基于语料关联生成的知识增强型BERT
2022-10-31卢嘉荣肖红姜文超杨建仁王涛
卢嘉荣,肖红,姜文超,,杨建仁,王涛
(1.广东工业大学计算机学院,广东 广州 510006;2.广州云硕科技发展有限公司,广东 广州 511458)
0 引言
自然语言处理是语言学领域的重要分支,近年来随着人工智能技术对自然语言处理研究的逐渐深入和计算机硬件性能的飞速提升,诞生了许多用于自然语言处理的神经网络模型,如ELMo[1]、OpenAI GPT[2]及BERT[3]等.该类模型拥有优秀的自然语言理解与信息处理能力,远超N-Gram[4]、决策树[5]、最大熵[6]等传统概率学模型[7].
BERT作为近年主流的自然语言理解模型,其在多个开放领域任务中取得了较好的性能.BERT的神经网络层级结构由transformer的encoder与self-attention[8]自注意力机制组成,BERT的Base模型具备12层上述结构,从而构成深层神经网络.BERT的主要贡献在于推广了预训练模型两步法思路:首先使用大量语料训练模型参数,使其获得普遍语境下的知识与语言认知能力;然后使用先前的预训练参数对下游任务进行微调.预训练(pre-train)与微调(fine-tune)两步走的策略使BERT在2018年成为在多个开放领域任务榜单上的最佳模型.
但是,BERT并没有解决预训练模型的一些常见问题,比如,受限于预训练语料的规模与特性及模型本身的学习能力,在不同的适用场景中仍存在较大局限性.为了提升BERT的精度性能,多个工作开始以BERT为基础进行调整与优化,具体优化方向包括调整预训练过程、改进模型结构、引入外部知识等.
首先,在调整预训练过程方向上,通过改进pre-train阶段的训练工作,调整MLM(masked language model)为WWM(whole word mask)的Baidu-ERNIE[9]及BERT-WWM[10].Baidu-ERNIE与BERT-WWM通过将BERT的MLM训练逐一遮蔽单个字符的方式,更改为遮蔽一个完整的中文词语,并借助规模更大的中文语料进行模型训练.RoBERTa[11]则是删除BERT的NSP训练,并采用更长的训练时间以及更多更长的句子进行模型训练.
其次,在模型结构改进方向上,XLNet[12]采用Transformer-XL[13]替代BERT的Transformer结构,增加更多数据进行预训练.而T5模型[14]使用Decoder-Encoder结构替代BERT的Encoder结构,并通过规模更大、数据更为纯净的Colossal Clean Crawled Corpus数据集[14]对模型进行精细训练与调整,从而在一系列下游任务中成为目前的最佳模型;最后,在引入外部知识方向上,相对于清晰且结构化的显性知识,预训练让模型可从大量语料中获得模糊的隐性知识.而为了解决BERT缺少显性知识的问题,通过将显性知识融入到模型中,可以在一定程度上提高模型的泛化能力,增强模型的鲁棒性[15],引入外部显性知识的模型主要有THU-ERNIE[16]、KnowBERT[17]、K-BERT[18]等.
此外,在引入外部知识的优化方法中,根据引入知识的阶段不同,又分为pre-train与fine-tune两类.其中THU-ERNIE与KnowBERT选择在模型的pre-train阶段进行知识引入,将知识实体通过word2vec[19]与TransE[20]进行编码,输入其各自的融合层结构中,叠加至深层神经网络中实现知识注入.K-BERT选择在fine-tune阶段进行知识增强,相比于ERNIE与KnowBERT在pre-train阶段进行知识增强,K-BERT在fine-tune阶段添加的显性知识可以快速更换不同领域相关的知识库,在各专业领域的下游任务中获得性能提升[21].与ERNIE与KnowBERT等在pre-train阶段进行知识增强的模型相比,K-BERT模型可以免去预训练阶段的知识导入,减少模型对计算资源的额外需求.但是K-BERT模型的知识增强方法仍存在以下3个问题:
1)显性知识与原本语句产生关联的语句树无法让BERT模型直接进行训练;
2)采用可视化矩阵的数据解析方法存在过多的信息冗余;
3)解码语句树的可视化矩阵随着输入句子长度增加,其计算资源需求指数式增长,注入知识与训练需要更长的时间.
