基于全局时空编码网络的猴类动物行为识别
2022-11-02张素才马喜波
孙 峥,张素才,马喜波
基于全局时空编码网络的猴类动物行为识别
孙 峥1,2,张素才3,马喜波1,2
(1. 中国科学院自动化研究所,北京 100190;2. 中国科学院大学人工智能学院,北京 100049;3. 北京昭衍新药研究中心股份有限公司,北京 100176)
猴类动物行为的准确量化是临床前药物安全评价的一个基本目标。视频中猴类动物行为分析的一个重要路径是使用目标的骨架序列信息,然而现有的大部分骨架行为识别方法通常在时间和空间维度分别提取骨架序列的特征,忽略了骨架拓扑结构在时空维度的整体性。针对该问题,提出了一种基于全局时空编码网络(GSTEN)的骨架行为识别方法。该方法在时空图卷积网络(ST-GCN)的基础上,并行插入全局标志生成器(GTG)和全局时空编码器(GSTE)来提取时间和空间维度的全局特征。为了验证提出的GSTEN性能,在自建的猴类动物行为识别数据集上开展实验。实验结果表明,该网络在基本不增加模型参数量的情况下,准确率指标达到76.54%,相较于基准模型ST-GCN提升6.79%。
行为识别;骨架序列;全局时空编码网络;猴类动物;药物安全评价
在临床前药物安全评价中,猴类动物在用药前后的行为变化是必不可少的观测指标[1-3]。长时间的人为观察在成本和随机性方面均存在不可忽视的缺陷。因此需要研发可行的人工智能方法对猴类动物表现出来的与药物安全评价相关的行为进行实时、定量分析。目前针对人类的行为识别方法已经得到了广泛发展,然而在猴类动物上相关方法的研发却发展缓慢。因此,使用人工智能方法自动识别猴类动物的行为对临床前药物安全评价具有重要的现实意义和应用前景。
近些年,一些学者使用人工智能方法进行了动物行为识别任务的研究[4-5],并在各自的动物数据集上达到了较高的性能指标,但在临床前药物安全评价场景中,猴类动物行为识别任务仍有一些特有问题亟待解决。如,猴类动物所处的场景单一、背景扰动、光照变化以及目标外观差异较小,导致连续的视频帧和光流图中包含冗余信息。此外,猴类动物的行为识别需要充分考虑动作在时空维度的整体性。针对此,本文使用猴类动物的骨架序列信息进行行为识别,并提出基于全局时空编码网络(global spatiotemporal encode network,GSTEN)的骨架行为识别方法。该方法本质是使用训练好的姿态估计模型对一段视频中的每一帧进行关键点的识别,再基于上述关键点形成的骨架序列信息进行行为识别,其中骨架序列信息包括每一帧中目标关键点的二维坐标和置信概率。骨架行为识别方法关注目标的肢体动作变化,丢弃了视频背景和目标外观中的冗余信息,降低了数据对模型参数量的要求。然而,现有的大部分骨架行为识别方法[6]通常在时间和空间维度分别提取骨架序列的特征,忽略了骨架拓扑结构在时空维度的整体性。本文在时空图卷积网络(spatial temporal graph convolutional network,ST-GCN)[6]和Transformer[7]等相关工作的基础上提出基于GSTEN的猴类动物骨架行为识别方法。该网络主要包括ST-GCN和全局时空编码器(global spatiotemporal encoder,GSTE)。其中,ST-GCN负责提取时空维度的局部特征来识别简单动作;GSTE由少量的线性算子和自注意力计算模块组成,对时空维度的全局特征进行建模分析进而识别一些困难动作。同时可作为即插即用的轻量级模块来配合骨架行为识别模型ST-GCN使用,提高模型在时空维度整体性建模分析的能力。实验结果证明,GSTEN在基本不增加模型参数量的情况下,可以显著提高基准模型ST-GCN的行为识别准确率,并且优于其他的基于视频帧和基于骨架序列的行为识别方法。
1 相关工作
1.1 人类行为识别
人类行为识别任务通常是识别一段视频中包含的行为类别。由于视频中包含丰富的信息,不同方法利用不同角度的信息对视频中的行为进行建模分析,如外观、光流以及骨架等。SIMONYAN和ZISSERMAN[8]提出经典双流网络,以模仿人类大脑皮层理解视频信息的机制,在处理视频帧图像空间信息的基础上,对视频时序信息也做了建模理解。单独的视频帧可作为表述空间信息的载体,包括背景和目标外观等空间信息,被称为空间卷积网络;另光流图作为时序信息的载体输入到另一个卷积神经网络(convolutional neural networks,CNN)中,用来理解行为的动态特征,称为时间卷积网络。针对行为识别任务中的长范围依赖问题,WANG等[9]在经典双流网络的基础上提出了稀疏时间采样和视频级监督策略,即从整个视频段中稀疏采样一系列片段来促使模型学习行为的全局特征。HARA等[10]在2D CNN ResNet[11]的基础上拓展了一个时间维度得到3D卷积网络。ResNet3D在提取时间维度特征的同时还使用了2D网络中的一系列技巧,如使用残差结构来缓解梯度消失问题。TRAN等[12]在ResNet3D的基础上进一步将3D卷积核分解为2个独立且连续的操作:2D空间卷积和1D时间卷积。卷积分解不仅减少了模型运算参数,同时提高了模型的拟合能力。FEICHTENHOFER等[13]探索了视频的高低帧率对行为识别的影响,设计了低帧率的慢支路来捕获空间维度的语义信息以及高帧率的快支路捕获时间维度的运动信息。
