基于CWGAN-GP 平衡化的网络恶意流量识别方法
2022-10-29丁要军王安宙
丁要军,王安宙
(甘肃政法大学网络空间安全学院 兰州 730070)
在机器学习和数据挖掘领域,恶意流量不平衡是一种普遍存在的现象。目前对恶意流量不平衡数据分类的研究主要涉及两种方法[1]:一是对分类算法进行新的设计或改进;二是在数据级别上进行操作,主要通过过采样、欠采样或混合采样来达到数据集的平衡。现有的过采样方法主要分为传统方法和基于生成对抗网络的方法。大多数传统的过采样方法都基于SMOTE 技术[2],由于这些方法更关注局部数据信息,生成的数据不够真实;另一种是基于生成性对抗网络(generative adversarial networks,GAN)[3],它可以捕捉数据的真实分布并直接生成合成数据,用于无监督学习。随后,文献[4]提出了一种基于条件生成对抗网络(conditional generative adversarial networks, CGAN)的模型,该模型在GAN的基础上加入了条件信息生成特定的类别。然而,GAN 与CGAN 都会受到不稳定训练(梯度消失)和模式崩溃的影响。为解决这些问题,WGAN(Wasserstein generative adversarial networks)[5]随 即被提出,该模型使用EM 距离(也称为Wasserstein)而不是JS 散度来度量真实数据分布和生成数据分布之间的距离,从理论上解决了梯度消失的问题,可有效缓解模式崩溃问题。但CGAN 与WGAN 依然存在着训练只生成质量不高的样本或模型无法收敛。在使用GAN 模型解决网络恶意数据分类问题中,文献[6]提出了GAN 模型生成具备可执行性和攻击性的恶意网络流样本,但它只针对缓冲区溢出漏洞攻击进行了研究,模型的泛化性有待进一步研究。文献[7]提出了Attack-GAN 模型,用于生成能够敝开入侵检测系统的数据包级别对抗网络流量。文献[8]提出将WGAN-GP 与CGAN 优势融合的CWGAN-GP(conditional Wasserstein generative adversarial network-gradient penalty)方法,该方法不仅生成更真实多样的数据,而且克服了模式崩溃和训练不稳定的问题。
本文将WGAN-GP 与辅助条件信息相结合,作为一种新的过采样方法,为网络流量图片不平衡数据集中的少数类生成合成样本。
1 CWGAN-GP 原理
与其他GAN 模型及其衍生版本类似,CWGANGP 也是由鉴别器(discriminator)和生成器(generator)组成,它们以相反的方式训练,通过博弈使得生成的样本与真实数据无法区分。CGAN 模型在原始GAN 模型上添加辅助条件信息,WGAN-GP 模型以同样的方式扩展到CWGAN-GP。CWGANGP 采用EM 距离来评估真实样本和模拟样本之间的分布,且加入了条件信息。Wasserstein 距离为:

CWGAN-GP 是通过惩罚鉴别器相对于其输入梯度的范数来替代WGAN 削减权重,有效克服了WGAN 模型难以收敛的问题。
为限制生成器生成方向,使生成器能够生成特定类别数据,与CGAN 类似,CWGAN-GP 模型向生成器和鉴别器添加了附加信息y,y可以是类别标签或任何其他类型的辅助信息。本文中条件信息是类别标签。在鉴别器中,将Pdata、Pg和y以联合隐藏表达的形式结合;在生成器中,以相同的形式将条件y与生成数据分布pg连接。函数形式为:

