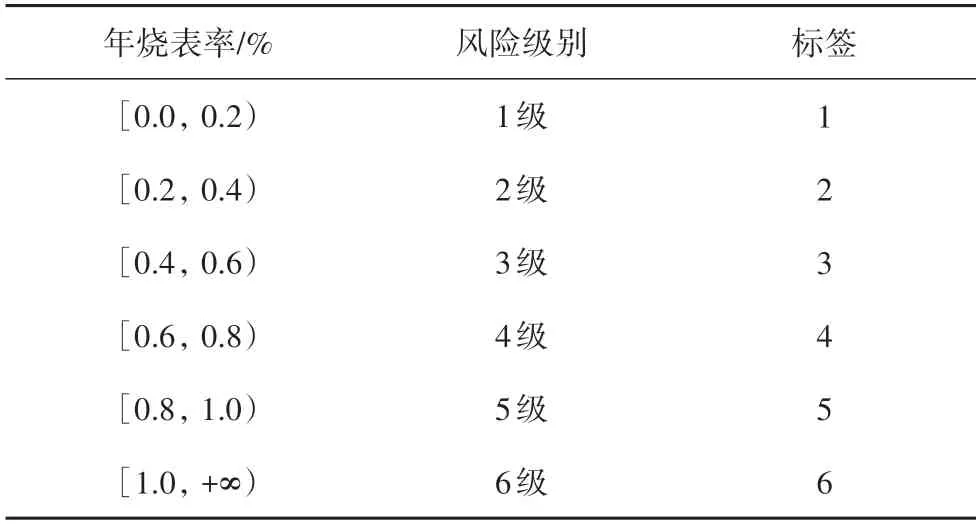
表2 生产厂家属性风险程度等级分类Tab.2 Risk degree classification of different manufacturers
3)根据统计结果,不同安装年份的烧表率有着明显差异,如图1 所示,安装时间在2013 年到2018年电能表烧损居多,占总烧表数量的74.16%.
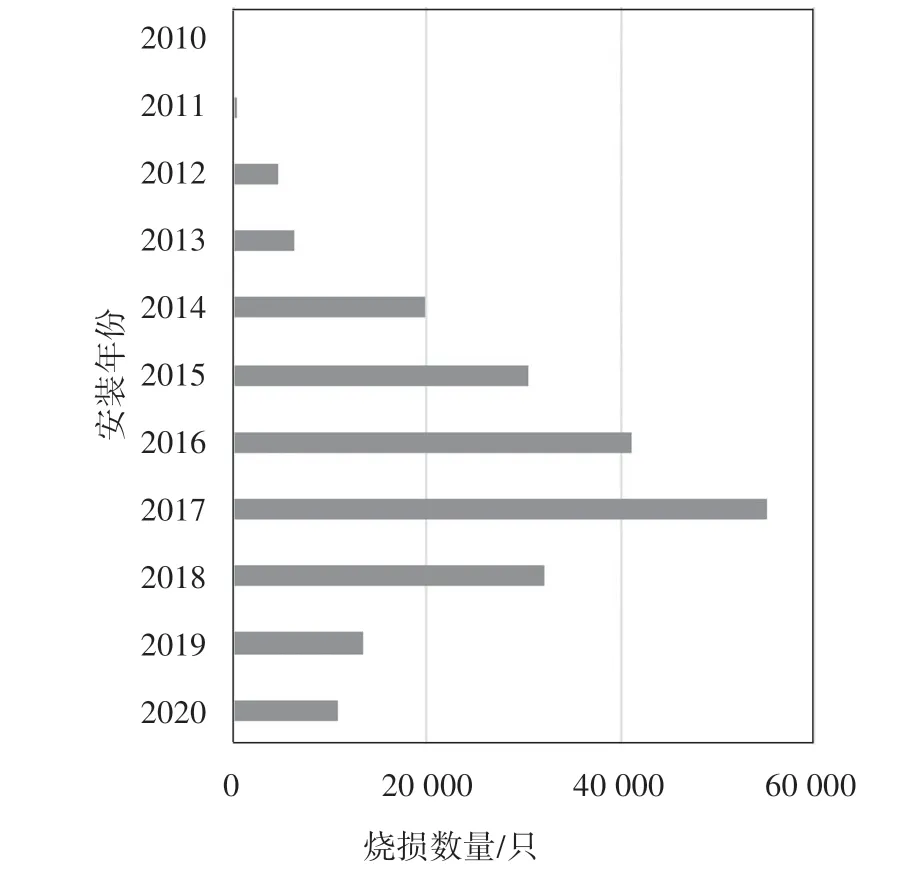
图1 不同安装年份烧损电能表数量Fig.1 Number of burned smart meters in different installation years
4)根据统计结果,每年不同的月份烧表率也有着明显的差异,以某城市为例,2019—2021年夏季月平均气温每升高1 ℃,月烧表数量增加约719 块;2019—2021年冬季月相对湿度每下降1%,烧表数量增加约108块.
