基于自然进化策略的可再生能源ELM 预测两阶段优化训练方法
2022-10-31吕立臻葛轶文
权 浩,吕立臻,郭 健,葛轶文,柳 伟
(南京理工大学自动化学院,江苏省南京市 210094)
0 引言
随着中国“双碳”战略和以新能源为主体的新型电力系统建设目标的提出,未来电力系统将呈现高比例可再生能源和高度电力电子化的“双高”特征。可再生能源具有波动性和间歇性等不确定性特征,在运行和调度时存在弃风、弃光等问题[1-2]。基于可再生能源历史出力和外部环境因素数据,准确预测其出力、有效量化其不确定性对优化风电、光伏电场运行调度以及保障电力系统安全稳定运行具有重要意义。
目前,风光预测模型主要分为4 类:物理数学模型、统计模型、人工智能数据驱动模型和混合模型[3]。其中,比较常见的预测模型有整合滑动平均自回归模型[4]、神经网络(neural network,NN)模型[3]、支 持 向 量 回 归(support vector regression,SVR)模型[5]、深度学习模型及其变式[6]等。以上数据驱动模型参数依赖于数据,对数据的质量要求较高,其泛化性能、可解释性和训练时间等是研究中主要关注的问题。
文献[7]提出的极限学习机(extreme learning machine,ELM)模型具有训练速度快且算法一致性强的优点。ELM 本质上是一种单隐含层前向人工神经网络,标准前向神经网络已被证明有着较强的函数拟合和逼近能力[8-10]。文献[11-12]研究了当隐含层节点个数有限时,多层前向神经网络的逼近能力。ELM 模型除了被广泛应用于可再生能源预测领域[13],也被应用在可再生能源的聚合序列生成[14]、电力系统频率安全评估[15]和用户用电行为分类[16]等方面。
现有研究大多直接采用ELM 实现电力系统中的具体应用,对于ELM 原训练方法、输出层偏移和自适应优化等问题改进不足。但是原始ELM 模型训练过程具有随机性且在矩阵逆运算过程中缺少对参数的微调,导致该模型虽然训练速度较快,但是在精度上有所欠缺。已有研究提出引入智能优化算法对ELM 模型的参数进行优化。文献[17]采用粒子群优化算法优化ELM 输出权值,文献[18]将麻雀优化算法应用于深度极限学习机中进行参数寻优,均提高了ELM 模型的预测性能。已有ELM 模型参数优化以单阶段优化为主。
与传统进化算法相比,自然进化策略(natural evolution strategy,NES)[19-20]是 一 种 利 用 分 布 参 数上的估计梯度迭代更新搜索分布的进化策略,其引入自然梯度下降替代传统进化算子中的随机突变和重组步骤。对概率分布空间进行优化,改善了常规梯度中存在的振荡、过早收敛和尺度不变性问题,使得进化方向能够向更好的个体适应度进行。NES在函数拟合、全局优化等方面已有不少研究成果。文献[21]提出了一种基于NES 的动态流权值学习框架,该框架通过多模态数据融合进行目标定位和跟踪,且不需要显式计算Oracle 信息。文献[22]提出了一种扩展的距离加权指数NES,适用于具有不确定性的目标函数参数优化问题。文献[23]提出了一种同时估计状态空间模型状态和参数的序贯估计方法,降低了多种模型的均方误差。
