基于批量式强化学习的群组放煤智能决策研究
2022-11-02李庆元李化敏李东印杨延麟费树岷
杨 艺,李庆元, 李化敏,李东印,杨延麟,费树岷
(1.河南理工大学 电气工程与自动化学院,河南 焦作 454000;2.河南省煤矿装备智能检测与控制重点实验室,河南 焦作 454003;3.河南理工大学 能源科学与工程学院,河南 焦作 454000;4.河南理工大学 学术出版中心,河南 焦作 454000;5.东南大学 自动化学院,江苏 南京 210096)
0 引 言
综放开采技术于20世纪80年代自欧洲引入我国,经过30余年时间的不断发展,我国综放开采技术已达到世界领先水平。目前,综放开采已成为我国厚煤层以及特厚煤层的主要开采方式[1-2]。
经过长期积累和基础性研究,针对不同的地质条件,研究人员提出了:顺序放煤、间隔放煤、多轮放煤、一采一放、多采一放等一系列放煤工艺[3-5]。文献[6]定性研究了不同采放比条件下,单口和双口间隔放煤方式的顶煤放出率和出煤含矸率。随后,一系列基于离散元分析方法的放煤工艺被深入研究。文献[7]结合二维颗粒流程序(PFC2D),分析顶煤放出过程中的成拱现象及原理,通过振动方式破坏成拱,提高顶煤采出率。文献[8-9]结合基于离散元的三维颗粒流程序(PFC3D),建立BBR研究体系,研究煤岩分界面、顶煤放出体、顶煤采出率和含矸率的相互影响与制约关系。文献[10]以理论分析、数值模拟为主要手段,围绕多放煤口协同放煤方法,研究煤岩运动特征对顶煤采出率和放煤效率的影响。随着人工智能技术不断取得突破,基于机器学习的放煤智能决策方法越来越受到研究人员的关注,并对其展开了深入研究。2014年,文献[11]针对厚煤层采煤方法的不确定性因素,运用多级模糊综合评判方法对采煤工艺进行综合评判,建立了基于BP神经网络的厚煤层开采方法评价模型。2015年,文献[12]采用记忆放煤时序控制模式,实现连续放煤。2018年,文献[13]通过果蝇优化算法与RBF(Radial Basis Function)混合预测放顶煤的时间,使得放煤时间随煤层赋存条件自动调整。2019年,文献[14]通过对多传感器采集信号进行特征提取,对比放煤特征范例库做出放煤预警或控制。文献[15]基于智能化放煤装备,融合煤流量信息、顶煤量信息、煤矸辨识信息,给出智能放煤控制框架。2020年,文献[16]提出构建“放煤全过程监测系统”,将透地测量雷达、三维空间雷达用于后部放煤空间感知,扫描未放顶煤空间测量计算剩余煤厚与煤矸比例,对放顶煤全过程进行实时监测,为实现自动化、智能化放煤提供了必要手段。
由于综放工作面环境恶劣,影响煤岩运动特征的因素庞杂,难以建立开采环境和开采过程的准确数学模型。这使得液压支架放煤口的动作控制丧失精确的指挥棒,从而导致难以形成精准的放煤工艺。因此,国家“十三五”重点研发计划项目“千万吨级特厚煤层智能化综放开采关键技术及示范”中将智能放煤工艺模型和方法列为子课题,开展研究工作。2019年,课题组提出了一种基于传统Q-learning的免模型放煤决策算法,将放煤口智能决策单元定义为放煤智能体。智能体结合顶煤放出体实时状态特征与顶煤动态赋存特征,生成群组放煤过程中多放煤口开、闭实时控制策略,对放煤口控制动作做在线调整[17]。2020年1月,课题组将深度强化学习网络Deep Q-Network用于放煤最优决策,实现智能体随煤层赋存状态自适应、智能化调节放煤口动作,并通过搭建的三维仿真试验平台验证了该方法的有效性[18]。2020年3月,课题组将综放工作面液压支架群抽象为图模型(Graphic Model)结构,并提出了放顶煤多智能体优化决策的隐马尔可夫随机场模型,用以优化智能体的动作决策[19]。