上述方法输入的模型是视频帧或视频帧中的光流图。由于受背景扰动、光照变化以及目标外观差异的影响,完整输入的视频帧或光流图中存在一些信息冗余。近些年一些学者开始使用视频中目标的骨架序列信息来识别目标的行为,其识别方法大致分为4类:基于循环神经网络(recurrent neural network,RNN)、基于CNN、基于图卷积网络(graph convolutional network,GCN)以及基于Transformer的方法。ZHU等[14]将每个关键点形成的时间序列输入到RNN中,同时使用稀疏连接的全连接层来融合不同RNN输出的特征,最后使用函数对提取的特征进行分类。LI等[15]使用双流卷积神经网络提取骨架伪图像在时间和空间上的局部特征,最后融合时空维度的特征来识别行为。文献[6]提出了ST-GCN,首次将GCN用于骨架行为识别。ST-GCN模型对帧内骨架拓扑结构进行空间卷积,对帧间关键点序列进行时间卷积来提取时空维度的局部特征。SHI等[16]在ST-GCN的基础上提出了一种双流自适应图卷积网络(two-stream adaptive graph convolutional networks,2s-AGCN),其中自适应指图的拓扑结构可以由梯度反传算法进行端到端的学习。这种数据驱动的方法增加了图构造的灵活性,使模型可以适应各种数据版本。PLIZZARI等[17]提出时空Transformer (spatial temporal transformer,ST-TR),该方法将骨架的拓扑结构和关键点形成的时间序列分别输入Transformer模型以提取时空维度的全局特征。ZHANG等[18]提出STST模型,在空间维度和时间维度上分别使用特定的Transformer模型来捕捉整个骨架的动态变化,同时提出自监督学习模块提高模型对于残缺的骨架结构和扰乱的视频帧序列等情况的鲁棒性。
1.2 动物行为识别
动物行为识别任务是识别一段视频中目标动物的行为类别,其方法可分为单阶段和两阶段方法。单阶段方法直接使用3D (或2D)卷积核来提取视频中目标动物行为的局部特征,再使用全连接层输出对应的行为类别,缺点是很多与行为无关的冗余信息也会输入到模型当中,增加了模型参数量和运算量,且易导致模型的误识别。文献[4]构建了家猪的行为识别数据集PBVD-5,其包含5类行为:喂食、躺卧、运动、抓及攀爬。同时,基于SlowFast[13]的时空卷积网络对家猪行为进行建模分析。两阶段方法首先从视频的每一帧提取目标的关键点并得到骨架序列,再对目标的骨架信息进行分析得到行为类别,缺点是需耗费大量的时间。文献[5]提出恒河猴3D姿态估计数据集,需先对3D姿态信息进行降维,再对降维后的特征进行聚类分析得到恒河猴的6类行为:站立、行走、攀爬、颠倒攀爬、坐下和跳跃。
2 方 法
2.1 问题分析
临床前药物安全评价场景下,猴类动物行为识别任务有如下特点:
(1) 猴类动物行为识别数据集中的连续视频帧包含冗余信息。在临床前药物安全评价中,猴类动物通常在室内的铁笼中,导致行为识别数据集中的场景较单一,视频背景扰动和光照变化小。此外,相同品种不同猴类动物个体的外观非常相似,如恒河猴的毛发普遍呈棕黄色,食蟹猴的毛发一般为灰白色。如图1所示,视频数据中背景扰动、光照变化以及目标外观差异较小,导致连续的视频帧中包含冗余信息。特别地,一些运动量较小的行为(如蹲坐、扶立)对应的连续视频帧序列冗余信息较明显。
(2) 猴类动物行为识别需要考虑时空维度的全局信息。在临床前药物安全评价场景下,一些猴类动作定义需要考虑全局的空间和时间信息。特别地,在时间维度上,攀爬行为初始动作类似于蹲坐或扶立,训练时提取前几帧的特征可能会导致模型误识别,如图1(c)中向下攀爬行为的前四帧和图1(a)中蹲坐行为类似。空间维度上,如蹲坐行为的脚踝和臀部对应的关键点联系紧密,然而在ST-GCN中无法建模骨架上非直接连接的关键点之间的联系。此外,一些动作需要考虑骨架上不同关键点在不同时刻的联系,如四肢触地行走(行走动作可以视为四肢关键点的周期性运动)和仅下肢触地扶立的局部特征相似,但在空间行走时四肢距离更近,且行走动作具有时序信息。现有的一些基于Transformer的骨架行为识别方法[17-18]针对时空维度分别提取全局特征,无法建模骨架不同关键点在不同时刻的联系。
与视频帧序列不同的是,骨架时序信息只关注目标的肢体动作,丢弃了背景以及外观中的冗余信息,降低了行为识别任务对模型参数量的要求。因此,本文使用猴类动物的骨架序列信息进行行为识别,并针对行为的时空整体性问题,进一步提出GSTEN对猴类动物的行为进行整体性建模分析。

