基于特征解耦的无监督水下图像增强
2022-10-29刘彦呈董张伟朱鹏莅刘厶源
刘彦呈 董张伟 朱鹏莅* 刘厶源
①(大连海事大学轮机工程学院 大连 116026)
②(大连海事大学船舶电气工程学院 大连 116026)
1 引言
21 世纪是海洋的世纪,世界各国家无不将目光投向海洋,纷纷提出了各自的海洋发展规划。清晰的水下图像和视频可以提供宝贵的海洋信息,这对于许多工程和研究任务是必不可少的。然而,复杂的水下成像环境使水下图像质量下降,如散射效应会造成细节模糊和低对比度,波长吸收会导致图像颜色偏差等。对水下图像进行质量增强,可以改善图像的整体或局部特性、丰富可用信息,有利于提升后续处理任务的精度。目前,针对水下图像增强的传统算法诸多,如基于归一化的方法[1,2]、基于Retinex理论的方法[3,4]、基于滤波的方法[5]和基于融合的方法[6]等,它们大多基于水下成像模型[7,8]考虑光在不同波长水介质中的衰减程度,然而由于模型参数的复杂性和不确定性限制了其表现效果。
近年来,得益于深度学习强大的非线性映射能力,越来越多的研究者提出基于深度学习的水下图像增强方法[9]。Sun等人[10]提出一种像素到像素(Pixel-to-Pixel, P2P)的对称编码解码网络结构,在合成成对数据集上训练得到能将水下图像映射至清晰图像的网络模型。Wang等人[11]提出了一种多支路水下图像增强网络框架,采用共享网络提取图像特征,通过色彩修正和去模糊子网络生成修正色差的图像和去模糊的图像。Li等人[12]提出了一种基于门控融合网络的水下图像增强方法,通过卷积神经网络融合降质图像及其白平衡、直方图均衡和伽马校正的置信度图获得增强的水下图像。上述方法的效果一定程度上依赖成对数据集的质量,目前数据集的制作普遍利用先验信息进行合成,这种做法很难反映真实水下图像特性,所以模型的泛化能力不强。
随着生成对抗网络(Generative Adversarial Network, GAN)[13]在图像变换的飞速发展,诸多学者将其应用于水下图像增强领域。Fabbri等人[14]提出基于梯度惩罚的Wasserstein生成对抗网络(Wasserstein GAN with Gradient Penalty,WGAN-GP) [15]架构的水下生成对抗网络(Underwater Generative Adversarial Network, UGAN),对鉴别器的输出通过梯度规范的Lipschitz进行软约束,而不是在某些范围内剪切梯度,但是增强后的图像边缘比较模糊。Guo等人[16]提出了一种多尺度密集块算法(DenseGAN),通过密集连接、残差学习和多尺度网络对水下图像进行增强,提升了图像的视觉效果,但是增强的图像存在颜色失真。Li等人[17]先用WaterGAN生成成对的水下数据集,再由深度估计网络和颜色校正网络组成图像修复网络对图像进行修复,该方法能够很好地恢复出水下物体的颜色,但是纹理细节恢复不理想。合成训练数据限制了模型的泛化,因此不依赖成对数据集的无监督学习是水下图像增强的一个新方向。Lu等人[18]提出了多尺度循环生成对抗网络(Multi-scale Cycle Generative Adversarial Network, MCycleGAN),其目的是将水下图像的风格转移到清晰风格,通过将结构相似性指数 (Structural SIMilarity index,SSIM)损失函数融合至循环生成对抗网络 (Cycle Generative Adversarial Network, CycleGAN)[19]进而改善水下图像的恢复,并实现了无监督学习。