基于改进FDOD度量的航空发动机健康状况评估
2022-10-29韩亚娟章露露雷小虎
韩亚娟, 章露露, 雷小虎
(上海大学管理学院, 上海 200444)
0 引 言
航空发动机被称为飞机的心脏,其健康状况直接影响飞行的安全性。对发动机健康状况进行准确评估,不仅能减少飞行事故,增强安全性,还可依此作出合理维修决策,提高经济性。高扬等将熵权法引入灰靶技术,建立航空发动机状态评估模型,该研究在评估时仅考虑了各指标的客观权重。崔建国等将层次分析法与熵权法结合,同时考虑了主、客观权重,建立了基于模糊灰色聚类的发动机健康评估模型,提高了健康评估的准确性。然而,熵权法在计算指标客观权重时,忽略了指标间的相关性信息。Wang等利用模糊层次分析法和模糊聚类分析法分别确定指标的主、客观权重,进而基于逼近理想解的排序法(technique for order preference by similarity to an ideal solution,TOPSIS)对发动机健康状况进行评估,提高了健康评估分类准确性。Li等将航空发动机健康评估问题归为一个多准则决策问题,提出了一个两步评估模型。该模型首先利用模糊层次分析法确定多个评估标准的相对权重,进而考虑评估者的态度偏好,使用TOPSIS确定发动机的排序。然而,TOPSIS方法在插入新的样本计算时,会产生逆序问题。
部分学者基于相似性度量评估航空发动机的健康状况。杨洲等针对评估中的多工况、非线性和小子样问题,提出评估发动机健康状况的变精度粗集决策方法,其利用交叉信息熵确定属性客观权重,根据专家经验和运行工况确定属性主观权重,最终形成基于综合权重的加权相似性度量方法。Sun等通过分析发动机无故障状态和当前状态的状态信息,提出利用相似性指数评估单个航空发动机的运行可靠性。张春晓等利用Holt双参数指数平滑方法,建立基于机载快速存取记录器数据的对称发动机性能参数的差异监控模型,可有效识别发动机运行状态,预测发动机故障征兆。张研等通过度量待测样本数据与历史数据的相似性,判断发动机的健康状态,并预测发动机的剩余使用寿命。该类方法判断准确性与历史数据的数量相关,且当出现新的故障模式时,判断准确性将会大幅下降。
航空发动机属于典型的复杂系统,Lim等提出使用切换卡尔曼滤波器确定系统经历的各种退化阶段,进而对每个阶段使用合适的卡尔曼滤波器进行剩余寿命预测,实现了对航空发动机剩余寿命和退化阶段的连续和离散预测。彭宅铭等基于加权马氏距离构建多指标融合成的健康指数模型,对发动机健康状况进行评估。然而,强相关问题将使马氏距离难以计算或很不准确。Wang等针对未标记、不平衡状态监测数据和预测过程不确定性带来的问题,提出航空发动机剩余使用寿命的多元健康评估模型和多元多步提前长期退化预测模型,这种数据驱动的退化预测模型高度依赖于退化数据的数量和质量。