图1 猴类动物行为识别数据集中的不同行为样本((a)蹲坐;(b)扶立;(c)向下攀爬;(d)悬挂)
2.2 骨架序列信息提取


经逐帧的骨架信息提取,可得到每一个视频样本的骨架序列表示。假设视频的帧数为,关键点个数为,则每一个视频样本的骨架序列信息可表示为一个维度为××的张量,其中=3表示每一个关键点的特征维数。考虑到猴类动物的动作普遍较快,需统一设置=150,不足帧的样本视频通过从头回放的方式进行填充,超过帧的样本视频直接截取前帧作为输入。
2.3 全局时空编码器
本文利用GSTE来提取猴类动物骨架序列信息的全局特征。与原始的Transformer[7]不同的是,GSTE首先舍弃了Transformer中的解码器,只使用串联的编码器来提取全局时空特征。其次,在每个单独的编码器中使用一个线性变换来连接自注意力(self-Attention,SA)模块和前馈神经网络(FeedForward network,FFN),该线性变换将SA特征变换为原始输入特征的维数,变换后的特征在后续的FFN中完成“编码-解码”过程。因此,本文提出的GSTE在单个编码器内部完成“编码器编码特征-解码器解码推理”的过程。此外,还设计了一个全局标志生成器(global token generator,GTG)来处理骨架序列。与现有的一些基于Transformer的骨架行为识别方法(如ST-TR[17]和STST[18]模型)分别从空间和时间维度提取全局特征不同的是,GTG将骨架序列信息视为一个整体。GTG不仅考虑了同一时刻的不同关键点以及同一关键点在不同时刻之间的联系,还对骨架空间拓扑结构处于不同时刻的不同关键点之间的联系做了建模分析。总之,GSTE在单个编码器中完成了“编码-解码”过程,同时使用GTG进一步增强编码器对骨架序列整体性建模分析的能力。

