协整和集对分析法在降雨资料短缺地区的插补移用
2022-10-29王秀杰齐喜玲滕振敏李丹丹
王秀杰 ,齐喜玲 ,滕振敏,李丹丹
(1. 天津大学 水利工程仿真与安全国家重点实验室,天津 300072; 2. 天津大学 建筑工程学院,天津 300072; 3. 崇左市左江治旱工程管理中心,广西 崇左 532200)
洪灾具有破坏性强、影响范围广、突发性强、频率高等特点[1],极易造成社会经济和人民生命财产损失。据统计,洪涝灾害损失在全球所有自然灾害损失中占比高达40%[2]。因此,及时准确的洪水预报作为非工程措施[3],在防洪减灾中发挥着重要作用[4]。洪水预报中,气象数据的可靠性是关键[5],然而降雨资料短缺一直是个难题[6]。因此,插补移用降雨资料是非常必要的[7]。常用的方法有线性相关法、反距离权重法、泰森多边形法及克里金插值法等[8-9]。国内外诸多学者在降雨资料空间插补方面做了大量研究[10-11],但较少考虑降雨序列的非平稳性。随着全球气候变暖,极端降雨事件的频次和强度均发生了变化,变化环境导致极端降雨存在非平稳性[12-13]。台风雨的极端降雨强度大、分布范围广,一定影响范围内的雨量站间的降雨资料存在线性协整关系。因此,考虑降雨数据的线性协整关系并建立模型插补短缺数据,是提高降雨数据插补质量的一种新思路。
因多种因素干扰,降雨序列往往是缺失的[14]。许多学者对无资料地区数据移用进行了研究,通常采用邻近测站资料替代研究区域数据的方法[8],其中,金倩芳[15]分别以卫星降雨数据及测站降雨数据作为驱动建立水文模型,计算结果表明卫星降雨数据驱动的水文预报模型在洪峰预报精度上低于实测降雨数据驱动的模型。可见监测仪器精度不高会降低卫星雷达降雨产品的空间分辨率[16],造成数据精度不高,使得卫星降雨数据驱动的水文预报模型在流域的数据移用方面适用性较差[17]。彭安帮等[18]对流域划分水文相似组并建立子流域洪水预报模型,对无资料地区进行参数移植,模拟中发现在洪水预报精度方面,总体上参数移植后的精度较移植前较差。
无资料地区在降雨数据移用进行流域水文预报时,除需要考虑地形、距离、下垫面等因素做出相似判断外,降雨数据的同一度分析也至关重要。因此,存在由于忽略降雨中心时空分布而造成的数据移用精度不高现象[19-20]。非台风影响下的降雨资料缺少测站引入集对分析(Set Pair Analysis, SPA)[21-22],对相邻站点降雨数据进行确定性和不确定性研究分析,从同、异、反3个角度对降雨序列集合进行定量特性分析测站之间的关联性,可有效提高移用资料的精度。降雨序列是非平稳时间序列,需要寻求一种能从非平稳信号中感受到数据偏差或噪声的数据影响、有效提取具有实际物理意义的特征信号的方法[23],才能准确地进行降雨序列间的集对分析。研究表明,补充集合经验模态(Complementary Ensemble Empirical Mode Decomposition, CEEMD)[24-26]相比于经验模态分解(Empirical Mode Decomposition, EMD)及集合平均经验模态分解(Ensemble Empirical Mode Decomposition, EEMD)不仅解决了模态混叠问题,而且对原始信号进行了精确重构,分解效果更好。利用CEEMD将非台风雨降雨数据分解为多个本征模态函数(Intrinsic Mode Function,IMF)分量,分别建立集对分析,通过综合联系度判别测站之间的相似性,选择最佳降雨数据移用,提高资料移用的准确性,可为无资料地区高精度的洪水预报提供参考依据。
本文针对广西驼英水库洪水预报过程中降雨数据短缺问题,提出一种基于线性协整的台风雨降雨插补和集对分析的非台风雨降雨资料移用方法,以期为洪水预报提供较准确可靠的降雨数据。
1 研究方法
1.1 线性协整理论
协整分析研究两个及以上非平稳时间序列间的均衡关系,主要步骤包括平稳性检验、协整关系的估计与检验及误差模型的建立,具体步骤见文献[27]。
(1)平稳性检验方法。对时间序列进行平稳性检验,即单位根(Augmented Dickey-Fuller, ADF)检验。ADF检验中最小二乘法回归模型有以下3种:

式中:Δyt为 变量y的一阶差分;t为时间项;α为 截距;β为回归系数;ρ为系数;i为时间滞后项;k为滞后阶数(AIC和SC准则确定);Δyt-i为 滞后i时刻的变量y的一阶差分;δi为 时间项相关系数;εt为白噪声。
在零单位根检验时,假设有单位根,若ADF的显著性检验统计量小于相应的置信度(10%,5%,1%),则说明该时间序列为平稳序列,否则对降雨序列先进行一阶差分后再次进行检验,直至降雨序列差分为平稳序列,并判断两个降雨序列的单整阶数。若两个时间序列具有相同的单整阶数,则进行以下的协整关系估计与检验。
(2)协整关系的估计与检验。通过最小二乘法对2个降雨序列进行协整回归,并对回归方程的残差是否具有单位根进行检验。若2个时间序列是协整的,则残差将是平稳的。
(3)误差修正模型建立。若降雨序列间存在协整关系,则可根据两变量的一阶自回归滞后模型建立误差修正模型(Error Correction Model, ECM):

式中:Δyt、Δxt分 别为y、x变量在t时刻的一阶差分;β0、 β1为 回归系数;et-1为两序列协整关系的前一时刻计算残差;γ为修正系数,即因变量拉回长期均衡状态的速度。
1.2 集对分析(SPA)理论
集合对H(A,B)是指由两个相互关联的集合A和B组成的一对集合。这两个集合的性质包括同一度、差异度和对立度[28],其表达式如下:

式(5)经简化后可得:

式中:µ为集合对的综合联系度;S为同一的个数;F为差异的个数;P为对立的个数;N为特征个数总数;a为同一度;b为差异度;c为对立度;m为差异不确定性系数;n为对立系数;在计算中一般取m=0.5,n=-1。
根据综合联系度判断目标站点的场次降雨序列与相邻站点降雨序列的相似性,进行综合联系度高的降雨数据的移用,并非距离近的站点间的降雨数据移用,这在很大程度上取决于降雨的时空分布。
1.3 补充集合经验模态(CEEMD)分解方法
CEEMD算法通过对原始信号加入白噪声,有效消除重构信号中的残留噪声,具体步骤[29-30]如下:
(1)在原始信号中分别加入n种固定比例的高斯白噪声,对加噪的信号进行分解,得到n个IMF,将得到的各IMF进行加总平均得IMF1:

式中:IMF1为 原信号的第一阶分量;N为分解次数; ωi(t) 为随机高斯白噪声;E1表示EMD分解结果中第一个模态函数分量。
从原始信号中减去IMF1得到一阶残差r1(t):

(2)对残差重构待分解信号重新分解,即可得到原始信号的第二模态函数IMF2:

式中:r1(t)+εE1(ωi(t)) 为重构分解信号。
对k=2, 3,···,k,分别计算第k阶残差:rk=rk-1-IMFk, 根据式(9)得出rk(t)+εEk(ωi(t))的第1个分量,通过对IMF平均得:

(3)反复迭代,直到残差的极值个数不超过2:

式中:R为 最终残差值;K为最终IMF分量数。
1.4 SCS-CN洪水预报方法
SCS-CN模型是基于水量平衡方程和两个基本假设建立的[31]。由于其模型结构简单,参数较少,被广泛应用于无资料中小河流的洪水预报中[32-33],详细的洪水预报模型原理和过程见参考文献[4],此处不再赘述。
本文采用绝对误差、相对误差、相关系数和纳什系数4个指标评定模型结果。相关系数用来反映模拟值和实测值之间的线性相关程度,纳什系数可以描述洪水预报过程与实测过程之间的拟合程度。
2 实例应用
驮英水库位于广西宁明县那堪乡垌中村上游约6 km的珠江流域西江水系明江支流公安河上游河段(图1),流域经纬度范围为21°35′45′′N~21°55′5.9′′N,107°17′7.1′′E~107°34′3.7′′E,流域面积606 km2,属南亚热带季风气候[34]。流域内83.87%面积的土壤为壤土,饱和导水率在1.8~18 mm/h范围内。夏末秋季,受南海及太平洋台风影响,工程区多出现台风雨,且台风雨强度大、雨量集中。
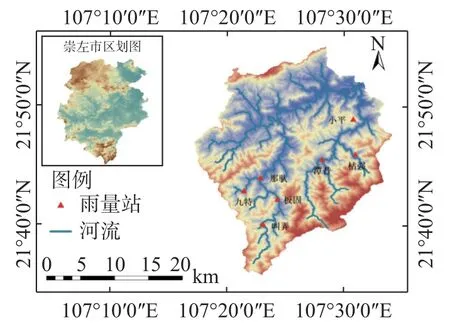
图1 驮英水库上游流域示意Fig. 1 Schematic diagram of the upper reaches of Tuoying Reservoir
由于特殊的地理位置和气候特征,驮英水库流域降雨分为台风雨和非台风雨2种类型。驮英水库未建前曾设有驮英水文站,水文站目前已停测,存有1987—1999年共计13 年的水文气象资料。驮英水库上游流域已建九特、那驮、板固、叫弄、枯强、潭昔、小平共7个雨量站,各站实测降雨是水库来水预报的重要数据来源,现仅有2012—2018年实测资料。数据的不完整性给洪水预报模型的建立和率定带来了一定挑战。由于台风雨与非台风雨的时空异质性差异较大,采用线性协整理论与SPA法分别对台风雨和非台风雨两种情况下的降雨进行插补移用计算。基于线性协整理论的台风雨选取板固和叫弄站2013年、2014年和2016年的3场降雨资料计算;非台风雨选取那驮、九特、板固站2013年、2015年、2017年和2018年的4场降雨序列进行SPA分析降雨数据移用计算。
2.1 基于线性协整关系的台风降雨计算
由于降雨序列为非平稳序列,台风影响下一定范围内雨量站的原始降雨序列间存在“伪回归”的线性关系。因此,需进行协整分析。首先对降雨序列进行ADF检验,以2013年某场降雨为例,表1为台风雨过程下的流域上游板固站与叫弄站降雨序列的ADF检验结果。从表1可以看出,板固站与叫弄站的AIC及SC值均在无截距无趋势模型达到最小,且两站的降雨经一阶差分后均无单位根,这说明经过一阶差分后的降雨序列成为平稳序列,且都为一阶单整序列。