Ma等提出一种数据驱动的航空发动机健康状态评估框架,其基于密度距离聚类生成伪标签,进而基于模糊贝叶斯风险模型分配权重和选择特征。该评价方法扩展了健康状态评估的维度和视角,更全面衡量发动机的健康状态。另外,也有学者们采用机器学习类方法对发动机健康状况进行评估,如支持向量机、隐马尔可夫模型等,这类方法前期需要大量数据作为训练集,且机器学习方法易出现过拟合问题,其推理过程和最终结果较难解释。
方舜岚提出使用离散度函数(function of degree of disagreement, FDOD)度量评估商业银行的稳健性,并与线性判别法和单层神经网络法的分析结果进行对比,结果显示FDOD度量的评估效果更好。韩亚娟提出使用FDOD度量代替马氏距离函数作为综合评价指标,并将FDOD度量与田口方法结合进行多维系统优化降维,彻底解决多维系统优化中的强相关问题。利用FDOD度量进行综合评价时,需要的数据量小,评价结果更优,且有利于后期样本异常原因的解释。因此,本文拟采用FDOD度量对航空发动机健康状况进行综合评估,同时为了提高评估结果的准确性,拟对传统FDOD度量进行改进。
1 传统FDOD度量
FDOD度量由方伟武教授于1994年提出,通过度量多个序列/信息源间的信息离散度,来对序列进行比对分析,被用于度量一组序列间的差异程度。
定义一个序列∶=(,,…,),且
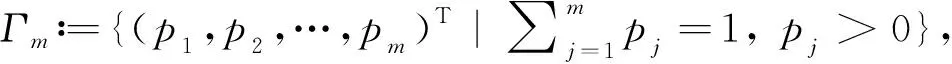
=2,3,…
(1)
则FDOD度量为
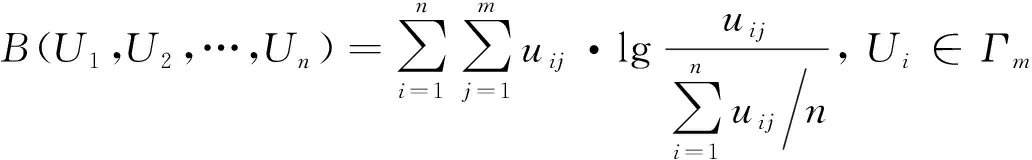
(2)
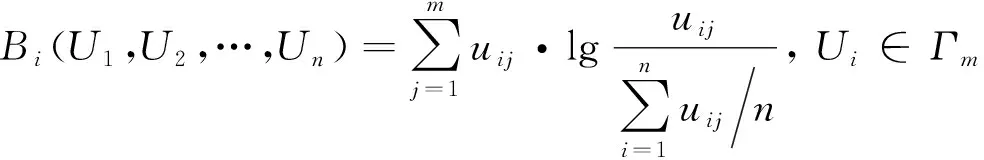
(3)
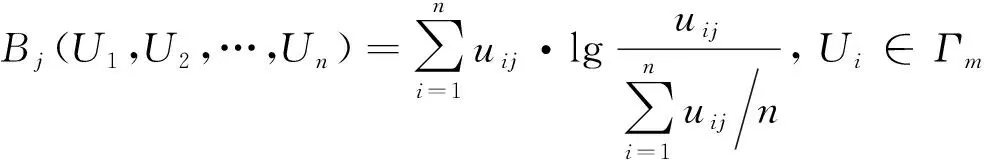
(4)
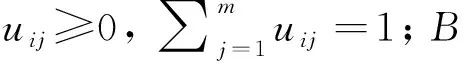
FDOD度量具有许多重要特性,如非负性、连续性、单调递增性等,同时其也被证明是一种距离测度函数。早期FDOD度量主要被应用于多序列相似性比较,目前已扩展到调查表分析、多指标综合评估等领域。
2 传统FDOD度量的改进
2.1 FDOD度量改进的必要性
如文献[17]所述,如果将多维系统的样本(每一个样本包含多项指标)作为一个信息源,用代表第个样本的第项指标值,则可利用式(3)计算第个样本相对于其余样本的离散度。如果将正常参考样本构成一个组,则可计算待测样本相对于正常参考组的离散度。值越大,待测样本偏离正常参考组越远,待测样本的异常程度越高。然而,分析式(3)可知,计算时仅考虑了各指标数据的离散程度,未考虑指标间的相关性和各指标的相对重要程度,降低了样本综合评价的准确性。因此,有必要对FDOD度量中的进行改进,全面考虑各指标的贡献,以提高样本综合评价的准确性。