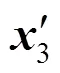


图2 全局时空编码器
2.4 全局时空编码网络
本文在人体骨架行为识别模型ST-GCN[6]的基础上提出GSTEN。如图3所示,GSTEN由4部分组成,主网络为ST-GCN模型,其负责提取骨架序列信息时空维度的局部特征来识别简单动作;在ST-GCN模型上并行插入全局标志生成器和个串联的轻量级模块GSTE,GSTE针对骨架序列信息时空维度的全局特征进行建模分析,进而识别一些困难动作;最后融合提取到的全局特征和局部特征,将其输入到行为分类器中进行分类。

图3 全局时空编码网络


其中,为序列拼接。
猴类动物骨架序列信息通过ST-GCN支路可以提取时空维度的局部特征,通过GSTE支路提取全局特征,最后对两类特征加权融合进行行为识别。这种并行连接GSTE的网络结构在几乎不增加模型参数量的情况下,可以显著提高行为识别准确率。具体地,ST-GCN模型由10个串联连接的时空卷积模块(spatial temporal convolution module,STCM)组成。每一个STCM包括空间卷积和时间卷积。空间卷积可为
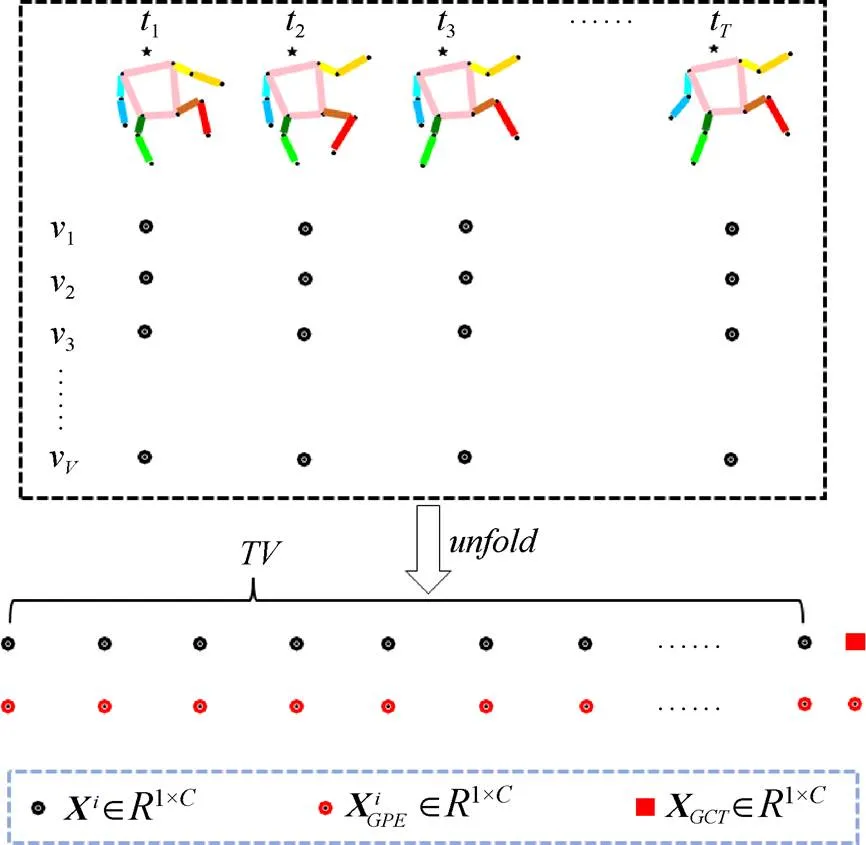
图4 全局标志生成器