CWGAN-GP 的目标是使L最小化[9],从而实现生成数据与真实数据之间的分布距离更小。与传统的过采样方法相比,CWGAN-GP 直接生成数据,而不只是关注局部信息。
2 基于CWGAN-GP 的流量图片数据平衡方法
由于深度学习模型对输入数据格式有具体要求,本节介绍数据集的预处理方法,将原始流量数据进行图片化处理,在此基础上对数据扩充平衡。
2.1 网络流量图片化
基于文献[10]对数据处理的经验,本节的网络流量图片化主要是使用工具集USTC-TK2016 将原始流量数据(PCAP 或PCAPNG 格式)处理成IDX数据集格式(更好的迁移到多数模型)。
1) 流量切分:按照流量表示形式将原始PCAP文件按照数据流形式切分为多个PCAP 文件,本数据流是具有相同五元组信息的数据包的时间排序集合。
2) 图片生成:将处理过的文件按照784 字节进行统一长度处理,即保留文件前784 字节数据,舍弃文件785 字节以后的所有信息,如果长度少于784 字节,则在文件后面补充0x00;统一长度后的文件按照二进制形式转换为灰度图片,即一个字节对应灰度像素值,如0x00 对应黑色,0xff 对应白色,输出格式为PNG。
3) 数据集格式转换:将生成的多类别图像转换为包含图像像素信息和统计信息的IDX 格式,方便后续数据扩展和分类模型输入。
完成以上处理操作后,每张图片都是28*28 的灰度图片,这些图片类别之间有良好的区分度,保证了深度学习模型分类有很好的效果。
2.2 流量图片数据平衡
将预处理完成的数据放入CWGAN-GP 图像生成器中,利用CWGAN-GP 能稳定地生成多样样本的特点产生新的少数类别流量图片。生成数据是具有真实图像特征且多样性较强的扩充数据,利用这些数据对原始不平衡数据集进行数据扩充,不仅能有效平衡数据集,还能防止像传统上采样技术扩充数据集所造成的数据样本单一、训练模型容易过拟合的问题。CWGAN-GP 网络的鉴别器损失是与生成图片质量高度相关的参数,在生成阶段加入一个判别函数,在鉴别器、生成器损失小于某阈值时输出生成图像,保证生成的图像与原始真实图像的高度相关性。平衡方法如图1 所示。
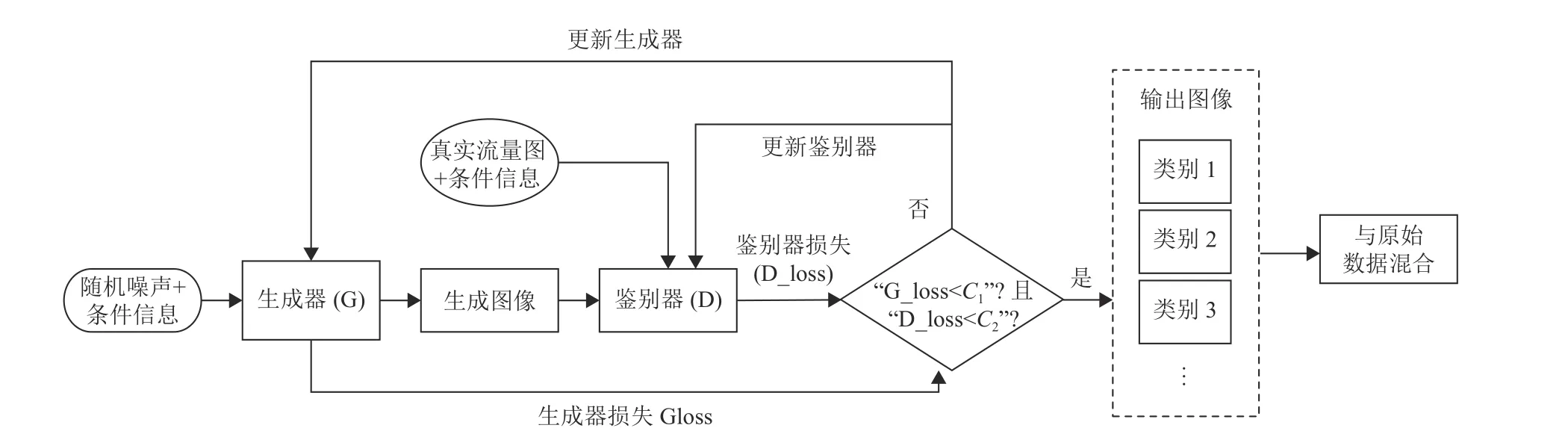
图1 基于CWGAN-GP 数据平衡方法
1) 将需要扩充的少数类真实流量图制作成IDX数据集格式,输入进CWGAN-GP 模型中进行训练。
2) 在生成器损失小于C1且鉴别器损失小于C2时,将生成器骗过鉴别器的图像按类别输出。本文的C1、C2绝对值大小分别为1.0 和0.2,在大量训练情况下记录生成器、鉴别器损失大小变化,如图2 所示,C1、C2是在考虑时间效率下相对收敛的损失值大小。

图2 生成器、鉴别器损失变化
3) 将生成的流量图片与原始流量图片进行合,完成原始数据集的平衡。
平衡完成的数据是和原始流量图片高度相关且具有多样性,如图3 所示,可以看出利用此方法可以生成人眼均可明确分辨的相关图像,且具有一定的多样性。生成数据相关程度在实验结果中得到验证。

图3 生成流量图与真实流量图对比
3 实验结果分析
3.1 不平衡数据集
实验使用的是公共数据集USTC-TFC2016 和CIC-IDS2017[11]中的部分数据,数据集由原始PCAP文件组成。从USTC-TFC2016 中选择了9 类应用程序,其中包括6 类正常应用流量和3 类异常应用流量;从CIC-IDS2017 选择10 类应用程序,9 类异常应用流量和1 类正常流量,数据集均有较大的不平衡。使用不同方法使数据集实现平衡,将数据样本随机划分成90%的训练集和10%的测试集。数据集平衡前后分布如表1 和表2 所示。为保证实验有效性,数据集的测试集部分均为真实数据,生成数据只对训练集部分进行平衡。