2.2 改进的FDOD度量
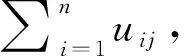
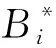
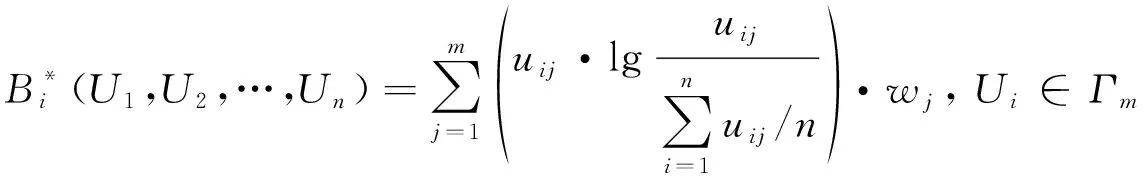
(5)
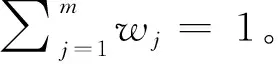
2.3 赋权方法的选择
通过对式(3)分析可知,的计算已考虑了各指标数据的离散程度,但未涉及指标间的相关性信息,而此类信息客观存在,因此需要进行客观赋权。同时,各指标对样本健康状况的贡献不同,因此还需要进行主观赋权。综上,本文将选用组合赋权法对FDOD度量进行改进。
目前,组合赋权主要分为两大类:乘法合成和线性加法合成。乘法合成法是将主、客观赋权法确定的权重对应相乘,再归一化得到各指标的组合权重。该方法适用于指标个数较多且权重在指标间分配相对均匀的情况,当指标较少时会产生乘数倍增效应。线性加法合成法是将多种赋权方法求得的权重向量赋以权重系数进行加法合成,合成时需要考虑决策者对不同赋权方法的偏好;若决策者无明显偏好,则需进一步确定不同赋权方法的权重系数。赋权方法权重系数的确定有多种方法,从是否考虑指标值角度可分为两类:① 只考虑权重值,不考虑指标值;② 既考虑权重值,又考虑指标值。第一类方法求解结果完全不受指标值的影响,但受指标个数的影响,且稳定性不足。第二类方法将权重值与指标值进行融合,通过建立基于不同目标的优化模型进行权重系数的求解,归纳起来主要有3种模型:① 基于综合评价值最大化的组合优化模型;② 基于偏差最小化的组合优化模型;③ 基于离差最大化的组合优化模型。其中,基于综合评价值最大化的组合赋权法是在综合决策结果最优的原则下求解主、客观赋权的权重系数。该方法从评价结果层面求组合权重,更加灵活,解释性更强,但未考虑评价对象之间的区分度。基于偏差最小化的组合赋权法是使组合权重评价值与单一赋权方法评价下的评价值之间的偏差尽可能小,以此建立模型求解主、客观赋权方法的权重系数。该方法提高了组合评价结果与主、客观赋权方法下评价结果之间的一致性,也未考虑评价对象之间的区分度。基于离差最大化的组合赋权法是基于各评价对象之间的差异达到最大的思想,建立模型并求解使评价对象综合评价值更加分散的权重向量,进而提高分类的准确率。该方法可以使最终得到的综合评价值更加分散,便于区分。因此,本文拟采用基于离差最大化的组合赋权法确定各指标的最终权重。
3 基于离差最大化的组合赋权法
3.1 主观赋权法
序关系分析法(简称为G1法)的中心思想是对各指标的重要程度进行对比,确立指标间的序关系,得到指标的主观权重。G1法不仅解决了层次分析法需要检验判断矩阵一致性的问题,而且根据指标重要度来递归排序,保证了思维过程的稳定性,赋权结果更加合理。因此,本文拟采用G1法获得各指标的主观权重,其具体步骤如下。