针对上述问题,提出一种基于语料关联生成的知识增强型BERT模型(corpus association generation based knowledge enhanced BERT,CAGBERT),CAGBERT将知识图谱的异构数据转换为序列结构引入至模型训练中,并基于语义关联引入显性知识,从而进一步提升模型精度和性能,在知识增强及微调训练两方面有效减少模型训练与计算耗时.以LCQMC、XNLI等6个公开数据集进行实验分析,结果表明在下游任务中准确度比BERT最高提升2.24%,知识引入阶段与训练计算阶段的平均耗时比K-BERT分别降低53.5%与37.4%.
1 基于语料关联生成的知识增强型BERT
1.1 符号定义本模型将一个句子表示为一个有顺序的令牌组合S={c0,c1,c2,,cn},n表示句子长度,英文令牌以单词为级别,中文令牌则以字符为级别.每一个令牌ci都包含在词汇表中,ci∈.知识图谱则定义为,其包含所有三元组τ=(ei,r,ej),τ∈.ei与ej表示两个不同的实体名称,而r则代表这两个不同实体间的关系.所有实体名词Noun∈.
1.2 模型概述基于语料关联生成的知识增强型模型结构如图1所示,其包括5个部分:查询知识实体的知识谱图检索层、将知识实体与相关文本进行语料关联生成的语料生成层、与包含Token Embedding、Position Embedding、Segment Embedding的Embedding层、总数为12层的Transformer Encoder层,以及外部知识层.外部知识主要用于在不同的下游任务中更换其知识来源,从而实现对不同专业领域任务的知识增强.

图1 模型结构与运作流程
从训练集中得到的语句被输入到模型内,将会经过以下流程进行知识增强并应用到下游任务中:1)语句输入到模型后将进行数据拷贝,其中一份拷贝将直接进入Embedding Layer等待数据嵌入;2)另一份数据则会交给知识检索层,连接到外置的知识库中对语句进行知识检索,并将得到的三元组返回给语料生成器;3)语料生成器将知识检索层的三元组与原始句子进行融合,并将新生成的语料传输到Embedding Layer;4)原始句子的拷贝与用于知识增强的语料同时输入至Embedding Layer进行Embedding,最后交由Transformer Encoder层进行模型训练.
1.3 注入知识的语料关联生成方法传统的预训练模型是基于大规模无标注语料进行训练,通过给预训练模型人类自然语言及语法相似的语料进行训练,使其获取隐藏在语料中的信息.此概念已在不同工程应用中实现并在大量自然语言任务(如GLUE、SQuAD等)中证明了其可行性性与有效性[15].但是这类传统方法引入的语料知识将存在大量冗余与噪声,从而加重了模型训练的计算负载.为了克服这个问题,提出通过语料关联生成方法生成含有领域语义相关知识的语料,对预训练模型进行fine-tune,从而将该部分显性知识引入至预训练模型中,使预训练模型从外源知识库中获得与下游任务语义相关的知识,从而获得在不同领域下游任务中更好的性能表现.

图2 引入外部知识与原始语料进行语料关联生成的过程
基于语料关联生成的外部知识注入通过知识检索层运算得到的知识三元组集合J与实体名词集合进行运算,其具体步骤如图2所示.模型使用来自外部的知识库进行知识强化,采用实体检索的方式进行选取.为了从输入语料中获得需要知识增强的实体名词,知识检索层需要将输入的原始句子S={c0,c1,c2,,cn}中所包含的实体名词Noun∈进行区分(Seg),如式(1)所示.
=Seg(S,Noun)
(1)
Q=Query(,)
(2)

(3)
s={Noun0,c1,c2,Noun3,,cn}
(4)
(5)
完成句子s的迭代后,将获得大量包含外源显性知识的语料t.然后如图1所示,该部分数据将同时与原始输入句子S作为整个Transformer层的输入数据.
1.4 Transformer与Embedding层在数据进入Embedding层后,将沿用BERT的设计对数据进行Embedding操作,包含Token Embedding、Position Embedding和Segment Embedding.Token embedding对应字词嵌入,为解决字词嵌入过程中可能丢失句子序列顺序位置信息的问题,必须通过后续position embedding进行补充,最后是分句分段嵌入,用于在嵌入过程中对单次输入包含多个句子的区分.
Token Embedding操作参考BERT执行,沿用其模型参数与词汇表.标签[CLS]被用于句子开头,标签[SEP]则用于区分单次输入中不同句子,输入语句中每个Token将通过BERT提供的预设参数转换为维度为H的嵌入矢量.