依托前期研究成果,从智能决策角度出发,提出了一种基于批量式Q值更新的放煤动态决策算法,对放煤智能体的在线学习过程进行加速。作者将该算法作为综放工作面智能群组放煤方法的智能决策部分,并通过理论分析、三维数值仿真等主要手段对不同放煤方式展开对比研究。
1 基于强化学习的群组放煤智能决策建模
1.1 群组放煤决策的智能属性
顶煤放出效果直接由放煤口的开闭动作决定,而放煤口开闭动作由电液控系统驱动。从控制理论角度出发,电液控系统的运行必须基于给定的控制模型和对应的控制算法。然而,放顶煤过程是一个十分复杂的动态过程,涉及到顶板地质信息、顶煤破碎及运移过程、围岩动态信息等庞大的非线性、强耦合状态变量和作用关系,难以采用动力学方程建立控制模型,从而无法设计控制算法。这也是目前放煤不得不采用人工操作,或者依据开闭时间来控制放煤口动作的根本原因。但是,这2种方式显然无法全局统筹顶板地质条件、顶煤赋存状态、液压支架群动作等各类信息之间的关联关系,从而导致无法定量生成最优控制策略来驱动电液控系统,难以达到最优的放煤效益。
将放煤口上方及掩护梁后方作为顶煤赋存状态的检测区域。随着顶煤不断放落,顶煤赋存状态发生变化,对应的放出体状态也会随之产生相应变化。该变化可由顶煤赋存状态与放出体状态的映射关系来表征。传统的人工放煤控制,通过观测煤流信息,实现对放煤口的控制。但对于已放落顶煤,由于受人工操作时间、放煤口动作时间等影响,其放出过程不可改变,导致放出体中存在部分矸石,未能提前实现对放出体状态的精确控制。因此,结合顶煤赋存状态对放煤口进行决策控制,研究“顶煤赋存状态-放煤口控制”二者关联关系,对于提高放顶煤开采效益,具有重要意义。
在放煤口动作过程中,其决策结果取决于前一时刻的顶煤赋存状态、瞬时放出体状态等外部环境,这是典型的马尔可夫决策过程,这表明人工智能的“环境感知-决策控制”的关联机制与放煤口控制高度契合[15, 20-21]。结合人工智能技术,实现放煤口智能化控制,是现阶段提高顶煤放出率、降低出煤含矸率的有效方法之一。
一个综放工作面通常有上百台液压支架排列,构成液压支架群。在放顶煤过程中,每个液压支架可以看作是一个智能体,液压支架群则可以看作是一个需要协同控制的多智能体。因此,在多智能体框架下,将放出体实时状态、顶煤动态赋存等主要环境信息作为决策依据,赋予各放煤智能体自主决策和自主控制能力的同时,使得各智能体之间高度协调、相互协同能够有效提高顶煤的采出率、降低出煤的含矸率。
强化学习(Reinforcement Learning)是一种基于动态规划(Dynamic Programming)的机器学习算法。该算法以外部环境作为输入,以决策结果作为输出,适用于马尔可夫过程的最优决策[22-23]。其主要思想是与环境在线式的交互与试错,通过学习“环境状态-执行动作”之间的映射关系,使所执行动作从环境中收获最大期望累积奖赏值,从而逼近最优策略。