为了提升ELM 模型的预测精度,与常规单阶段的训练方法不同,本文将其与NES 相结合,提出了ELM 网络参数两阶段优化训练方法及可再生能源功率预测改进模型。在第1 阶段,使用ELM 随机参数和广义矩阵逆运算过程训练模型网络参数;第2阶段在其基础上引入输出层偏移,利用NES 继续优化训练,并进一步引入自适应因子优化收敛速度,用以提高预测模型精度。
1 基于NES 的ELM 模型网络参数两阶段优化方法
1.1 ELM 模型
ELM 是一种前向人工神经网络[7]。前向人工神经网络能够从所提供的训练样本中直接拟合输入和输出之间的非线性映射关系,从而为难以通过传统数据分析方法得到合适解析式的工程问题提供数学模型。ELM 网络结构见附录A 图A1。
ELM 预测模型作为前馈神经网络的一种改进形式,具有学习速度快、效率高等优点。在ELM 中,隐含层的连接权值和偏差是随机生成的,输出层的连接权值通过矩阵求逆得到。与其他机器学习模型相比,ELM 模型的优点在于其无须在反复的迭代过程中调整参数,极大地节省了训练模型所需时间并具有与传统神经网络算法相当的预测精度。此外,ELM 在网络训练可重复性和稳定性方面也具有一定优势,在不同的重复实验中保持了良好的稳定性。因此,ELM 适合于需要大量模型训练的集合预测、特征选择等任务。与传统神经网络算法相比,ELM 模型的缺点在于随机和广义矩阵求逆过程可能会导致模型对训练集依赖性较高,可以通过优化算法对模型参数进行第2 阶段的优化训练。鉴于ELM 的以上优点,本文选取ELM 作为可再生能源预测与优化模型。算法流程如下[7]。
对于给定的由N个训练样本(xj,tj)组成的训练集,其中,xj∈Rl为第j个训练样本的输入向量,具有l个维度方向,tj∈Rm为第j个训练样本的目标真实值,具有m个维度方向,则ELM 数学模型如下:


式中:N͂为预测模型隐含层的节点个数;g(·)为预测模型隐含层激活函数;βi∈Rm为预测模型隐含层第i个节点到输出层的连接权重;wi∈Rl为模型输入层到隐含层第i个节点的连接权重;bi为输入层到隐含层 第i个 节 点 的 偏 移 量;t͂j∈Rm为 第j个 训 练 样 本 的模型输出值。可以发现,原始ELM 隐含层到输出层没有偏移值设置。
式(1)和式(2)可整理为:
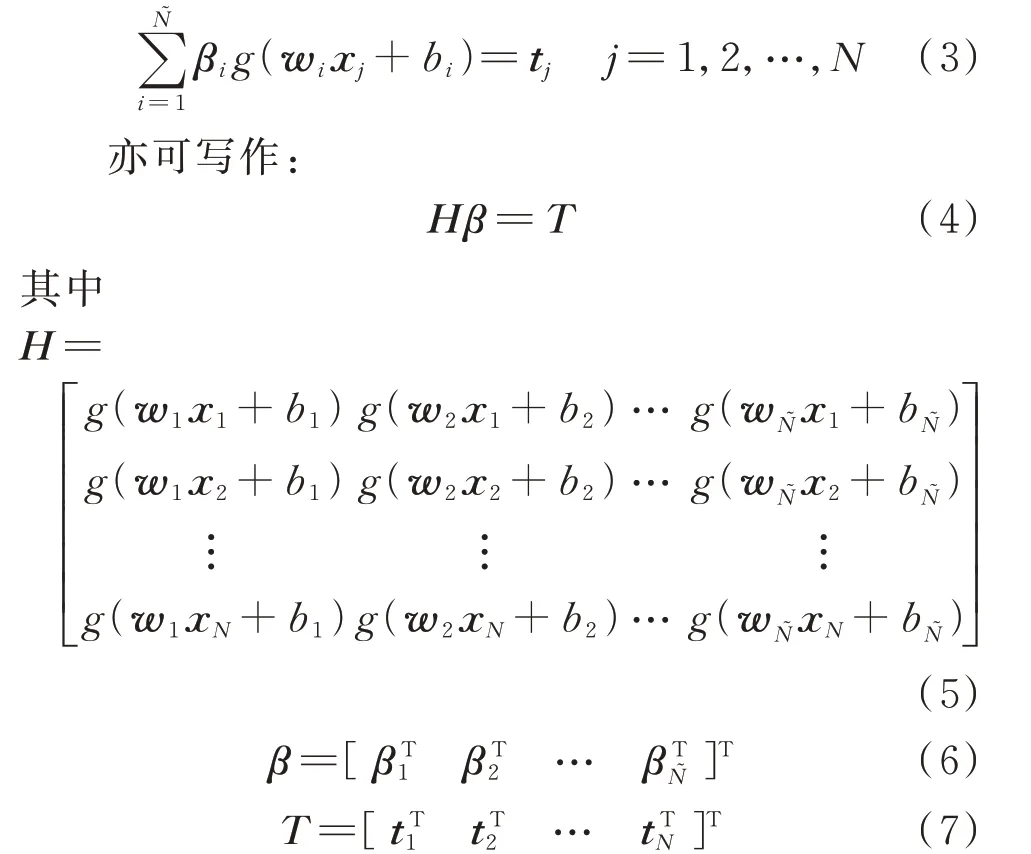
其具体训练过程如下[7]:
1)确定隐含层节点数N͂和激活函数g(·);
2)随机产生输入层到隐含层连接权重矩阵W和输入层到隐含层偏移矩阵B;
3)计算隐含层输出矩阵H;
4)通过广义矩阵逆运算求得β=H+T,其中H+为矩阵H的Moore-Penrose 广义逆矩阵。
1.2 NES 算法
NES 算法[19]是进化策略算法的一类变式算法,与传统标准进化策略算法的主要区别在于利用分布参数的估计梯度来迭代更新搜索分布[20]。其一般过程如下:首先,利用诸如高斯分布等参数化分布方法在原有初始化基因个体周围生成一批突变搜索点,并在每个搜索点处计算适应度函数,通过选择不同的参数分布形式,使算法具有自适应地捕捉适应度函数局部结构的能力;然后,在这些由随机分布所生成的子代样本中,采用NES 算法计算参数的搜索梯度;最后,沿着自然梯度采用一定的数学公式更新基因个体的基因序列,以达到更加适合的目标函数适应度值。通过重复上述过程可以使得目标函数按自然梯度方向达到最优值。
以本文所采用的多重正态分布为例,具体算法过程如下[20]:
1)确定NES 算法进行搜索的起点,即初始化基因X;
2)利用多重正态分布在初始化基因X周围生成符合分布的n个基因样本,第s个基因样本Zs~N(X,σ),其中,σ为多重正态分布的分布范围协方差矩阵;
3)计算第s个基因样本Zs的目标函数适应度值f(Zs);
4)计算将被用于更新基因个体X基因序列的对数导数∇Zlogπ(Zs|θ)以及被用于更新σ的对数导数

式中:θ为分布函数π(Zs|θ)的参数;∇Z和∇σ表示对对数似然函数中参数的各元素进行求导。
5)计算被用于更新基因个体X基因序列的自然梯度向量∇Z J以及被用于更新σ的自然梯度向量∇σ J:
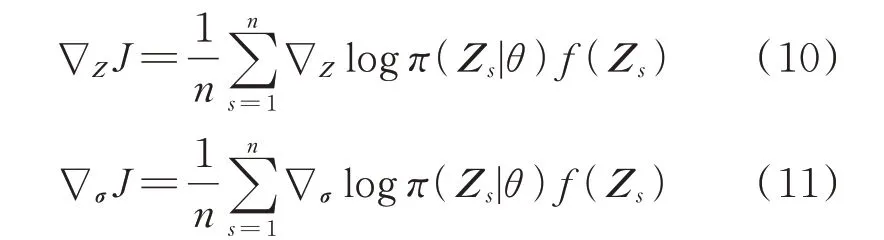
6)用∇Z J和∇σ J分别以同样的学习速率η更新基因个体X基因序列和σ得到X*和σ*:

7)重复上述过程直到算法达到完全收敛或者达到迭代循环次数上限。
2 所提方法主要流程
基于NES 算法的ELM 网络参数训练优化方法的主要流程图如图1 所示。

图1 基于NES 算法的两阶段参数训练方法流程图Fig.1 Flow chart of two-stage parameter training method based on NES algorithm
首先,利用可再生能源历史出力数据和外部环境变量,通过ELM 随机过程和广义逆运算求逆过程得到第1 阶段的模型参数。其次,在第1 阶段模型参数的基础上引入输出层偏移量,初始值设置为零。然后,对模型网络参数与预测目标值之间的关系进行数学建模,并利用带有自适应因子改进的NES 算法进行第2 阶段的优化。最后,通过预测误差衡量本文所提优化方法的性能。详细步骤如下。
2.1 第1 阶段