为避免模型因缺少句子序列顺序信息而退化为词袋模型,Position Embedding将句子中每个字按从左往右的顺序位置嵌入数据,从而给予模型一定的相对位置信息.
Segment Embedding使用布尔值对(0,1)作为分句的区分.例如句子{c0,c1,c2,,cn}与{w0,w1,w2,,wn}需要同时被输入到模型进行训练或微调时,其将被拼接到一起构成一个长句{[CLS],c0,c1,c2,,cn,[SEP],w1,w2,,wn}.此时为了在模型内部对其进行区分,使用布尔值对(0,1)对拼接句子中的两个分句进行区分,表现为segment tags的{0,0,0,,0,1,1,,1}.Token Embedding、Position Embedding和Segment Embedding构成模型的基础输入结构层,对输入的数据进行初步的运算.
Transformer层沿用BERT的Transformer结构,其Encoder主要是由多头注意力机制、全连接前馈神经网络、残差连接与归一化组成.将Embedding层的结果e=e0,e1,e2,,en作为模型的输入.多头注意力机制由8个self-Attention机制构成,将输入向量e分别于矩阵WQ、WK、WV进行矩阵乘法,得到查询矩阵Q、键矩阵K和值矩阵V,再使用Q、K、V计算自注意力,如式(6)所示.
(6)
与K-BERT不同,本模型中的Attention计算仍然使用传统的计算公式,而非K-BERT中进行改版过后的Mask-Self-Attention方法,如式(7)所示.本文中提出的知识增强方法无需对Transformer层的结构进行修改,而且采用self-Attention与Mask-Self-Attention相比减少了可视化矩阵VM的SoftMax运算,从而降低了运算量规模.
(7)
在Transformer层的输出则使用交叉熵损失函数[22]如式(8)所示,对神经网络结构进行反向传播训练,作为下游任务的目标函数进行任务训练.
(8)
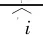
1.5 计算复杂度与时间复杂度分析浮点运算次数(floating point operations,FLOPs)用于衡量模型计算复杂度及作为神经网络模型速度的间接衡量标准,FLOPs数值越大,则该模型在实际运行中需要的运算操作需求越大,与实际运算时间成正相关关系[23].
本文中的对比对象K-BERT使用的语句树数据结构在运算上需要两方面额外计算:1)用于解读语句树数据结构的可视化矩阵;2)避免BERT模型对输入信息造成混淆的mask-self-attention计算.在引入知识阶段用于计算VM的计算量则如式(9)所示.
FLOPsVM=(N+M)2+P
(9)
如对长度为N的句子进行知识注入,假设其额外引入了数量为M的知识三元组,在K-BERT中需要对其进行运算得到用于解读其语句树数据结构的可视化矩阵,其矩阵维度为N+M.长度为N的句子引入数量为M的外部知识,其生成矩阵的稀疏性及数据关联程度等性质,需要额外消耗数量为P的运算次数进行可视化矩阵信息补充.
将上述的操作以n表示其运算规模,则该部分的函数操作可表示为式(10)所示,该部分涉及维度为N+M的矩阵运算,需要对其进行一次选择性赋值运算来补充信息,其运算规模P与(N+M)正相关,此处将其视为近似值.该运算操作的时间复杂度可通过大O运算进行描述,在最坏情况下的时间复杂度如计算如式(11)所示,进而得到K-BERT中计算VM算法的计算时间如式(12)所示,时间复杂度为O(n2).
f(n)=n2+n
(10)
T(n)=O(f(n))
(11)
T(n)=O(n2)
(12)
而本文中提出的基于语料关联生成的知识注入方法,则采用更为轻便的方式引入知识到下游任务过程中,无需引入额外数据结构,进而无需对引入的知识进行解读,输入数据将交由模型结构中的Embedding层直接进行数据的嵌入.知识注入的语料生成计算量如式(13)所示.
FLOPsCK=N+M
(13)
对长度为N的句子进行知识注入后,假设其额外引入了数量为M的知识三元组,则结合原长度为N的句子拼接数量为M的知识三元组,输出数量为N+M的蕴含外部知识语料.同样将上述操作以n作为其规模的表示,则该部分的函数操作可以表达为式(14)所示,其时间复杂度则可通过大O运算进行描述,通过最坏情况下的时间复杂度计算如式(15)所示.
f(n)=2n
(14)
T(n)=O(n)
(15)
对比K-BERT的知识引入过程中的VM算法的时间复杂度O(n2),本文中提出的模型时间复杂度达到了O(n),可以有效降低其模型训练的时间复杂度.