在综放工作面放煤决策过程中,其核心研究内容是根据煤层赋存状态,动态调整放顶煤策略,实现放顶煤收益最大化。即以强化学习“环境状态-执行动作”二者间映射关系为基础,解决马尔可夫过程的最优决策问题。基于此,在多智能体框架下,建立面向放顶煤过程的马尔可夫决策模型,运用强化学习基本原理解决传统综放工作面存在的顶煤采出率低、出煤含矸率高等问题。
1.2 放煤过程的Q-learning决策过程建模
1.2.1 面向马尔可夫决策过程的Q-learning算法
马尔可夫决策过程(Markov Decision Process,MDP)可用四元组Μ≜{s;a;R;γ}表示。其中,s∈为系统状态,={s1,s2,…,sD}为系统状态空间,D∈表示状态空间维度,为正整数集;a∈为智能体的动作,={a1,a2,…,aJ}为智能体动作空间,J∈表示动作空间维度;R∈为瞬时奖赏值,为实数集,取决于放出体状态;γ∈(0,1)为折扣因子,表明决策步骤对当前状态执行动作的重要程度。
强化学习是学习环境状态与执行动作之间的映射关系,通常使用Q值表来对状态-动作对进行评价。智能体基于在线学习机制,通过与环境不断进行交互,以此来更新Q值表,并通过Q值表来进行目标和行为决策。
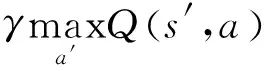
(1)
在第k次学习过程中,将学习到的Qk(s,a)称为估计值:
Qestimate=Qk(s,a)
(2)
Q-learning算法通过Qactual与Qestimate之间的差值来更新Q值表,以此来逼近目标函数。第k+1次Qk+1(s,a)值学习结果表示为如下形式:
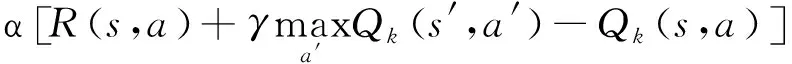
(3)
式中:k为采样次数;α∈(0,1)为学习率;R(s,a)为状态s下,执行a动作的单步奖赏值。
在保证算法收敛的情况下,为合理增加采样次数,在Q(s,a)的学习过程中引入了“探索”与“利用”均衡ε-greedy算法,实现动作a的选择。如式(4):
(4)
式中:π(a|s)为“状态-动作”选择策略,由概率值表示;ε∈(0,1),表示探索率;|A(s)是状态s条件下可选的动作数量;a*为候选动作的最优值,即
(5)
其中,在状态s条件下,候选动作是最优动作时a=a*,用于“利用”;而候选动作不是已知最优动作时a≠a*,用于“探索”;最后依据π(a|s)的概率最大值选择动作。
1.2.2 放煤过程的Q-learning决策模型
(6)
式中:m和n分别为待检测状态区域煤炭总量和矸石总量。
在放顶煤决策过程中,智能体决策结果仅仅是依据当前状态和控制策略给定放煤口应该打开还是关闭。本文指定放煤口动作空间为
={a1,a2}
(7)
式中,动作选取a1表示放煤口执行打开,选取a2表示放煤口执行关闭。
瞬时煤流中煤、矸量受顶煤赋存状态s和放煤口开闭动作a共同影响。结合瞬时煤流信息中煤、矸量(M,N),将放出体中煤、矸含量占比作为奖赏值输入,奖赏函数设定为
(8)
式中,λm、λn为权重系数。
2 群组放煤过程批量式Q-learning智能决策
2.1 群组放煤过程批量式Q-learning决策模型
2.1.1 群组放煤批量式更新方法
