基于运动矢量排序的视频可逆信息隐藏
2022-11-01宁志强钮可潘峰邱枫
宁志强, 钮可,2*, 潘峰,2, 邱枫
(1.武警工程大学密码工程学院, 西安 710086; 2.网络与信息安全武警部队重点实验室, 西安 710086)
信息隐藏技术利用原始载体中存在的冗余空间进行秘密信息的嵌入,并且在信息嵌入后不会引起人们的察觉[1]。按照载体与嵌入信息的关系,信息隐藏可以分为隐写术与数字水印。隐写术是隐蔽通信的重要手段,数字水印是保护版权、防伪与追踪的重要方法。按照载体的类别,信息隐藏可以分为音频信息隐藏、图像信息隐藏和视频信息隐藏等。视频信息隐藏与其他方法相比,具有隐藏容量大、隐蔽性好、应用途径广泛的优点,近年来引起了学者的关注。
目前,视频信息隐藏的常用嵌入方法有基于量化或未量化的离散余弦变换(discrete cosine transformation, DCT)系数、基于帧内/帧间预测模式和基于运动矢量的信息隐藏。在运动矢量上嵌入信息具有嵌入容量大且不易遭到破坏的特点,已经成为视频信息隐藏的主要方法之一。
传统的信息隐藏技术虽然能够完成较好的不可见性,但是在嵌入信息过程中会破坏载体,造成载体的永久性失真。为了解决这个问题,发展出了可逆信息隐藏技术。可逆信息隐藏是指接收方正确提取秘密信息后,可以利用一定的规则完全恢复载体的技术。可逆信息隐藏具有更加广泛的应用,例如:在军事视频通讯中使用可逆信息隐藏,既可以完成秘密消息的传送,又不影响正常的视频通话;在远程医疗中使用可逆信息隐藏,既可以把病人的个人信息嵌入到视频中,保护病人的隐私,又可以保证视频质量,避免由于视频质量的原因影响对病人病情的判断。
差值扩展算法(difference expansion, DE)、直方图平移算法(histogram shifting, HS)和预测误差扩展算法(prediction-error expansion, PEE)是可逆信息隐藏中常用的三种方法。像素值排序(pixel value ordering, PVO)是从PEE发展而来的一种技术[2]。在PVO中,图像被分成相同大小的非重叠块。块中的像素值按升序排列,使用第二大像素预测最大值像素,使用第二小像素预测最小值像素。计算最大(小)像素和第二大(小)像素之间的预测误差,生成预测误差直方图。利用PVO技术能够以较小的失真换取较大的嵌入容量,一个块中最多可以隐藏两位数据[3]。Ou等[4]提出了k阶运动矢量排序技术(k-pass pixel value ordering, PVO-k),把块中的k个最大(最小)像素作为嵌入单元,同时修改k个像素来嵌入一位数据。与PVO相比,具有更大的嵌入容量,但同时增大了嵌入时造成的失真。Wu等[5]考虑到每个块中的两个预测误差具有密切的相关性,将两个预测误差视为一对,并利用自适应二维直方图嵌入秘密信息。