2 实验分析
2.1 实验数据集实验包括问答和文本分类两类任务,包括6个数据集,如表1所示,其中Book review、XNLI、LCQMC、NLPCC-DBQA为开放领域数据集,Law_QA、insurance_QA为专业领域数据集,测试比较包括性能与耗时两个方面.
WikiZh是中文维基百科语料库,实验中被用于训练Google BERT,其包含100万条格式化的中文词条,共1.2亿个句子,数据总大小为1.2 GB.

表1 实验数据集
CN-DBpedia[24]是复旦大学知识工作实验室开发的大规模开放领域百科知识库,其涵盖千万数量级别的实体与数亿的关系属性.实验采用CN-DBpedia进行知识增强,并对CN-DBpedia进行一定的简化处理.参考K-BERT文中对CN-DBpedia的数据处理,在实验数据预处理中通过消除实体名称长度小于 2 或包含特殊字符的三元组来提炼官方CN-DBpedia,精简过后的CN-DBpedia 总共包含 517 万个三元组.
2.2 测试基准与实验环境对比实验设置Google BERT Base与K-BERT两道基准线.Google BERT Base是Google公司使用WikiZH语料集进行预训练后公开的模型.将自注意力机制层数与自注意力头个数分别用L与A进行描述,隐藏层的维度则用H表示.Google BERT Base的模型参数如下:L=12、A=12、H=768,该模型可用于训练的神经网络参数则是110 M.K-BERT与Google BERT的神经网络参数互相兼容,其数量均为110 M,因此K-BERT实验中使用与BERT相同的模型参数进行实验.为保持实验数据的严谨与可对比性,实验采用与K-BERT原文中模型参数一致的实验设置.
为保持实验的严谨性与一致性原则,CAGBERT使用Google BERT Base的模型参数进行实验.引入外部知识的知识库则采用简化版CN-DBpedia,保证实验环境与对比对象K-BERT一致.实验环境如表2所示,神经网络的学习率参数设置为5*10-5,单次实验任务运行5个epoch,batch size设置为32.

表2 实验环境
2.3 评估标准实验采用分类任务常见的评估标准,即准确率进行下游任务的实验评估.用于计算准确率的混淆矩阵如表3所示.

表3 混淆矩阵
准确率(Acc) 表示预测正确的样本占总样本的比重,其计算公式如(16)描述.
(16)
下游任务的对比实验中引入了加速比(Speedup)与耗时(Timecount)两个指标.耗时通过系统时钟的精确计时进行统计,加速比(Speedup)的计算公式如(17)描述.
(17)
其中,p表示处理器数量,Time1表示当前顺序执行算法的执行时间,Timep指当有p个处理器时,并行算法的执行耗时,为了严格进行执行耗时的对比,本文中特定限制p=1,此时计算公式结果则表示两者算法的加速比.Time1表示K-BERT的算法耗时,Timep表示CAGBERT模型方法的算法耗时.加速比数值越大,则说明CAGBERT模型的加速效果越好.
2.4 实验结果与分析实验数据集被分割为Train、Dev、Test这3个子集,并应用到模型微调及下游任务实验当中.实验使用Train训练集对模型进行Fine-tune, Dev与Test用于验证模型在下游任务中的准确度提升.
如表4所示,实验结果显示CAGBERT在文本分类任务中,在LCQMC数据集上取得准确率比Google BERT高1.24%的成绩,并在XNLI和Book Review数据集上分别提高了0.8%和0.16%的准确率.在问答任务上,得益于外源知识的增强,CAGBERT在NLPCC-DBQA[25]数据集上精确度比Google BERT高2.24%,在Law_QA与Insurance_QA上精确度则分别比Google BERT高0.97%和1.92%,总体准确度与K-BERT的准确度持平.

表4 文中模型在不同领域任务中的成绩 %
由实验结果可知,在引入外源知识对模型进行增强后,CAGBERT在Laq_QA、Insurance_QA、NLPCC-DBQA这3个专业领域的数据集上显著比BERT准确度更高,而在其余3个数据集上则提升较少.因为在模型预训练时期使用的语料数据偏向于公开领域,缺少专业领域相关的知识,而知识图谱则可以提供专业领域的知识,弥补BERT模型在专业领域上的专业知识缺失问题,从而显著提高模型在专业领域任务上的性能表现,略微提高其在公开领域的准确度性能.