结合实际开采过程可知,在放顶煤过程中,理想情况下顶煤中煤含量占比随放煤时长增加而逐渐减少,即:顶煤赋存状态随放煤时长由全煤下放逐渐转移至全矸下放,且整个过程中煤含量单调变化。然而,受数据处理及计算机运算效率的影响,放煤过程的状态变量常需要定时采样,从而使得煤矸含量在数值上出现较大幅度的跳跃。如:前一采样过程中获取顶煤赋存状态为si,当前采样过程中获取顶煤赋存状态为sj,其中i,j∈{1,2,…,D}。顶煤赋存状态更为精细的单调变化状态为si→…→sl→…→sj,l∈[i,j)且l∈。然而,由于采样时间间隔的影响导致若干个中间转移状态sl未能通过采样获取。
上述采样过程在强化学习框架下的直接后果是状态-动作值函数Q(s,a)中s的更新过程无法短时间内覆盖到所有的状态变量,大幅降低智能体的在线学习效率,甚至会导致学习结果失败。为此,提出一种批量式Q值更新的放顶煤动态决策算法,实现对顶煤赋存状态更为精细变化的学习,提升智能体状态-动作值函数Q(s,a)的学习能力,确保智能体的决策模型快速收敛到最优值。
若存在前一时刻采样状态si及当前采样状态sj,且前后状态下所执行动作一致,即π(sj)=π(si),则设精细化变化的离散状态空间{si,…,sl,…,sj},对应的瞬时奖赏值{R(si,π(si)),…,R(sl,π(sl)),…,R(sj,π(sj))}。采用等差值划分的方式对未采样状态sl所对应瞬时奖赏值R(sl,π(sl))进行估计,如式(9)所示:
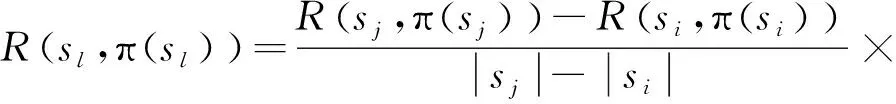
(9)
式中:|sj-|si为采样间隔过程中的离散状态变化量。
已知,前后采样状态si、sj,对于任意l∈[i,j),以sj作为后续转移状态s′,且π(sl)=π(sj)=π(si),对精细化变化的离散状态空间sl∈{si,…,sj-1}状态-动作值函数Q(sl,π(sl))进行批量式更新,如式(10)所示:

(10)
2.1.2 批量式Q-Learning算法收敛性分析
在批量式Q-learning算法中,状态空间为SD={s1,s2,…,sD},对任意i∈{1,2,…,D},状态变量取值si=i;R(si,π(si))∈为奖赏值。对于状态变量si∈SD,sl∈SD,sj∈SD,j>i,l∈[i,j),则sj>sl>si,且有R(sj,π(sj))>R(sl,π(sl))>R(si,π(si)),给出如下定义:
定义1:状态变量的单调性:
1)单调增:状态转移过程si→…→sl→…→sj;
2)单调减:状态转移过程sj→…→sl→…→si。
定义2:奖赏值的单调性:
1)单调增:状态变量满足单调增,奖赏值变化过程R(si,π(si))→…→R(sl,π(sl))→…→R(sj,π(sj));
2)单调减:状态变量满足单调减,奖赏值变化过程R(sj,π(sj))→…→R(sl,π(sl))→…→R(si,π(si))。
定义3:单调马尔可夫过程:
1)单调增:状态转移过程为si至sj,则状态变量满足单调增;
2)单调减:状态转移过程为sj至si,则状态变量满足单调减。
定义4:状态跳变:
1)单调增:已观测前后状态si、sj,满足单调增马尔可夫过程,且j-i>1,则存在若干未观测中间转移状态sl,存在状态转移过程si→…→sl→…→sj;