但由于嵌入容量过大,导致嵌入信息后的视觉质量较差。Lee等[6]使用不同的操作模式将秘密信息分散到两层中,第一层和第二层不存在重复。该方法能够应用到现阶段的PVO技术中,增大嵌入容量。孔咏俊等[7]提出了基于排序像素值也阶跃响应的可逆信息隐藏方案,能够在减小像素修改数量的同时增大了嵌入容量。Niu等[8]提出了一种新的视频可逆信息隐藏算法,通过改变编解码时的参考帧,克服了修改运动矢量而引起的失真漂移效应,提升了视觉质量。
PVO技术已经在图像信息隐藏发挥了重要的作用,但在视频领域中很少被使用。基于上述研究基础,现改进PVO-k技术,使其应用在视频时具有较低的失真和更好的视觉质量,设计一种基于运动矢量排序的视频可逆信息隐藏算法。本文算法将运动矢量分组,在每组中把运动矢量按升序排列,使用第二大(小)运动矢量预测最大(小)运动矢量,统计预测误差直方图,利用PEE嵌入和提取信息,获得较好的视频质量。同时融入改变参考帧的方法,进一步改善视频质量。
1 算法理论基础
1.1 运动矢量和运动补偿
在继承了以往标准中成熟的标准编码框架的同时,H.264标准支持可变大小的运动矢量(motion vector, mv)和1/4像素精度的运动估计。每个16×16大小的宏块有4种分割方式:1个16×16、2个16×8、2个8×16、4个8×8。每个8×8的子宏块可以继续进行分割:1个8×8、2个4×8、2个8×4和4个4×4。不同的分割方式有其对应的运动补偿。如图1所示,这种分割下的运动补偿称为树状结构运动补偿[9]。
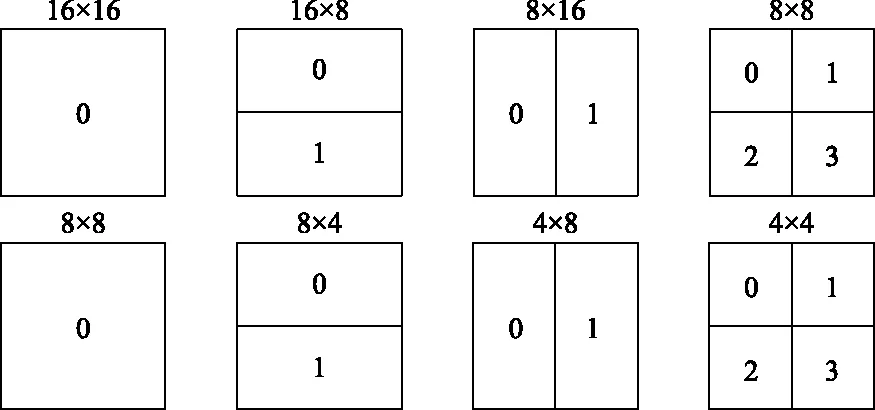
图1 宏块及子宏块分割Fig.1 Macroblock and sub-macroblock partitions
1.2 运动矢量排序
由于相邻运动矢量的具有较强的相关性,将运动矢量分组后,同一组中的运动矢量可能存在多个相同的最值。所以,本文算法以k个最值作为单元,更适用于在运动矢量中嵌入信息。运动矢量可分为横向分量和纵向分量,两者均能嵌入信息。本文中只利用横向运动矢量进行说明,纵向运动矢量的嵌入方式与横向运动矢量相同。
具体来说,当排序序列中存在k个最大(小)横向分量时,可以取第二大(小)横向分量来预测最大(小)运动矢量。为了保证嵌入信息后的排列顺序不变,必须同时修改所有最大(小)值横向分量。例如,在分块中存在下列排序序列。
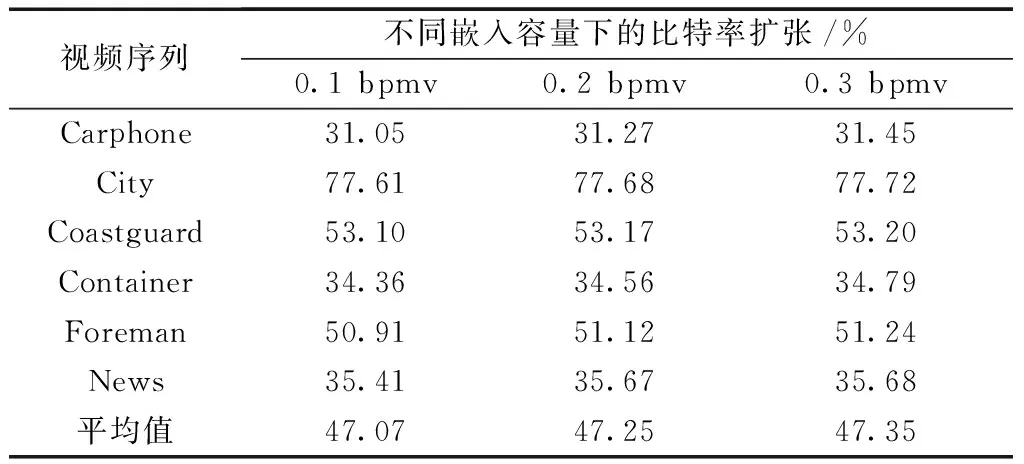