与此同时,为了进行实验耗时的对比,实验中配备高精度系统计时器用于在下游任务中记录了K-BERT和CAGBERT的Fine-tune与知识注入过程耗时,结果保留小数点后3位数,数值越小则表明其在训练阶段耗时越少,表明对计算资源需求越少.NLPCC-DBQA、Law_QA、Insurance_QA、Book Review这4个数据集被挑选用于Fine-tune与知识注入的过程耗时对比实验.
CAGBERT和K-BERT模型的微调耗时实验结果如表5所示,在LCQMC、Book Review、XNLI等6个数据集上进行模型微调并记录耗时,实验结果显示CAGBERT在上述6个数据集中耗时均少于K-BERT.由表5中加速比数据可得,在6个数据集上CAGBERT对比K-BERT的加速比值均大于1,说明CAGBERT比K-BERT在微调阶段耗时普遍减少,并在LCQMC数据集上取得最高1.87倍的加速效果,在Law_QA数据集上取得最少1.10倍的加速效果.
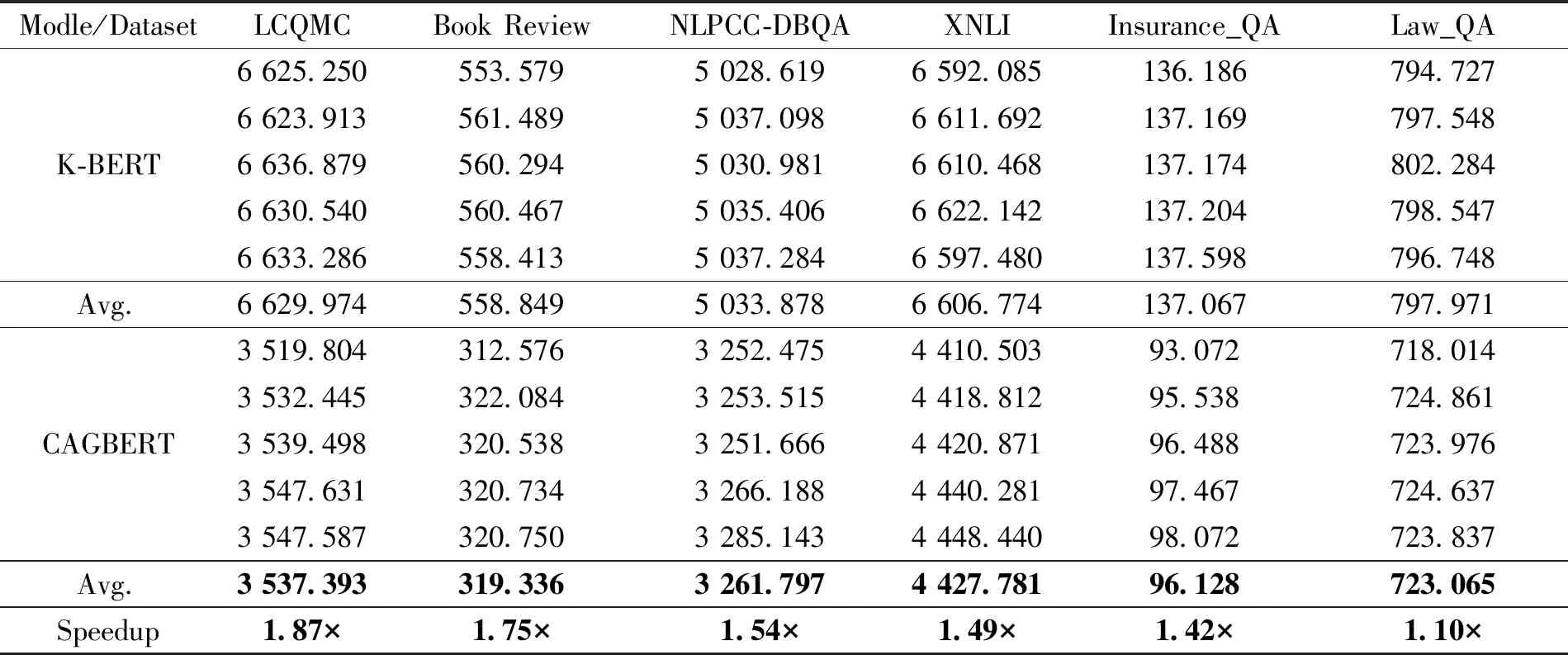
表5 各模型在6个NLP 任务中进行微调的时间计数 s
实验设置了FLOPs计数器在知识注入阶段对K-BERT与CAGBERT进行FLOPs统计,K-BERT与CAGBERT的FLOPs测量数据结果如表6所示.由表6可得,在知识注入过程中CAGBERT比K-BERT的运算数量更少,如在Book Review和NLPCC-DBQA数据集上CAGBERT较K-BERT分别减少了3.9 M和50.9 M的FLOPs,验证了本文中提出的CAG方法计算资源需求更低.CAG方法通过减少知识注入阶段的操作数,从而实现降低在下游任务中进行知识注入所需的计算资源.