5)根据统计结果,在烧表前一段时间内,每日电量、每日最大电压和最大电流会有不同程度的突变的现象.
6)根据统计结果,存在一部分烧表会导致电能表“表码”出现异常,会影响其所在台区的线损.
7)根据统计结果,电能表运行终码越大,其烧损的概率更高,终码在一定程度上能够表示电能表内元器件工作运行的实际时长.
8)根据统计结果,台区历史烧表数量,表示电能表所在台区上一自然年的总烧表数量,该数据能够在一定程度上反映出该台区的运维水平.
2 算法原理
XGBoost 算法是是基于GBDT 改进而来的,它采用了GBDT 的生成算法和梯度提升思想,并进行了相应的提升,使得算法效果进一步得到提高[18-21].
对于样本属性集合x={x1,x2,…,xN}和样本标签组合y={y1,y2,…,yN},XGBoost 算法包括K棵树的加法模型为:
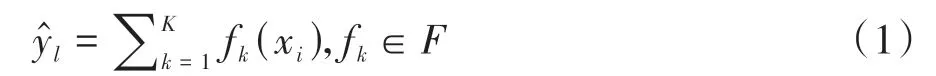
式中:fk为基类模型的目标函数;F为对应基类模型组成的函数空间.
目标函数计算公式为:
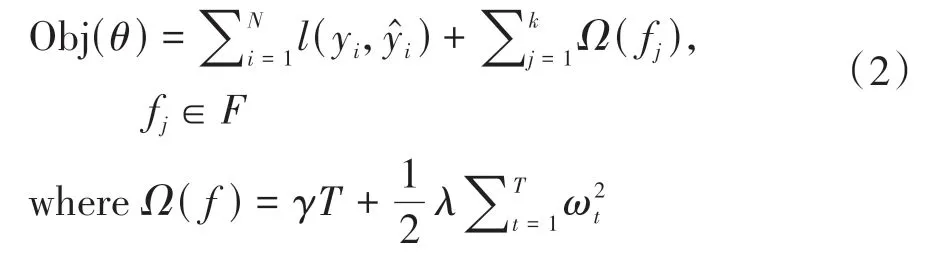
式中:l(yi,)表示真实值与预测值之间的误差;T表示叶子节点总数;ωt表示第t个叶子节点的分数;γ和λ表示L1和L2正则化系数.

为了极小化目标函数,XGBoost直接基于目标函数进行二阶泰勒展开.