其中,为某一个关键点的时序信息;为时间卷积参数矩阵;d为时间卷积变换后的特征维数。在本文的猴类动物场景中,节点相关性矩阵为
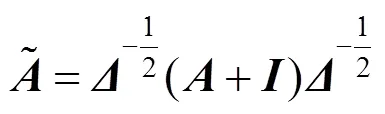

2.5 损失函数


3 实 验
3.1 数据集和评价指标
本文建立的猴类动物行为识别数据集见表1,包括卧倒、蹲坐、行走、向上跳跃、向下跳跃、向上攀爬、向下攀爬、悬挂、扶立以及攀附10类行为。将采集的猴类动物行为识别数据集按照3∶1的比例随机划分为训练集和验证集。评价指标采用准确率=N/×100%,其中为验证集的总样本数,N为验证集中模型预测正确的样本数。

表1 猴类动物行为识别数据集
3.2 参数设置
实验在Geforce RTX2080Ti´8的单节点服务器上完成,使用Pytorch v1.8深度学习框架进行训练。Epoch数设置为100,batch-size为16。初始学习率为0.1,随后在40个epoch和80个epoch处衰减为原来的0.1倍。在全局时空编码网络GSTEN中如果没有特别说明,则ST-GCN支路特征和GSTE支路特征的加权和系数为0.5,即merge=-GCN+×GSTE,其中-GCN和分别表示ST-GCN分支提取的局部时空特征和GSTE分支提取的全局时空特征。
3.3 对比实验
本文在猴类动物行为识别数据集上对比了基于视频帧的行为识别方法、基于骨架序列的行为识别方法以及GSTEN (表2),一些基于视频帧的方法如SlowFast[13]等在数据集上的性能指标明显低于骨架行为识别模型ST-GCN。I3D[21]方法的性能优于ST-GCN,但模型的参数量和运算量更多。特别地,TimeSformer[22]模型的准确率达到最高的77.16%,但该模型的参数量和运算量远多于其他基于视频帧以及基于骨架序列的方法。本文提出的GSTEN在ST-GCN模型的基础上并行添加GSTE。实验结果表明,GSTEN在基本不增加模型参数量和运算量的同时可以显著提高基准模型ST-GCN的准确率。此外,当GSTEN搭配2个GSTE时,不仅准确率比ST-GCN高6.79%,且优于大部分基于视频帧和基于骨架序列的行为识别方法。总之,本文构建的GSTEN在猴类动物行为识别任务上具有准确率高、参数少以及运算量小等优势。

表2 不同方法在猴类动物行为识别数据集上的实验结果
注:加粗数据为最优值
3.4 消融实验
为了验证局部特征和全局特征在猴类动物行为识别任务上的适用性,本文对GSTEN的各部分结构进行了消融实验(表3),并分别对比了与只使用ST-GCN分支提取局部特征、只使用GSTE分支提取全局特征以及使用GSTEN模型融合局部特征和全局特征三者之间的性能差异。实验结果表明,Exp-2中使用1个GSTE提取全局特征时,模型的准确率低于Exp-1中使用ST-GCN提取局部特征的结果。Exp-3中使用2个GSTE时,模型对猴类动物行为的建模分析能力超过了ST-GCN。当Exp-4和Exp-5中全局特征和局部特征融合时,GSTEN模型超过单一局部特征或全局特征的结果,且性能随着GSTE数量增加而提升,这表明全局特征和局部特征融合的结果比单一特征更适合猴类动物的行为识别。