Islam等人[20]提出了一种基于条件生成对抗网络(Conditional Generative Adversarial Nets,CGAN)[21]的水下图像实时增强模型,该模型通过感知图像的整体结构、颜色和风格信息来评估感知质量,可以通过成对和非成对数据集训练来提高水下图像质量。这些基于CycleGAN改进的方法尽管克服了模型对配对数据集的依赖问题,但这些方法往往在一个编码器中编码很多信息(如颜色、纹理和结构等),因此恢复的图像会产生一些不期望出现的失真。
为了解决上述问题,近期诞生一些无监督算法将图像解耦为域不变的结构特征和特定域的风格特征,从而产生多样的图像到图像的变换输出[22,23]。Liu等人[24]采用这种特征解耦方法提出了一种无监督循环变换网络,在编码-解码卷积神经网络架构下,采用分解循环变换和特征互换变换,去除了图像伪影。这类无监督的方法生成的图像细节更清晰,给水下图像增强领域提供了新思路。
本文提出一种基于特征解耦的无监督水下图像增强方法,通过使用结构编码器和风格编码器对水下图像中的结构和风格特征进行分割来实现解耦,同时结合多种损失函数对各模块输出结果进行针对性约束,用来保障网络训练的稳定性。此外,在主干网络中设计多尺度特征融合结构,将风格信息与多尺度的结构信息融合,得到的增强水下图像细节更清晰。
2 基于特征解耦的无监督水下图像增强方法
针对水下图像失真严重且无成对数据集的问题,本文所提基于特征解耦的无监督水下图像增强方法,在结构-风格特征解耦的学习机制下,采用结构风格双编码和多尺度融合解码的网络结构,结合对抗学习和特征一致性约束,最终建立一种通用的无监督水下图像增强策略,用于实现水下多种失真图像的通用质量增强。
2.1 水下图像结构风格特征解耦
本文的主要目标是解决复杂失真水下环境中的无监督图像增强问题,即无需同一场景下的配对图像训练。为了解决该问题,本文将水下图像增强问题转换为风格迁移建模,其中最重要的就是图像结构和风格特征分离。一般来说,水下图像包含结构信息(纹理、语义)和风格信息(色差、模糊、噪声以及清晰)。我们的目标是将水下图像在特征空间中解耦为这两个成分,而水下图像增强可以在保证结构信息一致的前提下,通过将清晰图像的风格特征迁移到失真图像结构特征上来实现。
首先将水下图像数据集分成失真和清晰两组,借鉴无监督学习解纠缠表示[25]的思想,即一个模型可以通过在这两组图像内在比较中自学习特征的分离,在模型的输出之间应用自我监督来指导潜在空间的操作,从而避免了对成对图像的需求。在此基础上,本文提出了具备结构和风格编码的水下图像增强网络结构,分别处理两组图像的风格和结构特征。这种不同组合的编码操作支持多种形式的图像风格转换,并且可以方便添加不同约束来促进期望纹理和语义结构信息的一致性,在保证完整细节信息的前提下,实现水下复杂失真图像的质量增强。
2.2 基于特征解耦的无监督水下图像增强方法
由于难以获得大量真实水下图像配对数据集,故无法提供为水下图像增强模型提供有效的监督信号,这将造成生成的增强图像中结构信息的缺失,为了解决该问题,本文借鉴CycleGAN[19]的思想,引入反向变换特征解耦和融合的过程,以保证增强前后图像的结构相似性。即合成图像xy和yx由结构编码器和风格编码器分别对结构特征和风格特征进行编码,再进行风格特征的交换恢复到x˜ 和y˜。用公式表示为
2.2.1 生成器网络结构