mvx1=…mvxb =…=mvxn (1) 式(1)中:mvx为运动矢量的横向分量。序列中存在a个最大横向分量和b个最小横向分量。在数据嵌入时,会修改所有的最大值横向分量{mvx(n-a+1),mvx(n-a+2),…,mvxn}和最小横向分量{mvx1,mvx2,…,mvxb},同时保持其他分量不变。序列中的最大横向分量在嵌入信息时的变换方法,可以通过式(2)得 (2) 式(2)中:x为预测误差,且x=mvx(n-k+1)-mvx(n-k)>0,m∈{0,1}是待嵌入的秘密信息。当k=1时,序列中只存在一个最大分量,只需修改这个最大值便可嵌入信息;当k=2时,序列中存在两个相同的最大分量,必须同时修改这两个最大值;当k>2时,序列中最大分量的个数大于2个,则跳过此分组,不进行任何修改。嵌入信息时,根据秘密信息的大小和可接受的最大失真程度确定k的值。k越大,嵌入容量越大,嵌入后的失真越大。 如图2(a)所示,在H.264压缩规则中,当前帧的解码依赖于前一帧或后一帧。基于运动矢量的信息隐藏会修改运动矢量,当前帧在解码时参考了已经被修改的前一帧,从而造成错误解码。特别是在基线编码中,第一帧为I帧,其余全部为P帧,因此运动矢量的修改会造成错误积累。P帧越多,视频的视觉质量就越差。 H.264编码的图像存储在编码器的参考缓冲区中,解码器有相应的参考图像列表用于补偿帧间预测[10]。与以前的编码标准不同,它在多个参考帧上使用预测技术,最多允许从15帧中选择1帧或2帧。如图2(b)所示,为了有效防止由于运动矢量修改而引起的误差传播和积累,可以指定编解码时的参考帧。参考帧不被嵌入信息,只用于后续若干帧的解码。由于参考帧的运动矢量没有被修改,错误被限制在有限帧中,阻断了错误积累。指定参考帧的间隔k可以灵活选择,k越大,嵌入容量越大,引起的失真漂移越大。 图2 参考帧的变换Fig.2 The transformation of the reference frame 本算法的流程框架如图3所示。视频发送方得到原始视频每一帧的运动矢量。而后对运动矢量分组和排序,按照规则嵌入信息。最后对视频进行量化和编码,得到二进制码流。视频接收方接收到视频后,得到含有秘密信息的运动矢量,再进行秘密信息的提取与运动矢量的恢复,最后利用恢复的运动矢量解码视频。根据设计的算法,接收方可以正确提取出秘密信息,并完全恢复原始视频。 图3 算法流程框架图Fig.3 Framework diagram of algorithm flow 根据H.264视频编码器的特点,把一帧中全部的运动矢量分组,便于排序和嵌入信息。 在H.264编码规则中,运动矢量最基本的单位是16×16大小的宏块,16×16的宏块还可以继续分割成更小精度的运动矢量。为增大嵌入容量、减小失真,本文在嵌入信息时尽可能利用所有的运动矢量宏块,并对不同类型的运动矢量设计分组规则。如表1所示,若宏块大小为16×16、16×8或8×16,则相邻两个宏块内的所有运动矢量为一组,对组中的运动矢量排序并嵌入信息;若宏块被分割成8×8及更小的运动矢量,则该宏块内的所有运动矢量为一组,对组中的运动矢量排序并嵌入信息。 