继续简化,得目标函数为:
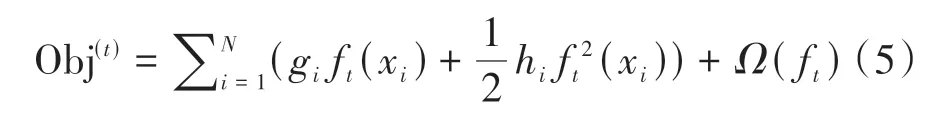
找到最优分裂节点的步骤如下:
1)每个叶子节点j上包含的样本集合Ij={i|q(xi=j)},为了进一步简化,目标函数可以改成如下形式:
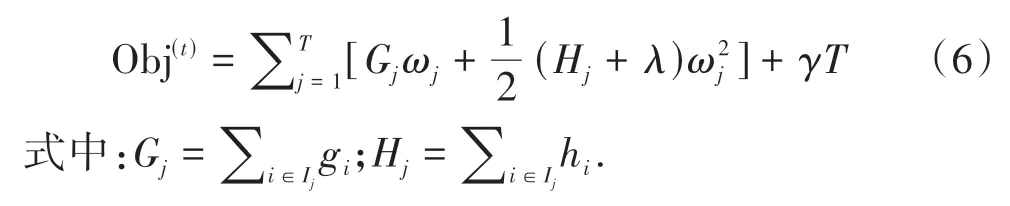
2)为使目标函数得到最优解,对ω进行求导,使导数为0,得ωj=
代入式(6)得:
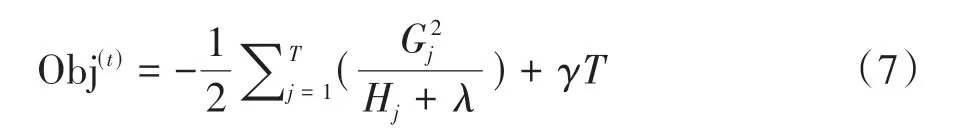
3)最优的分裂节点能够使信息增益G最大.G的计算方式如下:
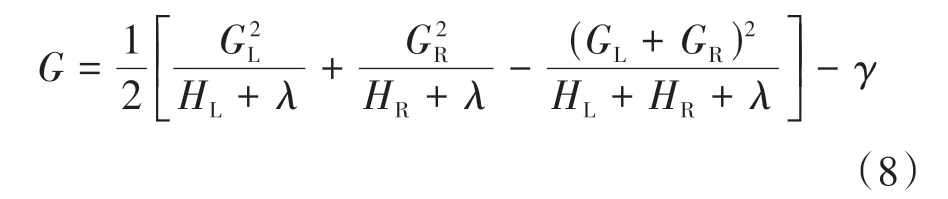
式中:HL和HR分别为目标函数在分裂后左、右节点的一阶导数之和;GL和GR分别为目标函数在分裂后左、右节点目标函数的二阶导数之和.
3 实验流程
经过分析,电能表烧损可能与多个因素存在关联性,为了对电能表的烧损建立统一的分析模型,选取电能表所在市州、生产厂家、安装时间、运行时间、所在台区2020—2021 年历史烧表数量以及退出运行前30 d 的每日电量数据,每日最大电压和最大电流数据,所在台区每日线损数据作为特征,结合XGBoost模型的特点进行实验分析.
3.1 参数调优
XGBoost模型包含多个参数,按照一般的调参顺序,先从框架参数开始进行调参:
1)“booster”:由于本课题涉及的特征数量较多,选择树模型;
2)“objective”:本课题研究属于分类问题,选择softmax分类器;
3)“n_estimators”:XGBoost算法是由若干个弱分类器组合而成,在一定程度上,弱分类器的数量越多,分类的准确度越高.为了找到最优参数,保持其他参数为默认参数,进行实验,结果如图2 所示,XGBoost 算法的识别正确率在迭代700 次时达到最高点,之后逐渐降低.
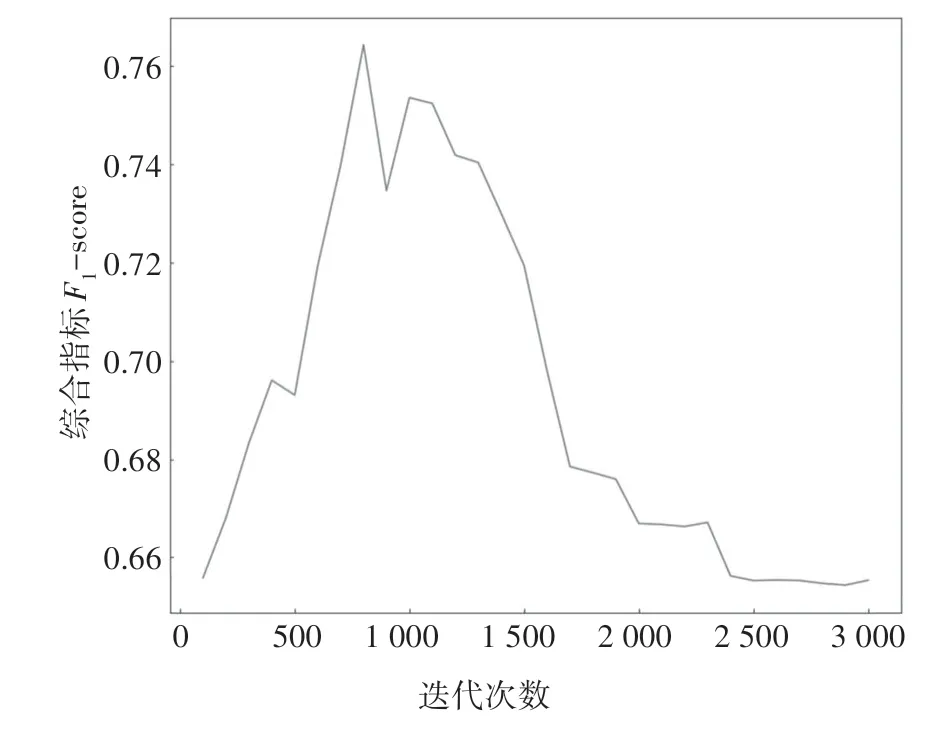
图2 不同迭代次数时模型的F1-scoreFig.2 F1-score of the algorithm at different estimators
然后,开始调节弱学习器的参数:
4)“max_depth”:固定XGBoost 算法的迭代次数为700 次,尝试采用不同树的高度,观察实验结果与树的高度关系.实验结果如图3 所示,当树的高度分别为2、4、6、8、10、12 时,随着迭代次数的增加,算法的识别正确率逐渐提高,并且很快趋于稳定,当树的高度为10时,算法的性能达到最优.