表1 USTC-TFC2016 数据集平衡前后分布

表2 CIC-IDS2017 数据集平衡前后分布
3.2 模型参数设置
对于相同的超参数,设置均保持相同;对于不同的超参数,单独设置。GAN、WGAN 和CWGANGP 均为4 层神经网络,噪声空间的维数设置为100,batch_size 设置为64。WGAN 和CWGAN-GP将α、β1、和β2 分别设置为0.002、0.5 和0.999;clip_value 均为0.01;critic 设置为5,即当生成器训练1 个batch 时,判别器要接着训练5 次;梯度惩罚系数λ 在CWGAN-GP 中设置为10,训练批次均为在满足2.2 节条件下且生成数据数量足够时停止;SMOTE 方法的k_neighbors 为5。
本文使用的分类模型是经典LeNet-5[12]的CNN结构,CNN 模型使用交叉熵损失,batch_size 设置为50,训练轮次均为2 000。
3.3 评价标准
本文使用评价网络流量分类器的性能指标有精确度(precision)、召回率(recall)和F1-score。
3.4 实验结果及分析
实验在一台配置了Intel(R)Core(TM) i7-7700HQ CPU @2.80 GHz 处理器、16 GB 内存、GPU(GeForce GTX1050)、Win10 系统的笔记本电脑上运行。使用TensorFlow 1.15.0+Keras 2.3.1 深度学习平台实现分类操作,基于GAN 及其衍生版本的数据生成方法使用torch1.3.1+GPU 实现。
使用CNN 模型对5 种平衡方法和原始数据进行实验测试。只对训练集进行处理,测试集全部为原始数据。随机选取10%的样本集作为测试集,并对剩余90%的数据集进行平衡化作为训练集。为消除随机划分数据集对结果的影响,将实验重复5 次取平均值作为最终结果,结果如图4、图5所示。

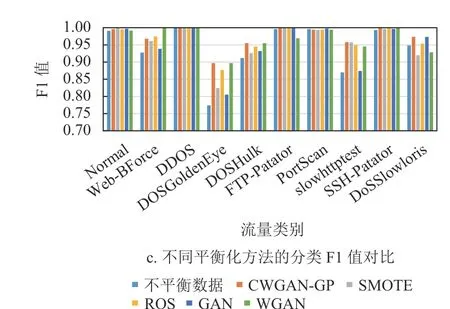
图4 CIC-IDS2017 分类结果对比

图5 USTC-TFC2016 分类结果对比
经过对比得到在相同训练参数下,使用CWGAN-GP 方法进行流量图片平衡后的数据集相较于其他分类方法识别效果提升明显,且在多数类别上识别均值高于使用其他平衡方法。CWGANGP 方法的最终效果优于其他方法,F1 值在IDS2017上相较于原始数据提高近3%,较于SMOTE 方法提高近2%;在TFC2016 上较原始提高近4%,较SMOTE 提高近1.3%;在两个数据集上均有识别率较低的流量类别,这些流量类别具有一定隐蔽性,不易被识别出来,但本方法对识别率有较大提高,验证了本方法具有一定的鲁棒性,且不易出现模式崩溃和收敛困难的问题。由于相较于WGAN-GP添加了辅助信息,在生成效率上也有很大提高。均值结果统计如表3、表4 所示。

表3 CIC-IDS2017 分类结果均值统计
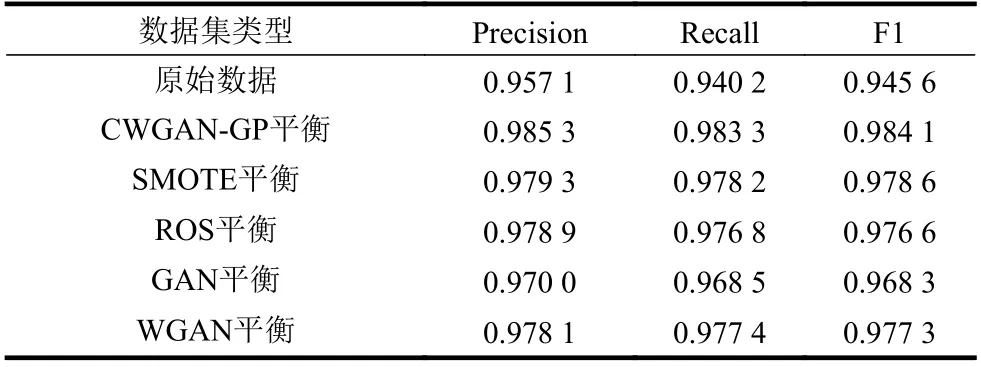
表4 USTC-TFC2016 分类结果均值统计
4 结 束 语
本文提出了利用流量图片化结合CWGANGP 来处理恶意流量识别领域的不平衡问题,此方法通过学习原始数据的真实分布来生成新的数据。
在两个不同的恶意流量不平衡数据集上,通过使用深度学习分类算法CNN 对基于CWGAN-GP方法进行了评估。实验结果表明,CWGAN-GP 在所有指标下均优于其他过采样方法,但需要更多的时间进行训练。在未来的研究中,将对CWGANGP 进行更加深入的理论研究,加速其训练和收敛过程;并探索更加合理的生成数据评价指标。