表3 GSTEN消融实验
注:加粗数据为最优值
在表3的Exp-5基础上进一步探索ST-GCN支路和GSTE支路的加权和系数对构建的GSTEN性能的影响。如图5所示,当<0.5时,ST-GCN分支的特征占比较大,GSTEN模型的准确率随着增大而提高;当=0.5时,GSTEN模型准确率达到最高的76.54%;当0.5<<1.0时,GSTEN模型准确率接近饱和;当>1.0时,GSTE分支的特征占据主导地位,此时GSTEN模型准确率稍有下降。以上结果说明GSTEN中ST-GCN分支重要性较GSTE高。原因可能是GSTE分支参数较少,在建模骨架序列所有关键点之间的联系时出现欠拟合的情况。

图5 基于不同系数w的GSTEN准确率
此外,为了验证本文提出的GSTE具有即插即用的特性,在不同的骨架行为识别模型上并行插入全局标志生成器和2个GSTE (表4),由于ST-GCN模型缺乏时空维度整体性建模分析的能力,GSTE应用在ST-GCN上可以显著提升模型的行为识别准确率。当GSTE应用在具有全局空间建模能力的AGCN上时,准确率相较于ST-GCN提升幅度略有下降,分别为2.47%和3.09%。特别地,当MS-G3D-Bone添加GSTE之后模型的准确率达到78.40%,超过本文提出的GSTEN和表2中准确率最高的CTR-GCN[26]方法。以上结果表明,GSTE可以作为即插即用的轻量级模块配合不同的骨架行为识别模型使用,并且构建的新网络在基本不增加模型参数量的情况下,显著提高基准模型在猴类动物行为识别的准确率。

表4 GSTE对不同基准模型的影响
本文进一步对比了不同数量的GSTE对模型的影响。表5中Exp-1,Exp-5和Exp-6中GSTE的数量过少或过多,均会对模型性能产生影响。Exp-2中使用2个GSTE提取全局特征时,模型准确率指标达到最高的71.60%。