表1 板固站及叫弄站降雨序列ADF检验结果Tab. 1 ADF test results of rainfall series at Bangu Station and Jiaonong Station
用普通最小二乘法(OLS法)估计上述雨量站两降雨序列的长期均衡方程:

对回归方程的残差进行单位根检验,检验结果见表2。残差平稳性检验按照第1种情形(有截距有趋势)接受原假设、第2种情形(有截距无趋势)接受原假设、第3种情形(无截距无趋势)拒绝原假设的流程说明残差是平稳性序列,从而进一步证明了在该场台风雨影响下板固站与叫弄站的降雨序列满足长期线性协整关系。

表2 残差序列ADF检验结果Tab. 2 ADF test results of residual sequence
基于二者的线性协整关系建立ECM误差修正模型,其中,ect-1为两个降雨序列协整关系的前一时刻计算残差,并利用OLS法进行误差修正模型的回归分析:

根据板固站的降雨序列,利用ECM模型计算叫弄站的降雨序列,计算结果见图2。场次雨量峰值的绝对误差为0.7 mm,计算结果和实测降雨的最大绝对误差也仅为4.0 mm,且降雨峰值出现时间相同;计算结果与实测数据的纳什系数为0.901,相关系数为0.979,主雨峰相对误差1.5%,场次降雨总量相对误差0.3%,误差较小满足要求,这表明该方法可以用于降雨序列间的插补计算。
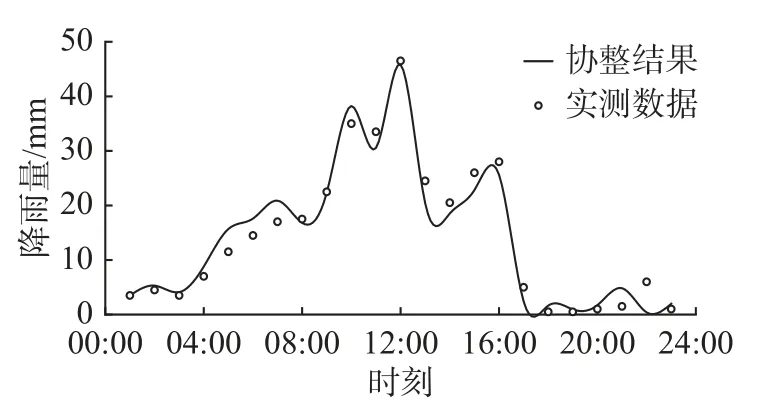
图2 叫弄站协整计算结果与实测降雨对比Fig. 2 Comparison of co-integration calculation results and measured rainfall at Jiaonong Station
利用协整理论对2014和2016年的两场降雨计算分析,模拟结果见图3。可以看出,总体计算结果较好。2014年场次降雨协整计算结果和实测数据相比,最大绝对误差9.4 mm,纳什系数0.892,相关系数0.955,主雨峰相对误差6.25%,场次降雨总量相对误差8.8%;2016年某场降雨与真实数据对比,最大绝对误差6.9 mm,纳什系数0.886,相关系数0.958,主雨峰相对误差14.69%(实测降雨47.0 mm,模拟降雨40.1 mm),场次降雨总量相对误差8.1%;协整计算雨量与实测数据拟合效果较好。由此可见,雨量信息缺失值可采用测站间协整理论插值得出,提高降雨序列完整性。