如图2所示,图2(a)是编码器和解码器构成生成器网络结构,有3种核心模块;图2(b)是下采样残差块;图2(c)是残差块;图2(d)是融合模块。下采样残差块和残差块都使用残差连接[27],允许在计算高层特征时考虑低层特征。这种设计对深度神经网络显示出更好的性能。结构编码器由卷积、下采样残差块和残差块组成。风格编码器由卷积、下采样和全局池化层组成。解码器将风格码和结构特征融合并上采样到原图大小,由融合模块、反卷积和卷积组成。上采样时使用反卷积,反卷积与插值上采样方法对比的优势在于可学习,理论上模型可以通过学习获取最适合当前数据集的上采样方式。在解码器中采用多尺度特征融合机制,将在下一节介绍。
2.2.2 多尺度特征融合
本文提出一种特殊的方法,在对图像特征进行解码时将结构特征和风格特征合并。本文参考金字塔解码器[28],设计了一种多尺度融合策略。对于水下图像的编码和解码,本文的目标是有效地恢复图像的细节。多尺度融合将风格码与不同大小的结构特征图融合,包括了高清晰度特征,很好地满足了这一目的。多尺度融合如图2(a)所示,Exs/Eys对原图下采样得到长度为8的1维的特征向量,本文称为风格码,Gx/Gy由融合模块、残差块和最后的卷积层组成。通过在解码过程中将风格码与不同尺度的结构特征合并来生成目标域的图像。结构特征和风格特征融合时,使用自适应实例归一化(Adaptive Instance Normalization, AdaIN)[29]
其中,µ(c)和σ(c)分别表示结构特征的均值和标准差,µ(s)和σ(s)分别是风格特征的均值和标准差,结构特征先去风格化(减去自身均值再除以自身标准差),再转换风格到失真特征的风格(乘风格特征的标准差再加均值)。
2.3 损失函数
考虑生成图像的视觉效果和细节特征保持,本文设计了6种损失函数以得到期望的输出,各损失函数的关系如图3所示。模型训练时使用以下不同损失函数的线性组合,即
2.3.1 对抗损失函数
为了使生成的图像看起来更真实,本文在两个领域都应用了对抗损失函数[18]。对于清晰的图像域,本文将对抗性损失定义为
2.3.2 KL散度损失函数
在水下图像特征解耦的过程中,需要对图像的结构信息和风格信息分别解码,目标是结构信息尽可能只包含图像的纹理和语义特征。由于图像的风格信息服从相同的分布,而结构信息则各不相同,确保水下图像结构特征与风格特征的分离,本文引入了KL散度损失[30]将风格特征的分布z和规范为正态分布以抑制所包含的结构信息,具体形式为
其中,µi,σi,N分别为风格特征分布的均值、标准差 和维度。
2.3.3 自重建损失函数
为了确保编码和解码过程中没有信息丢失或模型引起新的失真,水下图像增强模型应具有自我重建能力,即按照编码器提取的结构和风格信息重新生成原图像。因此,我们引入自重建损失,具体公式为
2.3.4 循环一致损失函数
由于非配对数据集中无法提供监督信号,造成生成的增强图像可能不会保留原始图像中的结构信息。为了解决该问题,本文引入了循环一致性损失[18],以保证增强前后图像的结构尽量相似,具体公式为
2.3.5 风格一致损失函数
为了保证风格特征提取的一致性,约束生成的清晰和失真图像与原图的风格保持一致,具体公式为
2.3.6 结构一致损失函数
实验过程中发现仅依靠循环一致性损失,无法保证生成图像与原图像的结构完全一致,为了加强约束生成前后的结构特征一致性,本文引入结构一致损失,其具体公式为
3 实验结果与分析
为了验证所提方法的有效性,将本文与传统基于模型的方法和基于学习的算法进行实验对比,并从主观和客观的角度对结果进行对比分析。实验结果表明,本文算法针对水下图像质量增强具有较高的鲁棒性。实验在Ubuntu操作系统下,基于深度学习框架Pytorch实现,服务器CPU为Intel Core i7-8700K, GPU为NVIDIA GeForce GTX 2080Ti 11GB。