表5 GSTE消融实验
注:加粗数据为最优值
4 结束语
本文从实际临床前药物安全评价场景出发,使用深度学习方法对猴类动物行为识别任务进行了研究,对人工智能方法在药物安全评价中的应用进行了积极地探索。首先分析了临床前药物安全评价场景下,现有人类行为识别领域基于视频帧和基于骨架序列的方法应用到猴类动物的缺陷。并基于这些缺陷,提出了一种基于GSTEN的猴类动物行为识别方法,即插即用的轻量级GSTE可以搭配骨架行为识别模型ST-GCN使用,在不增加模型参数量的同时提高模型在时空维度整体性建模分析的能力。最后在生成的猴类动物行为识别数据集上进行了实验,对比了基于视频帧的行为识别方法、基于骨架序列的行为识别方法以及本文提出的GSTEN方法,结果充分验证了本文方法在临床前药物安全评价场景猴类动物行为识别任务上具有准确率高、参数少等优势。
对于骨架行为识别方法而言,其前提条件是获取带有骨架序列标签的训练数据。借助于训练好的姿态估计模型,可以大规模获取行为视频中每个猴类动物个体的骨架信息。然而,使用姿态估计模型提取骨架信息再进行行为识别的两阶段过程比较耗时,且对于不同的临床前药物安全评价场景,需要训练鲁棒性和泛化性更强的姿态估计模型。因此,未来工作的一个重点方向是探索更有效的骨架信息获取方法,如使用一些穿戴式设备[28]直接获取猴类动物的骨架信息。
[1] PLAGENHOEF M R, CALLAHAN P M, BECK W D, et al. Aged rhesus monkeys: cognitive performance categorizations and preclinical drug testing[J]. Neuropharmacology, 2021, 187: 108489.
[2] BANKS M L, HUTSELL B A, BLOUGH B E, et al. Preclinical assessment of lisdexamfetamine as an agonist medication candidate for cocaine addiction: effects in rhesus monkeys trained to discriminate cocaine or to self-administer cocaine in a cocaine versus food choice procedure[J]. International Journal of Neuropsychopharmacology, 2015, 18(8): pyv009.
[3] EBELING M, KÜNG E, SEE A, et al. Genome-based analysis of the nonhuman primate Macaca fascicularis as a model for drug safety assessment[J]. Genome Research, 2011, 21(10): 1746-1756.
[4] LI D, ZHANG K F, LI Z B, et al. A spatiotemporal convolutional network for multi-behavior recognition of pigs[J]. Sensors: Basel, Switzerland, 2020, 20(8): 2381.
[5] BALA P C, EISENREICH B R, YOO S B M, et al. Automated markerless pose estimation in freely moving macaques with OpenMonkeyStudio[J]. Nature Communications, 2020, 11: 4560.
[6] YAN S J, XIONG Y J, LIN D H. Spatial temporal graph convolutional networks for skeleton-based action recognition[EB/OL]. [2021-06-10]. https://arxiv.org/pdf/1801. 07455.pdf.
[7] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all You need[C]//The 31st International Conference on Neural Information Processing Systems. New York: ACM Press, 2017: 6000-6010.
[8] SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos[C]// The 27th International Conference on Neural Information Processing Systems - Volume 1. New York: ACM Press, 2014: 568-576.
[9] WANG L M, XIONG Y J, WANG Z, et al. Temporal segment networks: towards good practices for deep action recognition[M]//Computer Vision - ECCV 2016. Cham: Springer International Publishing, 2016: 20-36.
[10] HARA K, KATAOKA H, SATOH Y. Learning spatio-temporal features with 3D residual networks for action recognition[C]// 2017 IEEE International Conference on Computer Vision Workshops. New York: IEEE Press, 2017: 3154-3160.
[11] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2016: 770-778.
[12] TRAN D, WANG H, TORRESANI L, et al. A closer look at spatiotemporal convolutions for action recognition[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 6450-6459.
[13] FEICHTENHOFER C, FAN H Q, MALIK J, et al. SlowFast networks for video recognition[C]//2019 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2019: 6201-6210.
[14] ZHU W T, LAN C L, XING J L, et al. Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks[C]//The 13th AAAI Conference on Artificial Intelligence. New York: ACM Press, 2016: 3697-3703.
[15] LI C, ZHONG Q Y, XIE D, et al. Skeleton-based action recognition with convolutional neural networks[C]//2017 IEEE International Conference on Multimedia & Expo Workshops. New York: IEEE Press, 2017: 597-600.
[16] SHI L, ZHANG Y F, CHENG J, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2019: 12018-12027.
[17] PLIZZARI C, CANNICI M, MATTEUCCI M. Spatial temporal transformer network for skeleton-based action recognition[M]//Pattern Recognition. ICPR International Workshops and Challenges. Cham: Springer International Publishing, 2021: 694-701.
[18] ZHANG Y H, WU B, LI W, et al. STST: spatial-temporal specialized transformer for skeleton-based action recognition[C]//MM '21: The 29th ACM International Conference on Multimedia. New York: ACM Press, 2021: 3229-3237.
[19] XIAO B, WU H P, WEI Y C. Simple baselines for human pose estimation and tracking[M]//Computer Vision - ECCV 2018. Cham: Springer International Publishing, 2018: 472-487.