2)单调减:已观测前后状态sj、si,满足单调减马尔可夫过程,且j-i>1,则存在若干未观测中间转移状态sl,存在状态转移过程sj→…→sl→…→si。
批量式Q-learning算法通过式(10)的迭代方式,经过若干次迭代,动作值函数可收敛到系统的最优解。首先给出Q-learning按照式(3)所示的迭代过程的收敛性引理。
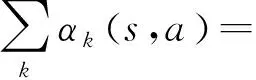
根据引理1,批量式Q-learning算法的收敛性质可由以下定理确定。
定理1:设在马尔可夫决策过程中,定义智能体的状态变量si∈SD;动作a∈;R∈为瞬时奖赏值;智能体执行策略为π,对应的状态-动作值函数为Qπ(s,a)。决策过程的状态变量和奖赏值满足如下条件:①状态变量满足单调性;②奖赏值满足单调性;③马尔可夫过程的状态转移满足单调性;④已观测到的相邻状态变量间存在状态跳变;⑤若执行策略满足π(sj)=π(sl),状态变量si和sj对应的奖赏值存在正比关系:R(sj,π(sj))-R(si,π(si))=k(sj-si),k为常数,且k>0。
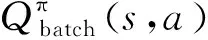
下文针对上述单调性定义中的单调增现象,对批量式Q-Learning算法的收敛性进行证明。
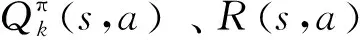
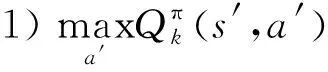
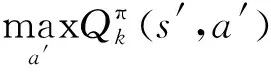
2)R(s,a)近似性证明。由条件(5)可知,精细化变化离散状态空间{si,…,sl,…,sj}中,瞬时奖赏值变化量正比于状态变化量,满足一次函数关系,且比例系数k可表示为:
(11)
对于任意l∈[i,j),批量式Q-learning算法中状态sl的估计奖赏值R(sl,π(sl))batch如下:
R(sl,π(sl))batch=k×sl+R(si,π(si))-k×si
(12)
式中,R(si,π(si))-k×si表示一次函数中常数项。
将式(11)代入式(12),可得如下形式,
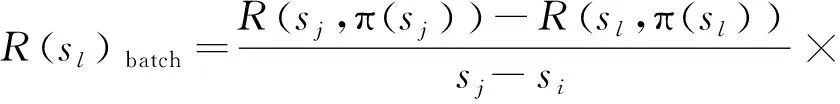
(13)
在不改变连续动作,即满足π(sj)=π(si)=π(sl)的条件下,状态sl的估计奖赏值R(sl,π(sl))batch与未获取的真实奖赏值R(sl,π(sl))true满足以下关系,
R(sl,π(sl))batch≈R(sl,π(sl))true
(14)
结合批量式Q-learning算法目标函数式(10),Q-learning算法目标函数式(3),可得
(15)
因此,批量式Q-learning所得到的动作值函数与式(3)的结论近似。
2.2 基于批量式Q-learning的群组放顶煤智能决策算法
结合目标函数式,给出放顶煤开采环境下,基于批量式Q值更新的放顶煤智能决策算法伪代码:

3 智能群组放煤三维仿真试验及结果分析