3.1 数据集和训练细节
为了验证所提水下图像增强算法的有效性,本文选用增强水下视觉感知数据集 (Enhancement of Underwater Visual Perception, EUVP)[20]中的非配对数据集作为训练集,共包含3195张低质量图像和3140张高质量图像,其通过志愿者根据颜色、对比度和清晰度等属性对图像质量进行分离,此无配对数据集支持了人类对水下图像质量感知偏好的建模。本文的测试集是在网上筛选的200张严重失真水下图像(大部分呈现过蓝或过绿的特性),来评估所提方法的性能。
在训练过程中,E,G和D的 优化以交替的方式进行。同时,为了提高模型的性能,采用了数据增强策略,随机裁剪128×128个图像块,将训练集随机水平和垂直翻转。本文模型训练均使用Adam[31]优化器。其中,设置学习率为0.0001,1阶动量项为0.1,2阶动量项为0.99。网络以小批量梯度下降方式进行优化,设置Batchsize大小为4,总Epoch为150。各损失加权系数λKL,λrec,λcyc,λsty,λcont在本训练中分别取值为0.01, 5, 10, 5, 5。
3.2 定性分析
本文从测试集中选取了色差失真严重程度不同的场景,并将本文算法与IBLA(Image restoration based on Blurriness and Light Absorption)[32],SMBLO(Statistical Model of Background Light and Optimization of transmission map)[33],UGAN[14], UWGAN(Underwater Weakly supervised Generative Adversarial Network)[34], FUnIEGAN(Fast Underwater Image Enhancement)[20]进行比较,其中文献[32,33]是传统基于模型的方法,文献[14,20,34]为基于学习的方法,最终各算法的定性分析的对比结果如图4所示。
从图4可以看出,IBLA缺少颜色校正功能,无法修正偏蓝偏绿失真,不能有效解决水下图像的偏色问题;SMBLO方法具有明显效果提升,主要归功于复杂的还原机制,但是过度增加了图像的亮度和对比度,使视觉效果显得过亮甚至产生过曝光现象(如第4和第6幅图);相比之下,基于学习的方法的视觉增强效果更好,其中UGAN和FUnIE-GAN算法均采用端到端的单输入模型结构,在增强效果中均出现局部区域红色过度补偿问题(如第4幅图),并且对于严重色差失真并不敏感(如第1和第5幅图)。此外,UGAN经常过度饱和场景中的明亮物体(如第2幅图),FUnIE-GAN算法采用了轻量级模型,其速度得到了明显提升,但在非配对训练的模型对色彩风格的纠正能力欠佳。在水下图像增强的背景效果方面,UWGAN毫无疑问是所有对比方法中最优异的,基本上可以还原出脱水特性的背景特征,但是对于局部目标会出现颜色失真的现象(如第3幅图中的人物雕像和第5幅图的乌龟背部),均出现了不同程度的泛绿。
相比之下,本文的方法在不使用场景深度或先验水体信息的情况下,视觉增强效果超越了基于物理的方法,在无配对数据集训练的情况下,效果媲美现有的基于监督学习模型,并且生成的图像有用更丰富的细节特征,从而扩大了使用范围,在主观视觉增强效果方面具有一定的优势。
除上述对比实验以外,本文提出的方法还可对真实的水下视频进行处理,处理后的视频上传于网址https://www.bilibili.com/video/BV1TS4y1771Y/。