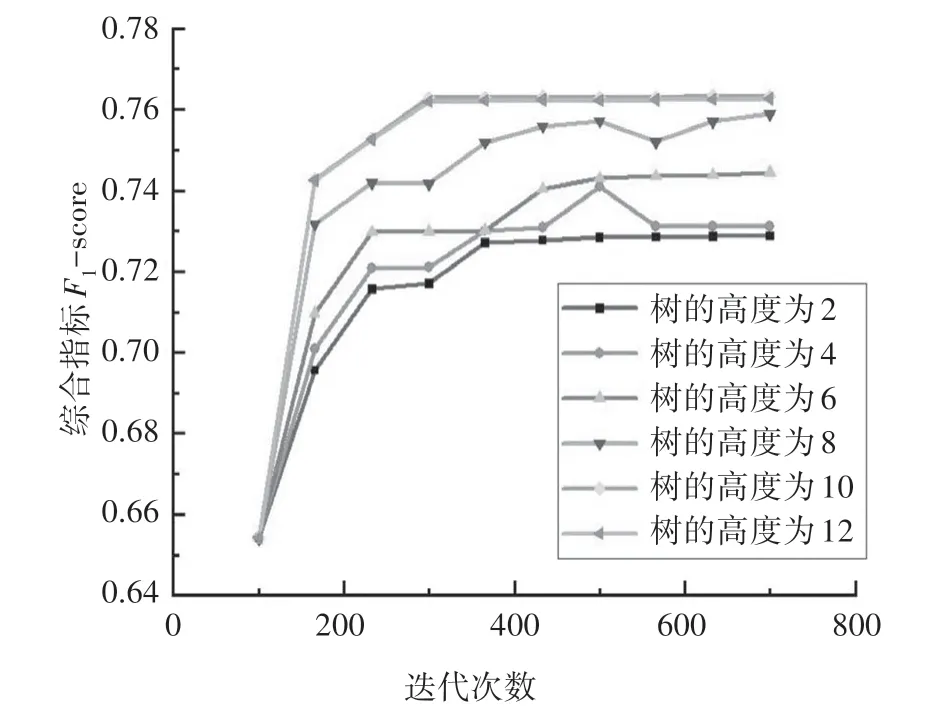
图3 不同树的高度时模型的F1-scoreFig.3 F1-score of the algorithm at different tree height
5)其他参数:在确定了前面4 个参数之后,采用网格搜索,对学习率、gamma 参数、lambda 正则系数、alpha 正则系数等参数按给定步长在一定范围内依次进行调整,最终结果如表3所示.