智能群组放煤需要放煤智能体把握工作面动态数据,来实现群组放煤过程的动态决策。由于煤矸识别这一关键技术尚未取得突破性进展,依现有技术和装备,难以对现场动态数据精准获取,因此无法通过工业性试验对智能群组放煤方法进行验证。以同煤塔山煤矿8222综放工作面煤层条件为基础,结合液压支架主要技术参数,建立单轮群组放煤过程数值模拟模型,对智能群组放煤方法展开仿真试验。塔山煤矿8222综放工作面煤层平均煤厚15.76 m,采高3.8 m,放煤高度11.96 m,采放比1∶3.14。
3.1 综放工作面智能放煤三维仿真试验平台
结合Yade开源代码,在ubuntu系统上开发了一种基于离散元方法的放顶煤过程仿真平台,对智能群组放煤控制方法展开研究,建立放顶煤模型如图1所示。
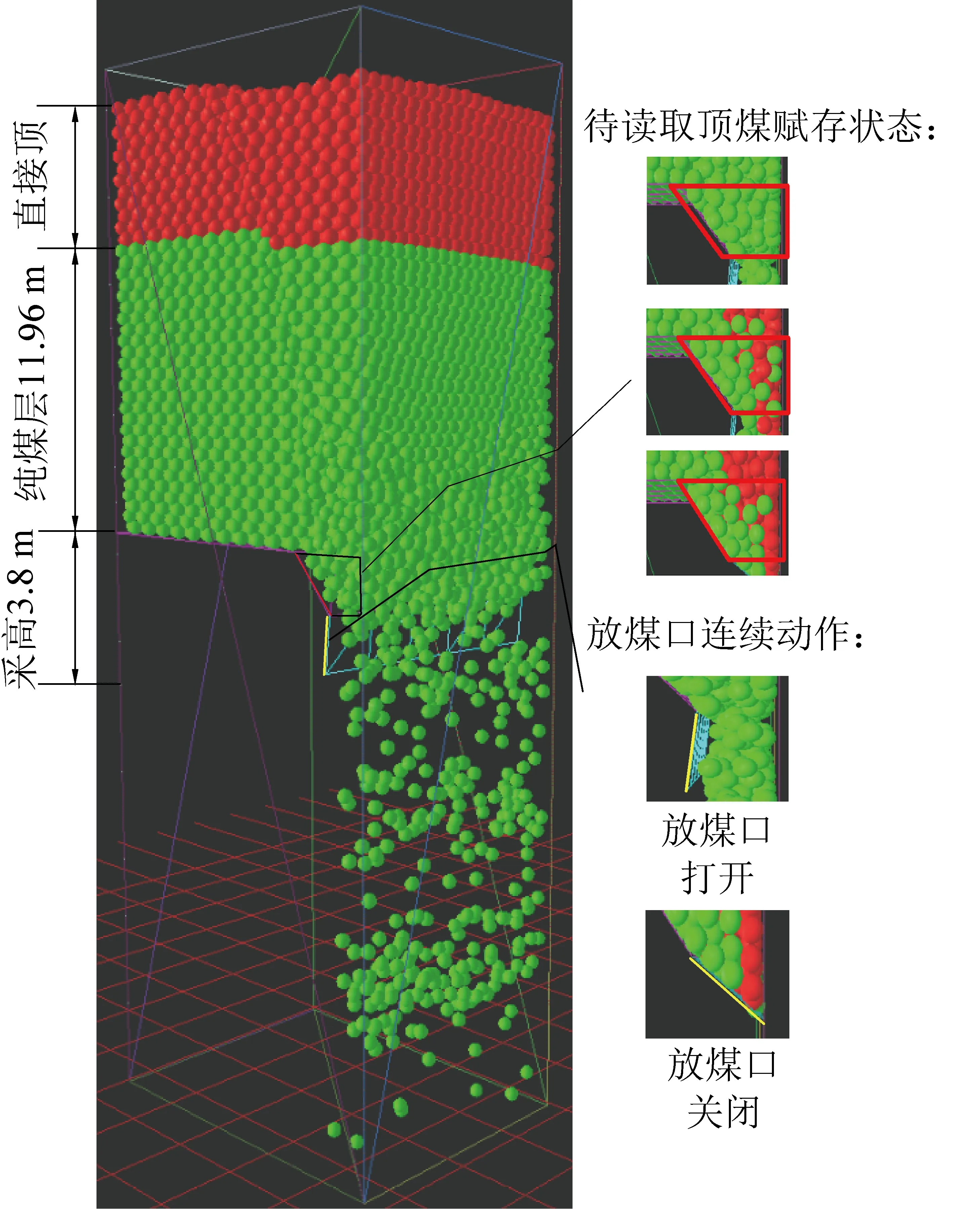
图1 三维放顶煤模型Fig.1 Three-dimensional top-coal caving model
放顶煤模型中包括5个顶煤放出口,液压支架主要技术参数如下:wsp为工作面宽度,6.8 m;why为液压支架宽度,1.5 m;hhy为液压支架高度,3.8 m;lsh为掩护梁长度,3 m;lta为尾梁长度,2 m;θs为顶梁与掩护梁之间锐角夹角,15°;θu为尾梁上摆与掩护梁锐角夹角,15°;θl为尾梁下摆与掩护梁锐角夹角,45°。
由煤炭、矸石2种材料作为顶板上方散体顶煤的构成成分,设定在仿真环境中煤炭、矸石颗粒在自身重力作用下达到密实状态,离散元颗粒主要力学参数见表1。

表1 离散元颗粒主要力学参数
3.2 智能群组放煤仿真试验
对于单个离散元粒子,煤炭粒子取奖赏值为3,矸石粒子取奖赏值为-7;对于放出体中煤、矸含量占比权重λm=0.7、λn=0.3,即煤、矸流中瞬时煤含量等于70%存在临界放煤收益0。设定学习率α=0.1,折扣因子γ=0.9,探索率ε=0.8。结合上述参数,在给定放顶煤模型下,对群组智能放煤算法展开训练。
3.2.1 试验过程
在Linux操作系统上,结合YADE离散元开源环境进行试验,并采用多核CPU并行加速,具体试验环境如下:

操作系统Ubuntu18.04YADE版本2020.01a语言PythonCPUIntel Core i7-7700k内核数8RAM32 G
在训练过程中,由于放顶煤动作受行为策略影响,存在一定随机性,进而会在连续的放顶煤过程中形成不同的连续变化的顶煤赋存状态,因此,在训练过程中将会形成不同的马尔可夫决策链。智能体对决策链中各顶煤赋存状态与决策动作对进行逐一学习,直至Q(s,a)完全收敛,结束训练。取煤含量每5%变化作为一种煤层状态,学习速率如图2所示。
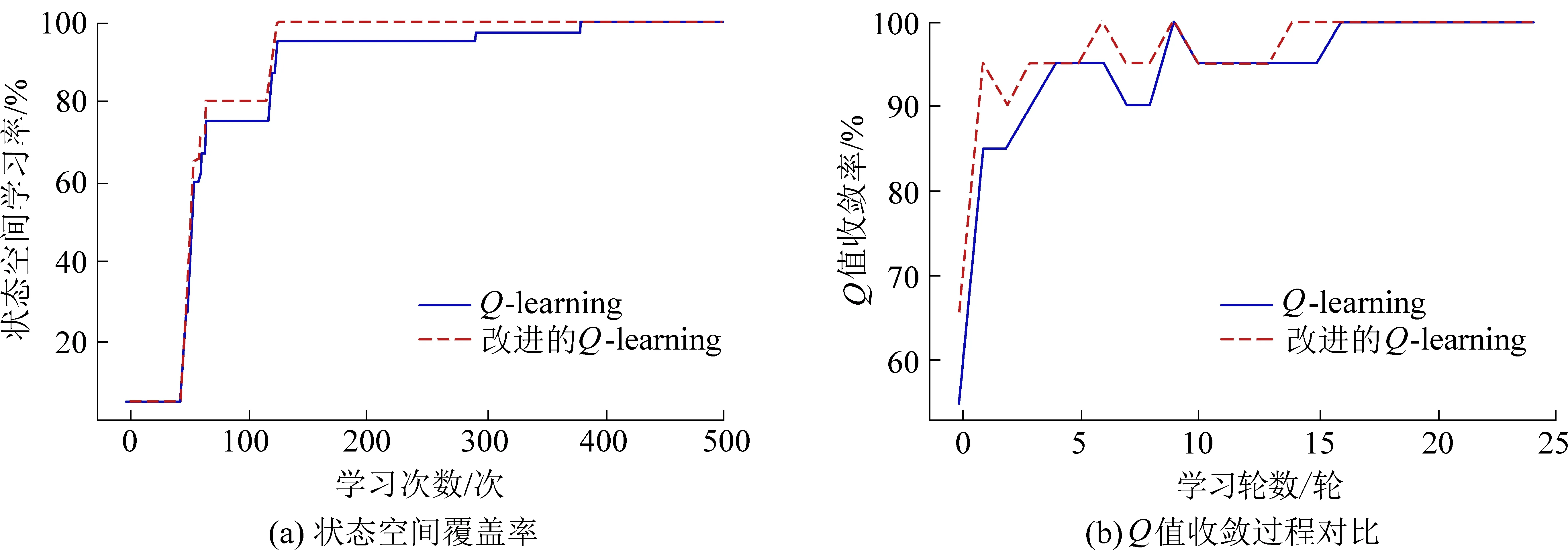
图2 智能体学习速率对比Fig.2 Agent learning rate comparison
受煤层条件影响,在放煤初期,放出体以纯煤为主,放煤状态较单一,因此智能体获得的经验与知识较少;随着放煤过程进行,直接顶逐渐破碎,放出体中开始出现矸石,放煤口上方逐渐出现混矸、夹矸等顶煤赋存状态,智能体对不同赋存状态下的放煤决策动作进行学习,放煤知识与经验逐步积累增多,状态空间覆盖率出现跳跃式增长。经对实验过程观察记录分析,整块煤体放落时长受限于自身力学参数模型,仿真环境中散体顶煤完全垮落时长多接近但不超1 000 s,因此,在该训练模型中预设训练时长为1 000 s/round。