3.3 定量分析
为了更加客观地评价和分析本文所提方法的性能,本文采用了通用的无参考水下图像质量评价指标来对算法进行定量分析,如表1所示,分别为水下图像质量评价指标(Underwater Image Quality Measure, UIQM)[35]和水下色彩图像质量评价指标(Underwater Colour Image Quality Evaluation,UCIQE)[36]。其中,UIQM方法针对水下图像的退化机理和成像特点,采用水下图像色彩测量指标(Underwater Image Colorfulness Measure,UICM)、水下图像清晰度测量指标(Underwater Image Sharpness Measure, UISM)和水下图像对比度测量指标(Underwater Image Contrast Measure,UIConM)3个测量分量的线性组合作为评价水下图像质量的依据。而UCIQE是以色度、饱和度和对比度为测量分量,通过线性组合的方式将测量水下图像的最终质量。每个评估指标的值越高,图像的视觉质量就越好。
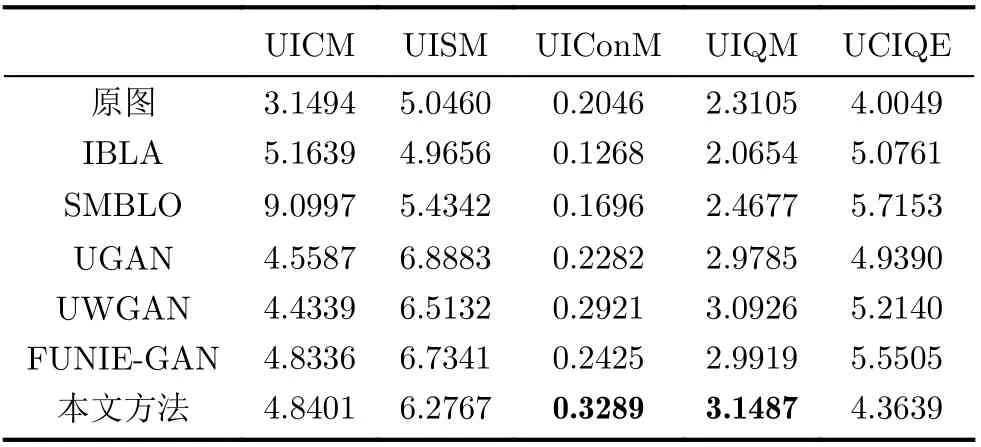
表1 水下图像定量分析对比
从表1可以看出,经过本文算法增强之后,UIConM和UIQM两个指标取得了最优成绩,分别比目前最好效果提高了12.6%和1.8%。在基于学习的方法中,UICM指标领先于其他3种对比方法。同时,UISM和UCIQE均取得了具有相对可观的结果,达到了对本文增强算法的预期。通过以上分析,证明了本文算法能够有效地还原水下图像的真实色彩、提高图像的对比度和清晰度,并可以保留完整的纹理结构特征。
3.4 消融实验
为了进一步研究本文中不同损失函数对算法性能的贡献,进行了详细的消融实验。所有实验的数据均保持一致,便于对各部分的效果进行公平分析。如图5所示为本文消融实验定性分析对比图,其中M1是指仅使用对抗损失Ladv训练的模型,M2是指同时训练对抗损失Ladv和循环一致性损失Lcyc的模型,M3是在M2的基础上增加了风格一致损失函数Lsty和结构一致损失函数Lcont进行训练的模型,M4是进一步增加了自重建损失函数Lrec训练的模型,M5为所有损失函数训练后的模型。
从图5可以看出,M1在仅有对抗损失的情况下,生成图像与原图结构不完全匹配,部分细节信息丢失;相比之下,M2生成的结果中,结构信息比较完整,这是因为循环一致性损失对图像结构细节的保持起到了一定的促进作用;由于结构和风格一致性的约束,M3生成的图像在色彩风格感官效果上恢复得更好,并精确地保留了绝大部分原图结构信息;对于M4,本文发现生成的结果得到了进一步的改进,这表明自我重建机制减少了图像合成的权重,对图像增强的效果确有提升;最后,在特征解耦机制的作用下,本文所采用的M5模型所生成的图像无论在纹理细节上,还是人类视觉主观感受上都达到了最优,有效地改善了图像模型问题,提高了图像清晰度和对比度,同时色彩还原也更加自然真实。
4 结束语
本文提出一种基于特征解耦的无监督水下图像增强方法,展示了如何利用分离的特征来实现不同形式的图像变换以及自我重建;设计针对性的对抗损失和特征一致性约束,解决了训练中缺少配对图像的问题;网络中引入了多尺度特征融合机制,提高生成图像的细节清晰度。使用非配对数据集进行训练,模型对于真实水下图像能够很好地还原场景的颜色及细节,取得与监督学习的方法相当的性能。另外,本文只是笼统地对所有失真类型提取了单一风格码,在下一步工作中可以针对不同的失真类型提取不同的风格码实现更精准地恢复水下图像,这也是后续需要重点研究的工作。