确定指标的重要性排序

确定各指标的相对重要程度
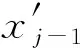

表1 指标重要性评分量表Table 1 Index importance rating scale
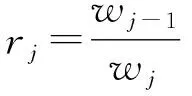
(6)
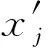
计算各指标的权重
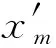

(7)
式中:上标“(1)”代表G1法。接着,逆序计算剩余指标的权重:
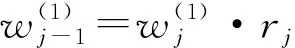
(8)
3.2 客观赋权法——因子分析法
因子分析法由Spearman教授提出,通过分析指标的相关性矩阵,将多指标综合成少数因子,以再现原始指标之间的相对影响程度及其对综合评价值的影响程度,也即各指标的权重值。因子分析法能较好地反映指标间的相关性信息,弥补FDOD度量在进行综合评价时未考虑相关性信息的不足。因此,本文拟采用因子分析法求取各指标的客观权重,其计算步骤如下。
数据标准化处理
设有个样本,项评价指标,表示第个样本的第项指标值。为了消除指标量纲不同带来的影响,对进行标准化处理:
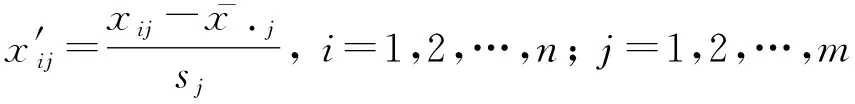
(9)
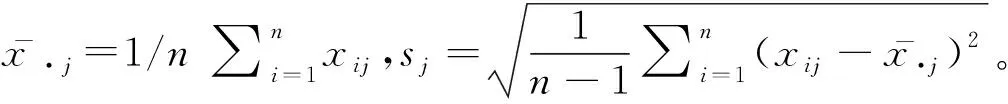
利用标准化后的数据,计算相关矩阵
求的特征值和特征向量
用Jacobi方法求的特征值(=1,2,…,)和相应特征向量(=1,2,…,)。其中,≥≥…≥>0。
选取主因子,建立初始因子载荷矩阵
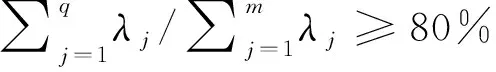
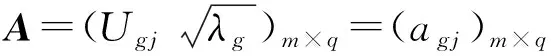
(10)
式中:为第项指标在第个因子处的载荷。
对初始因子载荷矩阵进行旋转变换
如果某个指标同时在多个主因子上有较大载荷,将导致主因子的实际含义模糊不清,此时需对进行旋转变换,使得指标仅在一个主因子上有较大载荷。旋转变换后新的因子载荷矩阵为=()×。
建立因子模型
利用因子载荷矩阵,建立因子模型=+。其中,=(,,…,),为公共因子矩阵,为特殊因子矩阵。
计算主因子得分
根据因子模型,将主因子表示为指标的线性组合,如下所示:
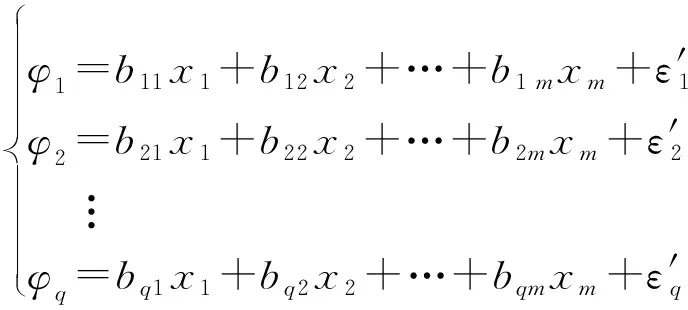
(11)
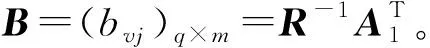
求各指标的权重
根据矩阵得到:
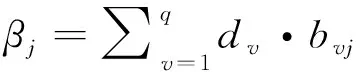
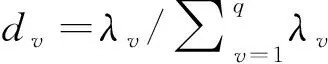
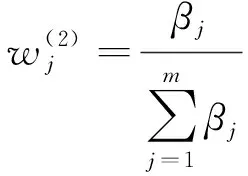
(12)
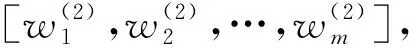
3.3 基于离差最大化的组合赋权法
(1) 模型构建
基于离差最大化的组合赋权法由王应明教授提出。该方法通过建立一个使各赋权方法下的结果值之间距离达到最大的模型,求得各单一赋权方法的权重系数,进而将各单一赋权法求得的权重组合起来,得到各指标的组合权重值。
设有个评价对象,项评价指标,评价对象集为={,,…,}。有种赋权方法,构成赋权方法集={,,…,}。若对象在单一赋权方法下的评价值为,则可得评价结果矩阵=()×(=1,2,…,;=1,2,…,)。设=[,,…,]为各单一赋权方法进行组合时的权重系数向量,为的权重系数。
设为单一赋权方法下评价对象与的离差,则
=|-|
(13)
组合赋权下评价对象与的离差为
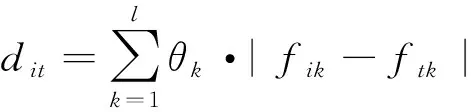
(14)
所有评价对象的总离差为
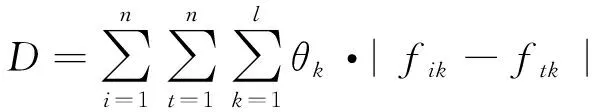
(15)
基于离差最大化思想,构建组合赋权下的最优化模型为
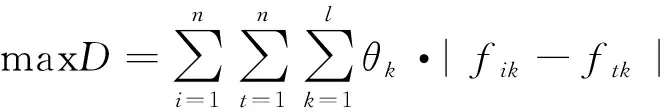
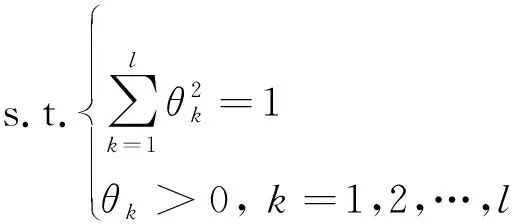
(16)
(2) 模型求解
运用拉格朗日函数求解,得到权重系数:
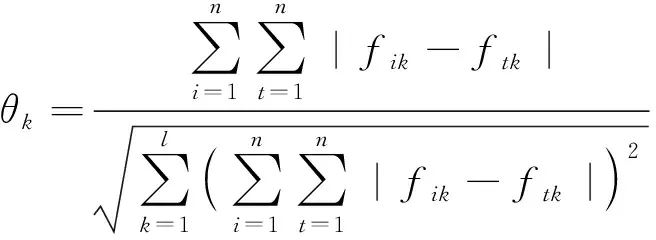
(17)
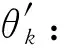
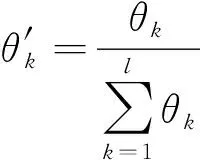
(18)
(3) 确定组合权重
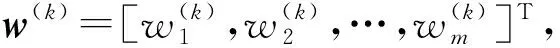
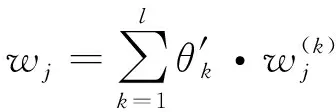
(19)
由此,通过基于离差最大化的组合赋权法得到指标的组合权重为[,,…,]。
4 基于改进FDOD度量的航空发动机健康状况评估
4.1 基本步骤
利用改进FDOD度量来综合评估航空发动机的健康状况,其具体步骤如下。
根据要求,将数据规范化。
对于效益型指标(越大越好型),进行规范化:
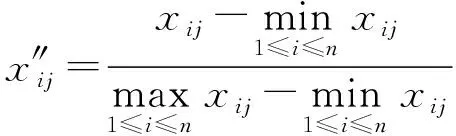
(20)
对于成本型指标(越小越好型),进行规范化:
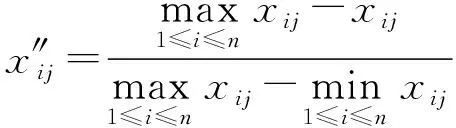
(21)