表6 K-BERT 和 CAGBERT实现知识注入的FLOPs
耗时加速比测试结果如表7所示,由表7可知:CAGBERT在NLPCC-DBQA、Law_QA、Insurance_QA、Book Review这4个数据集的实验中均取得不同程度的加速效果,如在Law_QA数据集上对比K-BERT减少了73.33%的知识注入操作耗时,实现了3.75倍于K-BERT的加速效果.

表7 K-BERT和CAGBERT实现知识注入的耗时 s
Law_QA、Insurance_QA数据集中文本信息较长,单句长度普遍大于50个字符,而NLPCC-DBQA、Book Review的文本信息则较前者短,平均长度约为20字符.从实验结果上可观察到CAG方法在文本数据较长时加速效果更为明显,因为其无需通过中间数据介质对文本数据进行解读,计算资源需求较少.
综上所述,我们通过实验证明了CAGBERT对比K-BERT在任务微调与知识注入两个步骤上均取得了明显的速度提升,证明CAGBERT模型在训练速度上有明显优势.CAGBERT在获得显著速度优势的同时,其准确度性能与K-BERT持平,在精度性能上不存在下降的问题,成功地引入了外源知识提高了BERT模型的准确度性能.
2.5 消融实验为验证CAG方法的有效性,我们构建消融实验以证明基于CAG的知识增强方法在下游任务中的增强作用,实验使用专业领域任务数据集进行.
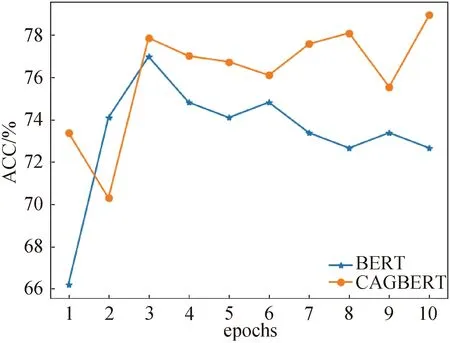
图3 在金融领域数据集上进行实验
实验结果如图3所示,图中CAGBERT为经过本研究提出的CAG方法进行增强后的模型,BERT则为去除CAG方法后的原始版本BERT.由图3可知:1)CAGBERT能达到二者中最好的效果;2)去掉CAG方法的BERT模型,在实验中准确率表现不如CAGBERT.
通过上述实验结果可知,CAG方法能通过为模型提供外源知识,有效地提升模型在下游任务上的准确度性能.
3 结束语
针对预训练模型BERT缺少专业领域知识支持导致模型准确率受限,K-BERT引入外部知识提高准确率的同时却带来计算资源与训练耗时大规模提升的问题,提出基于语料关联生成的知识增强型BERT模型,该模型无需侵入性的修改其原有神经网络结构,具备更好的鲁棒性与模型兼容性.轻量化的快速知识引入方法,对计算资源要求更低,便于大规模的工业应用及系统集成.实验证明在LCQMC、XNLI等6个公开数据集上CAGBERT准确度比BERT平均提升1.22%,而在知识引入阶段与训练计算阶段的平均耗时上,CAGBERT比K-BERT分别降低53.5%与37.4%,有着显著的提升.
鉴于引入知识关联度不足和BERT模型规模仍然较大,以不损失模型精度为前提,如何实现模型轻量级优化仍然是目前自然语言处理模型面临的关键问题.今后将继续研究如何通过更好地精确检索与语义相关度对知识进行高质量筛选以提升模型的精度,并通过模型蒸馏技术提升模型运行速度,实现轻量级模型构建等.