图2a共进行5轮学习,每轮Q值更新次数为100次。提出的批量式Q值更新算法在第2轮学习结束完成首次对全状态空间的学习,而Q-learning算法首次完成全状态空间学习在第4轮,采用批量式Q-learning算法使智能体对全状态空间的探索时间缩短了50%。
图2b以两种算法最终收敛Q值为比对目标,分别对每轮训练结束后Q值进行收敛度对比。本文提出的批量式Q值更新算法在第14轮后完全收敛,Q-learning算法在16轮后完全收敛,批量式Q值更新算法提前两轮完成收敛,训练效率提高12.5%;批量式Q值更新算法收敛率普遍高于Q-learning算法,至Q值完全收敛,单轮训练平均收敛率为93.21%,Q-learning算法单轮训练平均收敛率为92.91%,批量式Q值更新算法单轮训练平均收敛率较Q-learning算法提高0.3%。
由上述分析可知,通过对目标函数改进提出的批量式Q值更新算法,大幅提高了智能体学习效率,加速了智能体在线学习过程,从而减少了智能体因学习不充分而造成无法决策或决策失误所导致的资源损失与浪费。智能体依训练结果对放煤过程进行测试,测试结果如图3所示。

图3 放顶煤过程仿真Fig.3 Simulation of top-coal caving process
引入采出率Wc、含矸率ρ、全局奖赏值RA对放煤总体效益进行评估,计算方式如下:
(16)
式中:QC为顶煤放出体中煤颗粒个数;QD为放煤区间内纯煤颗粒个数。
式中:QG为顶煤放出体中矸石颗粒个数;QA为放出体中全部颗粒个数。
RA=QCRm-QGRn
式中:Rm为回收一个煤颗粒,智能体得到的奖赏值;Rn为回收一个矸石颗粒,智能体得到的惩罚值;QG为顶煤放出体中矸石颗粒个数。
3.2.2 试验结果分析
将提出的智能群组放煤方法与传统以“见矸关窗”为准则的单放煤口连续放煤、“大中小”间隔放煤等放煤方式进行放煤结果对比,见表2。
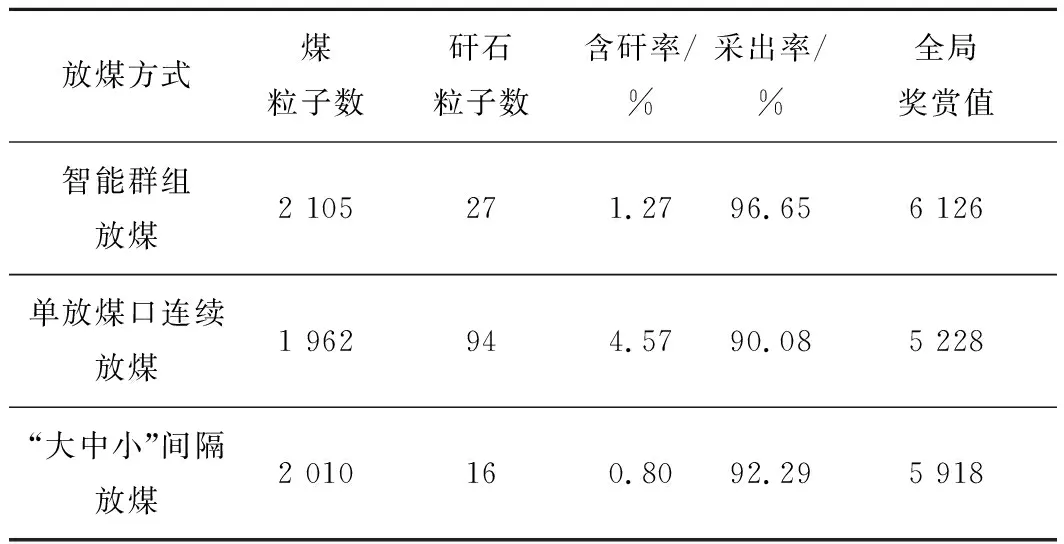
表2 放顶煤仿真结果对比
其中,“大中小”间隔放煤方式对于两端1号及5号放煤口采用优先“大”放,然后对中部3号放煤口采用“中”放,最后对2号及4号放煤口采用“小”放。“大中小”间隔放煤旨在模拟研究分段大间隔放煤方式对放顶煤开采效益的影响。
由表3可知,智能群组放煤顶煤采出率为96.65%,相对于单放煤口连续放煤提高6.57%,放煤总体收益提高17.17%;相对于“大中小”间隔放煤提高4.36%,放煤总体收益提高3.51%。“大中小”间隔放煤顶煤采出率为92.29%,相对于单放煤口连续放煤提高2.21%,放煤总体收益提高13.20%。
在单放煤口放煤过程中,当前放煤口状态易受临架放煤结果影响,如图4所示。因此,若严格按照“见矸关窗”准则对放煤口进行控制,会导致放煤收益偏低。以待检测赋存状态空间达到临界放煤收益,即矸石含量超过30%作为常规放煤方式的临界控制条件,对放煤口进行控制,致使放煤结果中出煤含矸率不为0。

图4 放顶煤过程中的窜矸现象Fig.4 Gangue channeling phenomenon in top-coal caving process