图3 叫弄站协整计算结果与实测降雨对比Fig. 3 Comparison of co-integration calculation results and measured rainfall at Jiaonong Station
2.2 基于SPA的非台风降雨移用
那驮、九特、板固3个雨量站间彼此相邻,2018年某一场降雨实测过程如图4所示。可以看出那驮站的降水峰值处于板固站和九特站之间;该场降雨中,板固站降水峰值时刻更接近那驮站雨量峰值时刻,板固站和那驮站相关系数为0.907,九特和那驮的相关系数为0.725,板固站降雨序列和那驮站的相关性更好。从降水时空分布初步考虑,板固站的降水数据移用到那驮站更为合理。

图4 各雨量站场次降雨数据对比Fig. 4 Comparison of rainfall data of each rainfall station
选取非台风雨影响下的那驮、九特、板固站记录的场次降雨序列分别进行CEEMD分解,结果见图5。CEEMD将降雨原序列分解为4个IMF分量,每个IMF的频率、振幅、周期都不同;从IMF1到IMF4频率和振幅变小,周期变长;IMF1和IMF2的振幅和频率较大,周期较短,IMF3和IMF4的振幅和频率较小,周期较长。
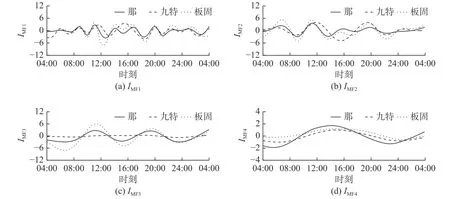
图5 CEEMD分解结果Fig. 5 CEEMD decomposition results
每个IMF分量的集对分析结果见表3。从表3可以看出,本场降雨过程中,那驮-九特的同一性较高,而差异性和对立性低于那驮-板固站,具体表现在那驮站-板固站的平均综合联系度0.893,那驮-九特的平均综合联系度0.732,在数据移植时更适合将板固站的资料移用到那驮站。尽管九特站与那驮站的距离更近,但场次降雨相似性在很大程度上取决于降雨的时空分布。

表3 IMF分量集对分析结果Tab. 3 Analysis results of IMF component set pairs
假设将九特站与板固站记录的该场降雨过程分别移植至那驮站,并参与面雨量计算进行洪水预报。建立的SCS-CN模型经率定后纳什系数为0.87,满足预报精度要求,可用于洪水模拟研究。移用数据的预报结果与真实那驮站降雨资料预报结果见图6。结果表明:利用九特站移用的降雨数据的水文预测值与真实数据预测值之间的纳什系数为0.847,自板固站移用数据的模拟结果与真实预报值间的纳什系数为0.905。因此,板固站的移用数据模拟效果好于九特站。在洪峰预测精度上,实测洪峰为563 m3/s,采用板固站移用情况下预测洪峰为591 m3/s,相对误差为4.97%;采用九特站移用情况下洪峰为503 m3/s,相对误差为10.70%。这说明自板固站移用降雨数据更能保证洪峰流量的准确性,可避免因低估洪峰而发生重大生命财产损失。

图6 洪水预报模拟结果对比Fig. 6 Comparison of flood prediction simulation results
那驮、板固、九特降雨资料中,存在多场降雨那驮-板固的综合联系度好于那驮-九特的现象。另外,分析了2013年、2015年和2017年3场降雨测站间集对关系。结果表明:2013年那驮-板固的综合联系度为0.863,略好于那驮-九特的综合联系度(0.836);2015年那驮-板固的综合联系度(0.866)明显高于那驮-九特的(0.741);2017年那驮-板固的综合联系度(0.816)略高于那驮-九特的(0.786)。将板固站的降雨资料移用到那驮站作为洪水预报输入,模拟结果都好于九特站移用结果。因此,非台风雨影响下的目标站点降雨资料移用时,提前对相邻站点同时段现有序列分别进行集对分析,根据综合联系度指标衡量移用对象在此场降雨中与目标站降雨序列的相似性,可提高移用数据的可靠性和合理性。
3 结 语
针对驼英水库洪水预报过程中降雨数据短缺现象,提出了基于线性协整和集对分析分别对台风雨和非台风雨降水序列插补移用,并用此方法对驮英水库进行了洪水预报研究。主要结论如下:
(1)基于线性协整关系的台风雨计算,测站之间满足线性协整关系,协整理论模拟值与实测降雨的纳什系数均在0.85以上,相关系数均大于0.90,绝对误差、主雨峰相对误差和场次降雨总量误差均较小,这表明该方法可以插补降雨序列,提高降雨序列的完整性。
(2)非台风降雨移用采用SPA,各个雨量站经CEEMD分解,将IMF的分量采用集对分析,根据综合联系度计算结果移用最佳的降雨资料,利用移用降雨数据进行洪水预报,其纳什系数达到0.85,洪峰预测值相对误差较小。由此可见,SPA方法为无资料地区降雨数据移用提供了一种新思路。