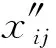
求各指标的组合权重。
首先,分别采用G1法和因子分析法确定各指标的主、客观权重;接着,基于离差最大化的组合赋权法求得各指标的组合权重。
利用Jackknife方式,根据式(5)计算所选取发动机与各类发动机的信息离散度,并按照最近邻原则进行分类。
统计分类准确率。
4.2 优点
利用改进FDOD度量对航空发动机健康状况进行综合评估,具有如下优点。
(1) 对数据要求少。
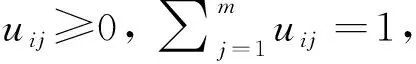
(2) 不受多重共线性的影响,同时又考虑了指标间的相关性信息,提高了分类准确率。
FDOD度量在计算过程中不涉及相关矩阵及逆矩阵,因此不受多重共线性影响。利用因子分析法对指标进行客观赋权,又考虑了指标间相关性信息,提高了样本评价准确度和分类准确率。
5 仿真分析
5.1 数据来源
本文选用仿真模型C-MAPSS生成的数据集作为样本数据。该仿真数据包含4组数据,每组数据均包含训练集和测试集。本文选取训练集FD001,该数据集包含100台发动机,记录了每台发动机从正常运行到完全故障停止运行期间的所有飞行循环数据。选取每台发动机的第一条数据作为健康样本,最后一条数据作为故障样本。因此,本文有100条健康样本数据和100条故障样本数据。所有发动机的检测数据均包含21项性能指标和3项状态指标。
发动机结构复杂,不同指标将反映不同方面的信息。如果指标过少,将难以全面反映发动机的健康状况。然而,并不是指标越多越好,过多指标将造成信息冗余,甚至给评价带来干扰。学者们基于C-MPASS平台生成的数据集进行了航空发动机相关研究,周俊提出一种基于信息理论的指标选择方法,从21项性能指标中选择了6项;Wang等先是根据数据集中所有指标的时间序列数据走势选择了11项指标,而后进一步选择若干指标进行组合,最后选出了使剩余寿命预测更准确的7项指标作为评价指标。本文基于上述文献和对数据的预处理分析,从21项性能指标中选取了7项性能指标进行发动机健康状况评估,如表2所示。

表2 航空发动机健康状况评估指标Table 2 Aero-engine health status evaluation index
5.2 数据分析与结果
(1) 对原始数据进行规范化与归一化处理
当发动机有故障发生或者压气机、涡轮效率下降时,在同样初始条件下,燃油流量和排气温度就会升高,导致指标,,,,的值变大,指标和的值变小。另外,通过对FD001中的时间序列数据进行分析可以看出,随着故障程度的加深,指标,,,,的值总体趋势逐渐变大,而指标和的值则逐渐变小。由此可见,指标,,,,属于成本型,可采用式(20)进行规范化处理;指标和属于效益型,可采用式(21)进行规范化处理。之后,再对数据进行归一化处理。
(2) 确定指标权重