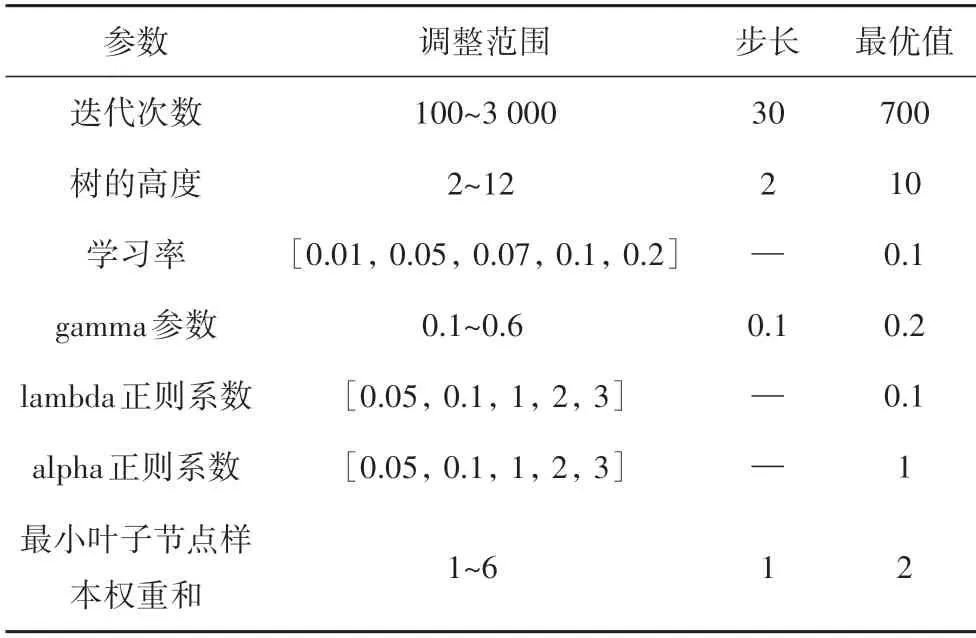
表3 XGBoost参数调优Tab.3 XGBoost parameters’optimization
3.2 特征的重要性排序
使用XGBoost 建模过程中,可以根据模型自带的feature_importances 排序工具,评价每个特征对模型的贡献程度,从而对特征变量进行进一步的筛选.图4 为重要性排在前十的特征量,可以看出,运行时长、台区历史烧表数量、表计止码和烧表前1 d 的用电量为模型中比较重要的特征.

图4 模型的特征重要性Fig.4 Feature importance of the algorithm
因为考虑到模型需要进行实际应用,任意一个网省公司的用户数量都是千万级别,模型的计算量相当大.因此,尝试进行降维,适当压缩电量、电压、电流、线损追溯的天数,在固定其他参数和特征不变的情况下,追溯天数与F1指标的变化情况如图5 所示.由图5 可知,往前追溯15 d 左右,即可得到较好的模型效果,所以为了模型计算更加快捷,将模型需要的追溯时间调整为烧表前的15 d.
3.3 其他机器学习模型结果对比
本文还采用了KNN、朴素贝叶斯、决策树、支持向量机、随机森林、GBDT 等进行实验,与XGBoost 算法的比对结果如表4 所示.实验采取了五折交叉验证的方式,从表4 可以看出,基于支持向量机、朴素贝叶斯和KNN 的识别指标比较低,分别为27.08%、22.86%和40.92%;采用决策树、随机森林和GBDT的算法识别准确率分别为56.00%、56.00%和72.75%;而基于XGBoost 算法的识别准确率为76.51%,远高于传统算法.

表4 与其他机器学习模型的结果对比Tab.4 Comparison of results of different machine learning algorithm
3.4 实验结果分析
根据电能表的实际运行数据,烧表情况占比很小,以某网省公司为例,每年烧表的比例不足1%,但由于基数比较大,所以烧表造成的经济损失相当大.
从理论上说,在实现二分类的过程中,如果类别分布不均衡,会在一定程度上影响模型分类的准确性.而在本实例中,数据集中包含的烧表样本仅占总数的10%.
根据以上所有模型的表现,所有模型的精度与召回率如表5 所示.基于朴素贝叶斯的算法精度只有40%;基于KNN、朴素贝叶斯、支持向量机的算法召回率分别为28%、16%和16%;而基于GBDT 和XGBoost 的算法精度和召回率都有明显提升,其中XGBoost 的精度达到91%,召回率也达到66%,相比传统算法,已经有了显著的提升.