[20] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context[M]//Computer Vision - ECCV 2014. Cham: Springer International Publishing, 2014: 740-755.
[21] CARREIRA J, ZISSERMAN A. Quo vadis, action recognition? A new model and the kinetics dataset[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2017: 4724-4733.
[22] BERTASIUS G, WANG H, TORRESANI L. Is space-time attention all You need for video understanding? [EB/OL]. [2021-06-09]. https://arxiv.org/abs/2102.05095.
[23] FEICHTENHOFER C. X3D: expanding architectures for efficient video recognition[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press: 200-210.
[24] FAN H Q, XIONG B, MANGALAM K, et al. Multiscale vision transformers[C]//2021 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2021: 6804-6815.
[25] LIU Z Y, ZHANG H W, CHEN Z H, et al. Disentangling and unifying graph convolutions for skeleton-based action recognition[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2020: 140-149.
[26] CHEN Y X, ZHANG Z Q, YUAN C F, et al. Channel-wise topology refinement graph convolution for skeleton-based action recognition[C]//2021 IEEE/CVF International Conference on Computer Vision. New York: IEEE Press, 2021: 13339-13348.
[27] LIU Z Y, ZHANG H W, CHEN Z H, et al. Revisiting skeleton-based action recognition[C]//The IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2022: 2969-2978.
[28] 邓颖, 吴华瑞, 孙想. 基于机器视觉和穿戴式设备感知的村镇老年人跌倒监测方法[J]. 西南大学学报: 自然科学版, 2021, 43(11): 186-194.
DENG Y, WU H R, SUN X. Design of a real-time human falling monitoring method for elderly people in villages and towns based on multi-dimensional data analysis[J]. Journal of Southwest University: Natural Science Edition, 2021, 43(11): 186-194 (in Chinese).
Monkey action recognition based on global spatiotemporal encode network
SUN Zheng1,2, ZHANG Su-cai3, MA Xi-bo1,2
(1. CBSR&NLPR, Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China;2. School of Artificial Intelligence, University of Chinese Academy of Sciences, Beijing 100049, China;3. JOINN Laboratories (Beijing) Co., Ltd., Beijing 100176, China)
Accurate quantification of caged monkeys’ behaviors is a primary goal for the preclinical drug safety assessment. Skeleton information is important to the analysis on the behaviors of monkeys. However, most of the current skeleton-based action recognition methods usually extract the features of the skeleton sequence in the spatial and temporal dimensions, ignoring the integrity of the skeleton topology. To address this problem, we proposed a skeleton action recognition method based on the global spatiotemporal encode network (GSTEN). Based on the spatial temporal graph convolutional network (ST-GCN), the proposed method inserted global token generator (GTG) and several global spatiotemporal encoders (GSTE) in parallel to extract the global features in the spatiotemporal dimension. To verify the performance of the proposed method, we conducted experiments on a self-built monkey action recognition dataset. The experimental results show that the proposed GSTEN could achieve an accuracy of 76.54% without increasing the number of model parameters, which was 6.79% higher than the baseline model ST-CGN.
action recognition; skeleton sequence; global spatiotemporal encode network; monkey; drug safety assessment
TP 391
10.11996/JG.j.2095-302X.2022050832
A
2095-302X(2022)05-0832-09
2022-04-15;
2022-06-03
15 April,2022;
3 June,2022
国家自然科学基金项目(82090051,81871442);中国科学院青年创新促进会(Y201930)
The Chinese National Natural Science Foundation Projects (82090051, 81871442);The Youth Innovation Promotion Association CAS (Y201930)
孙 峥(1996-),男,硕士研究生。主要研究方向为姿态估计和行为识别等。E-mail:zheng.sun@nlpr.ia.ac.cn
SUN Zheng (1996-), master student. His main research interests cover pose estimation and action recognition, etc. E-mail:zheng.sun@nlpr.ia.ac.cn
马喜波(1981-),女,研究员,博士。主要研究方向为多模态融合的医学成像方法及设备开发等。E-mail:xibo.ma@nlpr.ia.ac.cn
MA Xi-bo (1981−), researcher, Ph.D. Her main research interests cover development of multi-modal fusion medical imaging methods and equipment, etc. E-mail:xibo.ma@nlpr.ia.ac.cn