1)通过训练集和随机过程产生输入层到隐含层的连接权重矩阵W'和偏移矩阵B';
2)计算隐含层输出矩阵H':

式中:uj为模型输入向量,j=1,2,…,N;w'i和b'i分别为第1 阶段求得的wi和bi。
3)通过广义矩阵逆运算求得输出权重β'=H'+T,其中,H'+为矩阵Η'的Moore-Penrose 广义逆矩阵[7],从而得到第1 阶段的模型网络参数W'和B'。
2.2 第2 阶段
步骤1:在上述第1 阶段得到的模型参数中引入隐含层至输出层的偏移,组合成第2 阶段参数训练所需的输入,同时对其与该模型在训练集上的预测误差之间的映射关系进行数学建模,其过程如下。
1)将上述第1 阶段模型参数W'、B'和β'的数据集合按顺序组合成向量形式,视为输入x1,x2,…,xD,其中,D为第1 阶段模型参数总个数。
2)在ELM 模型参数的基础上,引入新参数隐含层到输出层的偏移基Β'ο,初始值设置为零,视为xD+1(点预测模型为单输出)与原模型参数一起组合为第2 阶段优化参数。
3)将该模型在训练集上的预测误差(模型输出与目标值的差)视为第2 阶段需优化的目标函数f(x1,x2,…,xD+1),其中,f(·)表示预测模型的输入向量和预测误差之间的映射关系。
4)将输入与预测误差之间的映射关系转化为标准的参数优化问题:

步骤2:利用NES 优化算法对上述参数优化问题进行求解[20]。
1)将第2 阶段步骤1 中所得多个输入x1,x2,…,xD+1作为初始种群空间。
2)利用多重正态分布在初始化基因X周围生成n个突变基因样本X͂s,其计算公式如下:

式中:ρ为比率系数;es为服从期望为0、协方差矩阵为单位矩阵I的正态分布的噪声,即es~N(0,I)。
3)计算第s个基因样本X͂s的目标函数f(X͂s)和其适应度值。
4)计算将被用于更新基因个体X基因序列的对数导数∇Zlogπ(X͂s|θ)以及被用于更新σ的对数导数∇σlogπ(X͂s|θ):
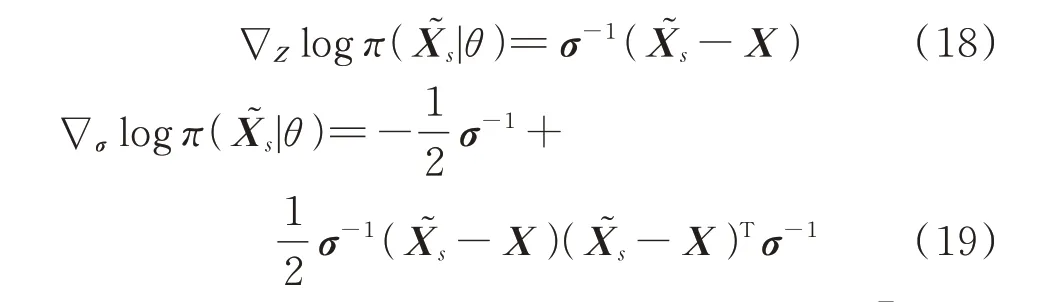
5)计算被用于更新基因个体X基因序列的自然梯度向量∇Z J以及被用于更新σ的自然梯度向量∇σ J:

式中:λ为自适应因子。
7)引入自适应因子λ,其数值由f(X͂s)的方差δ决定。当方差δ过大时,令λ<1,缩小多重正态分布分布范围σ;当方差δ过小时,令λ>1,扩大多重正态分布分布范围σ。
8)重复1)至7)过程直至达到设定好的收敛条件或者循环上限。
步骤3:计算测试集预测目标预测值和误差。
将步骤 2 中 6)所得优化完成的输入x1,x2,…,xD+1中的前D位数据重新组合成优化后连接权重W″、偏移B″和输出权重β″的矩阵形式,而xD+1构成优化后的输出偏移基B″o,在测试集数据进入系统时计算其预测目标预测值T͂:

式中:H″、β″i、w″i、b″i分别为优化后的H、βi、wi、bi。
则 均 方 根 误 差(root mean squared error,RMSE)可表示为:
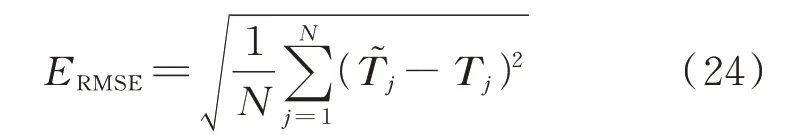
式中:Tj和T͂j分别为第j个样本的目标真实值和预测值。
3 算例分析
3.1 数据集介绍
为了检验本文所提基于NES 算法的ELM 模型网络参数两阶段训练优化的有效性,分别对光伏和风能2 个案例进行验证分析。
支撑光伏研究案例的数据收集自澳大利亚昆士兰大学圣卢西亚校区,其拥有2.14 MW 的集成光伏发电装置。本文所使用的光伏出力数据选自2015-03-21 的05:00 至2017-03-21 的18:00,额 定 容 量 约为0.35 MW,原始数据分辨率为1 min。同时期的气象等外部数据包括空气湿度、太阳辐射强度、风速、风向和气温5 类。本算例预测短期内未来1 h 光伏发电厂功率出力,将数据预处理为1 h 分辨率并补全丢失的数据,2 年合计10 234 组记录。光伏案例部分数据展示见附录A 图A2。
在实验开始前,将数据集按照2∶1∶1 拆分为训练集、验证集和测试集。第1 部分为训练集,数量为5 117 h,作用是训练本文所提预测模型;第2 部分为验证集,数量为2 558 h,作用是参与本文的模型训练和特征输入选取过程,通过观察预测模型在验证集上的表现调整模型参数、优化模型结构和预测结果;第3 部分为测试集,数量为2 558 h,作用是测试最终预测模型精度。本文根据ELM 预测模型的特点,将模型输入参数和预测目标(光伏出力)做0-1标准化处理。
支撑风能案例研究内容的数据集来自美国国家可再生能源实验室(National Renewable Energy Laboratory,NREL)某风电场2012 年的风电功率和周围环境信息数据,其额定容量为16 MW,NREL内部标识号为46 620,经度坐标为-106.398 224°,纬度坐标为39.273 796°。风能案例部分数据展示见附录A 图A3。
原数据集为每5 min 记录一次的风力发电厂功率出力数据以及周围环境风速、风向信息。同光伏案例一样,为了符合预测短期内未来1 h 风力发电厂功率出力这一目标,本文将其分辨率处理为1 h,处理完成后的数据集长度为8 784 h 且对其进行0-1 标准化处理,并按2∶1∶1 的比例拆分数据集。
3.2 ELM 模型结构参数选择
ELM 模型预测精度受激活函数类型与网络结构影响明显。本文针对预测对象特点,调研了激活函数与网络结构选择对ELM 预测精度的影响。