根据放顶煤原理,通过合理放煤工艺,控制煤岩分界面形态与放煤口保持相对平行,尽可能地扩大二者相切范围能够最大限度地将顶煤放出。对于单放煤口连续放煤方式,随着放煤过程进行,如图5a所示,受混矸、窜矸等现象严重影响,煤岩分界面曲线直线度遭到严重破坏,甚至出现分界面曲线垂直或超过垂直于放煤口的现象,放煤口控制难度加大,导致放煤收益低。对于智能群组放煤方式,如图5c所示,煤岩分界面曲线直线度良好,煤层赋存状态空间平稳变化,混矸、窜矸等现象较少,分界面曲线与放煤口几近平行,放煤口控制难度低,放煤总体收益高。
单放煤口“大中小”间隔放煤方式,如图5b所示,随间隔距离增长,两放煤口之间相互影响减少,分界面曲线坡度降低,可放出区域逐步扩大,进而顶煤采出率得以提高。但大间隔放煤方式最终使煤岩分界面呈现出“峰谷式”变化,在两端及中部放煤口仍会形成放出漏斗,相邻放出漏斗间形成三角煤区域,该区域顶煤无法有效采出,因此顶煤采出率相对较低。现阶段,塔山矿8222工作面采用“大中小微”分段间隔四级一次放煤工艺,旨在降低分段间隔中部放煤口上方煤矸分界面曲线弧度,保持放煤口正上方分界面曲线与放煤口相对平行,扩大可放出区域,提高顶煤采出率。

图5 煤岩分界面曲线变化过程Fig.5 Change process of coal-rock interface curve
智能群组放煤通过对放煤口的智能决策控制,收获最大放煤收益,且顶煤采出率最高。“大中小”间隔放煤方式以“见矸关窗”为控制准则,其放煤方式较为保守,故顶板上方残存煤炭粒子偏多。2种放煤方式下顶板上方粒子分布如图6所示。
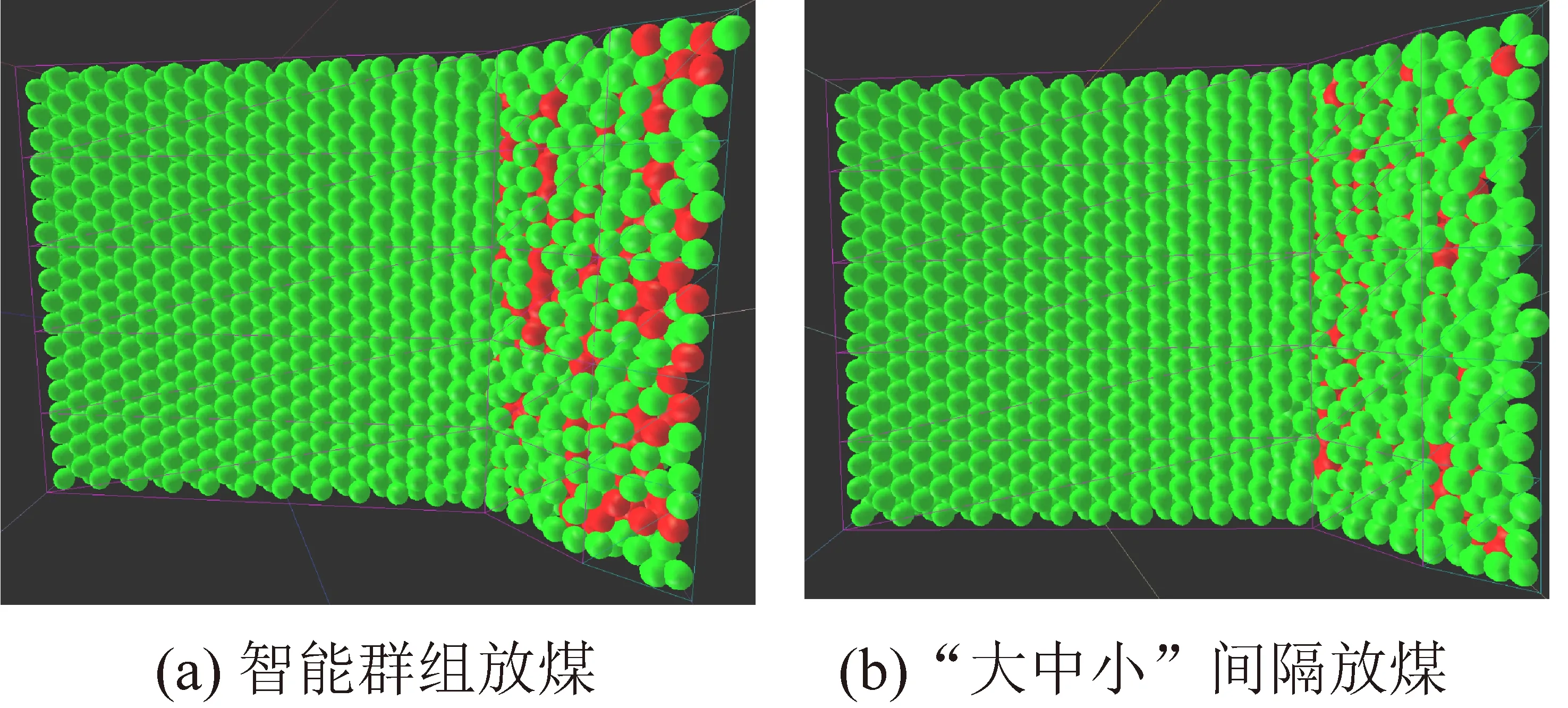
图6 顶板上方粒子分布Fig.6 Particle distribution above hydraulic support
智能群组放煤在直接顶破碎的情况下,将含有部分矸石的顶煤适量放出,在提高顶煤采出率的同时导致含矸率小幅升高,通过对采出率和含矸率的合理平衡,使放顶煤总体收益得到提高。
4 结 论
1)建立了基于离散元方法的放顶煤过程三维仿真模型,实现了对塔山矿8222工作面放顶煤过程的数值模拟仿真,为后续放顶煤开采理论的研究与发展提供仿真实验平台。
2)将液压支架群看作是一个需要协同控制的多智能体,在多智能体框架下,提出基于批量式强化学习的综放工作面群组放煤智能决策。依据该决策算法,放煤智能体能够根据顶煤动态赋存对放煤口动作做出在线调整,实现放顶煤收益最大化;并对智能体在线学习过程中“状态跳变”现象所带来的负面影响进行削减,使智能体的在线学习效率得到进一步提高。
3)仿真试验结果表明,塔山矿8222工作面采用大间隔分段放煤方式,显著优于单放煤口连续放煤方式。分段大间隔放煤方式通过维持煤岩分界面曲线平稳变化,始终保持当前放煤口与正上方煤岩分界面曲线相切,显著扩大了可放出区域,提高了顶煤采出率。
4)结合人工智能技术及方法,研究建立放出体状态、煤层赋存状态、煤岩分界面特征等主要环境信息与放煤口控制之间的匹配关系,实现对放煤口动作的合理预测控制,对于提高顶煤采出率、降低出煤含矸率具有重要意义。
5)在长期的实践积累中,放煤操作人员积累了丰富的放煤经验,但现阶段的科学研究过程中并未将这些经验很好地提炼、吸纳。在后续研究中,课题组将会对相关放煤经验进行总结、规范,构建放煤知识经验库,并将经验库作为先验知识,指导放煤智能体的学习过程。