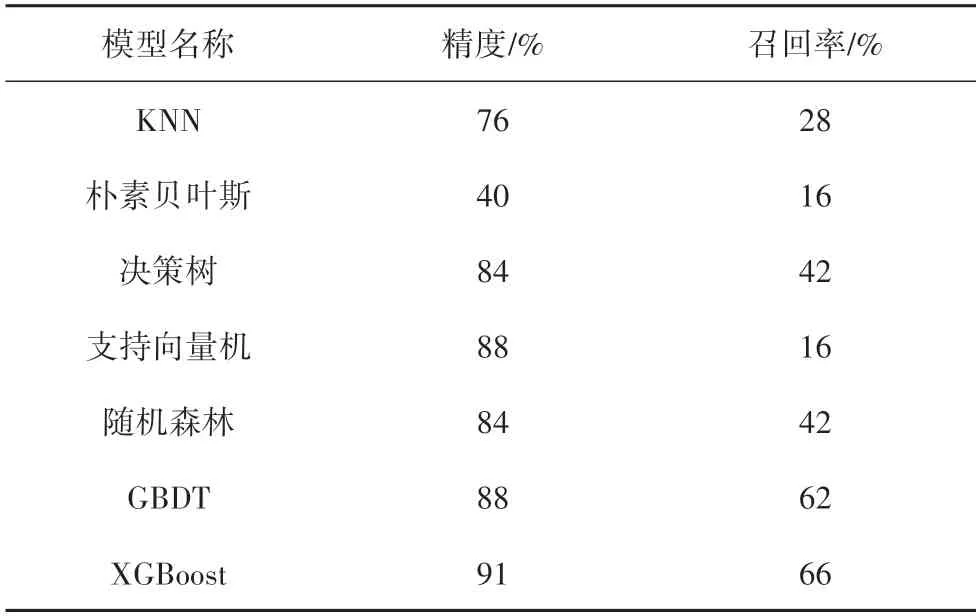
表5 精度和召回率对比Tab.5 Comparison of precision and recall
以上结果表明,本文所提出的基于XGBoost 的电能表烧表预测模型能够提高分类的准确性,在不平衡样本中也可以得到较为满意的效果.
4 应 用
根据实验模型结果,尝试将该模型应用于实际生产数据进行验证,图6 为某电力公司用电信息采集系统的烧表预测模块系统界面.
图6 烧表预测模块系统界面Fig.6 System interface of the module of burning fault prediction for smart meter
在试运行的时间段内,通过基层供电服务人员对系统预测情况和电能表的实际运行情况进行现场确认,测试该模型的综合指标能否达到预期.
在验证过程中,由于全省电能表数据基数大,电量、电压、电流等电能表运行数据受到自然条件影响,每天的数据采集成功率无法达到100%,因此存在很多的缺失值,需要进行缺失值的补充.这与训练集数据有所区别,训练集数据都是历史数据,对于存在缺失数据的样本,可以直接剔除,但验证数据集的样本是准实时数据,不能直接剔除,如果直接剔除,会导致样本越来越少.缺失值的填充有多种方法,常见的填充方法有均值填充和插值填充等,这些方法可以用于电压数据的填充,因为电压基本稳定在220 V,但电流和电量数据通常情况下具有较大的波动性,均值和插值算法都会带来一定程度的误差.由于电流和电量的预测基本上类似于短期电力负荷的预测,可以参考文献[13]使用LSTM 算法对缺失电量和电流数据进行预测和填充.
为了验证LSTM 预测填充法和均值、线性插值法的差异,在训练集中任意选取1 000组电能表烧损数据和1 000 组未烧损数据,在每组数据中,随机剔除1 项电流数据或者电量数据,之后,用不同的方法对剔除的数据进行填充.对比均值填充、线性插值填充和LSTM 算法预测填充的准确性,以平均绝对百分比误差(MAPE)作为评价指标,结果如表6所示.

表6 不同填充方法对比Tab.6 Comparison of different data imputation methods
经过缺失值的填充与处理,测试集数据预处理全部完成,用XGBoost 模型对试点验证的某市公司800 余个台区,共10 万余块在运电能表进行了验证,共验证了263 块烧表,精确率达到82.45%,召回率达到56.73%,基本上达到了预期水平.目前,该烧表预测模型已在系统部署并全省运行.
5 结语
本文针对供电公司低压台区烧表率高的现状,提出了一种基于XGBoost 算法的电能表烧表预测方法,通过对电能表生产厂家的基本信息、每日电量等运行信息和温度等环境信息,进行单变量和多变量组合分析,实现了烧表现象的准确预测.模型应用结果表明,所提算法有效实现了烧表现象的预测,并且具有广泛推广应用的适用性.