采用MATLAB 软件分别对不同激活函数和隐含层节点个数下的预测模型进行仿真和对比,所调研的输入层激活函数包括S 型函数、硬阈值函数和正弦函数。选取的隐含层节点变换范围为10 到1 000(风能为200),分度值为10。光伏案例和风能案例的比较结果如图2 所示。
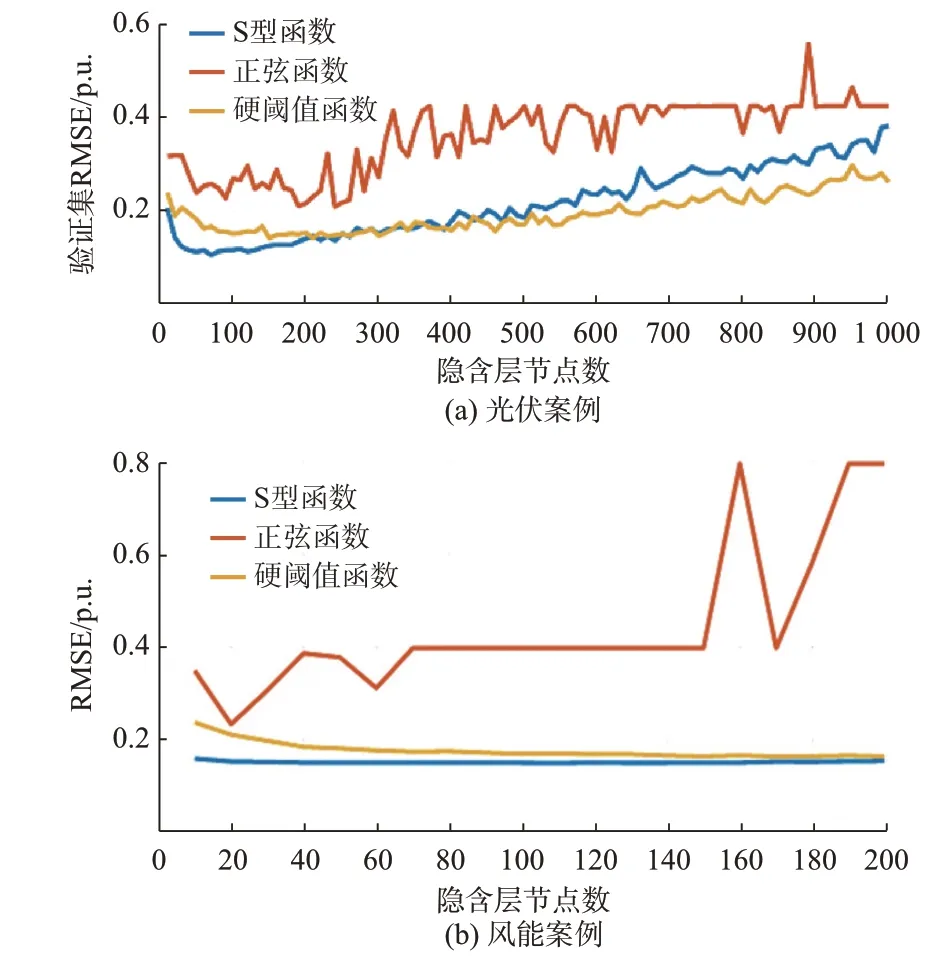
图2 不同激活函数下ELM 预测模型在验证集上的RMSEFig.2 RMSE of ELM forecasting model on validation set with different activation functions
从图2(a)可以看出,RMSE 随着隐含层节点个数的增加,一开始呈现明显的下降趋势,然后呈上升趋势。
从图2(b)可以看出,正弦函数的性能随隐含层节点数的增加而急剧波动,误差最大。采用S 型函数时的预测误差最小,且随着隐含层节点数的变化较为稳定。
综合2 个案例来看,当隐含层节点数小于200时,S 型函数的RMSE 最小且最稳定,比其他2 种激活函数更适合于本文的预测任务。因此,选择S 型函数作为本文预测模型的激活函数。考虑到提高模型准确性和减少计算复杂度来降低模型预测时间,光伏案例选择的隐含层节点数为70,风能案例选择的隐含层节点数为100。
从图3 中光伏案例不同隐含层节点数下的训练集和测试集RMSE 可知,随着隐含层节点数的不断提高,训练集的RMSE 先迅速减少,然后缓慢下降;而验证集的RMSE 在隐含层节点数小于70 时迅速减少,当隐含层节点数大于70 时,存在较为明显的上升趋势,说明大量增加隐含层节点数可能会造成过拟合现象,反而不利于验证集的误差减小。风能案例也有类似结果,本文不再赘述。

图3 光伏案例中不同隐含层节点数下ELM 预测模型的RMSEFig.3 RMSE of ELM forecasting model with different numbers of hidden nodes in photovoltaic case
3.3 基于NES 算法的预测模型网络参数两阶段训练
1)预测模型网络参数第1 阶段训练
通过上述过程确定ELM 预测模型的结构参数后,第1 阶段网络训练采用网络参数随机初始化以及Moore-Penrose 广义矩阵逆运算求解过程等得到预测模型隐含层连接权重、隐含层偏移和输出层连接权重等参数。
2)预测模型网络参数第2 阶段训练
本文研究过程中NES 算法参数设置学习速率为0.1%~1.0%,多重正态分布分布范围为0.001。
随着NES 算法迭代次数的增加,2 个案例在验证集上预测值与真实值的标准化均方根误差(nRMSE)变化过程如图4 所示。

图4 第2 阶段验证集的nRMSE 变化Fig.4 Change of nRMSE on validation set in stage 2