表1 运动矢量分组规则Table 1 Motion vector grouping rules 对运动矢量分组后,在每个分组中进行运动矢量的排序并嵌入信息。由于H.264/AVC中运动矢量为1/4像素,下列mvx均指4倍的运动矢量横向分量。 步骤1首先,对于某一分组中的n个横向分量,把它们按照升序排列,得到 mvx1=…=mvxb mvx(n-a+1)=…=mvxn (3) 式(3)中:a和b分别为最大和最小的横向分量个数,满足a>0,b>0且a+b≤n。 步骤2利用mvx(n-a)预测mvx(n-a+1),用mvx(b+1)预测mvxb,得到最大横向分量的预测误差x和最小横向分量的预测误差y: x=mvx(n-a+1)-mvx(n-a)≥1 (4) y=mvxb-mvx(b+1)≤-1 (5) 步骤3若a=k或b=k,则该分组按照下列4种情况嵌入信息。 (1)当a=k,b≠k时,只能修改最大值来嵌入信息,设i∈{1,2,…,n},则mvxi的值为 (6) 式(6)中:x为根据式(4)得到的预测误差;m为待嵌入的比特位,m∈{0,1}。若x=1,则可以向该运动矢量分组中嵌入1bit信息。 (2)当a≠k,b=k时,只能修改最小值来嵌入信息,则mvxi为 (7) 式(7)中:y为根据式(5)得到的预测误差,若y=-1,则可以向该运动矢量分组中嵌入1bit信息。 (3)当a=b=k,n>2k时,最大值和最小值都可以嵌入信息,mvxi的值为 (8) 此时可以在横向分量分组中嵌入最多2bit信息。 (4)当a=b=k,n=2k时,分组中的横向分量只存在最大值与最小值。此时只在最大值中嵌入信息,利用最小值预测最大值。 步骤4重复步骤1~步骤3,直到在所有分组中嵌入信息。 步骤1把嵌入信息后的横向分量按升序排列,其排列顺序与嵌入数据前保持不变。在解码端按式(9)把分量升序排列: mv′x1=…=mv′xb mv′x(n-a+1)=…=mv′xn (9) 步骤2利用mv′x(n-a)预测mv′x(n-a+1),用mv′x(b+1)预测mv′xb,得到最大横向分量的预测误差x′和最小横向分量的预测误差y′分别为 x′=mv′x(n-a+1)-mv′x(n-a)≥1 (10) y′=mv′xb-mv′x(b+1)≤-1 (11) 步骤3在嵌入信息时同时修改了所有的最大值或最小值,所以a和b的值是不变的。可以根据a和b判断是否嵌入了信息。并利用排列顺序和a、b的不变性,完全提取出秘密信息。与嵌入过程相同,提取过程也分为4种情况。 (1)当a=k,b≠k时,mv′xi可以恢复为 (12) 式(12)中:x′是根据式(10)得到的预测误差;x′为1和2时,嵌入的信息分别为0和1。 (2)当a≠k,b=k时,mv′xi可以恢复为 (13) 式(13)中:y′为根据式(11)得到的预测误差;y′为-1和-2时,嵌入的信息分别为0和1。 (3)当a=b=k,n>2k,mv′xi可以恢复为 (14) 当(x′,y′)为(1,-1)、(1,-2)、(2,-1)和(2,-2)时,嵌入的信息分别为“00”“01”“10”和“11”。 (4)当a=b=k,n=2k时,恢复横向分量和提取信息的方法与情况(1)相同。 步骤4重复步骤1~步骤3,直到提取所有信息和恢复所有的横向分量。 使用H.264编解码器,在MATLAB平台上进行实验。测试视频为6个QCIF(176×144)的YUV视频序列:Carphone, City, Coastguard, Container, Foreman和News。每个视频取前150 帧,第一帧为I帧,其他全部为P帧,量化参数(quant param, QP)值为27。把生成的随机二进制数据当作秘密信息嵌入。为验证算法的有效性,选取文献[11-13]这三个相同类型的视频可逆信息隐藏算法进行对比。 为验证本文算法的不可见性,分别从解码后视频的主观视觉感受和客观评价标准两方面进行分析。 图4分别是视频序列Carphone和News原始视频第150帧的亮度分量与嵌入信息后的对应帧的亮度分量。通过对比,从主观视觉上并未发现视频帧有改变。 图4 第150帧亮度分量对比Fig.4 Comparison of brightness components at frame 150 峰值信噪比(peak signal-to-noise ratio, PSNR)是当前常用的图像客观质量评价标准,表示为 (15) 最小均方误差MSE为 (16) 式(16)中:I1和I2为两个M×N大小的图像。若I1和I2完全相同,则MSE趋近于0,PSNR为无穷大。在图像中,PSNR通常在30~50[14]。结构相似性 (structuralsimilarityindex,SSIM)是另一种衡量人眼视觉质量的重要工具,是基于亮度、对比度和结构建立的[15]。本文引入ΔPSNR和ΔSSIM来评价嵌入信息对视频质量的影响。ΔPSNR和ΔSSIM越小,代表本算法对视频质量的影响就越小。 ΔPSNR=PSNRp-PSNRs (17) ΔSSIM=SSIMp-SSIMs (18) 式中:PSNRp和SSIMp分别为未嵌入信息的压缩视频的峰值信噪比和结构相似性;PSNRs和SSIMs为本算法得到的峰值信噪比和结构相似性。图5为150 帧视频序列的PSNR,图例为各视频序列的名称。表2为视频序列的ΔPSNR和ΔSSIM的值。 由图5和表2可以看出,本文算法在6个视频中的平均PSNR等于37.208,能够满足人眼对视频质量的要求。与对比文献相比,平均ΔPSNR分别降低了80.75%、78.20%和59.36%。