首先,专家根据经验确定上述7项指标的序关系,参照表1得到相邻指标之间的重要性比值,根据式(7)和式(8)计算得到各指标的主观权重,如表3第3列所示。

表3 基于G1法求得的主观权重Table 3 Subjective weight based on G1 method
其次,利用因子分析法得到指标(,,,,,,)的客观权重:

最后,利用式(14)~式(20),得到指标(,,,,,,)的组合权重:
=[,,,,,,]=[0141, 0152, 0136, 0124, 0175, 0114, 0135]
(3) 利用Jackknife方式,将组合权重代入式(5)计算所选取发动机与各类发动机的信息离散度,并按照最近邻原则进行分类,其分类准确率如表4所示。
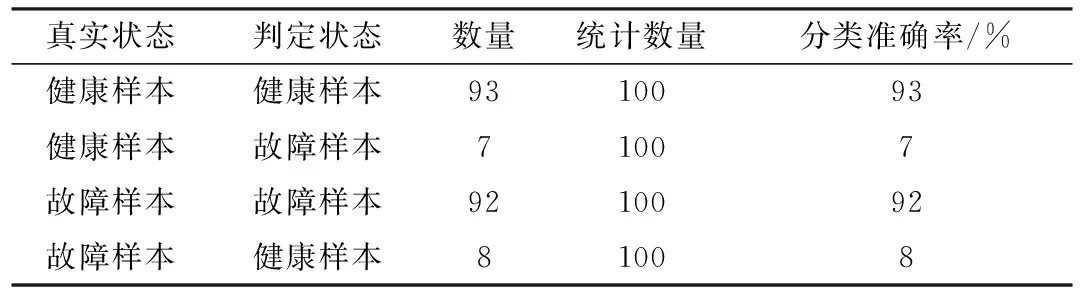
表4 分类准确率Table 4 Classification accuracy
由表4可知,健康发动机样本数据的分类准确率达到93%,故障发动机样本数据的分类准确率达到92%。
5.3 对比分析
为了进一步说明改进FDOD度量的有效性,对比分析如表5所示。
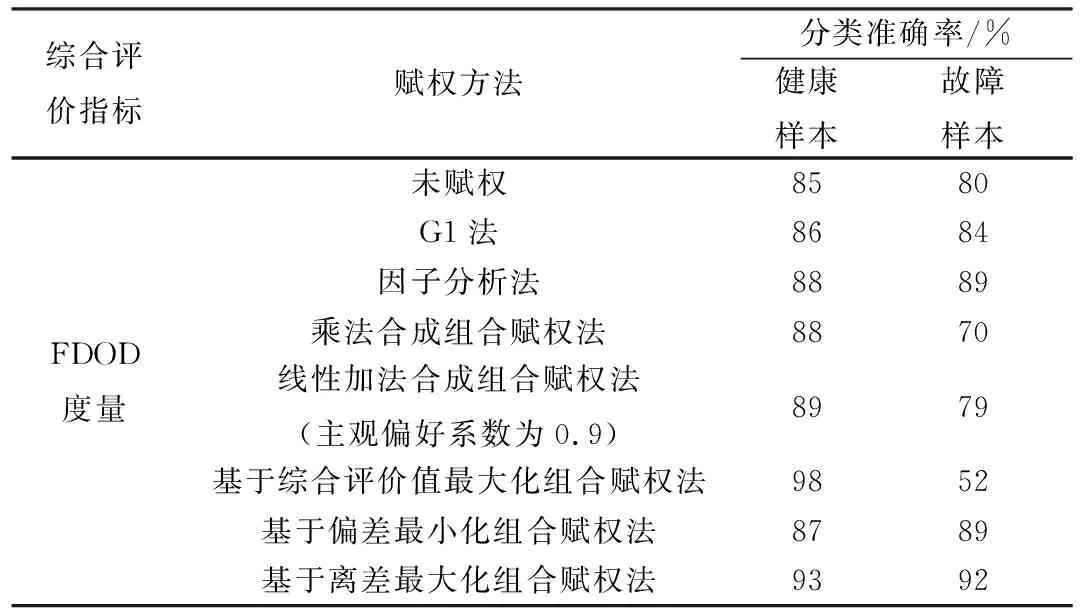
表5 不同赋权方法下结果对比分析Table 5 Comparative analysis of results under different weighting methods
由表5可知,相比于传统未加权FDOD度量,单一赋权法能提高综合评估时的分类准确率,其中因子分析法赋权效果好于G1法;采用组合赋权法时,乘法合成法、基于决策者主观偏好的线性加法合成法和基于综合评价值最大化组合赋权法仅提高了健康样本的分类准确率,故障样本的分类准确率反而降低了,而提高故障样本的分类准确率更有意义;基于偏差最小化组合赋权加权后两类样本的分类准确率均得到提高,但其均低于基于离差最大化组合赋权法加权后的分类准确率。由此可见,基于离差最大化的组合赋权法对FDOD度量的改进是最有效的,可以大幅度提高航空发动机分类的准确率。
6 结束语
本文重点研究了航空发动机健康状况的准确评估问题。分析现有综合评价方法,选择FDOD度量对航空发动机健康状况进行评估;分析传统FDOD度量在综合评价时的不足和各种赋权方法的优缺点,选用基于离差最大化的组合赋权法对FDOD度量进行改进。首先,分别使用G1法和因子分析法确定各指标的主、客观权重,接着基于离差最大化的组合赋权法确定组合权重,最后利用组合权重对传统FDOD度量进行改进。对美国国家航空航天局提供的涡扇发动机性能仿真数据进行综合评估与对比分析,结果验证了本文所选用赋权方法的科学合理性,以及改进的综合评估方法的有效性。在此基础上,将进一步研究如何对识别出来的故障发动机进行潜在异常原因分析。