通过图4 可知,随着循环次数的不断增加直至达到设置的循环次数上限,经过每次迭代优化过程得到的模型网络参数在验证集上的nRMSE 总体呈下降趋势,且在重复实验中均能够取得较理想的优化结果,这也体现了本文所提两阶段优化训练方法的稳定性。
在光伏案例中,测试集真实值优化过程中具体的下降幅度为:在验证集上,nRMSE 从优化前的0.074 95 下降到优化后的0.074 02,预测误差减小了1.24%。在风能案例中,测试集真实值优化过程中具体的下降幅度为:在验证集上,nRMSE 从优化前的0.132 3 下降到优化后的0.131 0,预测误差减小了0.98%。
从图5 可以看到,2 个案例中第2 阶段优化后的测试集预测值曲线与第1 阶段测试集预测值曲线相比,都更加贴合测试集真实值曲线,预测结果经过第2 阶段的优化后误差减小。
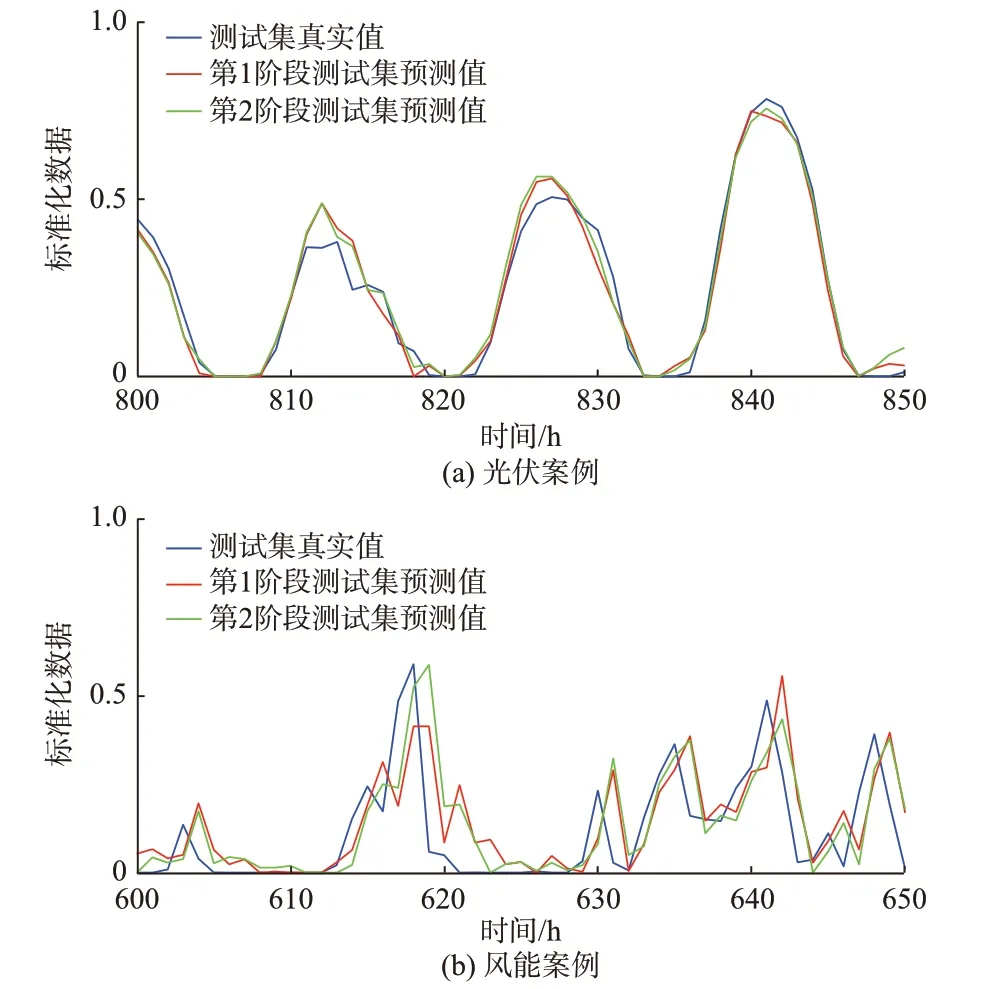
图5 测试集真实值、第1 阶段预测值和第2 阶段预测值对比Fig.5 Comparison of real values and forecasting values from stage 1 and stage 2 on test set
3.4 误差对比与结果分析
本文所提基于NES 算法的ELM 两阶段模型参数优化(简称为NES-ELM)方法分别与4 个比对模型开展预测结果比较,包括持续性模型(persistence model,PM)、人工神经网络(ANN)、SVR 和随机森林(RF)。误差度量指标包括RMSE、nRMSE(选用最大值标准化)、平均绝对误差(MAE)、加权平均绝对百分比误差(WMAPE)和平均偏差误差(MBE)。为了体现两阶段优化结果和单阶段优化结果的比较,分 别 给 出 了NES-ELM 第1 阶 段(NES-ELMS1)和第2 阶段(NES-ELM-S2)的预测结果。所提方法与比对模型预测误差的比较结果如表1 所示,各项指标的最优值均用红色字体显示。

表1 本文方法与比对预测模型在测试集上的误差比较Table 1 Comparison of errors between proposed method and comparative prediction models on test set
由表1 可以看出:光伏案例和风能案例第2 阶段预测精度均优于第1 阶段,nRMSE 指标分别提升了0.99%和0.66%。光伏案例中,本文所提NESELM 方法在各个误差衡量指标下均优于4 个比对预测模型。而风能案例中就本文所采纳的预测误差衡量核心指标RMSE 和nRMSE 而言,所提方法均优于4 个比对模型,而其他误差指标与最优比对模型预测误差相当。