平均ΔSSIM分别降低了82.63%、68.52%和41.38%。 图5 150帧视频序列的PSNRFig.5 PSNR of 150-frame video sequence 表2 视觉质量对比Table 2 Comparison of visual quality 对于嵌入容量的分析,采用每帧嵌入比特数(bits per frame, bpf)来进行评价。表3是视频序列的嵌入容量对比。从表3中可以看出,本算法的平均嵌入容量为41.05 bpf,与文献[11]和文献[12]相比增大了25.16%与47.28%,与文献[13]相比几乎相同。本算法具有良好的嵌入容量,能够满足应用场景的需求。 表3 嵌入容量对比Table 3 Comparison of embedding capacity 使用比特增长率来分析视频在嵌入信息前后的码率变化。由于比特率与视频的运动剧烈程度密切相关,且不同运动剧烈的视频的运动矢量数量较多,故在此利用每运动矢量嵌入比特数(bits per motion vector, bpmv)来衡量嵌入容量更恰当。表4是嵌入容量分别为0.1 bpmv、0.2 bpmv和0.3 bpmv时比特率的扩张对比。 表4 不同嵌入容量下的比特率扩张Table 4 Bit rate expansion under different embedding capacities 通过实验发现,本算法的比特率扩张较大。这是使用改变参考帧的技术所造成的结果。未改变参考帧时,后一帧以前一帧为参考,相邻两帧图像内容相差较小,得到的运动矢量数值也较小,编码得到的比特流较短。改变参考帧后,后一帧可能会以前K帧为参考,编码帧与参考帧之间内容相差较大,得到的运动矢量数值较大,编码得到的比特流较长,使比特率扩张变大。在今后的工作中,可以尝试对改变参考帧的技术加以改进,降低比特率的增长。 利用运动矢量分组与排序,微调最大或最小运动矢量,实现了信息的嵌入与提取。通过改变参考帧,进一步提高了解码后视频的视觉质量。实验证明,在提取信息后能够完全恢复载体,嵌入容量能够满足应用场景的需求。本文算法的最大优点在于视觉质量较好,适用于医学、军事等对视频质量要求较高的场合。 未来,可以在DCT系数中使用排序的方法嵌入信息,也可以将本算法拓展到密文域可逆信息隐藏中。1.3 参考帧变换
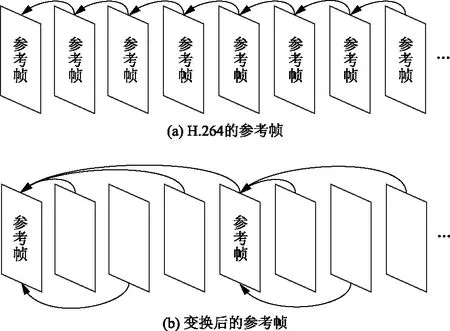
2 算法设计

2.1 运动矢量分组

2.2 嵌入流程
2.3 提取流程
3 实验结果
3.1 不可见性分析

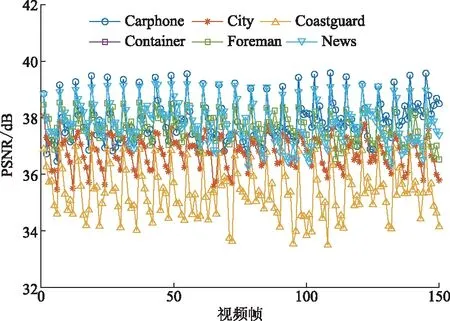
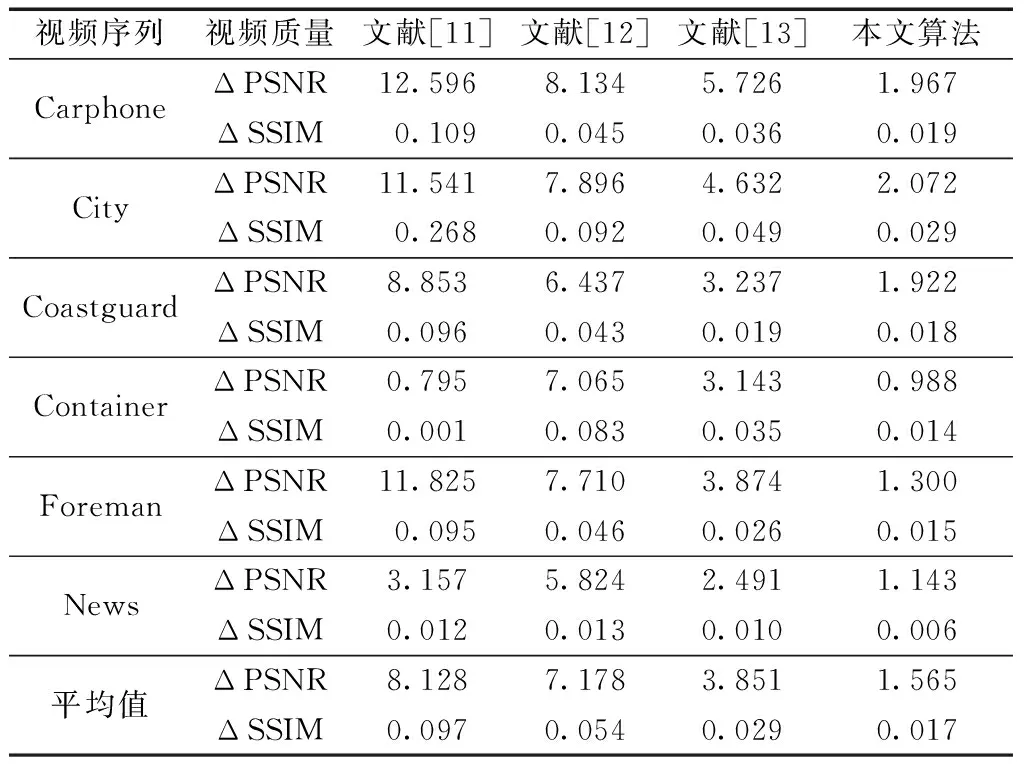
3.2 嵌入容量分析

3.3 比特率分析
4 结论