光伏、风电等可再生能源具有明显的季节性特点,其预测结果受不同季节影响往往有较强的波动性。在上述实验的基础上,将2016 年光伏案例和2012 年风能案例的数据集拆分成4 个季节,使用本文所提方法对未来1 h 出力进行预测,并且将其与其他预测模型进行对比,比较结果如表2 和表3 所示,各项指标的最优值均用红色字体显示。
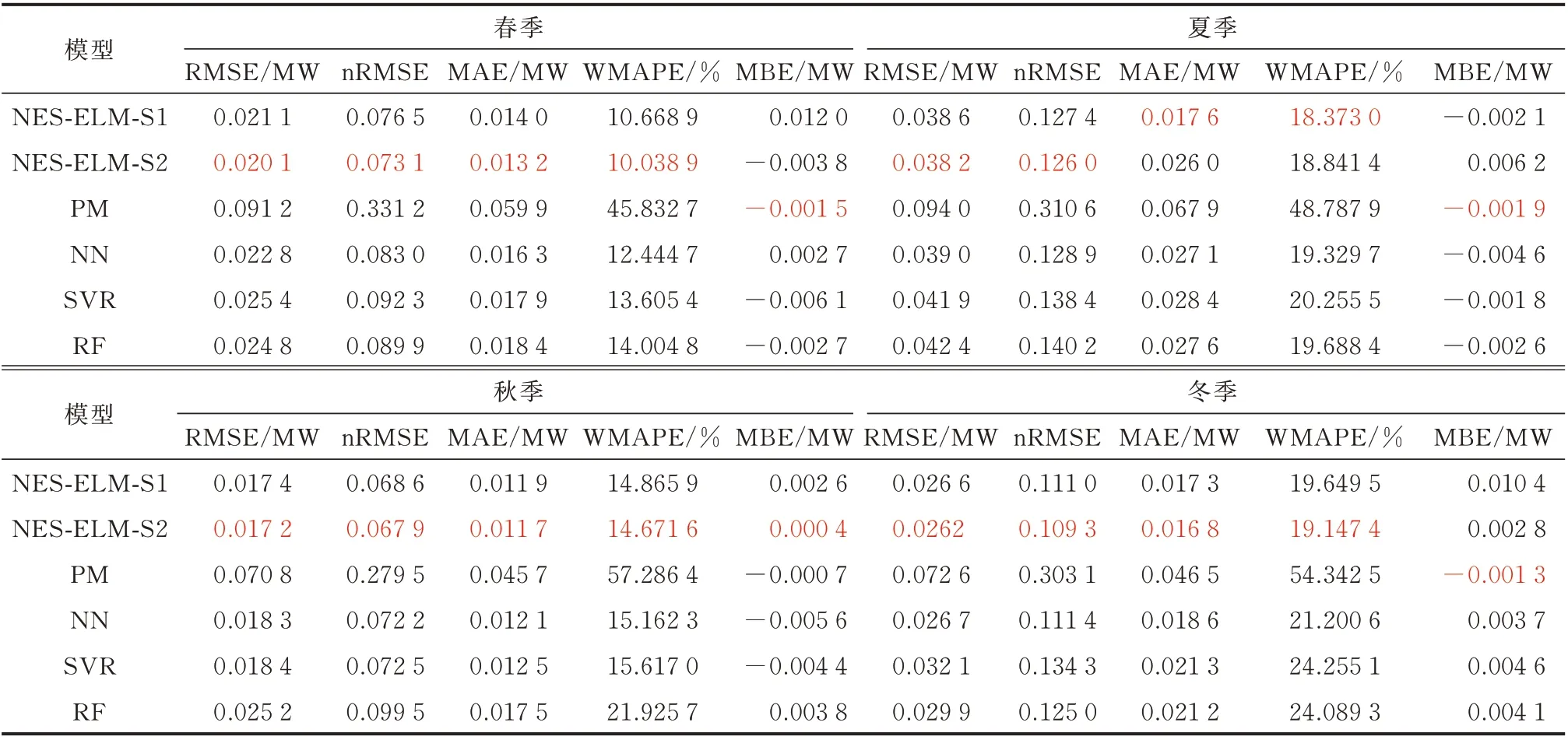
表2 本文方法与比对预测模型在光伏案例不同季节测试集误差比较Table 2 Comparison of errors between proposed method and comparative prediction models on test set of different seasons in photovoltaic case

表3 本文方法与比对预测模型在风能案例不同季节测试集误差比较Table 3 Comparison of errors between proposed method and comparative prediction models on test set of different seasons in wind energy case
由表2 可以看出:在光伏案例不同季节的4 个测试集中,第2 阶段的预测精度均比第1 阶段有所提升,nRMSE 指标分别提升了4.44%、1.10%、1.02%和1.53%;与其他模型相比,除MBE 指标外,NES-ELM 模型均优于其他4 个比对模型。
由表3 可以看出:在风能案例不同季节的4 个测试集中,第2 阶段的预测精度均比第1 阶段有所提升,nRMSE 指标分别提升了0.35%、0.77%、0.85%和0.78%;与其他模型相比,在春季、秋季、冬季数据集中,预测误差衡量标指标nRMSE 均优于传统模型。
4 结语
为了提升ELM 模型对于可再生能源出力的预测精度,本文提出一种基于NES 算法的可再生能源ELM 预测模型网络参数两阶段训练优化方法。在澳大利亚昆士兰大学光伏电站实际出力数据和NREL 的风电场数据上进行预测和分析。结果表明,本文所提出的NES-ELM 两阶段预测模型在2 个案例中的预测精度均有所提高。第2 阶段预测精度全部优于第1 阶段,即nRMSE 误差有效降低且表现稳定。与4 个比对模型相比,所提出的改进模型在减小预测误差方面具有优势。同时,对由不同季节的波动特性数据构成的数据集进行了预测和分析,结果表明该方法提升了多数季节的预测精度,预测模型性能较为稳定。
后续可以进一步开展NES 算法的参数变化对模型优化和误差的影响研究。两阶段ELM 模型和NES 算法的应用不限于本文的研究内容,还可以对ELM 模型的输出层进行拓展,对可再生能源进行概率预测,例如区间和分位点预测等。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
